私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
新型コロナウイルス感染症の流行は私たち一人ひとりの心に影響を与えています。この場合、ソーシャル コンピューティングの手法を使用して、流行に関連するニュースや噂を分析して支援しようとします。疫病情報研究。この課題は自由形式の課題であり、感染症流行時の社会データを提供し、ニュース、噂、法的文書から社会の傾向を分析することを学生に奨励します。 (ヒント: 感情分析、情報抽出、読解など、授業で学んだ方法を使用してデータを分析します)
https://covid19.thunlp.org/ は、流行関連の噂 CSDC-Rumor、流行関連の中国ニュース CSDC-News、流行関連の法的文書 CSDC-Legal など、新型コロナウイルスの流行に関連するソーシャル データ情報を提供します。
収集されたデータセットのこの部分:
(1) 2020年1月22日からWeiboの誤った情報このデータには、虚偽の情報とみなされるWeibo投稿の内容、発行者、内部告発者、裁判期間、結果などが含まれており、2020年3月1日現在、Weiboの原文は324件、転送は31,284件、コメントは7,912件ある。 、研究者が流行中に誤った情報の拡散を分析および研究するのを支援するために使用されます。
(2) 2020年1月18日以降のテンセントのデマ検証プラットフォームと丁祥源の虚偽情報データ。これには、デマの真偽の内容、時期、デマかどうかを判断する根拠などが含まれる。 2020 年 3 月 1 日現在、噂データは 507 件あり、そのうち事実データは 124 件あります。データ分布は、陰性例: 420 例、陽性例: 33 例、不確実例: 54 例です。
データセットのこの部分は、2020 年 1 月 1 日以降のニュースのタイトル、内容、キーワード、その他の情報を含むニュース データを収集します。2020 年 3 月 16 日の時点で、合計 148,960 件のニュース項目と 1,653,086 件の対応するコメントが収集されました。研究者が流行中にニュースデータを分析および研究するのを支援するために使用されます。
このデータは ケイル 収集された匿名化された法的文書データから合計 1,203 件の歴史的な疫病関連部分が選別され、各データには文書のタイトル、事件番号、文書の全文が含まれており、研究者が調査に使用できます。流行中の関連する法的問題に関する研究。
この課題はオープン課題です。次から始めます。
他の側面での課題の採点。
[1] Twitterにおける情報の信頼性。Proceedings of WWW、2011年。
[2] リカレントニューラルネットワークによるマイクロブログからの噂の検出。IJCAI Proceedings of IJCAI、2016年。
[3] 誤情報識別のための畳み込みアプローチ。IJCAI Proceedings of IJCAI、2017年。
[4] ネット上での真実と偽りのニュースの拡散。サイエンス、2018年。
[5] ウェブとソーシャルメディア上の虚偽情報:調査。arXivプレプリント、2018年。
[6] 個別の感情カテゴリーによる英語の単語の感情規範の特徴づけ。行動研究方法、2007年。
この実験では、疫病関連の噂データ セット CSDC-Rumor を提供します。データ セットの内容を分析することにより、最初にデータ セットに対して定量的な統計分析を実行し、次にクラスタリングを使用して噂の意味分析を実装し、最後に噂検知システム。
データ形式
この実験では、Weibo の虚偽情報データと噂の反論データを収集した疫病関連の噂データセット CSDC-Rumor を提供します。データセットには以下が含まれます。
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Weiboの誤った情報それぞれによって rumor_weibo そしてrumor_forward_comment 同じ名前の2つjson ファイルに記載されています。rumor_weibo 真ん中json 特定のフィールドは次のとおりです。
rumorCode: 噂の固有コード。噂報告ページに直接アクセスできます。title:報道されている噂のタイトル内容。informerName:Weiboの記者名。informerUrl:記者のWeiboリンク。rumormongerName: 噂を公開した人の Weibo 名。rumormongerUr: 噂を投稿した人のWeiboリンク。rumorText:噂の内容。visitTimes: この噂の訪問回数。result:この噂の検証結果。publishTime:噂が報道された時期。related_url: この噂に関する証拠、規制などへのリンク。rumor_forward_comment 真ん中json 特定のフィールドは次のとおりです。
uid:ユーザーIDを公開します。text: 追記をコメントまたは転送します。date: リリース時間。comment_or_forward: バイナリ、いずれか comment、 どちらか forward、メッセージがコメントであるか、転送された追記であるかを示します。テンセントとライラックガーデンの虚偽情報コンテンツの形式は次のとおりです。
date: 時間explain: 噂の種類tag:噂のタグabstract: 噂を検証するためのコンテンツrumor: 噂データの前処理
合格 json.load() 噂の Weibo データを個別に抽出するweibo_data 噂のあるコメント転送データforward_comment_data を選択し、DataFrame 形式に変換します。 Weibo 記事と Weibo コメント転送という同じ名前の 2 つのファイルは相互に対応しています。rumu_forward_comment フォルダー内のデータを処理する際に、後続の照合用に RumCode を追加します。
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
このセクションでは、定量的な統計分析を使用して、伝染病の噂の Weibo データの分布を具体的に理解します。
噂の訪問回数の統計
統計 weibo_df['visitTimes'] アクセス時間の分布と対応するヒストグラムを描画すると、次のようになります。
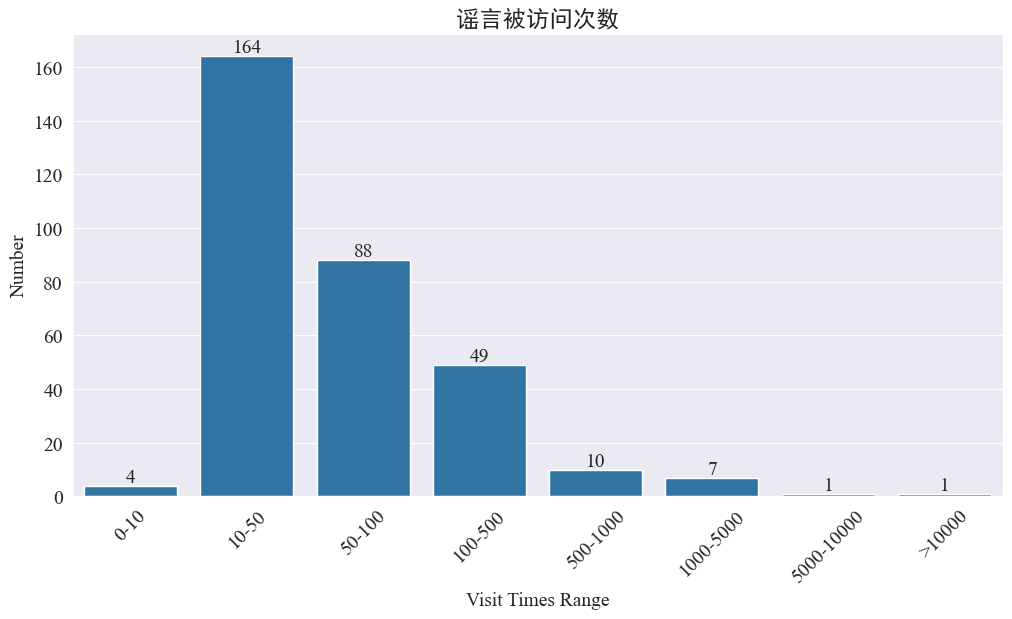
Weiboへの訪問回数によると、疫病の噂のほとんどはWeiboへの訪問回数が500回未満で、10~50回が最も大きな割合を占めている。ただし、Weibo には 5,000 回以上アクセスされている噂もあり、これは深刻な影響を及ぼし、法律で「重大」とみなされます。
噂作成者と内部告発者の発生に関する統計
統計による weibo_df['rumormongerName'] そしてweibo_df['informerName'] 各デマ発行者が公開したデマの数と、各記者が報告したデマの数を取得した結果は以下の通りです。
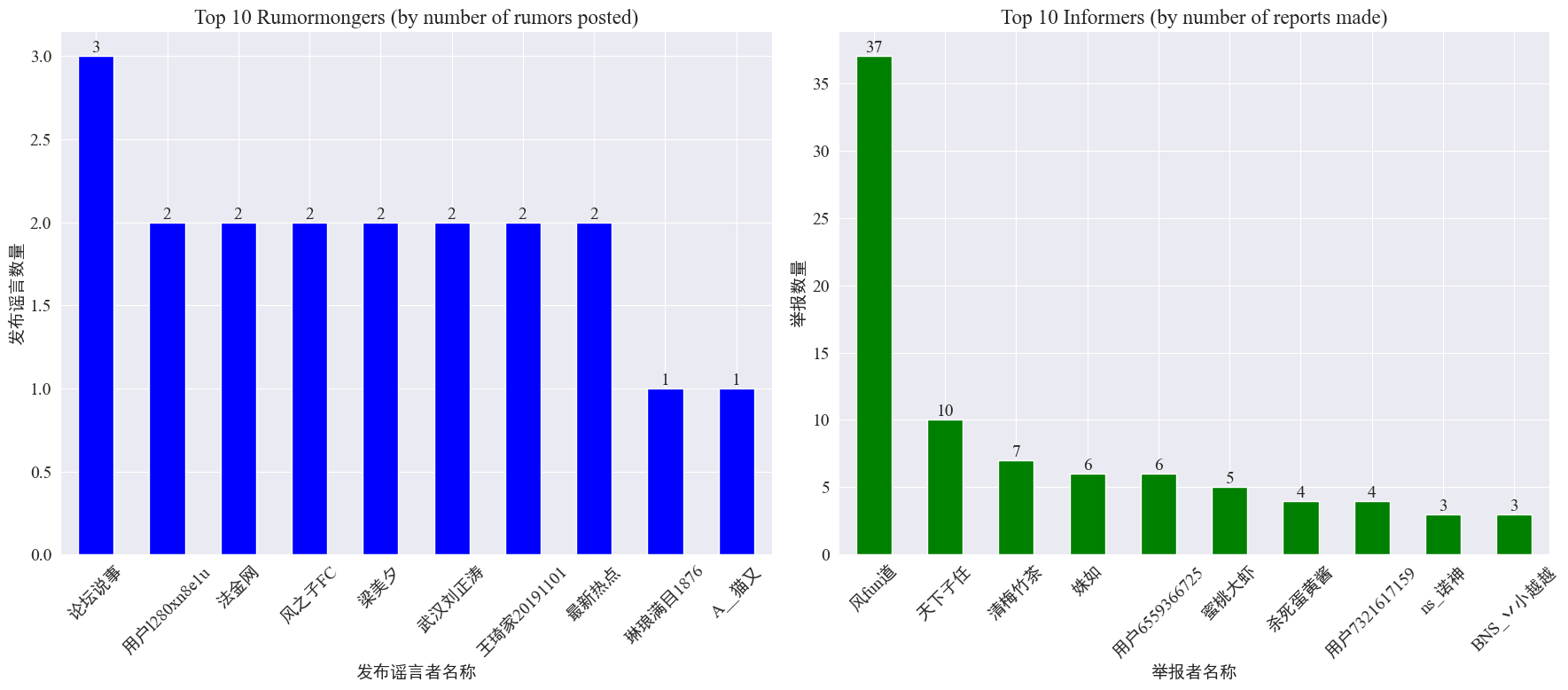
噂作成者が投稿した噂の数は一部の人に集中しているわけではなく、最も多くの噂を投稿したアカウントが 3 つの噂投稿を Weibo に投稿したことが比較的均等であることがわかります。上位10人の内部告発者はそれぞれ少なくとも3件の噂記事を報告しており、その中でWeibo上で内部告発者が報告した噂の数は他のユーザーよりも大幅に多く、37件に達した。
上記のデータに基づいて、視聴者は噂の発見を容易にするために、多数の噂のあるアカウントの報告に集中できます。
噂転送コメントの分布統計
噂の転送量とコメント量の分布を集計すると、以下のような分布イメージが得られます。

ほとんどの噂のWeiboでのコメントと再投稿の数は10回以内で、コメントの最大数は500を超えず、再投稿の最大数は10,000以上に達していることがわかります。インターネット管理法によれば、デマの転送が500回を超えた場合は「重大」な事態とみなされます。
噂テキストクラスター分析
この部分では、Weibo の噂テキストに対してデータの前処理を実行し、単語分割後にクラスター分析を実行して、Weibo の噂がどこに集中しているかを確認します。
データの前処理
まず、噂のデータ テキストを消去し、デフォルト値を削除し、 <> 囲まれたリンクのコンテンツ。
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
次に、中国語のストップワードをロードすると、ストップワードは次のようになります。 cn_ストップワード 、使用jieba データの単語分割処理を実装し、テキストのベクトル化を実行します。
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
最適なクラスタリングを決定する
エルボー法を使用することにより、最適なクラスターが決定されます。
エルボー法は、クラスター分析において最適なクラスター数を決定するために使用される方法です。これは、二乗誤差和 (SSE) とクラスター数の関係に基づいています。 SSE は、クラスター内のすべてのデータ ポイントから、それが属するクラスター中心までのユークリッド距離の二乗の合計であり、クラスター化の効果を反映します。SSE が小さいほど、クラスター化の効果は高くなります。
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
エルボー法では、「エルボー」を探すことによって最適なクラスター数を決定します。つまり、SSE の減少速度が大幅に遅くなる曲線上の点を探します。この点は腕の肘のようなものであるため、名前は「エルボー法」。通常、この点が最適なクラスター数と考えられます。
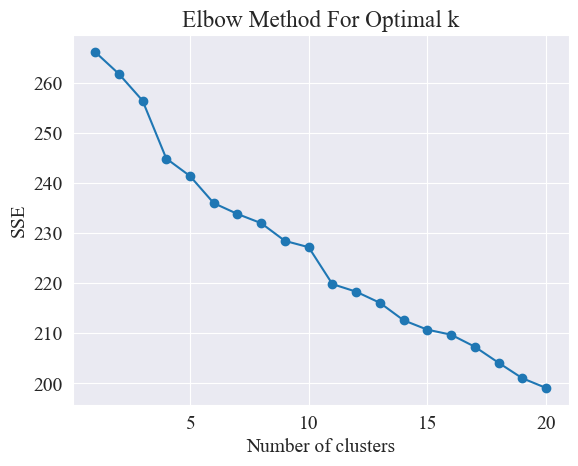
上の図から、エルボのクラスタリング値は 11 であると判断され、対応する散布図が描画されます。結果は次のとおりです。
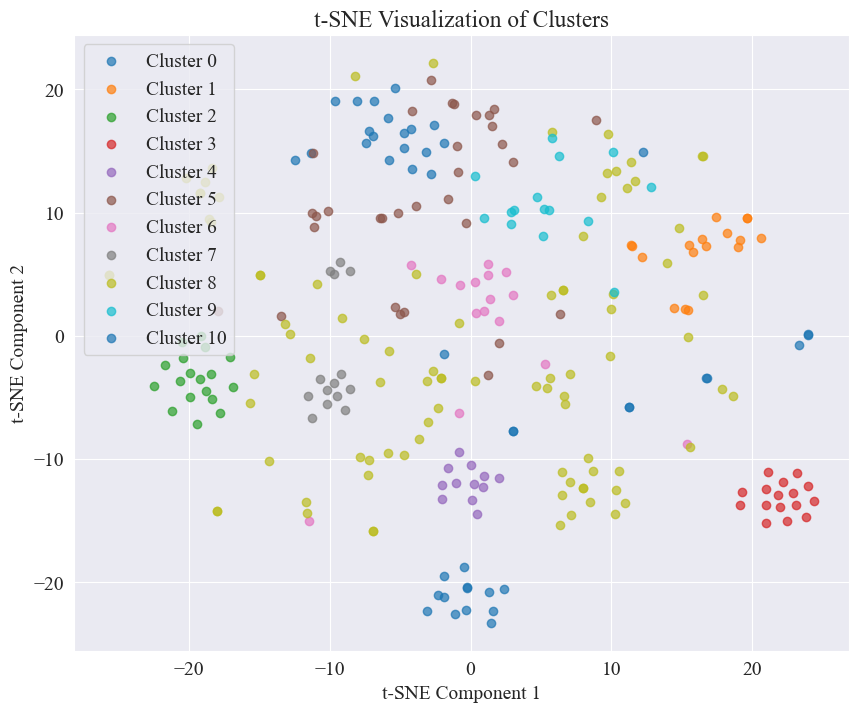
噂の Weibo の投稿のほとんどは十分にクラスター化されており、3 位と 4 位は広く分散されていますが、5 位と 8 位のように十分にクラスター化されていないことがわかります。
クラスタリングの結果
各カテゴリにどのような噂が集中しているかを明確に示すために、カテゴリごとに雲図を作成した結果は次のとおりです。

良くまとまった噂の Weibo コンテンツを印刷すると、結果は次のようになります。
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
噂調査結果のクラスター分析
噂のテキスト コンテンツをクラスタリングすることは、噂の内容分析にはあまり適していない可能性があるため、噂のレビュー結果をクラスタリングすることにしました。
最適なクラスタリングを決定する
エルボ プロットを使用して、最適なクラスタリングを決定します。
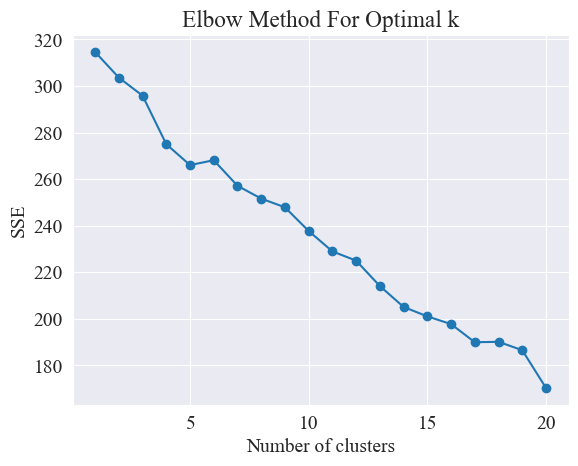
上のエルボ図から、2 つのエルボが決定できます。1 つはクラスタリングが 5 の場合、もう 1 つはクラスタリングが 20 の場合です。クラスタリングには 20 を選択します。
20 カテゴリをクラスタリングして得られた散布図は次のとおりです。
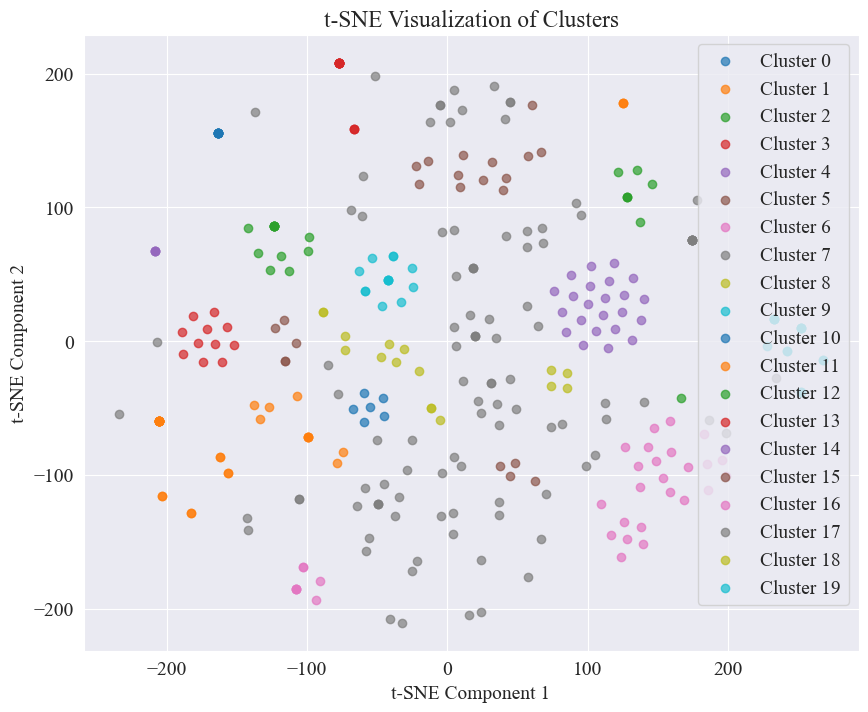
それらのほとんどは適切にクラスタ化されていますが、7 番目と 17 番目のカテゴリは十分にクラスタ化されていないことがわかります。
クラスタリングの結果
各カテゴリにどのような噂レビュー結果が集中しているかを明確に示すために、カテゴリごとに雲図を描画します。結果は次のとおりです。

よくまとまった噂のレビュー結果を出力します。結果は次のとおりです。
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
この噂の検出のために、私たちは反論されたデータセットを使用することを選択しました。 fact.json 反論された噂と本当の噂の類似性を比較し、噂 Weibo との類似性が最も高い反論された記事を噂検出の基礎として選択します。
Weiboの噂データと噂を反論するデータセットをロードします
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
事前トレーニングされた言語モデルを使用して、Weibo の噂や噂を否定するタイトルを埋め込みベクトルにエンコードします
この実験で使用された bert-base-chinese 事前トレーニングされたモデルとして、モデルのトレーニングを実行します。 SimCSE モデルは、対比学習を通じて文の意味の表現と類似性の測定を改善するために使用されます。
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
類似度の計算
類似度の計算には、SimCSE モデルの文埋め込みと固有表現類似度を使用して総合類似度を計算します。
extract_entitiesこの関数は、NER モデルを使用してテキストから名前付きエンティティを抽出します。
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarity関数は、2 つのテキスト間の名前付きエンティティの類似性を計算します。
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityこの関数は、SimCSE モデルの文埋め込みと固有表現類似度を組み合わせて、総合的な類似度を計算します。
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
噂の検出を実装する
類似性を比較することにより、噂検出メカニズムが実装されます。
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
出力は次のとおりです。
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
噂を否定する根拠を見つけることに成功し、噂を否定する判決を下した。
データ形式
この実験では、2020 年上半期のニュースと解説コンテンツを収集した疫病関連ニュース データ セット CSDC-News を提供します。データセットには以下が含まれます。
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
データ フォルダーは 3 つの部分に分かれています。data,comment。
data フォルダーには複数のファイルが含まれており、各ファイルは次の形式の特定の日付のデータに対応します。json 。この部分の内容はニュースのテキスト データに対応し (日付に応じて徐々に更新されます)、次のフィールドが含まれます。
time: ニュースリリースの時間。title:ニュースのタイトル。url:ニュースのオリジナルアドレスリンク。meta: ニュースのテキスト情報。次のフィールドが含まれます。 content: ニュースのテキストコンテンツ。description: ニュースの短い説明。title:ニュースのタイトル。keyword: ニュースのキーワード。type: ニュースの種類。comment フォルダーには複数のファイルが含まれており、各ファイルは次の形式の特定の日付のデータに対応します。json 。コンテンツのこの部分はニュースのコメント データに対応します (コメント データとニュース テキスト データの間には約 1 週間の遅延が発生する可能性があります)。フィールドには次のものが含まれます。
time: ニュースリリース時間、および data フォルダー内のデータに対応します。title:ニュースのタイトル、 data フォルダー内のデータに対応します。url: ニュースの元のアドレスのリンク、および data フォルダー内のデータに対応します。comment: ニュース コメント情報 このフィールドは配列です。配列の各要素には次の情報が含まれます。 area: レビュアーエリア。content:コメント。nickname:レビュアーのニックネーム。reply_to: コメント投稿者の返信オブジェクトがない場合は、返信ではないことを意味します。time: コメントタイム。データの前処理
ニュース記事のデータ data データの前処理中に、次のことが必要です。meta のコンテンツは DataFrame 形式でリリースされ、保存されます。
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
レビューデータでは comment データの前処理中に、次のことが必要です。comment のコンテンツは DataFrame 形式でリリースされ、保存されます。
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
データセットをロードする
上記のデータ前処理関数に従ってデータセットをロードします。
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
印刷結果は、ニュースデータ長:502550、コメントデータ長:1534616となります。
ニュース時間分布統計
別々に数える news_df 月ごとのニュース記事数と時間当たりのニュース記事数を棒グラフと折れ線グラフで表すと以下のようになります。
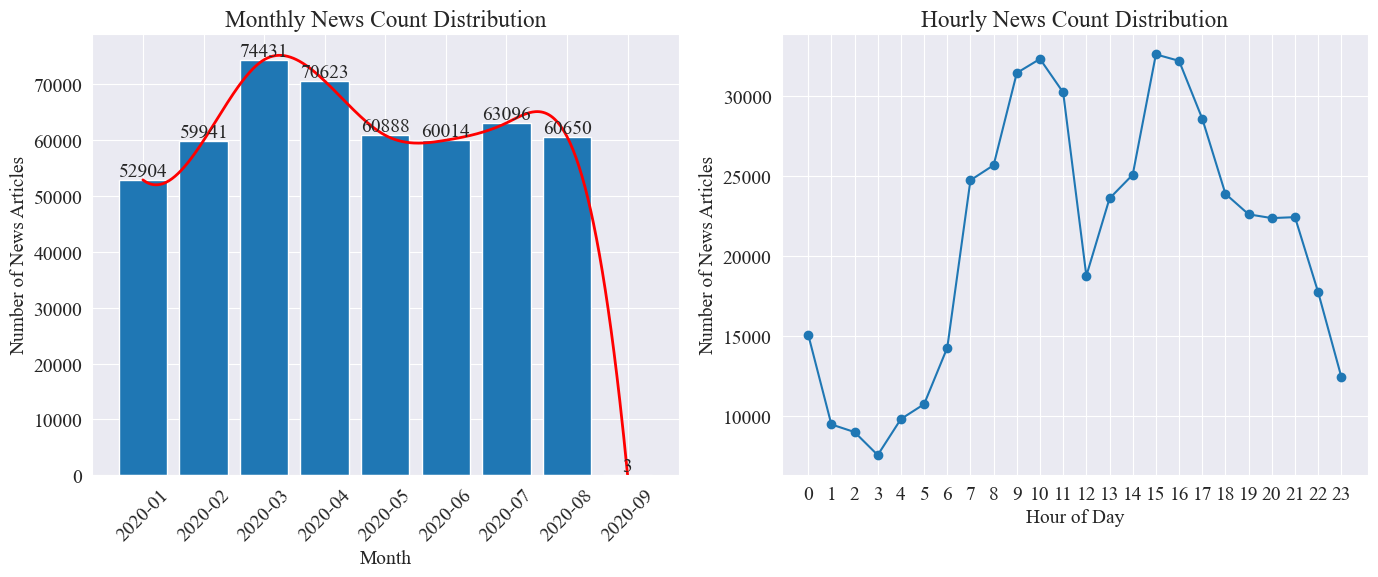
上図からわかるように、感染症の発生とともにニュース数は月ごとに増加し、3月の7.4万記事でピークに達した後、徐々に減少し、月間6万記事まで安定しました。 9月のデータは0時時点で3記事でしたので統計に含まれていない可能性があります。
時間当たりのニュース量の分布を見ると、毎日10時と15時がニュースリリースのピーク時間帯であり、それぞれ3万本以上の記事が公開されていることがわかります。 12時はお昼休みで、ニュースリリースの数は山と谷があります。ニュースリリースの最小数は毎日0時から5時までで、3時が最小点となります。
ニュースのホットスポットの追跡
この実験では、ニュースのキーワードを抽出する方法を使用して、この 8 か月間のニュースのホットスポットを追跡することを目的としています。存在するキーワードの分布をカウントし、ヒストグラムを描くと以下のようになります。
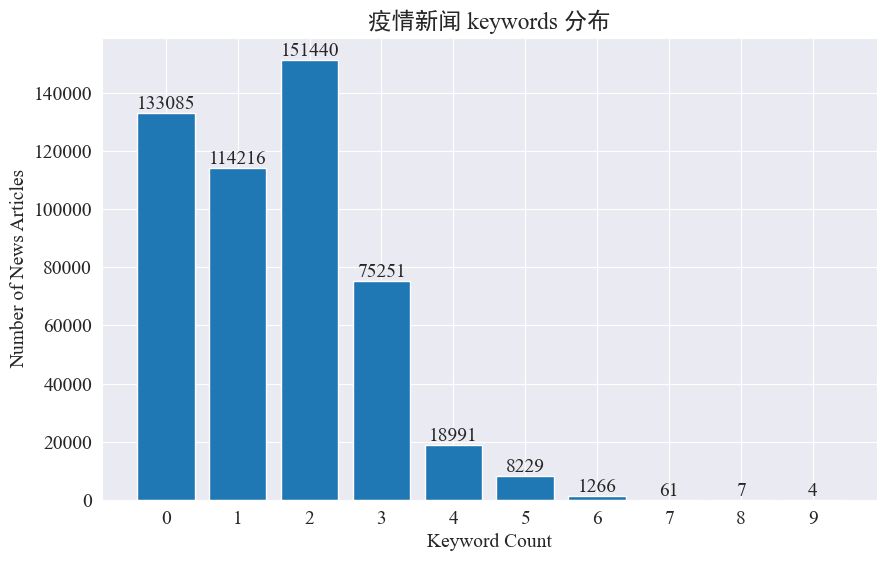
ほとんどのニュース記事のキーワードは 3 つ未満であり、キーワードがまったくない記事も大部分であることがわかります。したがって、ホットスポット追跡のために統計を収集し、キーワードを自分で要約する必要があります。今回使用するのは jieba.analyse.textrank() キーワードを数えるために。
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
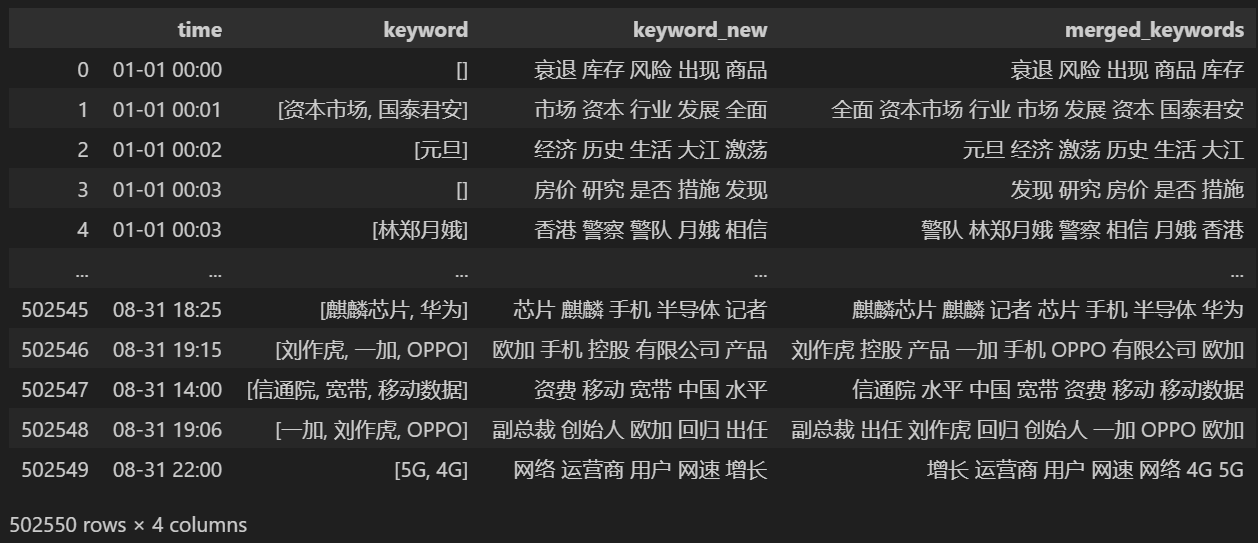
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
新しいキーワードを 5 つ数え、keyword_new に保存し、キーワードを結合して重複する単語を削除します。
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
結合後に印刷する keyword_data 、印刷結果は次のようになります。
ホットスポットを追跡するには、出現するすべての単語の単語頻度をカウントし、 keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
次に、上記の統計データを基に、ホットワードの日次変化グラフを作成します。
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
最後に、疫病ニュースのキーワードの変化を示すgifグラフが得られました。結果は次のとおりです。
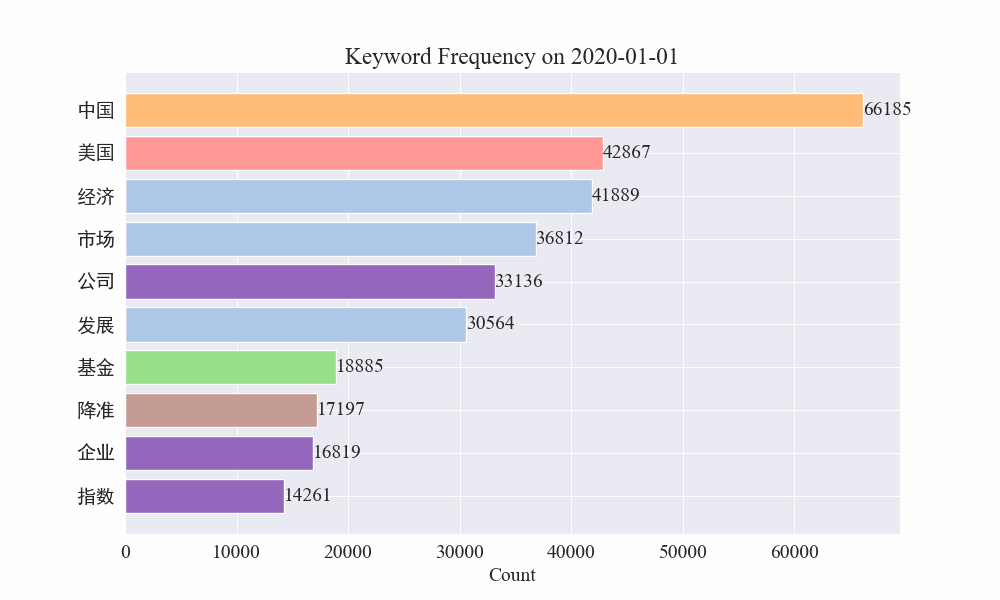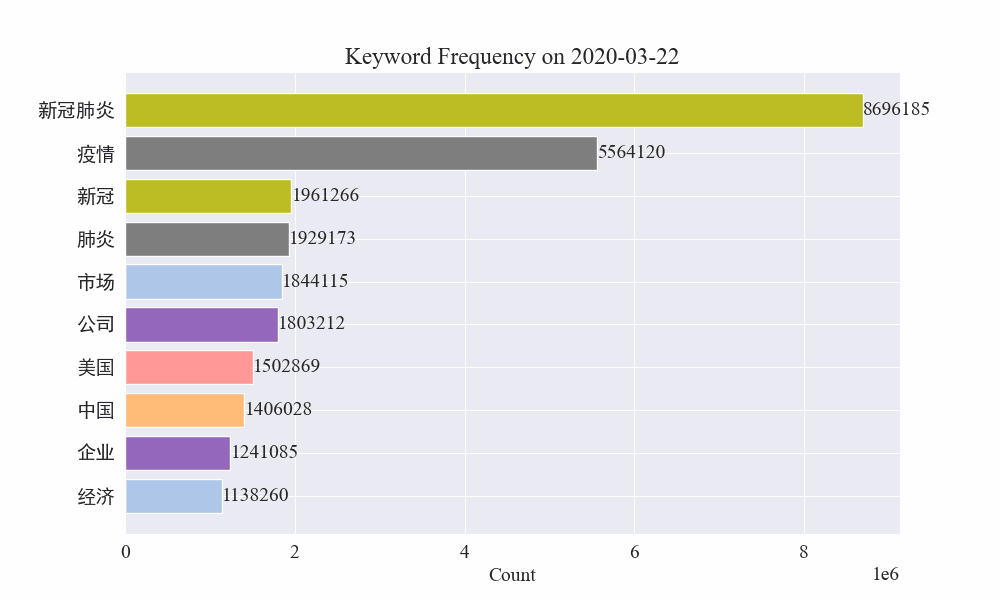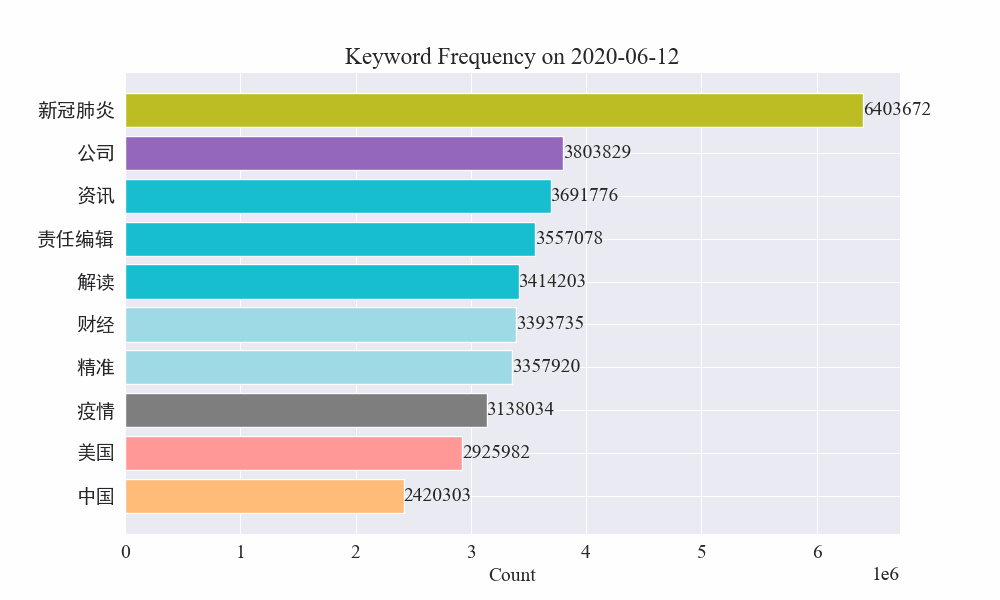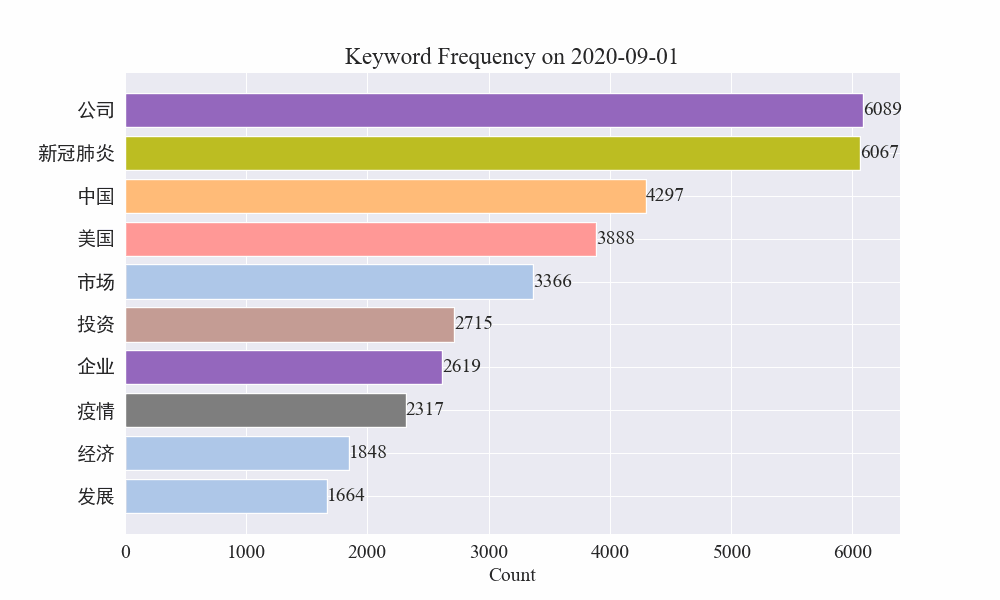
感染拡大前は「企業」や「イラン」という言葉が依然として高かった。流行の発生後、2月から「新型コロナウイルス」という用語が急増し始め、8月末まで1位を維持し続けたことが分かります。流行の第一波は減速し、第二波となった。
このセクションでは、まずニュースのコメントについて定量的な統計分析を実行し、次にさまざまなコメントについてセンチメント分析を実行します。
毎日のニュースのコメント数の統計
ニュースのコメント数の推移をカウントし、棒グラフで表し、近似曲線を描きます。 コードは次のとおりです。
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
毎日のニュースコメント数の統計グラフは以下のようになります。
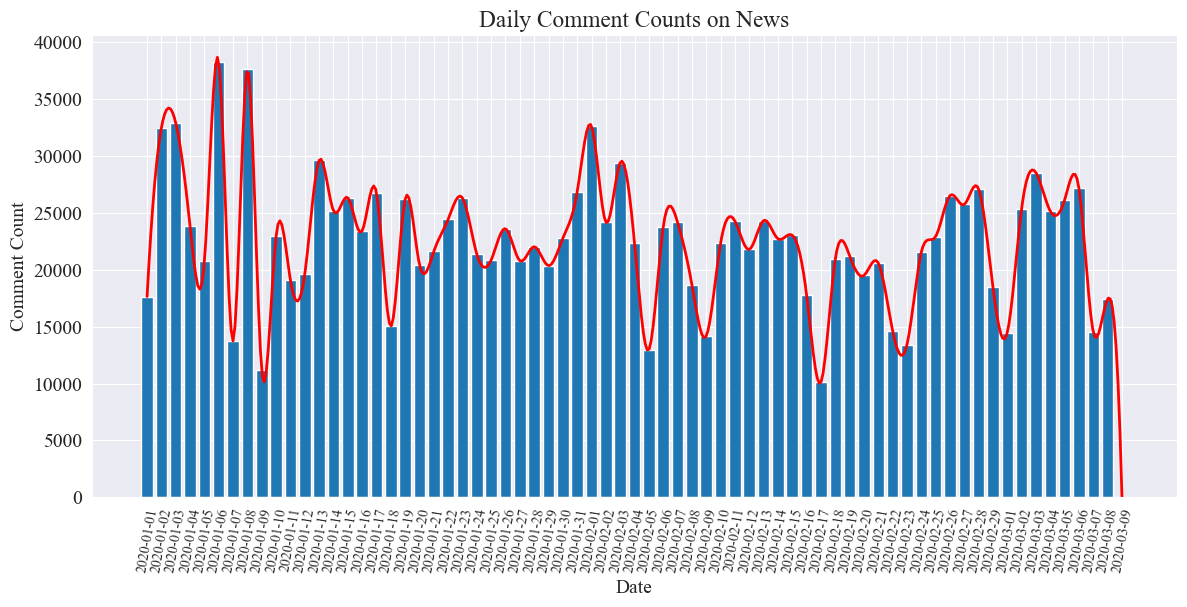
流行期間中のニュースのコメント数は 10,000 ~ 40,000 件の間で変動し、1 日あたりのコメント数は平均約 20,000 件であったことがわかります。
地域別の流行ニュース統計
県別 comment_df['province'] 各州のニュースの数を数え、各州の流行ニュースに対するコメントの数を数えます。
まず、次のパラメータを渡す必要があります。 comment_df['province'] 都道府県情報を抽出します。
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
次に、統計データに基づいて、各州のニュース コメントの割合を示す円グラフが描画されます。
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

今回の実験でも使用しました pyecharts.charts のMap 中国の地図上のコメント数の分布を省別にプロットするコンポーネント。
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
取得したHTMLでは、中国各省の疫病ニュースに対するコメント数の分布は以下の通りです。
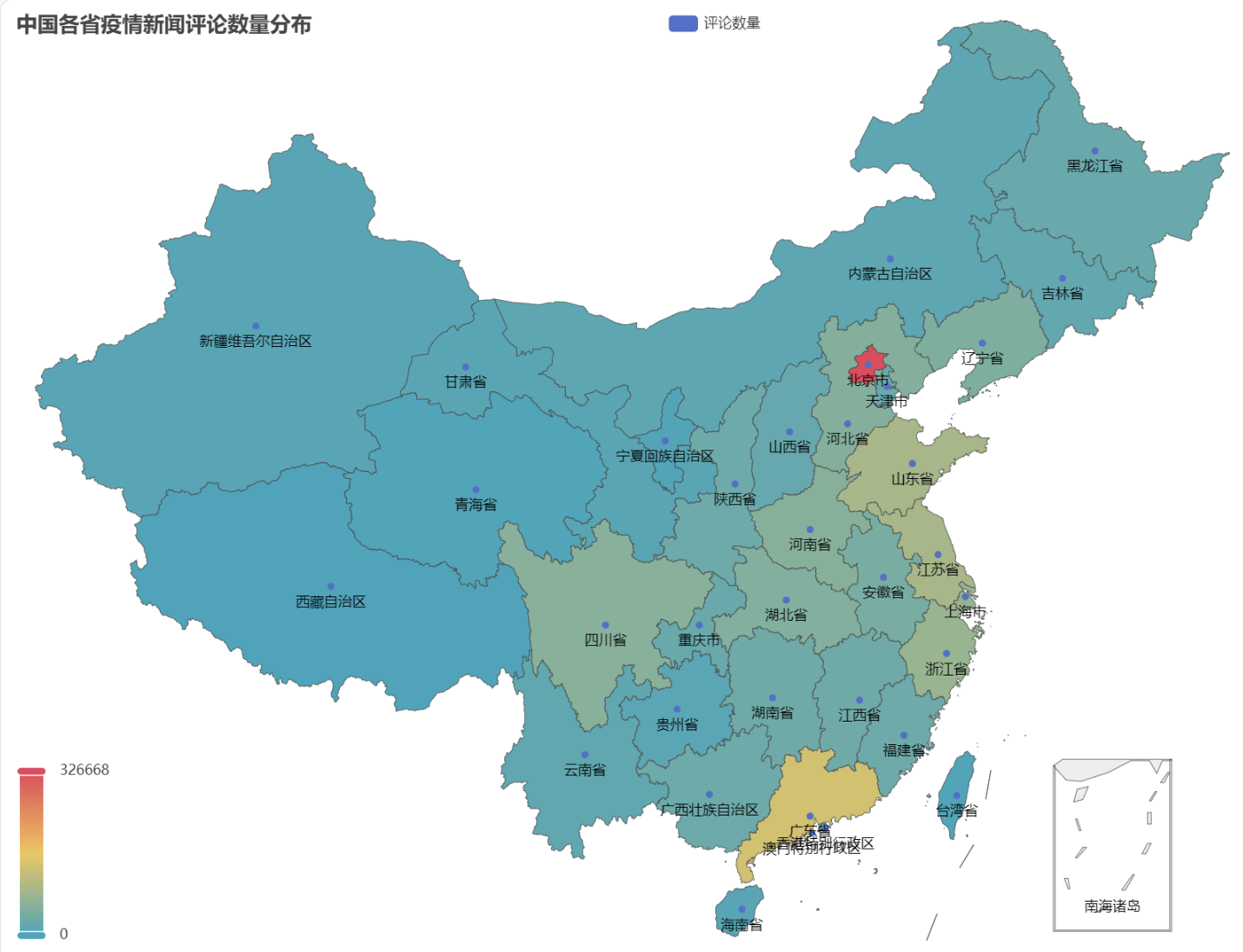
流行中、北京のコメント数が最も多く、次に広東省が続き、他の省のコメント数は比較的均等であったことがわかります。
伝染病感情分析をレビューする
この実験では、中国語テキストの処理に NLP ライブラリを使用します。 SnowNLP 、中国人感情分析を実装し、各コメントを分析し、対応するコメントを提供します。sentiment 値。値は 0 から 1 の間で、1 に近づくほど正の値となり、0 に近づくほど負の値になります。
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
この実験では、しきい値として 0.5 が使用されます。この値より大きいものは肯定的なコメントであり、この値より小さいものは否定的なコメントです。コードを記述することで、毎日のニュースのコメントのセンチメント分析グラフを描画し、毎日のニュースに対する肯定的なコメントの数と否定的なコメントの数をカウントします。肯定的なコメントの数は正の値、否定的なコメントの数は負の値になります。価値。
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
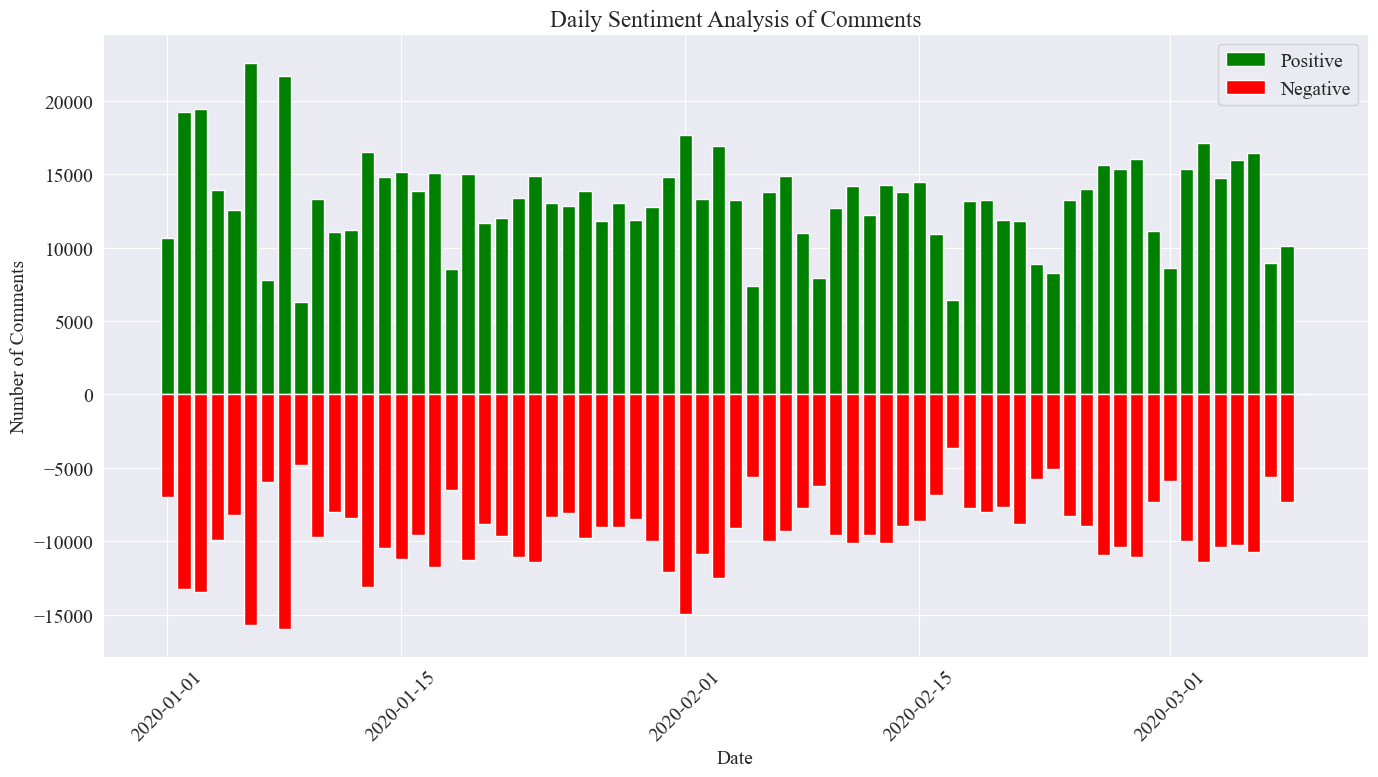
最終的な統計画像は上記のとおりで、流行中の肯定的なコメントの割合が否定的なコメントよりもわずかに高かったことがわかり、肯定的なコメントの割合が 58.63% であることがわかりました。国民が疫病に対してより前向きな態度をとったということ。
地域ごとのコメントのセンチメント分析
各省および地域ごとに投稿された肯定的なコメントの割合をカウントすることにより、各地域における肯定的なコメントの割合のグラフが得られました。
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
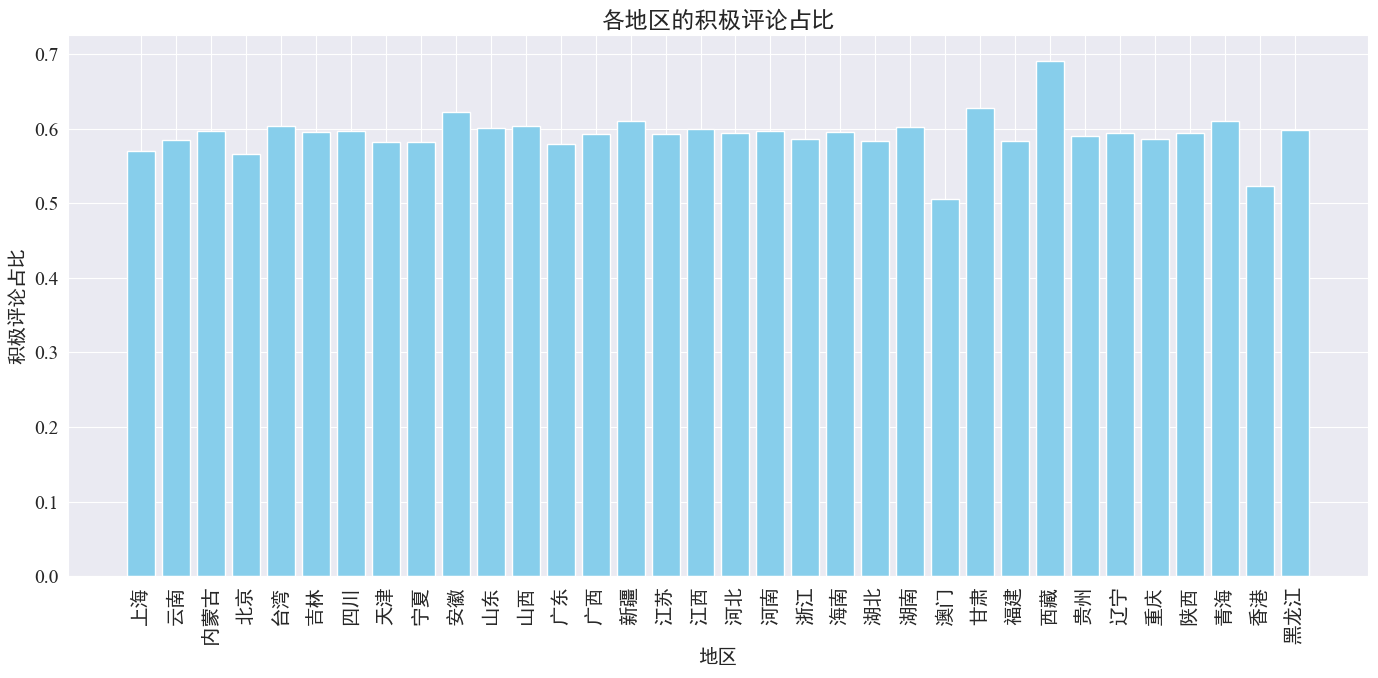
上の図からわかるように、ほとんどの省で肯定的なコメントの割合は約 60% であり、香港とマカオでは肯定的なコメントの割合が約 50% と最も低いのに対し、チベットでは肯定的なコメントの割合が最も高く、ほぼ 50% となっています。 70%。
上記のコメントの分布から、中国本土でのコメントはほとんどが肯定的なコメントであることがわかりますが、香港とマカオでの否定的なコメントが大幅に増加しているのは、チベットで最も多くの肯定的なコメントが発生したためである可能性があります。チベットのサンプルサイズは小さい。
ニュース コメント Word Cloud チャートの描画
すべてのコメントのワード クラウド図、肯定的なコメントと否定的なコメントを別々にカウントしました。ワード クラウド図では、肯定的なコメントは 0.6 より上、否定的なコメントは 0.4 より下として分類されます。描かれた図。

流行中の人々のコメントは、「笑」、「良かった」など比較的単純なものが多いことがわかります。肯定的なコメントには、「頑張れ中国」、「頑張れ武漢」などの励ましの言葉が見られます。 、などという意見もあれば、否定的なコメントの中には「ははは」「国を豊かにするのは難しい」といった批判もあります。

彼は 30 年以上テクノロジーの研究に専念しており、Java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: