2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Pestilentia COVID-19 cordi uniuscuiusque nostrum afficit. In hoc casu conabimur modi computandi socialis uti ad solutionem nuntii et rumores ad pestilentiam pertinentes adiuvandiPestilentia notitia Investigationes. Haec assignatio est aperta definitio assignationis. Sociales notitias in pestilentia praebemus, et studentes hortamur ad analysim a novorum, rumorum, et documenta legalia, ut socialis trends. (Significatio: Modi utere eruditorum in genere, ut analysi sentiendi, extractionis informationis, comprehensionis lectionis, etc. ad analysim data)
https://covid19.thunlp.org/ informationes sociales praebet ad novam pestilentiam coronavirus pertinentes, inter rumores pestilentes relatas CSDC-Rumor, pestilentia nuntiata Sinica CSDC-Nuntia, et pestilentia actis legalia documenta CSDC-Legal.
Haec pars dataset collegit;
(1) Incipiens a die 22 mensis Ianuarii, anno 2020Falsus notitia WeiboNotitia includunt argumenta Weibo nuntia quae falsa esse censentur, editores, whistleblowers, iudicii tempus, proventus et alia indicia. .
(2) rumor tencent suggestum verificationis et falsus notitias Dingxiangyuan notitias ab 18 Ianuarii 2020, inclusis informationibus talis sicut materia rumoris quae recte vel falsa censetur, tempus et fundamentum ad iudicandum utrum sit fama, As. Die 1 Martii 2020, sunt 507 partes famae datae, inter 124 partes scientificae datae.
In hac parte notitiarum copiarum notitiarum novarum ab initio diei 1 Ianuarii 2020, incluso titulo, contentorum, keywords et aliorum nuntiorum nuntiorum. Adhibebant investigatores analysin ac studium nuntiorum notitiarum in pestilentia adiuvare.
Haec data est a CAIL Pars mille trecenta fragmenta historicae partis pestilentiae relatas muniebant e notitia documenti iuris anonymizati collecti. Quaelibet pars notitiarum includit titulum documenti, numerum casuum, ac plenum textum documenti, qui ab inquisitoribus ad investigationes peragendas adhiberi potest. de quaestionibus legalibus in re morbis Investigationibus pertinentibus.
Haec assignatio aperta est assignatio, incipiemus ab
Gradatim assignationes alias.
[1] Informationes fidem in Twitter. in Bibliotheca WWW, MMXI.
[2] Detegere opiniones e microblogis cum retiacula neurali recurrentia. in Bibliotheca IJCAI, MMXVI.
[3] Actio convolutionis ad identitatem misinformationis. in Bibliotheca IJCAI, MMXVII.
[4] De vera et falsa fama online diffusio. Scientia, MMXVIII.
[5] Falsae informationes in instrumentis interretialibus et socialibus: Percontatio. arXiv preprint, MMXVIII.
[6] Characterization of the affective Norms for English Words by Discrete Motus Categories. Morum Investigationis Methodi, MMVII.
Hoc experimentum praebet notitiae pestilentiae relatae rumoris CSDC-Rumoris destinatae. Per analyses contentorum notitiarum statutorum, libemus primum analysin statisticam quantitatis statisticae in notitia statuta praestare, deinde uti ad analysin rumorum semanticam efficiendam, ac tandem excogitandum. rumoris deprehendendi ratio.
Data Forma
Hoc experimentum praebet notitiae rumoris pestilentiae relatae CSDC-Rumor positae, quae notitias falsas Weibo colligit et rumorem notitiae refutationis. Dataset sequentia continet.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Falsus notitia Weiborespectively by * rumor_weibo etrumor_forward_comment duos eiusdem nominisjson descriptus in tabella.rumor_weibo mediumjson Agri specificati sunt hoc modo;
rumorCode: Unicum codicem rumoris, per quem directe accessi potest fama de pagina.title: Tituli contenti famae famae.informerName: Weibo nomine notario.informerUrl: Report's Weibo link.rumormongerName: De Weibo nomine persone qui rumorem ediderat.rumormongerUr: Weibo nexus eius qui rumorem missae.rumorText: fama contentus.visitTimes: pluries fama haec allata est.result: Eventus huius rumoris recensio.publishTime: tempus quo fama nuntiata est.related_url: Vincula ad probationes, ordinationes, etc. ad hunc rumorem pertinentia.rumor_forward_comment mediumjson Agri specificati sunt hoc modo;
uid: Divulgare id usor.text: Commentarium seu deinceps Tomi.date: tempus dimittere.comment_or_forward: binarius vel commentaut forwardindicans num nuntium commentarium sit vel postscriptum transmissum.Tencent et Lilac Garden falsa notitiaContentum forma est:
date: tempusexplain: Rumor typetag: Rumores tagabstract: Content usus est cognoscere rumoresrumor: RumorData preprocessing
pass json.load() Rumor extractum Weibo separatim dataweibo_data Commentum procuret notitia per rumoremforward_comment_data ac deinde ad formatam DataFrame converte. Duo fasciculi nomine eodem, Weibo articulus et Weibo commentarium transmissionis inter se correspondent.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Haec sectio quantitatis statistica analysi utitur ad certam cognitionem distributionis rumoris pestilentiae Weibo datae.
Statistics pluries rumores visitati sunt
Statistics weibo_df['visitTimes'] Distributio accessuum temporum et histogrammum congruentem trahere.
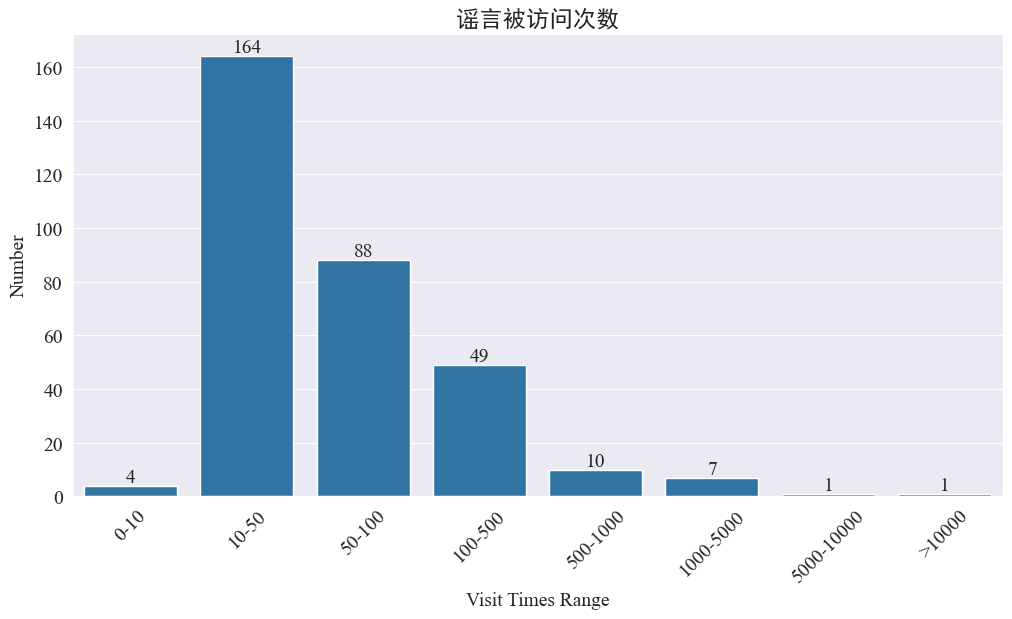
Secundum numerum visitationum ad Weibo, rumores pestilentes plus minus quam 500 vicibus in Weibo visitatae sunt, cum 10-50 pro maxima proportione. Attamen rumores sunt etiam de Weibo quae plus quam quinque milia temporum accesserunt, quae impulsum grave attulerunt et lege "gravia" censentur.
Statistics de eventu rumoris fabri et whistleblowers
per mutant weibo_df['rumormongerName'] etweibo_df['informerName'] Numerus rumorum ab unoquoque editore divulgatus et numerus rumorum ab unoquoque notario relatis obtinetur.
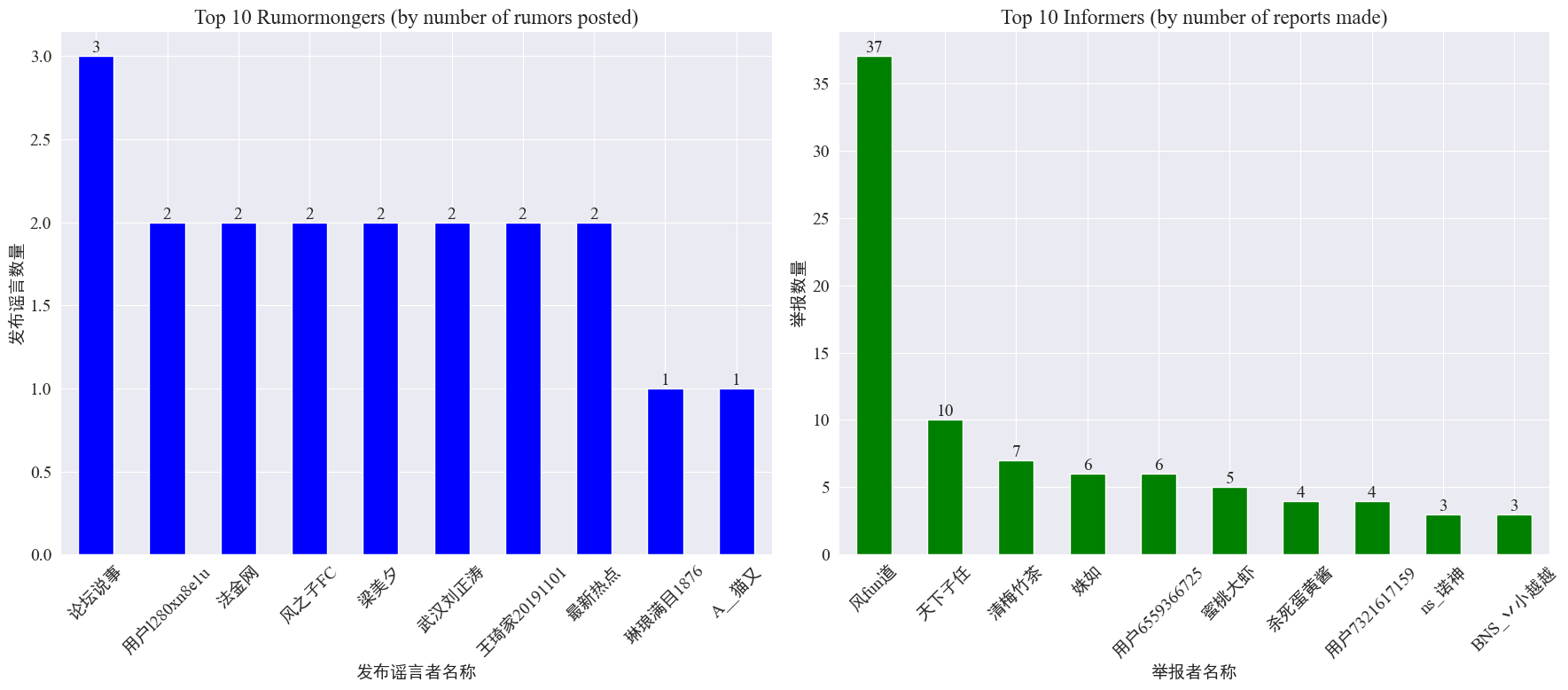
Videri potest quod numerus rumorum factorum per rumorem missae non contrahitur in pauci, sed est relative etiam. Singulae supremae 10 whistleblowers nuntiaverunt saltem 3 articulos rumoris. Inter eos, numerus rumorum ab whistlebloworum in Weibo relatum erat, insigniter altior quam aliorum utentium, 37 articulos attingens.
Fundata supra notitia, audientes in nuntiandis rationibus intendere possunt cum pluribus rumoribus ad deprehensionem rumorum faciliorem.
Distributio statistica rumoris procuret comment
Distributio rumoris computando volumen et commentarium in volumine, haec distributio imaginis habetur.

Perspici potest numerum commentariorum et repostorum in celeberrima rumore Weibo intra 10 tempora esse, cum maximus numerus commentariorum non excedentes quingentos et maximum numerum reposts plus quam 10,000 perveniat. Secundum Internet Procuratio legis, si fama plusquam 500 temporibus transmittitur, "gravis" condicio censetur.
Rumor textus analysis botri
Haec pars notitias praeprocessionales in Weibo textibus rumoris praestat, et analysin racemum cum verbo segmentationis facit ad videndum ubi rumores Weibo conducunt.
Data preprocessing
Primum, emunda rumorem textus notatium, tolle valores defectus, et <> Nexus conclusus contentus.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Tunc onerant Sinenses verba sistenda, et sistenda verba utere cn_stopwords , ususjieba Exsecutio verbi segmentationis processus notitiarum et vectorizationis textus perficit.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Determinare optimum pampineis
Ad modum cubiti utendo, uvae optimae determinantur.
Methodus Cubiculi methodus adhibita est ad meliorem numerum botrum in analysi botri determinandum. Fundatur in relatione errorum quadratorum (SSE) et numerus botri. SSE est summa distantiarum Euclidearum quadratarum ab omnibus punctis in botro usque ad centrum botri, cuius est.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
Methodus cubiti optimalem uvarum numerum determinat quaerendo "cubiti", id est, punctum in curva quaerens, postquam rate SSE decrescit signanter retardat nomen "Methodus Cubitus". Hoc punctum considerari solet numerus botri optimal.
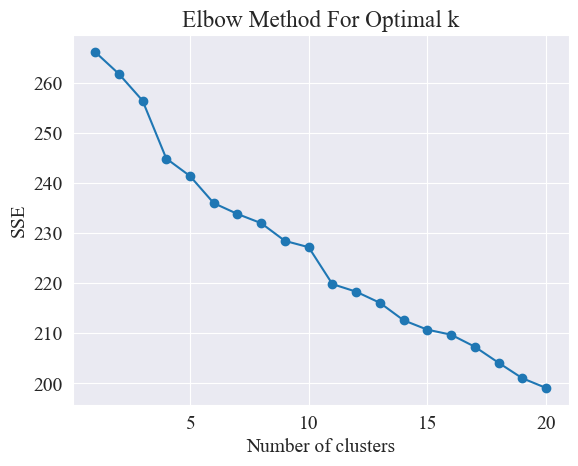
Ex superiore figura, constat, ut racemosi valoris cubiti 11, et respondentes dispertiendi insidiae ducatur.
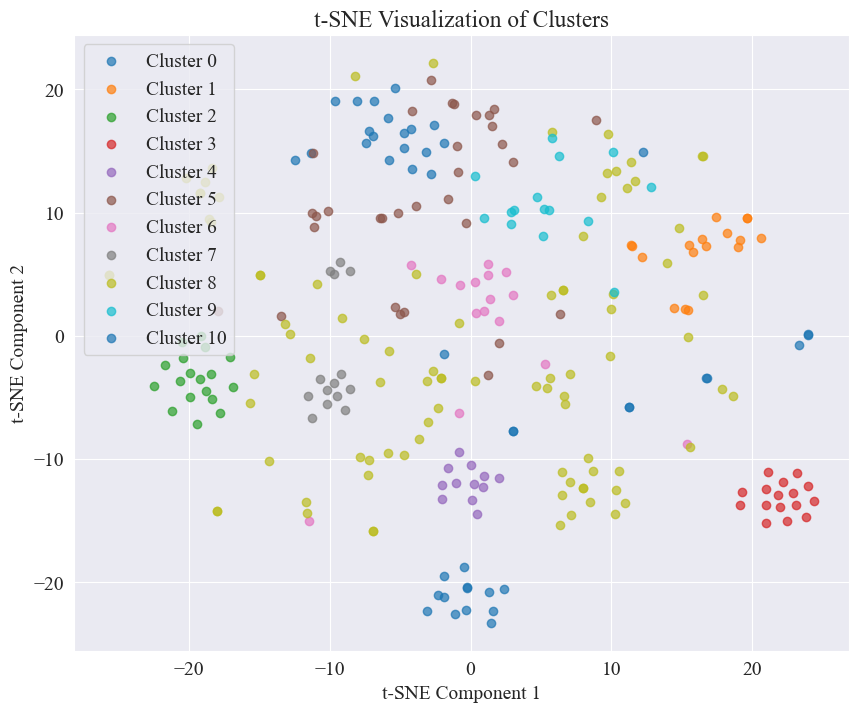
Plurima videri potest fama Weibo in postibus bene fasciculatis, N. 3 et N. 4;
Conglobati eventus
Ut clare ostendas quae in singulis categoriis rumores glomerantur, chart nubes pro singulis categoriis hauritur.

Imprimere aliquem rumorem Weibo contentum, et eventus sunt sequentes.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Botrus analysis rumoris retractationis
Rumores textus contenti conglobati non possunt esse ut bonae famae analysi contenti, sic rumorem retractationis eventum glomerare voluerimus.
Determinare optimum pampineis
Usura argumenti cubiti, optime pampineis determina.
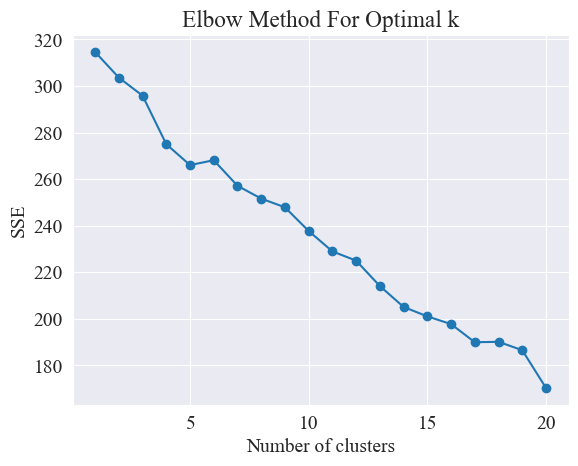
Ex superiore diagrammate cubiti duo cubiti determinari possunt, unus est cum racemus 5 et alter cum racemus est 20. eligo 20 pro pampineis.
Cuius coniurationis dispersas nactas ibil 20 genera talis est.
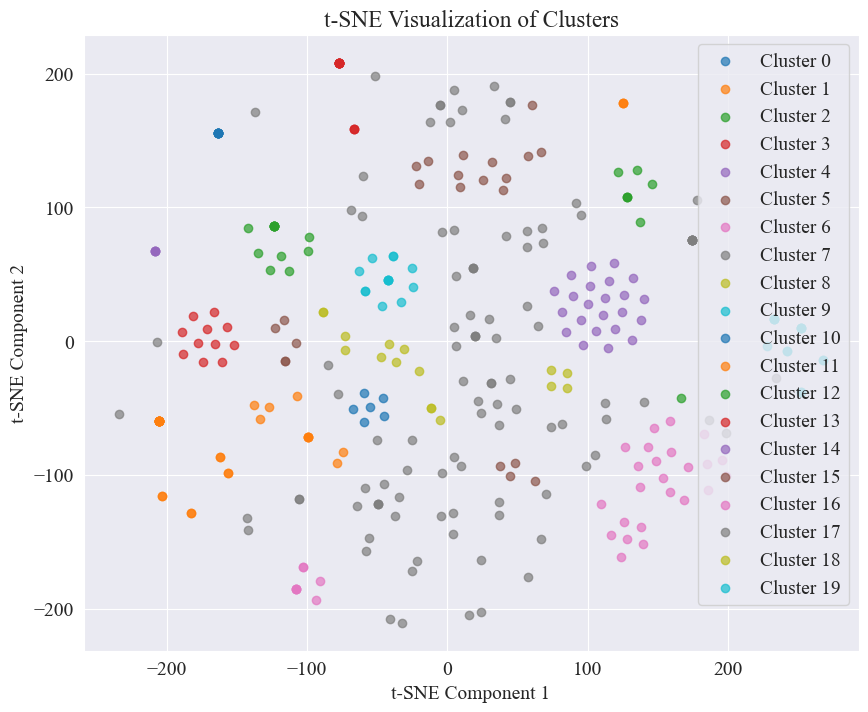
Plerique ex eis bene aggregati sunt, sed VII et XVII genera non bene aggregata sunt.
Conglobati eventus
Ut clare ostendas quos eventus recensionis rumor in singulis categoriis aggregata sint, nubes chart pro singulis categoriis trahitur.

Imprimere aliquem rumorem recensionis eventus.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Propter hoc rumoris deprehensio, notitia proposita quae refutata sunt uti maluimus. fact.json Compara similitudinem inter rumores refutatos et veras opiniones, et articulum refutatum cum summa similitudine rumoris Weibo, ut fundamentum rumoris deprehensio, elige.
Onerare Weibo rumoris notitia et fama refellendi data sets
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Linguae praeexercitatae exempla utere ad rumores rumoresque encode Weibo et famam refellendi titulos in vectoribus emblemandis
Usus est in hoc experimento bert-base-chinese Tamquam exemplar praeexercitatum, forma exercitatio praestare. Exemplar SimCSE adhibetur ad repraesentationem et similitudinem mensurae sententiae semanticae per diversam doctrinam emendare.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Conputat similitudinem
Ad similitudinem calculare, sententia ens in SimCSE similitudinem implicans et nominata similitudinem comprehensivam computare adhibita est.
extract_entitiesMunus extracta entia e textu utens exemplo NER nominata est.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityFunctio nominatam entitatem similitudinis inter duos textus computat.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityMunus componit sententiam inducens et nominavit entitatem similitudinem exemplaris SimCSE ad similitudinem comprehensivam computandi.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Effectus fama deprehensio
Comparando similitudines, mechanismus deprehensio rumor efficitur.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
Output talis est:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Feliciter fundamentum ad rumores refellendos et ad refellendos rumores iudicium dedit.
Data Forma
Hoc experimentum praebet notitias nuntiorum pestilentias relatas CSDC-Nuntiae positas, quae nuntium et commentariolum in prima parte dimidia colligit 2020. Dataset sequentia continet.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
Notitia folder in tres partes dividitur;data,comment。
data Folder aliquot fasciculos continet, quaelibet fasciculus respondet notitiae cuiusdam diei, in formajson . Contentum in hac parte respondet cum textu nuntii nuntiandi (gradatim cum tempore renovabitur), et agri includuntur:
time: nuntium emissio temporis.title:Titulus evangelii.url: Originale inscriptionis nexus nuntiorum.meta: Auctoritas nuntiorum quae sequentes agros includit; content: Auctoritas contenta evangelii.description: Brevis descriptio evangelii.title:Titulus evangelii.keyword: novae palaestrae.type: genus noui.comment Folder aliquot fasciculos continet, quaelibet fasciculus respondet notitiae cuiusdam diei, in formajson . Haec pars contenti respondet commento notitiae nuntiorum (fortasse mora sit circa octo dies inter notitia commentarii et notitia textus nuntiantis).
time: Nuntii emissio tempus et data Data respondet in folder.title: Tituli nuntiorum, with data Data respondet in folder.url: Inscriptio originalis nexus nuntiorum et data Data respondet in folder.comment: Nuntii commenti informationes. Hic campus est ordinatus. Unumquodque elementum ordinatae informationes sequentes continet: area: CENSOR regio.content: comment.nickname: Cognomen CENSOR.reply_to: obiectum commentatoris est.time: Commentarium temporis.Data preprocessing
Data ad nuntium vasa data In notitia preprocessing, necesse estmeta Contentum in dimittitur et in forma DataFrame conditur.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
In retractationis notitia comment In notitia preprocessing, necesse estcomment Contentum in dimittitur et in forma DataFrame conditur.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Onus dataset
Onerare notitias pone secundum praedictas notitias praeprocessing munus.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Vestigium proventuum ostendit longitudinem notitiarum nuntiorum: 502550 et longitudinem commenti notitia: 1534616.
News tempus distribution mutant
Seorsim numerare news_df Numerus nuntiorum menstruae et numerus articulorum nuntiorum per horam per chartis vectibus et chartis lineis repraesentantur.
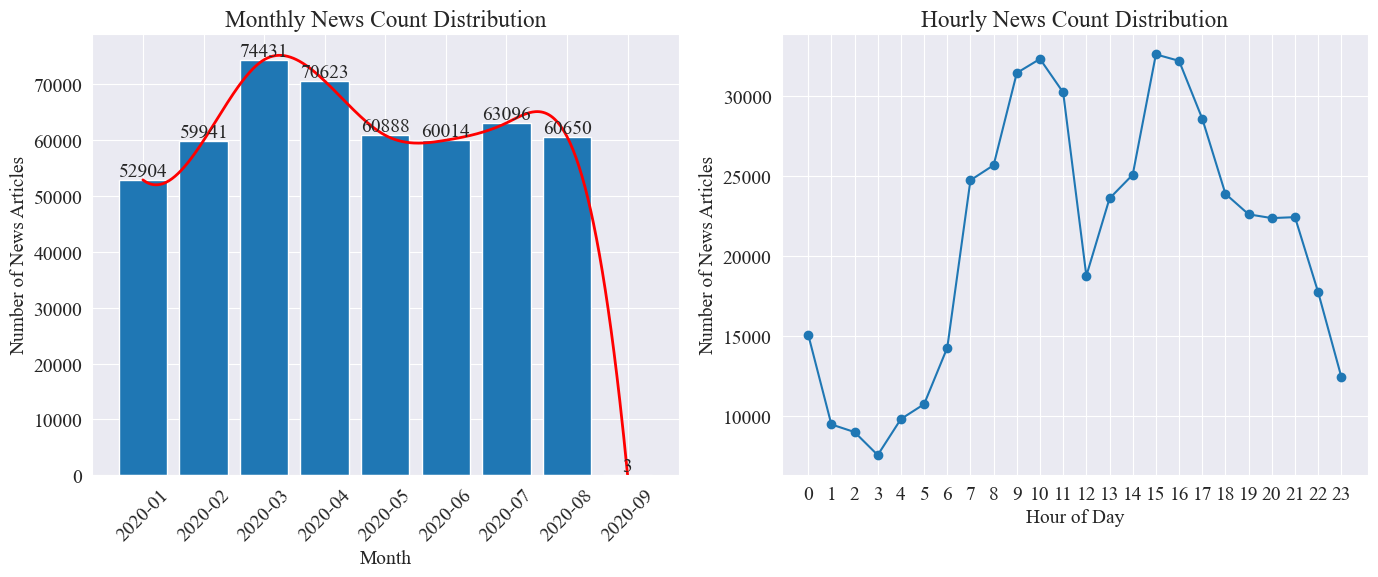
Ut ex superiore figura videri potest, cum ingruente pestilentia, numerus nuntiorum per mensem auctus mense Martio cum 74,000 articulorum nuntiorum apicem attingens, paulatim deflexit et stabilitur ad 60.000 articulorum per mensem, quorum. data mense Septembri facta 3 ante 0:00 articulorum, fortasse non mutant.
Secundum quantitatem per horam distributio nuntiorum, videri potest quod 10 horam et 15 horam in omni die sunt cacumen horae nuntiorum emissio, cum plusquam 30.000 articulorum singulis editis. Hora 12 est confractus prandii, et numerus nuntiorum emittit cacumina et canalibus. Numerus nuntiorum emissiones minimus est inter 0:00 et 5:00 cotidie, cum 3:00 minimus punctus.
News calidum maculis tracking
Hoc experimentum intendit uti methodo nuntiorum extrahendi keywords ad investigandum nuntium maculis calidis in his octo mensibus. In distributione keywords existendi et histogramma ducendo computando, eventus sunt huiusmodi.
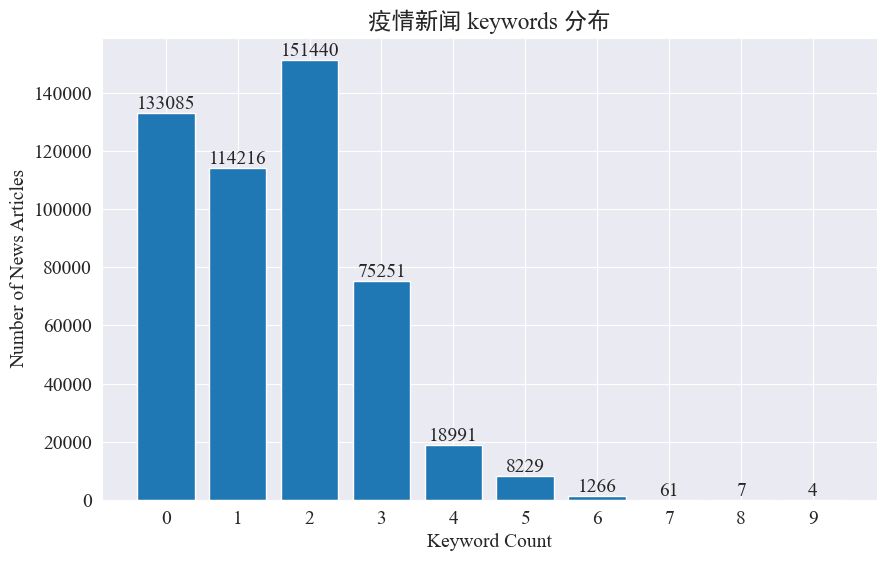
Videri potest pleraque nuntiorum articulorum minora quam 3 keywords habere, et magna proportio articulorum etiam nullas keywords habent. Ergo, debes statisticam colligere et keywords te ipsum pro hotspot sequi.Hoc tempore ususjieba.analyse.textrank() numerare alia.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
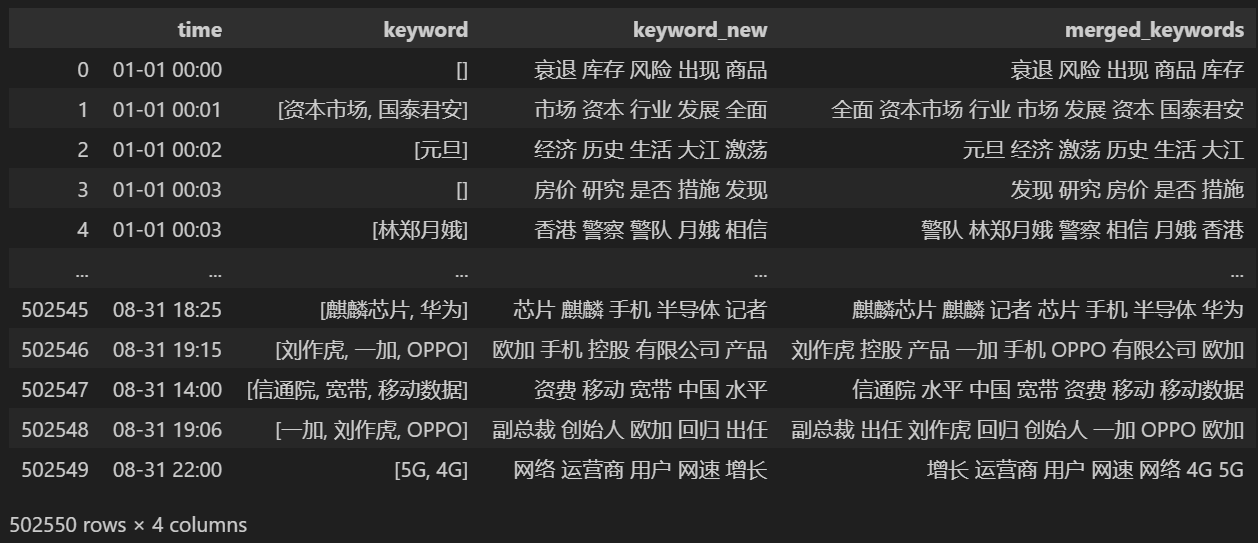
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Computa 5 novas keywords, salvos fac in keyword_new, deinde keywords cum illis confunde, et duplicata verba remove.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Print post bus keyword_data proventus typis expressi sunt.
Ut maculas callidas indagas, frequentiam verbi omnium apparentium verborum numera et computa keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Tum ex supra statistica notitia, cottidianam mutationem verborum calidi trahunt.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Denique, gif chartularum mutationum in keywords in nuntio epidemico consecutus est.
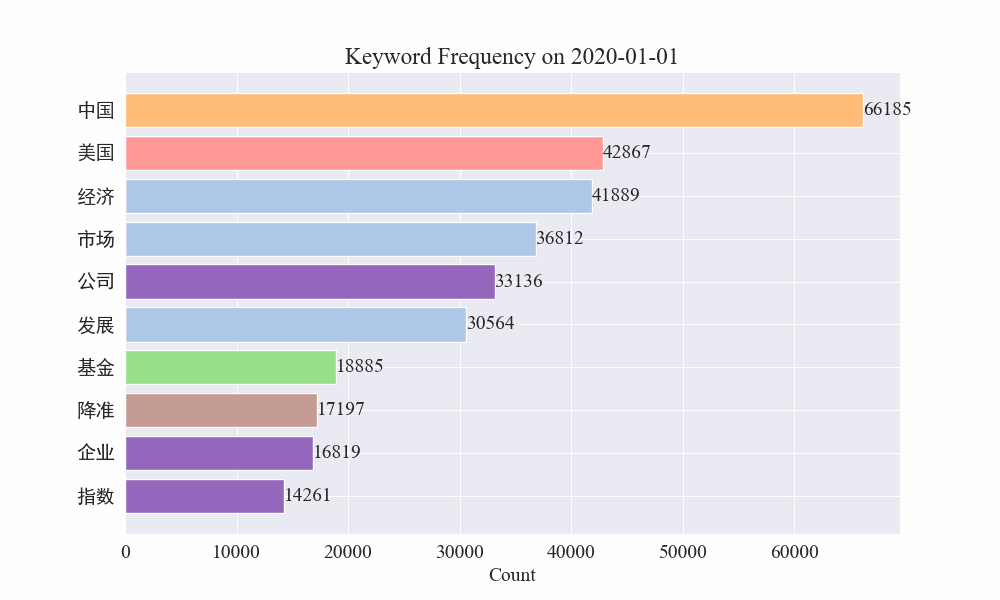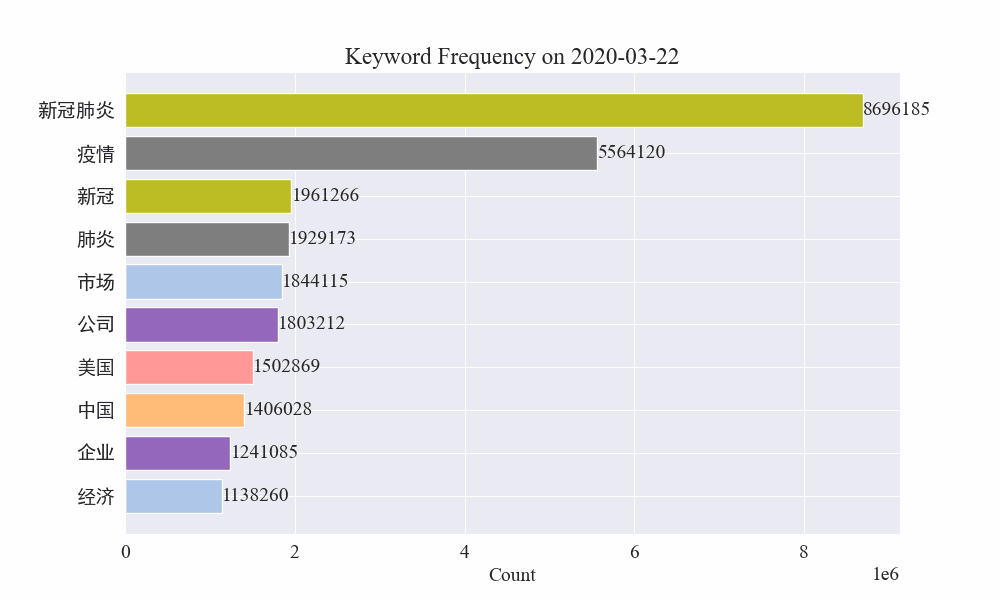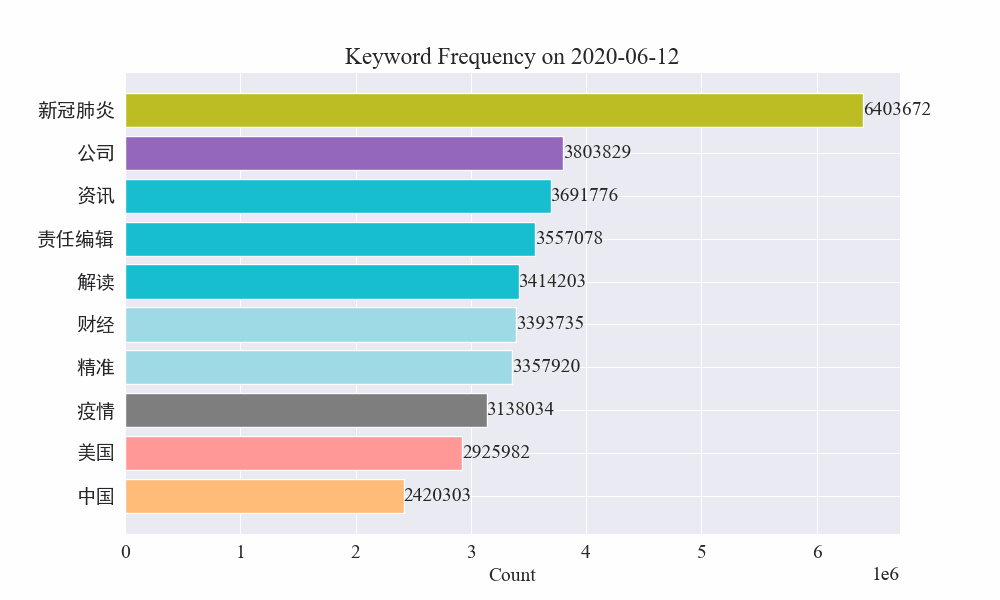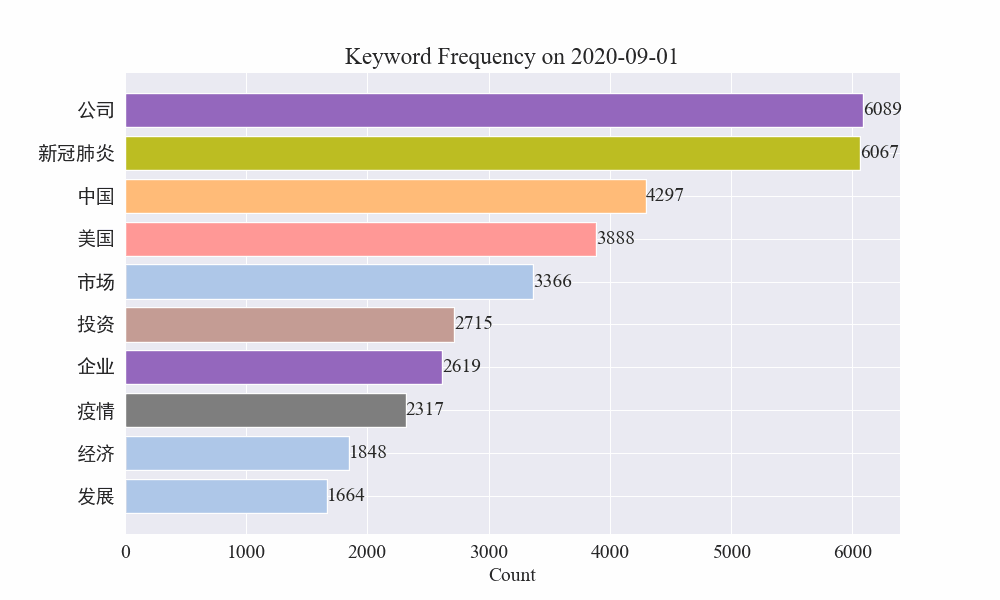
Antequam tumultus fieret, verba "turba" et "Iran" alta manebant. Ex his constare potest quod post ingruentem pestilentiam, numerus nuntiorum pestilentiae actis mense Februario incepit. prima pestilentia unda retardavit et secundo loco factus est.
Haec sectio primum analysin statisticam quantitatis circa novas commentationes agit, ac deinde analysin sensus in varias commentationes perducit.
Cotidiana nuntium comment comitem mutant
Numera flecte numerum commentariorum nuntiorum, utere chartis vectis ad repraesentandum eam, et ad proximam curvam ducendam.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Tabula statistica numerorum commentariorum cotidianorum nuntiorum sic trahitur.
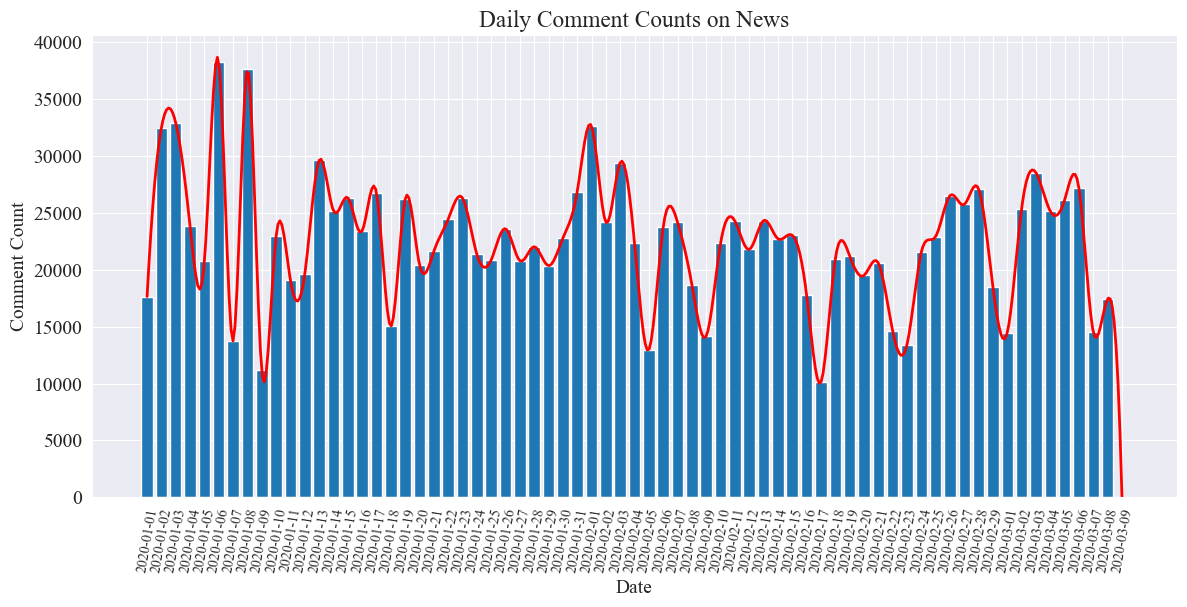
Videri potest numerum nuntiorum commentariorum in pestilentia inter 10,000 et 40,000 fluctuasse, cum mediocris circiter 20000 commentariorum per diem.
Pestilentia nuntium mutant in regione
per provinciam comment_df['province'] Numera nuntiorum in unaquaque provincia et numerum notionum de pestilentia nuntiorum in unaquaque provincia computa.
Primum, debes transire comment_df['province'] Extract notitia provinciae.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Deinde, ex data statistica innixa, chartula ducta est ostendens proportionem nuntiorum commentariorum in unaquaque provincia.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

In hoc experimento etiam nos usi sumus pyecharts.charts of*Map Component, quod machinatur distributio numeri commentaria in chartam Sinarum per provinciam.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
In HTML consecuto, distributio numerorum commentationum de epidemico nuntiorum in unaquaque provincia in Sinis talis est.
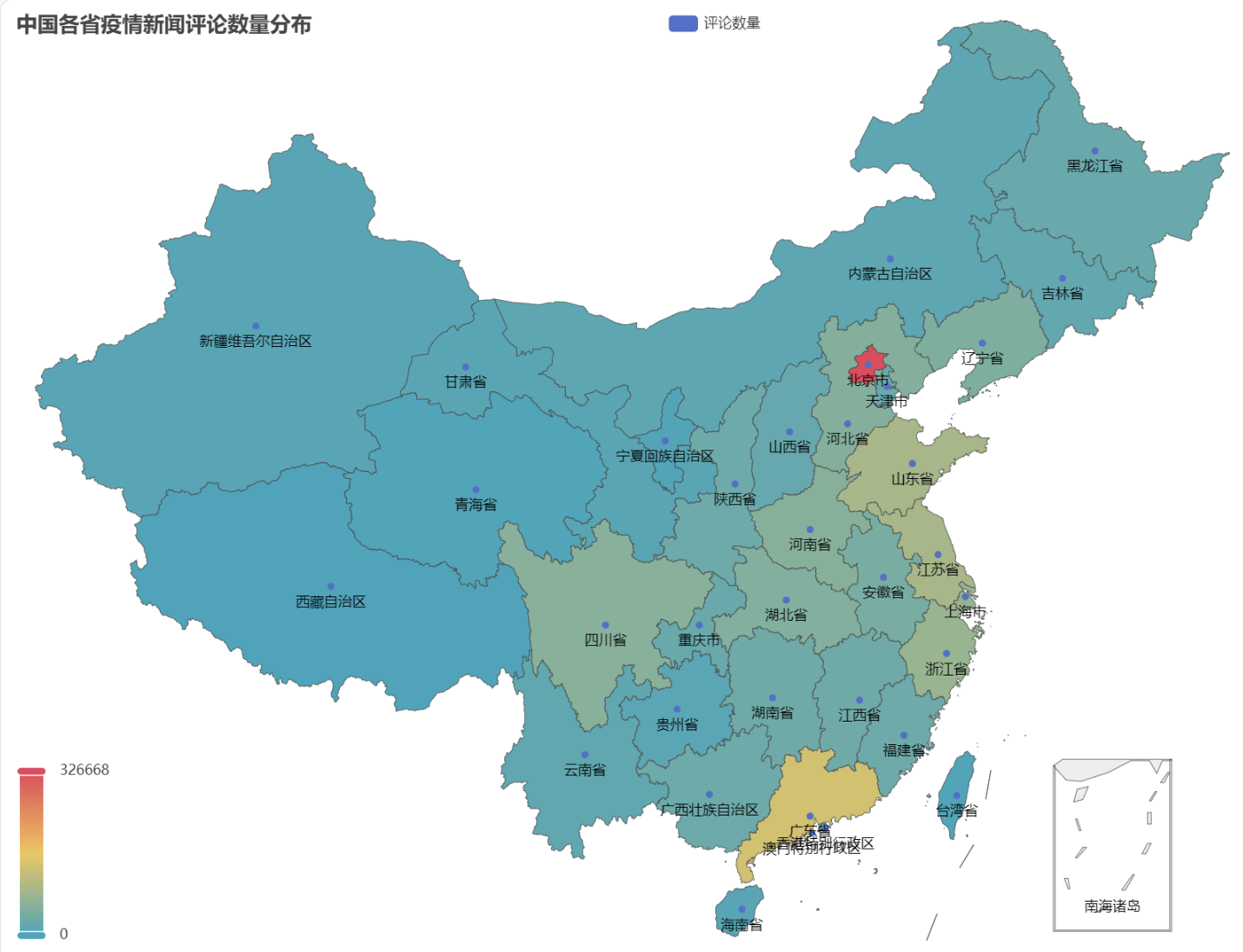
In pestilentia videri potest, numerum commentariorum in Beijing pro summa proportione computatum, Guangdong provinciam secutum esse, et numerum commentariorum in aliis provinciis etiam relative fuisse.
epidemiaSententia analysis review
Hoc experimento utitur bibliotheca NLP ad textum Sinensem expediendum SnowNLP analysin, sensus Sinenses efficiendi, singulas commentationes resolvere ac correspondentes daresentiment Valor, valor inter 0 et 1, quo propius 1, eo magis positivus, eo propius 0, eo magis negativus est.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
In hoc experimento, 0.5 pro limine ponitur. Quidquid maius hac valore est commentum positivum est, et aliquid minus quam hoc valore commentum negativum est. Scribere codicem, analysin analysin trahunt chartam nuntiorum diurnorum, et numerum commentorum positivorum computa et numerum commentariorum negativorum in cotidiano nuntio pretii.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
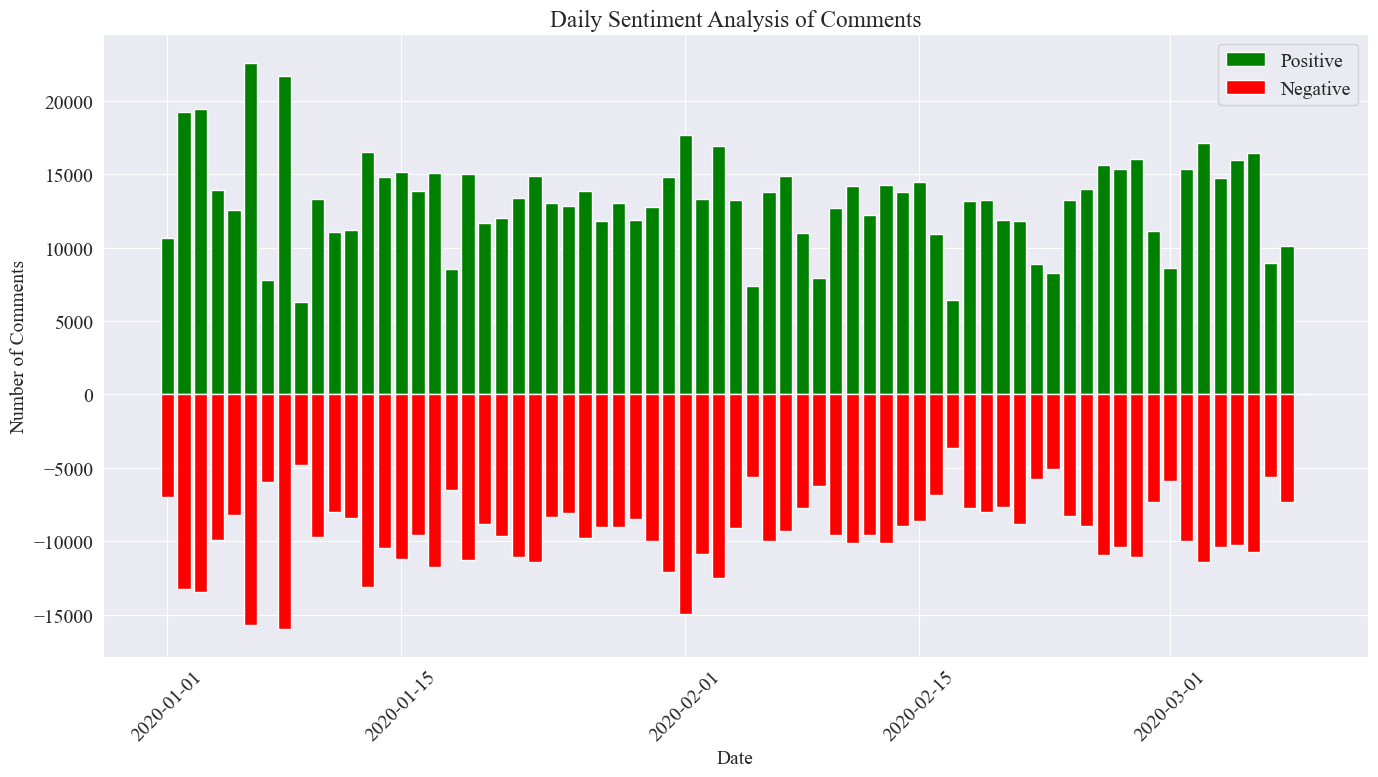
Postrema imago statistica est ut supra ostensum est. Videri potest commentarios positivas in pestilentia paulo altiores esse quam commentationes negativas rem publicam magis positivum habere erga pestilentiam.
Sententia analysis commentaria in regionem
Computando proportionem commentorum positivorum in unaquaque provincia et regione missae, graphi proportionis commentorum positivorum in unaquaque regione devenitur.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
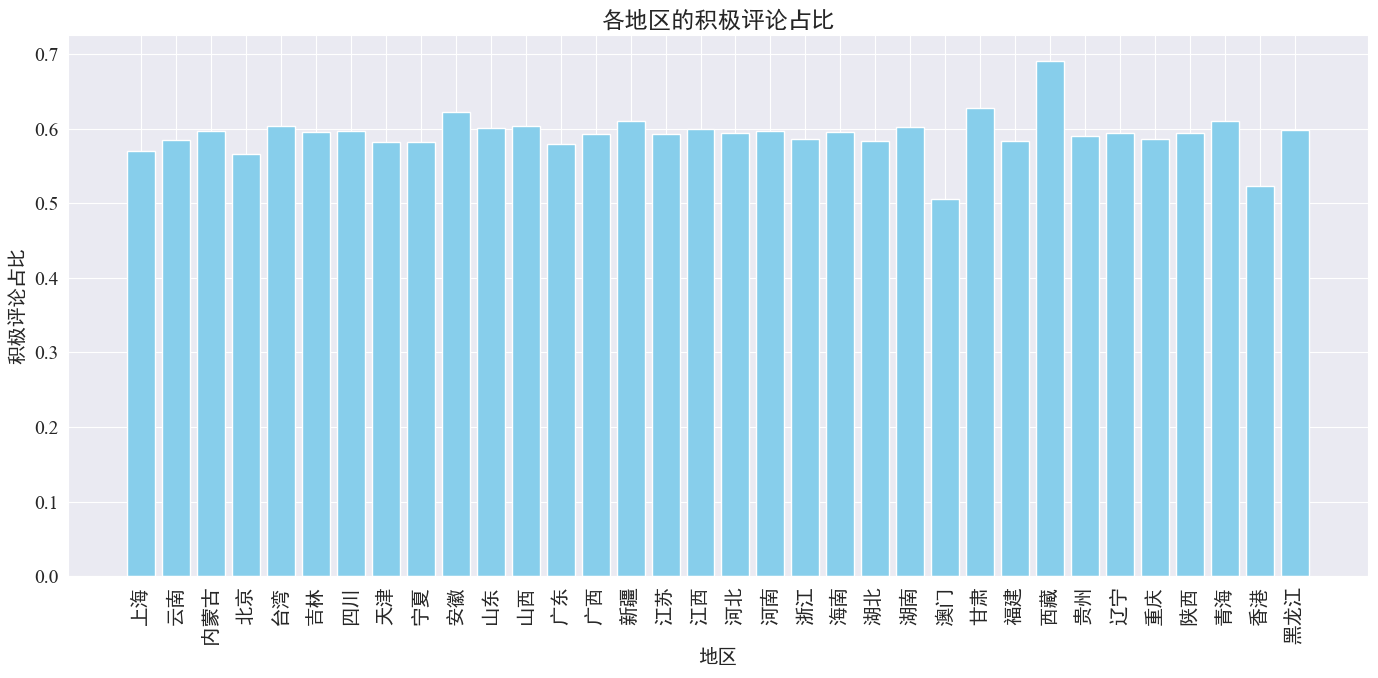
Proportio commentorum positivorum in plerisque provinciis, ut ex superiore figura videri potest, est circa 60%. LXX%.
Ex superioribus commentationis distributione, videre possumus commentarios in continenti Sinis commentationes plerumque affirmativas esse, cum commentationes negativae in Hong Kong et Macao significanter auctae sint parva magnitudine exempli in Tibet.
News Comments Word Cloud Chart Drawing
Verbum nubis schemata omnium commentorum, commentorum positivorum et commentorum negativorum separatim numerabantur schemata concinnata.

Ex his constare potest quod plerique commentationes in pestilentia relative simplices sunt, ut "haha", "bona", etc. In commentationibus affirmativis, videre potes verba hortatoria ut "Veni in Sina", "Veni in Wuhan". , etc., at in commentis negativis inveniuntur reprehensiones, ut "Haha" et "Difficile est facere patriam locupletem".

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones in technologia progressus ad futuram referentiam.
