le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'epidemia di COVID-19 colpisce il cuore di ognuno di noi. In questo caso, cercheremo di utilizzare metodi di social computing per analizzare notizie e voci relative all'epidemia per aiutareInformazioni sull'epidemia Ricerca. Questo compito è a tempo indeterminato. Forniamo dati sociali durante l'epidemia e incoraggiamo gli studenti ad analizzare le tendenze sociali da notizie, voci e documenti legali. (Suggerimento: utilizzare i metodi appresi in classe, come l'analisi del sentiment, l'estrazione delle informazioni, la comprensione della lettura, ecc. per analizzare i dati)
https://covid19.thunlp.org/ fornisce informazioni sui dati sociali relativi all'epidemia del nuovo coronavirus, comprese voci relative all'epidemia CSDC-Rumor, notizie cinesi relative all'epidemia CSDC-News e documenti legali relativi all'epidemia CSDC-Legal.
Questa parte del set di dati raccolto:
(1) A partire dal 22 gennaio 2020Weibo false informazioniI dati includono il contenuto dei post Weibo ritenuti informazioni false, editori, informatori, tempi del processo, risultati e altre informazioni. Al 1 marzo 2020, ci sono un totale di 324 testi originali Weibo, 31.284 forward e 7.912 commenti. ., utilizzato per aiutare i ricercatori ad analizzare e studiare la diffusione di informazioni false durante l'epidemia;
(2) La piattaforma di verifica delle voci di Tencent e i dati sulle false informazioni di Dingxiangyuan dal 18 gennaio 2020, comprese informazioni quali il contenuto della voce considerata corretta o falsa, l'ora e la base per giudicare se si tratta di una voce, al momento 1 marzo 2020, ci sono 507 dati di voci, inclusi 124 dati reali. La distribuzione dei dati è: casi negativi: 420, casi positivi: 33 e incerti: 54.
Questa parte del set di dati raccoglie dati sulle notizie a partire dal 1 gennaio 2020, inclusi titolo, contenuto, parole chiave e altre informazioni delle notizie. Al 16 marzo 2020 sono stati raccolti un totale di 148.960 notizie e 1.653.086 commenti corrispondenti. Utilizzato per aiutare i ricercatori ad analizzare e studiare i dati delle notizie durante l'epidemia.
Questi dati provengono da CHIAMA Un totale di 1.203 parti storiche relative all’epidemia sono state selezionate dai dati dei documenti legali raccolti in forma anonima. Ciascun dato include il titolo del documento, il numero del caso e il testo completo del documento, che può essere utilizzato dai ricercatori per condurre ricerche sulle questioni giuridiche rilevanti durante l’epidemia. Ricerca.
Questo incarico è un incarico aperto, inizieremo da
Incarichi di valutazione in altri aspetti.
[1] Credibilità delle informazioni su Twitter. in Proceedings of WWW, 2011.
[2] Rilevamento di voci da microblog con reti neurali ricorrenti. in Atti dell'IJCAI, 2016.
[3] Un approccio convoluzionale per l'identificazione della disinformazione. in Proceedings of IJCAI, 2017.
[4] La diffusione di notizie vere e false online. Science, 2018.
[5] False informazioni sul web e sui social media: un sondaggio. arXiv preprint, 2018.
[6] Caratterizzazione delle norme affettive per le parole inglesi tramite categorie emozionali discrete. Metodi di ricerca comportamentale, 2007.
Questo esperimento fornisce il set di dati sulle voci relative all'epidemia CSDC-Rumor Analizzando il contenuto del set di dati, scegliamo di eseguire prima un'analisi statistica quantitativa sul set di dati, quindi di utilizzare il clustering per implementare l'analisi semantica delle voci e infine di progettare un set di dati. sistema di rilevamento delle voci.
Formato dei dati
Questo esperimento fornisce il set di dati sulle voci relative all’epidemia CSDC-Rumor, che raccoglie dati Weibo su false informazioni e dati che confutano le voci. Il set di dati contiene quanto segue.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Weibo false informazionirispettivamente da rumor_weibo Erumor_forward_comment due con lo stesso nomejson descritto nel fascicolo.rumor_weibo mezzojson I campi specifici sono i seguenti:
rumorCode: Il codice univoco del rumor, attraverso il quale si può accedere direttamente alla pagina di segnalazione del rumor.title: il contenuto del titolo della voce segnalata.informerName: nome Weibo del giornalista.informerUrl: Link Weibo del giornalista.rumormongerName: il nome Weibo della persona che ha pubblicato la voce.rumormongerUr: Link Weibo della persona che ha pubblicato la voce.rumorText: Contenuto delle voci.visitTimes: il numero di volte in cui questa voce è stata visitata.result: I risultati di questa revisione delle voci.publishTime: L'ora in cui è stata riferita la voce.related_url: Collegamenti a prove, regolamenti, ecc. relativi a questa voce.rumor_forward_comment mezzojson I campi specifici sono i seguenti:
uid: pubblica l'ID utente.text: commenta o inoltra il post scriptum.date: tempo di rilascio.comment_or_forward: binario, neanche comment, O forward, indicando se il messaggio è un commento o un postscript inoltrato.Tencent e Lilac Garden false informazioniIl formato del contenuto è:
date: tempoexplain: Tipo di vocetag:tag vociabstract: contenuto utilizzato per verificare le vocirumor: PettegolezzoPreelaborazione dei dati
passaggio json.load() Estrai i dati Weibo delle voci separatamenteweibo_data Commenta l'invio di dati con indiscrezioniforward_comment_data e quindi convertirlo nel formato DataFrame. I due file con lo stesso nome, articolo Weibo e inoltro commenti Weibo, corrispondono tra loro durante l'elaborazione dei dati nella cartella rumor_forward_comment, aggiungi rumorCode per la successiva corrispondenza.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Questa sezione utilizza l'analisi statistica quantitativa per acquisire una comprensione specifica della distribuzione dei dati Weibo sulle voci sull'epidemia.
Statistiche sul numero di volte in cui i rumors sono stati visitati
statistiche weibo_df['visitTimes'] Distribuzione dei tempi di accesso e tracciamento dell'istogramma corrispondente I risultati sono i seguenti.
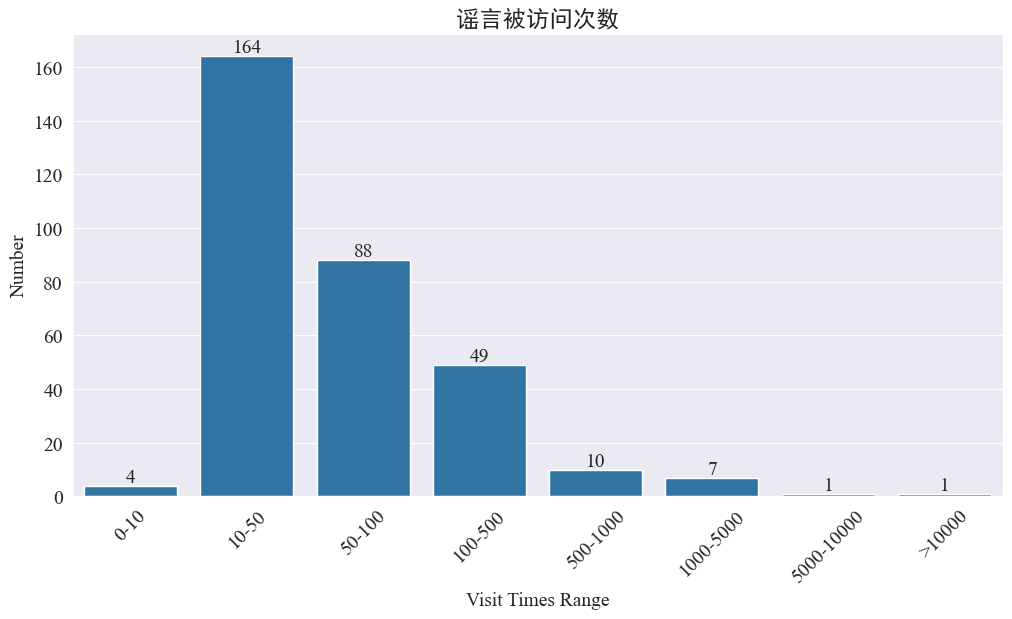
Secondo il numero di visite a Weibo, la maggior parte delle voci sull’epidemia sono state visitate meno di 500 volte su Weibo, di cui 10-50 rappresentano la percentuale maggiore. Tuttavia, su Weibo circolano anche voci a cui si è avuto accesso più di 5.000 volte, che hanno avuto un impatto grave e sono considerate “serie” dalla legge.
Statistiche sulla presenza di rumor maker e informatori
dalle statistiche weibo_df['rumormongerName'] Eweibo_df['informerName'] Si ottengono il numero di voci pubblicate da ciascun editore e il numero di voci riportate da ciascun giornalista. I risultati sono i seguenti.
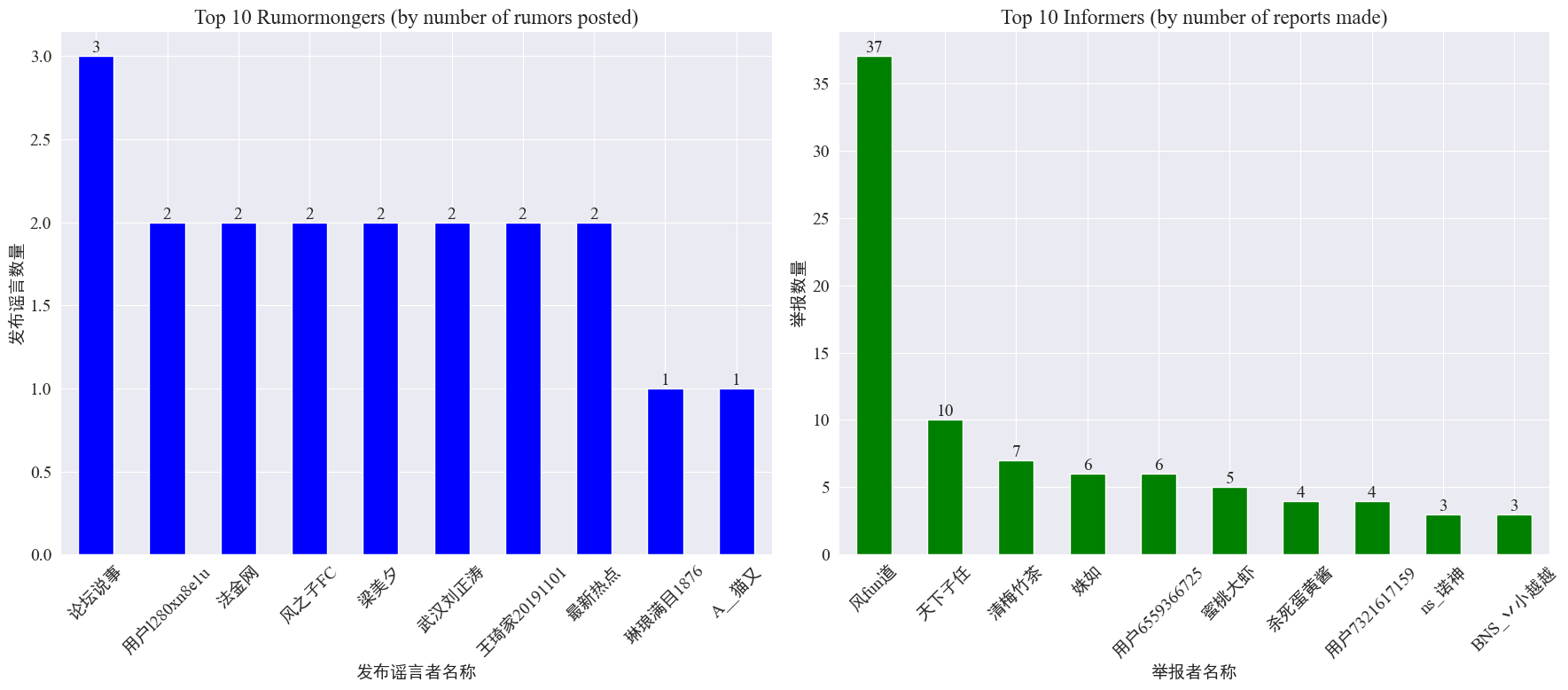
Si può vedere che il numero di voci pubblicate dai creatori di voci non è concentrato su poche persone, ma è relativamente uniforme. L'account che ha pubblicato il maggior numero di voci ha pubblicato tre post su Weibo. Ciascuno dei 10 principali informatori ha segnalato almeno 3 articoli di voci. Tra questi, il numero di voci segnalate dagli informatori su Weibo è stato significativamente superiore a quello degli altri utenti, raggiungendo i 37 articoli.
Sulla base dei dati di cui sopra, il pubblico può concentrarsi sulla segnalazione di account con un gran numero di voci per facilitarne l'individuazione.
Statistiche di distribuzione dei commenti che inoltrano voci
Contando la distribuzione del volume delle voci trasmesse e del volume dei commenti, si ottiene la seguente immagine di distribuzione.

Si può vedere che il numero di commenti e ripubblicazioni sulla maggior parte delle voci su Weibo è compreso tra 10 volte, con un numero massimo di commenti che non supera i 500 e un numero massimo di ripubblicazioni che supera i 10.000. Secondo la legge sulla gestione di Internet, se una voce viene trasmessa più di 500 volte, la situazione è considerata "grave".
Analisi dei cluster di testi di voci
Questa parte esegue la preelaborazione dei dati sui testi delle voci su Weibo ed esegue l'analisi dei cluster dopo la segmentazione delle parole per vedere dove sono concentrate le voci su Weibo.
Preelaborazione dei dati
Innanzitutto, pulisci il testo dei dati delle voci, rimuovi i valori predefiniti e <> Il contenuto del collegamento allegato.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Quindi caricare le parole chiave cinesi e utilizzarle cn_parole di stop ,utilizzojieba Implementare l'elaborazione della segmentazione delle parole dei dati ed eseguire la vettorizzazione del testo.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Determinare il miglior clustering
Utilizzando il metodo del gomito, vengono determinati i migliori cluster.
Il metodo del gomito è un metodo utilizzato per determinare il numero ottimale di cluster nell'analisi dei cluster. Si basa sulla relazione tra la somma degli errori quadratici (SSE) e il numero di cluster. SSE è la somma delle distanze euclidee al quadrato da tutti i punti dati nel cluster al centro del cluster a cui appartiene. Riflette l'effetto del clustering: minore è l'SSE, migliore è l'effetto del clustering.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
Il metodo del gomito determina il numero ottimale di cluster cercando il "gomito", cioè cercando un punto sulla curva dopo il quale la velocità di diminuzione dell'SSE rallenta in modo significativo. Questo punto è come il gomito di un braccio, da qui il nome "Metodo del gomito". Questo punto è solitamente considerato il numero ottimale di cluster.
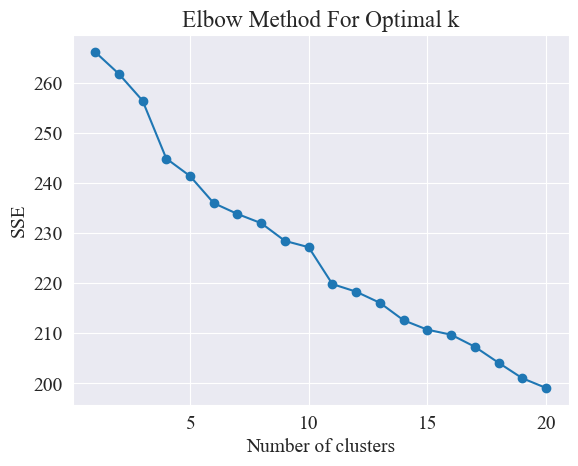
Dalla figura sopra, si determina che il valore di clustering del gomito è 11 e viene disegnato il grafico a dispersione corrispondente. I risultati sono i seguenti.
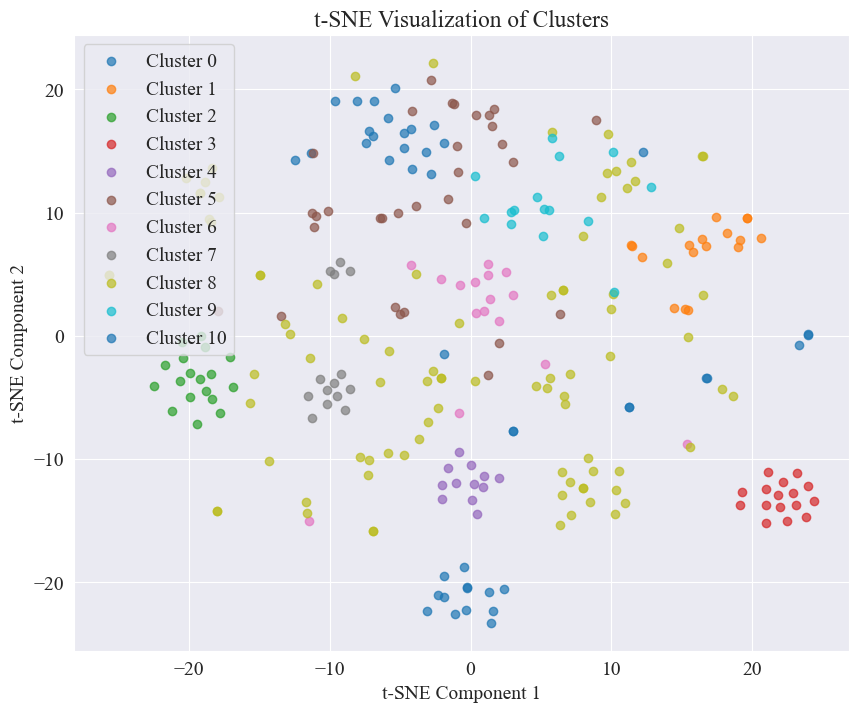
Si può vedere che la maggior parte dei post di Weibo sono ben raggruppati, il n. 3 e il n. 4, alcuni sono ampiamente distribuiti e non ben raggruppati, come il n. 5 e il n. 8;
Risultati del clustering
Per mostrare chiaramente quali voci sono raggruppate in ciascuna categoria, viene disegnato un grafico a nuvola per ciascuna categoria. I risultati sono i seguenti.

Stampa alcuni contenuti Weibo di voci ben raggruppate e i risultati sono i seguenti.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Analisi dei cluster dei risultati della revisione delle voci
Raggruppare il contenuto del testo delle voci potrebbe non essere molto utile per l'analisi del contenuto delle voci, quindi abbiamo scelto di raggruppare i risultati della revisione delle voci.
Determinare il miglior clustering
Utilizzando il grafico del gomito, determinare il miglior clustering.
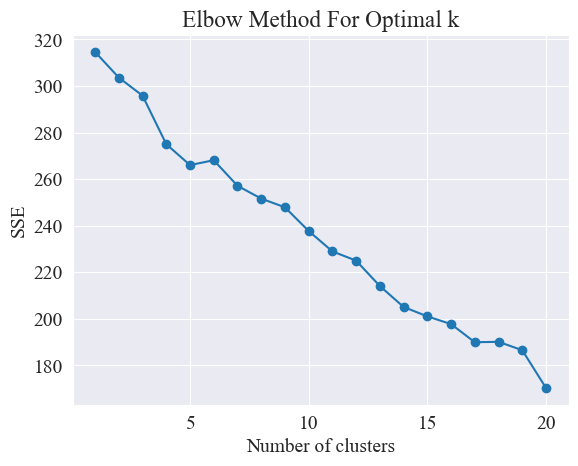
Dal diagramma del gomito sopra, è possibile determinare due gomiti, uno è quando il clustering è 5 e l'altro è quando il clustering è 20. Scelgo 20 per il clustering.
Il grafico a dispersione ottenuto raggruppando 20 categorie è il seguente.
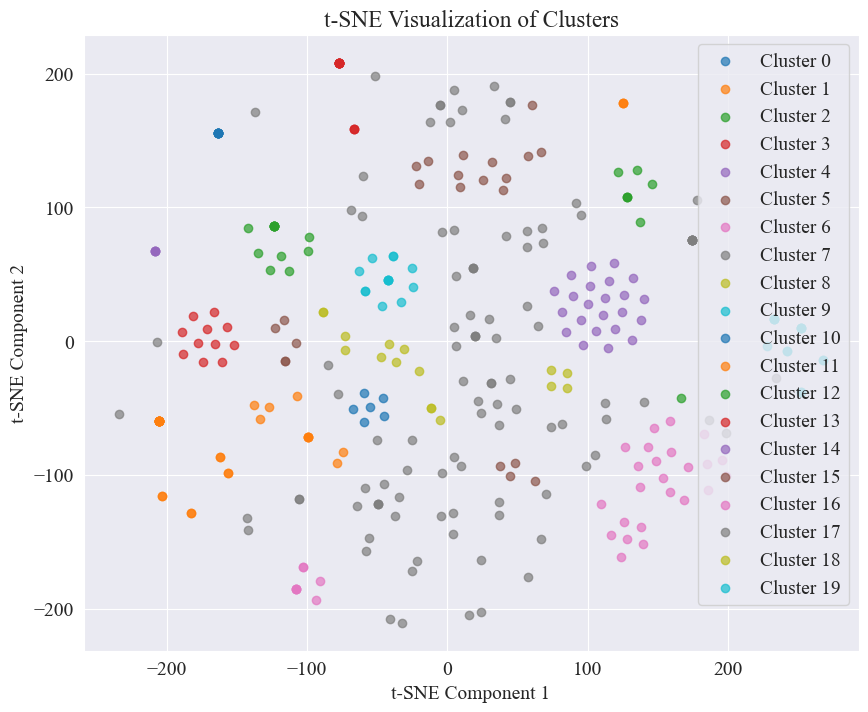
Si può vedere che la maggior parte di esse sono ben raggruppate, ma la settima e la diciassettesima categoria non sono ben raggruppate.
Risultati del clustering
Per mostrare chiaramente quali risultati della revisione delle voci sono raggruppati in ciascuna categoria, viene disegnato un grafico a nuvola per ciascuna categoria. I risultati sono i seguenti.

Stampa alcuni risultati della revisione delle voci ben raggruppati. I risultati sono i seguenti.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Per il rilevamento di queste voci, abbiamo scelto di utilizzare set di dati che sono stati confutati. fact.json Confronta la somiglianza tra voci confutate e voci vere e seleziona l'articolo confutato con la maggiore somiglianza con la voce Weibo come base per il rilevamento delle voci.
Carica i dati delle voci Weibo e i set di dati che confutano le voci
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Utilizza modelli linguistici pre-addestrati per codificare le voci su Weibo e i titoli che confutano le voci in vettori incorporati
Utilizzato in questo esperimento bert-base-chinese Come modello pre-addestrato, esegui l'addestramento del modello. Il modello SimCSE viene utilizzato per migliorare la rappresentazione e la misurazione della somiglianza della semantica delle frasi attraverso l'apprendimento contrastivo.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Calcola la somiglianza
Per calcolare la somiglianza, l'incorporamento della frase e la somiglianza dell'entità denominata del modello SimCSE vengono utilizzati per calcolare la somiglianza completa.
extract_entitiesLa funzione estrae entità denominate dal testo utilizzando il modello NER.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityLa funzione calcola la somiglianza dell'entità denominata tra due testi.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityLa funzione combina l'incorporamento della frase e la somiglianza dell'entità denominata del modello SimCSE per calcolare la somiglianza completa.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Implementare il rilevamento delle voci
Confrontando le somiglianze, viene implementato un meccanismo di rilevamento delle voci.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
L'output è il seguente:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Ha trovato con successo le basi per confutare le voci e ha dato un giudizio per confutare le voci.
Formato dei dati
Questo esperimento fornisce il set di dati sulle notizie relative all’epidemia CSDC-News, che raccoglie notizie e contenuti di commento nella prima metà del 2020. Il set di dati contiene quanto segue.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
La cartella dati è divisa in tre parti:data,comment。
data La cartella contiene diversi file, ogni file corrisponde ai dati di una certa data, nel formatojson . Il contenuto di questa parte corrisponde ai dati testuali della notizia (verrà aggiornato progressivamente con la data), e i campi comprendono:
time: Orario di rilascio delle notizie.title:Il titolo della notizia.url: Il link all'indirizzo originale della notizia.meta: le informazioni testuali della notizia, che comprendono i seguenti campi: content: il contenuto testuale della notizia.description: Una breve descrizione della notizia.title:Il titolo della notizia.keyword: Parole chiave delle notizie.type: Tipo di notizia.comment La cartella contiene diversi file, ogni file corrisponde ai dati di una certa data, nel formatojson . Questa parte del contenuto corrisponde ai dati del commento della notizia (potrebbe esserci un ritardo di circa una settimana tra i dati del commento e i dati del testo della notizia. I campi includono:
time: Orario di rilascio delle notizie e data Corrisponde ai dati nella cartella.title: Il titolo della notizia, con data Corrisponde ai dati nella cartella.url: Il collegamento all'indirizzo originale della notizia e data Corrisponde ai dati nella cartella.comment: Informazioni sui commenti alle notizie Questo campo è un array. Ogni elemento dell'array contiene le seguenti informazioni: area: Area revisore.content:Commenti.nickname: soprannome del revisore.reply_to: oggetto risposta del commentatore Se non ce n'è, significa che non è una risposta.time: Tempo di commento.Preelaborazione dei dati
Dati sugli articoli di notizie data Durante la preelaborazione dei dati è necessariometa Il contenuto viene rilasciato e archiviato in formato DataFrame.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
Nei dati di revisione comment Durante la preelaborazione dei dati è necessariocomment Il contenuto viene rilasciato e archiviato in formato DataFrame.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Carica il set di dati
Caricare il set di dati in base alla funzione di preelaborazione dei dati di cui sopra.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Il risultato della stampa mostra che la lunghezza dei dati delle notizie: 502550 e la lunghezza dei dati dei commenti: 1534616.
Statistiche sulla distribuzione temporale delle notizie
Contare separatamente news_df Il numero di articoli di notizie mensili e il numero di articoli di notizie all'ora sono rappresentati da grafici a barre e grafici a linee. I risultati sono i seguenti.
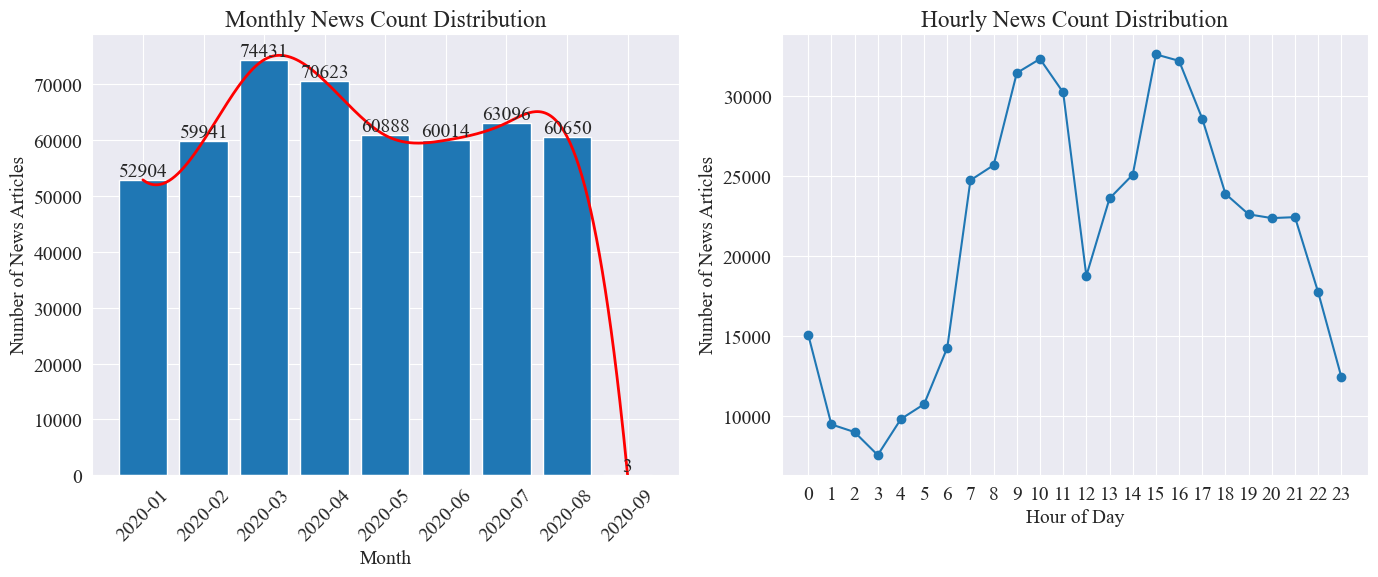
Come si vede dal grafico sopra riportato, con lo scoppio dell’epidemia il numero delle notizie è aumentato di mese in mese, raggiungendo il picco nel mese di marzo con 74.000 articoli, per poi diminuire gradualmente stabilizzandosi a 60.000 articoli al mese, di cui i dati di settembre erano 3 alle 0:00 articoli, potrebbero non essere inclusi nelle statistiche.
Secondo la distribuzione della quantità di notizie all'ora, si può vedere che le 10 e le 15 di ogni giorno sono le ore di punta del rilascio di notizie, con più di 30.000 articoli pubblicati ciascuna. Alle 12 è la pausa pranzo e il numero di comunicati stampa ha alti e bassi. Il numero di comunicati stampa è minimo tra le 0:00 e le 5:00 di ogni giorno, dove 3:00 è il punto più piccolo.
Monitoraggio dei punti caldi delle notizie
Questo esperimento intende utilizzare il metodo di estrazione delle parole chiave delle notizie per tracciare i punti caldi delle notizie in questi otto mesi. Contando la distribuzione delle parole chiave esistenti e disegnando un istogramma, i risultati sono i seguenti.
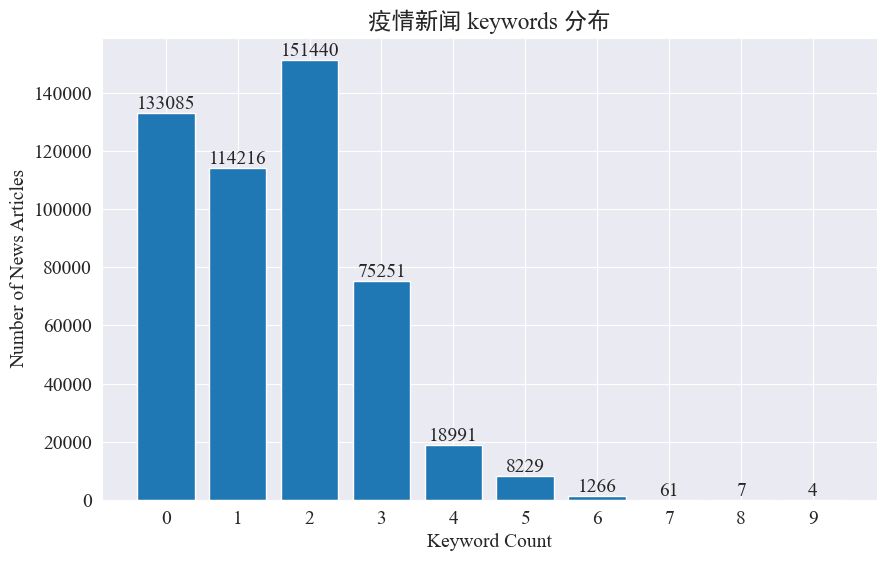
Si può vedere che la maggior parte degli articoli di notizie hanno meno di 3 parole chiave e gran parte degli articoli non hanno nemmeno parole chiave. Pertanto, è necessario raccogliere statistiche e riassumere personalmente le parole chiave per il monitoraggio degli hotspot.Questa volta usajieba.analyse.textrank() per contare le parole chiave.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
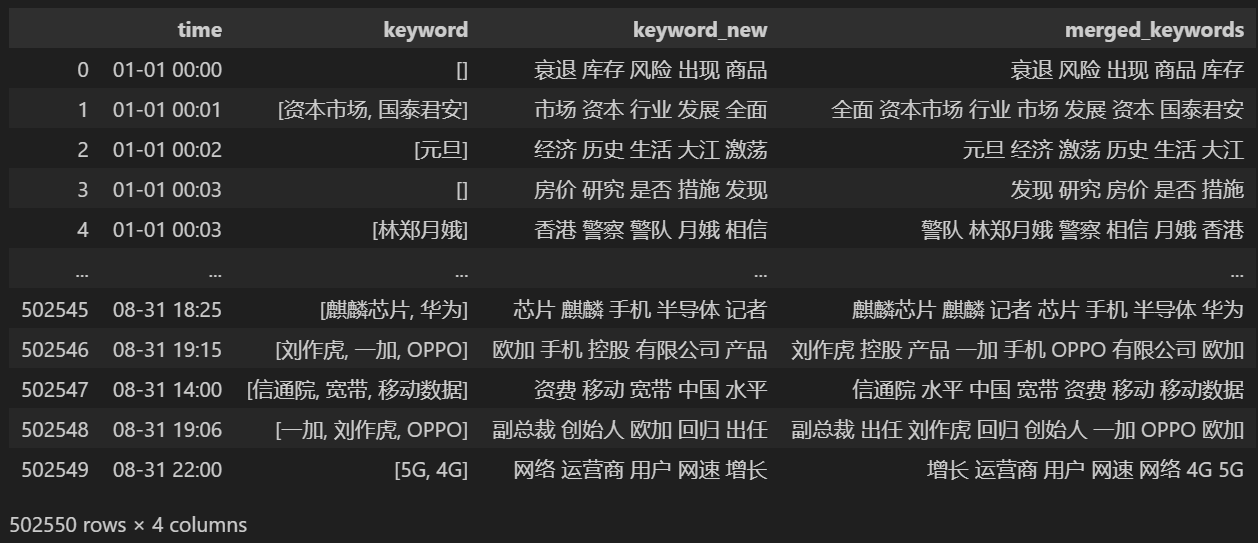
keyword_data
Conta 5 nuove parole chiave, salvale in keyword_new, quindi unisci le parole chiave con esse e rimuovi le parole duplicate.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Stampa dopo l'unione keyword_data , i risultati stampati sono i seguenti.
Per tenere traccia dei punti caldi, conta la frequenza delle parole di tutte le parole che appaiono e conta keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Quindi, sulla base dei dati statistici di cui sopra, disegna un grafico del cambiamento giornaliero delle parole calde.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Infine, è stato ottenuto un grafico gif delle variazioni delle parole chiave nelle notizie sull'epidemia. I risultati sono i seguenti.
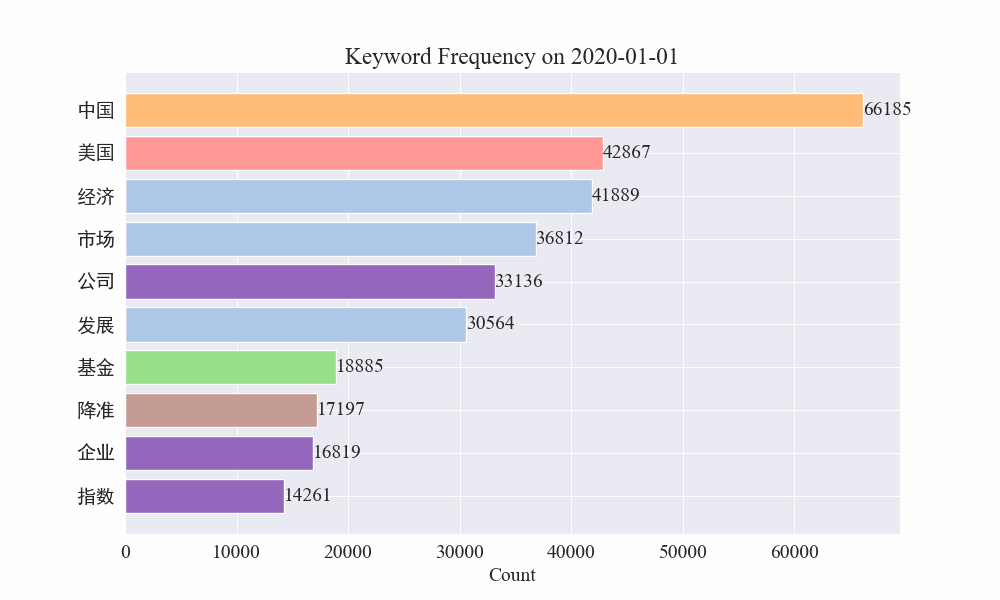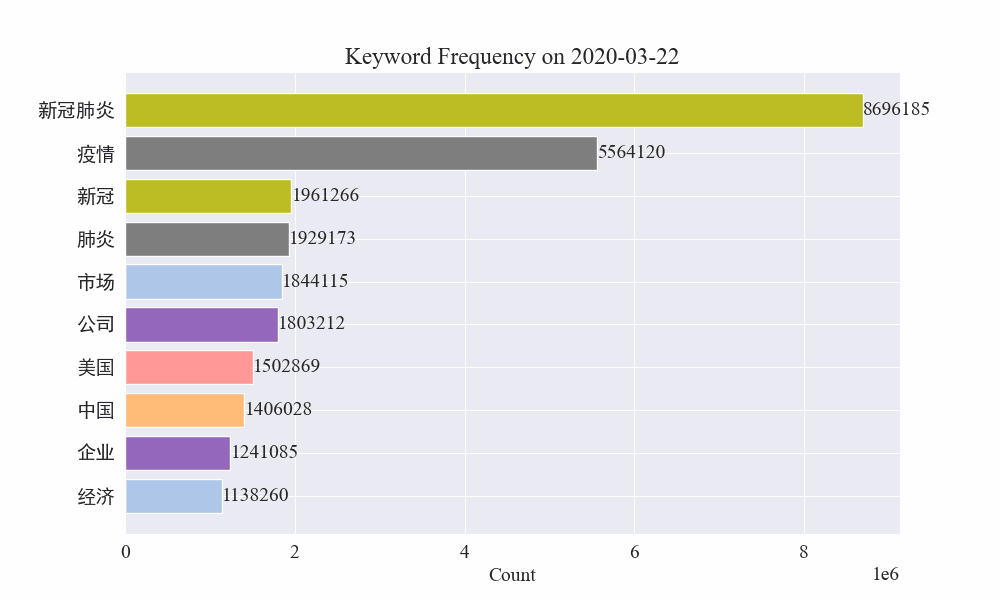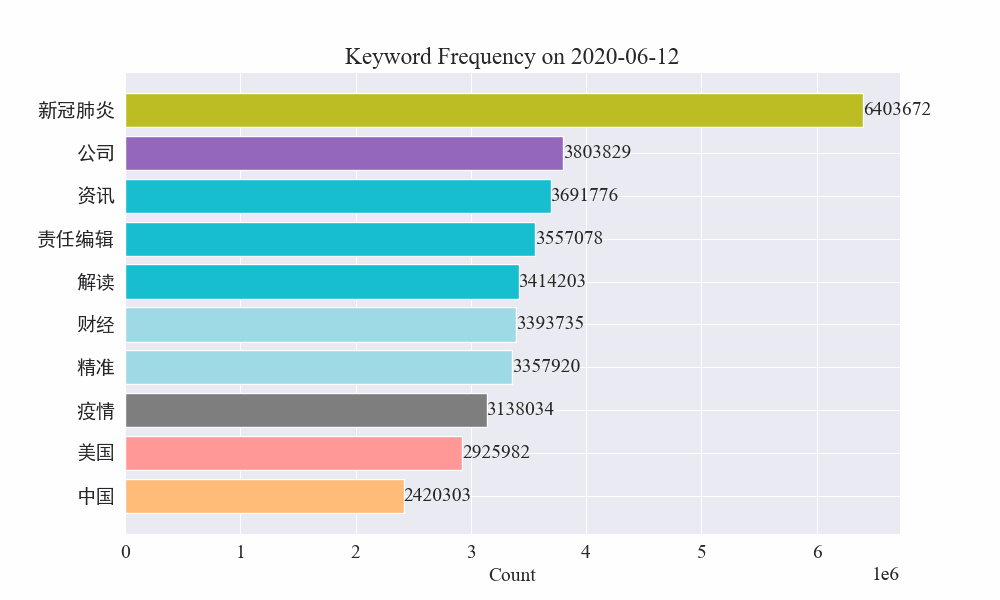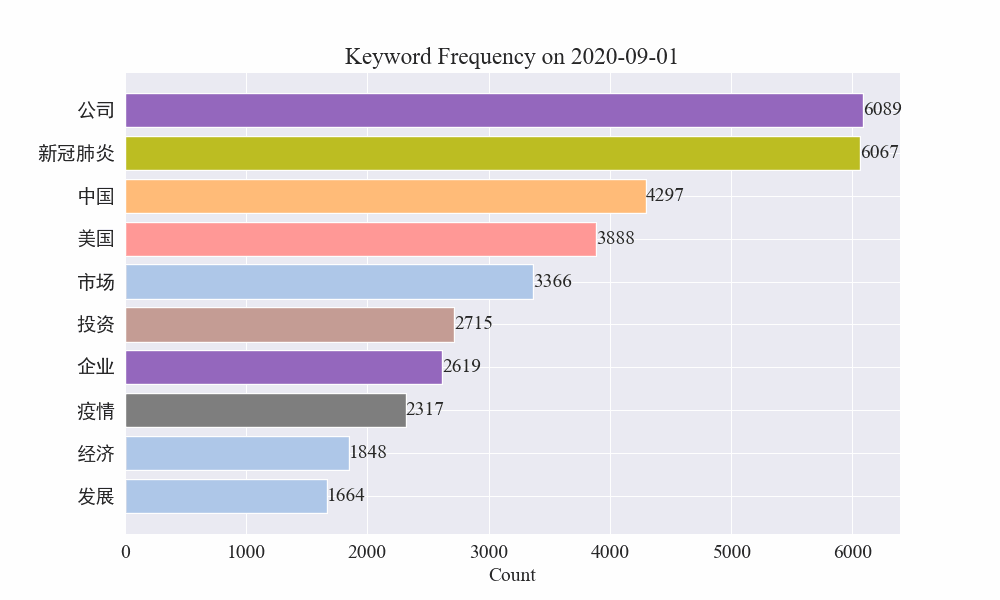
Prima dello scoppio, i termini “azienda” e “Iran” rimanevano alti. Si può notare che dopo lo scoppio dell'epidemia, il numero delle notizie relative all'epidemia ha cominciato ad aumentare a partire da febbraio. Successivamente, i termini "nuovo coronavirus" sono aumentati e sono rimasti al primo posto fino alla fine di agosto. la prima ondata dell'epidemia ha rallentato ed è diventata il secondo posto.
Questa sezione conduce innanzitutto un'analisi statistica quantitativa sui commenti alle notizie, quindi conduce un'analisi del sentiment su diversi commenti.
Statistiche sul conteggio dei commenti sulle notizie quotidiane
Contare l'andamento del numero di commenti alle notizie, utilizzare un grafico a barre per rappresentarlo e tracciare una curva approssimativa. Il codice è il seguente.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Il grafico statistico del numero di commenti alle notizie giornaliere è disegnato come segue.
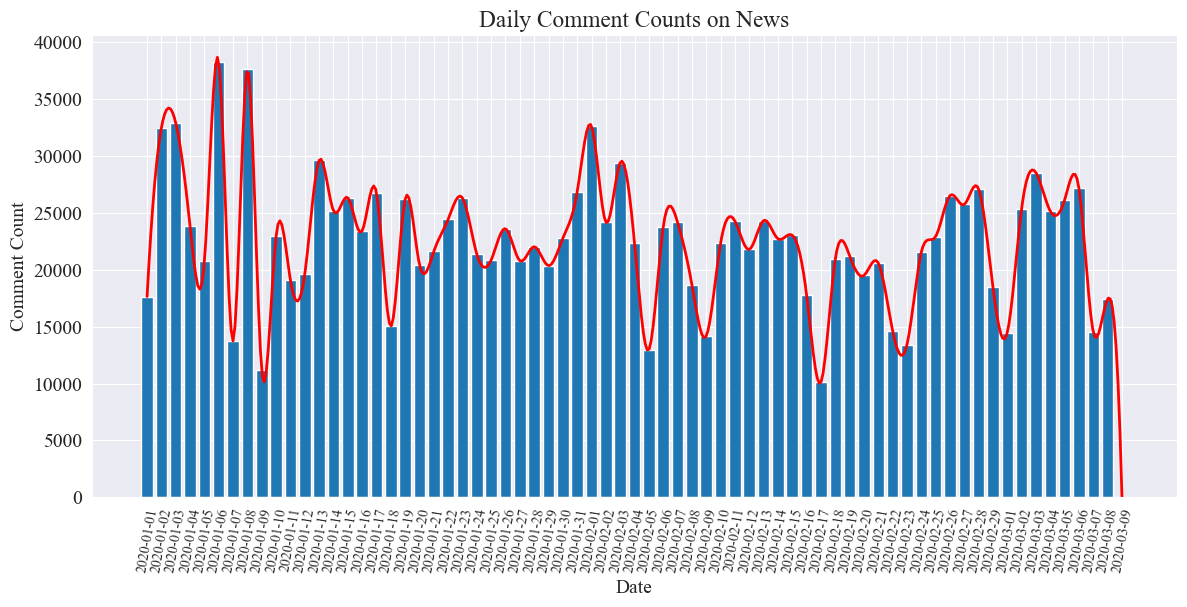
Si può notare che il numero di commenti alle notizie durante l’epidemia ha oscillato tra 10.000 e 40.000, con una media di circa 20.000 commenti al giorno.
Statistiche sulle notizie sull'epidemia per regione
per provincia comment_df['province'] Conta il numero di notizie in ciascuna provincia e conta il numero di commenti alle notizie sull'epidemia in ciascuna provincia.
Per prima cosa devi superare il file comment_df['province'] Estrai informazioni sulla provincia.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Quindi, sulla base dei dati statistici, viene tracciato un grafico a torta che mostra la proporzione dei commenti alle notizie in ciascuna provincia.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

In questo esperimento abbiamo utilizzato anche pyecharts.charts DiMap Componente, che traccia la distribuzione del numero di commenti sulla mappa della Cina per provincia.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
Nell'HTML ottenuto, la distribuzione del numero di commenti sulle notizie sull'epidemia in ciascuna provincia della Cina è la seguente.
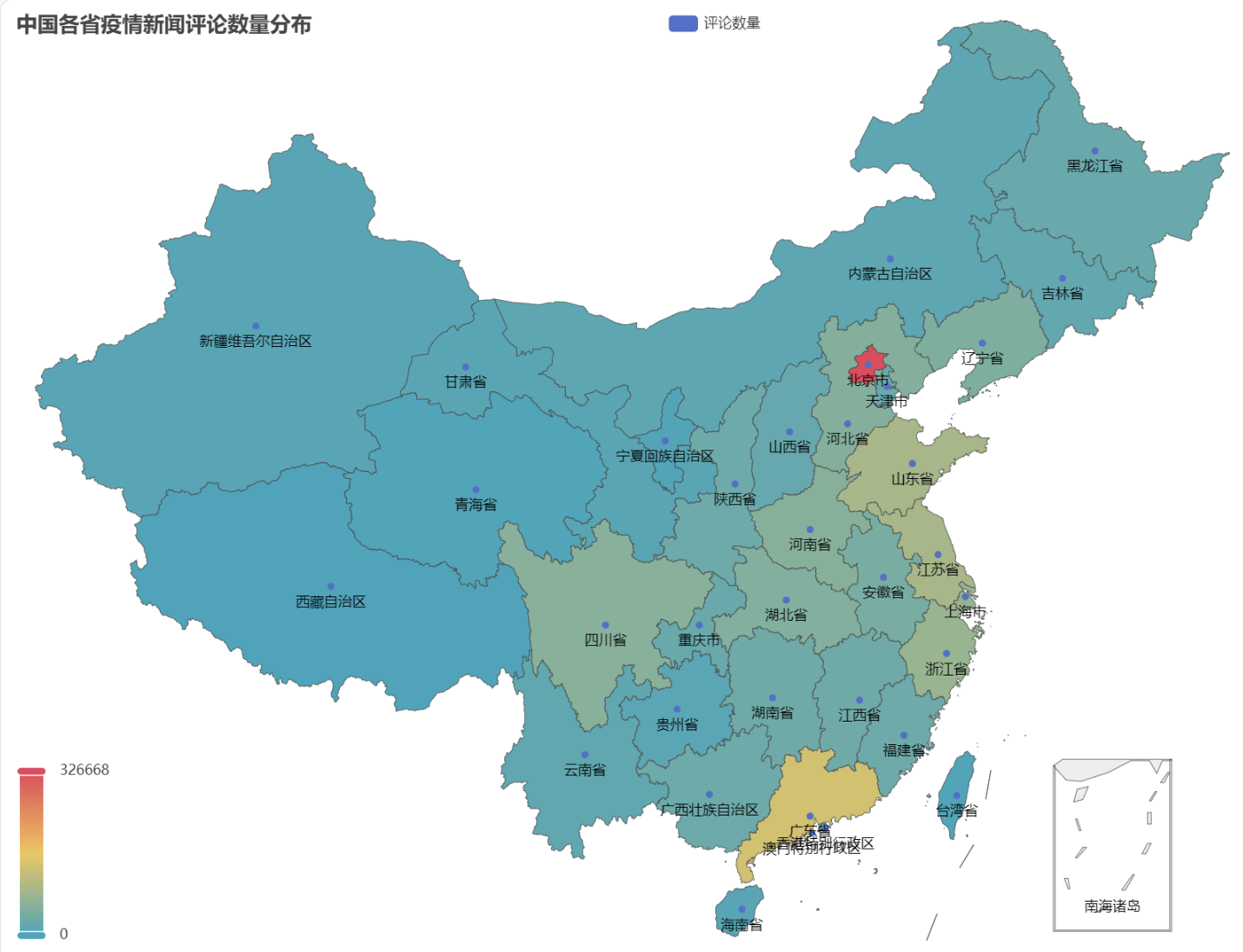
Si può vedere che durante l’epidemia, il numero di commenti a Pechino rappresentava la percentuale più alta, seguita dalla provincia di Guangdong, e il numero di commenti in altre province era relativamente uniforme.
epidemiaEsaminare l'analisi del sentiment
Questo esperimento utilizza la libreria NLP per l'elaborazione del testo cinese SnowNLP , implementa l'analisi del sentiment cinese, analizza ogni commento e fornisci il corrispondentesentiment Valore, il valore è compreso tra 0 e 1, più vicino a 1, più positivo, più vicino a 0, più negativo.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
In questo esperimento, 0,5 viene utilizzato come soglia. Qualsiasi valore superiore a questo valore è un commento positivo, mentre qualsiasi valore inferiore a questo valore è un commento negativo. Scrivendo il codice, disegna un grafico di analisi del sentiment dei commenti sulle notizie quotidiane e conta il numero di commenti positivi e il numero di commenti negativi sulle notizie quotidiane. Il numero di commenti positivi è un valore positivo e il numero di commenti negativi è negativo valore.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
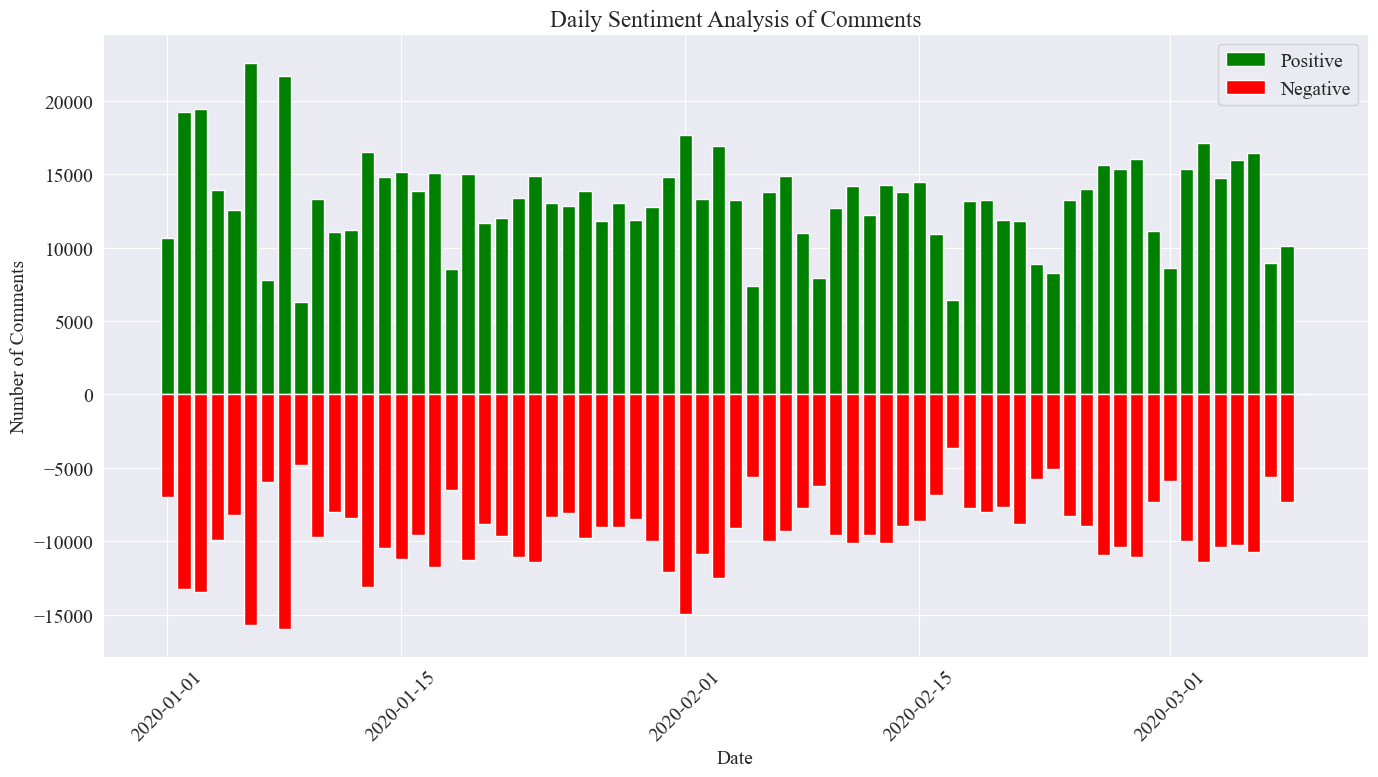
L'immagine statistica finale è quella mostrata sopra. Si può vedere che i commenti positivi durante l'epidemia erano leggermente superiori ai commenti negativi Contando la percentuale di commenti positivi, si è riscontrato che la percentuale di commenti positivi era del 58,63%. che il pubblico aveva un atteggiamento più positivo nei confronti dell’epidemia.
Analisi del sentiment dei commenti per regione
Contando la percentuale di commenti positivi pubblicati in ciascuna provincia e regione, è stato ottenuto un grafico della percentuale di commenti positivi in ciascuna regione.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
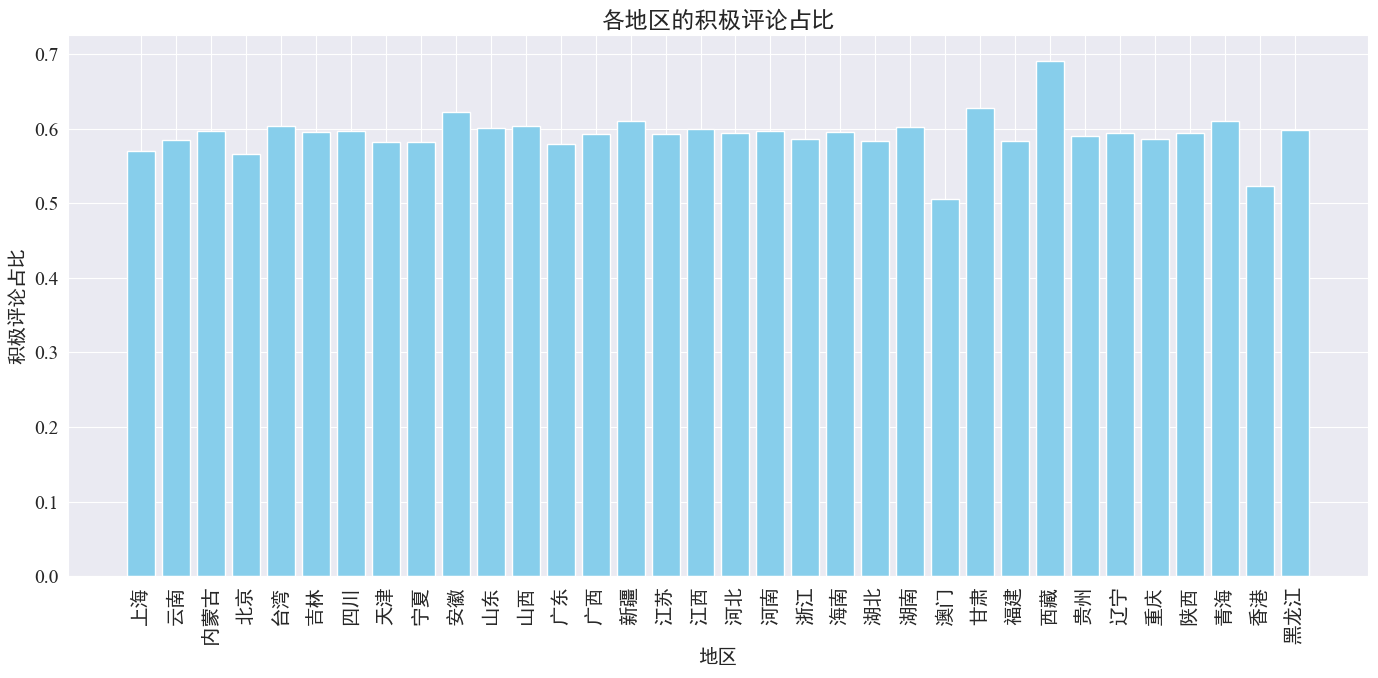
Come si può vedere dalla figura sopra, la percentuale di commenti positivi nella maggior parte delle province è intorno al 60%. Hong Kong e Macao hanno la percentuale più bassa di commenti positivi, circa il 50%, mentre il Tibet ha la percentuale più alta di commenti positivi, vicino al 50%. 70%.
Dalla distribuzione dei commenti di cui sopra, possiamo vedere che i commenti nella Cina continentale sono per lo più positivi, mentre i commenti negativi a Hong Kong e Macao sono aumentati in modo significativo. Il maggior numero di commenti positivi in Tibet potrebbe essere dovuto all'errore causato da la piccola dimensione del campione in Tibet.
Commenti alle notizie Disegno grafico Word Cloud
I diagrammi delle nuvole di parole di tutti i commenti, i commenti positivi e quelli negativi sono stati conteggiati separatamente Nel disegno del diagramma delle nuvole di parole, i commenti positivi sono stati elencati come sopra 0,6 e i commenti negativi sono stati classificati come sotto 0,4. Di seguito sono riportate le tre nuvole di parole diagrammi disegnati.

Si può vedere che i commenti della maggior parte delle persone durante l'epidemia sono relativamente semplici, come "ahah", "buono", ecc. Nei commenti positivi puoi vedere parole incoraggianti come "Vieni Cina", "Vieni Wuhan" , ecc., mentre nei commenti negativi si trovano critiche come "Haha" e "È difficile arricchire un Paese".

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]