minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
A epidemia de COVID-19 afeta o coração de cada um de nós. Neste caso, tentaremos usar métodos de computação social para analisar notícias e rumores relacionados à epidemia para ajudar.Informação sobre epidemia Pesquisar. Esta tarefa é aberta. Fornecemos dados sociais durante a epidemia e incentivamos os alunos a analisar tendências sociais a partir de notícias, rumores e documentos legais. (Dica: use os métodos aprendidos em aula, como análise de sentimentos, extração de informações, compreensão de leitura, etc. para analisar dados)
https://covid19.thunlp.org/ fornece informações de dados sociais relacionadas à epidemia do novo coronavírus, incluindo rumores relacionados à epidemia CSDC-Rumor, notícias chinesas relacionadas à epidemia CSDC-News e documentos legais relacionados à epidemia CSDC-Legal.
Esta parte do conjunto de dados coletado:
(1) A partir de 22 de janeiro de 2020Informações falsas do WeiboOs dados incluem o conteúdo das postagens do Weibo que são consideradas informações falsas, editores, denunciantes, tempo de julgamento, resultados e outras informações. Em 1º de março de 2020, havia um total de 324 textos originais do Weibo, 31.284 encaminhamentos e 7.912 comentários. ., usado para ajudar os pesquisadores a analisar e estudar a disseminação de informações falsas durante a epidemia;
(2) Plataforma de verificação de boatos da Tencent e dados de informações falsas de Dingxiangyuan desde 18 de janeiro de 2020, incluindo o conteúdo do boato considerado correto ou falso, a hora e a base usada para julgar se é um boato, etc. Em 1º de março de 2020, havia 507 dados de boatos, incluindo 124 dados factuais. A distribuição dos dados é: casos negativos: 420, casos positivos: 33 e incertos: 54.
Esta parte do conjunto de dados coleta dados de notícias a partir de 1º de janeiro de 2020, incluindo título, conteúdo, palavras-chave e outras informações das notícias. Em 16 de março de 2020, foram coletados um total de 148.960 notícias e 1.653.086 comentários correspondentes. Usado para ajudar os pesquisadores a analisar e estudar dados de notícias durante a epidemia.
Esses dados são de CAIL Um total de 1.203 partes históricas relacionadas à epidemia foram selecionadas dos dados anonimizados de documentos legais coletados. Cada dado inclui o título do documento, o número do caso e o texto completo do documento, que pode ser usado pelos pesquisadores para conduzir pesquisas. sobre questões jurídicas relevantes durante a epidemia.
Esta tarefa é uma tarefa aberta, começaremos a partir de
Avaliar trabalhos em outros aspectos.
[1] Credibilidade da informação no twitter. em Proceedings of WWW, 2011.
[2] Detecção de rumores de microblogs com redes neurais recorrentes. em Proceedings of IJCAI, 2016.
[3] Uma abordagem convolucional para identificação de desinformação. em Proceedings of IJCAI, 2017.
[4] A disseminação de notícias verdadeiras e falsas online. Science, 2018.
[5] Informações falsas na web e nas redes sociais: uma pesquisa. arXiv preprint, 2018.
[6] Caracterização das Normas Afetivas para Palavras Inglesas por Categorias Emocionais Discretas. Behavior Research Methods, 2007.
Este experimento fornece o conjunto de dados de rumores relacionados à epidemia CSDC-Rumor. Ao analisar o conteúdo do conjunto de dados, optamos primeiro por realizar uma análise estatística quantitativa no conjunto de dados, depois usar o agrupamento para implementar a análise semântica dos rumores e, finalmente, projetar um. sistema de detecção de boatos.
Formato de dados
Este experimento fornece o conjunto de dados de boatos relacionados à epidemia CSDC-Rumor, que coleta dados de informações falsas do Weibo e dados de refutação de boatos. O conjunto de dados contém o seguinte.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Informações falsas do Weiborespectivamente por rumor_weibo erumor_forward_comment dois com o mesmo nomejson descrito no arquivo.rumor_weibo meiojson Os campos específicos são os seguintes:
rumorCode: O código exclusivo do boato, por meio do qual a página de reportagem do boato pode ser acessada diretamente.title: O conteúdo do título do boato relatado.informerName: Nome Weibo do repórter.informerUrl: Link do Weibo do repórter.rumormongerName: O nome Weibo da pessoa que publicou o boato.rumormongerUr: Link do Weibo da pessoa que postou o boato.rumorText: Conteúdo de boato.visitTimes: O número de vezes que esse boato foi visitado.result: Os resultados desta revisão de boatos.publishTime: A hora em que o boato foi relatado.related_url: Links para evidências, regulamentos, etc. relacionados a este boato.rumor_forward_comment meiojson Os campos específicos são os seguintes:
uid: publique o ID do usuário.text: Comente ou encaminhe o postscript.date: tempo de lançamento.comment_or_forward: binário, também comment, qualquer forward, indicando se a mensagem é um comentário ou um postscript encaminhado.Informações falsas de Tencent e Lilac GardenO formato do conteúdo é:
date: tempoexplain: Tipo de boatotag:tag de rumoresabstract: Conteúdo usado para verificar rumoresrumor: BoatoPré-processamento de dados
passar json.load() Extraia dados de rumores do Weibo separadamenteweibo_data Comentário encaminhando dados com rumoresforward_comment_data e, em seguida, converta-o para o formato DataFrame. Os dois arquivos com o mesmo nome, artigo do Weibo e encaminhamento de comentários do Weibo, correspondem entre si. Ao processar os dados na pasta rumor_forward_comment, adicione rumorCode para correspondência subsequente.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Esta seção usa análise estatística quantitativa para obter uma compreensão específica da distribuição dos dados do boato epidêmico do Weibo.
Estatísticas sobre o número de vezes que rumores foram visitados
Estatisticas weibo_df['visitTimes'] Distribuição dos tempos de acesso e desenho do histograma correspondente. Os resultados são os seguintes.
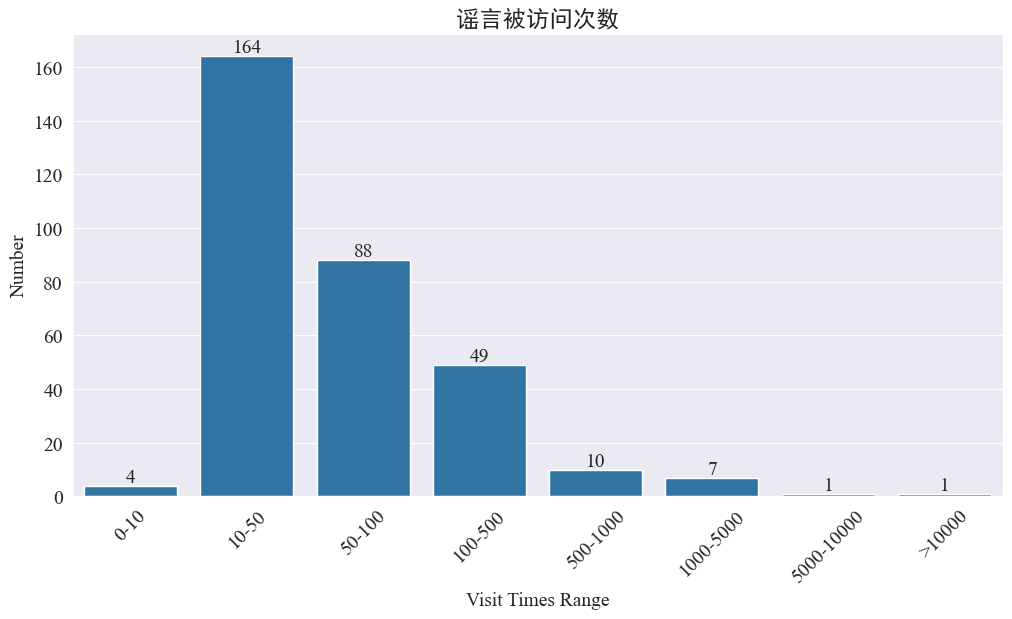
De acordo com o número de visitas ao Weibo, a maioria dos rumores epidêmicos foram visitados menos de 500 vezes no Weibo, com 10-50 representando a maior proporção. No entanto, também existem rumores no Weibo que foram acessados mais de 5.000 vezes, que causaram sério impacto e são considerados “graves” por lei.
Estatísticas sobre a ocorrência de boatos e denunciantes
por estatísticas weibo_df['rumormongerName'] eweibo_df['informerName'] O número de rumores publicados por cada editor de rumores e o número de rumores relatados por cada repórter são obtidos como segue.
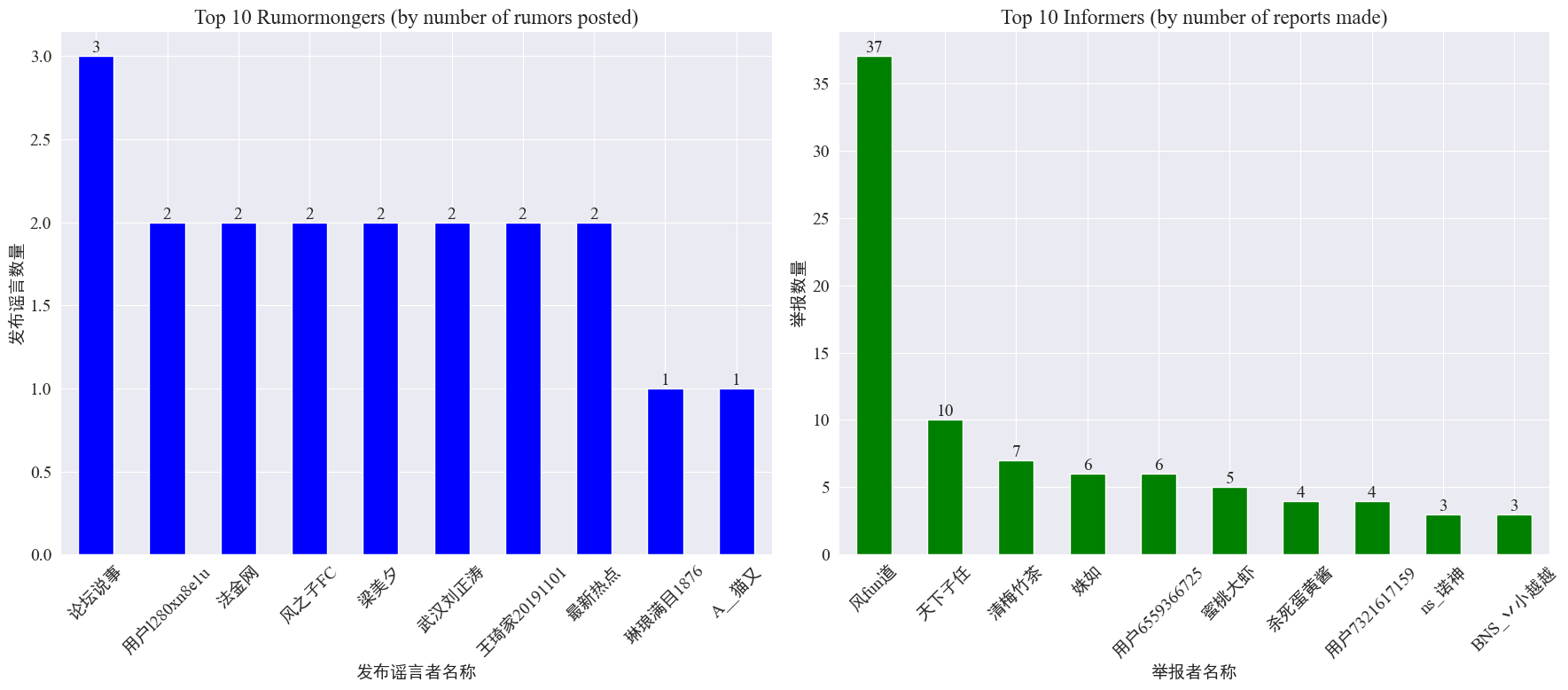
Pode-se observar que o número de boatos postados pelos criadores de boatos não está concentrado em poucas pessoas, mas é relativamente uniforme. A conta que postou mais boatos postou três postagens de boatos no Weibo. Cada um dos 10 principais denunciantes relatou pelo menos 3 artigos de boatos. Entre eles, o número de boatos relatados por denunciantes no Weibo foi significativamente maior do que o de outros usuários, chegando a 37 artigos.
Com base nos dados acima, o público pode se concentrar em relatar contas com grande número de boatos para facilitar a detecção de boatos.
Estatísticas de distribuição de comentários de encaminhamento de boatos
Contando a distribuição do volume de encaminhamento de boatos e do volume de comentários, obtém-se a seguinte imagem de distribuição.

Pode-se observar que o número de comentários e repostagens na maioria dos boatos do Weibo está dentro de 10 vezes, com o número máximo de comentários não ultrapassando 500, e o número máximo de repostagens chegando a mais de 10.000. De acordo com a Lei de Gestão da Internet, se um boato for repassado mais de 500 vezes, é considerado uma situação “grave”.
Análise de cluster de texto de boato
Esta parte realiza o pré-processamento de dados em textos de rumores do Weibo e realiza análise de cluster após segmentação de palavras para ver onde os rumores do Weibo estão concentrados.
Pré-processamento de dados
Primeiro, limpe o texto dos dados do boato, remova os valores padrão e <> O conteúdo do link incluído.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Em seguida, carregue palavras irrelevantes em chinês e as palavras irrelevantes usarão cn_palavras-chave ,usarjieba Implemente o processamento de segmentação de palavras de dados e execute a vetorização de texto.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Determine o melhor cluster
Usando o método do cotovelo, os melhores clusters são determinados.
O Método Elbow é um método usado para determinar o número ideal de clusters na análise de cluster. Baseia-se na relação entre a Soma dos Erros Quadrados (SSE) e o número de clusters. SSE é a soma das distâncias euclidianas quadradas de todos os pontos de dados no cluster até o centro do cluster ao qual pertence. Reflete o efeito do agrupamento: quanto menor o SSE, melhor será o efeito do agrupamento.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
O método do cotovelo determina o número ideal de clusters procurando o "cotovelo", ou seja, procurando um ponto na curva após o qual a taxa de diminuição do SSE diminui significativamente. Esse ponto é como o cotovelo de um braço, daí o cotovelo. nome " Método do cotovelo”. Este ponto é geralmente considerado o número ideal de clusters.
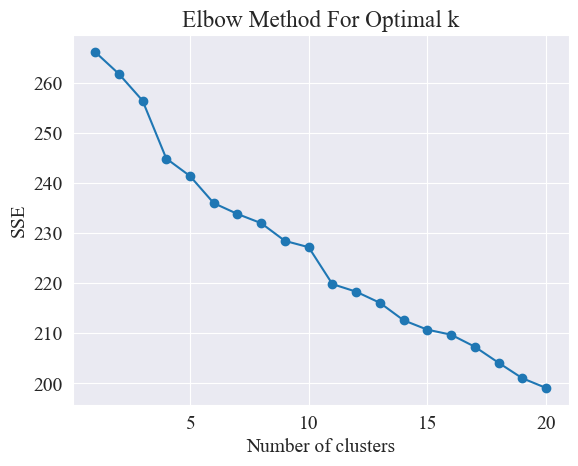
A partir da figura acima, é determinado que o valor de agrupamento do cotovelo é 11 e o gráfico de dispersão correspondente é desenhado.
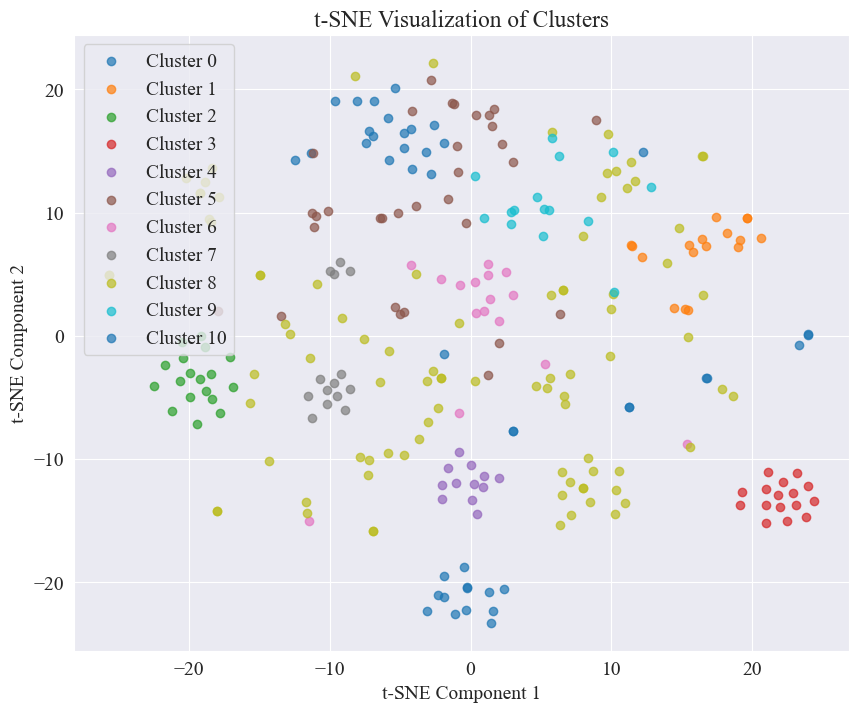
Pode-se observar que a maioria das postagens de boatos do Weibo estão bem agrupadas, nº 3 e nº 4, algumas são amplamente distribuídas e não bem agrupadas, como nº 5 e nº 8;
Agrupamento de resultados
Para mostrar claramente quais rumores estão agrupados em cada categoria, um gráfico de nuvens é desenhado para cada categoria. Os resultados são os seguintes.

Imprima alguns rumores bem agrupados sobre o conteúdo do Weibo e os resultados são os seguintes.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Análise de cluster dos resultados da revisão de boatos
Agrupar o conteúdo do texto do boato pode não ser tão bom para a análise do conteúdo do boato, por isso optamos por agrupar os resultados da revisão do boato.
Determine o melhor cluster
Usando o gráfico de cotovelo, determine o melhor agrupamento.
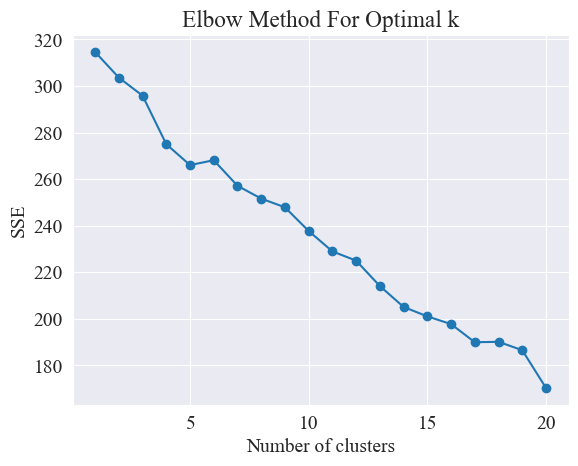
A partir do diagrama de cotovelo acima, dois cotovelos podem ser determinados, um é quando o agrupamento é 5 e o outro é quando o agrupamento é 20. Eu escolho 20 para agrupamento.
O gráfico de dispersão obtido agrupando 20 categorias é o seguinte.
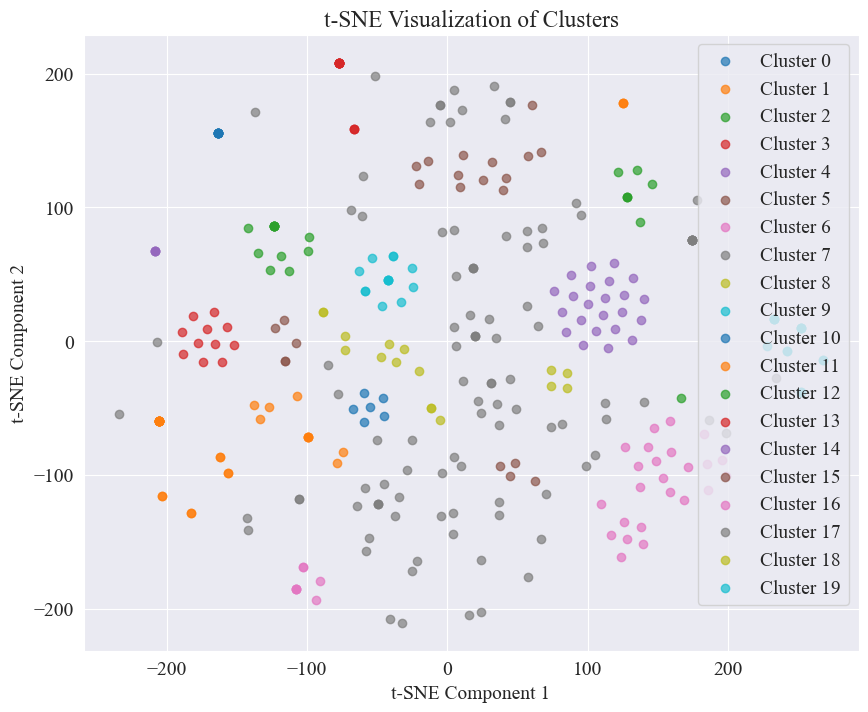
Percebe-se que a maioria está bem agrupada, mas as 7ª e 17ª categorias não estão bem agrupadas.
Agrupamento de resultados
Para mostrar claramente quais resultados da análise de boatos estão agrupados em cada categoria, um gráfico de nuvens é desenhado para cada categoria. Os resultados são os seguintes.

Imprima alguns resultados de análises de boatos bem agrupados. Os resultados são os seguintes.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Para esta detecção de boatos, optamos por usar conjuntos de dados que foram refutados. fact.json Compare a semelhança entre rumores refutados e rumores reais e selecione o artigo refutado com a maior semelhança com o boato do Weibo como base para a detecção de boatos.
Carregar dados de boatos do Weibo e conjuntos de dados de refutação de boatos
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Use modelos de linguagem pré-treinados para codificar rumores do Weibo e títulos que refutam rumores em vetores incorporados
usado neste experimento bert-base-chinese Como modelo pré-treinado, execute o treinamento do modelo. O modelo SimCSE é usado para melhorar a representação e medição de similaridade da semântica de frases por meio de aprendizagem contrastiva.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Calcular similaridade
Para calcular a similaridade, a incorporação de sentença e a similaridade de entidade nomeada do modelo SimCSE são usadas para calcular a similaridade abrangente.
extract_entitiesA função extrai entidades nomeadas do texto usando o modelo NER.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityA função calcula a semelhança da entidade nomeada entre dois textos.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityA função combina a incorporação de sentença e a similaridade de entidade nomeada do modelo SimCSE para calcular a similaridade abrangente.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Implementar detecção de boatos
Ao comparar semelhanças, um mecanismo de detecção de rumores é implementado.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
A saída é a seguinte:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Encontrou com sucesso a base para refutar os rumores e emitiu uma sentença para refutá-los.
Formato de dados
Esta experiência fornece o conjunto de dados de notícias relacionadas com a epidemia CSDC-News, que recolhe notícias e comentários no primeiro semestre de 2020. O conjunto de dados contém o seguinte.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
A pasta de dados está dividida em três partes:data,comment。
data A pasta contém vários arquivos, cada arquivo corresponde a dados de uma determinada data, no formatojson . O conteúdo desta parte corresponde aos dados textuais da notícia (serão atualizados gradativamente com a data), e os campos incluem:
time: Horário de divulgação da notícia.title:O título da notícia.url: O link do endereço original da notícia.meta: A informação textual da notícia, que inclui os seguintes campos: content: O conteúdo do texto da notícia.description: Uma breve descrição da notícia.title:O título da notícia.keyword: Palavras-chave de notícias.type: Tipo de notícia.comment A pasta contém vários arquivos, cada arquivo corresponde a dados de uma determinada data, no formatojson . Esta parte do conteúdo corresponde aos dados dos comentários das notícias (pode haver um atraso de cerca de uma semana entre os dados dos comentários e os dados do texto das notícias).
time: Horário de divulgação da notícia e data Corresponde aos dados da pasta.title: O título da notícia, com data Corresponde aos dados da pasta.url: O link do endereço original da notícia, e data Corresponde aos dados da pasta.comment: Informações de comentários de notícias Este campo é uma matriz. Cada elemento da matriz contém as seguintes informações: area: Área do revisor.content:comentários.nickname: apelido do revisor.reply_to: o objeto de resposta do comentarista. Se não houver, significa que não é uma resposta.time: Hora de comentar.Pré-processamento de dados
Dados sobre artigos de notícias data Durante o pré-processamento dos dados, é necessáriometa O conteúdo é liberado e armazenado no formato DataFrame.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
Nos dados de revisão comment Durante o pré-processamento dos dados, é necessáriocomment O conteúdo é liberado e armazenado no formato DataFrame.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Carregar conjunto de dados
Carregue o conjunto de dados de acordo com a função de pré-processamento de dados acima.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
O resultado da impressão mostra que o comprimento dos dados de notícias: 502550 e o comprimento dos dados de comentários: 1534616.
Estatísticas de distribuição de tempo de notícias
Conte separadamente news_df O número de artigos de notícias mensais e o número de artigos de notícias por hora são representados por gráficos de barras e gráficos de linhas.
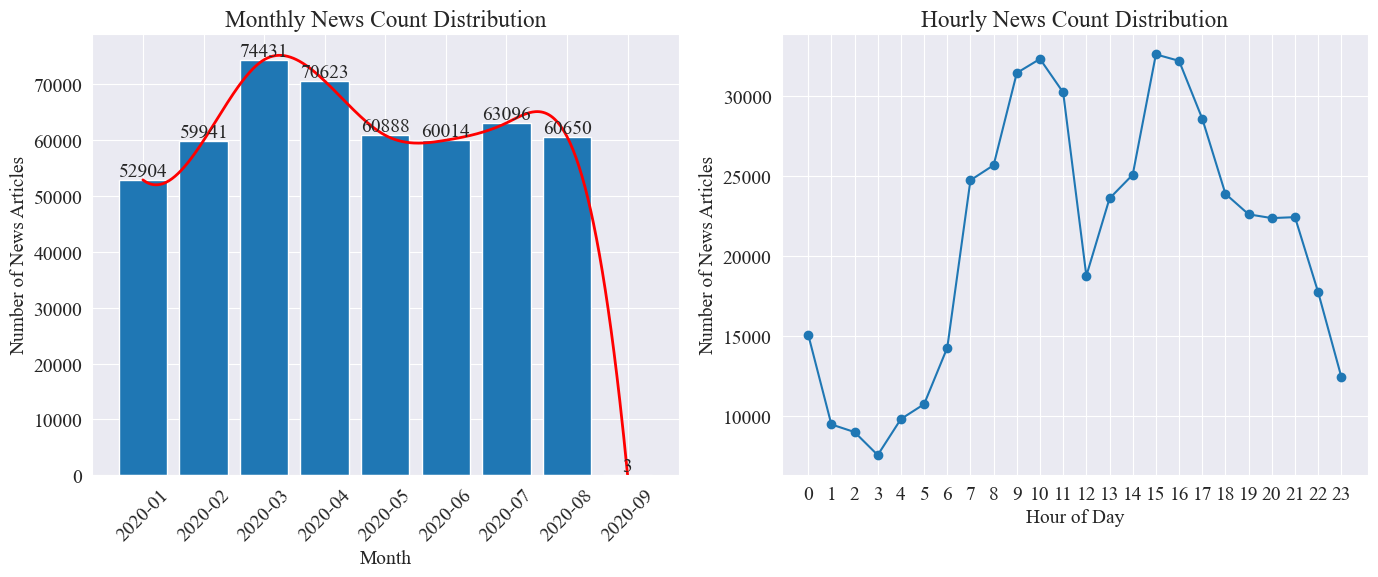
Como pode ser visto na figura acima, com o início da epidemia, o número de notícias aumentou mês a mês, atingindo um pico em março com 74.000 artigos noticiosos, e depois diminuiu gradualmente e estabilizou para 60.000 artigos por mês, dos quais o os dados de setembro eram 3 às 0:00 artigos, não podem ser incluídos nas estatísticas.
De acordo com a distribuição da quantidade de notícias por hora, verifica-se que 10h e 15h de cada dia são os horários de pico de divulgação de notícias, com mais de 30 mil artigos publicados cada. 12 horas é o intervalo para o almoço, e o número de comunicados à imprensa atinge altos e baixos. O número mínimo de comunicados de imprensa é das 0h às 5h todos os dias, sendo as 3h o ponto mínimo.
Rastreamento de pontos quentes de notícias
Este experimento pretende utilizar o método de extração de palavras-chave de notícias para rastrear os hot spots de notícias nesses oito meses. Contando a distribuição das palavras-chave existentes e traçando um histograma, os resultados são os seguintes.
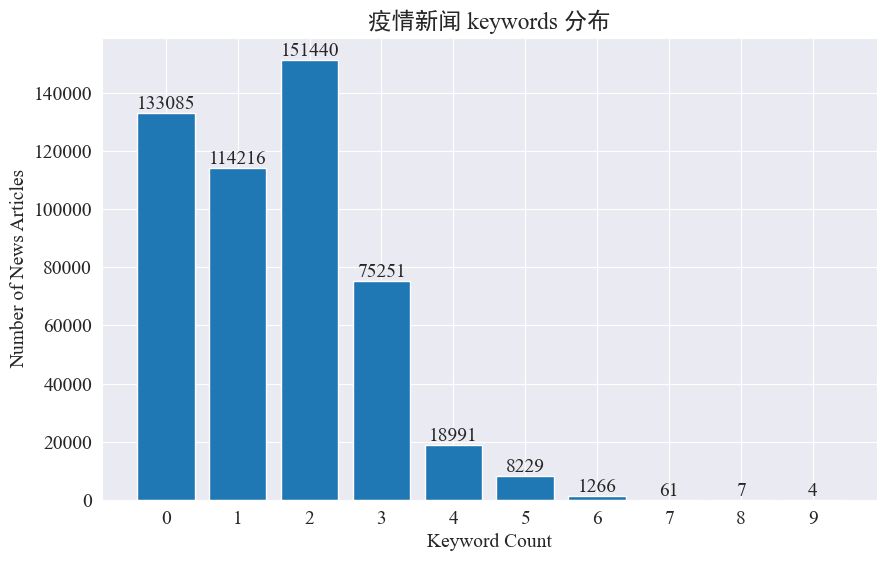
Pode-se observar que a maioria dos artigos de notícias possui menos de 3 palavras-chave, e uma grande proporção dos artigos ainda não possui palavras-chave. Portanto, você mesmo precisa coletar estatísticas e resumir palavras-chave para rastreamento de pontos de acesso.Desta vez usejieba.analyse.textrank() para contar palavras-chave.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Conte 5 novas palavras-chave, salve-as em keywords_new, depois mescle as palavras-chave com elas e remova as palavras duplicadas.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Imprimir após mesclar keyword_data , os resultados impressos são os seguintes.
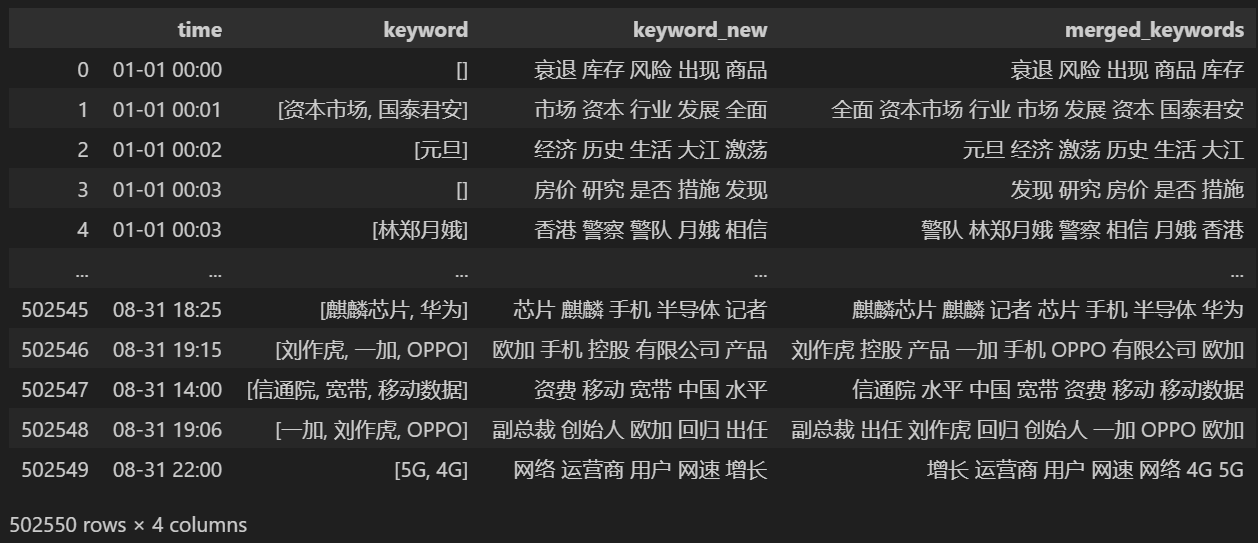
Para rastrear pontos quentes, conte a frequência de palavras de todas as palavras que aparecem e conte keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Em seguida, com base nos dados estatísticos acima, desenhe um gráfico de mudança diária de palavras importantes.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Por fim, foi obtido um gráfico gif de mudanças nas palavras-chave nas notícias epidêmicas. Os resultados são os seguintes.
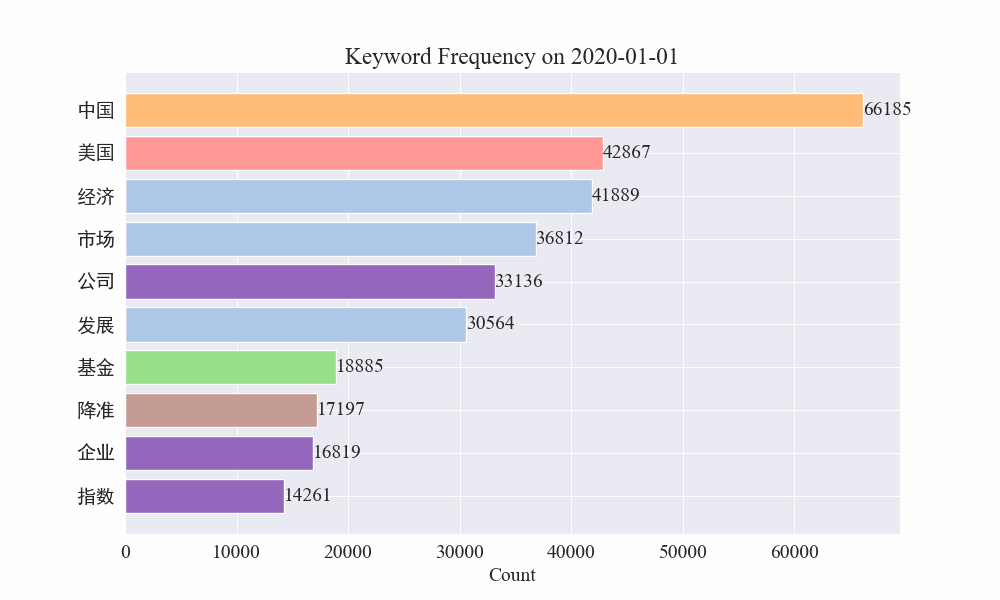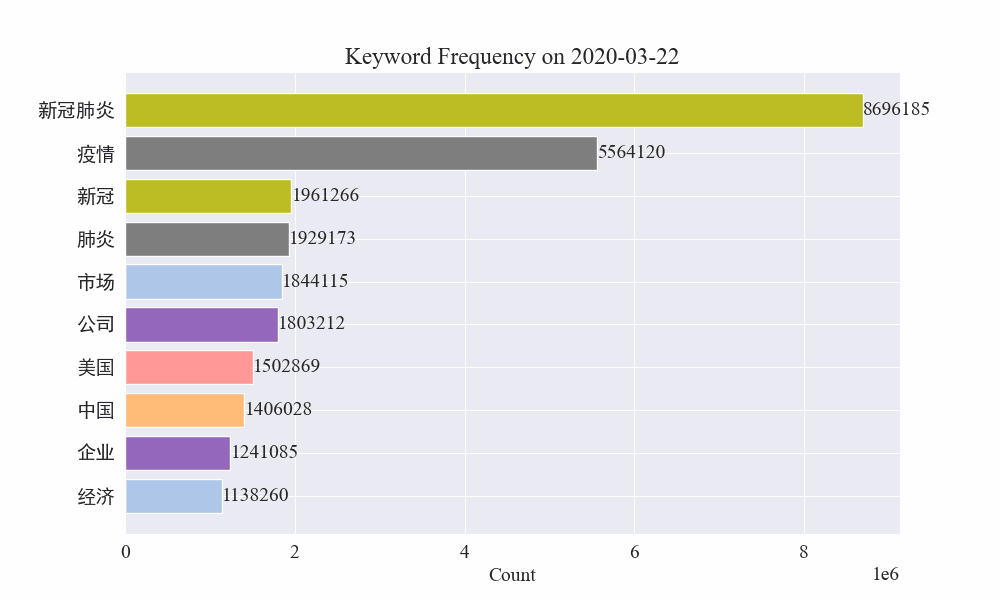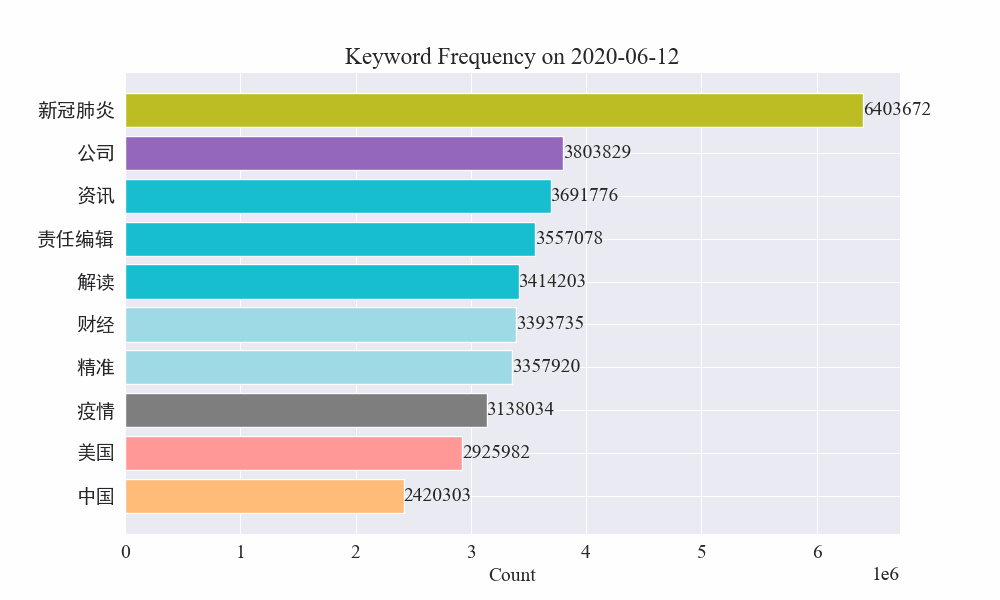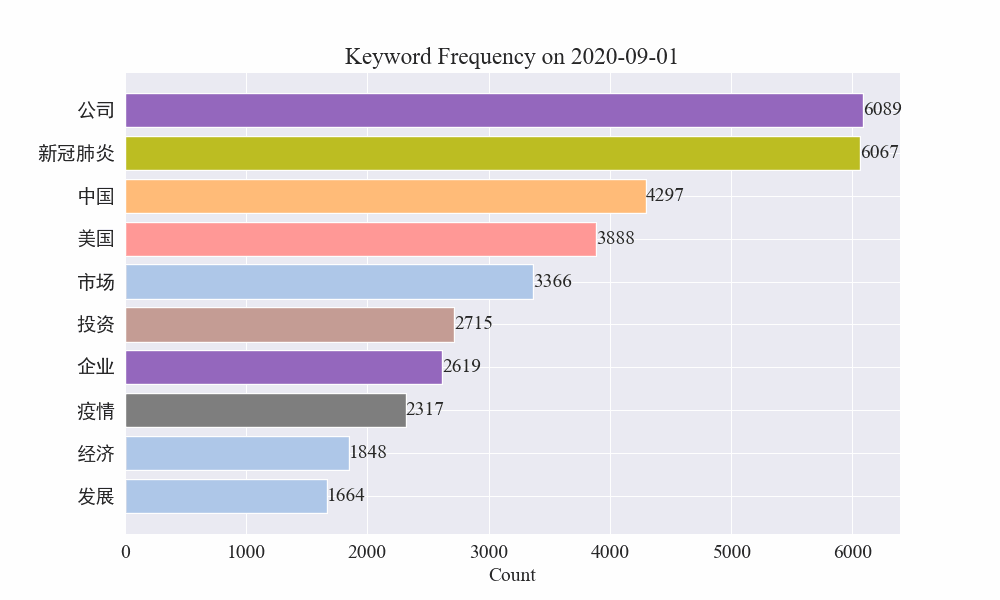
Antes do surto, os termos “empresa” e “Irã” permaneciam elevados. Percebe-se que após o início da epidemia, o número de notícias relacionadas à epidemia começou a aumentar em fevereiro. Depois disso, os termos “novo coronavírus” aumentaram e continuaram em primeiro lugar. a primeira onda da epidemia desacelerou e passou a ocupar o segundo lugar.
Esta seção primeiro conduz análises estatísticas quantitativas em comentários de notícias e, em seguida, conduz análises de sentimento em diferentes comentários.
Estatísticas de contagem de comentários de notícias diárias
Conte a tendência do número de comentários de notícias, use um gráfico de barras para representá-la e desenhe uma curva aproximada.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
O gráfico estatístico do número de comentários diários de notícias é desenhado da seguinte forma.
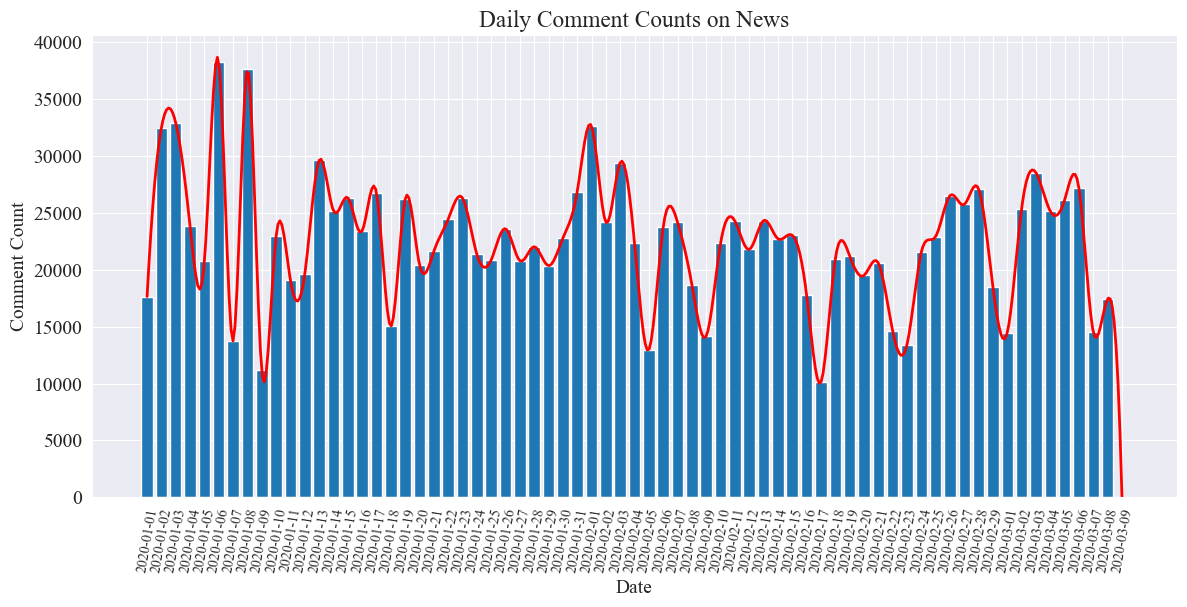
Percebe-se que o número de comentários noticiosos durante a epidemia oscilou entre 10.000 e 40.000, com uma média de cerca de 20.000 comentários por dia.
Estatísticas de notícias sobre epidemias por região
por província comment_df['province'] Contar o número de notícias em cada província e contar o número de comentários sobre notícias epidêmicas em cada província.
Primeiro você precisa passar pelo comment_df['province'] Extraia informações da província.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Depois, com base nos dados estatísticos, é desenhado um gráfico circular mostrando a proporção de comentários de notícias em cada província.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

Neste experimento também usamos pyecharts.charts deMap Componente, que traça a distribuição do número de comentários no mapa da China por província.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
No HTML obtido, a distribuição do número de comentários sobre notícias epidêmicas em cada província da China é a seguinte.
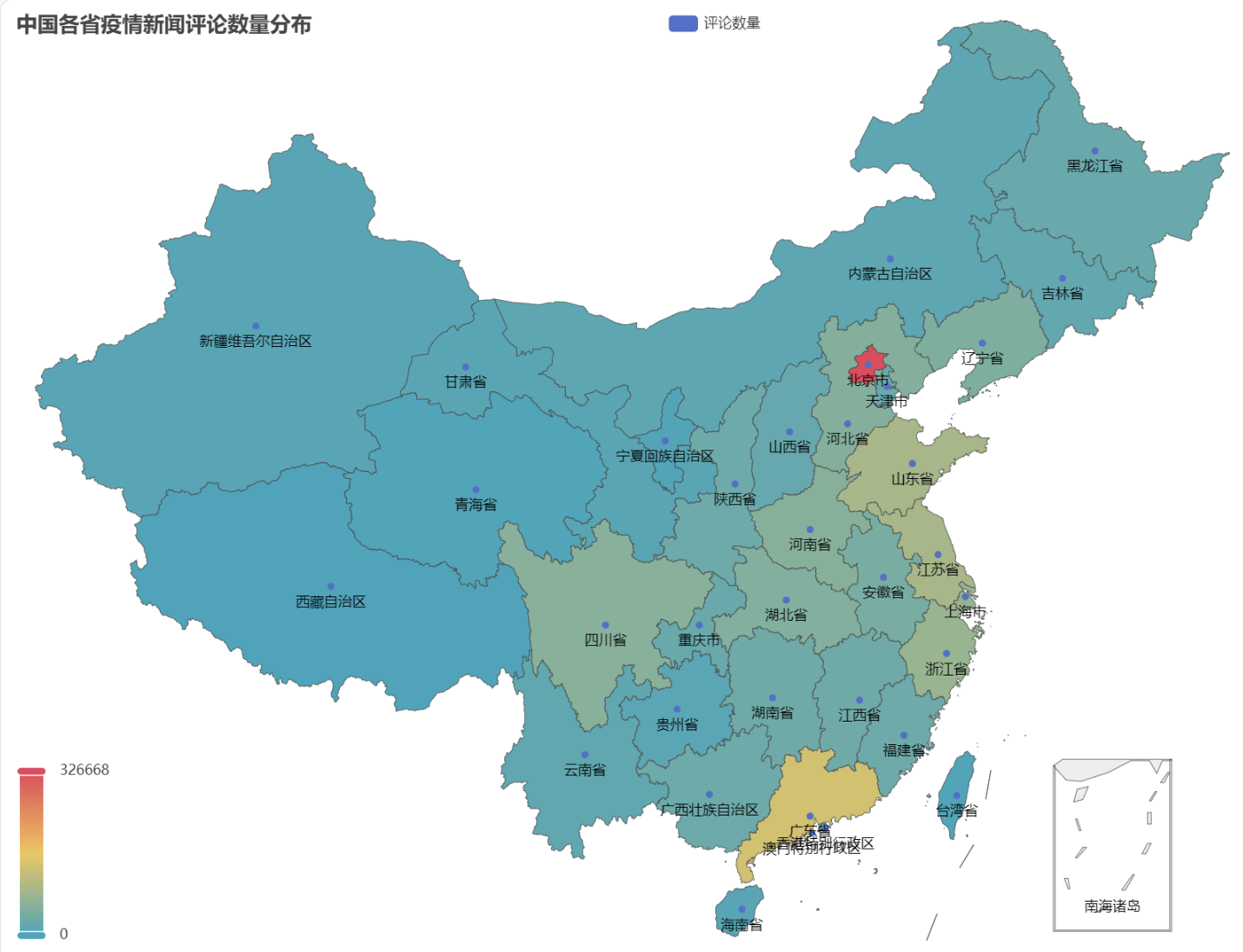
Pode-se observar que durante a epidemia, o número de comentários em Pequim representou a maior proporção, seguido pela província de Guangdong, e o número de comentários em outras províncias foi relativamente uniforme.
epidemiaRevise a análise de sentimento
Este experimento usa a biblioteca PNL para processar texto chinês SnowNLP , implemente a análise de sentimento chinês, analise cada comentário e forneça o correspondentesentiment Valor, o valor está entre 0 e 1, quanto mais próximo de 1, mais positivo é, e quanto mais próximo de 0, mais negativo é.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
Neste experimento, 0,5 é usado como limite. Qualquer valor maior que esse valor é um comentário positivo e qualquer valor menor que esse valor é um comentário negativo. Ao escrever o código, desenhe um gráfico de análise de sentimento dos comentários de notícias diárias e conte o número de comentários positivos e o número de comentários negativos nas notícias diárias. O número de comentários positivos é um valor positivo e o número de comentários negativos é um valor negativo. valor.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
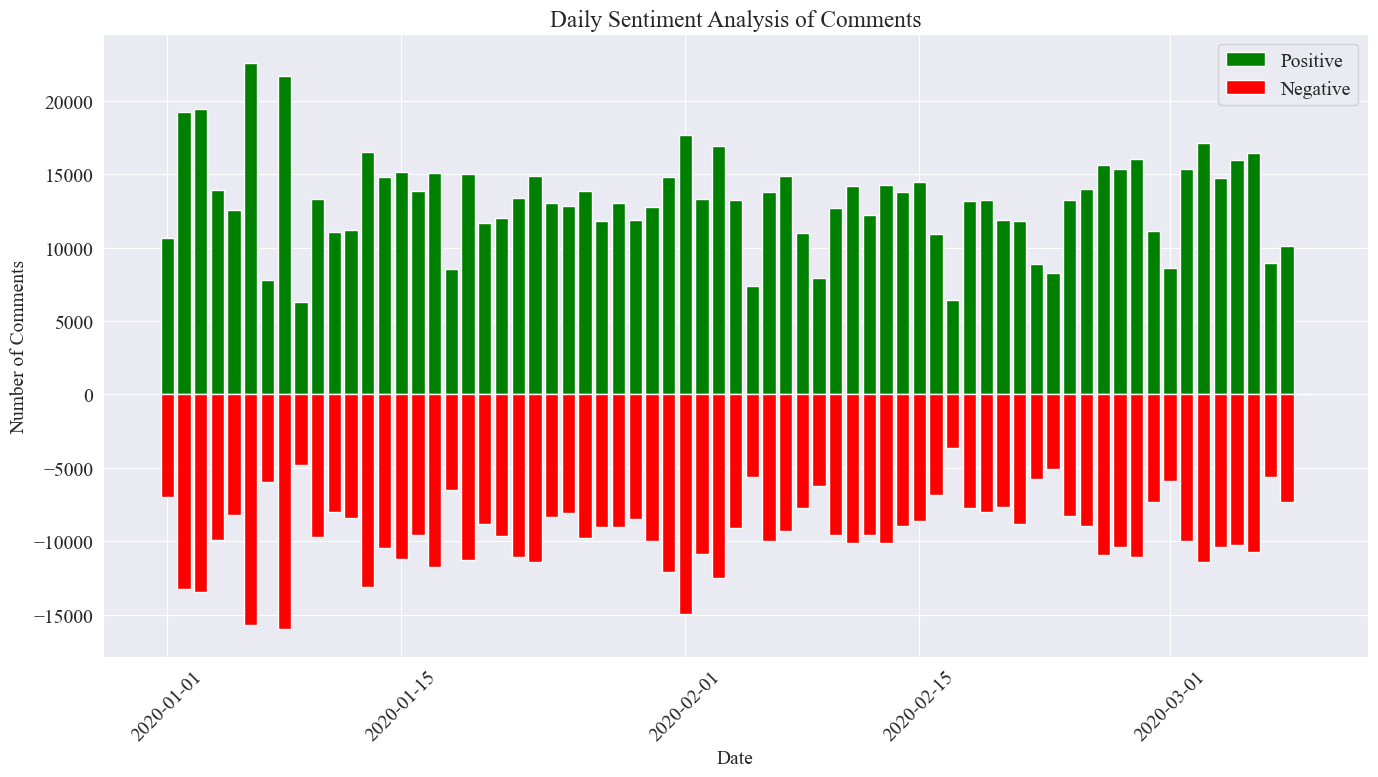
A imagem estatística final é a mostrada acima. Verifica-se que os comentários positivos durante a epidemia foram ligeiramente superiores aos comentários negativos. Ao contar a proporção de comentários positivos, constatou-se que a proporção de comentários positivos foi de 58,63%. que o público tinha uma atitude mais positiva em relação à epidemia.
Análise de sentimento de comentários por região
Ao contar a proporção de comentários positivos postados em cada província e região, foi obtido um gráfico da proporção de comentários positivos em cada região.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
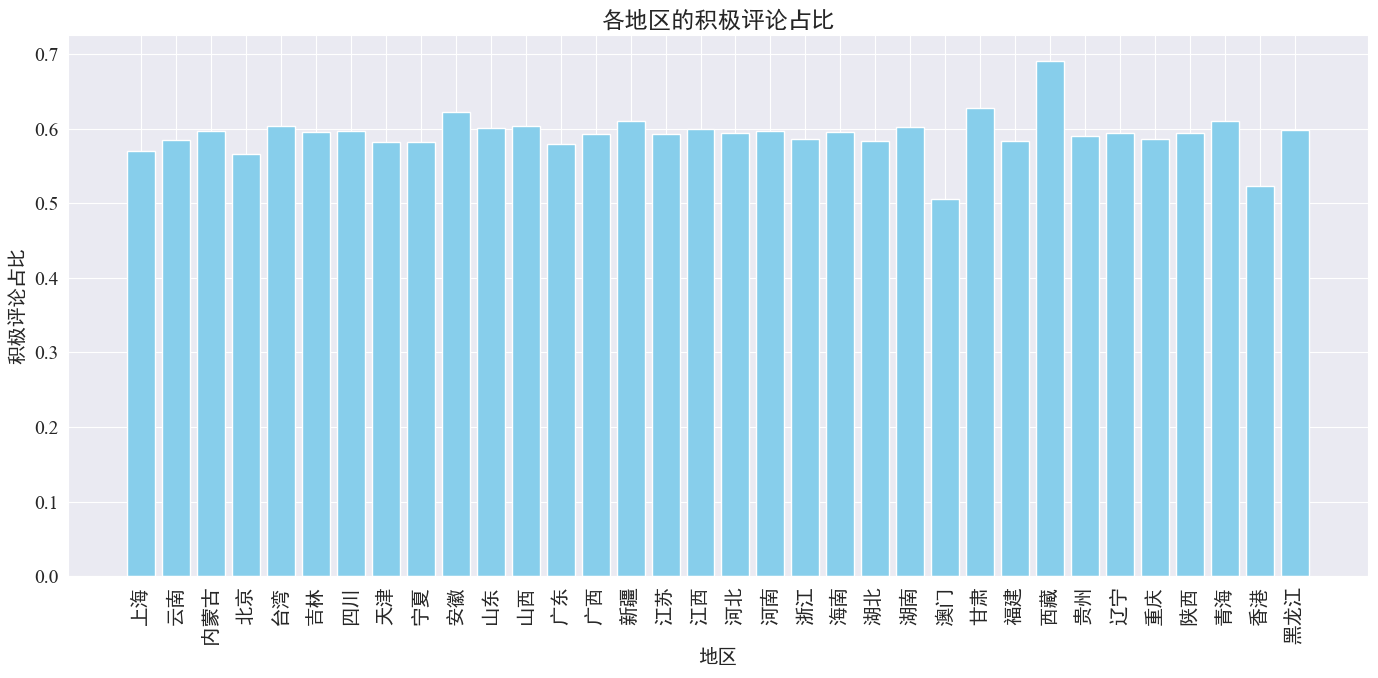
Como pode ser visto na figura acima, a proporção de comentários positivos na maioria das províncias é de cerca de 60%. Hong Kong e Macau têm a menor proporção de comentários positivos, cerca de 50%, enquanto o Tibete tem a maior proporção de comentários positivos, perto de. 70%.
Da distribuição de comentários acima, podemos ver que os comentários na China continental são na sua maioria comentários positivos, enquanto os comentários negativos em Hong Kong e Macau aumentaram significativamente. O maior número de comentários positivos no Tibete pode ser devido ao erro causado pelo erro. o pequeno tamanho da amostra no Tibete.
Comentários de notícias Desenho de gráfico de nuvem de palavras
Os diagramas de nuvem de palavras de todos os comentários, comentários positivos e comentários negativos foram contados separadamente. No desenho do diagrama de nuvem de palavras, os comentários positivos foram listados acima de 0,6 e os comentários negativos foram classificados como abaixo de 0,4. diagramas desenhados.

Pode-se observar que os comentários da maioria das pessoas durante a epidemia são relativamente simples, como "haha", "bom", etc. Nos comentários positivos, você pode ver palavras encorajadoras como "Vamos, China", "Vamos, Wuhan" , etc., enquanto nos comentários negativos há críticas como “Haha” e “É difícil enriquecer um país”.

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]