le mie informazioni di contatto
Posta[email protected]
2024-07-11
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
In evidenza: riclassificazione

In evidenza: indice di elaborazione dati

I punti salienti includono l'analisi dei documenti, il sezionamento, la riscrittura delle query e la messa a punto del modello di richiamo.

Vantaggi: Maggiore flessibilità
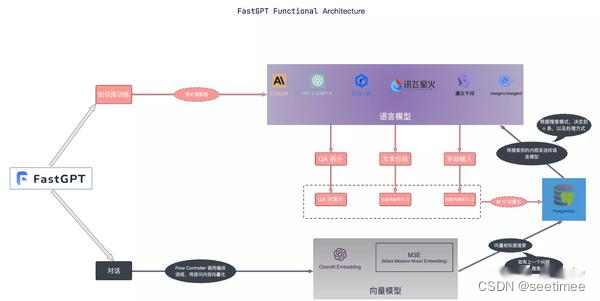
Di seguito vengono confrontate le differenze di ciascun framework in base ai moduli.
| modulo funzionale | QQualsiasi cosa | RAGFLow | GPT veloce | Spettro della saggezza AI |
|---|---|---|---|---|
| Modulo di elaborazione della conoscenza | L'analisi dei file PDF è implementata da PyMUPDF, che attualmente è il più efficiente. get_text di PyMuPDF viene utilizzato per analizzare il testo del documento. Non distingue tra documenti di testo e documenti di immagine (se non è presente testo nel documento di immagine, viene visualizzato un errore verrà segnalato) | OCR, Analisi del layout dei documenti, ecc., questi possono essere inclusi come un caricatore non strutturato poco appariscente nel normale RAG. Puoi immaginare che una delle funzionalità principali di RagFlow risieda nel processo di analisi dei file. | ||
| modulo di richiamo | La libreria vettoriale utilizza il recupero ibrido di milvus (recupero vettoriale BM25), non imposta una soglia e restituisce topk (100) | Il database vettoriale utilizza ElasticSearch.Il recupero ibrido implementa il recupero del vettore di recupero del testo. Non è specificato alcun modello vettoriale specifico, ma huqie viene utilizzato come segmentatore di parole per il recupero del testo. | Recupero semantico La modalità di recupero semantico utilizza la tecnologia avanzata del modello vettoriale per convertire i set di dati nella base di conoscenza in punti nello spazio vettoriale ad alta dimensione. In questo spazio ogni documento o dato è rappresentato come un vettore che cattura l'informazione semantica dei dati. Quando un utente pone una query, il sistema converte anche la domanda in un vettore ed esegue calcoli di somiglianza nello spazio vettoriale con i vettori nella knowledge base per trovare i risultati più rilevanti. Vantaggi: capacità di comprendere e acquisire il significato più profondo delle query e fornire risultati di ricerca più accurati. Scenari applicativi: adatti a situazioni che richiedono una profonda comprensione semantica e un'elaborazione di query complesse, come ricerca accademica, risoluzione di problemi tecnici, ecc. Implementazione tecnica: utilizzare modelli come text-embedding-ada-002 per incorporare dati di testo per ottenere una corrispondenza semantica efficiente. Ricerca full-text La modalità di ricerca full-text si concentra sull'indicizzazione del contenuto full-text dei documenti, consentendo agli utenti di cercare documenti inserendo parole chiave. Questa modalità analizza ogni termine nel documento e crea un database di indice contenente tutti i documenti, consentendo agli utenti di trovare rapidamente i documenti rilevanti attraverso qualsiasi parola o frase. Vantaggi: la velocità di recupero è elevata e può condurre ricerche estese su un gran numero di documenti, rendendo conveniente per gli utenti individuare rapidamente documenti contenenti parole specifiche. Scenari applicativi: adatti a scenari che richiedono ricerche complete di raccolte di documenti, come notizie, biblioteche online, ecc. Implementazione tecnica: utilizza la tecnologia dell'indice invertito per individuare rapidamente i documenti tramite parole chiave e combinala con algoritmi come TF-IDF per ottimizzare la pertinenza dei risultati di ricerca. Recupero ibrido La modalità di recupero ibrido combina la profonda comprensione del recupero semantico con la risposta rapida del recupero del testo completo, con l'obiettivo di fornire un'esperienza di ricerca accurata e completa. In questa modalità, il sistema non solo esegue la corrispondenza delle parole chiave, ma combina anche calcoli di somiglianza semantica per garantire la pertinenza e l'accuratezza dei risultati di ricerca. Vantaggi: tenendo conto della velocità di recupero del testo completo e della profondità del recupero semantico, fornisce una soluzione di ricerca equilibrata e migliora la soddisfazione dell'utente. Scenari applicativi: adatti a scenari in cui la velocità di recupero e la qualità dei risultati devono essere considerate in modo completo, come il servizio clienti online, i sistemi di raccomandazione dei contenuti, ecc. Implementazione tecnica: combinando l'indice invertito e il modello dello spazio vettoriale, si ottiene una comprensione completa e una risposta rapida alle domande degli utenti. Ad esempio, puoi filtrare rapidamente il set di candidati tramite la ricerca full-text e quindi trovare i risultati più pertinenti dal set di candidati tramite la ricerca semantica. Il modello vettoriale utilizza: BGE-M3 richiama i dati tramite il recupero del vettore e il recupero del testo e utilizza l'algoritmo RFF per l'ordinamento; | Adottare il suddivisione della struttura degli articoli e una strategia di indicizzazione da piccola a grande può essere una buona soluzione. Per quest'ultimo, il modello di incorporamento deve essere messo a punto. Abbiamo quattro diversi schemi per la costruzione dei dati, che funzionano tutti bene nella pratica: Query vs Original: semplice ed efficiente, la struttura dei dati utilizza direttamente la query dell'utente per richiamare frammenti della knowledge base: Query vs Query: facile da mantenere, cioè; l'utilizzo della query dell'utente richiama la query. Durante l'avvio a freddo, è possibile utilizzare l'automazione del modello per estrarre la query dal frammento di conoscenza corrispondente; Query vs riepilogo: utilizzare la query per richiamare il riepilogo del frammento di conoscenza e creare una relazione di mappatura tra il riepilogo e il frammento di conoscenza; Risposta F vs originale: genera risposte false basate sulle query degli utenti per richiamare frammenti di conoscenza.Messa a punto del modello di incorporamento |
| riorganizzare il modulo | L'ordinamento di precisione utilizza il proprio modello di riclassificazione, ma la soglia è fissata a 0,35 | La riorganizzazione si basa su una combinazione di punteggi di corrispondenza del testo e punteggi di corrispondenza dei vettori. Il peso predefinito della corrispondenza del testo è 0,3 e il peso della corrispondenza dei vettori è 0,7. | Supporta il riordino, imposta dinamicamente i risultati dell'unione di incorporamento e testo completo e rimuove la duplicazione in base all'ID; concatena le stringhe qa, rimuove spazi e segni di punteggiatura, codifica tramite hash le stringhe e rimuove la duplicazione se il modello di riclassificazione è configurato, chiama The model viene riordinato e il punteggio di riclassificazione viene aggiunto al punteggio, in caso contrario, il punteggio di riclassificazione non verrà aggiunto; | |
| Manipolazione di modelli di grandi dimensioni | Richiedi di organizzare tutti i dati insieme (ottimizzato per il token massimo) | Filtra in base al numero di token disponibili per i modelli di grandi dimensioni | Per la messa a punto del modello, viene adottata la messa a punto per fasi, ovvero la prima messa a punto viene eseguita utilizzando dati generali di domande e risposte open source, quindi la messa a punto viene eseguita utilizzando dati di domande e risposte del dominio verticale e infine la messa a punto viene eseguito utilizzando domande e risposte di alta qualità annotate manualmente. | |
| servizio web | Utilizzo di sanic per implementare i servizi web | Borraccia | Fastapi | |
| Elaborazione della segmentazione delle parole | ChineseTextSplitter personalizzato completato | huqie | ||
| Archiviazione di file | L'archiviazione dei file utilizza MinIO | |||
| Punti salienti | Rispetto al RAG convenzionale, sono state apportate modifiche precise nel processo di riclassificazione. | Anche il processo di analisi è molto complicato da scrivere, quindi non c'è da stupirsi che la velocità di elaborazione sia un po' lenta. Tuttavia, si prevede che l’effetto di elaborazione sarà migliore rispetto ad altri progetti RAG. A giudicare dalla demo visualizzata sul front-end reale, RAGFlow può associare il blocco di testo analizzato alla posizione originale nel documento originale. Questo effetto è piuttosto sorprendente Attualmente, sembra che solo RagFlow abbia ottenuto un effetto simile. | FastGPT fornisce tre modalità di recupero, coprendo le implementazioni tradizionali in RAG. Deduplica i dati e utilizza il punteggio più alto; calcola rrfScore e ordina in base ad esso; |
Riassumere:
1. Il modulo di riclassificazione Qanything è il meglio progettato
2. L'elaborazione dei documenti RAGFlow è la migliore
3. Il modulo FastGPT ha molte configurazioni dinamiche
4. Wisdom Spectrum RAG è la soluzione migliore per perfezionare la formazione sui dati di dominio
dimensione intera. Non c'è niente di meglio in termini di dati della tua attività, è il meglio essere in grado di implementarlo~

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]