2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Die COVID-19-Epidemie betrifft die Herzen eines jeden von uns. In diesem Fall werden wir versuchen, mithilfe von Social-Computing-Methoden Nachrichten und Gerüchte im Zusammenhang mit der Epidemie zu analysierenInformationen zur Epidemie Forschung. Bei dieser Aufgabe handelt es sich um eine offene Aufgabe. Wir stellen soziale Daten während der Epidemie bereit und ermutigen die Schüler, soziale Trends anhand von Nachrichten, Gerüchten und Rechtsdokumenten zu analysieren. (Tipp: Nutzen Sie die im Unterricht erlernten Methoden wie Stimmungsanalyse, Informationsextraktion, Leseverständnis usw., um Daten zu analysieren.)
https://covid19.thunlp.org/ bietet soziale Dateninformationen im Zusammenhang mit der neuen Coronavirus-Epidemie, einschließlich epidemiebezogener Gerüchte (CSDC-Rumor), epidemiebezogener chinesischer Nachrichten (CSDC-News) und epidemiebezogener Rechtsdokumente (CSDC-Legal).
Dieser Teil des erfassten Datensatzes:
(1) Ab dem 22. Januar 2020Weibo falsche InformationenDie Daten umfassen den Inhalt von Weibo-Beiträgen, die als falsche Informationen gelten, Herausgeber, Whistleblower, Verhandlungszeit, Ergebnisse und andere Informationen. Mit Stand vom 1. März 2020 gibt es insgesamt 324 Weibo-Originaltexte, 31.284 Weiterleitungen und 7.912 Kommentare . , um Forschern bei der Analyse und Untersuchung der Verbreitung falscher Informationen während der Epidemie zu helfen;
(2) Tencents Gerüchteverifizierungsplattform und Dingxiangyuans Falschinformationsdaten seit dem 18. Januar 2020, einschließlich des Inhalts des Gerüchts, der als richtig oder falsch angesehen wird, des Zeitpunkts und der Grundlage für die Beurteilung, ob es sich um ein Gerücht handelt usw. Zum 1. März 2020 liegen 507 Gerüchtedaten vor, darunter 124 Sachdaten. Die Datenverteilung ist: negative Fälle: 420, positive Fälle: 33 und unsichere: 54.
Dieser Teil des Datensatzes sammelt Nachrichtendaten ab dem 1. Januar 2020, einschließlich Titel, Inhalt, Schlüsselwörtern und anderen Informationen der Nachrichten. Mit Stand vom 16. März 2020 wurden insgesamt 148.960 Nachrichten und 1.653.086 entsprechende Kommentare gesammelt. Wird verwendet, um Forschern bei der Analyse und Untersuchung von Nachrichtendaten während der Epidemie zu helfen.
Diese Daten stammen von CAIL Aus den gesammelten anonymisierten Rechtsdokumentdaten wurden insgesamt 1.203 Teile historischer epidemiebezogener Dokumente herausgefiltert. Zu jedem Datenelement gehören der Dokumenttitel, die Fallnummer und der vollständige Text des Dokuments, die von Forschern für die Durchführung von Recherchen verwendet werden können zu relevanten rechtlichen Fragen während der Epidemie.
Bei dieser Aufgabe handelt es sich um eine offene Aufgabe, mit der wir beginnen
Benotung von Aufgaben in anderen Aspekten.
[1] Glaubwürdigkeit von Informationen auf Twitter. in Proceedings of WWW, 2011.
[2] Erkennen von Gerüchten aus Microblogs mit rekurrierenden neuronalen Netzwerken. in Proceedings of IJCAI, 2016.
[3] Ein faltender Ansatz zur Identifizierung von Fehlinformationen. in Proceedings of IJCAI, 2017.
[4] Die Verbreitung von wahren und falschen Nachrichten im Internet. Science, 2018.
[5] Falsche Informationen im Internet und in sozialen Medien: Eine Untersuchung. arXiv-Vorabdruck, 2018.
[6] Charakterisierung der affektiven Normen für englische Wörter durch diskrete emotionale Kategorien. Methoden der Verhaltensforschung, 2007.
Dieses Experiment liefert den epidemiebezogenen Gerüchtedatensatz CSDC-Rumor. Durch die Analyse des Inhalts des Datensatzes führen wir zunächst eine quantitative statistische Analyse des Datensatzes durch, verwenden dann Clustering, um eine semantische Analyse von Gerüchten zu implementieren, und entwerfen schließlich einen Gerüchteerkennungssystem.
Datei Format
Dieses Experiment stellt den epidemiebezogenen Gerüchtedatensatz CSDC-Rumor bereit, der Weibo-Falschinformationsdaten und Daten zur Widerlegung von Gerüchten sammelt. Der Datensatz enthält Folgendes.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Weibo falsche Informationenjeweils von rumor_weibo Undrumor_forward_comment zwei mit demselben Namenjson in der Datei beschrieben.rumor_weibo Mittejson Die spezifischen Felder sind wie folgt:
rumorCode: Der eindeutige Code des Gerüchts, über den direkt auf die Gerücht-Meldeseite zugegriffen werden kann.title: Der Titelinhalt des gemeldeten Gerüchts.informerName: Weibo-Name des Reporters.informerUrl: Weibo-Link des Reporters.rumormongerName: Der Weibo-Name der Person, die das Gerücht veröffentlicht hat.rumormongerUr: Weibo-Link der Person, die das Gerücht gepostet hat.rumorText: Gerüchteinhalt.visitTimes: Die Häufigkeit, mit der dieses Gerücht besucht wurde.result: Die Ergebnisse dieser Gerüchtebewertung.publishTime: Der Zeitpunkt, als das Gerücht gemeldet wurde.related_url: Links zu Beweisen, Vorschriften usw. im Zusammenhang mit diesem Gerücht.rumor_forward_comment Mittejson Die spezifischen Felder sind wie folgt:
uid: Benutzer-ID veröffentlichen.text: Kommentieren oder leiten Sie das Postscript weiter.date: Veröffentlichkeitsdatum.comment_or_forward: entweder binär comment, entweder forward, was angibt, ob es sich bei der Nachricht um einen Kommentar oder ein weitergeleitetes Postscript handelt.Falsche Informationen von Tencent und Lilac GardenDas Inhaltsformat ist:
date: Zeitexplain: Gerüchtetyptag:gerüchte-Tagabstract: Inhalte, die zur Überprüfung von Gerüchten verwendet werdenrumor: GerüchtDatenvorverarbeitung
passieren json.load() Extrahieren Sie Gerüchte-Weibo-Daten separatweibo_data Kommentar zur Weiterleitung von Daten mit Gerüchtenforward_comment_data und konvertieren Sie es dann in das DataFrame-Format. Die beiden Dateien mit demselben Namen, Weibo-Artikel und Weibo-Kommentarweiterleitung, entsprechen einander. Fügen Sie bei der Verarbeitung der Daten im Ordner „rumrum_forward_comment“ „rumumCode“ für den anschließenden Abgleich hinzu.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
In diesem Abschnitt wird eine quantitative statistische Analyse verwendet, um ein spezifisches Verständnis der Verteilung der Weibo-Daten zu Epidemiegerüchten zu erlangen.
Statistiken über die Häufigkeit, mit der Gerüchte besucht wurden
Statistiken weibo_df['visitTimes'] Verteilung der Zugriffszeiten und Zeichnen des entsprechenden Histogramms. Die Ergebnisse sind wie folgt.
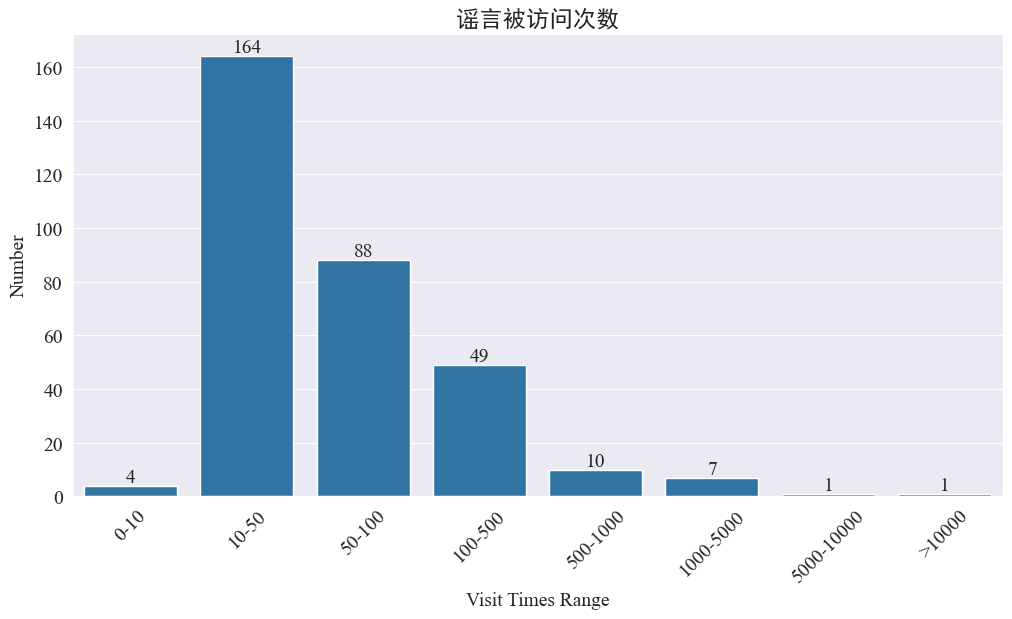
Gemessen an der Anzahl der Besuche auf Weibo wurden die meisten Epidemiegerüchte weniger als 500 Mal auf Weibo besucht, wobei 10–50 den größten Anteil ausmachen. Allerdings gibt es auf Weibo auch mehr als 5.000 Mal aufgerufene Gerüchte, die schwerwiegende Auswirkungen haben und rechtlich als „schwerwiegend“ gelten.
Statistiken zum Auftreten von Gerüchtemachern und Whistleblowern
durch Statistiken weibo_df['rumormongerName'] Undweibo_df['informerName'] Die Anzahl der von jedem Gerüchteherausgeber veröffentlichten Gerüchte und die Anzahl der von jedem Reporter gemeldeten Gerüchte werden wie folgt ermittelt.
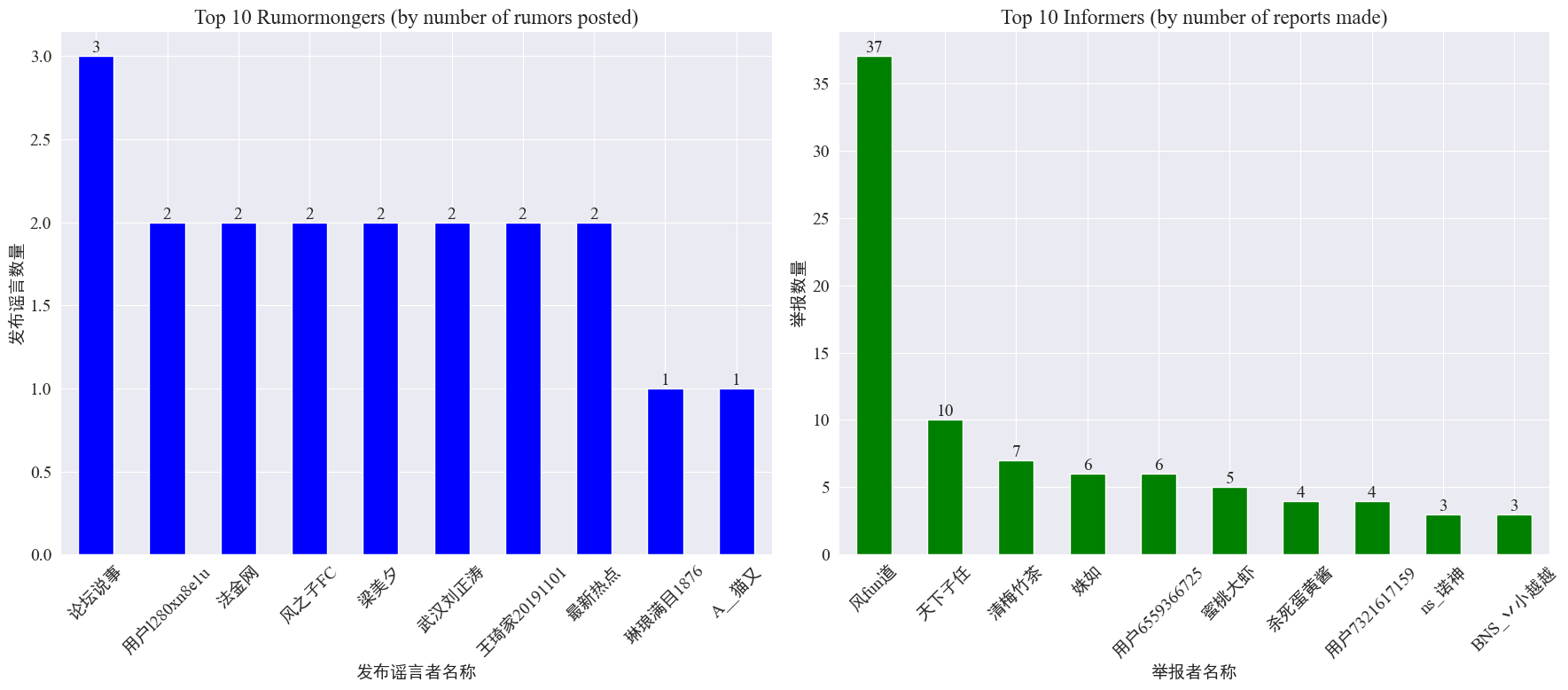
Es ist zu erkennen, dass sich die Anzahl der von Gerüchtemachern geposteten Gerüchte nicht auf wenige Personen konzentriert, sondern relativ gleichmäßig ist. Der Account, der die meisten Gerüchte gepostet hat, hat drei Gerüchte-Weibo-Beiträge gepostet. Jeder der Top-10-Whistleblower meldete mindestens drei Gerüchteartikel. Unter ihnen war die Anzahl der von Whistleblowern auf Weibo gemeldeten Gerüchte deutlich höher als die der anderen Nutzer und erreichte 37 Artikel.
Basierend auf den oben genannten Daten kann sich das Publikum auf die Meldung von Konten mit einer großen Anzahl von Gerüchten konzentrieren, um die Erkennung von Gerüchten zu erleichtern.
Verteilungsstatistik von Gerüchten, die Kommentare weiterleiten
Durch Zählen der Verteilung des Gerüchteweiterleitungsvolumens und des Kommentarvolumens erhält man das folgende Verteilungsbild.

Es ist ersichtlich, dass die Anzahl der Kommentare und Reposts bei den meisten Gerüchten auf Weibo innerhalb des Zehnfachen liegt, wobei die maximale Anzahl an Kommentaren 500 nicht überschreitet und die maximale Anzahl an Reposts mehr als 10.000 erreicht. Wenn ein Gerücht mehr als 500 Mal weitergegeben wird, gilt es laut Internet-Management-Gesetz als „ernsthafte“ Situation.
Analyse von Gerüchtetextclustern
Dieser Teil führt eine Datenvorverarbeitung für Weibo-Gerüchtetexte durch und führt nach der Wortsegmentierung eine Clusteranalyse durch, um zu sehen, wo Weibo-Gerüchte konzentriert sind.
Datenvorverarbeitung
Bereinigen Sie zunächst den Gerüchtdatentext, entfernen Sie die Standardwerte und <> Der beigefügte Linkinhalt.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Laden Sie dann chinesische Stoppwörter und verwenden Sie die Stoppwörter cn_Stoppwörter ,verwendenjieba Implementieren Sie die Wortsegmentierungsverarbeitung von Daten und führen Sie eine Textvektorisierung durch.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Bestimmen Sie die beste Clusterbildung
Mithilfe der Ellenbogenmethode werden die besten Cluster ermittelt.
Die Elbow-Methode ist eine Methode zur Bestimmung der optimalen Anzahl von Clustern in der Clusteranalyse. Es basiert auf der Beziehung zwischen der Summe der quadratischen Fehler (SSE) und der Anzahl der Cluster. SSE ist die Summe der quadrierten euklidischen Abstände aller Datenpunkte im Cluster zum Clusterzentrum, zu dem es gehört. Es spiegelt den Effekt des Clusterings wider: Je kleiner der SSE, desto besser der Clustering-Effekt.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
Die Ellbogenmethode ermittelt die optimale Anzahl von Clustern, indem sie nach dem „Ellenbogen“ sucht, d. h. nach einem Punkt auf der Kurve, nach dem sich die SSE-Abnahmerate erheblich verlangsamt Name „ Ellenbogenmethode“. Dieser Punkt wird normalerweise als die optimale Anzahl von Clustern angesehen.
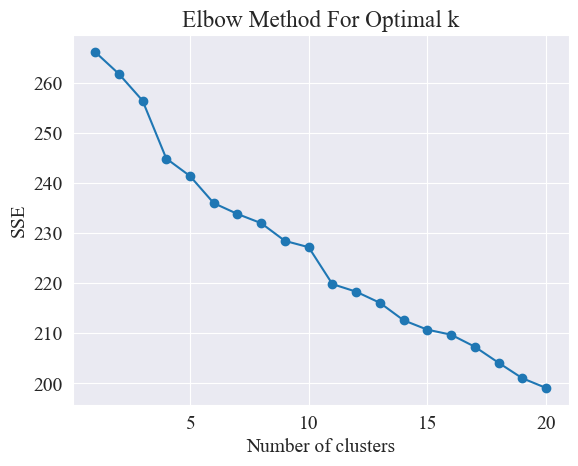
Aus der obigen Abbildung wird ermittelt, dass der Clustering-Wert des Ellbogens 11 beträgt, und das entsprechende Streudiagramm wird wie folgt gezeichnet.
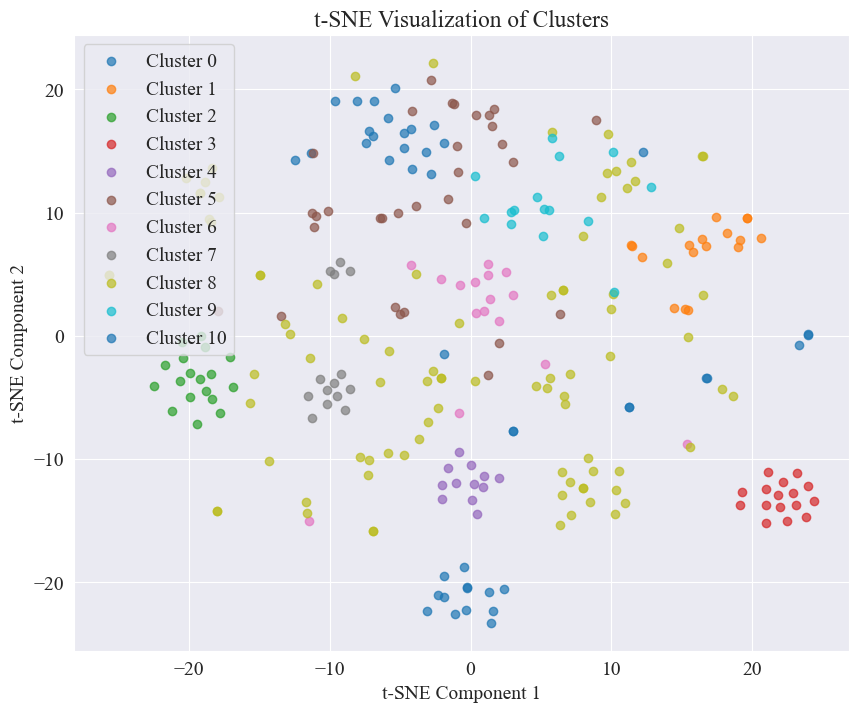
Es ist ersichtlich, dass die meisten Weibo-Gerüchte gut gruppiert sind, einige sind weit verbreitet und nicht gut gruppiert, wie z. B. Nr. 5 und Nr. 8.
Clustering-Ergebnisse
Um deutlich zu machen, welche Gerüchte in den einzelnen Kategorien gebündelt sind, wird für jede Kategorie ein Wolkendiagramm erstellt. Die Ergebnisse sind wie folgt.

Drucken Sie einige gut gebündelte Gerüchte über Weibo-Inhalte aus, und die Ergebnisse sind wie folgt.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Clusteranalyse der Ergebnisse der Gerüchteprüfung
Das Gruppieren des Gerüchtetextinhalts ist für die Analyse des Gerüchteinhalts möglicherweise nicht so gut, daher haben wir uns dafür entschieden, die Ergebnisse der Gerüchteüberprüfung zu gruppieren.
Bestimmen Sie die beste Clusterbildung
Bestimmen Sie mithilfe des Ellenbogendiagramms die beste Clusterbildung.
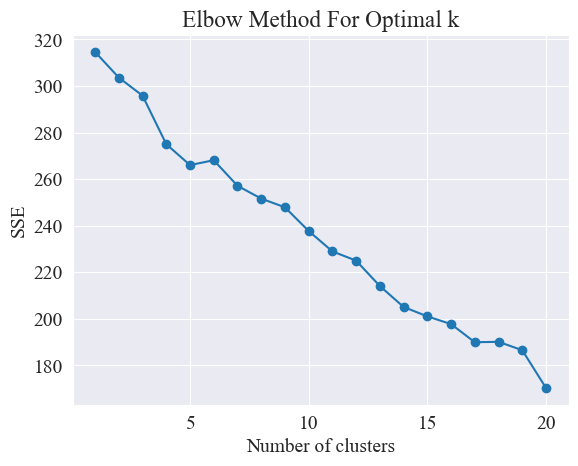
Aus dem obigen Ellbogendiagramm können zwei Ellenbogen bestimmt werden, einer bei einer Clusterbildung von 5 und der andere bei einer Clusterbildung von 20. Ich wähle 20 für die Clusterbildung.
Das durch Clustering von 20 Kategorien erhaltene Streudiagramm sieht wie folgt aus.
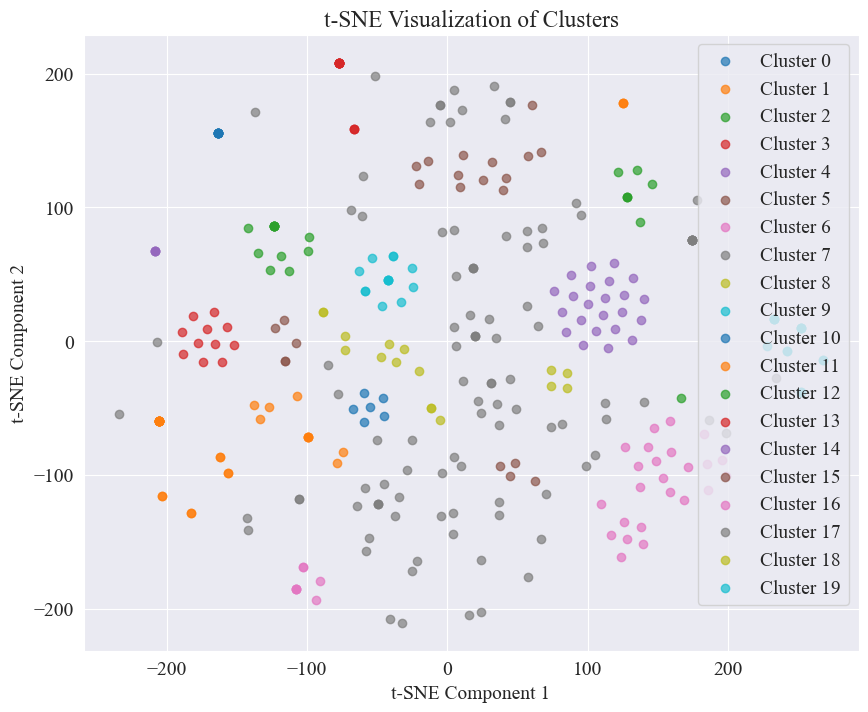
Es ist ersichtlich, dass die meisten von ihnen gut geclustert sind, die 7. und 17. Kategorie jedoch nicht gut geclustert sind.
Clustering-Ergebnisse
Um deutlich zu machen, welche Gerüchtebewertungsergebnisse in den einzelnen Kategorien zusammengefasst sind, wird für jede Kategorie ein Wolkendiagramm erstellt. Die Ergebnisse sind wie folgt.

Drucken Sie einige gut zusammengefasste Ergebnisse der Gerüchteprüfung aus.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Für diese Gerüchteerkennung haben wir uns für die Verwendung widerlegter Datensätze entschieden. fact.json Vergleichen Sie die Ähnlichkeit zwischen widerlegten Gerüchten und echten Gerüchten und wählen Sie den widerlegten Artikel mit der höchsten Ähnlichkeit zum Gerücht Weibo als Grundlage für die Gerüchteerkennung aus.
Laden Sie Weibo-Gerüchtedaten und Datensätze, die Gerüchte widerlegen
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Verwenden Sie vorab trainierte Sprachmodelle, um Weibo-Gerüchte und Gerüchte widerlegende Titel in Einbettungsvektoren zu kodieren
in diesem Experiment verwendet bert-base-chinese Führen Sie als vorab trainiertes Modell ein Modelltraining durch. Das SimCSE-Modell wird verwendet, um die Darstellung und Ähnlichkeitsmessung der Satzsemantik durch kontrastives Lernen zu verbessern.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Berechnen Sie die Ähnlichkeit
Zur Berechnung der Ähnlichkeit werden die Satzeinbettung und die Ähnlichkeit benannter Entitäten des SimCSE-Modells verwendet, um die umfassende Ähnlichkeit zu berechnen.
extract_entitiesDie Funktion extrahiert benannte Entitäten aus Text mithilfe des NER-Modells.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityDie Funktion berechnet die benannte Entitätsähnlichkeit zwischen zwei Texten.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityDie Funktion kombiniert die Satzeinbettung und die Ähnlichkeit benannter Entitäten des SimCSE-Modells, um die umfassende Ähnlichkeit zu berechnen.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Implementieren Sie die Erkennung von Gerüchten
Durch den Vergleich von Ähnlichkeiten wird ein Mechanismus zur Gerüchteerkennung implementiert.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
Die Ausgabe ist wie folgt:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Es gelang, die Grundlage für die Widerlegung der Gerüchte zu finden und ein Urteil zur Widerlegung der Gerüchte zu fällen.
Datei Format
Dieses Experiment stellt den epidemiebezogenen Nachrichtendatensatz CSDC-News bereit, der Nachrichten- und Kommentarinhalte im ersten Halbjahr 2020 sammelt. Der Datensatz enthält Folgendes.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
Der Datenordner ist in drei Teile unterteilt:data,comment。
data Der Ordner enthält mehrere Dateien, jede Datei entspricht Daten eines bestimmten Datums im Formatjson . Der Inhalt dieses Teils entspricht den Textdaten der Nachrichten (wird nach und nach mit dem Datum aktualisiert), und die Felder umfassen:
time: Zeitpunkt der Pressemitteilung.title:Der Titel der Nachricht.url: Der ursprüngliche Adresslink der Nachrichten.meta: Die Textinformationen der Nachrichten, die die folgenden Felder umfassen: content: Der Textinhalt der Nachrichten.description: Eine kurze Beschreibung der Neuigkeiten.title:Der Titel der Nachricht.keyword: Nachrichtenschlüsselwörter.type: Art der Nachrichten.comment Der Ordner enthält mehrere Dateien, jede Datei entspricht Daten eines bestimmten Datums im Formatjson . Dieser Teil des Inhalts entspricht den Kommentardaten der Nachrichten (es kann zu einer Verzögerung von etwa einer Woche zwischen den Kommentardaten und den Nachrichtentextdaten kommen).
time: Zeitpunkt der Pressemitteilung und data Entspricht den Daten im Ordner.title: Der Titel der Nachricht, mit data Entspricht den Daten im Ordner.url: Der ursprüngliche Adresslink der Nachrichten und data Entspricht den Daten im Ordner.comment: Nachrichtenkommentarinformationen. Dieses Feld ist ein Array. Jedes Element des Arrays enthält die folgenden Informationen: area: Rezensentenbereich.content:Kommentare.nickname: Spitzname des Rezensenten.reply_to: Das Antwortobjekt des Kommentators. Wenn keins vorhanden ist, bedeutet dies, dass es sich nicht um eine Antwort handelt.time: Kommentarzeit.Datenvorverarbeitung
Daten zu Nachrichtenartikeln data Bei der Datenvorverarbeitung ist es notwendigmeta Der Inhalt wird im DataFrame-Format veröffentlicht und gespeichert.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
In den Überprüfungsdaten comment Bei der Datenvorverarbeitung ist es notwendigcomment Der Inhalt wird im DataFrame-Format veröffentlicht und gespeichert.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Datensatz laden
Laden Sie den Datensatz gemäß der oben genannten Datenvorverarbeitungsfunktion.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Das Druckergebnis zeigt, dass die Länge der Nachrichtendaten 502550 und die Länge der Kommentardaten 1534616 beträgt.
Statistiken zur Nachrichtenzeitverteilung
Getrennt zählen news_df Die Anzahl der monatlichen Nachrichtenartikel und die Anzahl der Nachrichtenartikel pro Stunde werden durch Balkendiagramme und Liniendiagramme dargestellt. Die Ergebnisse sind wie folgt.
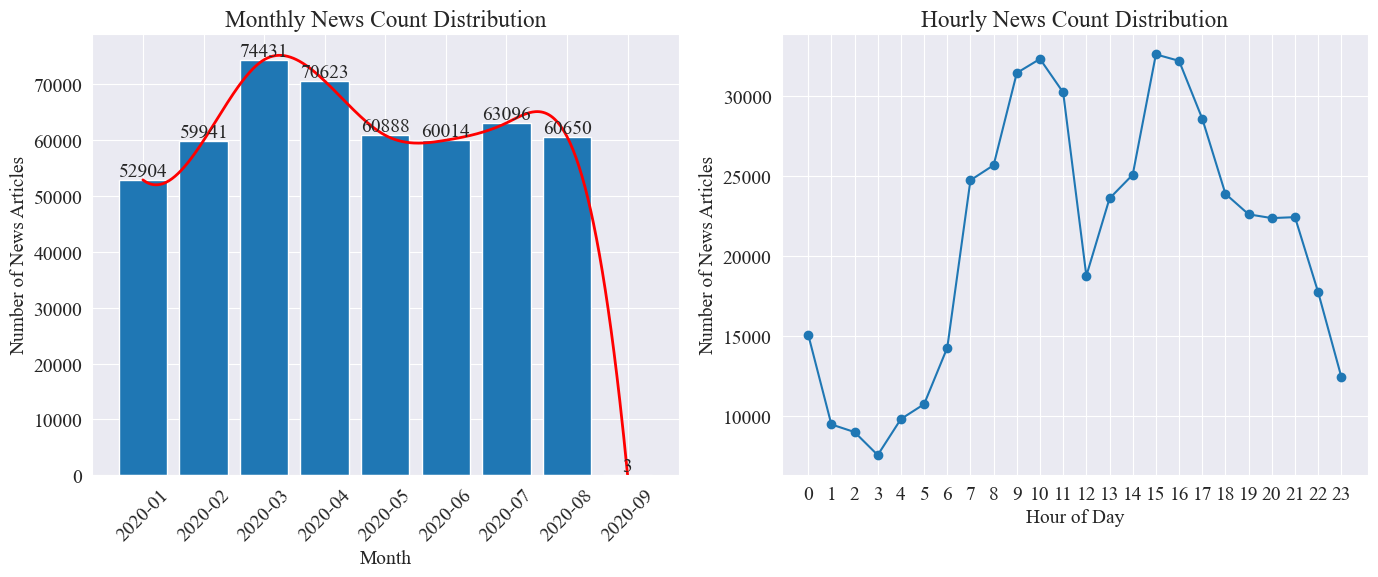
Wie aus der obigen Abbildung ersichtlich ist, stieg die Zahl der Nachrichten mit dem Ausbruch der Epidemie von Monat zu Monat an und erreichte im März mit 74.000 Nachrichtenartikeln einen Höhepunkt. Anschließend ging sie allmählich zurück und stabilisierte sich auf 60.000 Artikel pro Monat, von denen die Daten im September waren 3 bei 0:00 Artikel, möglicherweise nicht in der Statistik enthalten.
Anhand der Verteilung der Nachrichtenmenge pro Stunde lässt sich erkennen, dass täglich um 10 Uhr und um 15 Uhr die Spitzenzeiten der Nachrichtenveröffentlichung liegen, wobei jeweils mehr als 30.000 Artikel veröffentlicht werden. 12 Uhr ist Mittagspause und die Zahl der Pressemitteilungen erreicht ihren Höhepunkt und ihren Tiefpunkt. Die Mindestanzahl an Pressemitteilungen liegt täglich zwischen 0 und 17 Uhr, wobei 3 Uhr der Mindestpunkt ist.
Verfolgung von Nachrichten-Hotspots
In diesem Experiment soll die Methode der Extraktion von Nachrichtenschlüsselwörtern verwendet werden, um die Nachrichten-Hotspots in diesen acht Monaten zu verfolgen. Durch Zählen der Verteilung vorhandener Schlüsselwörter und Zeichnen eines Histogramms ergeben sich folgende Ergebnisse.
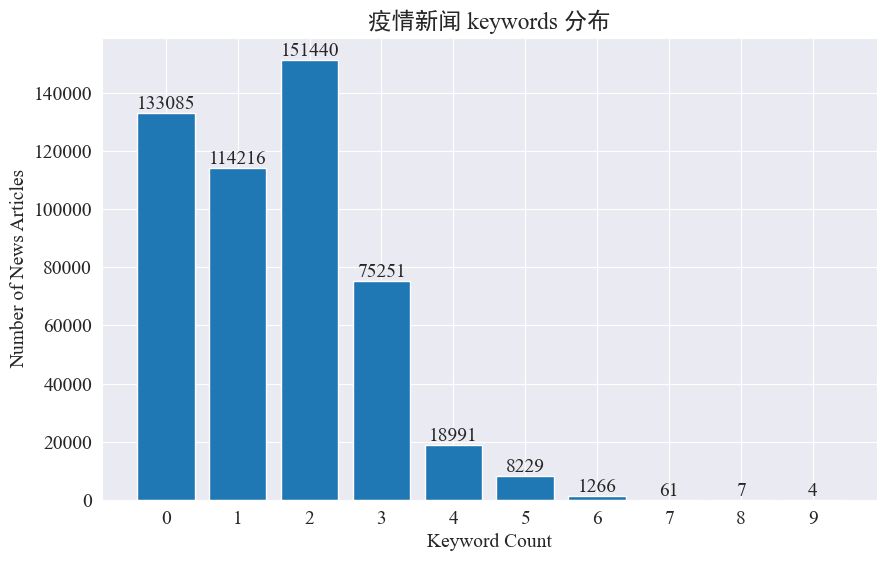
Es ist ersichtlich, dass die meisten Nachrichtenartikel weniger als 3 Schlüsselwörter haben und ein großer Teil der Artikel sogar keine Schlüsselwörter enthält. Daher müssen Sie für das Hotspot-Tracking selbst Statistiken sammeln und Schlüsselwörter zusammenfassen.Diesmal verwendenjieba.analyse.textrank() um Schlüsselwörter zu zählen.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Zählen Sie 5 neue Schlüsselwörter ab, speichern Sie sie in keyword_new, führen Sie dann die Schlüsselwörter mit ihnen zusammen und entfernen Sie doppelte Wörter.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Nach dem Zusammenführen drucken keyword_data Die gedruckten Ergebnisse lauten wie folgt.
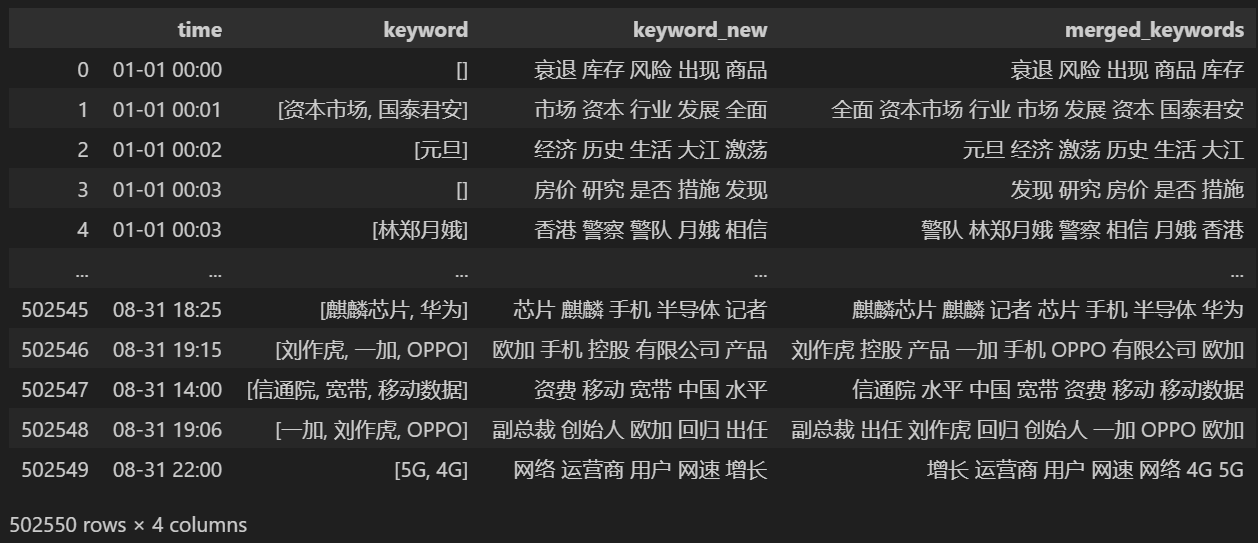
Um Hotspots aufzuspüren, zählen Sie die Worthäufigkeit aller vorkommenden Wörter und zählen Sie keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Zeichnen Sie dann basierend auf den oben genannten statistischen Daten ein tägliches Änderungsdiagramm mit wichtigen Wörtern.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Schließlich wurde ein GIF-Diagramm der Schlüsselwortänderungen in Epidemienachrichten erstellt. Die Ergebnisse sind wie folgt.
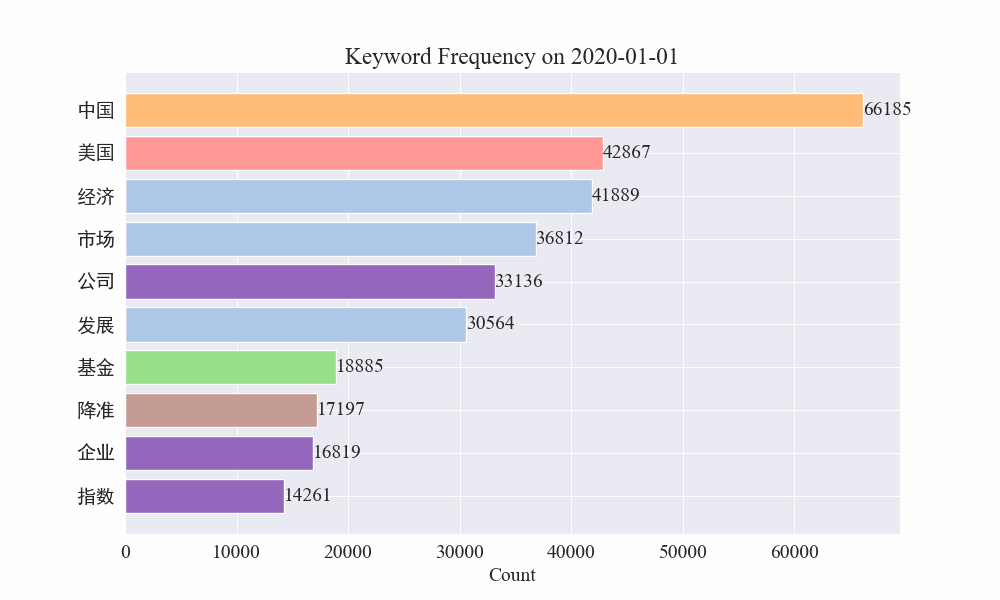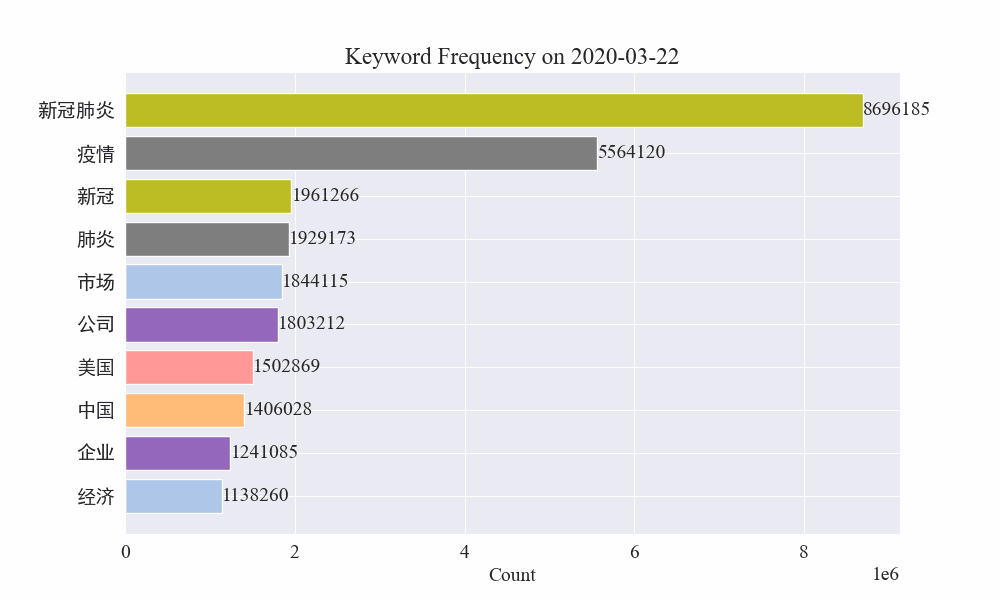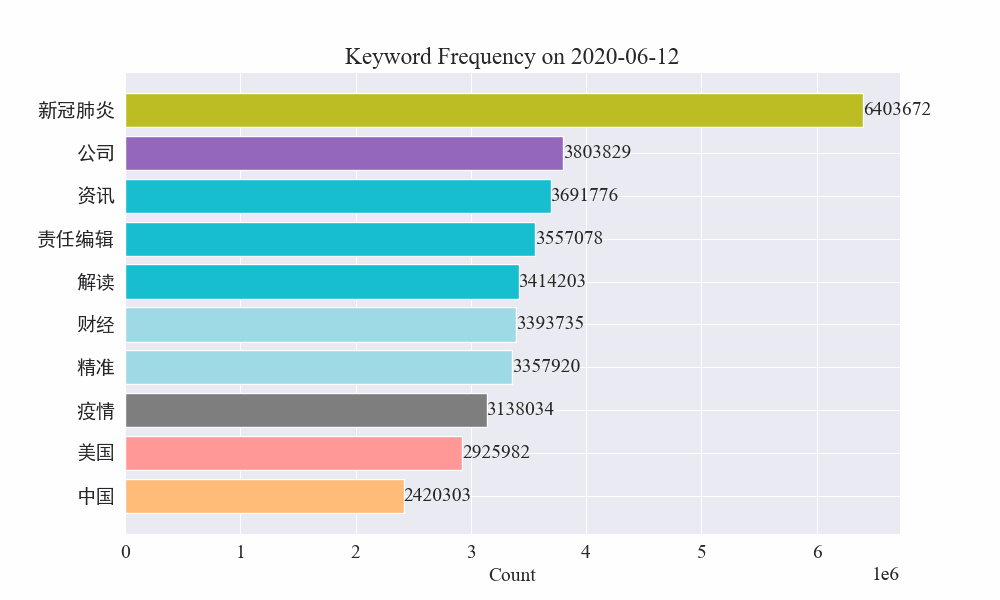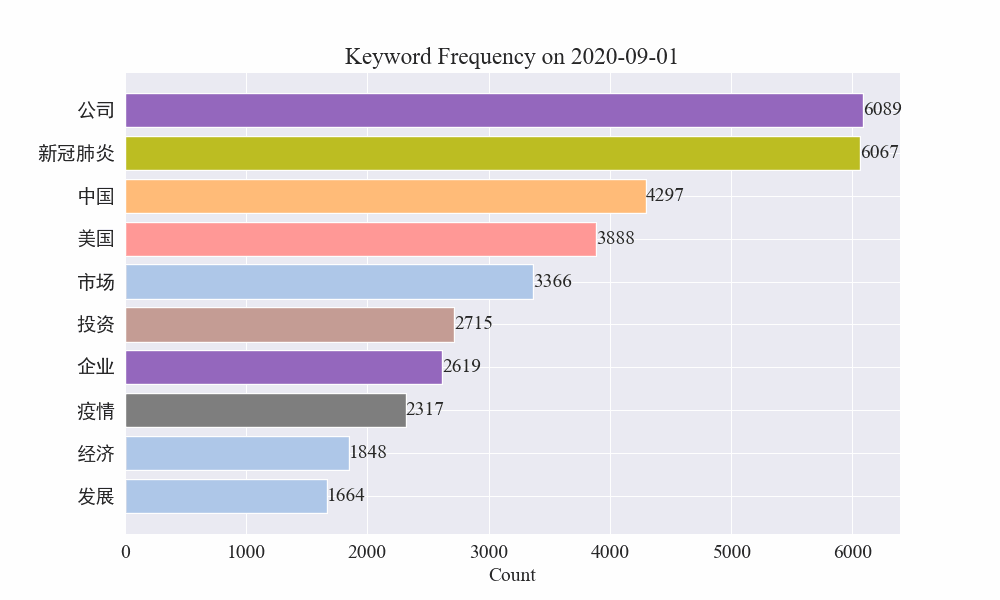
Vor dem Ausbruch blieben die Begriffe „Unternehmen“ und „Iran“ hoch im Kurs. Es ist ersichtlich, dass nach dem Ausbruch der Epidemie die Zahl der Nachrichten im Zusammenhang mit der Epidemie im Februar zu steigen begann. Danach stiegen die Begriffe „neues Coronavirus“ stark an und blieben bis Ende August an erster Stelle. Die erste Welle der Epidemie verlangsamte sich und wurde zur zweiten Welle.
In diesem Abschnitt wird zunächst eine quantitative statistische Analyse der Nachrichtenkommentare und anschließend eine Stimmungsanalyse verschiedener Kommentare durchgeführt.
Statistiken zur Anzahl der täglichen Nachrichtenkommentare
Zählen Sie den Trend der Anzahl der Nachrichtenkommentare, stellen Sie ihn mit einem Balkendiagramm dar und zeichnen Sie eine ungefähre Kurve. Der Code lautet wie folgt.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Das statistische Diagramm der Anzahl der täglichen Nachrichtenkommentare wird wie folgt erstellt.
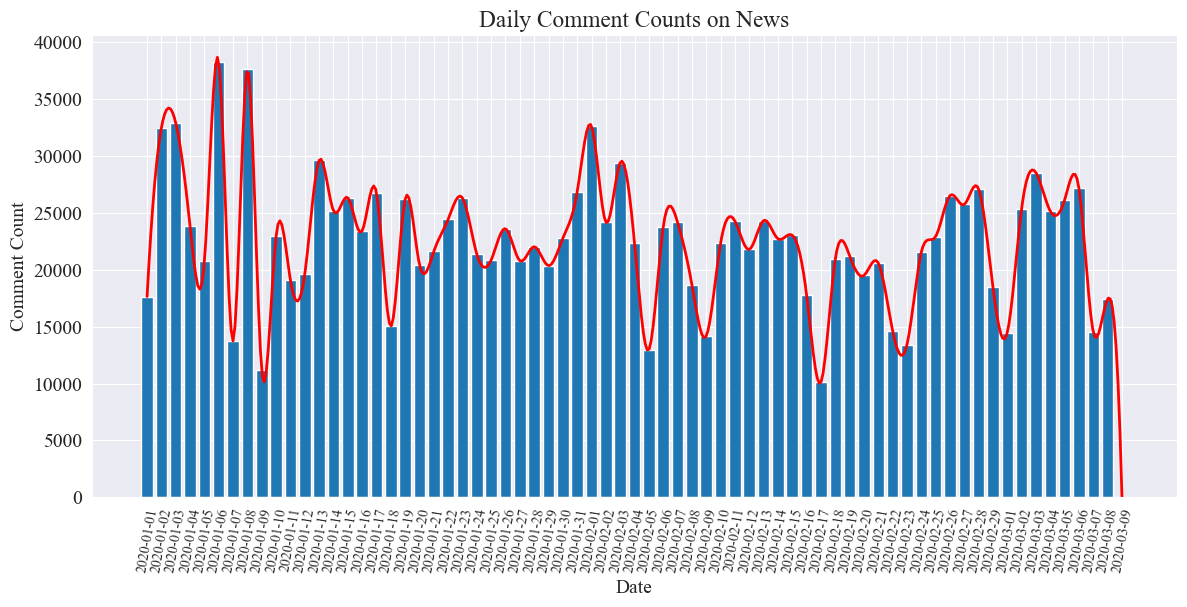
Es ist ersichtlich, dass die Anzahl der Nachrichtenkommentare während der Epidemie zwischen 10.000 und 40.000 schwankte, mit einem Durchschnitt von etwa 20.000 Kommentaren pro Tag.
Epidemie-Nachrichtenstatistik nach Region
nach Provinz comment_df['province'] Zählen Sie die Anzahl der Nachrichten in jeder Provinz und zählen Sie die Anzahl der Kommentare zu Epidemienachrichten in jeder Provinz.
Zuerst müssen Sie das bestehen comment_df['province'] Provinzinformationen extrahieren.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Anschließend wird auf Grundlage der statistischen Daten ein Kreisdiagramm erstellt, das den Anteil der Nachrichtenkommentare in jeder Provinz zeigt.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

In diesem Experiment haben wir auch verwendet pyecharts.charts vonMap Komponente, die die Verteilung der Anzahl der Kommentare auf der Karte von China nach Provinz darstellt.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
Im erhaltenen HTML ist die Verteilung der Anzahl der Kommentare zu Epidemienachrichten in den einzelnen Provinzen Chinas wie folgt.
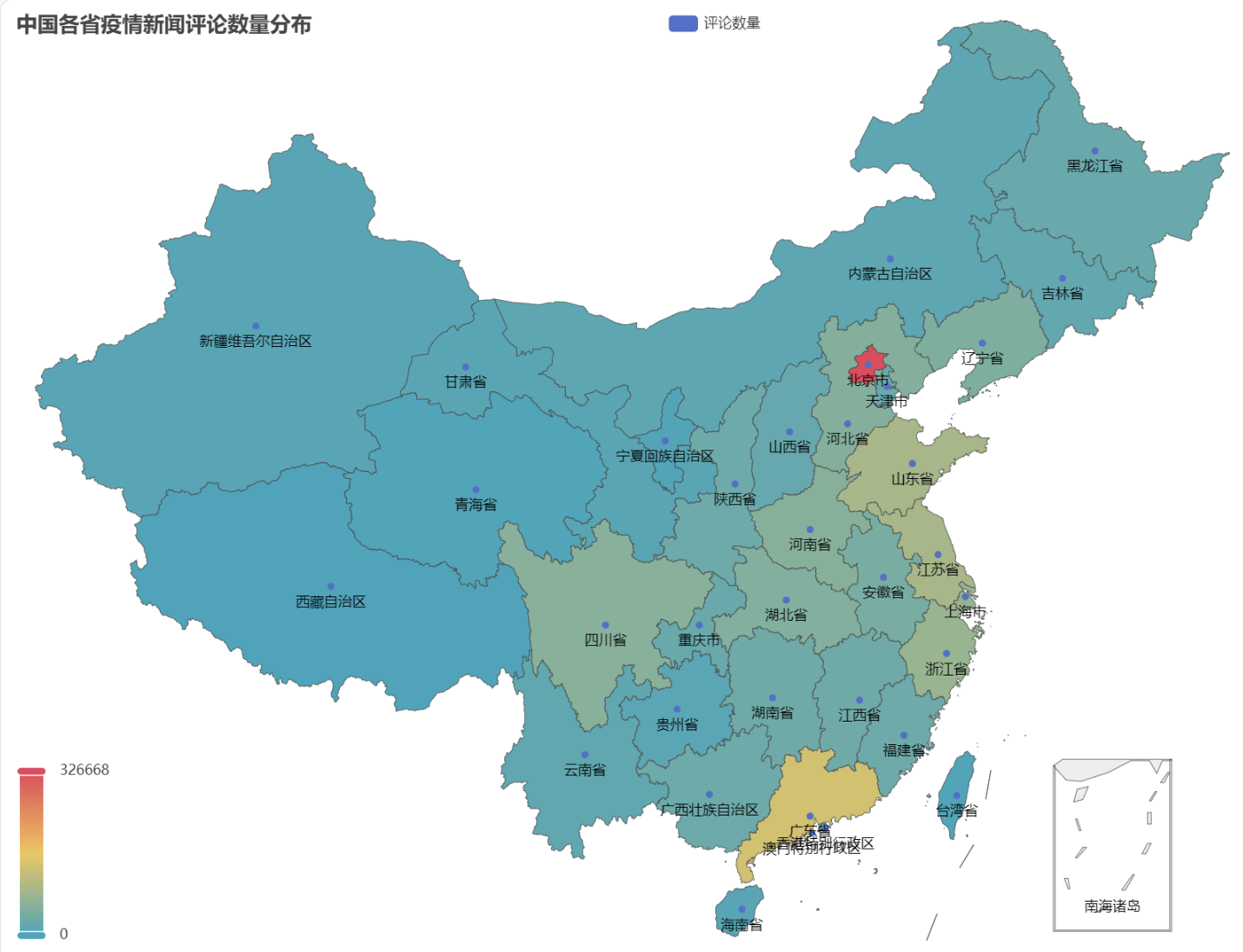
Es ist ersichtlich, dass während der Epidemie die Anzahl der Kommentare in Peking den höchsten Anteil ausmachte, gefolgt von der Provinz Guangdong, und die Anzahl der Kommentare in anderen Provinzen relativ gleichmäßig war.
EpidemieÜberprüfen Sie die Stimmungsanalyse
Dieses Experiment verwendet die NLP-Bibliothek zur Verarbeitung von chinesischem Text SnowNLP , Führen Sie eine chinesische Stimmungsanalyse durch, analysieren Sie jeden Kommentar und geben Sie den entsprechenden Kommentar absentiment Wert: Der Wert liegt zwischen 0 und 1. Je näher er an 1 liegt, desto positiver ist er. Je näher er an 0 liegt, desto negativer ist er.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
In diesem Experiment wird 0,5 als Schwellenwert verwendet. Alles, was über diesem Wert liegt, ist ein positiver Kommentar, und alles, was unter diesem Wert liegt, ist ein negativer Kommentar. Zeichnen Sie durch das Schreiben von Code ein Stimmungsanalysediagramm der täglichen Nachrichtenkommentare und zählen Sie die Anzahl der positiven Kommentare und die Anzahl der negativen Kommentare zu den täglichen Nachrichten. Die Anzahl der positiven Kommentare ist ein positiver Wert und die Anzahl der negativen Kommentare ist ein negativer Wert Wert.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
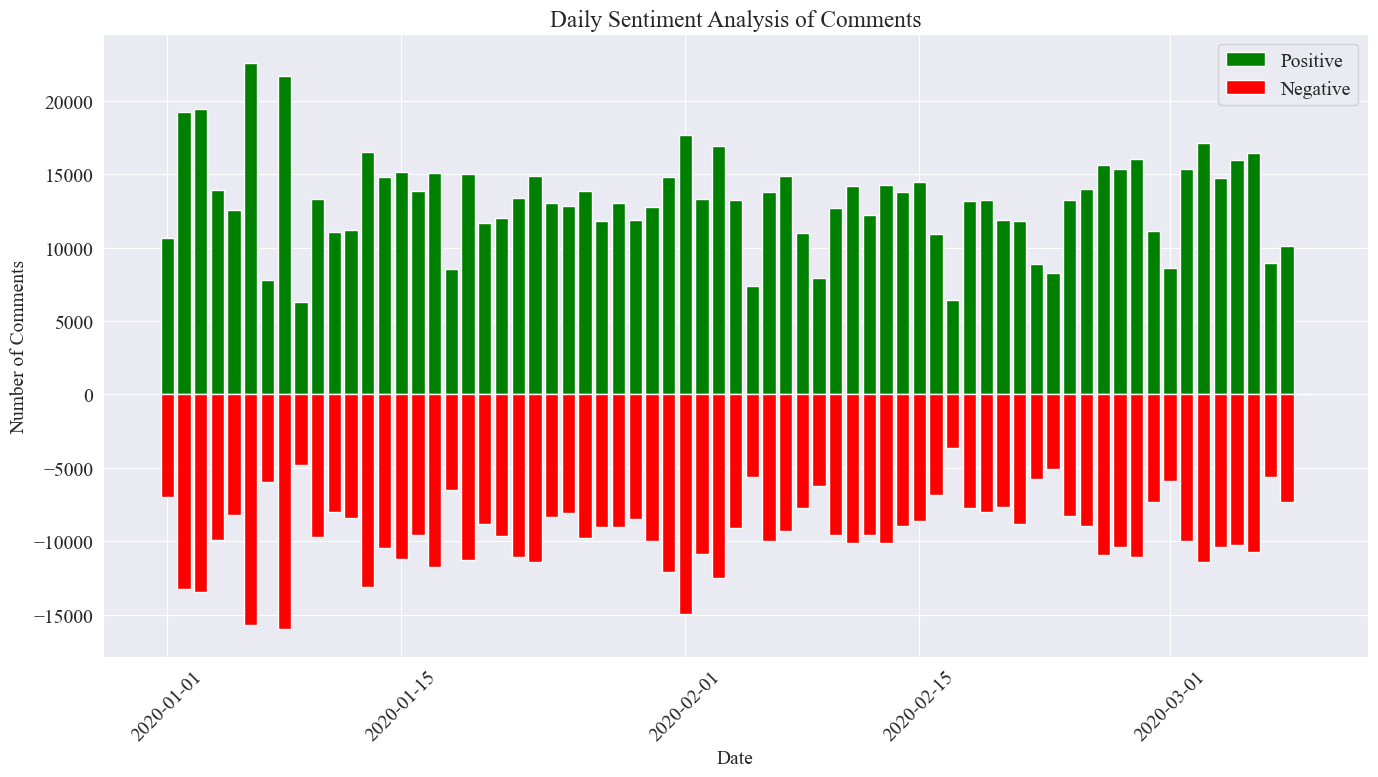
Das endgültige statistische Bild ist wie oben dargestellt. Es ist ersichtlich, dass die positiven Kommentare während der Epidemie etwas höher waren als die negativen Kommentare. Durch Zählen des Anteils positiver Kommentare wurde festgestellt, dass der Anteil positiver Kommentare 58,63 % betrug dass die Öffentlichkeit eine positivere Einstellung zur Epidemie hatte.
Stimmungsanalyse der Kommentare nach Regionen
Durch Zählen des Anteils der in jeder Provinz und Region geposteten positiven Kommentare wurde ein Diagramm des Anteils positiver Kommentare in jeder Region erstellt.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
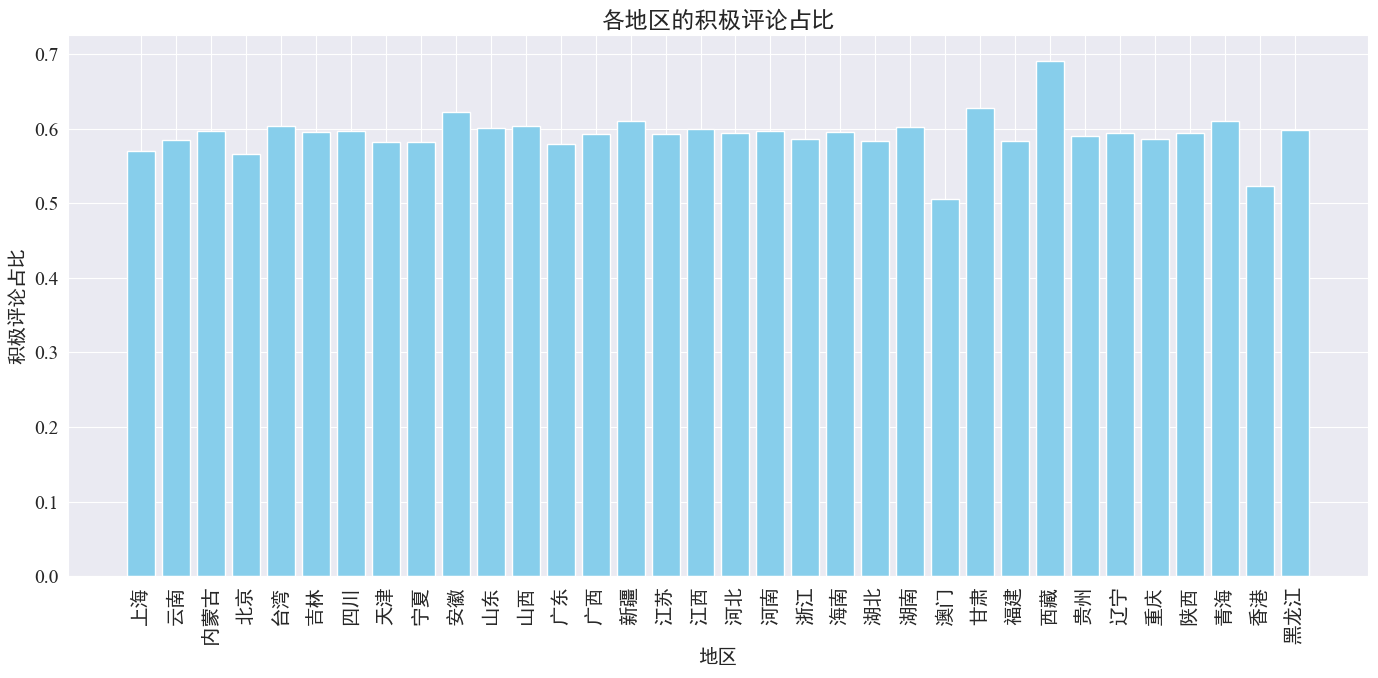
Wie aus der obigen Abbildung hervorgeht, liegt der Anteil positiver Kommentare in den meisten Provinzen bei etwa 60 %. Hongkong und Macau weisen mit etwa 50 % den niedrigsten Anteil positiver Kommentare auf, während Tibet mit nahezu 50 % den höchsten Anteil positiver Kommentare aufweist 70 %.
Aus der obigen Verteilung der Kommentare können wir ersehen, dass es sich bei den Kommentaren auf dem chinesischen Festland überwiegend um positive Kommentare handelt, während die negativen Kommentare in Hongkong und Macao erheblich zugenommen haben. Die höchste Anzahl positiver Kommentare in Tibet ist möglicherweise auf den Fehler zurückzuführen, der durch verursacht wurde die kleine Stichprobengröße in Tibet.
Nachrichtenkommentare Wortwolkendiagrammzeichnung
Die Wortwolkendiagramme aller Kommentare, positive Kommentare und negative Kommentare, wurden separat gezählt. In der Wortwolkendiagrammzeichnung wurden die positiven Kommentare als über 0,6 aufgeführt und die negativen Kommentare wurden als unter 0,4 klassifiziert. Im Folgenden sind die drei Wortwolken aufgeführt Diagramme gezeichnet.

Es ist ersichtlich, dass die Kommentare der meisten Menschen während der Epidemie relativ einfach sind, wie zum Beispiel „haha“, „gut“ usw. In den positiven Kommentaren sieht man ermutigende Worte wie „Komm schon, China“, „Komm schon, Wuhan“. usw., während in den negativen Kommentaren Kritikpunkte wie „Haha“ und „Es ist schwierig, ein Land reich zu machen“ zu finden sind.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen
