τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Η επιδημία του COVID-19 επηρεάζει τις καρδιές του καθενός από εμάς, σε αυτήν την περίπτωση, θα προσπαθήσουμε να χρησιμοποιήσουμε μεθόδους κοινωνικής πληροφορικής για να αναλύσουμε ειδήσεις και φήμες που σχετίζονται με την επιδημία για να βοηθήσουμε.Πληροφορίες για την επιδημία Ερευνα. Αυτή η εργασία είναι μια εργασία ανοιχτού τύπου Παρέχουμε κοινωνικά δεδομένα κατά τη διάρκεια της επιδημίας και ενθαρρύνουμε τους μαθητές να αναλύσουν τις κοινωνικές τάσεις από ειδήσεις, φήμες και νομικά έγγραφα. (Συμβουλή: Χρησιμοποιήστε τις μεθόδους που μαθαίνετε στην τάξη, όπως ανάλυση συναισθήματος, εξαγωγή πληροφοριών, κατανόηση ανάγνωσης κ.λπ. για την ανάλυση δεδομένων)
Το https://covid19.thunlp.org/ παρέχει πληροφορίες κοινωνικών δεδομένων που σχετίζονται με τη νέα επιδημία του κορωνοϊού, συμπεριλαμβανομένων φημών που σχετίζονται με επιδημία CSDC-Rumor, κινεζικών ειδήσεων CSDC-News που σχετίζονται με επιδημίες και νομικών εγγράφων CSDC-Legal που σχετίζονται με επιδημία.
Αυτό το μέρος του συνόλου δεδομένων συλλέχτηκε:
(1) Από τις 22 Ιανουαρίου 2020Ψεύτικες πληροφορίες WeiboΤα δεδομένα περιλαμβάνουν το περιεχόμενο των αναρτήσεων του Weibo που θεωρούνται ψευδείς πληροφορίες, τους εκδότες, τους καταγγέλλοντες, τον χρόνο δοκιμής, τα αποτελέσματα και άλλες πληροφορίες Από την 1η Μαρτίου 2020, υπάρχουν συνολικά 324 πρωτότυπα κείμενα στο Weibo, 31.284 προωθήσεις και 7.912 σχόλια. , χρησιμοποιείται για να βοηθήσει τους ερευνητές να αναλύσουν και να μελετήσουν τη διάδοση ψευδών πληροφοριών κατά τη διάρκεια της επιδημίας.
(2) Η πλατφόρμα επαλήθευσης φημών της Tencent και τα δεδομένα ψευδών πληροφοριών της Dingxiangyuan από τις 18 Ιανουαρίου 2020, συμπεριλαμβανομένου του περιεχομένου της φήμης που θεωρείται σωστή ή ψευδής, του χρόνου και της βάσης που χρησιμοποιείται για να κριθεί εάν πρόκειται για φήμη κ.λπ. Από την 1η Μαρτίου 2020, υπάρχουν 507 στοιχεία φημών, συμπεριλαμβανομένων 124 γεγονότων Η κατανομή των δεδομένων είναι: αρνητικές περιπτώσεις: 420, θετικές περιπτώσεις: 33 και αβέβαιες: 54.
Αυτό το τμήμα του συνόλου δεδομένων συλλέγει δεδομένα ειδήσεων από την 1η Ιανουαρίου 2020, συμπεριλαμβανομένων του τίτλου, του περιεχομένου, των λέξεων-κλειδιών και άλλων πληροφοριών των ειδήσεων Στις 16 Μαρτίου 2020, συγκεντρώθηκαν συνολικά 148.960 ειδήσεις και 1.653.086 αντίστοιχα σχόλια. Χρησιμοποιείται για να βοηθήσει τους ερευνητές να αναλύσουν και να μελετήσουν δεδομένα ειδήσεων κατά τη διάρκεια της επιδημίας.
Αυτά τα δεδομένα προέρχονται από CAIL Συνολικά 1.203 κομμάτια ιστορικών τμημάτων που σχετίζονται με επιδημίες εξετάστηκαν από τα συλλεγμένα ανώνυμα νομικά δεδομένα. για σχετικά νομικά ζητήματα κατά τη διάρκεια της επιδημίας.
Αυτή η εργασία είναι μια ανοιχτή εργασία, θα ξεκινήσουμε από
Βαθμολόγηση εργασιών σε άλλες πτυχές.
[1] Αξιοπιστία πληροφοριών στο twitter. στο Proceedings of WWW, 2011.
[2] Ανίχνευση φημών από μικρομπλογκ με επαναλαμβανόμενα νευρωνικά δίκτυα. στο Proceedings of IJCAI, 2016.
[3] Μια συνεκτική προσέγγιση για τον εντοπισμό παραπληροφόρησης. στο Proceedings of IJCAI, 2017.
[4] Η διάδοση αληθινών και ψευδών ειδήσεων στο διαδίκτυο. Επιστήμη, 2018.
[5] Ψεύτικες πληροφορίες στον ιστό και τα μέσα κοινωνικής δικτύωσης: Μια έρευνα. arXiv προεκτύπωση, 2018.
[6] Χαρακτηρισμός των συναισθηματικών κανόνων για αγγλικές λέξεις από διακριτές συναισθηματικές κατηγορίες. Μέθοδοι Έρευνας Συμπεριφοράς, 2007.
Αυτό το πείραμα παρέχει το σύνολο δεδομένων φημών που σχετίζονται με την επιδημία CSDC-Rumor Αναλύοντας το περιεχόμενο του συνόλου δεδομένων, επιλέγουμε να εκτελέσουμε πρώτα ποσοτική στατιστική ανάλυση στο σύνολο δεδομένων, στη συνέχεια να χρησιμοποιήσουμε ομαδοποίηση για την εφαρμογή σημασιολογικής ανάλυσης φημών και, τέλος, να σχεδιάσουμε ένα σύνολο δεδομένων. σύστημα ανίχνευσης φημών.
Μορφή δεδομένων
Αυτό το πείραμα παρέχει το σύνολο δεδομένων φημών που σχετίζονται με την επιδημία CSDC-Rumor, το οποίο συλλέγει δεδομένα ψευδών πληροφοριών του Weibo και δεδομένα διάψευσης φημών. Το σύνολο δεδομένων περιέχει τα ακόλουθα.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Ψεύτικες πληροφορίες Weiboαντίστοιχα από rumor_weibo καιrumor_forward_comment δύο με το ίδιο όνομαjson περιγράφεται στο αρχείο.rumor_weibo Μέσηςjson Τα συγκεκριμένα πεδία είναι τα εξής:
rumorCode: Ο μοναδικός κωδικός της φήμης, μέσω του οποίου είναι δυνατή η άμεση πρόσβαση στη σελίδα αναφοράς φημών.title: Το περιεχόμενο τίτλου της αναφερόμενης φήμης.informerName: Weibo όνομα του ρεπόρτερ.informerUrl: Σύνδεσμος του δημοσιογράφου στο Weibo.rumormongerName: Το όνομα Weibo του ατόμου που δημοσίευσε τη φήμη.rumormongerUr: Σύνδεσμος Weibo του ατόμου που δημοσίευσε τη φήμη.rumorText: Περιεχόμενο φημών.visitTimes: Πόσες φορές επισκέφθηκε αυτή τη φήμη.result: Τα αποτελέσματα αυτής της ανασκόπησης φημών.publishTime: Η ώρα που αναφέρθηκε η φήμη.related_url: Σύνδεσμοι με στοιχεία, κανονισμούς κ.λπ. που σχετίζονται με αυτή τη φήμη.rumor_forward_comment Μέσηςjson Τα συγκεκριμένα πεδία είναι τα εξής:
uid: Δημοσίευση αναγνωριστικού χρήστη.text: Σχολιάστε ή προωθήστε το υστερόγραφο.date: χρόνος απελευθέρωσης.comment_or_forward: δυαδικό, είτε comment, είτε forward, υποδεικνύοντας εάν το μήνυμα είναι σχόλιο ή προωθημένο υστερόγραφο.Ψεύτικες πληροφορίες Tencent και Lilac GardenΗ μορφή περιεχομένου είναι:
date: χρόνοςexplain: Τύπος φήμηςtagΕτικέτα: φήμεςabstract: Περιεχόμενο που χρησιμοποιείται για την επαλήθευση φημώνrumor: ΦήμεςΠροεπεξεργασία δεδομένων
πέρασμα json.load() Εξαγάγετε τα δεδομένα του Weibo για φήμες ξεχωριστάweibo_data Στοιχεία προώθησης σχολίων με φήμεςforward_comment_data και, στη συνέχεια, μετατρέψτε το σε μορφή DataFrame. Τα δύο αρχεία με το ίδιο όνομα, άρθρο Weibo και προώθηση σχολίων Weibo αντιστοιχούν μεταξύ τους Κατά την επεξεργασία των δεδομένων στο φάκελο rumor_forward_comment, προσθέστε rumorCode για μεταγενέστερη αντιστοίχιση.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Αυτή η ενότητα χρησιμοποιεί ποσοτική στατιστική ανάλυση για να αποκτήσει μια συγκεκριμένη κατανόηση της κατανομής των δεδομένων του Weibo για τις επιδημικές φήμες.
Στατιστικά στοιχεία σχετικά με τον αριθμό των φορών που επισκέφθηκαν φήμες
στατιστική weibo_df['visitTimes'] Κατανομή των χρόνων πρόσβασης και σχεδίαση του αντίστοιχου ιστογράμματος Τα αποτελέσματα είναι τα εξής.
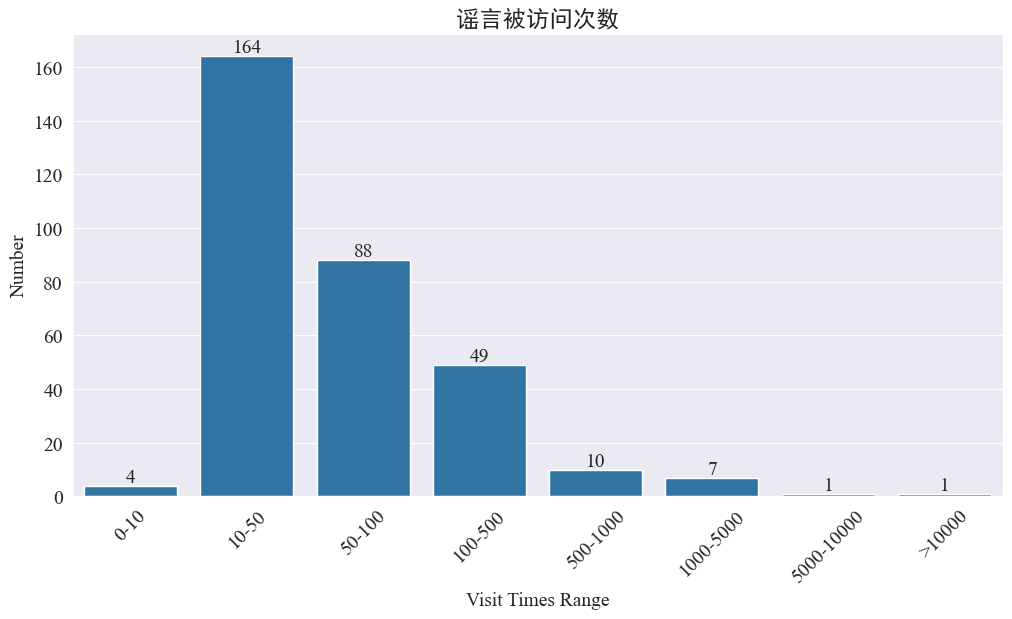
Σύμφωνα με τον αριθμό των επισκέψεων στο Weibo, οι περισσότερες φήμες για επιδημίες έχουν επισκέψει λιγότερες από 500 φορές στο Weibo, με 10-50 να αντιπροσωπεύουν το μεγαλύτερο ποσοστό. Ωστόσο, υπάρχουν και φήμες στο Weibo που έχουν προσπελαστεί περισσότερες από 5.000 φορές, οι οποίες έχουν προκαλέσει σοβαρό αντίκτυπο και θεωρούνται «σοβαρές» από το νόμο.
Στατιστικά στοιχεία για την εμφάνιση φήμων και καταγγελιών
από στατιστικές weibo_df['rumormongerName'] καιweibo_df['informerName'] Ο αριθμός των φημών που δημοσιεύονται από κάθε εκδότη φημών και ο αριθμός των φημών που αναφέρονται από κάθε ρεπόρτερ προκύπτουν ως εξής.
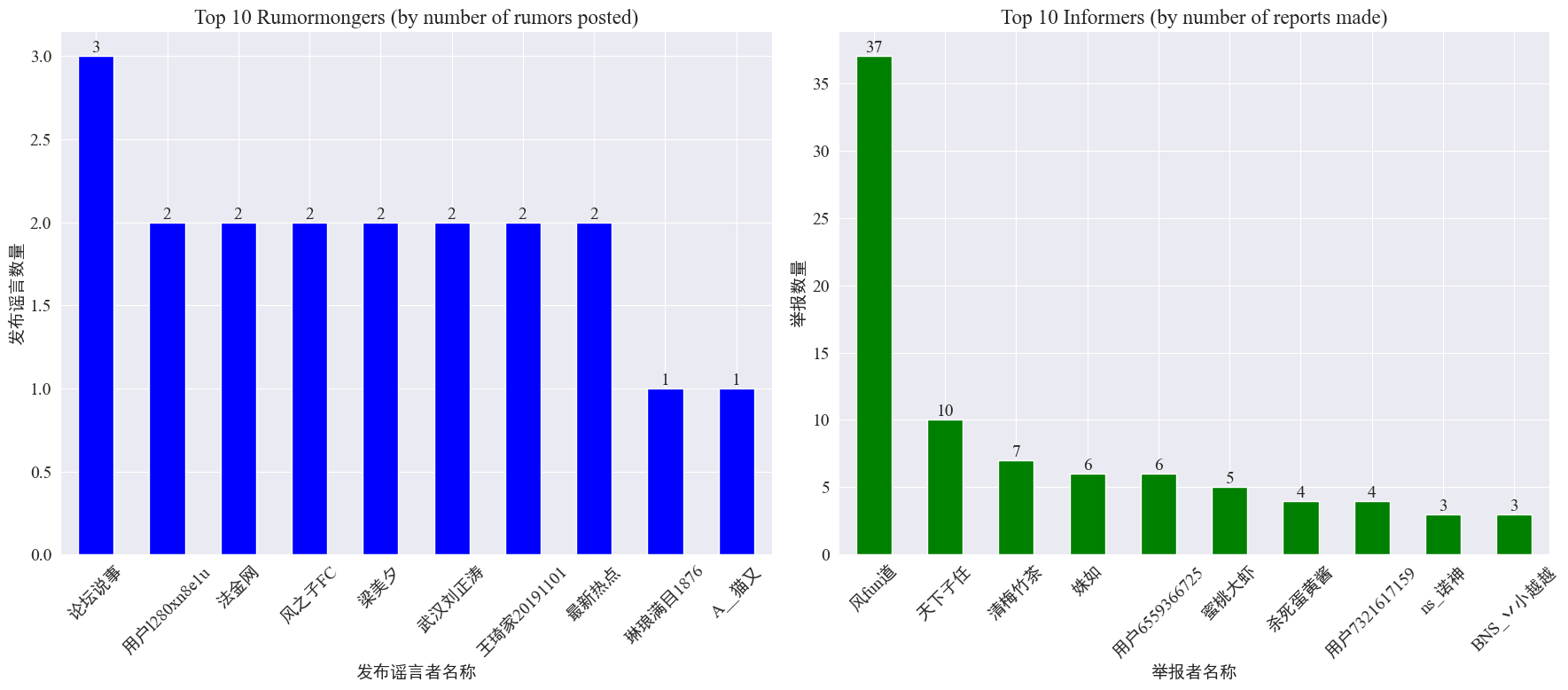
Μπορεί να φανεί ότι ο αριθμός των φημών που δημοσιεύονται από τους κατασκευαστές φημών δεν συγκεντρώνεται σε λίγα άτομα, αλλά είναι σχετικά ομοιόμορφος. Καθένας από τους 10 κορυφαίους πληροφοριοδότες ανέφερε τουλάχιστον 3 φήμες Μεταξύ αυτών, ο αριθμός των φημών που αναφέρθηκαν από τους καταγγέλλοντες στο Weibo ήταν σημαντικά υψηλότερος από αυτόν των άλλων χρηστών, φτάνοντας τα 37 άρθρα.
Με βάση τα παραπάνω δεδομένα, το κοινό μπορεί να επικεντρωθεί στην αναφορά λογαριασμών με μεγάλο αριθμό φημών για να διευκολύνει τον εντοπισμό φημών.
Στατιστικά στοιχεία διανομής σχολίων προώθησης φημών
Μετρώντας την κατανομή του όγκου προώθησης φημών και του όγκου σχολίων, προκύπτει η ακόλουθη εικόνα διανομής.

Μπορεί να φανεί ότι ο αριθμός των σχολίων και των αναδημοσιεύσεων στις περισσότερες φήμες του Weibo είναι 10 φορές, με τον μέγιστο αριθμό σχολίων να μην υπερβαίνει τα 500 και τον μέγιστο αριθμό αναδημοσιεύσεων να ξεπερνά τις 10.000. Σύμφωνα με το Νόμο για τη Διαχείριση Διαδικτύου, εάν μια φήμη προωθηθεί περισσότερες από 500 φορές, θεωρείται «σοβαρή» κατάσταση.
Ανάλυση συμπλέγματος κειμένου φημών
Αυτό το τμήμα εκτελεί προεπεξεργασία δεδομένων σε κείμενα φημών του Weibo και εκτελεί ανάλυση συμπλέγματος μετά από τμηματοποίηση λέξεων για να δει πού συγκεντρώνονται οι φήμες του Weibo.
Προεπεξεργασία δεδομένων
Πρώτα, καθαρίστε το κείμενο δεδομένων φημών, αφαιρέστε τις προεπιλεγμένες τιμές και <> Το περιεχόμενο του συνημμένου συνδέσμου.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Στη συνέχεια, φορτώστε τις κινεζικές λέξεις στοπ και χρησιμοποιήστε τις λέξεις διακοπής cn_stopwords ,χρήσηjieba Εφαρμογή επεξεργασίας τμηματοποίησης λέξεων των δεδομένων και εκτέλεση διανυσματοποίησης κειμένου.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Προσδιορίστε την καλύτερη ομαδοποίηση
Χρησιμοποιώντας τη μέθοδο του αγκώνα, καθορίζονται οι καλύτερες ομάδες.
Η μέθοδος Elbow είναι μια μέθοδος που χρησιμοποιείται για τον προσδιορισμό του βέλτιστου αριθμού συστάδων στην ανάλυση συστάδων. Βασίζεται στη σχέση μεταξύ του αθροίσματος των τετραγωνικών σφαλμάτων (SSE) και του αριθμού των συστάδων. Το SSE είναι το άθροισμα των ευκλείδειων αποστάσεων από όλα τα σημεία δεδομένων στο σύμπλεγμα στο κέντρο του συμπλέγματος στο οποίο ανήκει: όσο μικρότερο είναι το SSE, τόσο καλύτερο το φαινόμενο ομαδοποίησης.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
Η μέθοδος του αγκώνα καθορίζει τον βέλτιστο αριθμό συστάδων αναζητώντας τον "αγκώνα", δηλαδή αναζητώντας ένα σημείο στην καμπύλη μετά το οποίο ο ρυθμός μείωσης SSE επιβραδύνεται σημαντικά. Αυτό το σημείο είναι σαν τον αγκώνα ενός βραχίονα όνομα "Μέθοδος αγκώνα". Αυτό το σημείο θεωρείται συνήθως ο βέλτιστος αριθμός συστάδων.
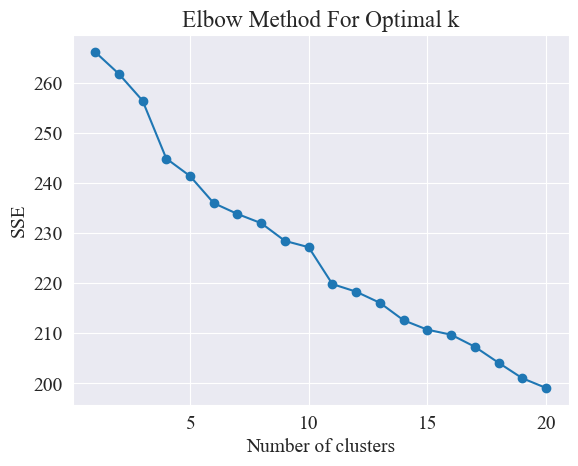
Από το παραπάνω σχήμα, προσδιορίζεται ότι η τιμή ομαδοποίησης του αγκώνα είναι 11 και σχεδιάζεται το αντίστοιχο διάγραμμα διασποράς Τα αποτελέσματα είναι τα εξής.
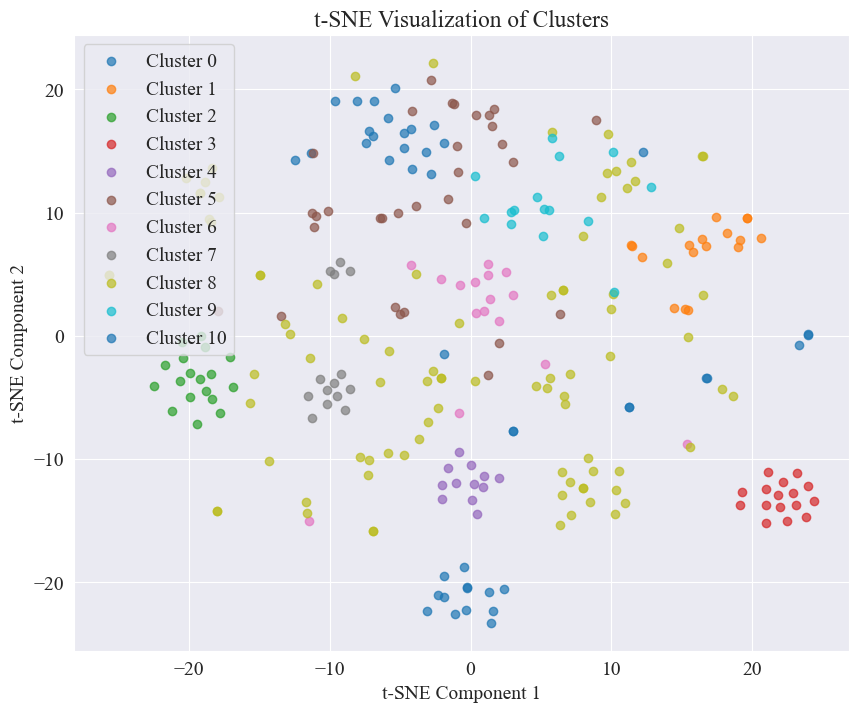
Μπορεί να φανεί ότι οι περισσότερες από τις φήμες που δημοσιεύονται στο Weibo είναι καλά συγκεντρωμένες.
Αποτελέσματα ομαδοποίησης
Προκειμένου να φανεί με σαφήνεια ποιες φήμες συγκεντρώνονται σε κάθε κατηγορία, σχεδιάζεται ένα σύννεφο γράφημα για κάθε κατηγορία Τα αποτελέσματα είναι τα εξής.

Εκτυπώστε κάποιο καλά συγκεντρωμένο περιεχόμενο φημών Weibo και τα αποτελέσματα είναι τα εξής.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Ανάλυση συμπλέγματος των αποτελεσμάτων ανασκόπησης φημών
Η ομαδοποίηση του περιεχομένου του κειμένου φημών μπορεί να μην είναι τόσο καλή για την ανάλυση περιεχομένου φημών, γι' αυτό επιλέξαμε να ομαδοποιήσουμε τα αποτελέσματα ελέγχου φημών.
Προσδιορίστε την καλύτερη ομαδοποίηση
Χρησιμοποιώντας το διάγραμμα του αγκώνα, καθορίστε την καλύτερη ομαδοποίηση.
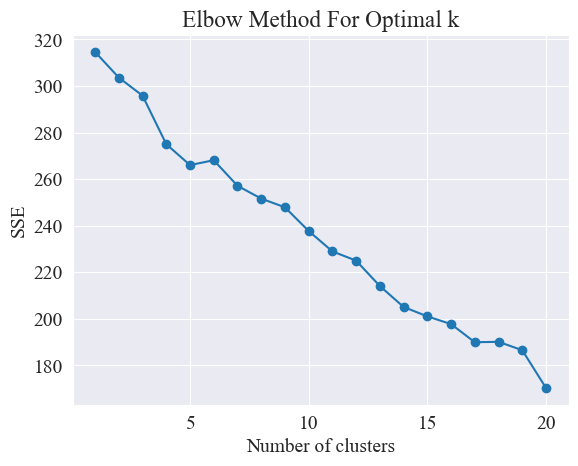
Από το παραπάνω διάγραμμα αγκώνα, μπορούν να προσδιοριστούν δύο αγκώνες, ο ένας είναι όταν η ομαδοποίηση είναι 5 και η άλλη όταν η ομαδοποίηση είναι 20. Επιλέγω 20 για ομαδοποίηση.
Το διάγραμμα διασποράς που προκύπτει από την ομαδοποίηση 20 κατηγοριών έχει ως εξής.
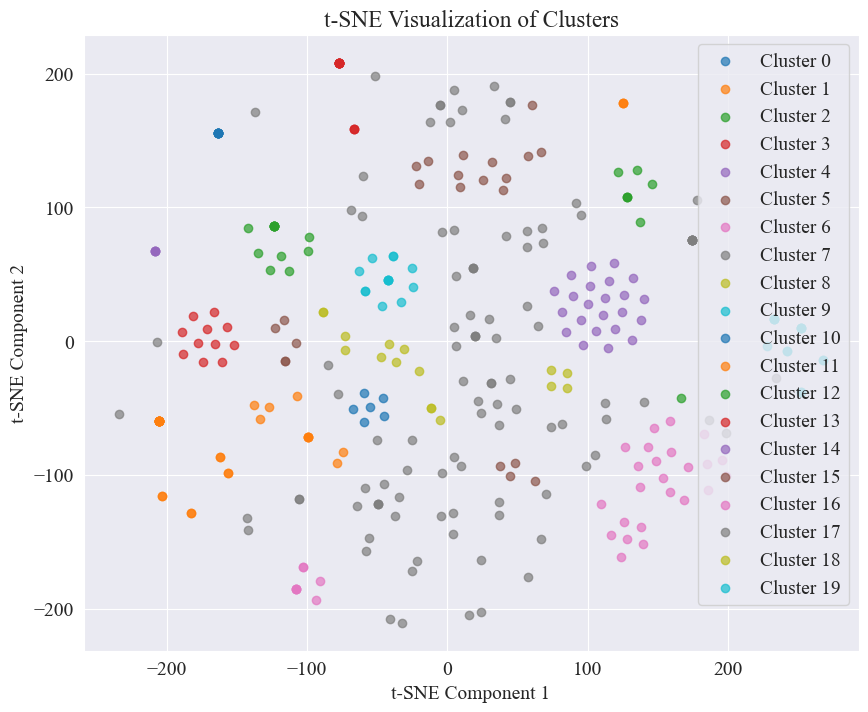
Μπορεί να φανεί ότι οι περισσότερες από αυτές είναι καλά συγκεντρωμένες, αλλά η 7η και η 17η κατηγορία δεν είναι καλά συγκεντρωμένες.
Αποτελέσματα ομαδοποίησης
Για να δείξουμε με σαφήνεια ποια αποτελέσματα ανασκόπησης φημών συγκεντρώνονται σε κάθε κατηγορία, σχεδιάζεται ένα γράφημα cloud για κάθε κατηγορία.

Εκτυπώστε μερικά καλά συγκεντρωμένα αποτελέσματα ανασκόπησης φημών Τα αποτελέσματα είναι τα εξής.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Για αυτόν τον εντοπισμό φημών, επιλέξαμε να χρησιμοποιήσουμε σύνολα δεδομένων που έχουν διαψευσθεί. fact.json Συγκρίνετε την ομοιότητα μεταξύ διαψευσμένων φημών και πραγματικών φημών και επιλέξτε το διαψευσμένο άρθρο με την υψηλότερη ομοιότητα με τη φήμη Weibo ως βάση για τον εντοπισμό φημών.
Φορτώστε δεδομένα φημών Weibo και σύνολα δεδομένων που διαψεύδουν φήμες
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Χρησιμοποιήστε προ-εκπαιδευμένα μοντέλα γλώσσας για να κωδικοποιήσετε φήμες Weibo και τίτλους διάψευσης φημών σε ενσωματωμένα διανύσματα
χρησιμοποιείται σε αυτό το πείραμα bert-base-chinese Ως προεκπαιδευμένο μοντέλο, εκτελέστε εκπαίδευση μοντέλων. Το μοντέλο SimCSE χρησιμοποιείται για τη βελτίωση της αναπαράστασης και της μέτρησης της ομοιότητας της σημασιολογίας των προτάσεων μέσω της αντιθετικής μάθησης.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Υπολογίστε την ομοιότητα
Για τον υπολογισμό της ομοιότητας, η ενσωμάτωση πρότασης και η ομοιότητα ονομαζόμενης οντότητας του μοντέλου SimCSE χρησιμοποιούνται για τον υπολογισμό της συνολικής ομοιότητας.
extract_entitiesΗ συνάρτηση εξάγει ονομασμένες οντότητες από κείμενο χρησιμοποιώντας το μοντέλο NER.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityΗ συνάρτηση υπολογίζει την ομοιότητα της ονομασμένης οντότητας μεταξύ δύο κειμένων.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityΗ συνάρτηση συνδυάζει την ενσωμάτωση πρότασης και την ομοιότητα ονομαζόμενης οντότητας του μοντέλου SimCSE για να υπολογίσει την πλήρη ομοιότητα.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Εφαρμογή ανίχνευσης φημών
Με τη σύγκριση ομοιοτήτων, εφαρμόζεται ένας μηχανισμός ανίχνευσης φημών.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
Η έξοδος είναι η εξής:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Βρήκε με επιτυχία τη βάση για τη διάψευση των φημών και έδωσε μια κρίση για να διαψεύσει τις φήμες.
Μορφή δεδομένων
Αυτό το πείραμα παρέχει το σύνολο δεδομένων ειδήσεων που σχετίζονται με την επιδημία CSDC-News, το οποίο συλλέγει ειδήσεις και περιεχόμενο σχολίων το πρώτο εξάμηνο του 2020. Το σύνολο δεδομένων περιέχει τα ακόλουθα.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
Ο φάκελος δεδομένων χωρίζεται σε τρία μέρη:data,comment。
data Ο φάκελος περιέχει πολλά αρχεία, κάθε αρχείο αντιστοιχεί σε δεδομένα μιας συγκεκριμένης ημερομηνίας, στη μορφήjson . Το περιεχόμενο αυτού του μέρους αντιστοιχεί στα δεδομένα κειμένου της είδησης (θα ενημερώνεται σταδιακά με την ημερομηνία) και τα πεδία περιλαμβάνουν:
time: Ώρα κυκλοφορίας ειδήσεων.title:Ο τίτλος της είδησης.url: Ο αρχικός σύνδεσμος διεύθυνσης της είδησης.meta: Οι πληροφορίες κειμένου των ειδήσεων, οι οποίες περιλαμβάνουν τα ακόλουθα πεδία: content: Το περιεχόμενο κειμένου της είδησης.description: Σύντομη περιγραφή της είδησης.title:Ο τίτλος της είδησης.keyword: Λέξεις-κλειδιά ειδήσεων.type: Είδος ειδήσεων.comment Ο φάκελος περιέχει πολλά αρχεία, κάθε αρχείο αντιστοιχεί σε δεδομένα μιας συγκεκριμένης ημερομηνίας, στη μορφήjson . Αυτό το μέρος του περιεχομένου αντιστοιχεί στα δεδομένα σχολίων των ειδήσεων (ενδέχεται να υπάρχει καθυστέρηση περίπου μίας εβδομάδας μεταξύ των δεδομένων σχολίου και των δεδομένων κειμένου ειδήσεων).
time: Ώρα κυκλοφορίας ειδήσεων και data Αντιστοιχεί στα δεδομένα του φακέλου.title: Ο τίτλος της είδησης, με data Αντιστοιχεί στα δεδομένα του φακέλου.url: Ο αρχικός σύνδεσμος διεύθυνσης της είδησης, και data Αντιστοιχεί στα δεδομένα του φακέλου.comment: Πληροφορίες για σχόλια ειδήσεων Αυτό το πεδίο είναι ένας πίνακας. area: Περιοχή κριτικών.content:σχόλια.nickname: Ψευδώνυμο κριτικού.reply_to: Η απάντηση του σχολιαστή αν δεν υπάρχει, σημαίνει ότι δεν είναι απάντηση.time: Ώρα σχολίων.Προεπεξεργασία δεδομένων
Δεδομένα για άρθρα ειδήσεων data Κατά την προεπεξεργασία δεδομένων, είναι απαραίτητο ναmeta Το περιεχόμενο κυκλοφορεί και αποθηκεύεται σε μορφή DataFrame.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
Στα δεδομένα αναθεώρησης comment Κατά την προεπεξεργασία δεδομένων, είναι απαραίτητο ναcomment Το περιεχόμενο κυκλοφορεί και αποθηκεύεται σε μορφή DataFrame.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Φόρτωση δεδομένων
Φορτώστε το σύνολο δεδομένων σύμφωνα με την παραπάνω λειτουργία προεπεξεργασίας δεδομένων.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Το αποτέλεσμα εκτύπωσης δείχνει ότι το μήκος των δεδομένων ειδήσεων: 502550 και το μήκος των δεδομένων σχολίων: 1534616.
Στατιστικά στοιχεία διανομής ώρας ειδήσεων
Μετρήστε ξεχωριστά news_df Ο αριθμός των μηνιαίων άρθρων ειδήσεων και ο αριθμός των άρθρων ειδήσεων ανά ώρα αντιπροσωπεύονται από διαγράμματα ράβδων και διαγράμματα γραμμών Τα αποτελέσματα είναι τα εξής.
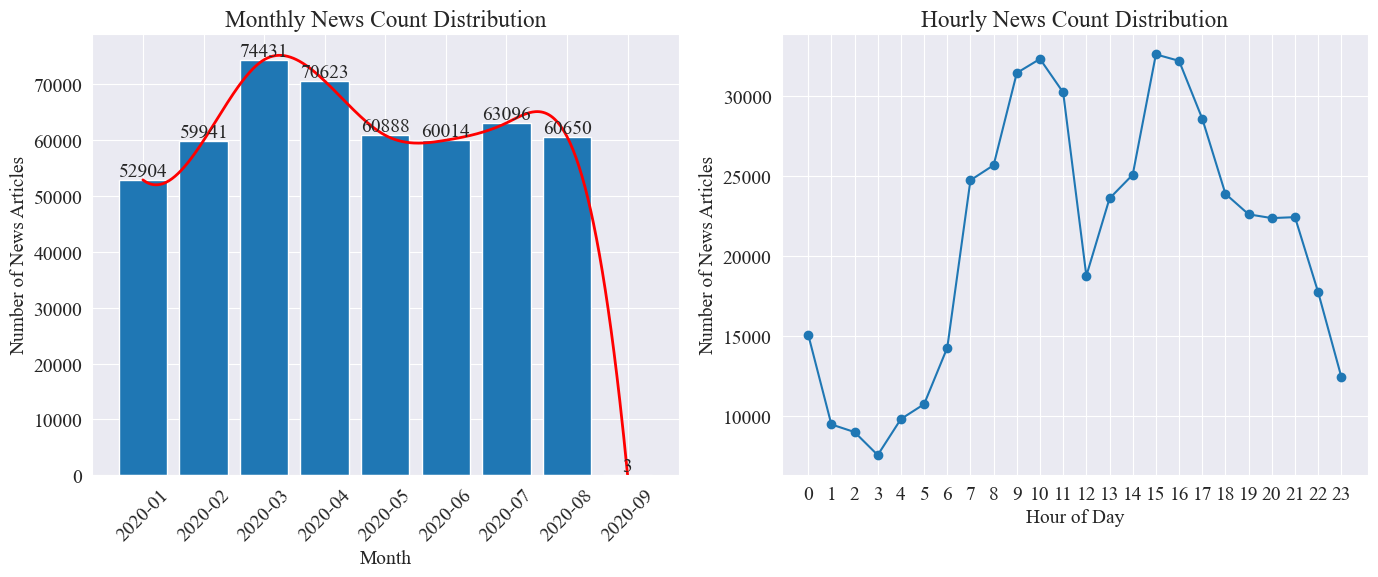
Όπως φαίνεται από το παραπάνω σχήμα, με το ξέσπασμα της επιδημίας, ο αριθμός των ειδήσεων αυξήθηκε μήνα με τον μήνα, φτάνοντας στο αποκορύφωμά του τον Μάρτιο με 74.000 άρθρα ειδήσεων και στη συνέχεια σταδιακά μειώθηκε και σταθεροποιήθηκε σε 60.000 άρθρα το μήνα, εκ των οποίων τα Τα δεδομένα τον Σεπτέμβριο ήταν 3 στο 0:00 άρθρα, ενδέχεται να μην περιλαμβάνονται στα στατιστικά στοιχεία.
Σύμφωνα με την κατανομή της ποσότητας ειδήσεων ανά ώρα, μπορεί να φανεί ότι οι 10 η ώρα και οι 15 η ώρα κάθε μέρα είναι οι ώρες αιχμής των ειδήσεων, με περισσότερα από 30.000 άρθρα να δημοσιεύονται το καθένα. 12:00 είναι το μεσημεριανό διάλειμμα και ο αριθμός των δελτίων ειδήσεων κορυφώνεται. Ο ελάχιστος αριθμός δελτίων ειδήσεων είναι από τις 0 η ώρα έως τις 5 η ώρα κάθε μέρα, με την 3 η ώρα να είναι το ελάχιστο σημείο.
Παρακολούθηση καυτών σημείων ειδήσεων
Αυτό το πείραμα σκοπεύει να χρησιμοποιήσει τη μέθοδο εξαγωγής λέξεων-κλειδιών ειδήσεων για την παρακολούθηση των καυτών σημείων ειδήσεων σε αυτούς τους οκτώ μήνες. Μετρώντας την κατανομή των υπαρχουσών λέξεων-κλειδιών και σχεδιάζοντας ένα ιστόγραμμα, τα αποτελέσματα είναι τα εξής.
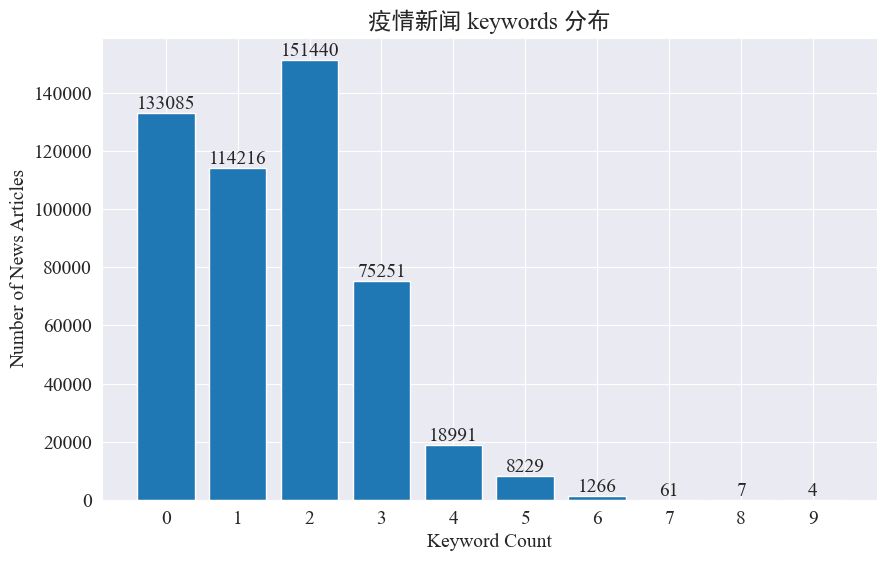
Μπορεί να φανεί ότι τα περισσότερα άρθρα ειδήσεων έχουν λιγότερες από 3 λέξεις-κλειδιά και ένα μεγάλο ποσοστό άρθρων δεν έχουν ακόμη και λέξεις-κλειδιά. Επομένως, πρέπει να συλλέγετε στατιστικά στοιχεία και να συνοψίζετε μόνοι σας λέξεις-κλειδιά για την παρακολούθηση hotspot.Αυτή τη φορά χρησιμοποιήστεjieba.analyse.textrank() για να μετρήσετε λέξεις-κλειδιά.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
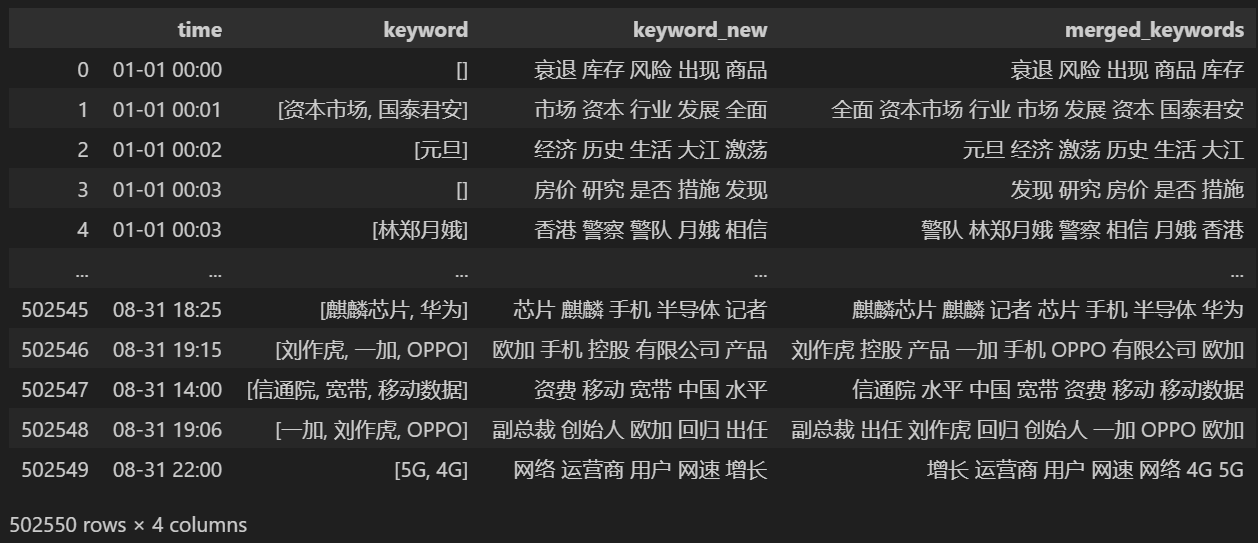
Μετρήστε 5 νέες λέξεις-κλειδιά, αποθηκεύστε τις στο keyword_new και, στη συνέχεια, συγχωνεύστε τις λέξεις-κλειδιά με αυτές και αφαιρέστε τις διπλότυπες λέξεις.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Εκτύπωση μετά τη συγχώνευση keyword_data , τα τυπωμένα αποτελέσματα έχουν ως εξής.
Για να παρακολουθήσετε τα hot spots, μετρήστε τη συχνότητα λέξεων όλων των λέξεων που εμφανίζονται και μετρήστε keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Στη συνέχεια, με βάση τα παραπάνω στατιστικά δεδομένα, σχεδιάστε ένα διάγραμμα ημερήσιας αλλαγής καυτών λέξεων.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Τέλος, λήφθηκε ένα γράφημα gif με αλλαγές στις λέξεις-κλειδιά στις επιδημικές ειδήσεις Τα αποτελέσματα είναι τα εξής.
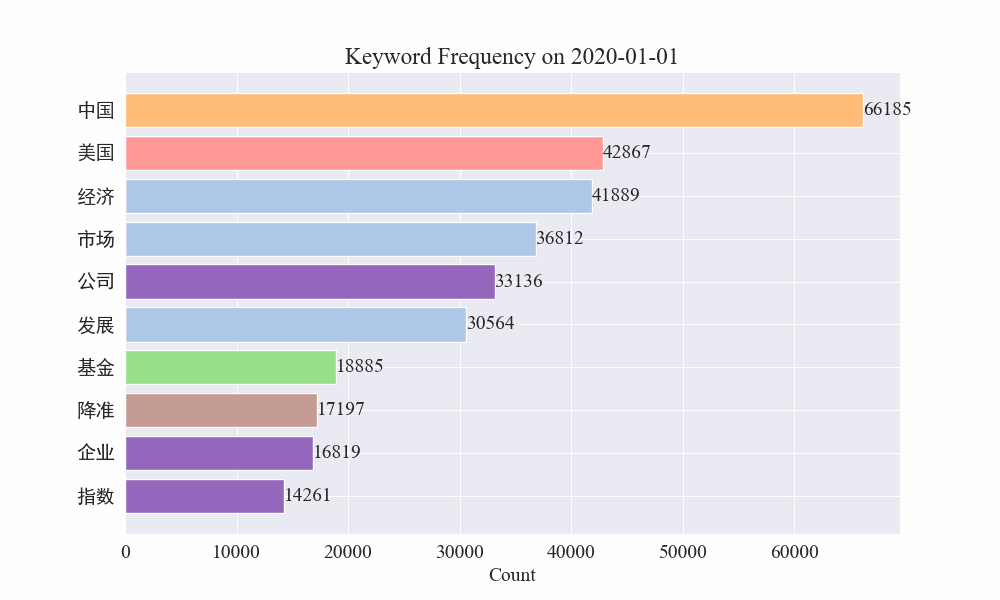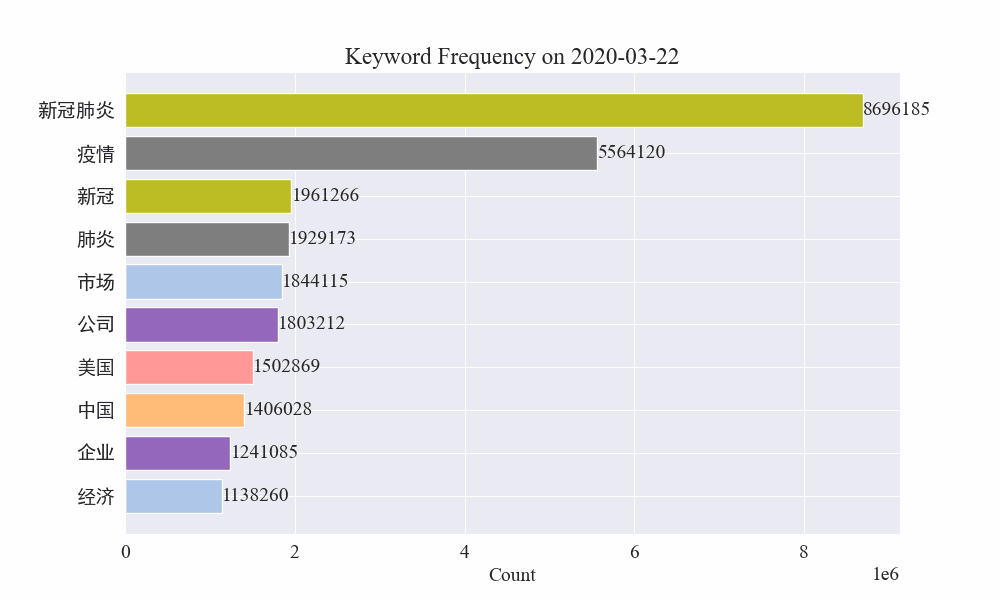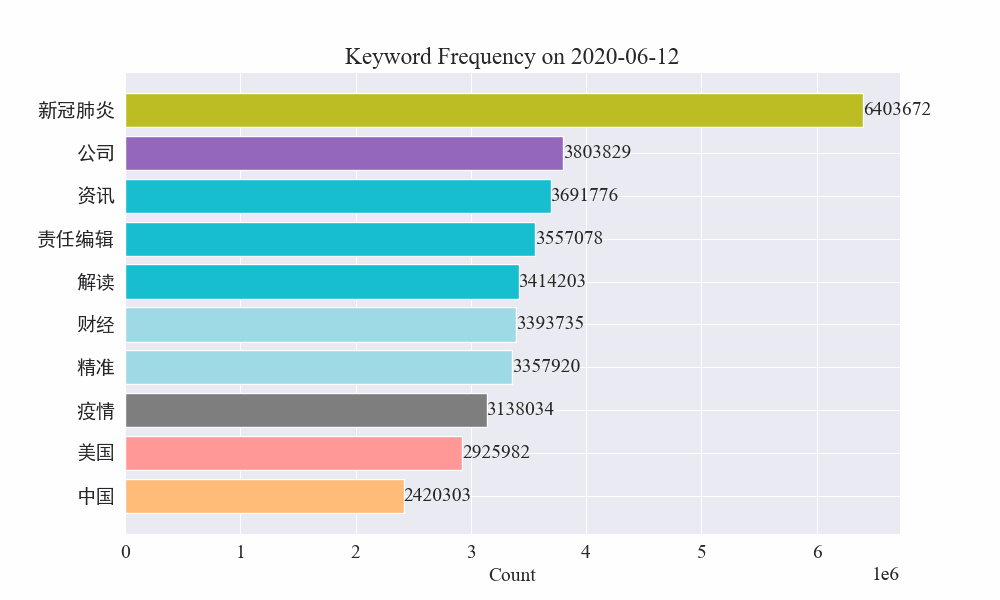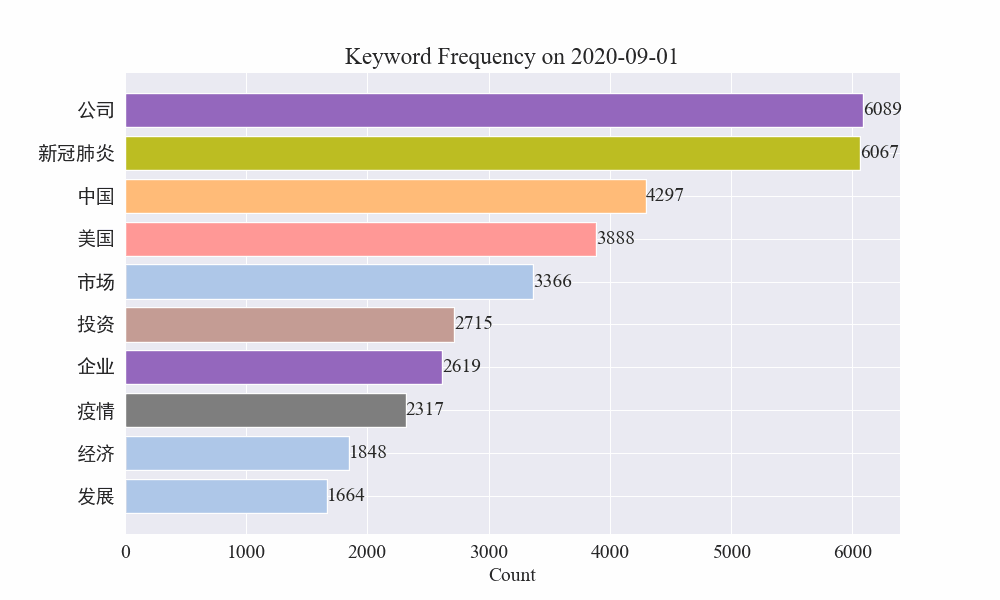
Πριν από το ξέσπασμα, οι όροι «εταιρεία» και «Ιράν» παρέμεναν υψηλοί. Μπορεί να φανεί ότι μετά το ξέσπασμα της επιδημίας, ο αριθμός των ειδήσεων που σχετίζονται με την επιδημία άρχισε να αυξάνεται τον Φεβρουάριο. το πρώτο κύμα της επιδημίας επιβραδύνθηκε και έγινε η δεύτερη θέση.
Αυτή η ενότητα διενεργεί πρώτα ποσοτική στατιστική ανάλυση για τα σχόλια ειδήσεων και, στη συνέχεια, διεξάγει ανάλυση συναισθήματος για διαφορετικά σχόλια.
Στατιστικά καταμέτρησης σχολίων καθημερινών ειδήσεων
Μετρήστε την τάση του αριθμού των σχολίων ειδήσεων, χρησιμοποιήστε ένα γράφημα ράβδων για να το αναπαραστήσετε και σχεδιάστε μια κατά προσέγγιση καμπύλη Ο κώδικας είναι ο εξής.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Το στατιστικό διάγραμμα του αριθμού των καθημερινών σχολίων ειδήσεων σχεδιάζεται ως εξής.
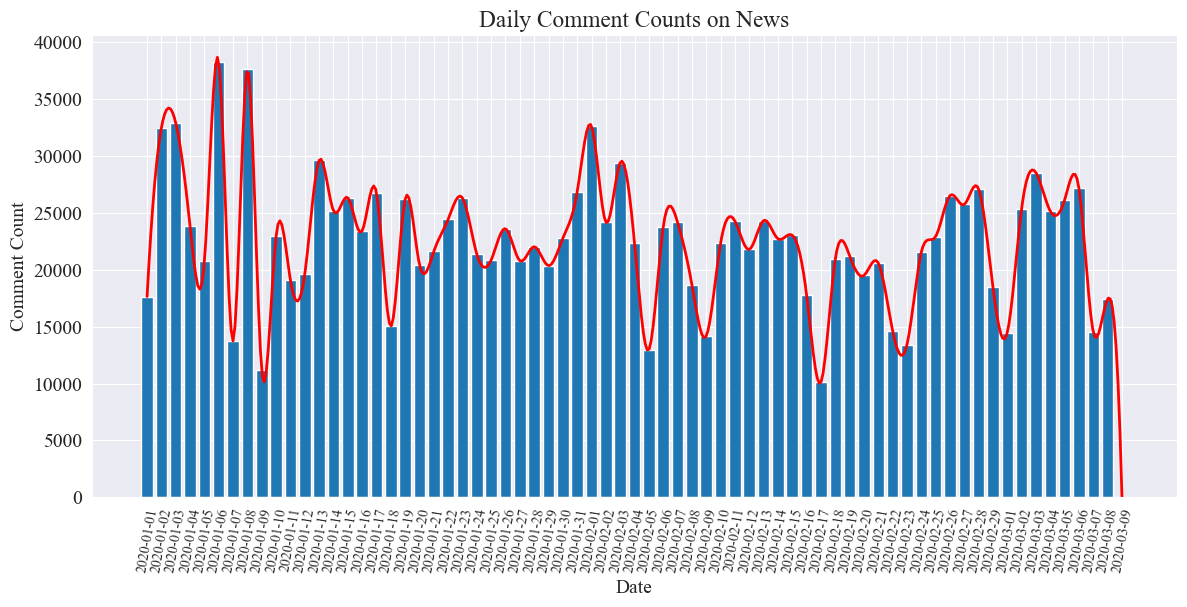
Μπορεί να φανεί ότι ο αριθμός των σχολίων ειδήσεων κατά τη διάρκεια της επιδημίας κυμάνθηκε μεταξύ 10.000 και 40.000, με μέσο όρο περίπου 20.000 σχόλια την ημέρα.
Στατιστικά επιδημικών ειδήσεων ανά περιοχή
κατά επαρχία comment_df['province'] Μετρήστε τον αριθμό των ειδήσεων σε κάθε επαρχία και μετρήστε τον αριθμό των σχολίων για επιδημικές ειδήσεις σε κάθε επαρχία.
Πρώτα, πρέπει να περάσετε το comment_df['province'] Εξαγωγή πληροφοριών επαρχίας.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Στη συνέχεια, με βάση τα στατιστικά δεδομένα, σχεδιάζεται ένα γράφημα πίτας που δείχνει την αναλογία των σχολίων ειδήσεων σε κάθε επαρχία.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

Σε αυτό το πείραμα χρησιμοποιήσαμε επίσης pyecharts.charts τουMap Στοιχείο, το οποίο απεικονίζει την κατανομή του αριθμού των σχολίων στον χάρτη της Κίνας ανά επαρχία.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
Στο HTML που αποκτήθηκε, η κατανομή του αριθμού των σχολίων για επιδημικές ειδήσεις σε κάθε επαρχία της Κίνας είναι η εξής.
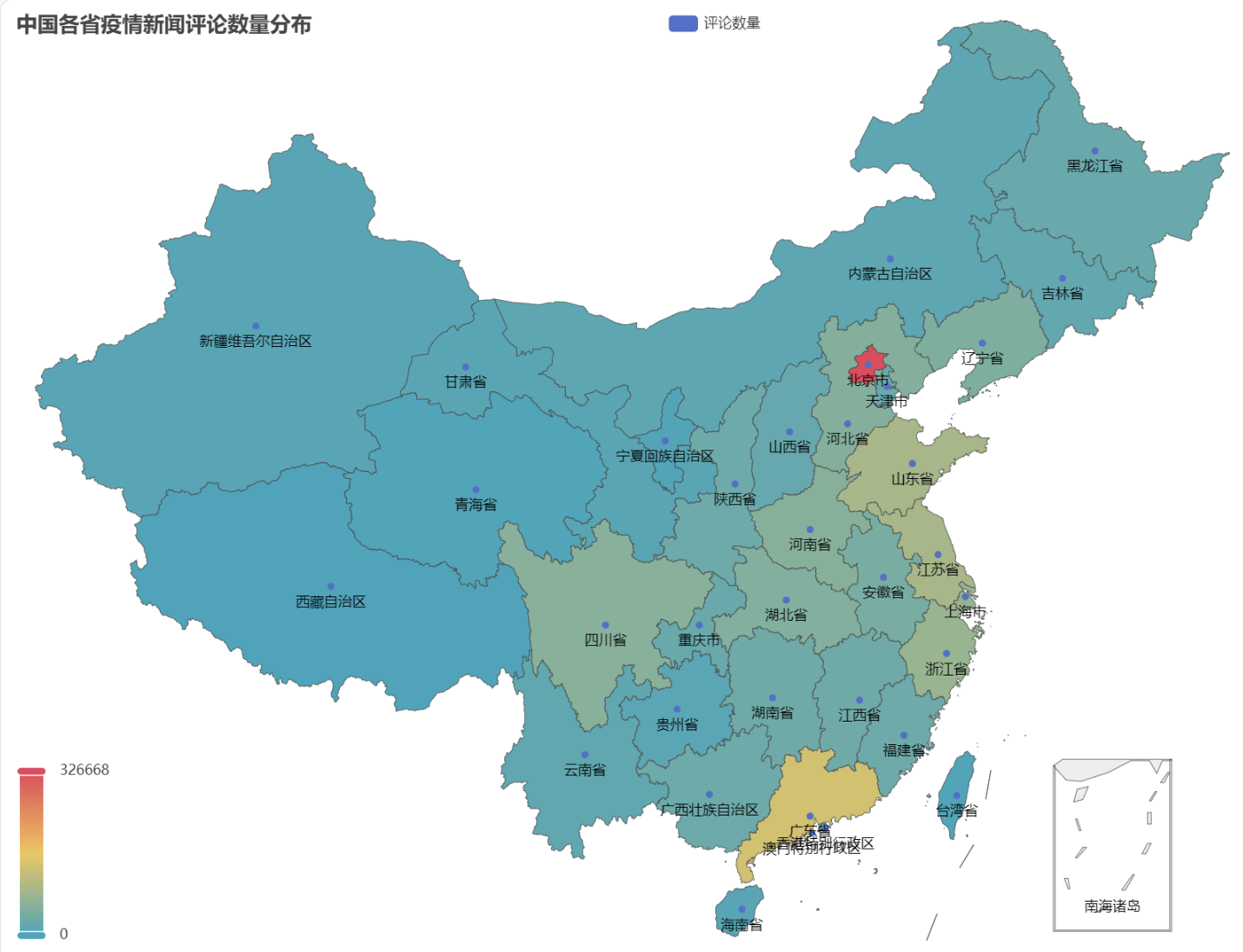
Μπορεί να φανεί ότι κατά τη διάρκεια της επιδημίας, ο αριθμός των σχολίων στο Πεκίνο αντιπροσώπευε το υψηλότερο ποσοστό, ακολουθούμενο από την επαρχία Γκουανγκντόνγκ και ο αριθμός των σχολίων σε άλλες επαρχίες ήταν σχετικά ίσος.
επιδημίαΕλέγξτε την ανάλυση συναισθήματος
Αυτό το πείραμα χρησιμοποιεί τη βιβλιοθήκη NLP για την επεξεργασία κινεζικού κειμένου SnowNLP , εφαρμόστε ανάλυση κινεζικών συναισθημάτων, αναλύστε κάθε σχόλιο και δώστε το αντίστοιχοsentiment Τιμή, η τιμή είναι μεταξύ 0 και 1, όσο πιο κοντά είναι στο 1, τόσο πιο θετική είναι και όσο πιο κοντά στο 0, τόσο πιο αρνητική είναι.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
Σε αυτό το πείραμα, το 0,5 χρησιμοποιείται ως όριο Οτιδήποτε μεγαλύτερο από αυτήν την τιμή είναι θετικό σχόλιο και οτιδήποτε μικρότερο από αυτήν την τιμή είναι αρνητικό. Γράφοντας κώδικα, σχεδιάστε ένα διάγραμμα ανάλυσης συναισθημάτων με καθημερινά σχόλια ειδήσεων και μετρήστε τον αριθμό των θετικών σχολίων και τον αριθμό των αρνητικών σχολίων στις καθημερινές ειδήσεις Ο αριθμός των θετικών σχολίων είναι μια θετική τιμή και ο αριθμός των αρνητικών σχολίων είναι αρνητικός αξία.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
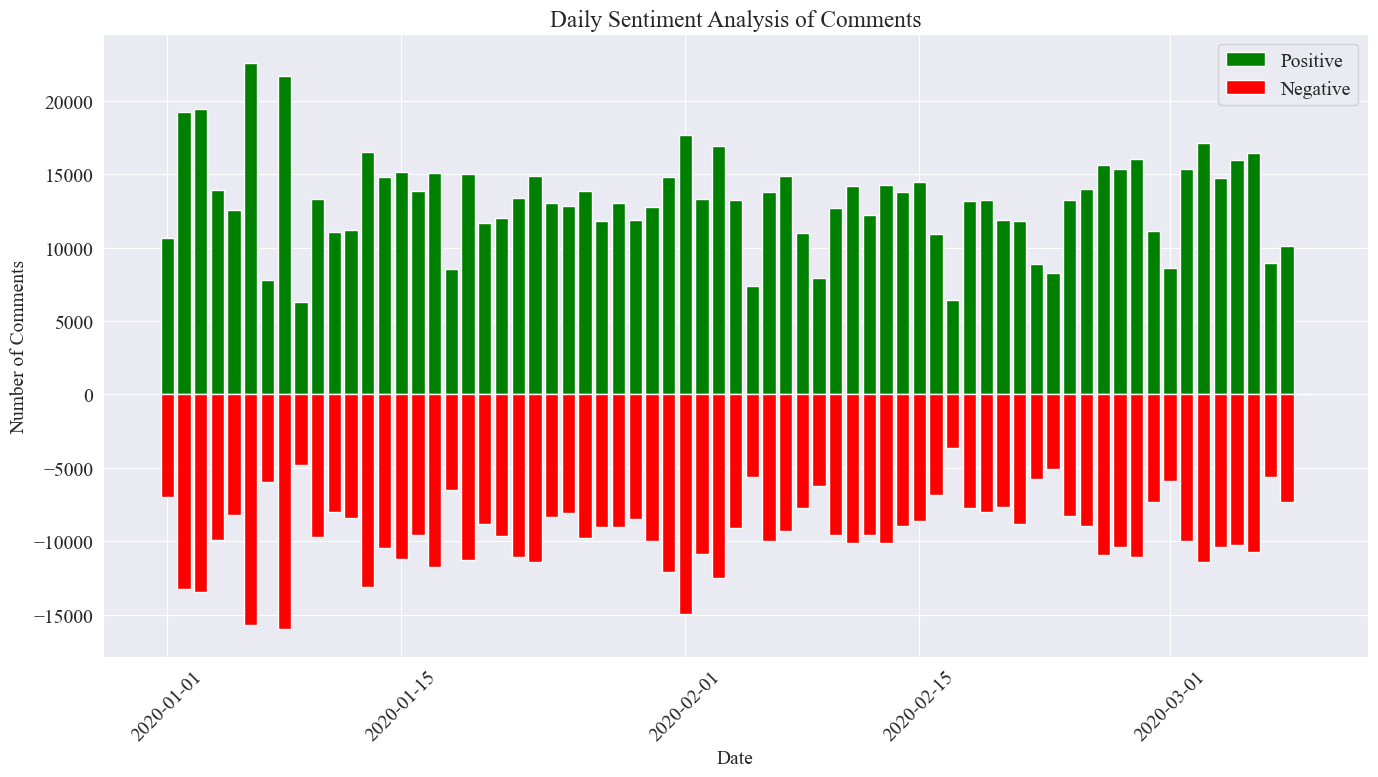
Η τελική στατιστική εικόνα είναι όπως φαίνεται παραπάνω. Μπορεί να φανεί ότι τα θετικά σχόλια κατά τη διάρκεια της επιδημίας ήταν ελαφρώς υψηλότερα από τα αρνητικά σχόλια, διαπιστώθηκε ότι το ποσοστό των θετικών σχολίων ήταν 58,63%. ότι το κοινό είχε πιο θετική στάση απέναντι στην επιδημία.
Ανάλυση συναισθήματος σχολίων ανά περιοχή
Με την καταμέτρηση της αναλογίας των θετικών σχολίων που δημοσιεύτηκαν σε κάθε επαρχία και περιοχή, προέκυψε ένα γράφημα της αναλογίας των θετικών σχολίων σε κάθε περιοχή.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
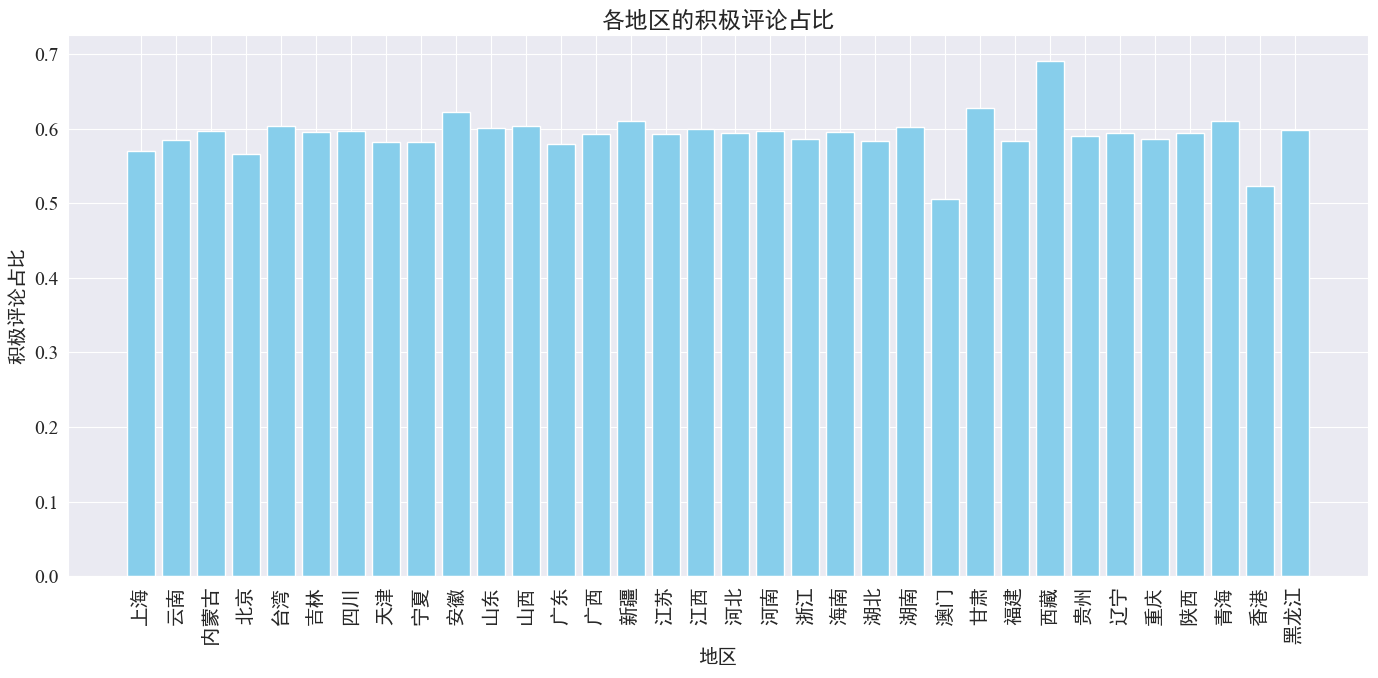
Όπως φαίνεται από το παραπάνω σχήμα, το ποσοστό των θετικών σχολίων στις περισσότερες επαρχίες είναι περίπου 60%. 70%.
Από την παραπάνω κατανομή σχολίων, μπορούμε να δούμε ότι τα σχόλια στην ηπειρωτική Κίνα είναι ως επί το πλείστον θετικά σχόλια, ενώ τα αρνητικά σχόλια στο Χονγκ Κονγκ και στο Μακάο έχουν αυξηθεί σημαντικά Ο μεγαλύτερος αριθμός θετικών σχολίων στο Θιβέτ μπορεί να οφείλεται στο σφάλμα που προκαλείται από το μικρό μέγεθος δείγματος στο Θιβέτ.
Ειδήσεις Σχόλια Σχέδιο γραφήματος στο σύννεφο του Word
Τα διαγράμματα σύννεφων λέξεων όλων των σχολίων, τα θετικά σχόλια και τα αρνητικά σχόλια μετρήθηκαν ξεχωριστά στο σχέδιο του διαγράμματος σύννεφων λέξεων, τα θετικά σχόλια ταξινομήθηκαν ως κάτω από 0,4 σχεδιάζονται διαγράμματα.

Φαίνεται ότι τα σχόλια των περισσότερων ανθρώπων κατά τη διάρκεια της επιδημίας είναι σχετικά απλά, όπως "χαχα", "καλό" κλπ. Στα θετικά σχόλια, μπορείτε να δείτε ενθαρρυντικές λέξεις όπως "Έλα Κίνα", "Έλα Γουχάν" , κ.λπ., ενώ στα αρνητικά σχόλια υπάρχουν Κριτικές όπως «Χαχα» και «Είναι δύσκολο να κάνεις μια χώρα πλούσια».

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]