Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
La epidemia de COVID-19 afecta el corazón de cada uno de nosotros. En este caso, intentaremos utilizar métodos de computación social para analizar noticias y rumores relacionados con la epidemia para ayudar.Información epidémica Investigación. Esta tarea es una tarea abierta. Proporcionamos datos sociales durante la epidemia y alentamos a los estudiantes a analizar tendencias sociales a partir de noticias, rumores y documentos legales. (Consejo: utilice los métodos aprendidos en clase, como análisis de sentimientos, extracción de información, comprensión lectora, etc. para analizar datos)
https://covid19.thunlp.org/ proporciona información de datos sociales relacionados con la epidemia del nuevo coronavirus, incluidos rumores relacionados con la epidemia CSDC-Rumor, noticias chinas relacionadas con la epidemia CSDC-News y documentos legales relacionados con la epidemia CSDC-Legal.
Esta parte del conjunto de datos recopiló:
(1) A partir del 22 de enero de 2020Weibo información falsaLos datos incluyen el contenido de las publicaciones de Weibo que se consideran información falsa, los editores, los denunciantes, el tiempo de prueba, los resultados y otra información. Al 1 de marzo de 2020, hay un total de 324 textos originales de Weibo, 31.284 reenvíos y 7.912 comentarios. , utilizado para ayudar a los investigadores a analizar y estudiar la difusión de información falsa durante la epidemia;
(2) La plataforma de verificación de rumores de Tencent y los datos de información falsa de Dingxiangyuan desde el 18 de enero de 2020, incluida información como el contenido del rumor que se considera correcto o falso, el momento y la base para juzgar si es un rumor. Al 1 de marzo de 2020, hay 507 datos de rumores, incluidos 124 datos fácticos. La distribución de los datos es: casos negativos: 420, casos positivos: 33 e incierto: 54.
Esta parte del conjunto de datos recopila datos de noticias a partir del 1 de enero de 2020, incluido el título, el contenido, las palabras clave y otra información de las noticias. Al 16 de marzo de 2020, se recopilaron un total de 148.960 noticias y 1.653.086 comentarios correspondientes. Se utiliza para ayudar a los investigadores a analizar y estudiar datos de noticias durante la epidemia.
Estos datos son de CAIL Se seleccionaron un total de 1.203 piezas históricas relacionadas con la epidemia a partir de los datos de documentos legales anónimos recopilados. Cada pieza de datos incluye el título del documento, el número de caso y el texto completo del documento, que los investigadores pueden utilizar para realizar investigaciones. sobre cuestiones jurídicas relevantes durante la epidemia.
Esta tarea es una tarea abierta, comenzaremos desde
Calificación de trabajos en otros aspectos.
[1] Credibilidad de la información en Twitter. en Actas de WWW, 2011.
[2] Detección de rumores en microblogs con redes neuronales recurrentes. en Actas del IJCAI, 2016.
[3] Un enfoque convolucional para la identificación de desinformación. en Actas del IJCAI, 2017.
[4] La difusión de noticias verdaderas y falsas en línea. Science, 2018.
[5] Información falsa en la web y las redes sociales: una encuesta. Preimpresión de arXiv, 2018.
[6] Caracterización de las normas afectivas para palabras en inglés mediante categorías emocionales discretas. Behavior Research Methods, 2007.
Este experimento proporciona el conjunto de datos de rumores relacionados con la epidemia CSDC-Rumor. Al analizar el contenido del conjunto de datos, elegimos realizar primero un análisis estadístico cuantitativo en el conjunto de datos, luego usar la agrupación para implementar el análisis semántico de los rumores y finalmente diseñar un. Sistema de detección de rumores.
Formato de datos
Este experimento proporciona el conjunto de datos de rumores relacionados con la epidemia CSDC-Rumor, que recopila datos de información falsa de Weibo y datos que refutan rumores. El conjunto de datos contiene lo siguiente.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Weibo información falsarespectivamente por rumor_weibo yrumor_forward_comment dos del mismo nombrejson descrito en el expediente.rumor_weibo mediojson Los campos específicos son los siguientes:
rumorCode: El código único del rumor, a través del cual se puede acceder directamente a la página de informes del rumor.title: El contenido del título del rumor reportado.informerName: Nombre de Weibo del reportero.informerUrl: Enlace de Weibo del periodista.rumormongerName: El nombre de Weibo de la persona que publicó el rumor.rumormongerUr: Enlace de Weibo de la persona que publicó el rumor.rumorText: Contenido del rumor.visitTimes: El número de veces que se ha visitado este rumor.result: Los resultados de esta revisión de rumores.publishTime: La hora en que se informó el rumor.related_url: Enlaces a pruebas, normativas, etc. relacionados con este rumor.rumor_forward_comment mediojson Los campos específicos son los siguientes:
uid: Publicar ID de usuario.text: Comente o reenvíe la posdata.date: tiempo de liberación.comment_or_forward: binario, cualquiera comment, cualquiera forward, indicando si el mensaje es un comentario o una posdata reenviada.Información falsa de Tencent y Lilac GardenEl formato del contenido es:
date: tiempoexplain: Tipo de rumortag: etiqueta de rumoresabstract: Contenido utilizado para verificar rumores.rumor: RumorPreprocesamiento de datos
aprobar json.load() Extraiga los datos de rumores de Weibo por separadoweibo_data Comentar reenviando datos con rumores.forward_comment_data y luego conviértalo al formato DataFrame. Los dos archivos con el mismo nombre, el artículo de Weibo y el reenvío de comentarios de Weibo se corresponden entre sí. Al procesar los datos en la carpeta rumor_forward_comment, agregue rumorCode para su posterior comparación.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Esta sección utiliza análisis estadístico cuantitativo para obtener una comprensión específica de la distribución de los datos de Weibo sobre rumores epidémicos.
Estadísticas sobre el número de veces que se han visitado los rumores
Estadísticas weibo_df['visitTimes'] Distribución de tiempos de acceso y elaboración del histograma correspondiente. Los resultados son los siguientes.
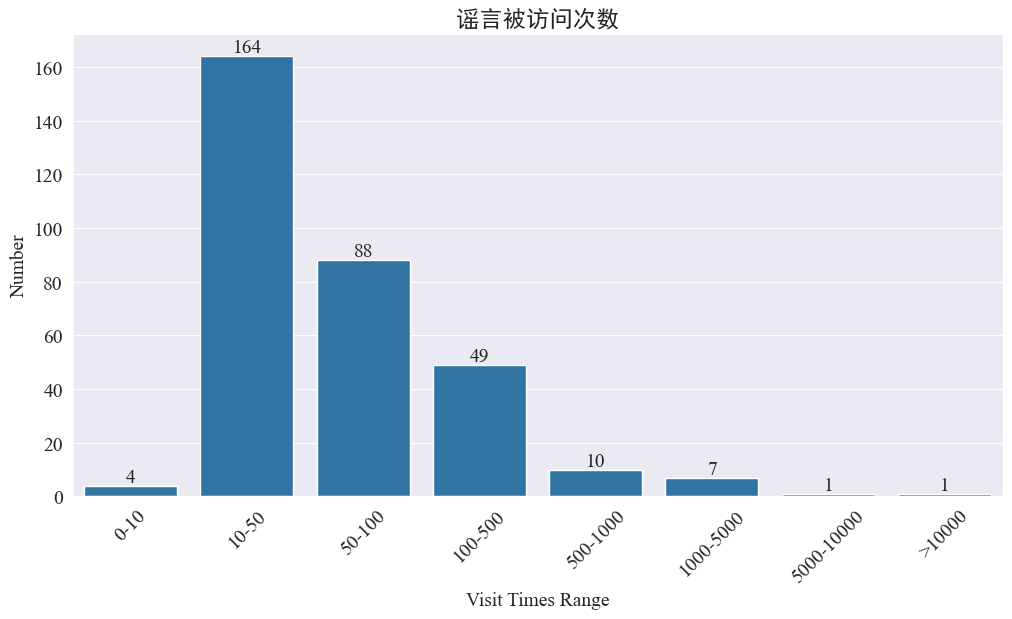
Según el número de visitas a Weibo, la mayoría de los rumores de epidemia han sido visitados menos de 500 veces en Weibo, y entre 10 y 50 representan la mayor proporción. Sin embargo, también hay rumores en Weibo a los que se ha accedido más de 5.000 veces, que han causado grave impacto y son considerados “serios” por ley.
Estadísticas sobre la aparición de creadores de rumores y denunciantes
por estadísticas weibo_df['rumormongerName'] yweibo_df['informerName'] Se obtienen el número de rumores publicados por cada editor de rumores y el número de rumores informados por cada reportero. Los resultados son los siguientes.
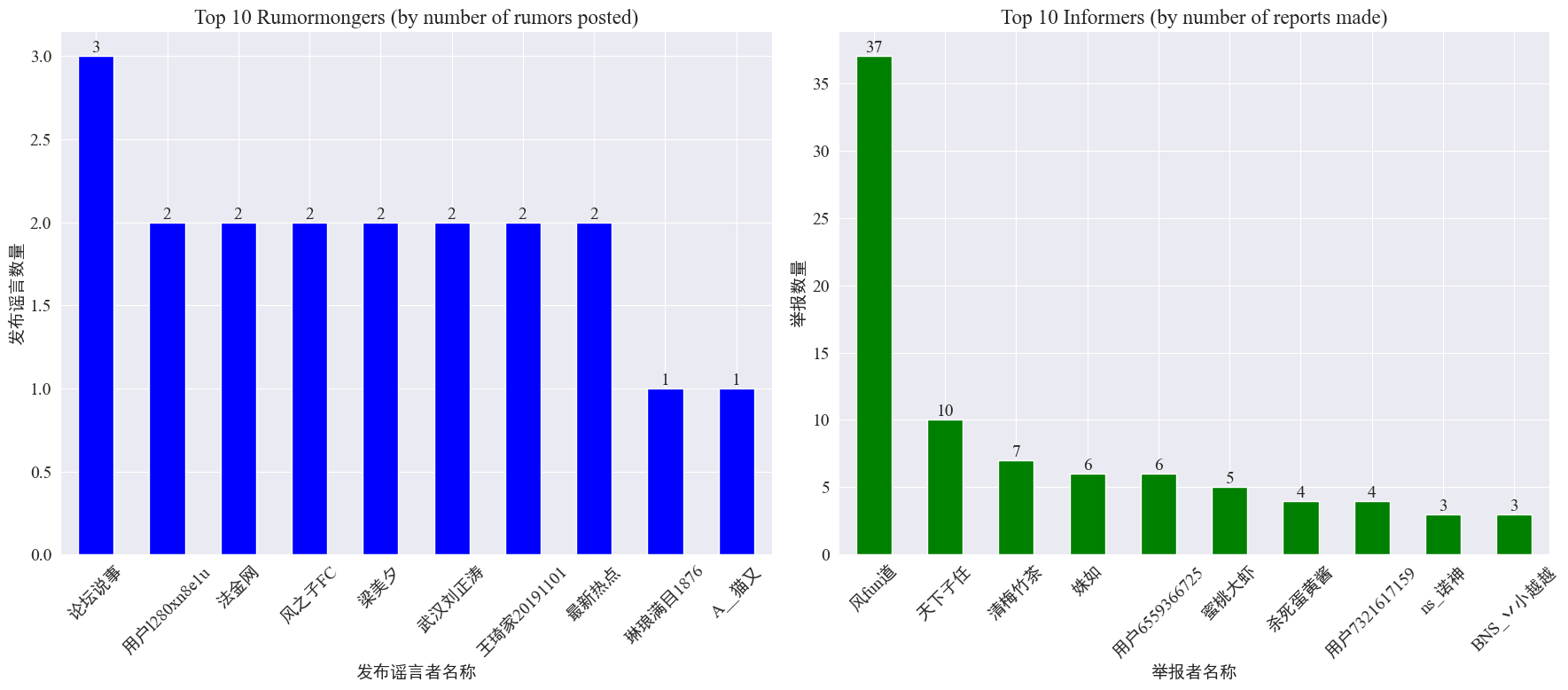
Se puede ver que la cantidad de rumores publicados por los creadores de rumores no se concentra en unas pocas personas, sino que es relativamente uniforme. La cuenta que publicó la mayor cantidad de rumores publicó tres publicaciones de rumores en Weibo. Cada uno de los 10 principales denunciantes informó al menos 3 artículos de rumores. Entre ellos, el número de rumores informados por los denunciantes en Weibo fue significativamente mayor que el de otros usuarios, llegando a 37 artículos.
Con base en los datos anteriores, la audiencia puede concentrarse en informar cuentas con una gran cantidad de rumores para facilitar la detección de rumores.
Estadísticas de distribución de comentarios de reenvío de rumores.
Al contar la distribución del volumen de reenvío de rumores y el volumen de comentarios, se obtiene la siguiente imagen de distribución.

Se puede ver que el número de comentarios y reenvíos en la mayoría de los rumores de Weibo es de 10 veces, con un número máximo de comentarios que no supera los 500 y un número máximo de reenvíos que supera los 10.000. Según la Ley de Gestión de Internet, si un rumor se transmite más de 500 veces, se considera una situación "grave".
Análisis de grupos de textos de rumores
Esta parte realiza un preprocesamiento de datos en los textos de rumores de Weibo y realiza un análisis de conglomerados después de la segmentación de palabras para ver dónde se concentran los rumores de Weibo.
Preprocesamiento de datos
Primero, limpie el texto de datos de rumores, elimine los valores predeterminados y <> El contenido del enlace adjunto.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Luego cargue palabras vacías en chino y use las palabras vacías cn_palabras vacías ,usarjieba Implementar el procesamiento de segmentación de palabras de datos y realizar la vectorización de texto.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Determinar la mejor agrupación
Utilizando el método del codo, se determinan los mejores grupos.
El método del codo es un método utilizado para determinar el número óptimo de conglomerados en el análisis de conglomerados. Se basa en la relación entre la suma de errores al cuadrado (SSE) y el número de conglomerados. SSE es la suma de las distancias euclidianas al cuadrado desde todos los puntos de datos del grupo hasta el centro del grupo al que pertenece. Refleja el efecto de la agrupación: cuanto menor sea el SSE, mejor será el efecto de la agrupación.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
El método del codo determina el número óptimo de grupos buscando el "codo", es decir, buscando un punto en la curva después del cual la tasa de disminución del SSE se ralentiza significativamente. Este punto es como el codo de un brazo, de ahí el nombre "Método del codo”. Este punto suele considerarse el número óptimo de conglomerados.
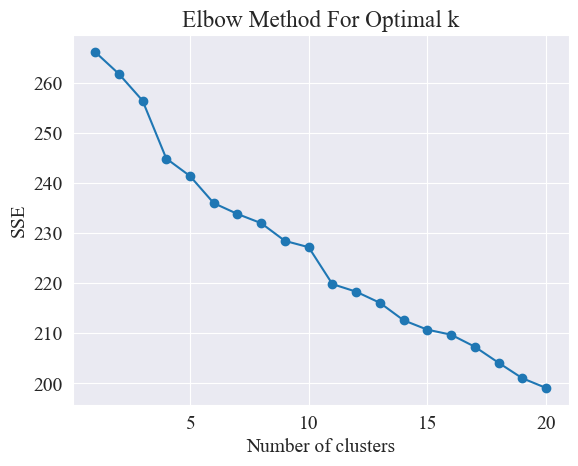
A partir de la figura anterior, se determina que el valor de agrupamiento del codo es 11 y se dibuja el diagrama de dispersión correspondiente. Los resultados son los siguientes.
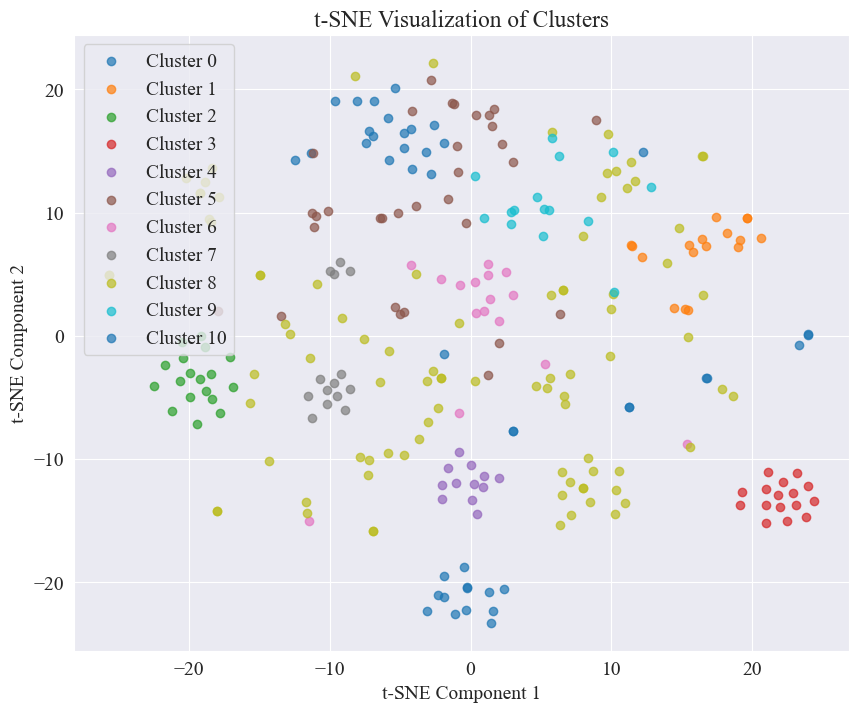
Se puede ver que la mayoría de los rumores en Weibo están bien agrupados, los números 3 y 4, algunos están ampliamente distribuidos y no están bien agrupados, como los números 5 y 8;
Resultados de agrupación
Para mostrar claramente qué rumores están agrupados en cada categoría, se dibuja un gráfico de nubes para cada categoría. Los resultados son los siguientes.

Imprima algunos contenidos de rumores de Weibo bien agrupados y los resultados son los siguientes.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Análisis de conglomerados de resultados de revisión de rumores.
Agrupar el contenido del texto de los rumores puede no ser tan bueno para el análisis del contenido de los rumores, por lo que optamos por agrupar los resultados de la revisión de los rumores.
Determinar la mejor agrupación
Utilizando el gráfico del codo, determine la mejor agrupación.
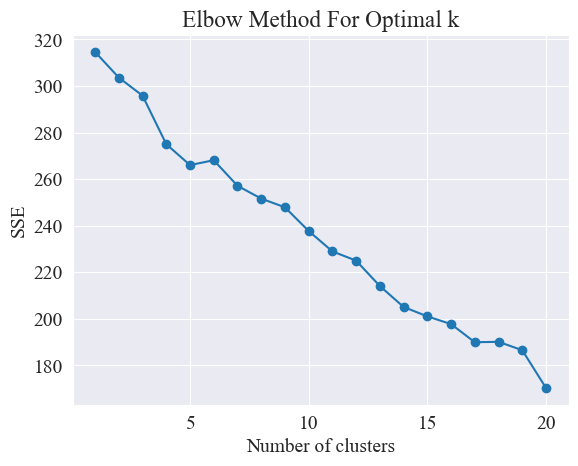
A partir del diagrama de codo anterior, se pueden determinar dos codos, uno es cuando el agrupamiento es 5 y el otro es cuando el agrupamiento es 20. Elijo 20 para el agrupamiento.
El diagrama de dispersión obtenido al agrupar 20 categorías es el siguiente.
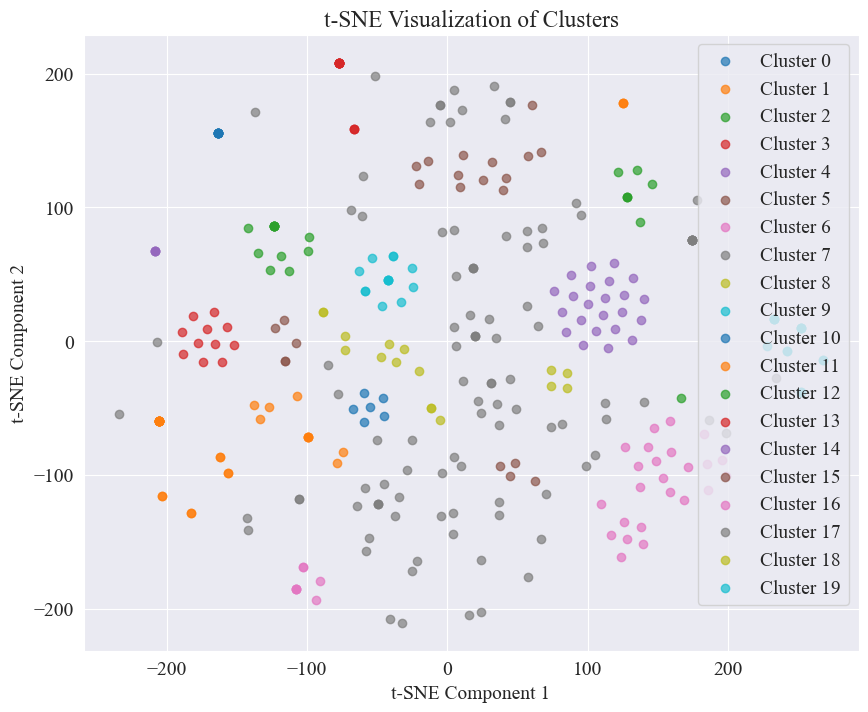
Se puede observar que la mayoría de ellos están bien agrupados, pero las categorías 7 y 17 no están bien agrupadas.
Resultados de agrupación
Para mostrar claramente qué resultados de la revisión de rumores están agrupados en cada categoría, se dibuja un gráfico de nubes para cada categoría. Los resultados son los siguientes.

Imprima algunos resultados de revisión de rumores bien agrupados. Los resultados son los siguientes.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Para esta detección de rumores, optamos por utilizar conjuntos de datos que han sido refutados. fact.json Compare la similitud entre los rumores refutados y los rumores reales, y seleccione el artículo refutado con la mayor similitud con el rumor de Weibo como base para la detección de rumores.
Cargue datos de rumores de Weibo y conjuntos de datos que refuten rumores
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Utilice modelos de lenguaje previamente entrenados para codificar rumores de Weibo y títulos que los refutan en vectores de incrustación.
Utilizado en este experimento. bert-base-chinese Como modelo previamente entrenado, realice el entrenamiento del modelo. El modelo SimCSE se utiliza para mejorar la representación y medición de similitud de la semántica de oraciones mediante el aprendizaje contrastivo.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Calcular similitud
Para calcular la similitud, la incrustación de oraciones y la similitud de entidades nombradas del modelo SimCSE se utilizan para calcular la similitud integral.
extract_entitiesLa función extrae entidades nombradas del texto utilizando el modelo NER.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityLa función calcula la similitud de la entidad nombrada entre dos textos.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityLa función combina la incrustación de oraciones y la similitud de entidades nombradas del modelo SimCSE para calcular la similitud integral.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Implementar detección de rumores
Al comparar similitudes, se implementa un mecanismo de detección de rumores.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
El resultado es el siguiente:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Encontró con éxito la base para refutar los rumores y emitió un fallo para refutar los rumores.
Formato de datos
Este experimento proporciona el conjunto de datos de noticias relacionadas con la epidemia CSDC-News, que recopila contenido de noticias y comentarios en la primera mitad de 2020. El conjunto de datos contiene lo siguiente.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
La carpeta de datos se divide en tres partes:data,comment。
data La carpeta contiene varios archivos, cada archivo corresponde a datos de una fecha determinada, en el formatojson . El contenido de esta parte corresponde a los datos textuales de la noticia (se irá actualizando progresivamente con la fecha), y los campos incluyen:
time: Hora de publicación de noticias.title:El título de la noticia.url: El enlace de dirección original de la noticia.meta: La información de texto de la noticia, que incluye los siguientes campos: content: El contenido del texto de la noticia.description: Una breve descripción de la noticia.title:El título de la noticia.keyword: Palabras clave de noticias.type: Tipo de noticia.comment La carpeta contiene varios archivos, cada archivo corresponde a datos de una fecha determinada, en el formatojson . Esta parte del contenido corresponde a los datos del comentario de la noticia (puede haber un retraso de aproximadamente una semana entre los datos del comentario y los datos del texto de la noticia).
time: hora de publicación de noticias, y data Corresponde a los datos de la carpeta.title: El título de la noticia, con data Corresponde a los datos de la carpeta.url: El enlace de la dirección original de la noticia, y data Corresponde a los datos de la carpeta.comment: Información de comentarios de noticias. Este campo es una matriz. Cada elemento de la matriz contiene la siguiente información: area: Área del revisor.content:comentarios.nickname: Apodo del revisor.reply_to: El objeto de respuesta del comentarista. Si no hay ninguno, significa que no es una respuesta.time: Hora de comentar.Preprocesamiento de datos
Datos sobre artículos de noticias. data Durante el preprocesamiento de datos, es necesariometa El contenido se publica y almacena en formato DataFrame.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
En los datos de revisión. comment Durante el preprocesamiento de datos, es necesariocomment El contenido se publica y almacena en formato DataFrame.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Cargar conjunto de datos
Cargue el conjunto de datos de acuerdo con la función de preprocesamiento de datos anterior.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
El resultado impreso muestra que la longitud de los datos de noticias: 502550 y la longitud de los datos de comentarios: 1534616.
Estadísticas de distribución del tiempo de noticias
contar por separado news_df La cantidad de artículos de noticias mensuales y la cantidad de artículos de noticias por hora se representan mediante gráficos de barras y gráficos de líneas. Los resultados son los siguientes.
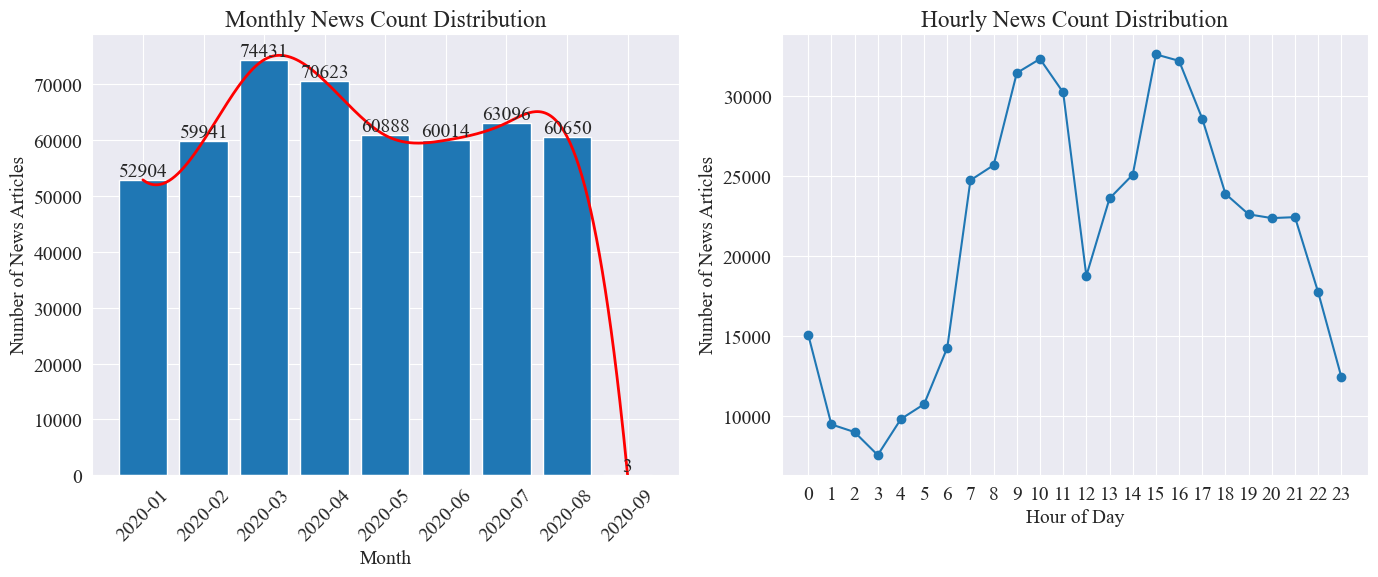
Como puede verse en la figura anterior, con el estallido de la epidemia, el número de noticias aumentó mes a mes, alcanzando un máximo en marzo con 74.000 artículos de noticias, y luego disminuyó gradualmente y se estabilizó hasta 60.000 artículos por mes, de los cuales el Los datos de septiembre fueron 3 a las 0:00 artículos, no pueden incluirse en las estadísticas.
Según la distribución de la cantidad de noticias por hora, se puede observar que las 10 y las 15 horas de cada día son las horas pico de publicación de noticias, con más de 30.000 artículos publicados cada una. Las 12 en punto es la pausa para el almuerzo y el número de comunicados de prensa alcanza sus máximos y mínimos. El número de comunicados de prensa es menor entre las 0:00 y las 5:00 todos los días, siendo las 3:00 el punto más pequeño.
Seguimiento de puntos calientes de noticias
Este experimento pretende utilizar el método de extracción de palabras clave de noticias para rastrear los puntos calientes de noticias en estos ocho meses. Al contar la distribución de las palabras clave existentes y dibujar un histograma, los resultados son los siguientes.
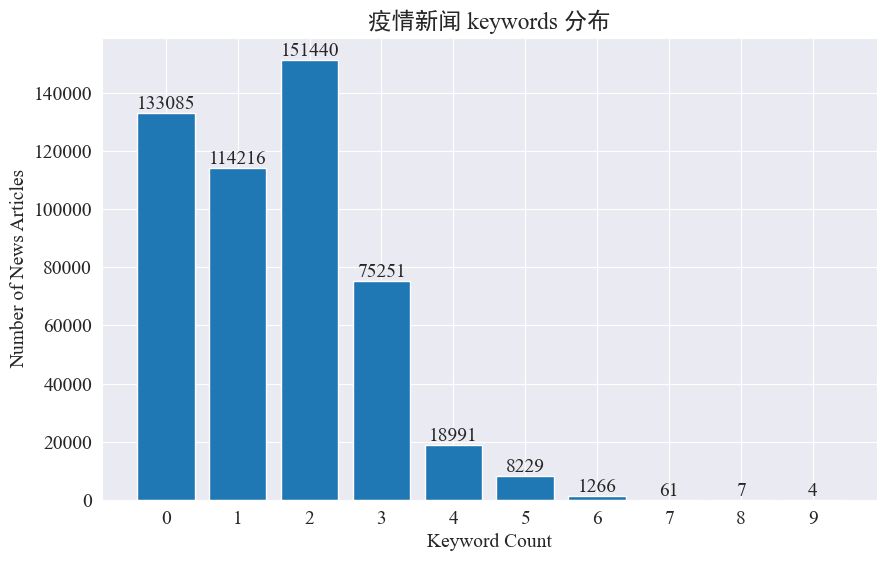
Se puede ver que la mayoría de los artículos de noticias tienen menos de 3 palabras clave y una gran proporción de artículos ni siquiera tienen palabras clave. Por lo tanto, usted mismo debe recopilar estadísticas y resumir las palabras clave para realizar el seguimiento de los puntos de acceso.Esta vez usojieba.analyse.textrank() para contar palabras clave.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Cuente 5 palabras clave nuevas, guárdelas en palabra clave_nueva, luego combine las palabras clave con ellas y elimine las palabras duplicadas.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Imprimir después de fusionar keyword_data , los resultados impresos son los siguientes.
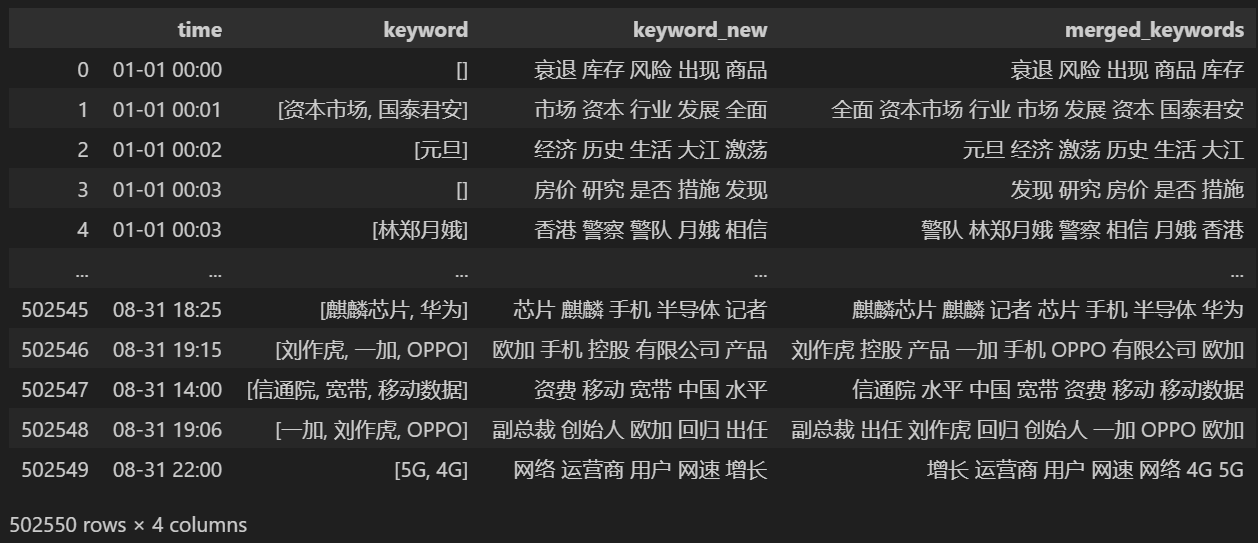
Para realizar un seguimiento de los puntos calientes, cuente la frecuencia de palabras de todas las palabras que aparecen y cuente keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Luego, basándose en los datos estadísticos anteriores, dibuje un gráfico de cambios diarios de palabras candentes.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Finalmente, se obtuvo un gráfico gif de cambios en las palabras clave en noticias sobre epidemias. Los resultados son los siguientes.
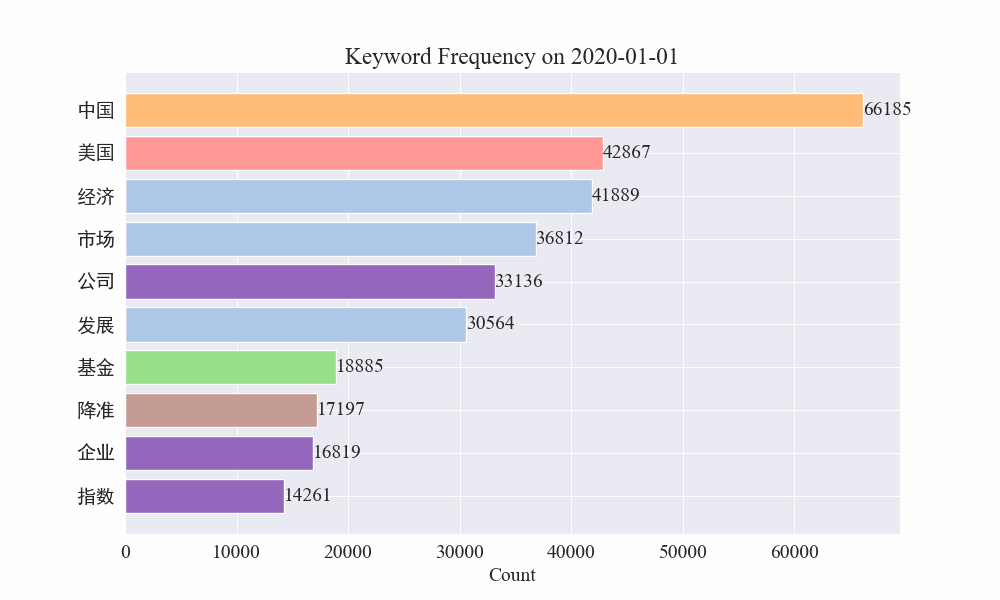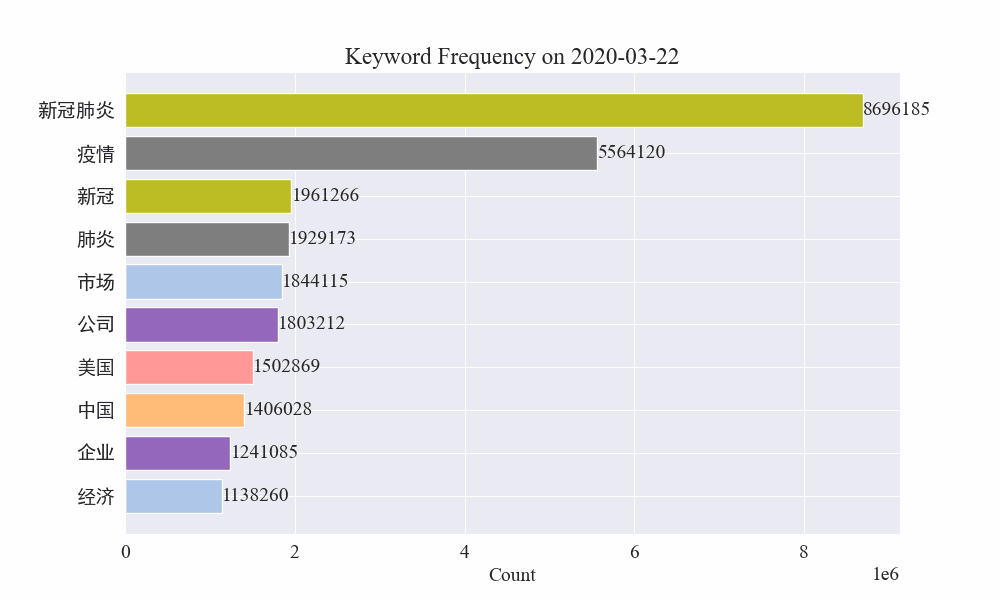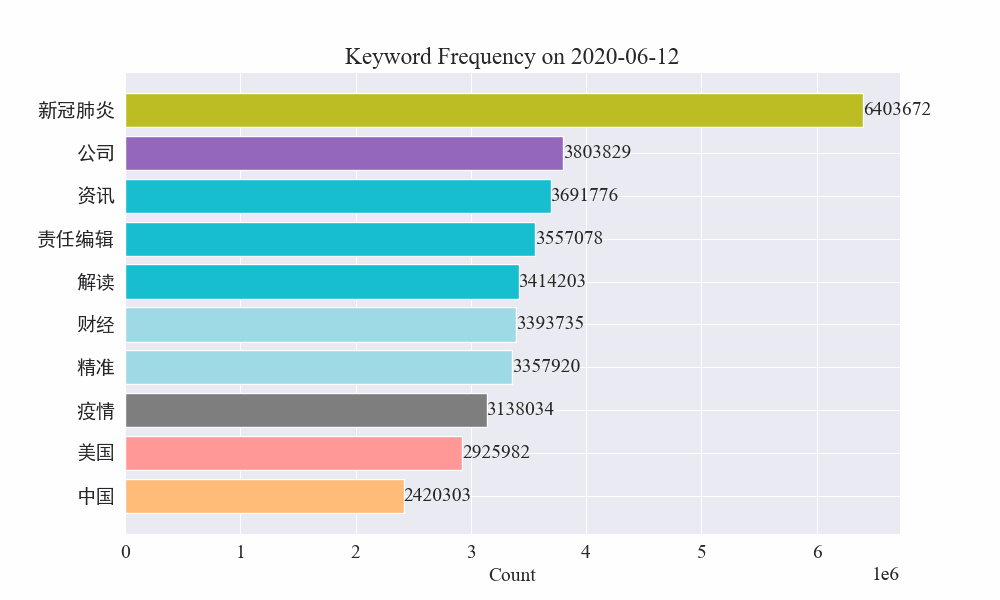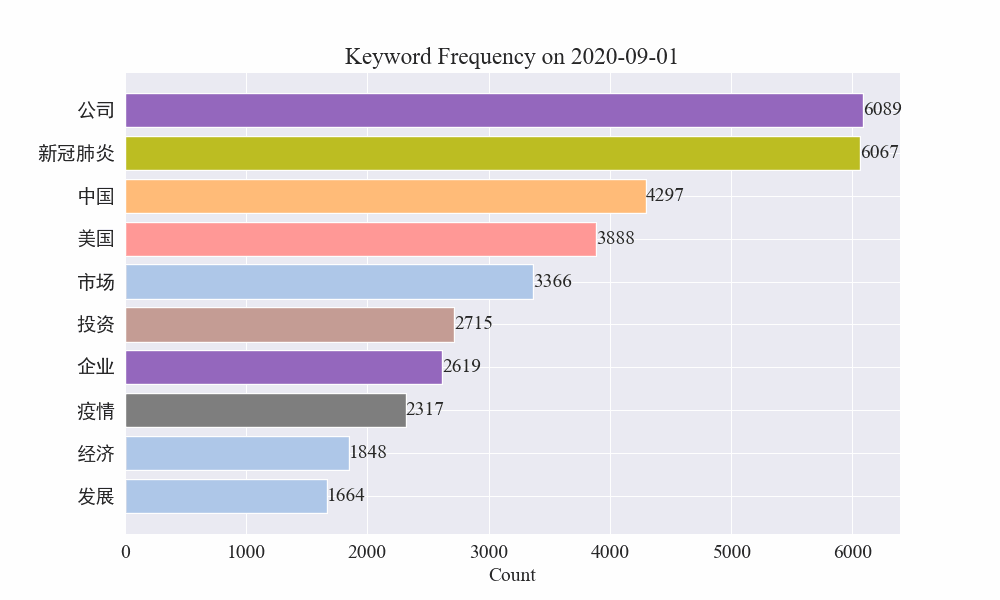
Antes del brote, los términos "empresa" e "Irán" seguían siendo elevados. Se puede ver que después del estallido de la epidemia, el número de noticias relacionadas con la epidemia comenzó a aumentar en febrero. Después de eso, los términos "nuevo coronavirus" aumentaron y continuaron en primer lugar hasta finales de agosto. La primera ola de la epidemia se desaceleró y pasó a ocupar el segundo lugar.
Esta sección primero realiza un análisis estadístico cuantitativo de los comentarios de noticias y luego realiza un análisis de sentimiento sobre diferentes comentarios.
Estadísticas diarias de recuento de comentarios de noticias
Cuente la tendencia del número de comentarios de noticias, utilice un gráfico de barras para representarla y dibuje una curva aproximada. El código es el siguiente.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
El cuadro estadístico del número de comentarios de noticias diarios se dibuja a continuación.
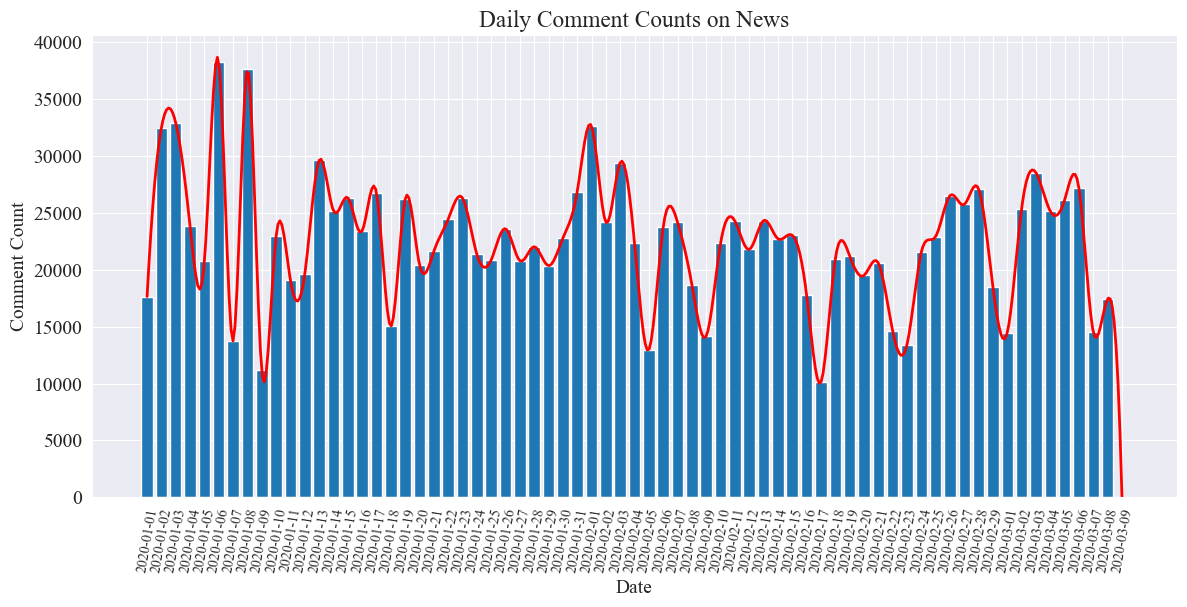
Se puede observar que el número de comentarios de noticias durante la epidemia osciló entre 10.000 y 40.000, con un promedio de unos 20.000 comentarios por día.
Estadísticas de noticias sobre epidemias por región
por provincia comment_df['province'] Cuente la cantidad de noticias en cada provincia y cuente la cantidad de comentarios sobre noticias epidémicas en cada provincia.
Primero, debes pasar el comment_df['province'] Extraer información de la provincia.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Luego, a partir de los datos estadísticos, se dibuja un gráfico circular que muestra la proporción de comentarios de noticias en cada provincia.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

En este experimento también utilizamos pyecharts.charts deMap Componente, que traza la distribución del número de comentarios en el mapa de China por provincia.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
En el HTML obtenido, la distribución del número de comentarios sobre noticias epidémicas en cada provincia de China es la siguiente.
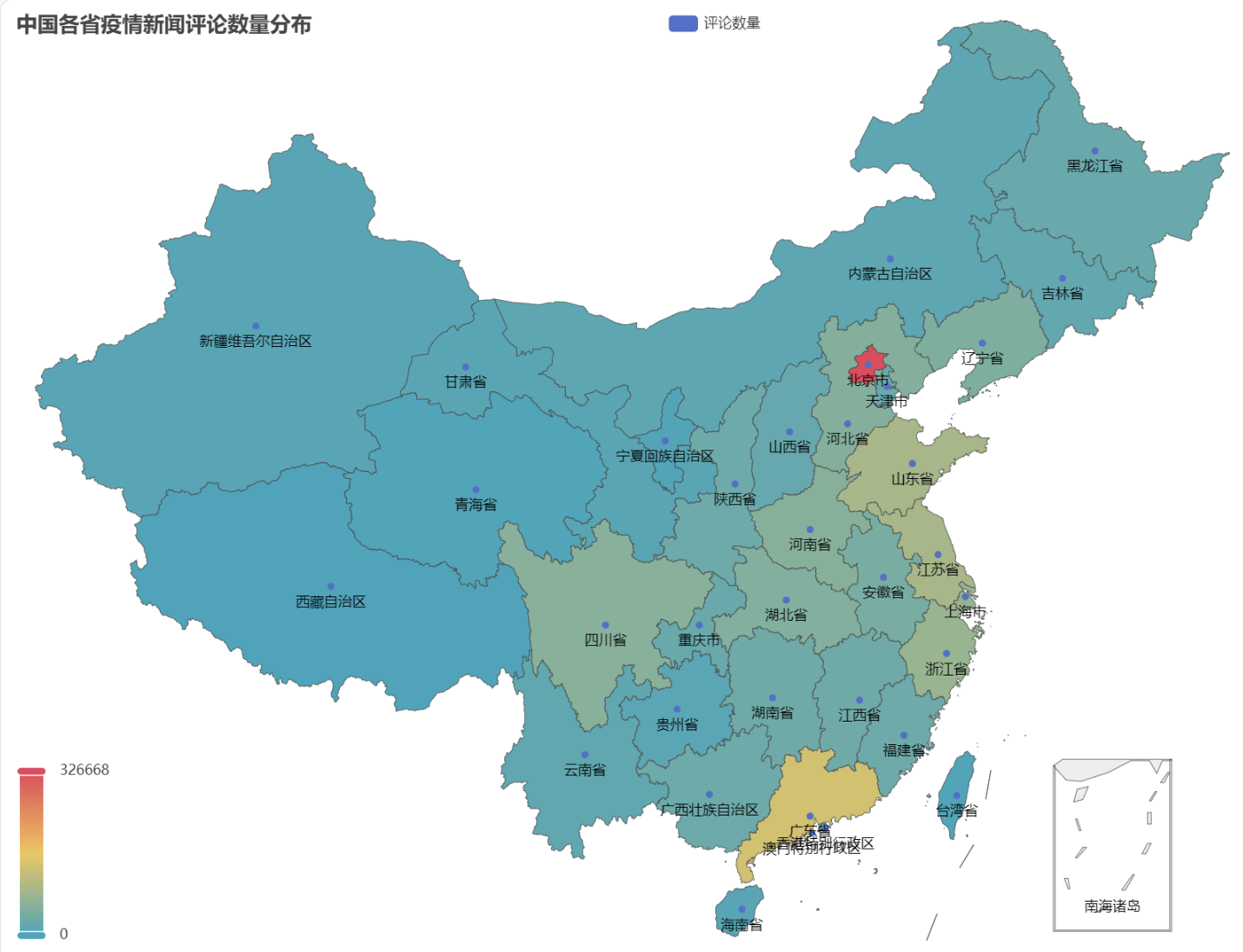
Se puede ver que durante la epidemia, el número de comentarios en Beijing representó la mayor proporción, seguido por la provincia de Guangdong, y el número de comentarios en otras provincias fue relativamente uniforme.
epidemiaRevisar el análisis de sentimiento
Este experimento utiliza la biblioteca NLP para procesar texto chino. SnowNLP , implementar el análisis del sentimiento chino, analizar cada comentario y dar el correspondientesentiment Valor, el valor está entre 0 y 1, cuanto más cerca de 1, más positivo, cuanto más cerca de 0, más negativo.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
En este experimento, se utiliza 0,5 como umbral. Cualquier valor superior a este valor es un comentario positivo y cualquier valor inferior a este valor es un comentario negativo. Al escribir código, dibuje un cuadro de análisis de sentimiento de los comentarios de noticias diarios y cuente la cantidad de comentarios positivos y la cantidad de comentarios negativos en las noticias diarias. La cantidad de comentarios positivos es un valor positivo y la cantidad de comentarios negativos es un valor negativo. valor.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
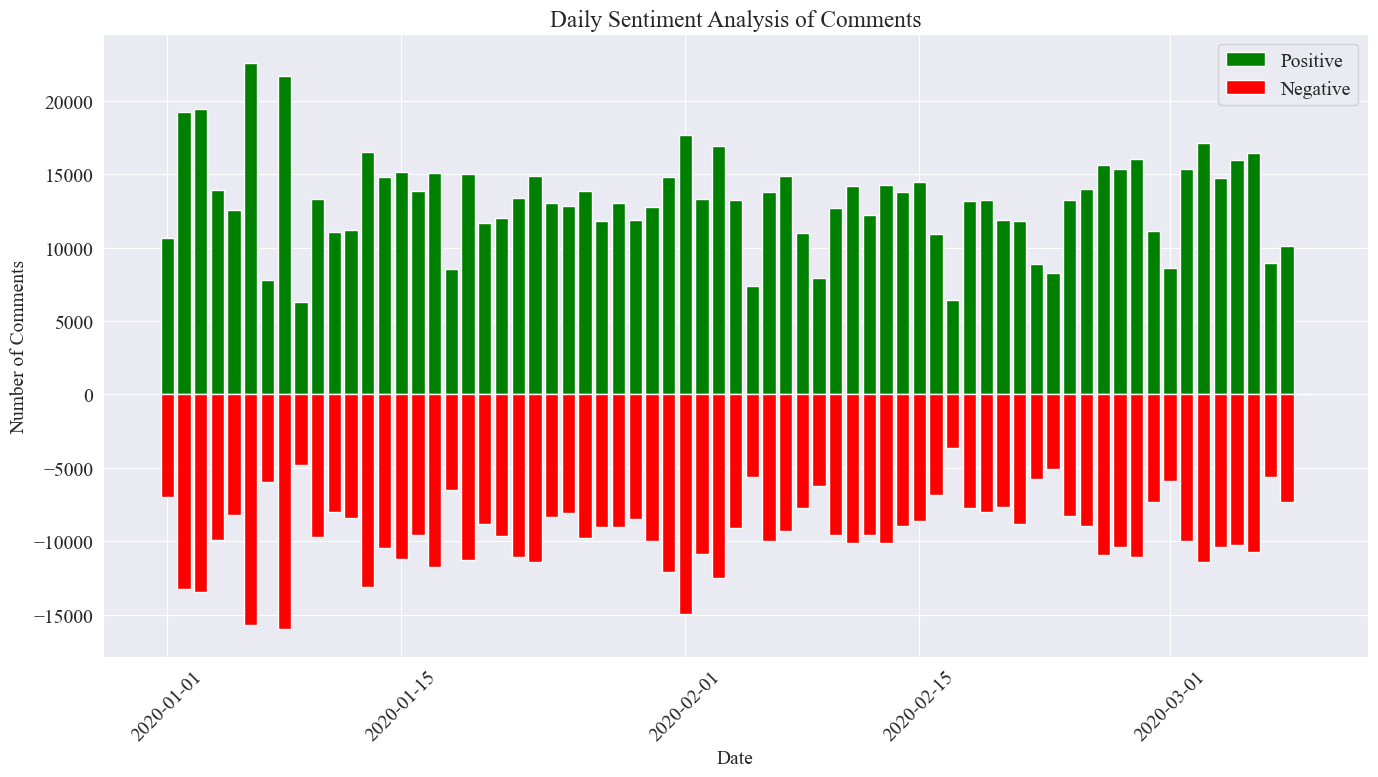
La imagen estadística final es como se muestra arriba. Se puede ver que los comentarios positivos durante la epidemia fueron ligeramente mayores que los comentarios negativos. Al contar la proporción de comentarios positivos, se encontró que la proporción de comentarios positivos fue del 58,63%. que el público tenía una actitud más positiva hacia la epidemia.
Análisis de sentimiento de los comentarios por región.
Al contabilizar la proporción de comentarios positivos publicados en cada provincia y región, se obtuvo un gráfico de la proporción de comentarios positivos en cada región.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
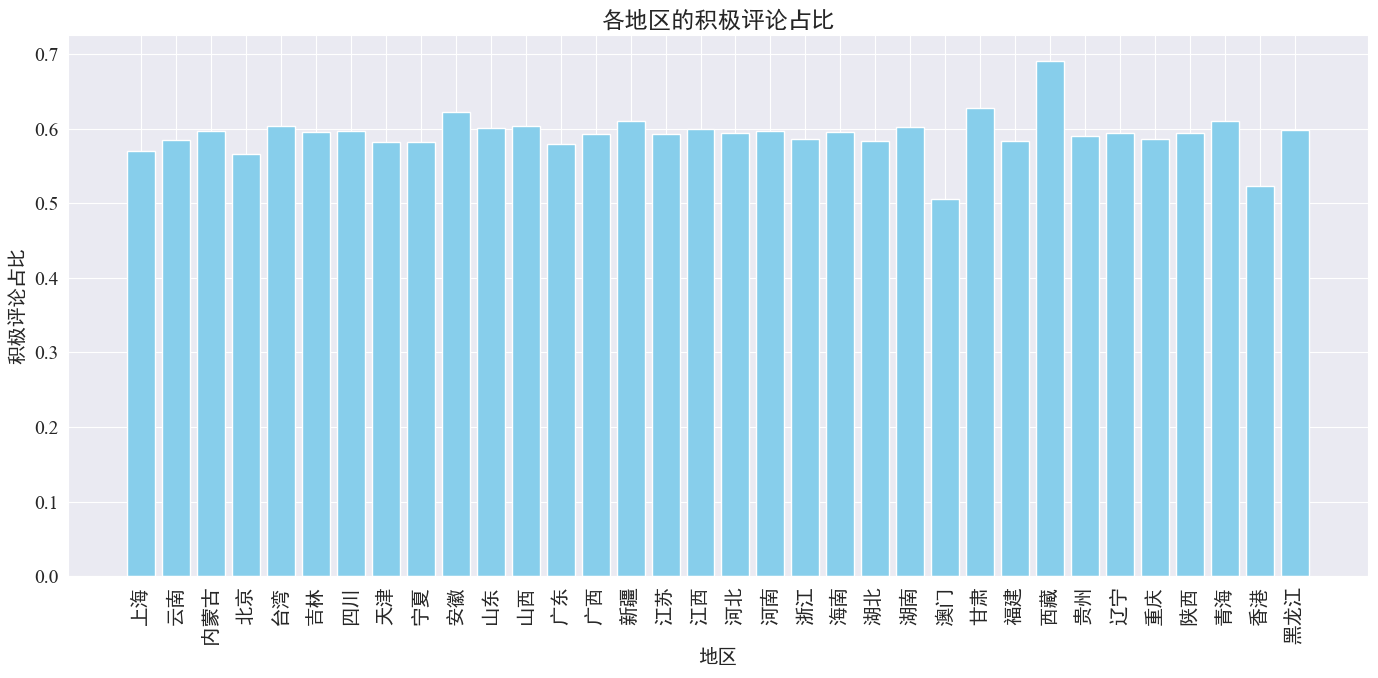
Como puede verse en la figura anterior, la proporción de comentarios positivos en la mayoría de las provincias es de alrededor del 60%. Hong Kong y Macao tienen la proporción más baja de comentarios positivos, alrededor del 50%, mientras que el Tíbet tiene la proporción más alta de comentarios positivos, cercana al 50%. 70%.
De la distribución de comentarios anterior, podemos ver que los comentarios en China continental son en su mayoría comentarios positivos, mientras que los comentarios negativos en Hong Kong y Macao han aumentado significativamente. El mayor número de comentarios positivos en el Tíbet puede deberse al error causado por. el pequeño tamaño de la muestra en el Tíbet.
Noticias, comentarios, palabra, nube, gráfico Dibujo
Los diagramas de nube de palabras de todos los comentarios, los comentarios positivos y los comentarios negativos se contaron por separado. En el dibujo del diagrama de nube de palabras, los comentarios positivos se enumeraron por encima de 0,6 y los comentarios negativos se clasificaron por debajo de 0,4. diagramas dibujados.

Se puede ver que los comentarios de la mayoría de las personas durante la epidemia son relativamente simples, como "jaja", "bien", etc. En los comentarios positivos, se pueden ver palabras alentadoras como "Vamos China", "Vamos Wuhan". , etc., mientras que en los comentarios negativos aparecen críticas como “Jaja” y “Es difícil hacer rico a un país”.

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]