私の連絡先情報
郵便メール:
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
ハイライト: 再ランク付け

ハイライト: データ処理インデックス

ハイライトには、ドキュメントの解析、スライス、クエリの書き換え、リコール モデルの微調整が含まれます。

利点: より高い柔軟性
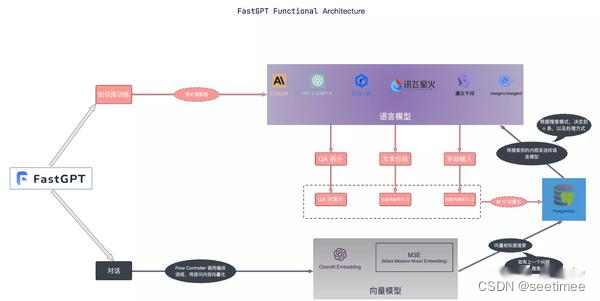
以下に各フレームワークの違いをモジュールごとに比較します。
| 機能モジュール | Q何でも | RAGFlow ラグフロー | ファストGPT | ウィズダムスペクトルAI |
|---|---|---|---|---|
| 知識処理モジュール | PDF ファイルの解析は PyMUPDF によって実装されており、現時点で最も効率的なのは PyMuPDF の get_text です。テキスト ドキュメントと画像ドキュメントは区別されません (画像ドキュメントにテキストがない場合はエラーになります)。報告されます) | OCR、ドキュメント レイアウト分析など、これらは通常の RAG に目立たない非構造化ローダーとして含まれている場合があります。RagFlow の中核機能の 1 つはファイル解析プロセスにあると推測できます。 | ||
| リコールモジュール | ベクトル ライブラリは milvus のハイブリッド検索 (BM25 ベクトル検索) を使用し、しきい値を設定せず、topk (100) を返します。 | ベクター データベースは ElasticSearch を使用します。ハイブリッド検索では、テキスト検索ベクトル検索が実装されています。特定のベクトル モデルは指定されていませんが、テキスト検索の単語セグメンタとして huqie が使用されます。 | セマンティック検索 セマンティック検索モードでは、高度なベクトル モデル テクノロジを使用して、知識ベース内のデータ セットを高次元ベクトル空間内の点に変換します。この空間では、各ドキュメントまたはデータ項目は、データの意味情報をキャプチャするベクトルとして表されます。ユーザーがクエリを提示すると、システムは質問をベクトルに変換し、ベクトル空間で知識ベース内のベクトルとの類似度計算を実行して、最も関連性の高い結果を見つけます。利点: クエリのより深い意味を理解して捕捉し、より正確な検索結果を提供する能力。 アプリケーション シナリオ: 学術研究、技術的問題解決など、深い意味理解と複雑なクエリ処理が必要な状況に適しています。 技術的な実装: text-embedding-ada-002 などのモデルを使用してテキスト データを埋め込み、効率的なセマンティック マッチングを実現します。全文検索 全文検索モードはドキュメントの全文コンテンツのインデックス作成に重点を置いており、ユーザーはキーワードを入力してドキュメントを検索できます。このモードでは、文書内の各用語を分析し、すべての文書を含む索引データベースを構築するため、ユーザーは任意の単語や語句から関連文書をすばやく見つけることができます。利点: 検索速度が速く、多数の文書に対して広範な検索を実行できるため、ユーザーは特定の単語を含む文書を素早く見つけるのに便利です。 アプリケーション シナリオ: ニュース レポート、オンライン ライブラリなど、ドキュメント ライブラリの包括的な検索が必要なシナリオに適しています。 技術的な実装: 逆索引テクノロジを使用してキーワードからドキュメントを迅速に検索し、TF-IDF などのアルゴリズムと組み合わせて検索結果の関連性を最適化します。ハイブリッド検索 ハイブリッド検索モードは、セマンティック検索の深い理解と全文検索の迅速な応答を組み合わせ、正確かつ包括的な検索エクスペリエンスを提供することを目的としています。このモードでは、システムはキーワード マッチングを実行するだけでなく、意味的類似性の計算を組み合わせて、検索結果の関連性と正確性を保証します。利点: 全文検索の速度と意味検索の深さを考慮して、バランスの取れた検索ソリューションを提供し、ユーザーの満足度を向上させます。 アプリケーション シナリオ: オンライン カスタマー サービス、コンテンツ推奨システムなど、検索速度と結果の品質を総合的に考慮する必要があるシナリオに適しています。 技術的な実装: 逆インデックスとベクトル空間モデルを組み合わせることで、ユーザーのクエリに対する包括的な理解と迅速な応答が実現します。たとえば、全文検索を通じて候補セットをすばやくフィルタリングし、セマンティック検索を通じて候補セットから最も関連性の高い結果を見つけることができます。 ベクトル モデルは以下を使用します。 BGE-M3 はベクトル検索とテキスト検索を通じてデータを呼び出し、RFF アルゴリズムを使用して並べ替えます。 | 記事構造のスライスと小規模から大規模へのインデックス戦略を採用することは、良い解決策となる可能性があります。後者の場合、埋め込みモデルを微調整する必要があります。データを構築するための 4 つの異なるスキームがあり、どれも実際にうまく機能します。 クエリとオリジナル: シンプルで効率的。データ構造はユーザー クエリを直接使用してナレッジ ベースの断片を呼び出します。つまり、保守が簡単です。ユーザーのクエリを使用すると、コールド スタート中に、モデルの自動化を使用して、対応するナレッジ フラグメントからクエリを抽出できます。クエリとサマリー: クエリを使用して、ナレッジ フラグメントのサマリーを呼び出し、サマリーとサマリーの間のマッピング関係を構築します。知識の断片; F 回答とオリジナル: ユーザーのクエリに基づいて偽の回答を生成し、知識の断片を思い出します。埋め込みモデルの微調整 |
| モジュールを再配置する | 精度の並べ替えでは独自の再ランク付けモデルが使用されますが、しきい値は 0.35 に設定されます。 | 再配置は、テキスト マッチング スコアとベクトル マッチング スコアの混合に基づいて行われます。テキスト マッチングのデフォルトの重みは 0.3、ベクトル マッチングの重みは 0.7 です。 | 並べ替えをサポートし、埋め込みとフルテキストのマージ結果を動的に設定し、ID に基づいて重複を削除します。QA 文字列を連結し、スペースと句読点を削除し、文字列をハッシュ エンコードし、再ランク付けモデルが設定されている場合は重複を削除します。順序が変更され、リランク スコアがスコアに追加されます。そうでない場合、リランク スコアは追加されません。 | |
| 大型モデルの取り扱い | すべてのデータをまとめて整理するよう求めるプロンプト (最大トークン用に最適化) | 大規模モデルで利用可能なトークンの数でフィルタリングする | モデルの微調整には段階的微調整が採用されています。つまり、最初にオープンソースの一般的な質問と回答データを使用して微調整が実行され、次に垂直ドメインの質問と回答データを使用して微調整が実行され、最後に微調整が行われます。手動で注釈が付けられた高品質の質問と回答のデータを使用して実行されます。 | |
| ウェブサービス | Sanic を使用して Web サービスを実装する | フラスコ | ファスタピ | |
| 単語分割処理 | カスタム ChineseTextSplitter が完成しました | フーキー | ||
| ファイルストレージ | ファイルストレージはMinIOを使用します | |||
| ハイライト | 従来のRAGと比較して、リランク処理において微調整が行われています。 | 解析処理の記述も非常に複雑なので、処理速度が少し遅くなるのも不思議ではありません。ただし、処理効果は他の RAG プロジェクトよりも優れていることが期待されます。実際のフロントエンドで表示されるデモから判断すると、RAGFlow は解析されたテキスト ブロックを元のドキュメント内の元の位置に関連付けることができます。この効果は、現時点では RagFlow だけが実現しているようです。 | FastGPT は、RAG の主流の実装をカバーする 3 つの取得モードを提供します。 データの重複を除去し、最も高いスコアを使用して rrfScore を計算し、それに基づいて並べ替えます。 |
要約:
1. Qanything 再ランク モジュールは最適に設計されています
2.RAGFlowのドキュメント処理が最高
3. FastGPT モジュールには多くの動的構成があります
4. Wisdom Spectrum RAG は、ドメイン データのトレーニングを微調整するのに最適です
完全な次元。自分のビジネスのデータに関しては、それを実行できるのが最善です。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: