2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
कोविड-१९ महामारी अस्माकं प्रत्येकस्य हृदयं प्रभावितं करोति अस्मिन् सन्दर्भे वयं सामाजिकगणनाविधिना सह महामारीसम्बद्धानां वार्तानां, अफवानां च विश्लेषणं कृत्वा सहायतां कर्तुं प्रयतेममहामारी सूचना अनुसंधानम्। इदं कार्यं मुक्तसमाप्तं कार्यं वयं महामारीयाः समये सामाजिकदत्तांशं प्रदामः तथा च छात्रान् समाचारात्, अफवाः, कानूनीदस्तावेजानां च सामाजिकप्रवृत्तीनां विश्लेषणं कर्तुं प्रोत्साहयामः। (युक्तिः - दत्तांशविश्लेषणार्थं कक्षायां ज्ञातानां पद्धतीनां उपयोगं कुर्वन्तु, यथा भावविश्लेषणं, सूचनानिष्कासनं, पठनबोधः इत्यादयः)
https://covid19.thunlp.org/ इत्यत्र महामारीसम्बद्धाः अफवाहाः CSDC-Rumor, महामारीसम्बद्धाः चीनीयसमाचाराः CSDC-News, महामारीसम्बद्धाः कानूनी दस्तावेजाः च CSDC-Legal इति नवीनकोरोनामहामारीसम्बद्धाः सामाजिकदत्तांशसूचनाः प्रदाति।
संगृहीतस्य दत्तांशसमूहस्य एषः भागः : १.
(1) 22 जनवरी, 2020 तः आरभ्यवेइबो मिथ्या सूचनादत्तांशेषु वेइबो-पोस्ट्-मध्ये मिथ्या-सूचना, प्रकाशकाः, श्वसनकर्तारः, परीक्षणसमयः, परिणामाः अन्याः च सूचनाः इति गण्यन्ते, तेषां सामग्रीः अस्ति .
(2) Tencent इत्यस्य अफवाहसत्यापनमञ्चः तथा च Dingxiangyuan इत्यस्य 18 जनवरी, 2020 तः मिथ्यासूचनादत्तांशः, यत्र अफवाहस्य सामग्रीः इत्यादीनि सूचनाः सन्ति या सम्यक् अथवा असत्यं मन्यते, समयः, अफवाहः अस्ति वा इति निर्णयस्य आधारः च, As of १ मार्च २०२० दिनाङ्के अफवाहदत्तांशस्य ५०७ खण्डाः सन्ति, येषु १२४ तथ्यात्मकदत्तांशः अस्ति ।
दत्तांशसमूहस्य एषः भागः २०२० तमस्य वर्षस्य जनवरी-मासस्य प्रथमदिनात् आरभ्य वार्तानां आँकडानां संग्रहणं करोति, यत्र समाचारस्य शीर्षकं, सामग्रीः, कीवर्डः, अन्याः सूचनाः च सन्ति । महामारीकाले समाचारदत्तांशस्य विश्लेषणं अध्ययनं च कर्तुं शोधकर्तृणां सहायतायै उपयुज्यते ।
एषः दत्तांशः तः अस्ति CAIL एकत्रित-अनामिका-कानूनी-दस्तावेज-आँकडानां मध्ये कुलम् १,२०३ ऐतिहासिक-महामारी-सम्बद्धानां भागानां परीक्षणं कृतम् महामारीकाले प्रासंगिककानूनीविषयेषु अनुसन्धानम्।
इदं असाइनमेण्ट् एकं मुक्तं असाइनमेण्ट् अस्ति, वयं तस्मात् आरभेमः
अन्येषु पक्षेषु नियुक्तीनां ग्रेडिंग्।
[1] ट्विट्टर् इत्यत्र सूचनायाः विश्वसनीयता। in Proceedings of WWW, 2011.
[2] पुनरावर्तनीय-तंत्रिका-जालयुक्तैः सूक्ष्मब्लॉग्-तः अफवाः अन्वेष्टुं । in Proceedings of IJCAI, 2016.
[3] गलतसूचनापरिचयार्थं एकः परिभ्रमणात्मकः उपायः । in Proceedings of IJCAI, 2017.
[4] अन्तर्जालद्वारा सत्यानां मिथ्यावार्तानां च प्रसारः। विज्ञान, 2018.
[5] जालपुटे सामाजिकमाध्यमेषु च मिथ्यासूचनाः : सर्वेक्षणम् । arXiv पूर्वमुद्रण, 2018.
[6] आङ्ग्लशब्दानां कृते भावात्मकमान्यतानां लक्षणीकरणं विच्छिन्नभावनात्मकवर्गैः। व्यवहार अनुसंधान विधियाँ, 2007.
अयं प्रयोगः महामारी-सम्बद्धं अफवाह-आँकडा-समूहं CSDC-Rumor प्रदाति दत्तांशसमूहस्य सामग्रीं विश्लेष्य वयं प्रथमं आँकडा-समूहे परिमाणात्मक-सांख्यिकीय-विश्लेषणं कर्तुं चयनं कुर्मः, ततः अफवाहानाम् अर्थ-विश्लेषणं कार्यान्वितुं समूहीकरणस्य उपयोगं कुर्मः, अन्ते च क अफवाहपरिचयप्रणाली।
दत्तांश प्रारूप
अयं प्रयोगः महामारीसम्बद्धं अफवाहदत्तांशसमूहं CSDC-Rumor इति प्रदाति, यत् वेइबो-मिथ्यासूचनादत्तांशं अफवाहखण्डनदत्तांशं च एकत्रयति । दत्तांशसमूहे निम्नलिखितम् अस्ति ।
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
वेइबो मिथ्या सूचनाक्रमशः द्वारा rumor_weibo तथाrumor_forward_comment समाननामद्वयम्json सञ्चिकायां वर्णितम् ।rumor_weibo मध्यंjson विशिष्टक्षेत्राणि यथा - १.
rumorCode: अफवाहस्य अद्वितीयः कोडः, यस्य माध्यमेन अफवाहस्य प्रतिवेदनपृष्ठं प्रत्यक्षतया प्राप्तुं शक्यते।title: रिपोर्ट् कृतस्य अफवाहस्य शीर्षकसामग्री।informerName: रिपोर्टरस्य वेइबो नाम।informerUrl: रिपोर्टरस्य वेइबो लिङ्क्।rumormongerName: अफवां प्रकाशितस्य व्यक्तिस्य वेइबो नाम।rumormongerUr: अफवाः यः व्यक्तिः स्थापितः तस्य वेइबो लिङ्क्।rumorText: अफवाह सामग्री।visitTimes: एतस्याः अफवाः कियत्वारं गताः।result: अस्याः अफवाहसमीक्षायाः परिणामाः।publishTime: यदा अफवाः ज्ञातः तदा समयः।related_url: अस्याः अफवाः सम्बद्धानां प्रमाणानां, नियमानाम् इत्यादीनां लिङ्कानां।rumor_forward_comment मध्यंjson विशिष्टक्षेत्राणि यथा - १.
uid: उपयोक्तृ-परिचयः प्रकाशयन्तु।text: पोस्टस्क्रिप्ट् टिप्पणीं कुर्वन्तु अथवा अग्रे प्रेषयन्तु।date: विमोचनसमयः।comment_or_forward: द्विचक्रिका, वा comment, अन्यतर forward, सन्देशः टिप्पणी अस्ति वा अग्रे प्रेषितः उत्तरलिपिः इति सूचयति ।टेन्सेन्ट् तथा बकाइन गार्डन् मिथ्यासूचनासामग्रीस्वरूपं अस्ति : १.
date: कालःexplain: अफवाहप्रकारःtag:अफवाह टैगabstract: अफवाः सत्यापयितुं प्रयुक्ता सामग्रीrumor: अफवाःदत्तांशपूर्वसंसाधनम्
उत्तीर्णः json.load() अफवाहं Weibo आँकडा पृथक् निष्कासयन्तुweibo_data अफवाभिः सह दत्तांशं अग्रे प्रेषयितुं टिप्पणीं कुर्वन्तुforward_comment_data , ततः DataFrame प्रारूपेण परिवर्तयन्तु । समाननामयुक्तौ सञ्चिकाद्वयं, Weibo लेखः, Weibo टिप्पणी अग्रेसारणं च परस्परं सङ्गच्छते rumor_forward_comment फोल्डर् मध्ये आँकडानां संसाधनं कुर्वन्, अनन्तरं मेलार्थं rumorCode योजयन्तु ।
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
अस्मिन् खण्डे महामारी-अफवाह-वेइबो-आँकडानां वितरणस्य विशिष्टा अवगमनं प्राप्तुं परिमाणात्मक-सांख्यिकीय-विश्लेषणस्य उपयोगः भवति ।
अफवाः कियत्वारं गताः इति आँकडानि
सांख्यिकी weibo_df['visitTimes'] अभिगमसमयानां वितरणं तथा तत्सम्बद्धं हिस्टोग्रामं आकर्षयितुं परिणामाः निम्नलिखितरूपेण सन्ति।
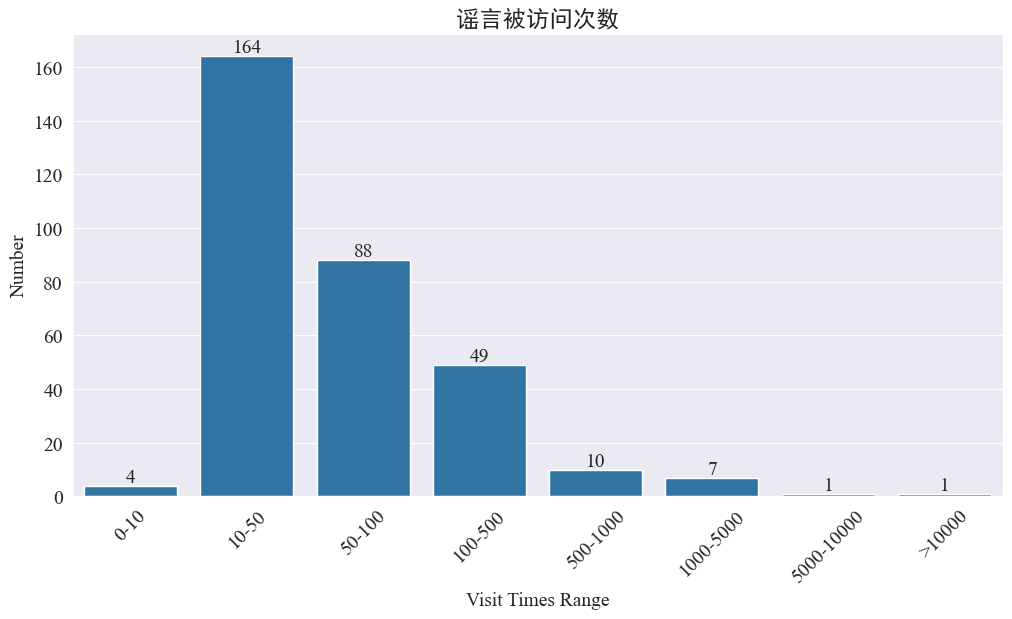
वेइबो-नगरस्य भ्रमणसङ्ख्यायाः अनुसारं अधिकांशः महामारी-अफवाः वेइबो-इत्यत्र ५०० वारात् न्यूनाः गताः सन्ति, यत्र १०-५० वाराः सर्वाधिकं भागं भवन्ति परन्तु वेइबो इत्यत्र अपि अफवाः सन्ति येषां प्रवेशः ५,००० तः अधिकवारं कृतः, येषां गम्भीरः प्रभावः अभवत्, कानूनेन च “गम्भीरः” इति मन्यते ।
अफवाहनिर्मातृणां, श्वसनकर्तानां च घटनायाः आँकडानि
सांख्यिकीद्वारा weibo_df['rumormongerName'] तथाweibo_df['informerName'] प्रत्येकं अफवाहप्रकाशकेन प्रकाशितानां अफवानां संख्या, प्रत्येकेन संवाददातृणा निवेदितानां अफवानां संख्या च निम्नलिखितरूपेण प्राप्यते।
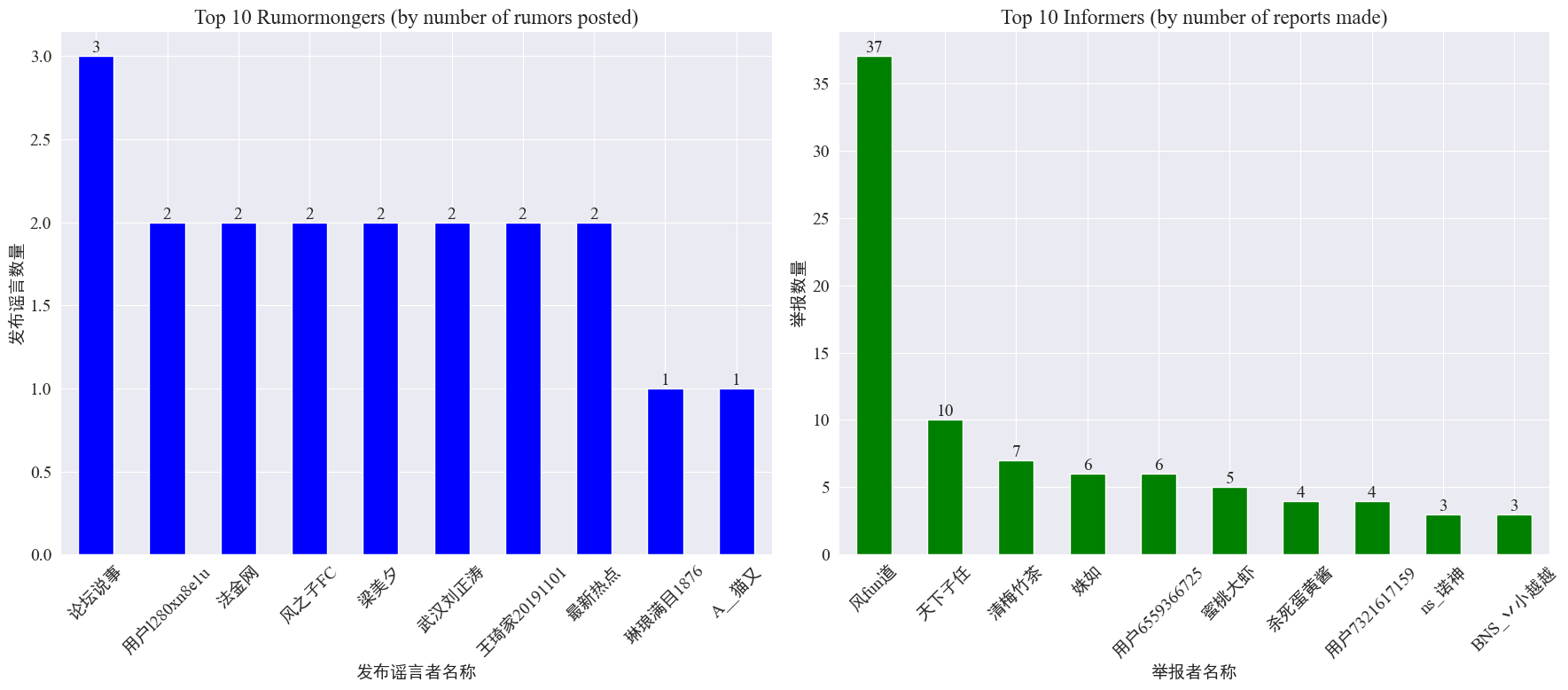
द्रष्टुं शक्यते यत् अफवाहनिर्मातृभिः स्थापितानां अफवानां संख्या कतिपयेषु जनासु केन्द्रीभूता नास्ति, परन्तु तुल्यकालिकरूपेण समः अस्ति यस्मिन् खाते सर्वाधिकं अफवाः प्रकाशिताः ते त्रीणि अफवाः वेइबो-पोस्ट्-पत्राणि प्रकाशितवन्तः। शीर्ष १० श्वसनकर्तासु प्रत्येकं न्यूनातिन्यूनं ३ अफवालेखान् प्रतिवेदितवान् तेषु वेइबो इत्यत्र श्वसनकर्ताभिः अफवाः ज्ञापितानां संख्या अन्येषां उपयोक्तृणां अपेक्षया महत्त्वपूर्णतया अधिका आसीत्, ३७ लेखाः यावत् अभवत्
उपर्युक्तदत्तांशस्य आधारेण प्रेक्षकाः अफवाहानाम् अन्वेषणं सुलभं कर्तुं बहुसंख्याकाः अफवाः सन्ति इति खातानां रिपोर्टिंग् इत्यत्र ध्यानं दातुं शक्नुवन्ति ।
अफवाहं अग्रे प्रेषयितुं टिप्पणीनां वितरणस्य आँकडा
अफवाहस्य अग्रे प्रेषणस्य मात्रायाः टिप्पणीमात्रायाः च वितरणस्य गणनाद्वारा निम्नलिखितवितरणप्रतिबिम्बं प्राप्यते ।

द्रष्टुं शक्यते यत् अधिकांशस्य अफवाः वेइबो इत्यत्र टिप्पणीनां पुनः पोस्ट् इत्यस्य च संख्या १० गुणाभ्यन्तरे अस्ति, अधिकतमं टिप्पणीनां संख्या ५०० तः अधिका न भवति, अधिकतमं पुनः पोस्ट् इत्यस्य संख्या १०,००० तः अधिका भवति अन्तर्जालप्रबन्धनकानूनानुसारं यदि कश्चन अफवा ५०० वारं अधिकं अग्रे प्रेष्यते तर्हि सा "गम्भीर" स्थितिः इति मन्यते ।
अफवाह पाठ समूह विश्लेषण
अयं भागः वेइबो अफवाहग्रन्थेषु आँकडापूर्वसंसाधनं करोति, तथा च वेइबो अफवाः कुत्र केन्द्रीकृताः इति द्रष्टुं शब्दविभाजनस्य अनन्तरं समूहविश्लेषणं करोति ।
दत्तांशपूर्वसंसाधनम्
प्रथमं, अफवाहदत्तांशपाठं स्वच्छं कुर्वन्तु, पूर्वनिर्धारितमूल्यानि निष्कासयन्तु, तथा च... <> संलग्नलिङ्कसामग्री।
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
ततः चीनी-विरामशब्दान् लोड् कुर्वन्तु, स्थगितशब्दाः च उपयुञ्जते cn_stopwords इति ,उपयुञ्जताम्jieba दत्तांशस्य शब्दविभाजनप्रक्रियाकरणं कार्यान्वितं कृत्वा पाठसदिशीकरणं कुर्वन्तु।
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
उत्तमं समूहीकरणं निर्धारयन्तु
कोणविधिना उत्तमाः समूहाः निर्धारिताः भवन्ति ।
कोहनीविधिः समूहविश्लेषणे समूहानां इष्टतमसङ्ख्यां निर्धारयितुं प्रयुक्ता पद्धतिः अस्ति । इदं Sum of Squared Errors (SSE) इत्यस्य समूहसङ्ख्यायाः च सम्बन्धे आधारितम् अस्ति । SSE इति समूहे सर्वेभ्यः दत्तांशबिन्दुभ्यः यस्मिन् समूहकेन्द्रे सः अन्तर्भवति तस्य वर्गीकृत-यूक्लिडियन-अन्तराणां योगः अस्ति यत् एतत् समूहीकरणस्य प्रभावं प्रतिबिम्बयति: एसएसई यावत् लघुः भवति, तावत् उत्तमः समूहीकरणप्रभावः भवति
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
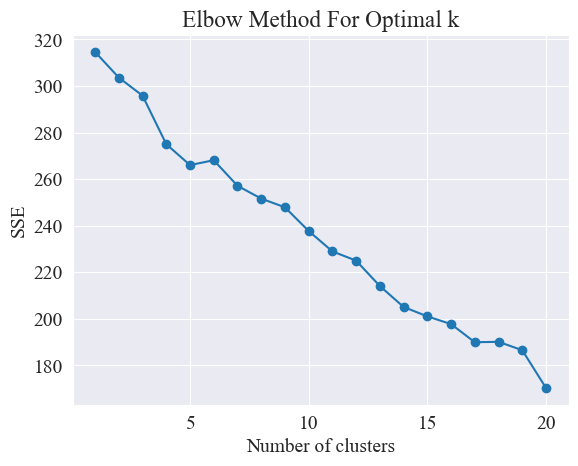
कोहनीविधिः "कोहनी" इत्यस्य अन्वेषणेन समूहानां इष्टतमसङ्ख्यां निर्धारयति, अर्थात् वक्रस्य उपरि एकं बिन्दुं अन्वेष्टुं यस्य अनन्तरं एसएसई-क्षयस्य गतिः महत्त्वपूर्णतया मन्दं भवति, अतः एषः बिन्दुः बाहुस्य कोहनी इव भवति name " कोहनी विधि "। प्रायः एषः बिन्दुः समूहानां इष्टतमसंख्या इति मन्यते ।
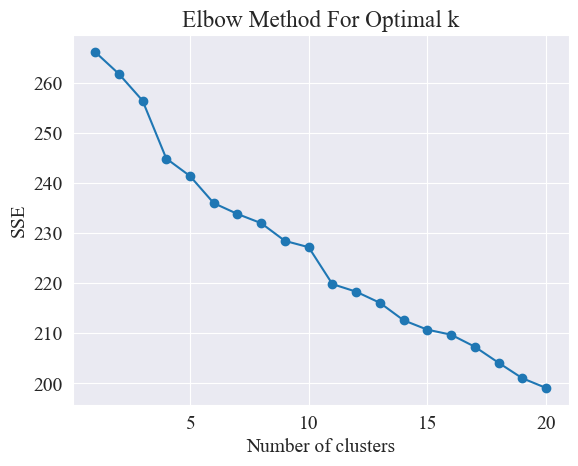
उपर्युक्तचित्रात् कोणस्य समूहीकरणमूल्यं ११ इति निर्धारितं भवति, तदनुरूपं प्रकीर्णनप्लॉटं च आकृष्यते
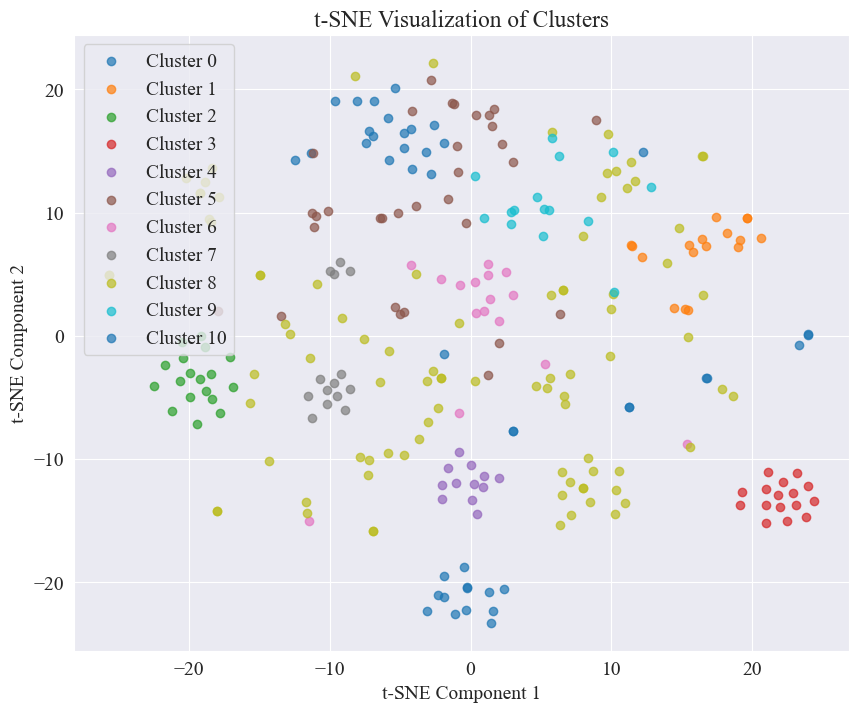
द्रष्टुं शक्यते यत् अधिकांशः अफवाः वेइबो-पोस्ट् सुसमूहीकृताः सन्ति, क्रमाङ्कः ३, क्रमाङ्कः ४ च केचन व्यापकरूपेण वितरिताः सन्ति, सुसमूहाः न सन्ति, यथा क्रमाङ्कः ५, क्रमाङ्कः ८ च
क्लस्टरिंग परिणाम
प्रत्येकस्मिन् वर्गे काः अफवाः समूहीकृताः इति स्पष्टतया दर्शयितुं प्रत्येकस्य वर्गस्य कृते मेघचार्टः आकृष्यते ।

किञ्चित् सुसमूहीकृतं अफवाहं वेइबो सामग्रीं मुद्रयन्तु, परिणामाः च निम्नलिखितरूपेण सन्ति।
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
अफवाहसमीक्षापरिणामानां समूहविश्लेषणम्
अफवाहपाठसामग्रीणां समूहीकरणं अफवाहसामग्रीविश्लेषणार्थं तावत् उत्तमं न भवेत्, अतः वयं अफवाहसमीक्षापरिणामानां समूहीकरणं चितवन्तः।
उत्तमं समूहीकरणं निर्धारयन्तु
कोणस्य प्लॉट् इत्यस्य उपयोगेन उत्तमं समूहीकरणं निर्धारयन्तु ।
उपरिष्टात् कोणचित्रात् द्वौ कोणौ निर्धारयितुं शक्यते, एकः यदा समूहीकरणं ५ भवति, अपरः यदा समूहीकरणं २० भवति तदा अहं समूहीकरणार्थं २० चिनोमि
२० वर्गानां समूहीकरणेन प्राप्तः प्रकीर्णनप्लॉटः निम्नलिखितरूपेण अस्ति ।
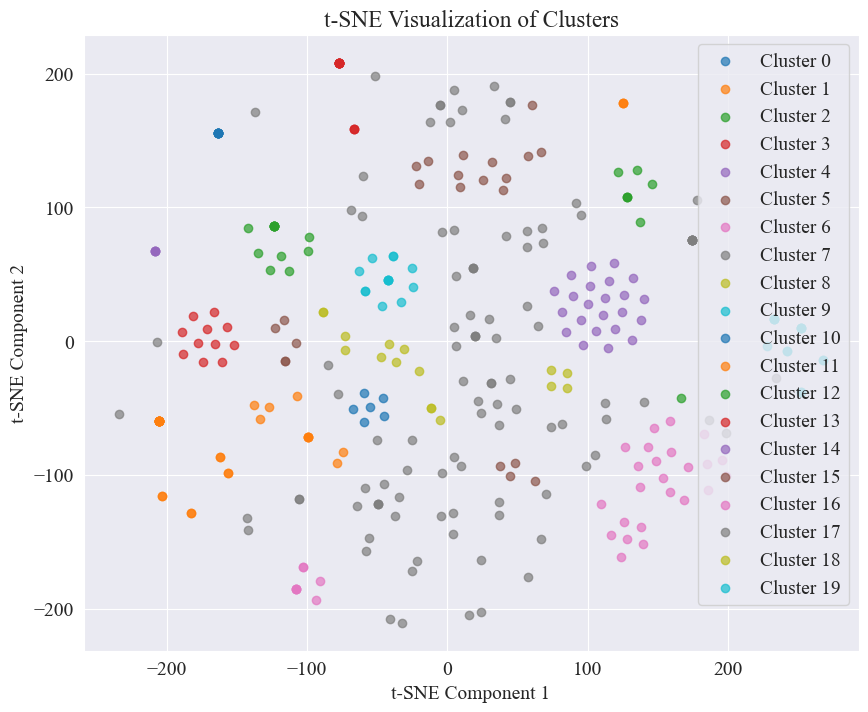
तेषु अधिकांशः सुसमूहः इति द्रष्टुं शक्यते, परन्तु ७, १७ च वर्गः सुसमूहः नास्ति ।
क्लस्टरिंग परिणाम
प्रत्येकस्मिन् वर्गे के अफवाहसमीक्षापरिणामाः समूहीकृताः इति स्पष्टतया दर्शयितुं प्रत्येकस्मिन् वर्गे मेघचार्टं आकृष्यते परिणामाः निम्नलिखितरूपेण सन्ति ।

केचन सुसमूहीकृताः अफवाहसमीक्षापरिणामाः मुद्रयन्तु परिणामाः निम्नलिखितरूपेण सन्ति।
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
अस्य अफवापरिचयस्य कृते वयं खण्डितानां दत्तांशसमूहानां उपयोगं कर्तुं चिनोमः । fact.json खण्डित-अफवानां वास्तविक-अफवानां च साम्यस्य तुलनां कुर्वन्तु, अफवाह-परिचयस्य आधाररूपेण अफवाह-वेइबो-इत्यस्य सर्वोच्चसादृश्यं युक्तं खण्डितं लेखं च चिनुत
Weibo अफवाहदत्तांशं लोडं कुर्वन्तु तथा च अफवाहं खण्डनं दत्तांशसमूहान्
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
वेइबो-अफवाः अफवाह-खण्डन-शीर्षकाणां च एम्बेडिंग् वेक्टर्-मध्ये एन्कोड् कर्तुं पूर्व-प्रशिक्षितानां भाषा-प्रतिमानानाम् उपयोगं कुर्वन्तु
अस्मिन् प्रयोगे प्रयुक्तः bert-base-chinese पूर्वप्रशिक्षितप्रतिरूपत्वेन आदर्शप्रशिक्षणं कुर्वन्तु। विपरीतशिक्षणद्वारा वाक्यशब्दार्थविज्ञानस्य प्रतिनिधित्वं समानतामापनं च सुधारयितुम् SimCSE प्रतिरूपस्य उपयोगः भवति ।
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
सादृश्यं गणयतु
सादृश्यस्य गणनायै SimCSE मॉडलस्य वाक्यनिक्षेपणं नामकृतसत्तासादृश्यं च व्यापकसादृश्यस्य गणनाय उपयुज्यते ।
extract_entitiesफंक्शन् NER मॉडल् इत्यस्य उपयोगेन पाठात् नामकृतानि सत्तानि निष्कासयति ।
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityफंक्शन् द्वयोः ग्रन्थयोः मध्ये नामकृतं सत्तासादृश्यं गणयति ।
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityफंक्शन् व्यापकसादृश्यस्य गणनां कर्तुं SimCSE मॉडलस्य वाक्यं एम्बेडिंग् तथा नामकृतं सत्तासादृश्यं च संयोजयति ।
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
अफवाहपरिचयं कार्यान्वितं कुर्वन्तु
समानतायाः तुलनां कृत्वा अफवाहपरिचयतन्त्रं कार्यान्वितं भवति ।
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
उत्पादनं यथा भवति ।
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
सफलतया अफवाः खण्डनस्य आधारं प्राप्य अफवाः खण्डयितुं निर्णयं दत्तवान् ।
दत्तांश प्रारूप
अयं प्रयोगः महामारीसम्बद्धं समाचारदत्तांशसमूहं CSDC-News इति प्रदाति, यत् २०२० तमस्य वर्षस्य प्रथमार्धे वार्तानां टिप्पण्याः च सामग्रीं संग्रहयति । दत्तांशसमूहे निम्नलिखितम् अस्ति ।
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
दत्तांशपुटं त्रयः भागाः विभक्तम् अस्ति : १.data,comment。
data पुटे अनेकाः सञ्चिकाः सन्ति, प्रत्येकं सञ्चिका निश्चिततिथिदत्तांशैः सह सङ्गच्छते, प्रारूपेणjson . अस्मिन् भागे सामग्री वार्तायाः पाठदत्तांशैः सह सङ्गच्छते (तिथिना सह क्रमेण अद्यतनं भविष्यति), क्षेत्रेषु च अन्तर्भवन्ति :
time: समाचारविमोचनसमयः।title:वार्तानां शीर्षकम्।url: वार्तायाः मूलपतेः लिङ्कः।meta: वार्तायाः पाठसूचना, यस्मिन् निम्नलिखितक्षेत्राणि सन्ति- १. content: वार्तायां पाठसामग्री।description: वार्तायाः लघुवर्णनम्।title:वार्तानां शीर्षकम्।keyword: समाचार कीवर्ड।type: वार्ताप्रकारः।comment पुटे अनेकाः सञ्चिकाः सन्ति, प्रत्येकं सञ्चिका निश्चिततिथिदत्तांशैः सह सङ्गच्छते, प्रारूपेणjson . सामग्रीयाः एषः भागः वार्तानां टिप्पणीदत्तांशैः सह सङ्गच्छते (टिप्पणीदत्तांशस्य वार्तापाठदत्तांशस्य च मध्ये प्रायः एकसप्ताहस्य विलम्बः भवितुम् अर्हति ।
time: समाचारविमोचनसमयः, तथा... data पुटे विद्यमानस्य दत्तांशस्य अनुरूपं भवति ।title: समाचारस्य शीर्षकं, सह data पुटे विद्यमानस्य दत्तांशस्य अनुरूपं भवति ।url: वार्तायाः मूलपतेः लिङ्कः, तथा च data पुटे विद्यमानस्य दत्तांशस्य अनुरूपं भवति ।comment: News comment information.इदं क्षेत्रं सरणी अस्ति । area: समीक्षकक्षेत्रम्।content:टिप्पणी।nickname: समीक्षकस्य उपनाम ।reply_to: भाष्यकारस्य उत्तराक्षेपः यदि नास्ति तर्हि न प्रतिवचनम् इत्यर्थः।time: टिप्पणी समय।दत्तांशपूर्वसंसाधनम्
वार्तालेखानां विषये आँकडा data दत्तांशपूर्वसंसाधनस्य समये एतत् आवश्यकं भवतिmeta इत्यस्मिन् सामग्रीः विमोच्यते, DataFrame प्रारूपेण च संगृहीतः भवति ।
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
समीक्षादत्तांशेषु comment दत्तांशपूर्वसंसाधनस्य समये एतत् आवश्यकं भवतिcomment इत्यस्मिन् सामग्रीः विमोच्यते, DataFrame प्रारूपेण च संगृहीतः भवति ।
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
दत्तांशसमूहं लोडं कुर्वन्तु
उपर्युक्तदत्तांशपूर्वसंसाधनकार्यस्य अनुसारं दत्तांशसमूहं लोड् कुर्वन्तु ।
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
मुद्रितपरिणामेन ज्ञायते यत् वार्तादत्तांशस्य दीर्घता: ५०२५५०, टिप्पणीदत्तांशस्य दीर्घता च १५३४६१६ ।
समाचार समय वितरण सांख्यिकी
पृथक् पृथक् गणयन्तु news_df मासिकवार्तालेखानां संख्या प्रतिघण्टां वार्तालेखानां संख्या च बारचार्टैः रेखाचार्टैः च दर्शिता भवति परिणामाः निम्नलिखितरूपेण सन्ति ।
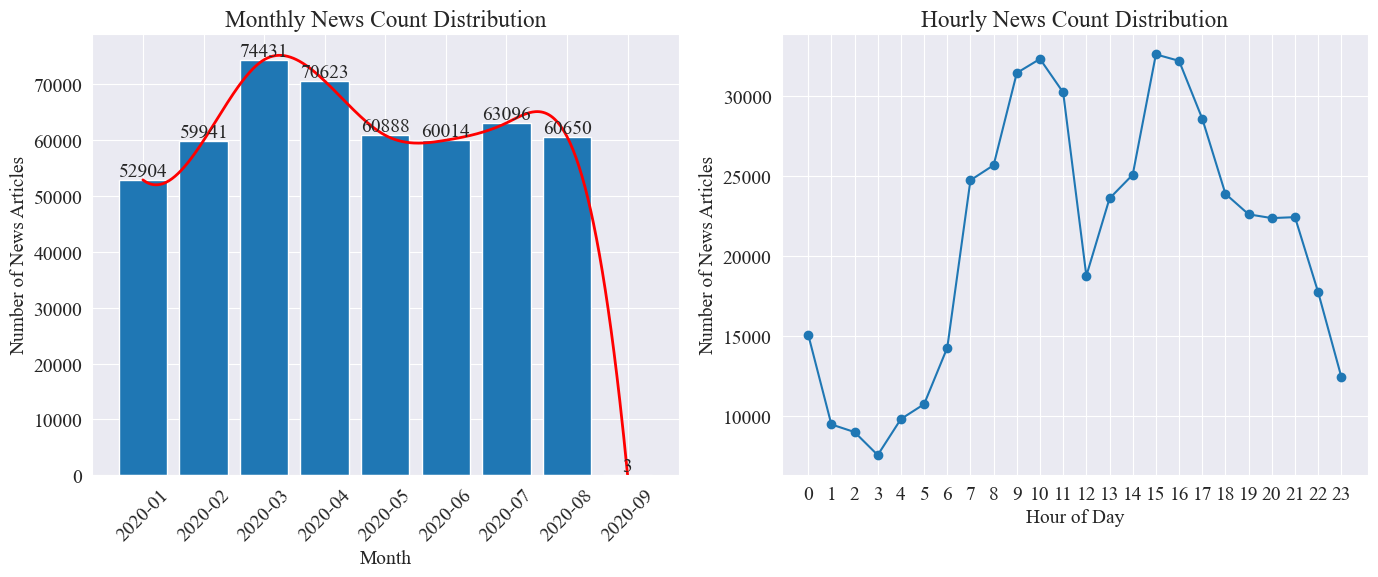
यथा उपर्युक्ताङ्कात् दृश्यते, महामारीयाः प्रकोपेन सह मासे मासे वार्तानां संख्या वर्धिता, मार्चमासे ७४,००० वार्तालेखैः चरमपर्यन्तं प्राप्तवती, ततः क्रमेण न्यूनीभूता, प्रतिमासं ६०,००० लेखाः यावत् स्थिराः अभवन्, येषु... सेप्टेम्बरमासे दत्तांशः 0:00 वादने 3 आसीत् लेखाः, सांख्यिकीयां न समाविष्टाः भवेयुः।
प्रतिघण्टां वार्तामात्रायाः वितरणस्य अनुसारं दृश्यते यत् प्रतिदिनं १० वादनतः १५ वादनपर्यन्तं वार्ताविमोचनस्य शिखरसमयः भवति, प्रत्येकं ३०,००० तः अधिकाः लेखाः प्रकाशिताः सन्ति १२ वादने मध्याह्नभोजनविरामः भवति, वार्ताविमोचनानाम् संख्या च शिखरं, गर्ता च भवति । प्रतिदिनं ०:०० तः ५:०० पर्यन्तं वार्ताविमोचनानाम् संख्या न्यूनतमा भवति, ३:०० वादनपर्यन्तं लघुतमः बिन्दुः भवति ।
समाचार हॉट स्पॉट् ट्रैकिंग
अस्मिन् प्रयोगे एतेषु अष्टमासेषु वार्ता-उष्णस्थानानि निरीक्षितुं वार्ता-कीवर्ड-निष्कासन-पद्धतिः उपयोक्तुं अभिप्रायः अस्ति । विद्यमानस्य कीवर्डस्य वितरणं गणयित्वा हिस्टोग्रामं आकर्षयित्वा परिणामाः निम्नलिखितरूपेण भवन्ति ।
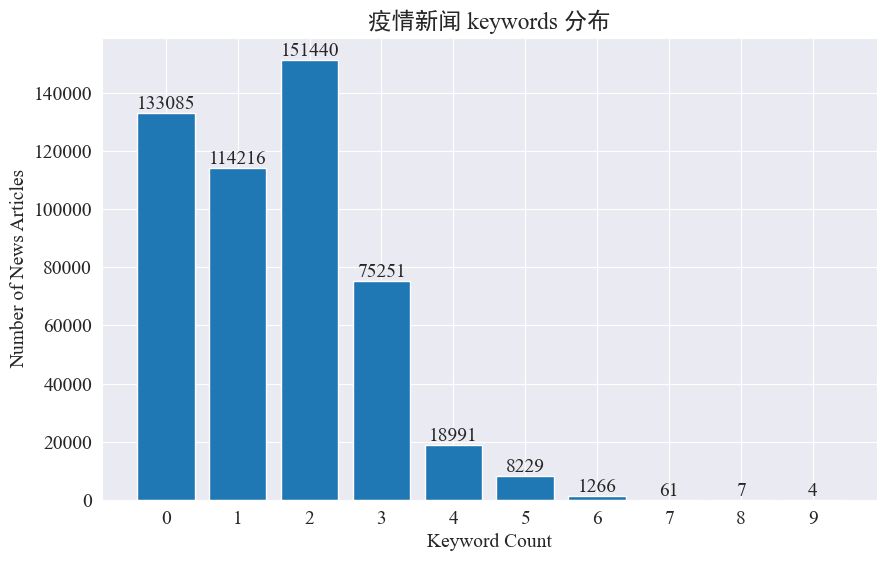
दृश्यते यत् अधिकांशवार्तालेखेषु ३ कीवर्डात् न्यूनाः सन्ति, लेखानाम् अपि बृहत् भागः कीवर्डः अपि नास्ति । अतः भवद्भिः हॉटस्पॉट्-निरीक्षणार्थं स्वयमेव सांख्यिकी-सङ्ग्रहः, कीवर्ड-शब्दानां सारांशः च आवश्यकः ।अस्मिन् समये प्रयोगःjieba.analyse.textrank() कीवर्डगणना कर्तुं।
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
५ नूतनानि कीवर्ड्स गणयन्तु, keyword_new इत्यत्र रक्षन्तु, ततः तेषां सह कीवर्ड्स् विलीनं कुर्वन्तु, द्वितीयकं शब्दं च निष्कासयन्तु ।
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
विलयानन्तरं मुद्रयन्तु keyword_data , मुद्रितफलं यथा भवति ।
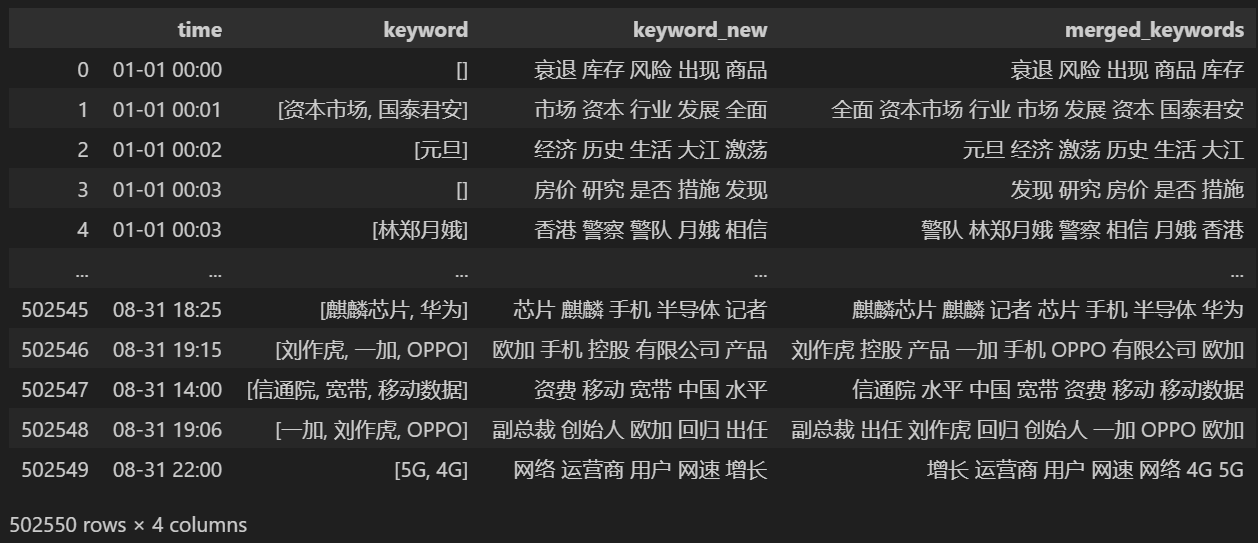
उष्णस्थानानां निरीक्षणार्थं सर्वेषां प्रकटितशब्दानां शब्दावृत्तिं गणयन्तु, गणयन्तु च keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
ततः उपर्युक्तानां सांख्यिकीयदत्तांशस्य आधारेण उष्णशब्दानां दैनिकपरिवर्तनचार्टं आकर्षयन्तु ।
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
अन्ते महामारीवार्तासु कीवर्डपरिवर्तनस्य gif चार्टः प्राप्तः परिणामाः निम्नलिखितरूपेण सन्ति।
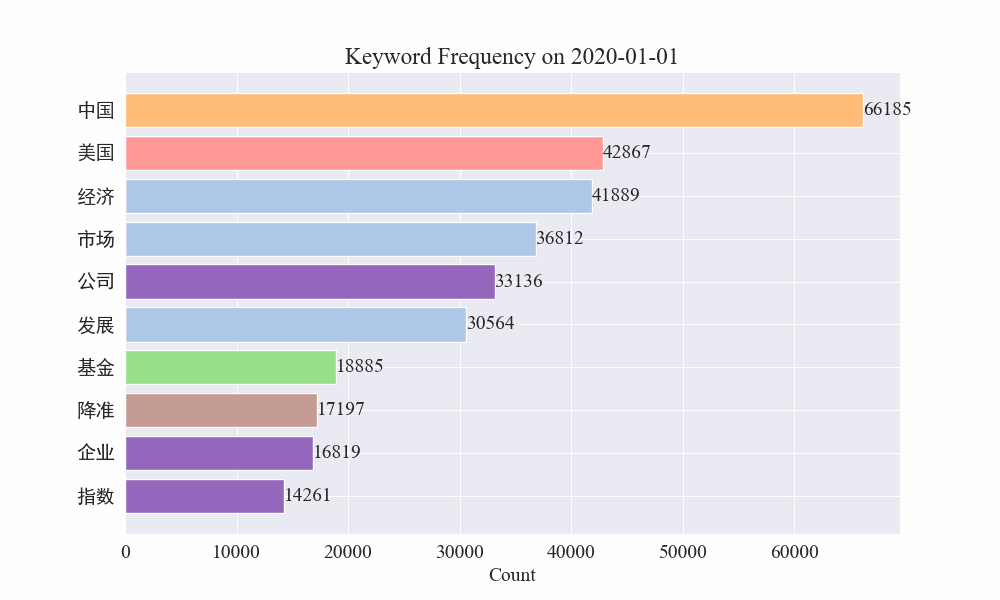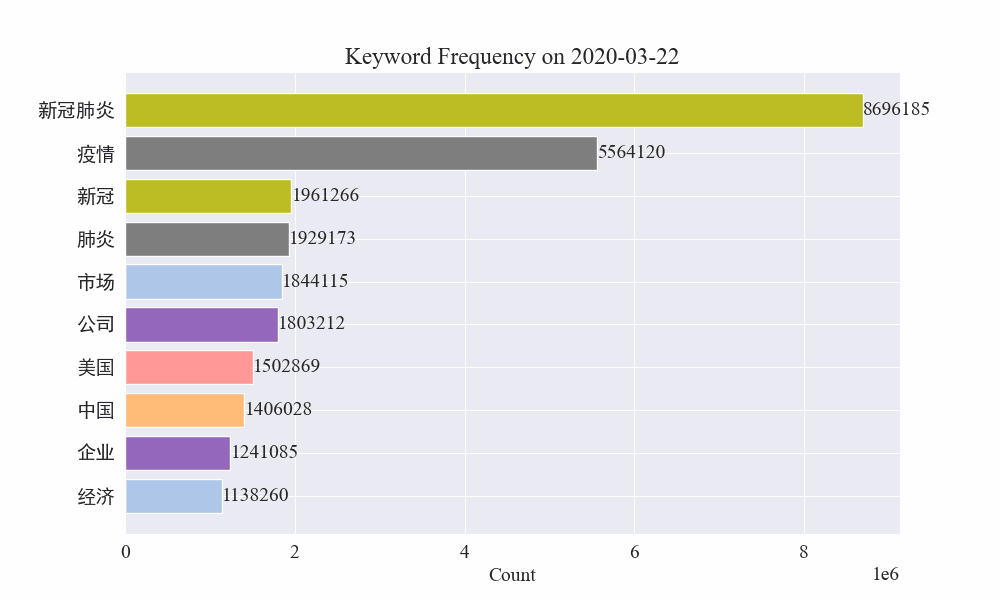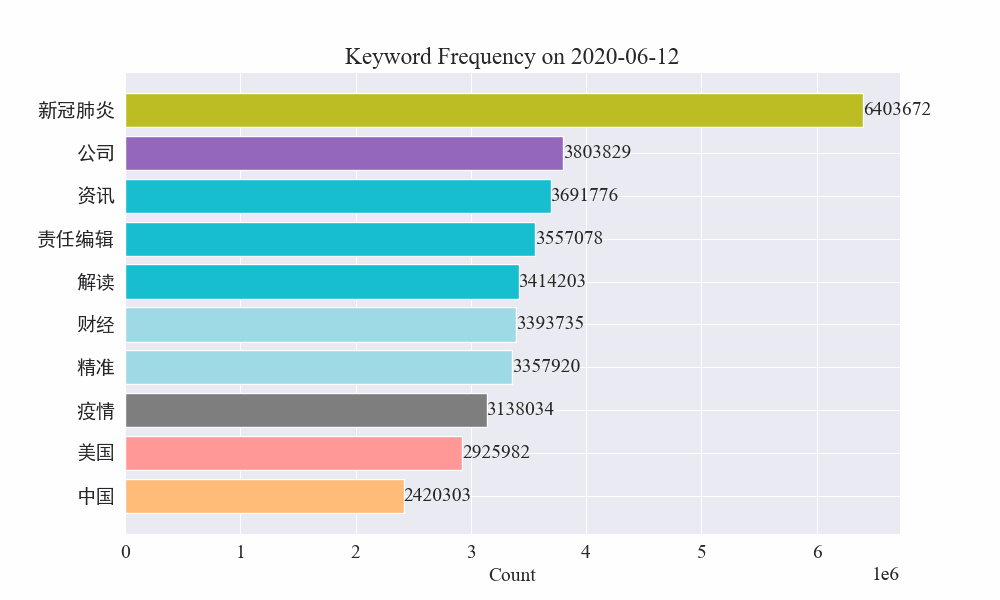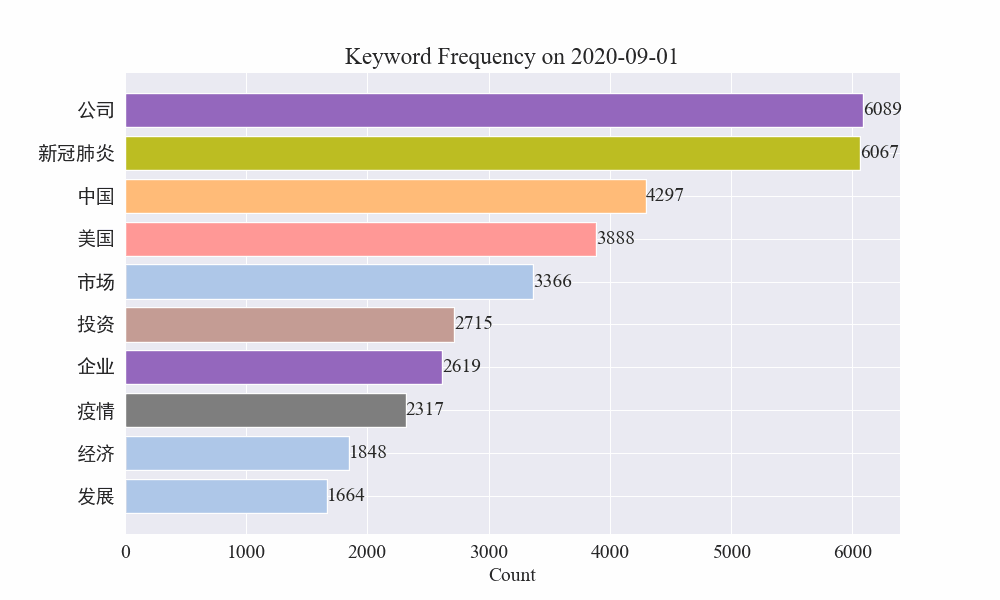
प्रकोपात् पूर्वं "कम्पनी" "ईरान" इति पदं उच्चं एव आसीत् । द्रष्टुं शक्यते यत् महामारी-प्रकोपस्य अनन्तरं फेब्रुवरी-मासे महामारी-सम्बद्धानां वार्तानां संख्यायां वृद्धिः आरब्धा तदनन्तरं "नव-कोरोना-विषाणुः" इति पदाः उच्छ्रिताः अभवन्, अगस्त-मासस्य अन्त्यपर्यन्तं च अभवन् । महामारीयाः प्रथमतरङ्गः मन्दं भूत्वा द्वितीयस्थानं जातम् ।
अस्मिन् खण्डे प्रथमं वार्ताटिप्पणीनां परिमाणात्मकसांख्यिकीयविश्लेषणं भवति, ततः भिन्नटिप्पणीनां भावनाविश्लेषणं भवति ।
दैनिक समाचारटिप्पणीगणना सांख्यिकी
वार्ताटिप्पणीनां संख्यायाः प्रवृत्तिं गणयन्तु, तस्य प्रतिनिधित्वार्थं बारचार्टस्य उपयोगं कुर्वन्तु, अनुमानितवक्रं च आकर्षयन्तु ।
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
दैनिकवार्ताटिप्पणीनां संख्यायाः सांख्यिकीयचार्टः निम्नलिखितरूपेण आकृष्यते ।
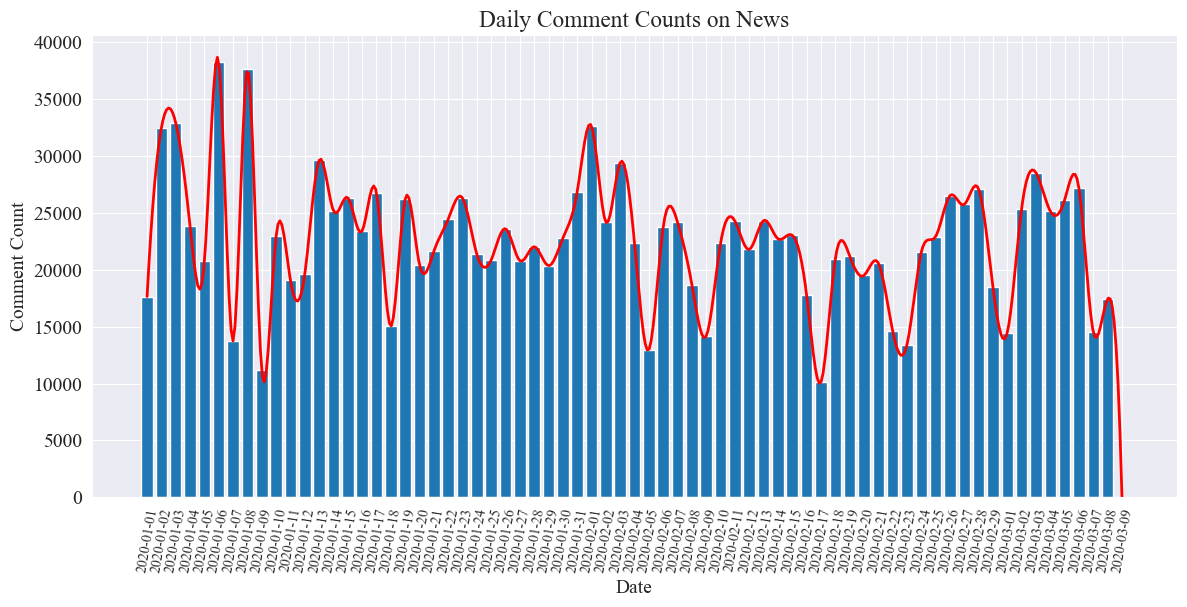
महामारीकाले वार्ताटिप्पणीनां संख्यायां १०,००० तः ४०,००० यावत् उतार-चढावः भवति स्म, प्रतिदिनं औसतेन प्रायः २०,००० टिप्पण्याः भवन्ति इति द्रष्टुं शक्यते
क्षेत्रानुसारं महामारीवार्तासांख्यिकी
प्रान्तेन comment_df['province'] प्रत्येकं प्रान्ते वार्तानां संख्यां गणयन्तु तथा च प्रत्येकस्मिन् प्रान्ते महामारीवार्तासु टिप्पणीनां संख्यां गणयन्तु।
प्रथमं भवता उत्तीर्णं कर्तव्यम् comment_df['province'] प्रान्तस्य सूचनां निष्कासयन्तु।
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
ततः सांख्यिकीयदत्तांशस्य आधारेण प्रत्येकस्मिन् प्रान्ते वार्ताटिप्पणीनां अनुपातं दर्शयन् पाई चार्टः आकृष्यते ।
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

अस्मिन् प्रयोगे वयं अपि प्रयुक्तवन्तः pyecharts.charts इत्यस्यMap घटकः, यः चीनदेशस्य मानचित्रे टिप्पणीनां संख्यायाः वितरणं प्रान्तेन प्लॉट् करोति ।
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
प्राप्ते HTML मध्ये चीनदेशस्य प्रत्येकस्मिन् प्रान्ते महामारीवार्तानां टिप्पणीनां संख्यायाः वितरणं निम्नलिखितरूपेण भवति ।
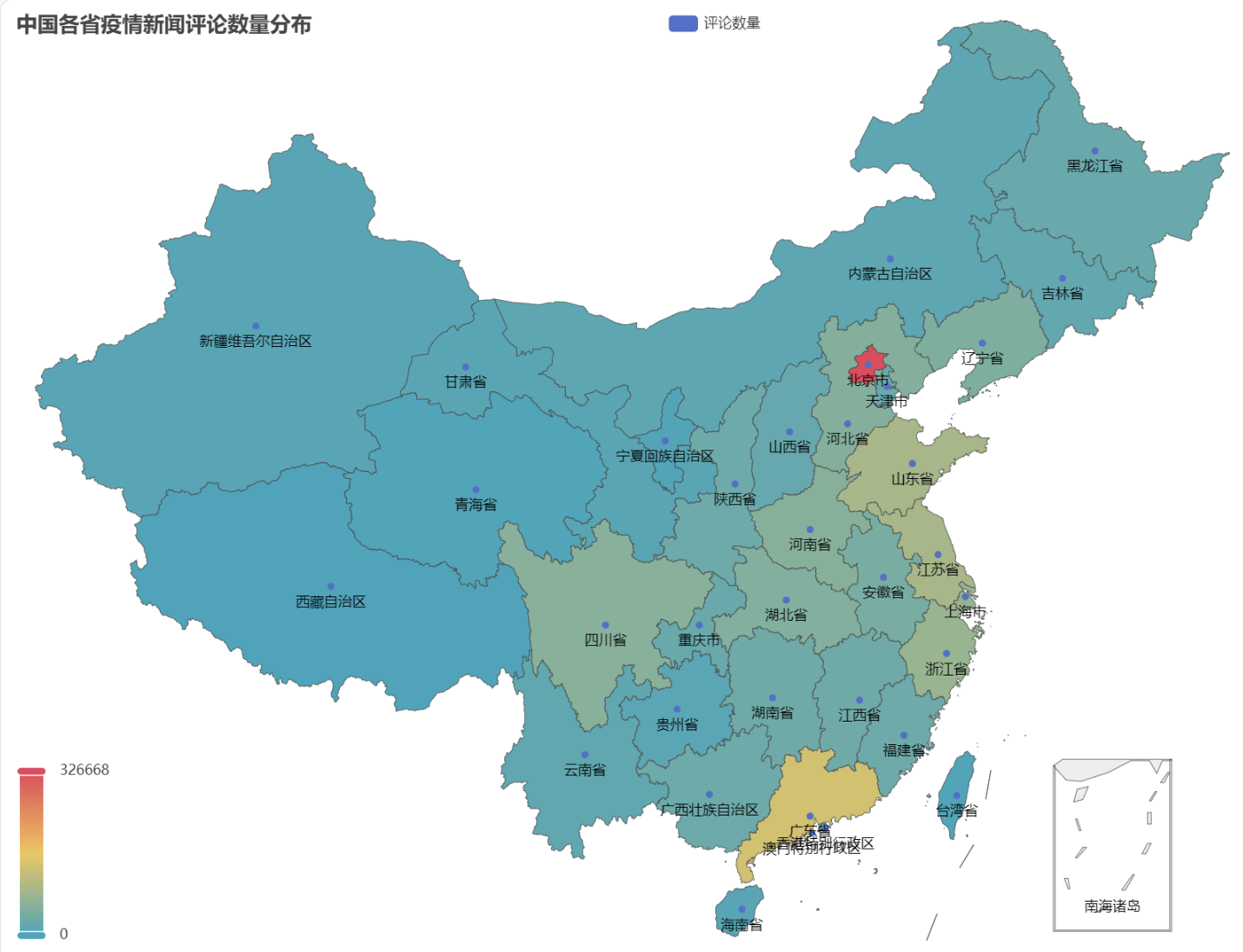
द्रष्टुं शक्यते यत् महामारी-काले बीजिंग-नगरे टिप्पणीनां संख्या सर्वाधिकं आसीत्, तदनन्तरं गुआङ्गडोङ्ग-प्रान्ते, अन्येषु प्रान्तेषु टिप्पणीनां संख्या तुल्यकालिकरूपेण समः आसीत्
महामारीभावना विश्लेषण की समीक्षा करें
अस्मिन् प्रयोगे चीनीपाठस्य संसाधनार्थं एनएलपी पुस्तकालयस्य उपयोगः भवति SnowNLP , चीनीभावविश्लेषणं कार्यान्वितं कृत्वा प्रत्येकं टिप्पणं विश्लेषयन्तु, तदनुरूपं च ददतुsentiment मूल्यं, मूल्यं 0 तः 1 पर्यन्तं भवति, 1 इत्यस्य समीपं यावत् अधिकं सकारात्मकं भवति, 0 इत्यस्य समीपं भवति तावत् अधिकं ऋणात्मकं भवति।
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
अस्मिन् प्रयोगे 0.5 इत्यस्य उपयोगः दहलीजरूपेण भवति । कोडं लिखित्वा दैनिकवार्ताटिप्पणीनां भावविश्लेषणचार्टं आकर्षयन्तु, तथा च दैनिकवार्तासु सकारात्मकटिप्पणीनां संख्यां नकारात्मकटिप्पणीनां संख्यां च गणयन्तु, सकारात्मकटिप्पणीनां संख्या सकारात्मकं मूल्यं भवति, नकारात्मकटिप्पणीनां संख्या च नकारात्मकं भवति मूल्यम्।
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
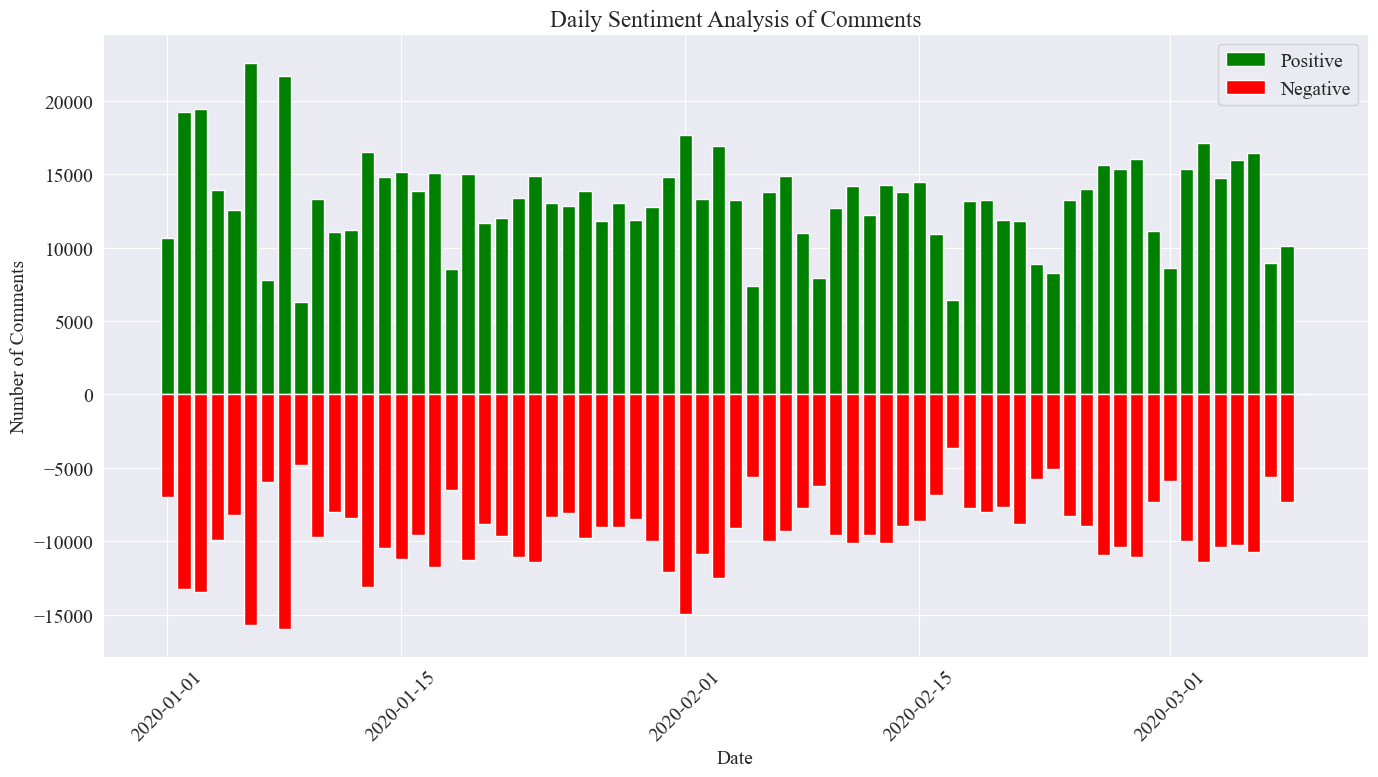
अन्तिमसांख्यिकीयप्रतिबिम्बं यथा उपरि दर्शितं तथा दृश्यते यत् महामारीकाले सकारात्मकटिप्पण्याः नकारात्मकटिप्पण्याः अपेक्षया किञ्चित् अधिकाः आसन्, सकारात्मकटिप्पणीनां अनुपातः ५८.६३% इति सूचयति यत् महामारीविषये जनसमूहस्य अधिका सकारात्मकदृष्टिकोणः आसीत्।
क्षेत्रानुसारं टिप्पणीनां भावविश्लेषणम्
प्रत्येकस्मिन् प्रान्ते क्षेत्रे च प्रकाशितानां सकारात्मकटिप्पणीनां अनुपातस्य गणनाद्वारा प्रत्येकस्मिन् क्षेत्रे सकारात्मकटिप्पणीनां अनुपातस्य आलेखः प्राप्तः
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
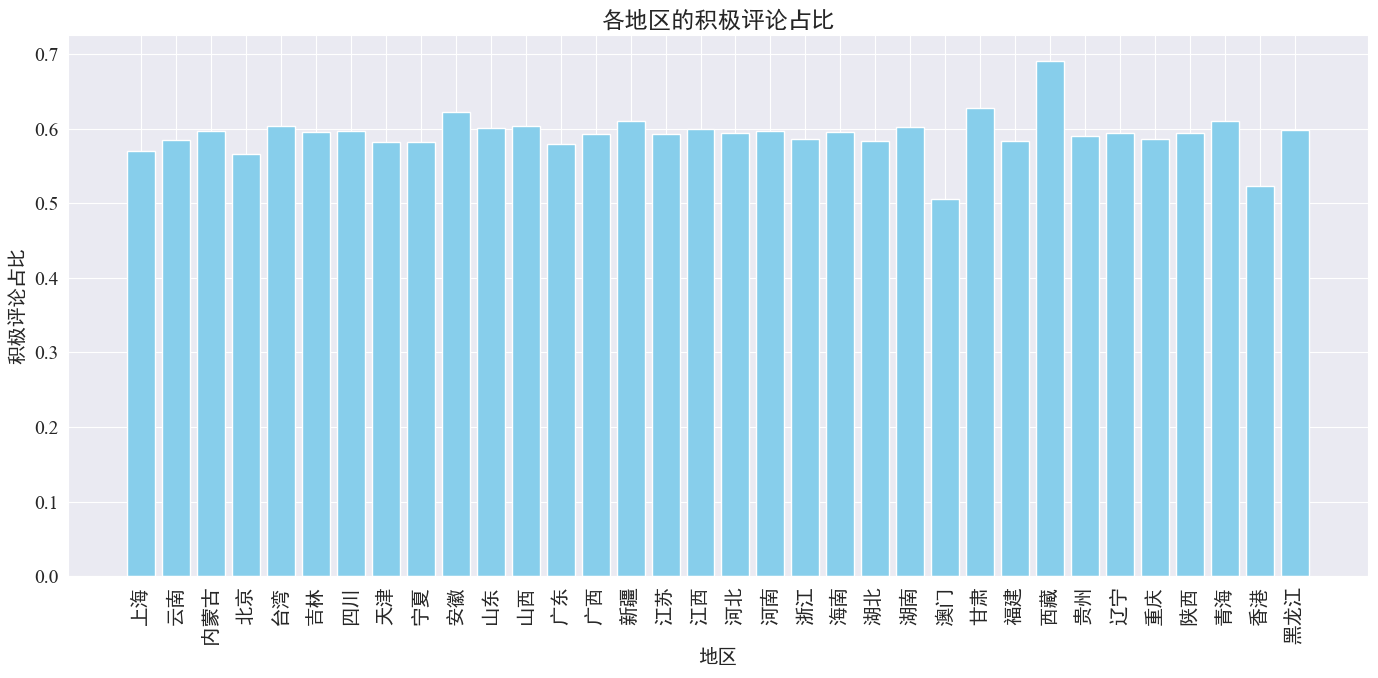
यथा उपर्युक्त आकङ्कणात् दृश्यते, अधिकांशप्रान्तेषु सकारात्मकटिप्पणीनां अनुपातः ६०% परिमितः अस्ति, मकाओ च सकारात्मकटिप्पणीनां न्यूनतमः अनुपातः अस्ति, प्रायः ५०%, यदा तु तिब्बते सकारात्मकटिप्पणीनां सर्वाधिकं अनुपातः अस्ति, तस्य समीपे ७०% ।
उपर्युक्तटिप्पणीनां वितरणात् वयं द्रष्टुं शक्नुमः यत् मुख्यभूमिचीनदेशे टिप्पण्याः अधिकतया सकारात्मकटिप्पण्याः सन्ति, यदा तु हाङ्गकाङ्ग-मकाओ-देशयोः नकारात्मकटिप्पणीनां महती वृद्धिः अभवत् तिब्बते लघु नमूना आकारः ।
समाचार टिप्पणियाँ शब्द मेघ चार्ट रेखाचित्र
सर्वेषां टिप्पणीनां, सकारात्मकटिप्पणीनां, नकारात्मकटिप्पणीनां च शब्दमेघचित्रं पृथक् पृथक् गण्यते स्म आकृष्टानि चित्राणि।

द्रष्टुं शक्यते यत् महामारीकाले अधिकांशजनानां टिप्पण्याः तुल्यकालिकरूपेण सरलाः सन्ति, यथा "हाहा", "उत्तमः" इत्यादयः सकारात्मकटिप्पण्यां भवन्तः "Come on China", "Come on Wuhan" इत्यादीन् उत्साहवर्धकशब्दान् द्रष्टुं शक्नुवन्ति। , इत्यादिषु नकारात्मकटिप्पणीषु "हाहा" "देशं धनिकं कर्तुं कठिनम्" इत्यादीनि आलोचनानि सन्ति ।

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु
