2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
L'épidémie de COVID-19 affecte le cœur de chacun de nous. Dans ce cas, nous essaierons d'utiliser des méthodes d'informatique sociale pour analyser les nouvelles et les rumeurs liées à l'épidémie afin d'aider.Informations sur l'épidémie Recherche. Cette mission est une mission à durée indéterminée. Nous fournissons des données sociales pendant l'épidémie et encourageons les étudiants à analyser les tendances sociales à partir des actualités, des rumeurs et des documents juridiques. (Conseil : utilisez les méthodes apprises en cours, telles que l'analyse des sentiments, l'extraction d'informations, la compréhension en lecture, etc. pour analyser les données)
https://covid19.thunlp.org/ fournit des informations sur les données sociales liées à l'épidémie du nouveau coronavirus, y compris les rumeurs liées à l'épidémie CSDC-Rumor, les actualités chinoises liées à l'épidémie CSDC-News et les documents juridiques liés à l'épidémie CSDC-Legal.
Cette partie de l'ensemble de données collectées :
(1) À compter du 22 janvier 2020Fausses informations sur WeiboLes données comprennent le contenu des publications Weibo considérées comme de fausses informations, les éditeurs, les lanceurs d'alerte, la durée du procès, les résultats et d'autres informations. Au 1er mars 2020, il y avait un total de 324 textes originaux Weibo, 31 284 transferts et 7 912 commentaires. . , utilisé pour aider les chercheurs à analyser et étudier la propagation de fausses informations pendant l’épidémie ;
(2) Plateforme de vérification des rumeurs de Tencent et données de fausses informations de Dingxiangyuan depuis le 18 janvier 2020, y compris des informations telles que le contenu de la rumeur qui est considéré comme correct ou faux, l'heure et la base pour juger s'il s'agit d'une rumeur. Au 1er mars 2020, il existe 507 données de rumeurs, dont 124 données factuelles. La répartition des données est la suivante : cas négatifs : 420, cas positifs : 33 et incertains : 54.
Cette partie de l'ensemble de données collecte des données d'actualité à partir du 1er janvier 2020, y compris le titre, le contenu, les mots-clés et d'autres informations de l'actualité. Au 16 mars 2020, un total de 148 960 actualités et 1 653 086 commentaires correspondants ont été collectés. Utilisé pour aider les chercheurs à analyser et à étudier les données d'actualité pendant l'épidémie.
Ces données proviennent de CAIL Au total, 1 203 éléments historiques liés à l'épidémie ont été éliminés des données anonymes collectées dans les documents juridiques. Chaque élément de données comprend le titre du document, le numéro de cas et le texte intégral du document, qui peuvent être utilisés par les chercheurs pour mener des recherches. sur les questions juridiques pertinentes pendant l’épidémie.
Cette mission est une mission ouverte, nous commencerons à partir de
Notation des devoirs dans d'autres aspects.
[1] Crédibilité de l'information sur Twitter. dans Proceedings of WWW, 2011.
[2] Détection de rumeurs à partir de microblogs avec des réseaux neuronaux récurrents. dans Proceedings of IJCAI, 2016.
[3] Une approche convolutionnelle pour l'identification de la désinformation. dans Proceedings of IJCAI, 2017.
[4] La diffusion de nouvelles vraies et fausses en ligne. Science, 2018.
[5] Fausses informations sur le Web et les médias sociaux : une enquête. Préimpression arXiv, 2018.
[6] Caractérisation des normes affectives des mots anglais par catégories émotionnelles discrètes. Méthodes de recherche sur le comportement, 2007.
Cette expérience fournit l'ensemble de données sur les rumeurs liées à l'épidémie CSDC-Rumor. En analysant le contenu de l'ensemble de données, nous choisissons d'abord d'effectuer une analyse statistique quantitative sur l'ensemble de données, puis d'utiliser le clustering pour mettre en œuvre une analyse sémantique des rumeurs, et enfin de concevoir un ensemble de données. système de détection de rumeurs.
Format des données
Cette expérience fournit l'ensemble de données sur les rumeurs liées à l'épidémie CSDC-Rumor, qui collecte des données sur les fausses informations de Weibo et des données réfutant les rumeurs. L'ensemble de données contient les éléments suivants.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Fausses informations sur Weiborespectivement par rumor_weibo etrumor_forward_comment deux du même nomjson décrit dans le dossier.rumor_weibo milieujson Les champs spécifiques sont les suivants :
rumorCode: Le code unique de la rumeur, grâce auquel on peut accéder directement à la page de reporting de la rumeur.title: Le contenu du titre de la rumeur rapportée.informerName: Nom Weibo du journaliste.informerUrl: Lien Weibo du journaliste.rumormongerName: Le nom Weibo de la personne qui a publié la rumeur.rumormongerUr: Lien Weibo de la personne qui a posté la rumeur.rumorText: Contenu de la rumeur.visitTimes: Le nombre de fois que cette rumeur a été visitée.result: Les résultats de cette revue de rumeurs.publishTime: L'heure à laquelle la rumeur a été rapportée.related_url: Liens vers des preuves, des réglementations, etc. liés à cette rumeur.rumor_forward_comment milieujson Les champs spécifiques sont les suivants :
uid: Publier l'ID utilisateur.text: Commentez ou transmettez le post-scriptum.date: temps de libération.comment_or_forward: binaire, soit comment, soit forward, indiquant si le message est un commentaire ou un post-scriptum transféré.Fausses informations de Tencent et Lilac GardenLe format du contenu est :
date: tempsexplain: Type de rumeurtag:étiquette de rumeursabstract: Contenu utilisé pour vérifier les rumeursrumor: RumeurPrétraitement des données
passer json.load() Extraire séparément les données de la rumeur Weiboweibo_data Commentaires sur la transmission de données avec des rumeursforward_comment_data , puis convertissez-le au format DataFrame. Les deux fichiers du même nom, l'article Weibo et le transfert de commentaires Weibo se correspondent lors du traitement des données dans le dossier rumeur_forward_comment, ajoutez rumeurCode pour une correspondance ultérieure.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Cette section utilise une analyse statistique quantitative pour acquérir une compréhension spécifique de la distribution des données de rumeurs épidémiques sur Weibo.
Statistiques sur le nombre de fois où des rumeurs ont été consultées
statistiques weibo_df['visitTimes'] Répartition des temps d'accès et dessin de l'histogramme correspondant. Les résultats sont les suivants.
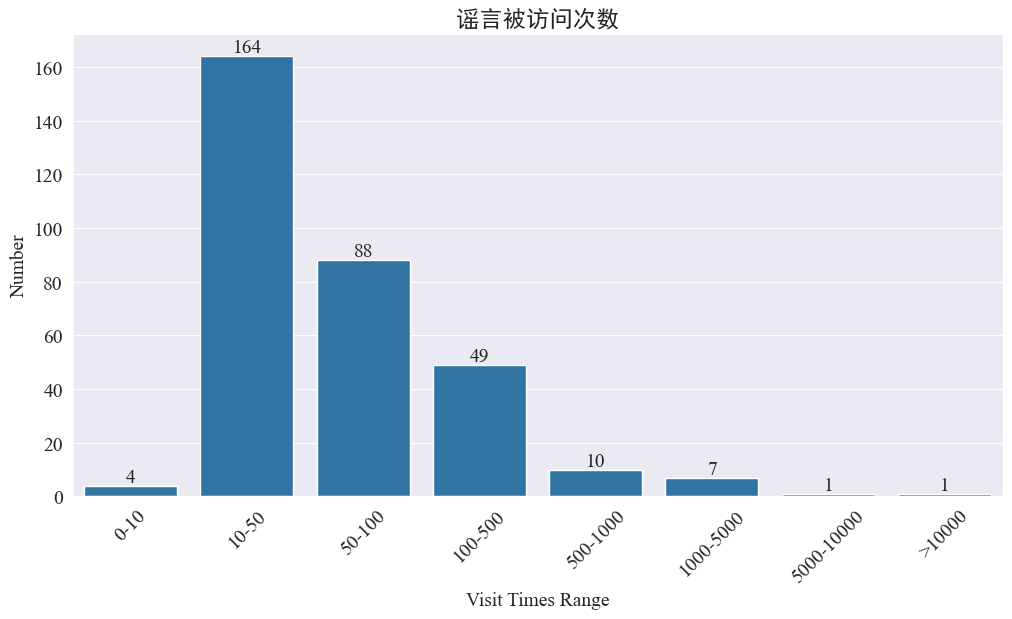
Selon le nombre de visites sur Weibo, la plupart des rumeurs épidémiques ont été visitées moins de 500 fois sur Weibo, 10 à 50 fois représentant la plus grande proportion. Cependant, il y a aussi des rumeurs sur Weibo qui ont été consultées plus de 5 000 fois, qui ont eu de graves conséquences et sont considérées comme « sérieuses » par la loi.
Statistiques sur l'occurrence des faiseurs de rumeurs et des lanceurs d'alerte
par les statistiques weibo_df['rumormongerName'] etweibo_df['informerName'] Le nombre de rumeurs publiées par chaque éditeur de rumeurs et le nombre de rumeurs rapportées par chaque journaliste sont obtenus. Les résultats sont les suivants.
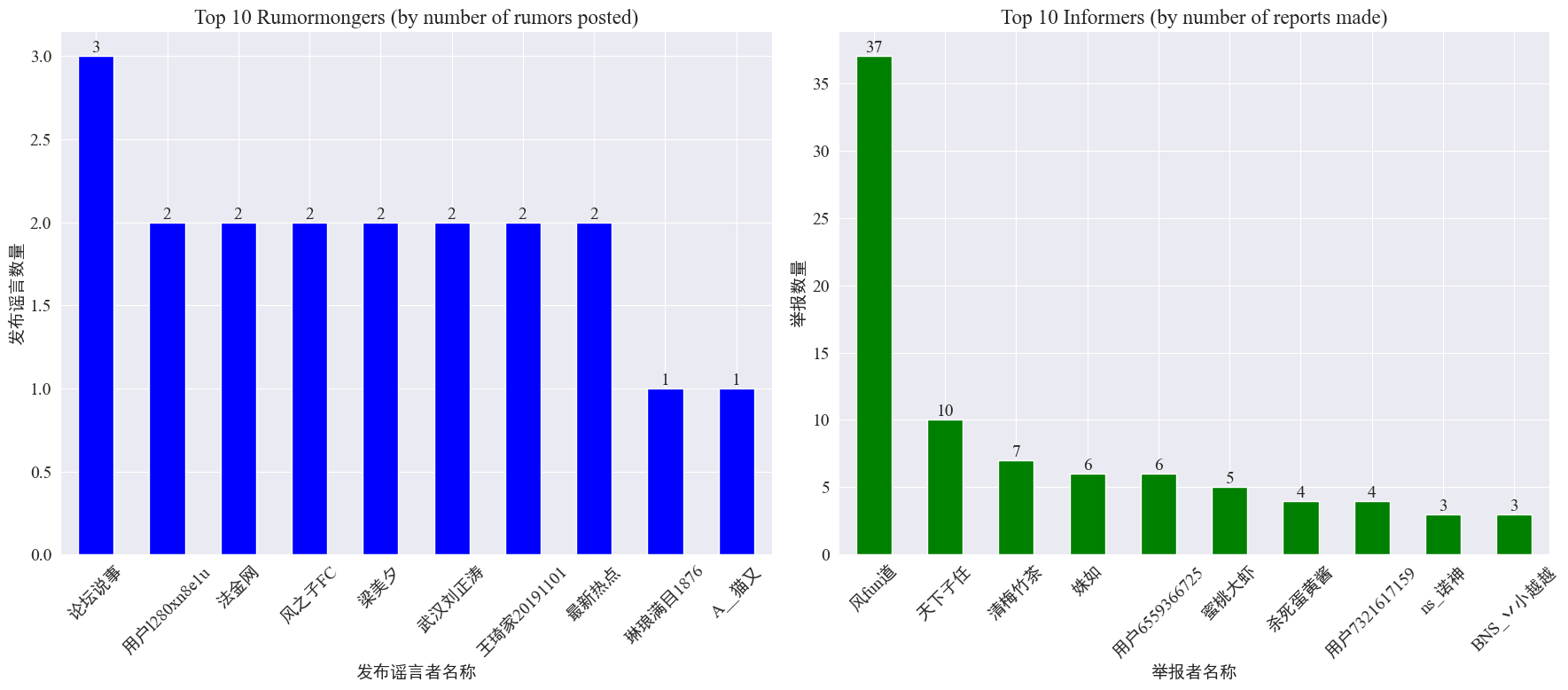
On peut voir que le nombre de rumeurs publiées par les faiseurs de rumeurs n'est pas concentré sur quelques personnes, mais est relativement uniforme. Le compte qui a publié le plus de rumeurs a publié trois messages de rumeurs sur Weibo. Chacun des 10 principaux lanceurs d'alerte a rapporté au moins 3 articles de rumeurs. Parmi eux, le nombre de rumeurs signalées par les lanceurs d'alerte sur Weibo était nettement supérieur à celui des autres utilisateurs, atteignant 37 articles.
Sur la base des données ci-dessus, le public peut se concentrer sur le reporting des comptes comportant un grand nombre de rumeurs pour faciliter la détection des rumeurs.
Statistiques de distribution des commentaires de transmission de rumeurs
En comptant la répartition du volume de transfert de rumeurs et du volume de commentaires, l'image de répartition suivante est obtenue.

On peut voir que le nombre de commentaires et de republications sur la plupart des rumeurs Weibo est inférieur à 10 fois, le nombre maximum de commentaires ne dépassant pas 500 et le nombre maximum de republications atteignant plus de 10 000. Selon la loi sur la gestion d'Internet, si une rumeur est relayée plus de 500 fois, elle est considérée comme une situation « grave ».
Analyse des clusters de textes de rumeurs
Cette partie effectue un prétraitement des données sur les textes de rumeurs Weibo et effectue une analyse de cluster après segmentation des mots pour voir où se concentrent les rumeurs Weibo.
Prétraitement des données
Tout d'abord, nettoyez le texte des données de rumeur, supprimez les valeurs par défaut et <> Le contenu du lien ci-joint.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Ensuite, chargez les mots vides chinois, et les mots vides utilisent cn_mots-clés ,utiliserjieba Implémentez le traitement de segmentation de mots des données et effectuez la vectorisation du texte.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Déterminer le meilleur regroupement
En utilisant la méthode du coude, les meilleurs clusters sont déterminés.
La méthode Elbow est une méthode utilisée pour déterminer le nombre optimal de clusters dans l’analyse cluster. Il est basé sur la relation entre la somme des erreurs quadratiques (SSE) et le nombre de clusters. SSE est la somme des carrés des distances euclidiennes entre tous les points de données du cluster et le centre du cluster auquel il appartient. Il reflète l'effet du clustering : plus le SSE est petit, meilleur est l'effet de clustering.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
La méthode du coude détermine le nombre optimal de clusters en recherchant le « coude », c'est-à-dire en recherchant un point sur la courbe après lequel le taux de diminution du SSE ralentit considérablement. Ce point est comme le coude d'un bras, d'où le. nom " Méthode du coude”. Ce point est généralement considéré comme le nombre optimal de clusters.
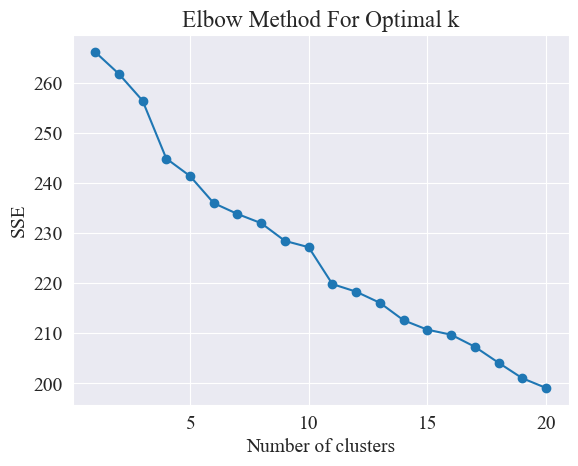
À partir de la figure ci-dessus, il est déterminé que la valeur de regroupement du coude est de 11 et le nuage de points correspondant est dessiné. Les résultats sont les suivants.
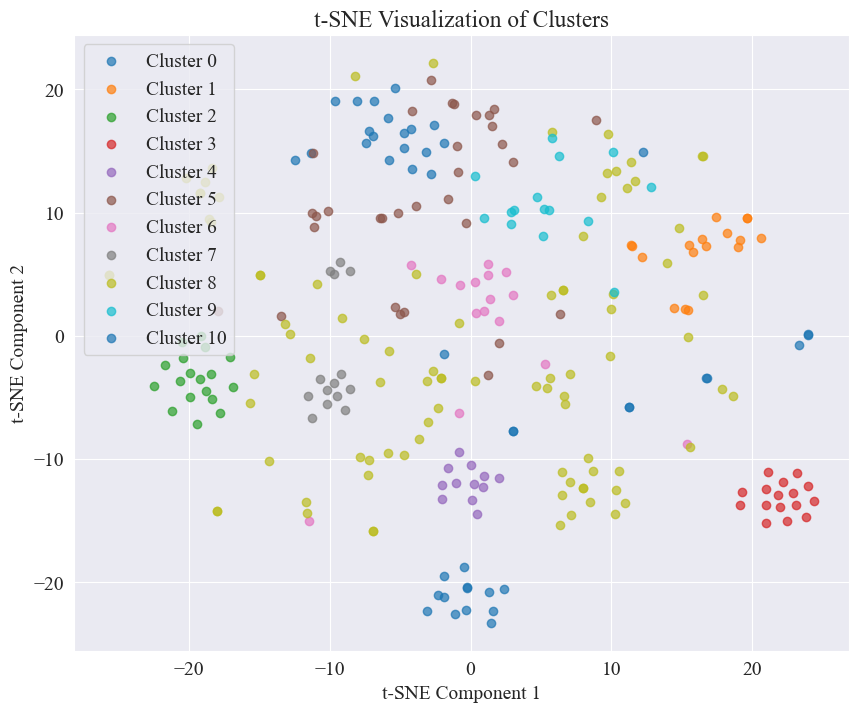
On peut voir que la plupart des messages de rumeurs sur Weibo sont bien regroupés, les n° 3 et n° 4 ; certains sont largement diffusés et mal regroupés, comme les n° 5 et n° 8 ;
Résultats de regroupement
Afin de montrer clairement quelles rumeurs sont regroupées dans chaque catégorie, un graphique nuageux est dessiné pour chaque catégorie. Les résultats sont les suivants.

Imprimez du contenu de rumeurs Weibo bien regroupé, et les résultats sont les suivants.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Analyse groupée des résultats de l'examen des rumeurs
Le regroupement du contenu textuel des rumeurs n'est peut-être pas très efficace pour l'analyse du contenu des rumeurs, nous avons donc choisi de regrouper les résultats de l'examen des rumeurs.
Déterminer le meilleur regroupement
À l’aide du tracé du coude, déterminez le meilleur regroupement.
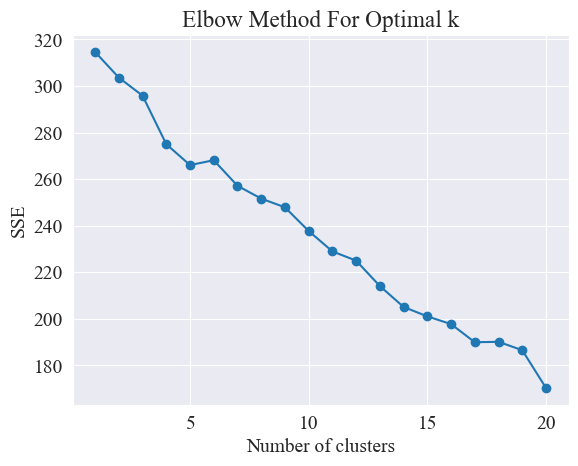
À partir du diagramme de coude ci-dessus, deux coudes peuvent être déterminés, l'un lorsque le regroupement est de 5 et l'autre lorsque le regroupement est de 20. Je choisis 20 pour le regroupement.
Le nuage de points obtenu en regroupant 20 catégories est le suivant.
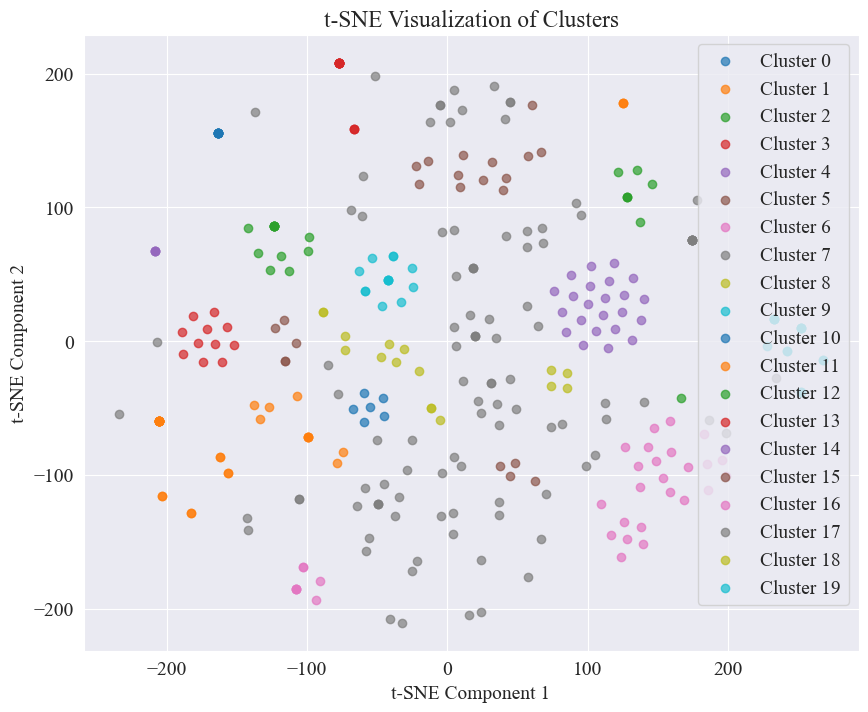
On peut voir que la plupart d'entre eux sont bien regroupés, mais les 7e et 17e catégories ne sont pas bien regroupées.
Résultats de regroupement
Afin de montrer clairement quels résultats d'examen des rumeurs sont regroupés dans chaque catégorie, un graphique nuageux est dessiné pour chaque catégorie. Les résultats sont les suivants.

Imprimez quelques résultats d'examen des rumeurs bien regroupés. Les résultats sont les suivants.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Pour cette détection de rumeurs, nous avons choisi d'utiliser des ensembles de données qui ont été réfutés. fact.json Comparez la similitude entre les rumeurs réfutées et les rumeurs réelles, et sélectionnez l'article réfuté présentant la plus grande similitude avec la rumeur Weibo comme base de détection des rumeurs.
Charger les données de rumeurs Weibo et les ensembles de données réfutant les rumeurs
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Utiliser des modèles linguistiques pré-entraînés pour encoder les rumeurs de Weibo et les titres réfutant les rumeurs dans des vecteurs d'intégration
Utilisé dans cette expérience bert-base-chinese En tant que modèle pré-entraîné, effectuez une formation de modèle. Le modèle SimCSE est utilisé pour améliorer la représentation et la mesure de similarité de la sémantique des phrases grâce à l'apprentissage contrastif.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Calculer la similarité
Pour calculer la similarité, l'incorporation de phrases et la similarité d'entité nommée du modèle SimCSE sont utilisées pour calculer la similarité globale.
extract_entitiesLa fonction extrait les entités nommées du texte à l'aide du modèle NER.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityLa fonction calcule la similarité de l'entité nommée entre deux textes.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityLa fonction combine l'intégration de phrases et la similarité d'entité nommée du modèle SimCSE pour calculer la similarité globale.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Mettre en œuvre la détection des rumeurs
En comparant les similitudes, un mécanisme de détection des rumeurs est mis en place.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
Le résultat est le suivant :
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
A trouvé avec succès la base pour réfuter les rumeurs et a rendu un jugement pour réfuter les rumeurs.
Format des données
Cette expérience fournit l'ensemble de données d'actualité liées à l'épidémie CSDC-News, qui collecte du contenu d'actualité et de commentaires au cours du premier semestre 2020. L'ensemble de données contient les éléments suivants.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
Le dossier de données est divisé en trois parties :data,comment。
data Le dossier contient plusieurs fichiers, chaque fichier correspond à des données d'une certaine date, au formatjson . Le contenu de cette partie correspond aux données texte de l'actualité (sera progressivement mis à jour avec la date), et les champs comprennent :
time: Heure du communiqué de presse.title:Le titre de la nouvelle.url: Le lien d'adresse original de la nouvelle.meta: Les informations textuelles de l'actualité, qui comprennent les champs suivants : content: Le contenu textuel de l'actualité.description: Une brève description de l'actualité.title:Le titre de la nouvelle.keyword: Mots-clés d'actualité.type: Type d'actualité.comment Le dossier contient plusieurs fichiers, chaque fichier correspond à des données d'une certaine date, au formatjson . Cette partie du contenu correspond aux données de commentaire de l'actualité (il peut y avoir un délai d'environ une semaine entre les données de commentaire et les données de texte de l'actualité).
time: Heure du communiqué de presse, et data Correspond aux données du dossier.title: Le titre de la nouvelle, avec data Correspond aux données du dossier.url: Le lien d'adresse original de l'actualité, et data Correspond aux données du dossier.comment: Informations sur les commentaires d'actualité. Ce champ est un tableau. Chaque élément du tableau contient les informations suivantes : area: Espace réviseur.content:commentaires.nickname: Surnom du critique.reply_to: L'objet de réponse du commentateur. S'il n'y en a pas, cela signifie qu'il ne s'agit pas d'une réponse.time: Heure du commentaire.Prétraitement des données
Données sur les articles de presse data Lors du prétraitement des données, il est nécessaire demeta Le contenu est publié et stocké au format DataFrame.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
Dans les données d'examen comment Lors du prétraitement des données, il est nécessaire decomment Le contenu est publié et stocké au format DataFrame.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Charger l'ensemble de données
Chargez l'ensemble de données selon la fonction de prétraitement des données ci-dessus.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Le résultat de l'impression montre que la longueur des données d'actualité : 502 550 et la longueur des données de commentaires : 1534616.
Statistiques de diffusion du temps d'information
Compter séparément news_df Le nombre d'articles de presse mensuels et le nombre d'articles de presse par heure sont représentés par des graphiques à barres et des graphiques linéaires. Les résultats sont les suivants.
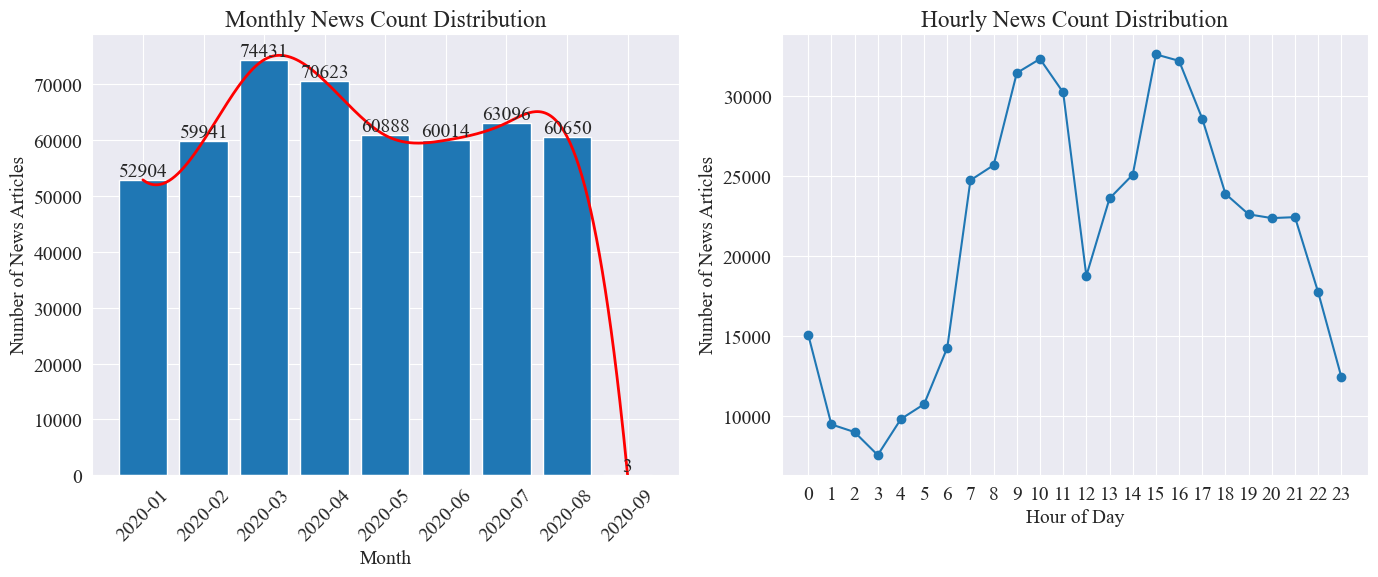
Comme le montre le graphique ci-dessus, avec l'apparition de l'épidémie, le nombre d'informations a augmenté de mois en mois, atteignant un pic en mars avec 74 000 articles de presse, puis a progressivement diminué et s'est stabilisé à 60 000 articles par mois, dont le les données en septembre étaient de 3 articles à 0h00, peuvent ne pas être incluses dans les statistiques.
Selon la répartition horaire de l'information, on peut constater que chaque jour, 10 heures et 15 heures sont les heures de pointe de diffusion de l'information, avec plus de 30 000 articles publiés chacune. 12 heures, c'est la pause déjeuner, et le nombre de communiqués de presse connaît des hauts et des bas. Le nombre de communiqués de presse est le plus petit entre 0h00 et 17h00 chaque jour, 3h00 étant le point le plus petit.
Suivi des points chauds de l'actualité
Cette expérience vise à utiliser la méthode d'extraction de mots-clés d'actualité pour suivre les points chauds de l'actualité au cours de ces huit mois. En comptant la répartition des mots-clés existants et en traçant un histogramme, les résultats sont les suivants.
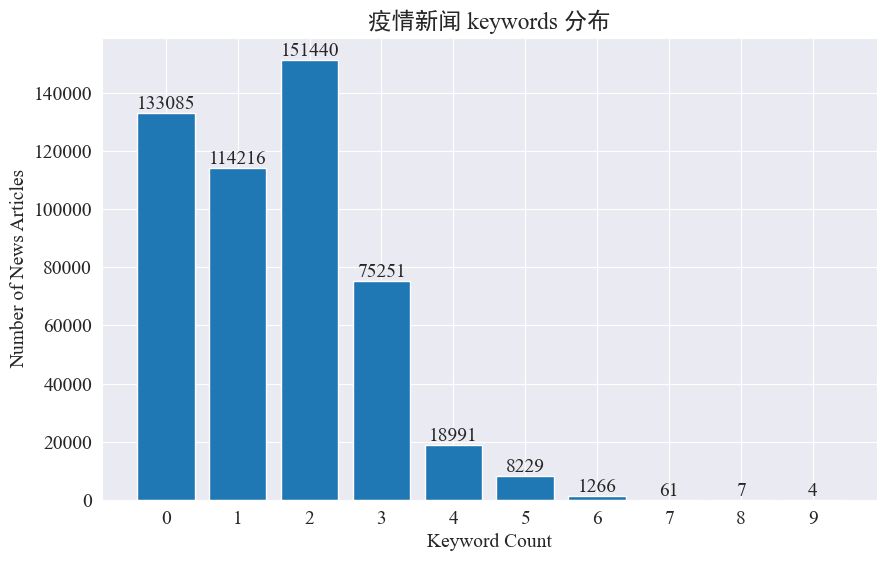
On constate que la plupart des articles d’actualité contiennent moins de 3 mots-clés, et qu’une grande proportion d’articles n’ont même aucun mot-clé. Par conséquent, vous devez collecter des statistiques et résumer vous-même les mots-clés pour le suivi des hotspots.Cette fois, utilisezjieba.analyse.textrank() pour compter les mots-clés.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Comptez 5 nouveaux mots-clés, enregistrez-les dans keyword_new, puis fusionnez les mots-clés avec eux et supprimez les mots en double.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Imprimer après la fusion keyword_data , les résultats imprimés sont les suivants.
Afin de suivre les points chauds, comptez la fréquence des mots de tous les mots apparaissant et comptez keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Ensuite, sur la base des données statistiques ci-dessus, dessinez un graphique de changement quotidien des mots chauds.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Enfin, un graphique GIF des changements dans les mots-clés dans l’actualité épidémique a été obtenu. Les résultats sont les suivants.
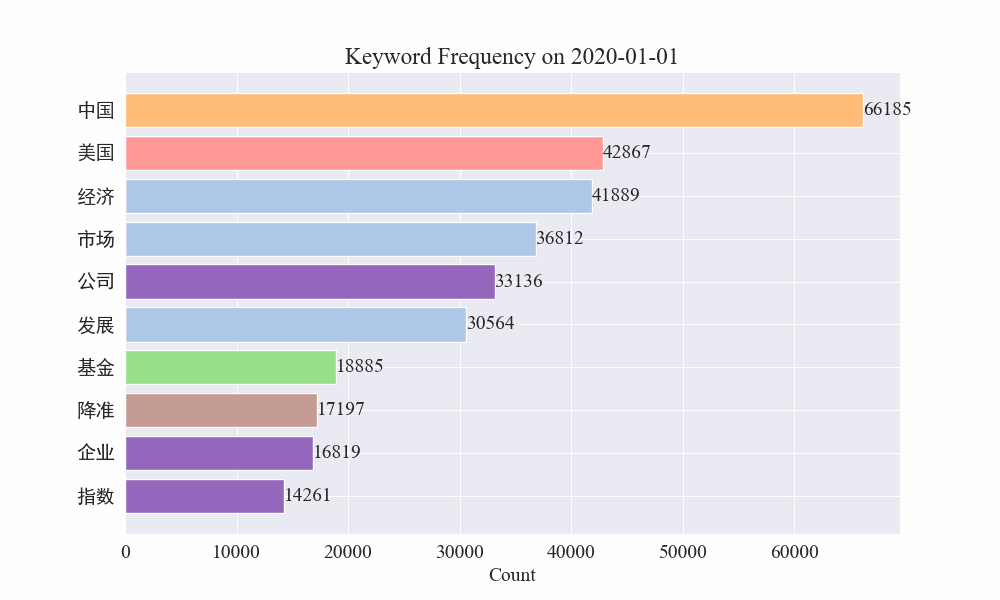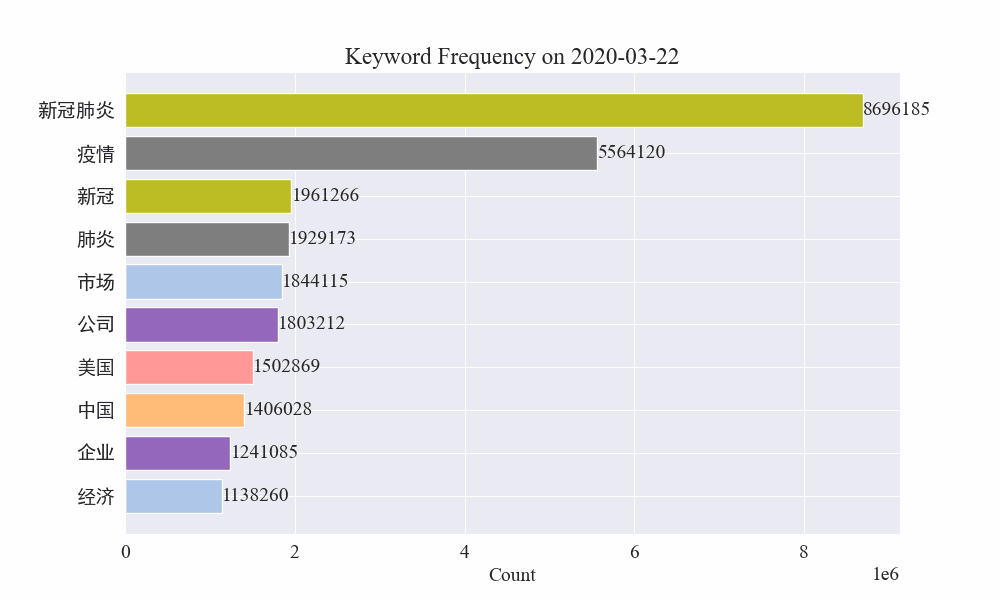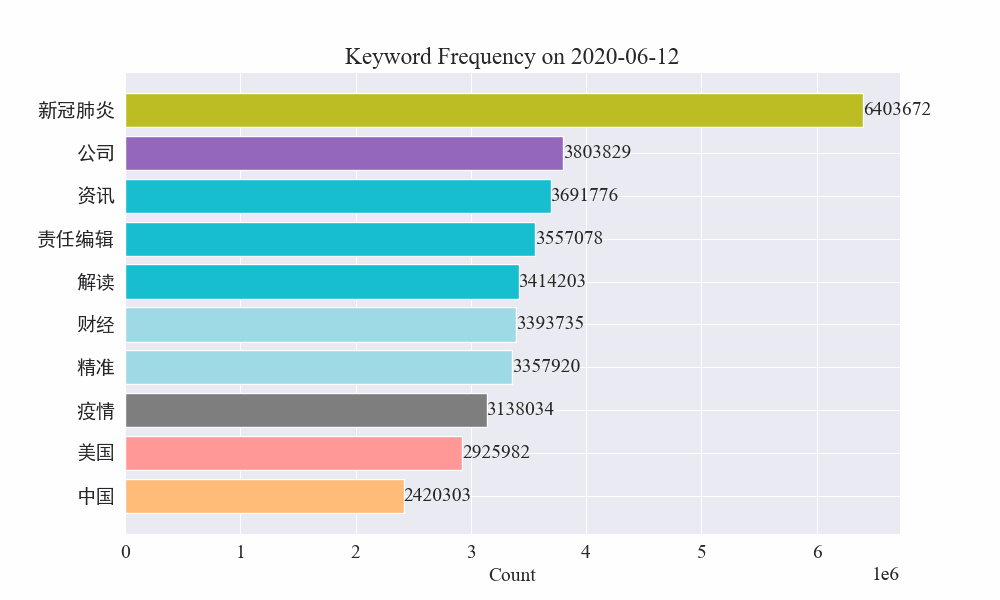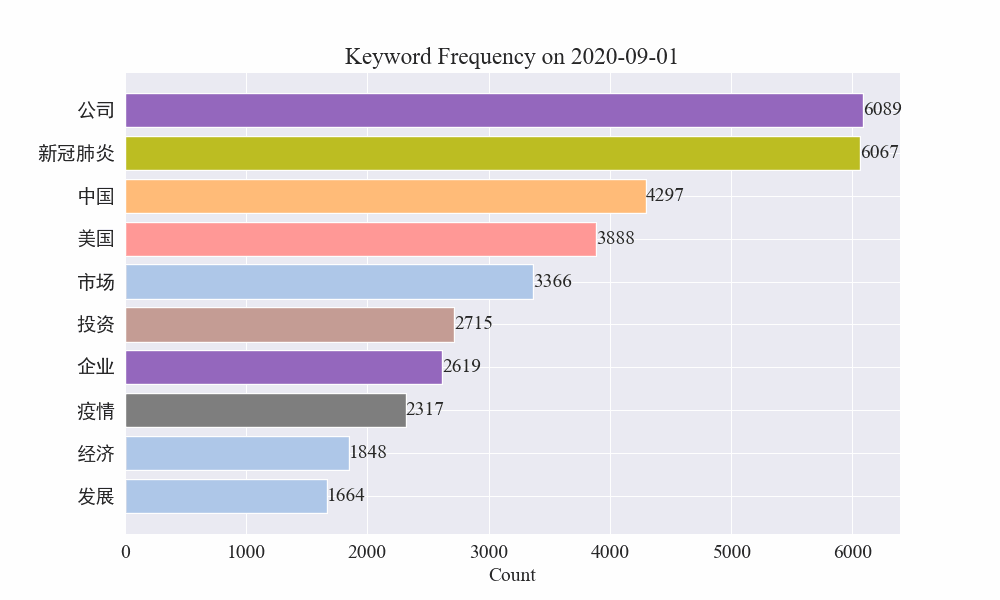
Avant l’épidémie, les termes « entreprise » et « Iran » restaient fréquents. On peut voir qu'après le déclenchement de l'épidémie, le nombre de nouvelles liées à l'épidémie a commencé à augmenter en février. Après cela, les termes « nouveau coronavirus » ont augmenté et ont continué à rester à la première place jusqu'à la fin août. la première vague de l'épidémie a ralenti et est devenue la deuxième.
Cette section effectue d'abord une analyse statistique quantitative sur les commentaires d'actualité, puis effectue une analyse des sentiments sur différents commentaires.
Statistiques quotidiennes du nombre de commentaires sur l'actualité
Comptez la tendance du nombre de commentaires d'actualité, utilisez un graphique à barres pour la représenter et tracez une courbe approximative. Le code est le suivant.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Le graphique statistique du nombre de commentaires quotidiens sur l’actualité est établi comme suit.
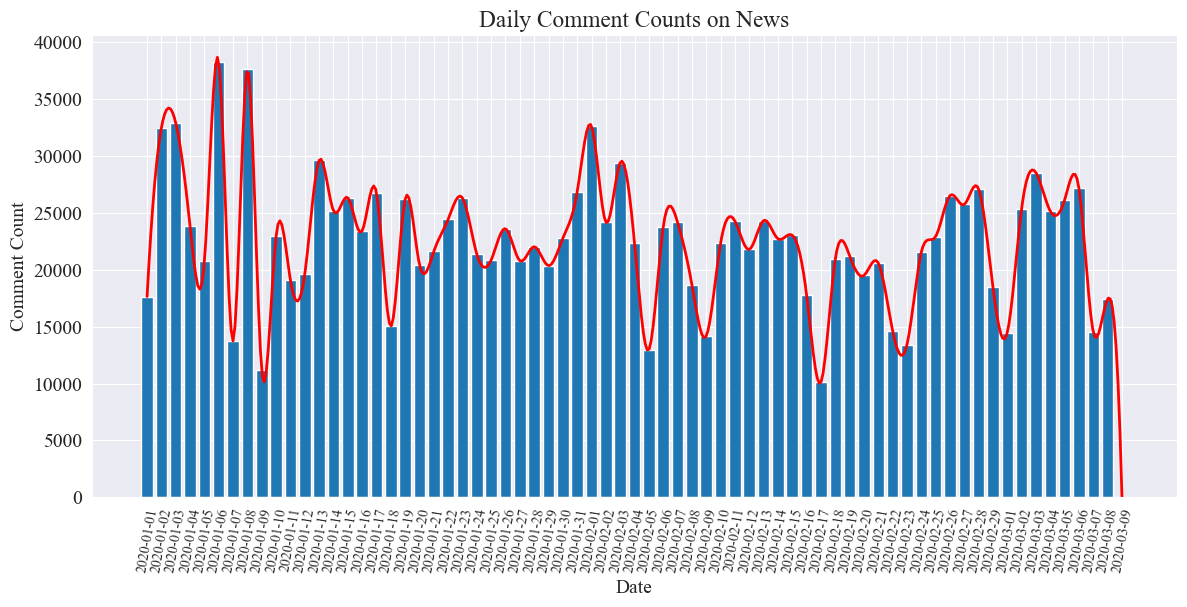
On constate que le nombre de commentaires d'actualités pendant l'épidémie a fluctué entre 10 000 et 40 000, avec une moyenne d'environ 20 000 commentaires par jour.
Statistiques de l'actualité épidémique par région
par province comment_df['province'] Comptez le nombre de nouvelles dans chaque province et comptez le nombre de commentaires sur l'actualité épidémique dans chaque province.
Tout d'abord, vous devez passer le comment_df['province'] Extrayez les informations sur la province.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Ensuite, sur la base des données statistiques, un diagramme circulaire est dessiné montrant la proportion de commentaires sur l'actualité dans chaque province.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

Dans cette expérience, nous avons également utilisé pyecharts.charts deMap Composant qui trace la répartition du nombre de commentaires sur la carte de la Chine par province.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
Dans le code HTML obtenu, la répartition du nombre de commentaires sur l'actualité épidémique dans chaque province de Chine est la suivante.
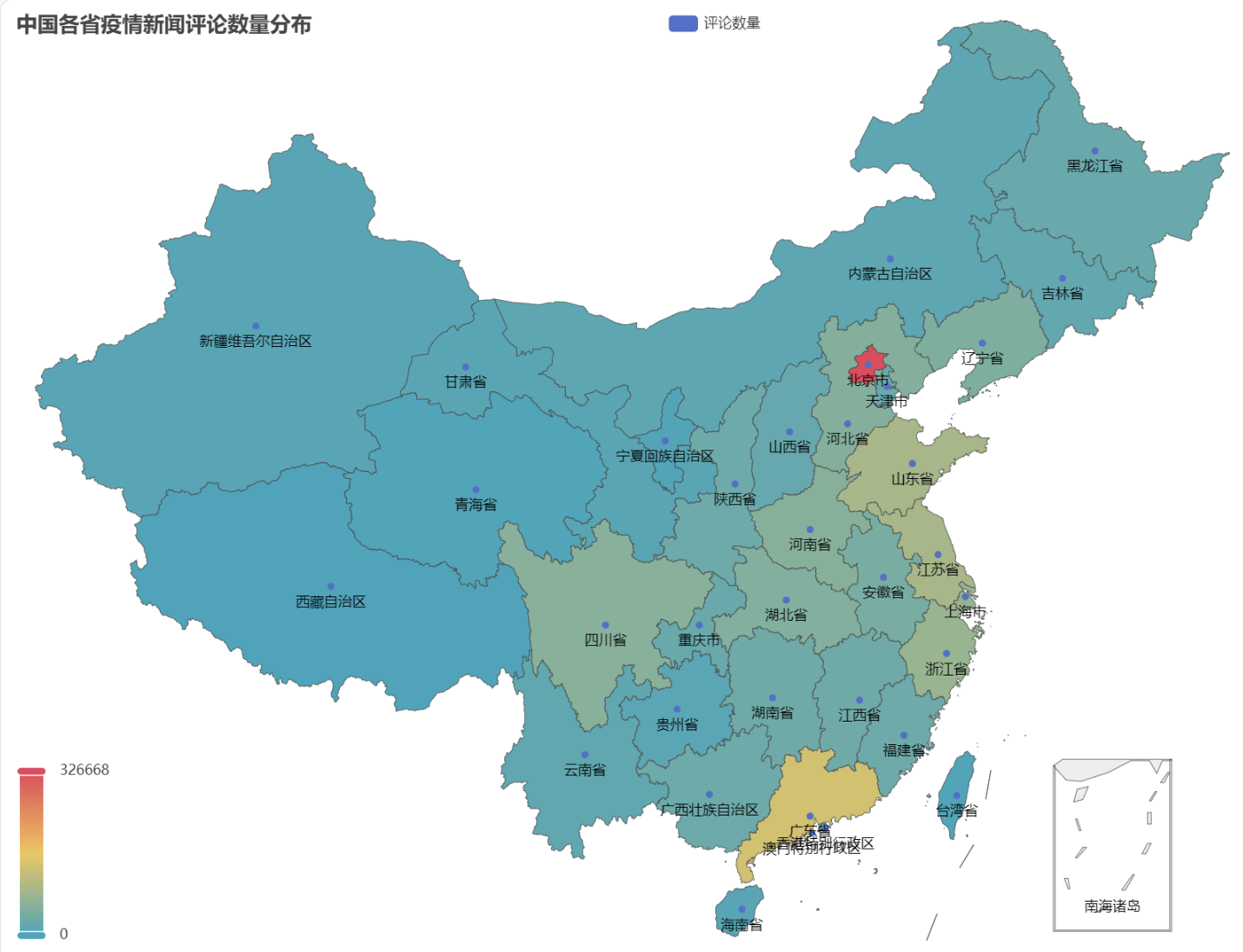
On peut voir que pendant l'épidémie, le nombre de commentaires à Pékin représentait la proportion la plus élevée, suivi par la province du Guangdong, et le nombre de commentaires dans les autres provinces était relativement égal.
épidémieExaminer l'analyse des sentiments
Cette expérience utilise la bibliothèque NLP pour traiter le texte chinois SnowNLP , mettre en œuvre une analyse des sentiments chinois, analyser chaque commentaire et donner le correspondantsentiment Valeur, la valeur est comprise entre 0 et 1, plus elle est proche de 1, plus elle est positive, plus elle est proche de 0, plus elle est négative.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
Dans cette expérience, 0,5 est utilisé comme seuil. Toute valeur supérieure à cette valeur est un commentaire positif, et toute valeur inférieure à cette valeur est un commentaire négatif. En écrivant du code, dessinez un graphique d'analyse des sentiments des commentaires d'actualité quotidiens et comptez le nombre de commentaires positifs et le nombre de commentaires négatifs sur l'actualité quotidienne. Le nombre de commentaires positifs est une valeur positive et le nombre de commentaires négatifs est une valeur négative. valeur.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
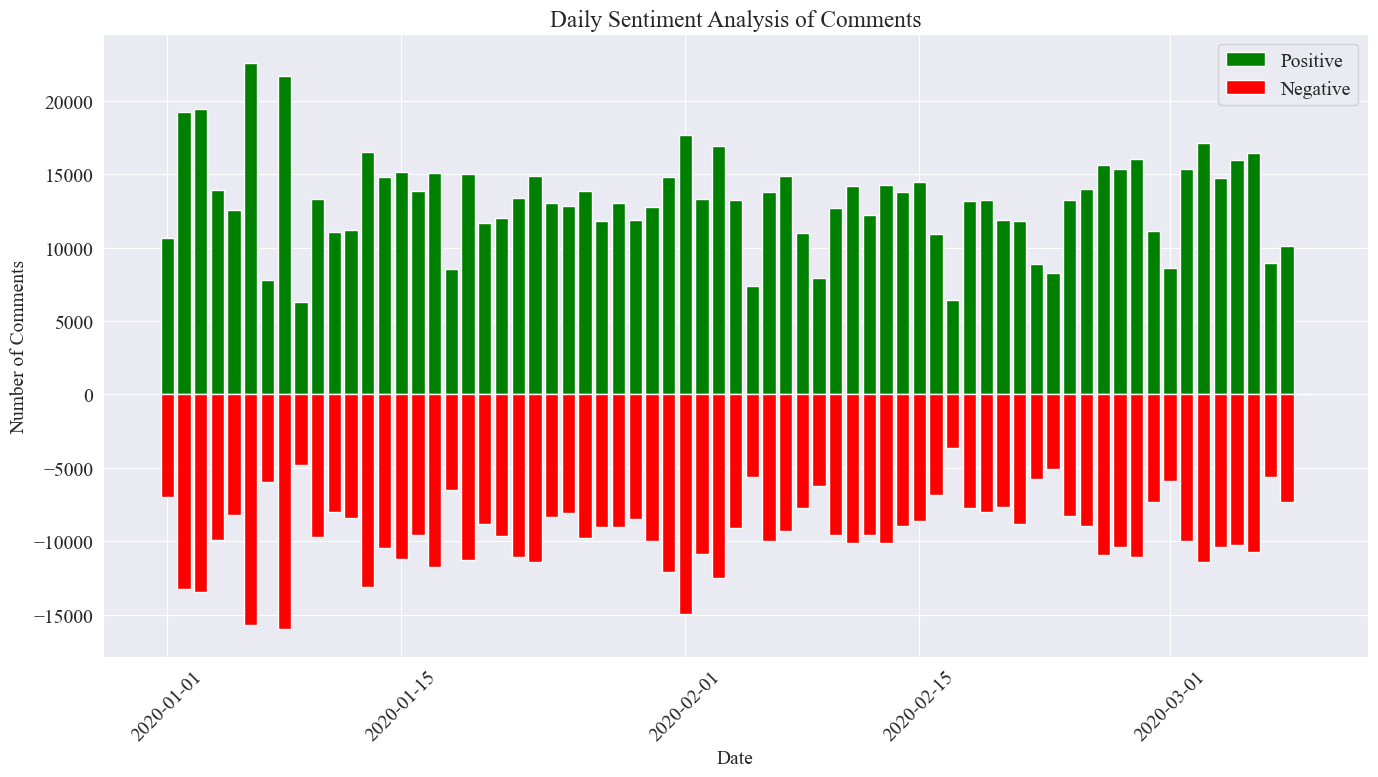
L'image statistique finale est celle présentée ci-dessus. On peut voir que les commentaires positifs pendant l'épidémie étaient légèrement supérieurs aux commentaires négatifs. En comptant la proportion de commentaires positifs, il a été constaté que la proportion de commentaires positifs était de 58,63 %, ce qui indique. que le public avait une attitude plus positive à l’égard de l’épidémie.
Analyse du sentiment des commentaires par région
En comptant la proportion de commentaires positifs affichés dans chaque province et région, un graphique de la proportion de commentaires positifs dans chaque région a été obtenu.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
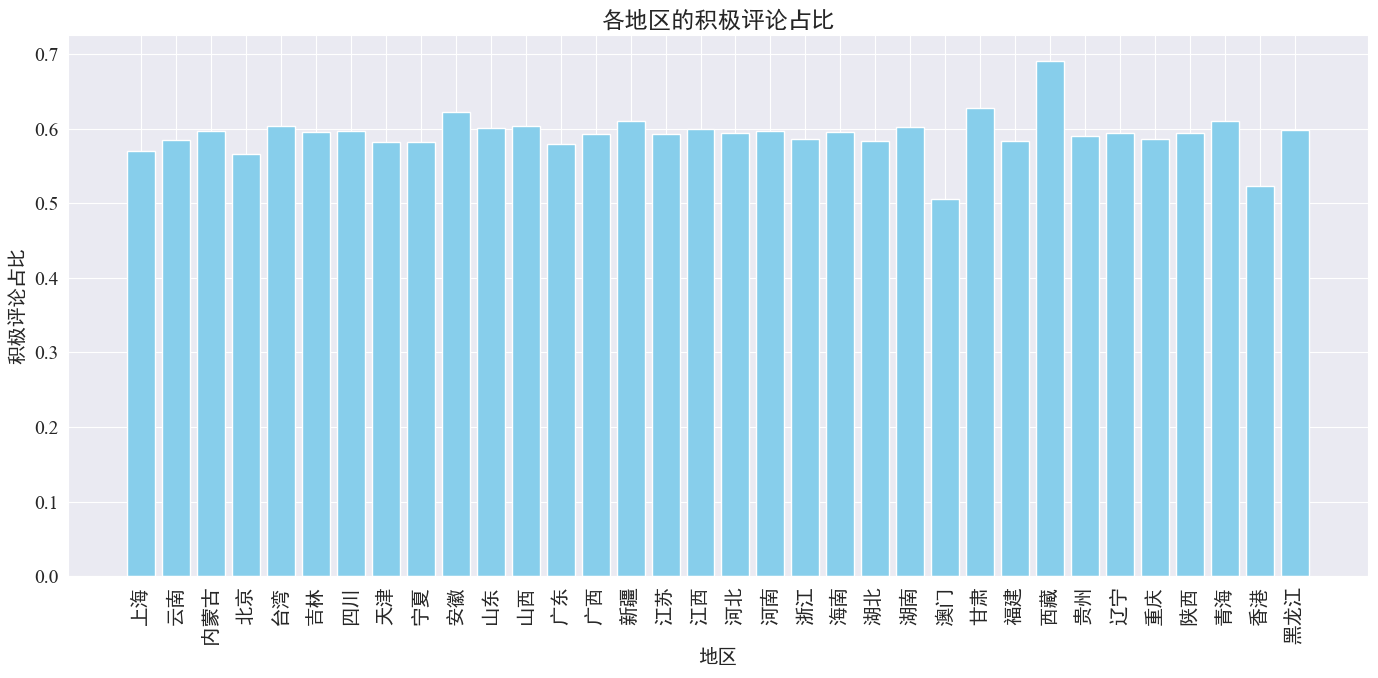
Comme le montre le graphique ci-dessus, la proportion de commentaires positifs dans la plupart des provinces est d'environ 60 %. Hong Kong et Macao ont la plus faible proportion de commentaires positifs, environ 50 %, tandis que le Tibet a la plus forte proportion de commentaires positifs, proche de 70%.
D'après la répartition des commentaires ci-dessus, nous pouvons voir que les commentaires en Chine continentale sont pour la plupart des commentaires positifs, tandis que les commentaires négatifs à Hong Kong et à Macao ont considérablement augmenté. Le plus grand nombre de commentaires positifs au Tibet peut être dû à l'erreur causée par. la petite taille de l’échantillon au Tibet.
Actualités Commentaires Word Cloud Chart Dessin
Les diagrammes de nuages de mots de tous les commentaires, commentaires positifs et commentaires négatifs ont été comptés séparément dans le dessin du diagramme de nuages de mots, les commentaires positifs ont été classés au-dessus de 0,6 et les commentaires négatifs ont été classés en dessous de 0,4. schémas dessinés.

On peut voir que la plupart des commentaires des gens pendant l'épidémie sont relativement simples, comme « haha », « bien », etc. Dans les commentaires positifs, vous pouvez voir des mots encourageants tels que « Allez la Chine », « Allez Wuhan ». , etc., tandis que dans les commentaires négatifs il y a des critiques telles que "Haha" et "Il est difficile de rendre un pays riche".

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.
