내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
코로나19 전염병은 우리 각자의 마음에 영향을 미칩니다. 이 경우, 우리는 소셜 컴퓨팅 방법을 사용하여 전염병과 관련된 뉴스와 소문을 분석하여 도움을 주려고 노력할 것입니다.전염병 정보 연구. 이 과제는 개방형 과제입니다. 우리는 전염병 기간 동안 소셜 데이터를 제공하고 학생들이 뉴스, 소문 및 법률 문서를 통해 사회적 추세를 분석하도록 권장합니다. (Tip: 감성분석, 정보추출, 독해 등 수업에서 배운 방법을 활용하여 데이터를 분석해보세요)
https://covid19.thunlp.org/는 전염병 관련 루머 CSDC-Rumor, 전염병 관련 중국 뉴스 CSDC-News, 전염병 관련 법률 문서 CSDC-Legal 등 신형 코로나바이러스 전염병과 관련된 소셜 데이터 정보를 제공합니다.
수집된 데이터 세트의 이 부분은 다음과 같습니다.
(1) 2020년 1월 22일부터웨이보 허위정보해당 데이터에는 허위정보로 간주되는 웨이보 게시물의 내용, 게시자, 내부고발자, 재판기간, 결과 등이 포함된다. 2020년 3월 1일 현재 웨이보 원문 324개, 전달 31,284개, 댓글 7,912개이다. . , 전염병 기간 중 허위 정보의 확산을 분석하고 연구하는 데 사용됩니다.
(2) 텐센트의 루머 검증 플랫폼과 딩샹위안의 2020년 1월 18일 이후 허위 정보 데이터에는 루머의 내용이 맞거나 허위로 간주되는 시기, 루머 여부를 판단하는 근거 등의 정보가 포함됩니다. 2020년 3월 1일 현재 루머 데이터는 507개이며 사실 데이터 124개, 데이터 분포는 부정적 사례 420개, 긍정적 사례 33개, 불확실함 54개입니다.
이 부분의 데이터 세트는 2020년 1월 1일부터 뉴스의 제목, 내용, 키워드 및 기타 정보를 포함한 뉴스 데이터를 수집하며, 2020년 3월 16일 기준 총 148,960개의 뉴스 항목과 1,653,086개의 해당 댓글이 수집되었습니다. 연구자들이 전염병 기간 동안 뉴스 데이터를 분석하고 연구하는 데 사용됩니다.
이 데이터는 케일 수집된 익명화된 법률 문서 데이터에서 총 1,203개의 과거 전염병 관련 부분을 선별했습니다. 각 데이터에는 문서 제목, 사건 번호, 문서 전문이 포함되어 있어 연구자가 연구 수행에 사용할 수 있습니다. 전염병 연구 중 관련 법적 문제에 대해.
이 과제는 공개 과제이므로 다음부터 시작하겠습니다.
다른 측면에서 과제를 채점합니다.
[1] 트위터에서의 정보 신뢰성. WWW 논문집, 2011.
[2] 순환 신경망을 사용하여 마이크로블로그에서 소문을 감지합니다. IJCAI 회의록, 2016.
[3] 잘못된 정보 식별을 위한 합성곱 접근법. IJCAI 회의록, 2017.
[4] 온라인에서 진짜 뉴스와 가짜 뉴스의 확산. 과학, 2018.
[5] 웹 및 소셜 미디어의 허위 정보: 조사. arXiv 사전 인쇄본, 2018.
[6] 영어 단어의 감정 규범의 이산적 감정 범주에 따른 특성 분석. 행동 연구 방법, 2007.
본 실험에서는 전염병 관련 루머 데이터 세트 CSDC-Rumor를 제공합니다. 데이터 세트의 내용을 분석하여 먼저 데이터 세트에 대한 정량적 통계 분석을 수행한 다음 클러스터링을 사용하여 루머의 의미 분석을 구현하고 마지막으로 루머를 설계합니다. 루머 탐지 시스템.
데이터 형식
본 실험은 웨이보의 허위 정보 데이터와 루머 반박 데이터를 수집하는 전염병 관련 루머 데이터 세트 CSDC-Rumor를 제공합니다. 데이터세트에는 다음이 포함되어 있습니다.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
웨이보 허위정보각각에 의해 rumor_weibo 그리고rumor_forward_comment 같은 이름 두 개json 파일에 설명되어 있습니다.rumor_weibo 가운데json 구체적인 필드는 다음과 같습니다.
rumorCode: 루머 신고 페이지에 바로 접속할 수 있는 루머 고유 코드입니다.title: 제보된 루머의 제목 내용입니다.informerName: 기자의 웨이보 이름입니다.informerUrl: 기자의 웨이보 링크입니다.rumormongerName: 루머를 퍼뜨린 사람의 웨이보 이름입니다.rumormongerUr: 해당 루머를 게시한 사람의 웨이보 링크입니다.rumorText: 루머 내용입니다.visitTimes: 이 소문에 방문한 횟수입니다.result: 이번 루머 리뷰 결과입니다.publishTime: 루머가 보도된 시간입니다.related_url: 해당 루머와 관련된 증거, 규정 등에 대한 링크입니다.rumor_forward_comment 가운데json 구체적인 필드는 다음과 같습니다.
uid: 사용자 ID를 공개합니다.text: 포스트스크립트에 댓글을 달거나 전달합니다.date: 출시 시간.comment_or_forward: 바이너리, 둘 중 하나 comment, 어느 하나 forward, 메시지가 주석인지 전달된 포스트스크립트인지를 나타냅니다.텐센트와 라일락가든 허위정보콘텐츠 형식은 다음과 같습니다.
date: 시간explain: 루머 유형tag:소문 태그abstract: 루머 검증에 활용되는 컨텐츠rumor: 소문데이터 전처리
통과하다 json.load() 루머 웨이보 데이터 별도로 추출weibo_data 루머가 포함된 댓글 전달 데이터forward_comment_data 를 누른 다음 DataFrame 형식으로 변환합니다. 같은 이름의 두 파일인 웨이보 기사와 웨이보 댓글 전달은 서로 대응됩니다.rumor_forward_comment 폴더의 데이터 처리 시 후속 매칭을 위해rumorCode를 추가합니다.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
이 섹션에서는 전염병 소문 웨이보 데이터의 분포에 대한 구체적인 이해를 얻기 위해 정량적 통계 분석을 사용합니다.
루머 방문 횟수 통계
통계 weibo_df['visitTimes'] 접속 시간 분포와 그에 따른 히스토그램을 그려보면 다음과 같다.
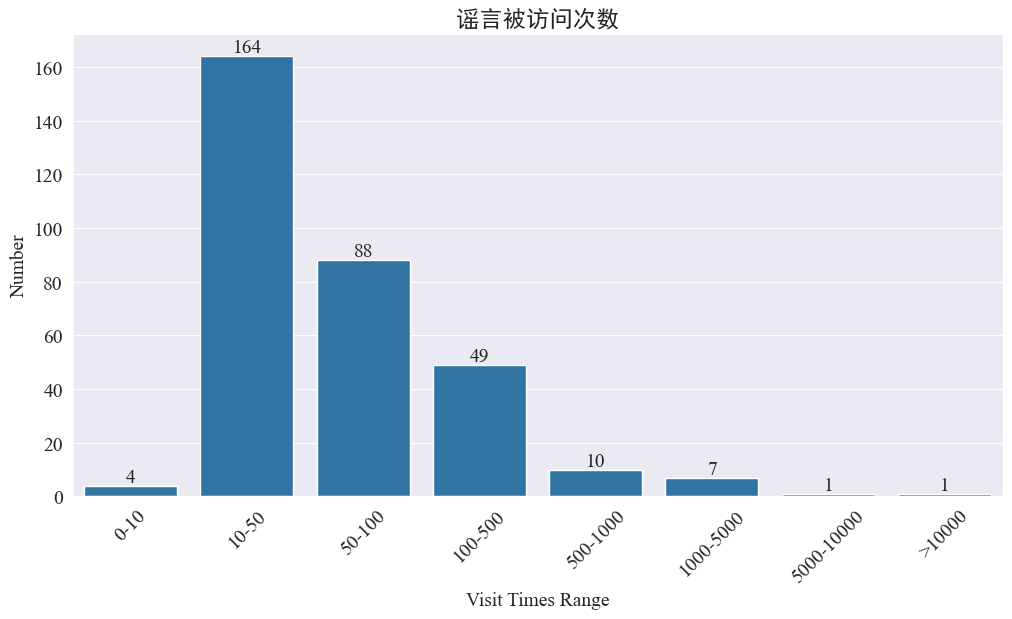
웨이보 방문자 수에 따르면 대부분의 전염병 루머는 웨이보에서 500회 미만으로 방문했으며 10~50회가 가장 큰 비율을 차지했습니다. 하지만 웨이보에는 조회수 5000회 이상으로 심각한 영향을 미칠 만큼 법적으로 '심각'하다고 판단되는 루머도 있다.
루머메이커 및 내부고발자 발생 통계
통계로 weibo_df['rumormongerName'] 그리고weibo_df['informerName'] 각 루머 게시자가 게시한 루머 수와 각 기자가 보도한 루머 수를 구한 결과는 다음과 같습니다.
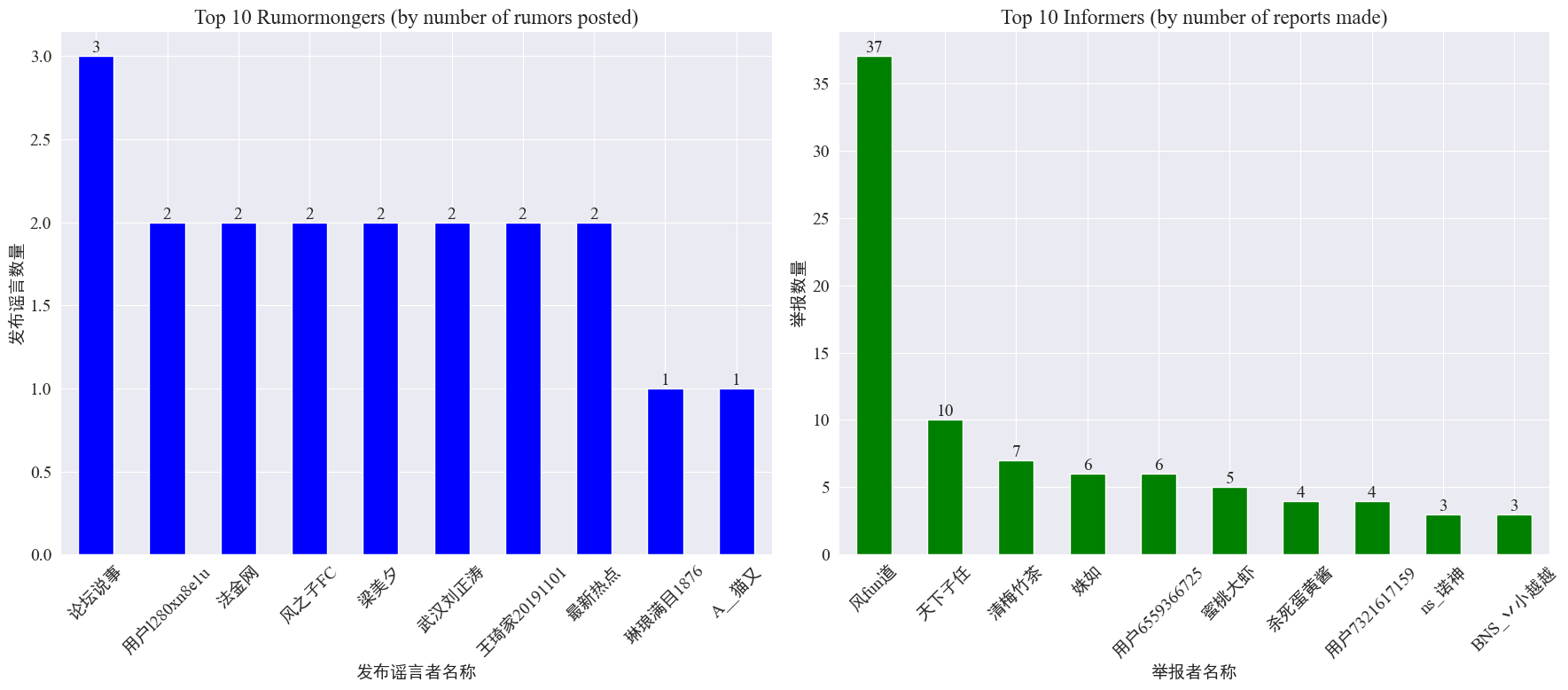
루머 제작자들이 올린 루머 수가 소수의 사람에게 집중되지 않고 상대적으로 균등하게 루머를 많이 올린 계정이 루머 웨이보 게시물 3개를 올렸다는 것을 알 수 있다. 상위 10명의 내부고발자는 각각 최소 3개 이상의 루머 기사를 신고했으며, 이 중 웨이보의 내부고발자가 신고한 루머의 수는 37개에 달해 다른 사용자보다 월등히 높았다.
위의 데이터를 바탕으로 시청자는 루머가 많은 계정을 집중적으로 신고하여 루머 탐지를 용이하게 할 수 있습니다.
루머 전달 댓글 분포 통계
루머 전달량과 댓글량의 분포를 계산하면 다음과 같은 분포 이미지를 얻을 수 있다.

대부분의 루머 웨이보의 댓글 수와 재게시 수는 10회 이내이며, 최대 댓글 수는 500개를 초과하지 않고, 최대 재게시 수는 10,000개를 초과하는 것으로 나타났습니다. 인터넷관리법에 따르면 루머가 500회 이상 전달되면 '심각한' 상황으로 간주된다.
루머 텍스트 클러스터 분석
웨이보 루머 텍스트에 대한 데이터 전처리를 수행하고, 웨이보 루머가 밀집되어 있는지 확인하기 위해 단어 분할 후 클러스터 분석을 수행합니다.
데이터 전처리
먼저 루머 데이터 텍스트를 정리하고 기본값을 제거한 다음, <> 동봉된 링크 내용입니다.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
그런 다음 중국어 불용어를 로드하면 불용어가 사용됩니다. cn_중단어 ,사용jieba 데이터의 단어 분할 처리를 구현하고 텍스트 벡터화를 수행합니다.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
최상의 클러스터링 결정
팔꿈치 방법을 사용하여 최상의 클러스터가 결정됩니다.
Elbow Method는 군집 분석에서 최적의 군집 수를 결정하는 데 사용되는 방법입니다. 이는 SSE(Sum of Squared Error)와 클러스터 수 간의 관계를 기반으로 합니다. SSE는 클러스터의 모든 데이터 포인트에서 해당 클러스터가 속한 클러스터 중심까지의 유클리드 거리 제곱의 합입니다. 이는 클러스터링 효과를 반영합니다. SSE가 작을수록 클러스터링 효과가 더 좋습니다.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
팔꿈치 방법은 "팔꿈치"를 찾아 최적의 클러스터 수를 결정합니다. 즉, SSE 감소 속도가 크게 느려지는 곡선의 지점을 찾습니다. 이 지점은 팔의 팔꿈치와 같습니다. 이름 " 팔꿈치 방법 ". 이 지점은 일반적으로 최적의 클러스터 수로 간주됩니다.
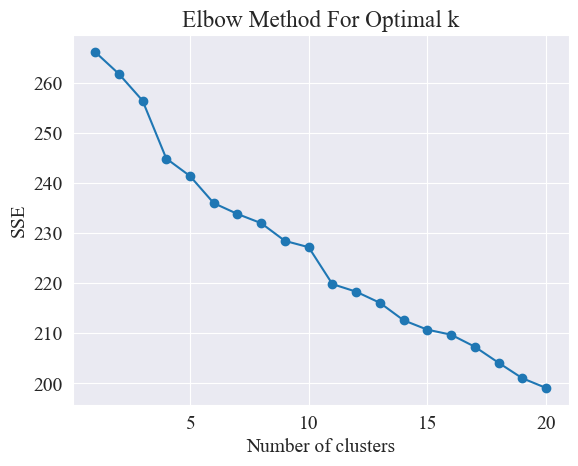
위 그림에서 엘보우의 클러스터링 값은 11로 판단되며, 해당 산점도는 다음과 같습니다.
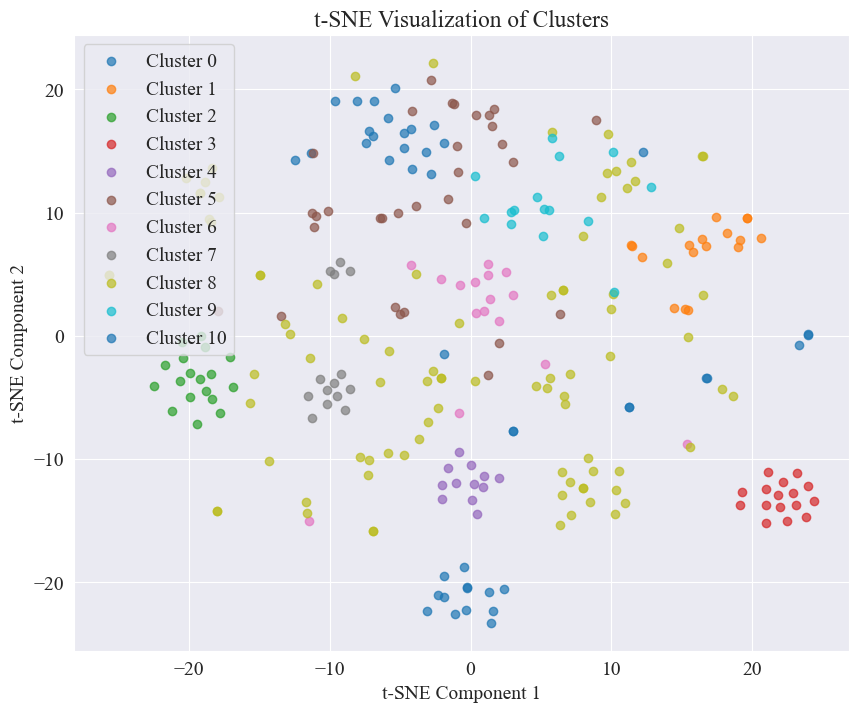
루머의 웨이보 게시물은 대부분 잘 밀집해 있고, 3번과 4번에는 5번과 8번처럼 잘 밀집해 있지 않은 경우도 있다는 것을 알 수 있다.
클러스터링 결과
각 카테고리에 어떤 루머가 밀집되어 있는지 명확하게 보여주기 위해 각 카테고리별로 클라우드 차트를 그려보면 다음과 같다.

잘 정리된 루머 웨이보 콘텐츠를 출력해 본 결과는 다음과 같습니다.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
루머 검토 결과의 클러스터 분석
루머 텍스트 내용을 클러스터링하는 것은 루머 내용 분석에 그다지 좋지 않을 수 있으므로 루머 검토 결과를 클러스터링하기로 결정했습니다.
최상의 클러스터링 결정
엘보우 플롯을 사용하여 최상의 클러스터링을 결정합니다.
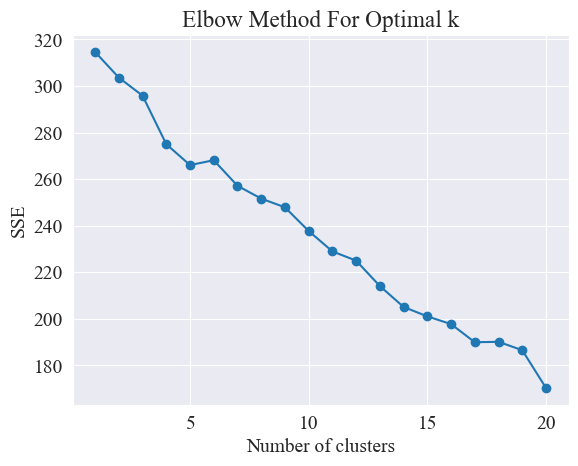
위의 엘보우 다이어그램에서 두 개의 엘보우를 결정할 수 있는데, 하나는 클러스터링이 5일 때이고 다른 하나는 클러스터링이 20일 때입니다. 저는 클러스터링을 위해 20을 선택합니다.
20개의 카테고리를 군집화하여 얻은 산점도는 다음과 같습니다.
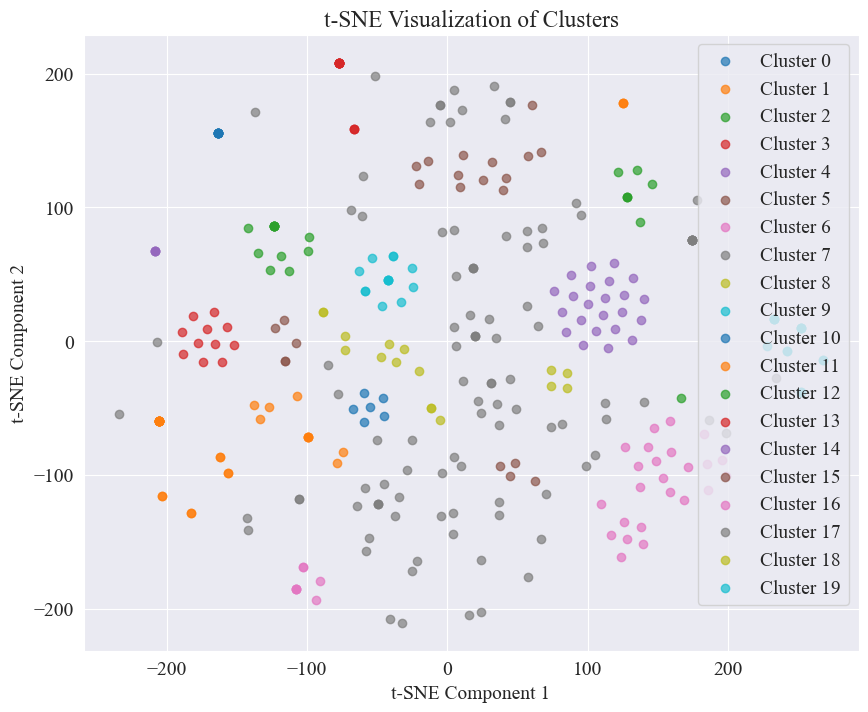
대부분의 항목이 잘 군집되어 있는 것을 볼 수 있지만, 7차와 17차 범주는 잘 군집되어 있지 않습니다.
클러스터링 결과
각 카테고리별로 어떤 루머 리뷰 결과가 밀집되어 있는지 명확하게 보여주기 위해 각 카테고리별로 클라우드 차트를 그려보면 다음과 같습니다.

잘 정리된 소문 검토 결과를 인쇄해 보세요.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
이번 루머 탐지를 위해 우리는 반박된 데이터 세트를 사용하기로 결정했습니다. fact.json 반박된 루머와 실제 루머의 유사성을 비교하고, 루머 웨이보와 유사성이 가장 높은 반박 기사를 루머 탐지의 근거로 선정합니다.
Weibo 루머 데이터 및 루머 반박 데이터 세트 로드
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
사전 학습된 언어 모델을 사용하여 Weibo 소문 및 소문 반박 제목을 임베딩 벡터로 인코딩합니다.
이번 실험에 사용된 bert-base-chinese 사전 학습된 모델로 모델 학습을 수행합니다. SimCSE 모델은 대조 학습을 통해 문장 의미의 표현 및 유사성 측정을 향상시키는 데 사용됩니다.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
유사성 계산
유사도를 계산하기 위해 SimCSE 모델의 문장 임베딩 및 개체명 유사도를 사용하여 포괄적 유사도를 계산합니다.
extract_entities이 함수는 NER 모델을 사용하여 텍스트에서 명명된 엔터티를 추출합니다.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarity함수는 두 텍스트 간의 명명된 엔터티 유사성을 계산합니다.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarity이 함수는 SimCSE 모델의 문장 임베딩과 명명된 엔터티 유사성을 결합하여 포괄적인 유사성을 계산합니다.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
루머 탐지 구현
유사점을 비교함으로써 소문 탐지 메커니즘이 구현됩니다.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
출력은 다음과 같습니다.
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
루머를 반박할 수 있는 근거를 성공적으로 찾아 루머를 반박하는 판결을 내렸습니다.
데이터 형식
본 실험에서는 2020년 상반기 뉴스 및 논평 콘텐츠를 수집한 전염병 관련 뉴스 데이터세트 CSDC-News를 제공합니다. 데이터세트에는 다음이 포함되어 있습니다.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
데이터 폴더는 세 부분으로 나뉩니다.data,comment。
data 폴더에는 여러 파일이 포함되어 있으며 각 파일은 다음 형식으로 특정 날짜의 데이터에 해당합니다.json . 이 부분의 내용은 뉴스의 텍스트 데이터에 해당하며(날짜에 따라 점진적으로 업데이트됩니다) 필드는 다음과 같습니다.
time: 보도자료 시간입니다.title:뉴스 제목입니다.url: 해당 뉴스의 원본 주소 링크입니다.meta: 다음 필드를 포함하는 뉴스의 텍스트 정보입니다. content: 뉴스의 텍스트 내용입니다.description: 뉴스에 대한 간략한 설명입니다.title:뉴스 제목입니다.keyword: 뉴스 키워드.type: 뉴스의 종류.comment 폴더에는 여러 파일이 포함되어 있으며 각 파일은 다음 형식으로 특정 날짜의 데이터에 해당합니다.json . 콘텐츠의 이 부분은 뉴스의 댓글 데이터에 해당합니다(댓글 데이터와 뉴스 텍스트 데이터 사이에 약 1주일 정도 지연될 수 있음). 필드는 다음과 같습니다.
time: 보도자료 발표 시간 및 data 폴더의 데이터에 해당합니다.title: 뉴스 제목, data 폴더의 데이터에 해당합니다.url: 뉴스의 원본 주소 링크 및 data 폴더의 데이터에 해당합니다.comment: 뉴스 댓글 정보입니다. 이 필드는 배열입니다. 배열의 각 요소에는 다음 정보가 포함됩니다. area: 리뷰어 영역.content:코멘트.nickname: 리뷰어의 닉네임입니다.reply_to: 댓글 작성자의 답변 개체가 없으면 답변이 아니라는 의미입니다.time: 댓글 시간입니다.데이터 전처리
뉴스 기사에 대한 데이터 data 데이터 전처리 과정에서 꼭 필요한meta 의 콘텐츠는 DataFrame 형식으로 공개되고 저장됩니다.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
리뷰 데이터에는 comment 데이터 전처리 과정에서 꼭 필요한comment 의 콘텐츠는 DataFrame 형식으로 공개되고 저장됩니다.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
데이터세트 로드
위의 데이터 전처리 기능에 따라 데이터 세트를 로드합니다.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
인쇄 결과에는 뉴스 데이터 길이: 502550, 댓글 데이터 길이: 1534616이 표시됩니다.
뉴스 시간 분포 통계
별도로 계산 news_df 월별 뉴스 기사 수와 시간당 뉴스 기사 수를 막대 차트와 선 차트로 표시하면 다음과 같습니다.
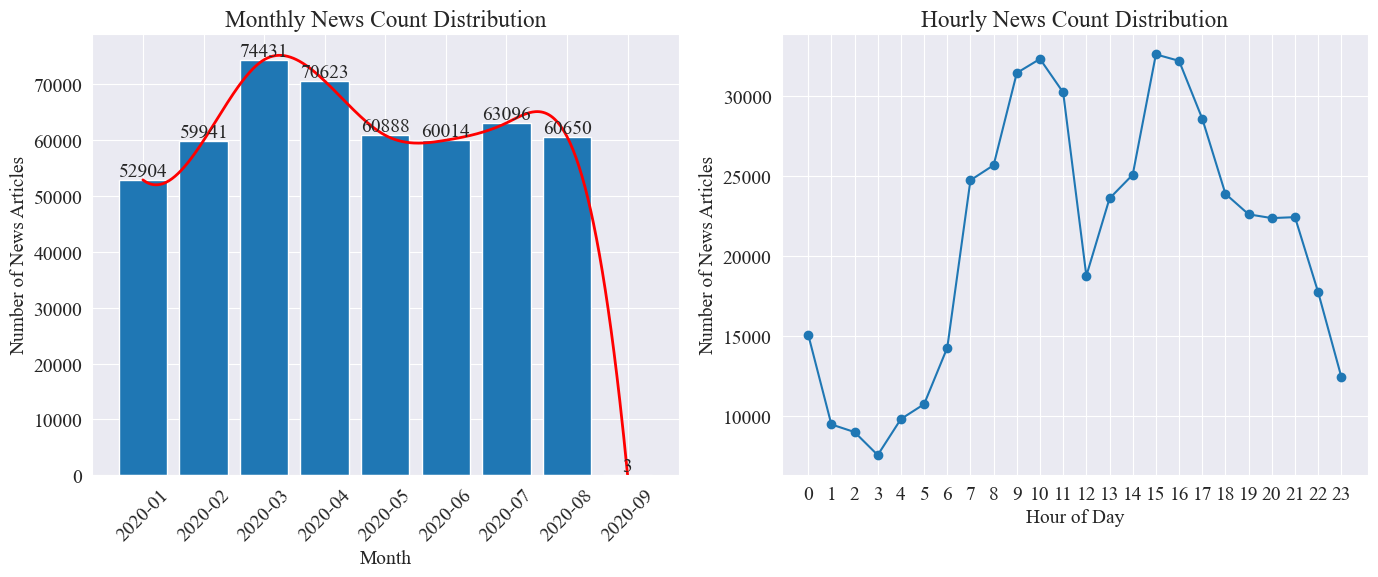
위 그림에서 볼 수 있듯이, 전염병이 발생하면서 뉴스의 수는 매달 증가하여 3월에 74,000개의 기사로 정점에 도달한 후 점차 감소하여 월 60,000개의 기사로 안정되었습니다. 9월 자료는 0시 3분 기사이므로 통계에 포함되지 않을 수 있습니다.
시간당 뉴스량 분포를 보면 매일 10시와 15시가 보도의 피크 시간으로 각각 3만 건 이상의 기사가 게재되는 것을 알 수 있다. 12시는 점심시간이고 보도자료 수가 최고점과 최저점을 기록합니다. 최소 보도 횟수는 매일 0시부터 5시까지이며, 3시가 최소 시점이다.
뉴스 핫스팟 추적
본 실험에서는 뉴스 키워드를 추출하는 방법을 이용하여 8개월간 뉴스 핫스팟을 추적하고자 한다. 기존 키워드의 분포를 계산하고 히스토그램을 그려보면 다음과 같다.
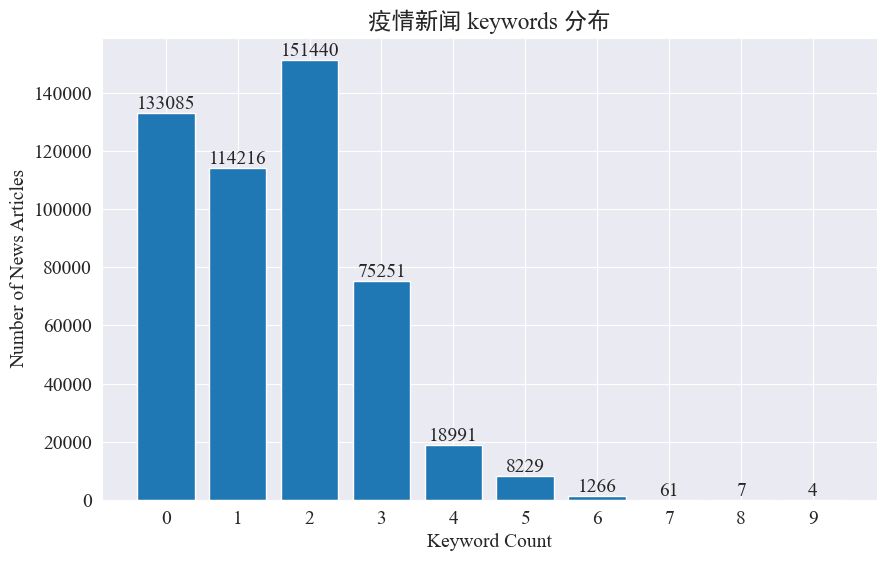
대부분의 뉴스 기사에는 3개 미만의 키워드가 있고, 심지어 키워드가 없는 기사도 상당수 있다는 것을 알 수 있습니다. 따라서 핫스팟 추적을 위해서는 직접 통계를 수집하고 키워드를 요약해야 합니다.이번에 사용jieba.analyse.textrank() 키워드를 계산합니다.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
5개의 새 키워드를 계산하여keyword_new에 저장한 다음 키워드를 병합하고 중복 단어를 제거합니다.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
병합 후 인쇄 keyword_data , 인쇄된 결과는 다음과 같습니다.
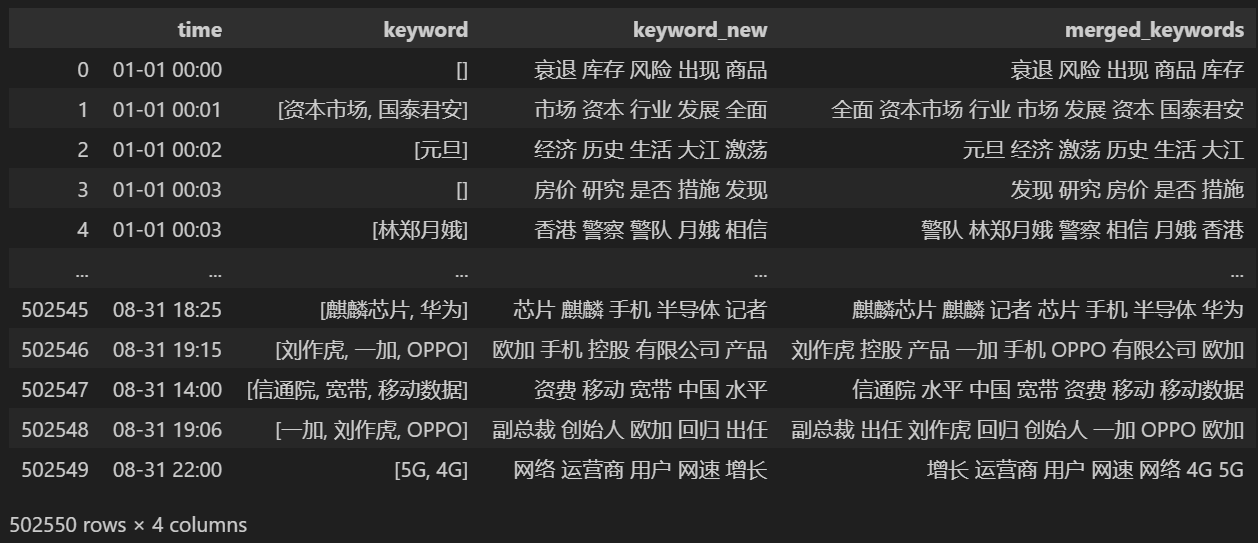
핫스팟을 추적하려면 나타나는 모든 단어의 단어 빈도를 계산하고 keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
그리고 위의 통계자료를 바탕으로 핫워드의 일일변화차트를 그려보세요.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
마지막으로 전염병 뉴스의 키워드 변화를 그래프로 나타낸 gif 차트를 얻었습니다.
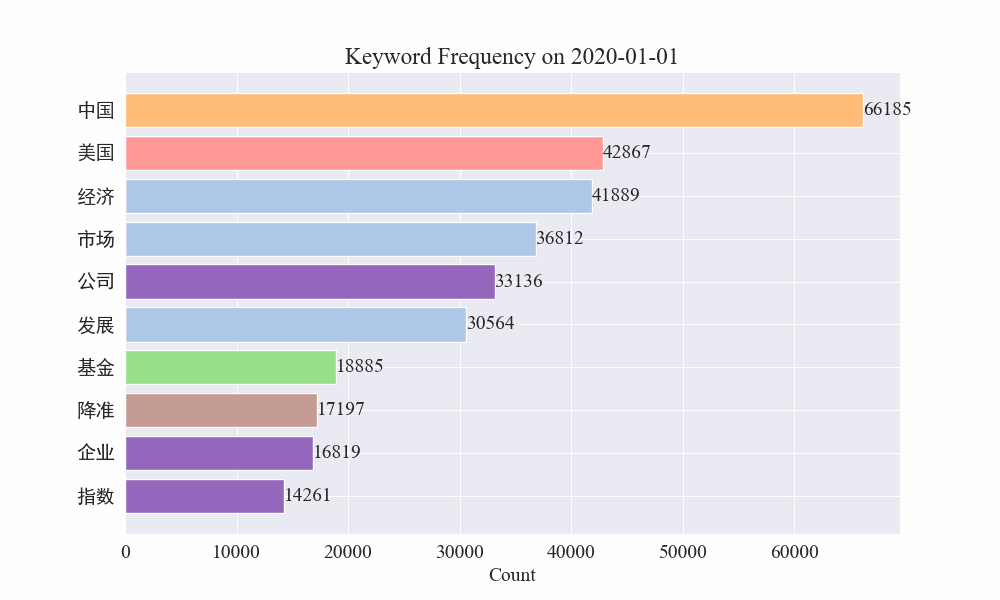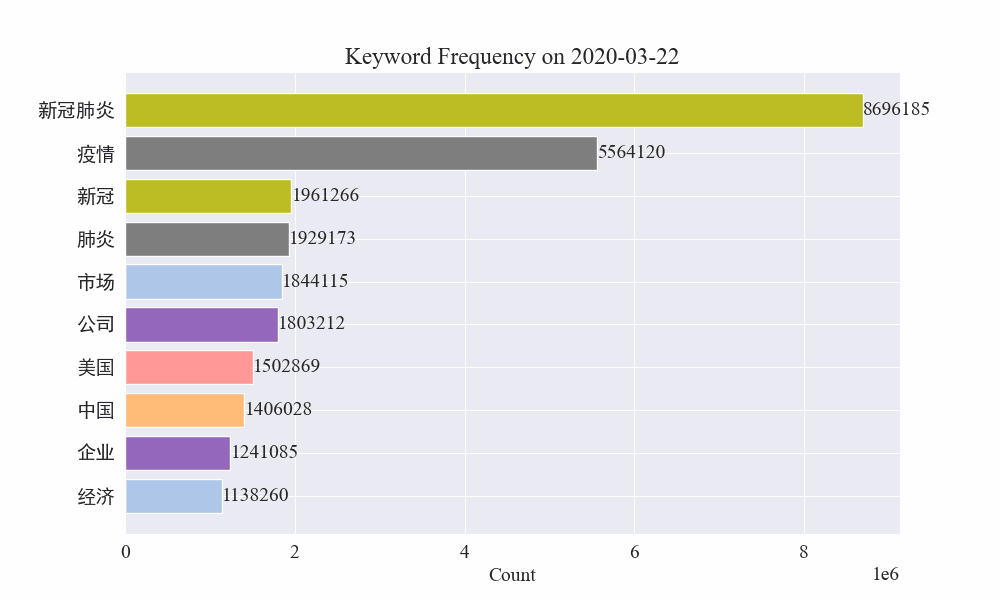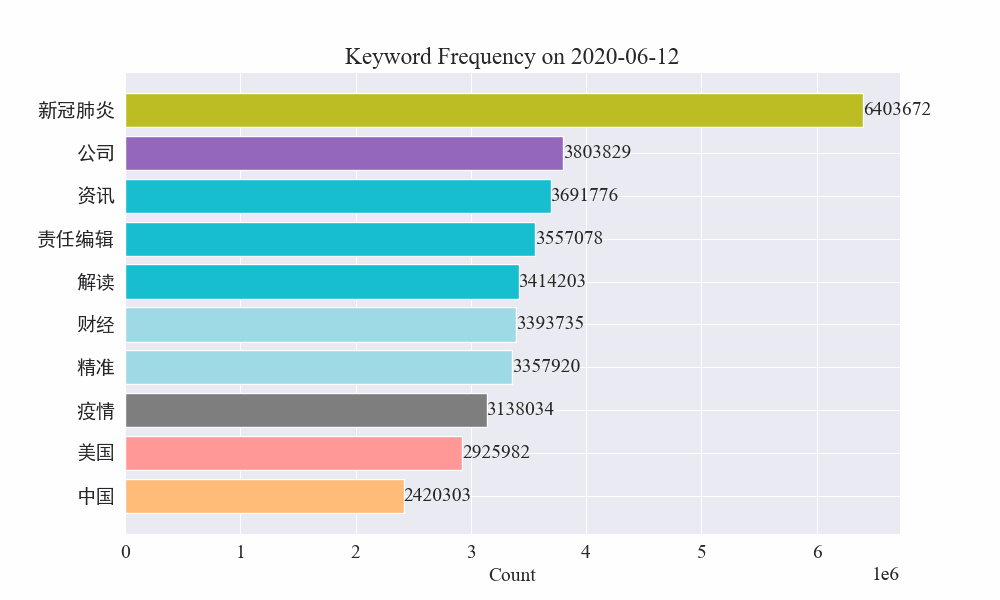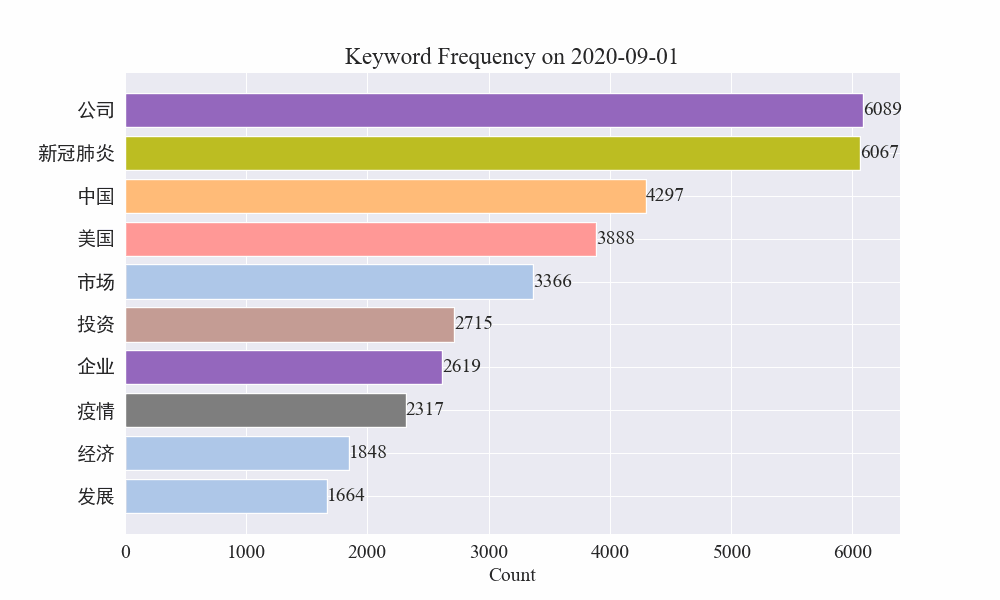
발병 이전에는 '회사'와 '이란'이라는 용어가 여전히 높았습니다. 전염병이 발생한 이후 2월부터 전염병 관련 뉴스가 급증하기 시작한 뒤 '신종 코로나바이러스'라는 용어가 급증해 8월 말까지 계속 1위를 유지한 것을 알 수 있다. 전염병의 첫 번째 물결이 느려지고 2위가 되었습니다.
본 섹션에서는 먼저 뉴스 댓글에 대한 정량적 통계 분석을 실시한 후, 다양한 댓글에 대한 감성 분석을 실시합니다.
일일뉴스 댓글수 통계
뉴스 댓글 수의 추세를 계산하고 이를 막대 차트로 표현한 후 대략적인 곡선을 그리는 코드는 다음과 같습니다.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
일일 뉴스 댓글 수에 대한 통계 차트는 다음과 같습니다.
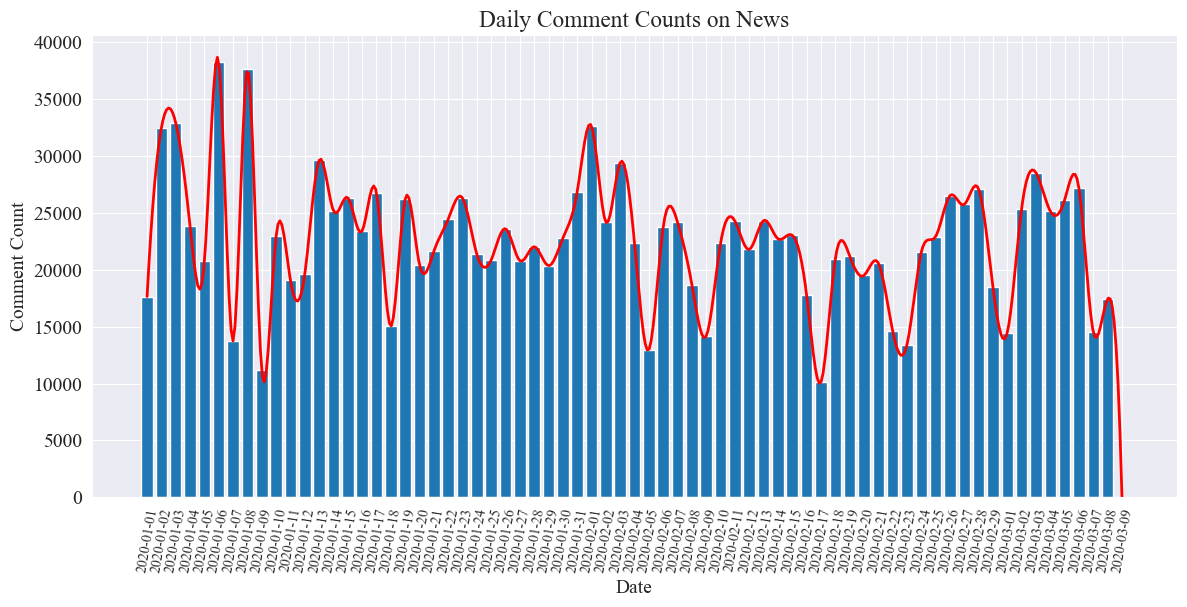
전염병 기간 동안 뉴스 댓글 수는 10,000에서 40,000 사이에서 변동했으며 하루 평균 약 20,000 건의 댓글이 있음을 알 수 있습니다.
지역별 전염병 뉴스 통계
지방별 comment_df['province'] 각 성의 뉴스 수를 세고 각 성의 전염병 뉴스에 대한 댓글 수를 세어보세요.
먼저, 시험을 통과해야 합니다. comment_df['province'] 지방 정보를 추출합니다.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
그런 다음 통계 데이터를 바탕으로 각 지역의 뉴스 댓글 비율을 보여주는 파이 차트가 그려집니다.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

이번 실험에서도 우리는 pyecharts.charts ~의Map 중국 지도의 성별 댓글 수 분포를 나타내는 구성요소입니다.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
획득한 HTML에서 중국 각 성별 전염병 뉴스 댓글 수의 분포는 다음과 같습니다.
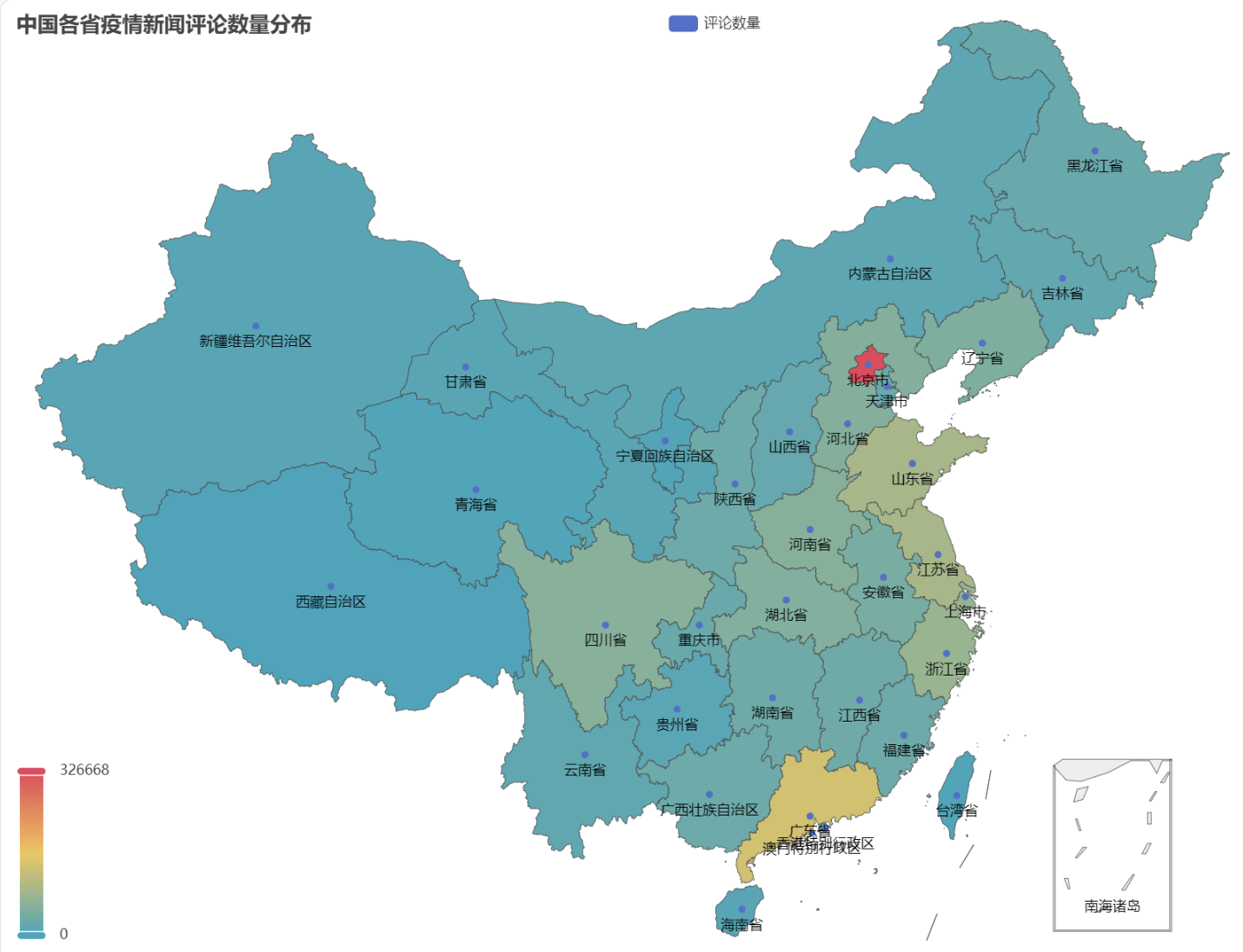
전염병 기간 동안 베이징의 댓글 수가 가장 높은 비율을 차지했으며 광둥성이 그 뒤를 이었고 기타 지방의 댓글 수는 상대적으로 균등했습니다.
감염병 유행감정 분석 검토
이 실험에서는 중국어 텍스트 처리를 위해 NLP 라이브러리를 사용합니다. SnowNLP , 중국 정서 분석을 구현하고 각 댓글을 분석하여 해당 내용을 제공합니다.sentiment 값은 0과 1사이의 값으로 1에 가까울수록 양수, 0에 가까울수록 음수를 의미합니다.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
이 실험에서는 0.5를 임계값으로 사용합니다. 이 값보다 크면 긍정적인 의견이고, 이 값보다 작으면 부정적인 의견입니다. 코드를 작성하여 일간 뉴스 댓글의 감성 분석 차트를 그려보고, 일간 뉴스에 대한 긍정적 댓글 수와 부정적인 댓글 수를 센다. 값.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
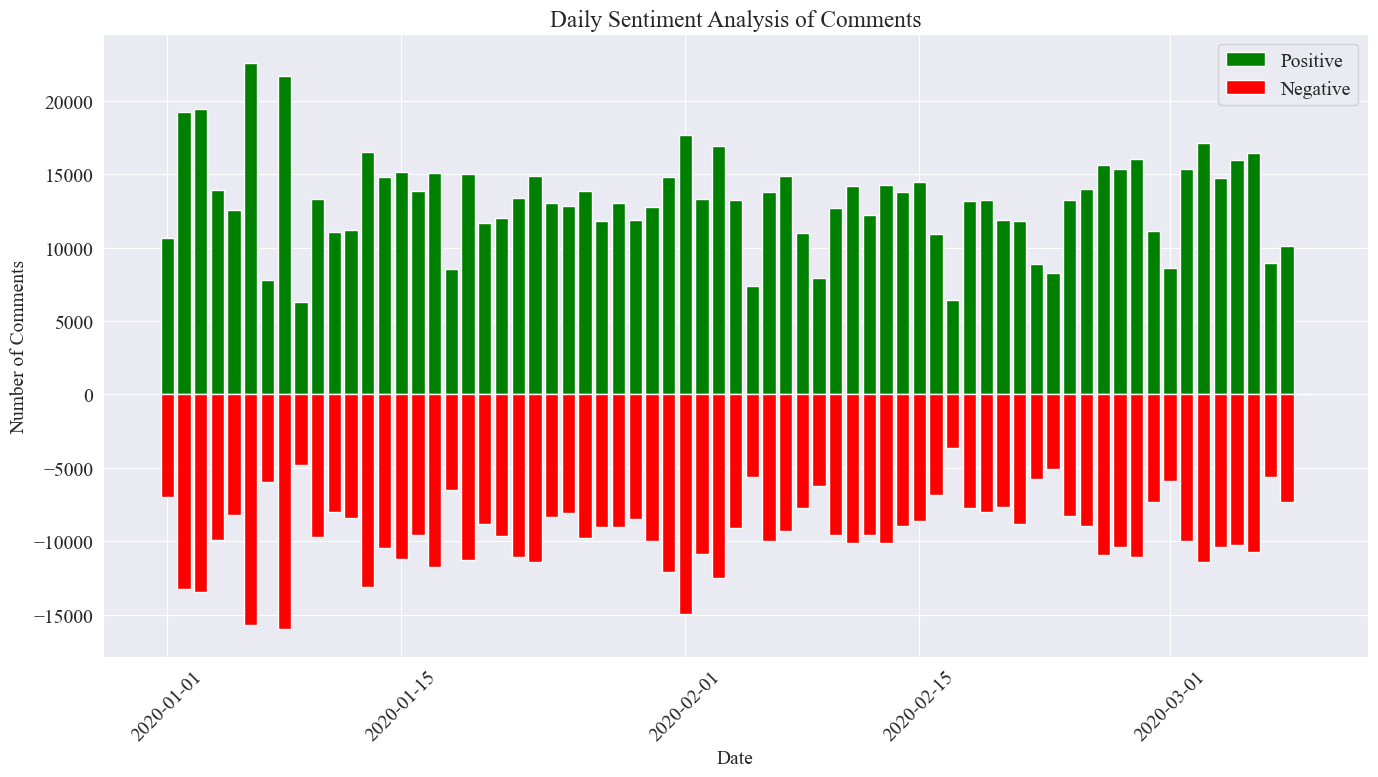
최종 통계 이미지는 위와 같습니다. 전염병 기간 동안 긍정적인 댓글이 부정적인 댓글보다 약간 높았음을 알 수 있으며, 긍정적인 댓글의 비율을 계산해 보면 긍정적인 댓글의 비율이 58.63%로 나타났습니다. 대중이 전염병에 대해 더 긍정적인 태도를 갖고 있다는 것입니다.
지역별 댓글 감성 분석
각 시·도별 긍정적 댓글 비율을 집계하여 지역별 긍정적 댓글 비율 그래프를 얻었다.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
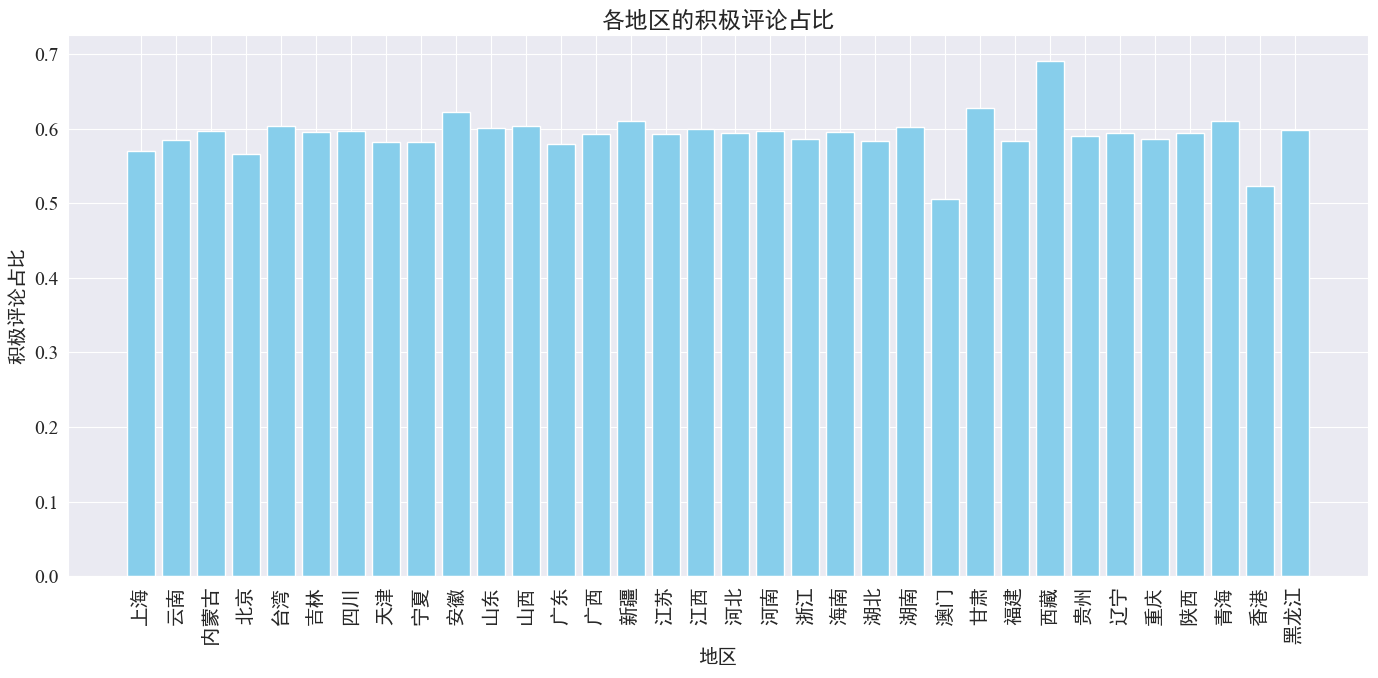
위 그림에서 볼 수 있듯이, 대부분의 지역에서 긍정적 댓글 비율은 약 60%로 홍콩과 마카오는 긍정적 댓글 비율이 약 50%로 가장 낮고, 티벳은 긍정적 댓글 비율이 거의 50%에 가깝습니다. 70%.
위의 댓글 분포를 보면 중국 본토의 댓글은 대부분 긍정적인 댓글인 반면, 홍콩과 마카오의 부정적인 댓글이 크게 증가한 것은 티베트에서 발생한 오류 때문일 수 있습니다. 티베트의 작은 표본 크기.
뉴스 댓글 단어 구름 차트 그리기
모든 댓글의 워드클라우드 다이어그램은 긍정적 댓글과 부정적인 댓글로 구분되어 집계되었으며, 워드클라우드 다이어그램 도면에서 긍정적 댓글은 0.6 이상으로 나열되었으며, 부정적인 댓글은 0.4 이하로 분류되었습니다. 그려진 다이어그램.

전염병 기간 동안 대부분의 사람들의 댓글은 "하하", "좋아요" 등과 같이 비교적 단순하다는 것을 알 수 있습니다. 긍정적인 댓글에서는 "어서 중국으로 와", "우한으로 와라"와 같은 격려적인 단어를 볼 수 있습니다. 등의 부정적인 댓글에도 '하하', '나라를 부자로 만들기 어렵다' 등의 비판이 이어지고 있다.

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에서 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com