моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Эпидемия COVID-19 затрагивает сердца каждого из нас. В этом случае мы попытаемся использовать методы социальных вычислений для анализа новостей и слухов, связанных с эпидемией, чтобы помочь.Эпидемическая информация Исследовать. Это задание является открытым. Мы предоставляем социальные данные во время эпидемии и призываем студентов анализировать социальные тенденции на основе новостей, слухов и юридических документов. (Совет: для анализа данных используйте методы, изученные на уроке, такие как анализ настроений, извлечение информации, понимание прочитанного и т. д.)
https://covid19.thunlp.org/ предоставляет социальные данные, связанные с новой эпидемией коронавируса, включая слухи, связанные с эпидемией, CSDC-Rumor, китайские новости, связанные с эпидемией, CSDC-News и юридические документы, связанные с эпидемией, CSDC-Legal.
В этой части набора данных собрано:
(1) Начиная с 22 января 2020 г.Ложная информация WeiboДанные включают содержание сообщений Weibo, которые считаются ложной информацией, издателей, информаторов, время судебного разбирательства, результаты и другую информацию. По состоянию на 1 марта 2020 года в общей сложности имеется 324 оригинальных текста Weibo, 31 284 пересылки и 7 912 комментариев. , используемый, чтобы помочь исследователям анализировать и изучать распространение ложной информации во время эпидемии;
(2) Платформа проверки слухов Tencent и ложные информационные данные Dingxiangyuan с 18 января 2020 года, включая такую информацию, как содержание слуха, который считается правильным или ложным, время и основание для определения того, является ли это слухом, по состоянию на На 1 марта 2020 года имеется 507 фрагментов слуховых данных, в том числе 124 фрагмента фактических данных. Распределение данных следующее: отрицательные случаи: 420, положительные случаи: 33 и неопределенные: 54.
Эта часть набора данных собирает данные новостей, начиная с 1 января 2020 года, включая название, содержание, ключевые слова и другую информацию новостей. По состоянию на 16 марта 2020 года было собрано в общей сложности 148 960 новостей и 1 653 086 соответствующих комментариев. Используется, чтобы помочь исследователям анализировать и изучать новостные данные во время эпидемии.
Эти данные взяты из КЕЙЛ В общей сложности из собранных анонимных данных юридических документов было отобрано 1203 части исторических данных, связанных с эпидемией. Каждая часть данных включает название документа, номер дела и полный текст документа, которые могут быть использованы исследователями для проведения исследований. по актуальным правовым вопросам во время эпидемии.
Это задание открытое, мы начнем с
Оценивание заданий по другим аспектам.
[1] Достоверность информации в Twitter. в Трудах WWW, 2011.
[2] Обнаружение слухов в микроблогах с помощью рекуррентных нейронных сетей. Труды IJCAI, 2016.
[3] Сверточный подход к идентификации дезинформации. в Трудах IJCAI, 2017.
[4] Распространение правдивых и ложных новостей в Интернете. Наука, 2018.
[5] Ложная информация в Интернете и социальных сетях: исследование. Препринт arXiv, 2018.
[6] Характеристика аффективных норм английских слов по дискретным эмоциональным категориям. Методы исследования поведения, 2007.
Этот эксперимент предоставляет набор данных о слухах, связанных с эпидемией, CSDC-Rumor. Анализируя содержимое набора данных, мы решили сначала выполнить количественный статистический анализ набора данных, затем использовать кластеризацию для реализации семантического анализа слухов и, наконец, разработать набор данных. система обнаружения слухов.
Формат данных
Этот эксперимент предоставляет набор данных о слухах, связанных с эпидемией, CSDC-Rumor, который собирает данные ложной информации Weibo и данные, опровергающие слухи. Набор данных содержит следующее.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Ложная информация Weiboсоответственно rumor_weibo иrumor_forward_comment двое с одинаковыми именамиjson описано в файле.rumor_weibo серединаjson Конкретные поля следующие:
rumorCode: уникальный код слуха, с помощью которого можно получить прямой доступ к странице сообщения о слухах.title: Заголовок сообщения о слухе.informerName: имя репортера в Weibo.informerUrl: ссылка репортера на Weibo.rumormongerName: имя Weibo человека, опубликовавшего слух.rumormongerUr: ссылка на Weibo человека, разместившего слух.rumorText: Содержание слухов.visitTimes: Сколько раз был посещен этот слух.result: Результаты обзора слухов.publishTime: Время, когда распространился слух.related_url: Ссылки на доказательства, правила и т. д., связанные с этим слухом.rumor_forward_comment серединаjson Конкретные поля следующие:
uid: Опубликовать идентификатор пользователя.text: Прокомментируйте или перешлите постскриптум.date: время выпуска.comment_or_forward: двоичный, либо comment, или forward, указывающий, является ли сообщение комментарием или пересылаемым постскриптумом.Tencent и Lilac Garden ложная информацияФормат контента:
date: времяexplain: Тип слухаtag:тег слуховabstract: Контент, используемый для проверки слухов.rumor: СлухПредварительная обработка данных
проходить json.load() Извлеките данные слухов Weibo отдельноweibo_data Комментарий о пересылке данных со слухамиforward_comment_data , а затем преобразуйте его в формат DataFrame. Два файла с одинаковым именем, статья Weibo и пересылка комментариев Weibo соответствуют друг другу. При обработке данных в папке слух_форвард_коммент добавьте слухкод для последующего сопоставления.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
В этом разделе используется количественный статистический анализ, чтобы получить конкретное представление о распространении слухов об эпидемиях по данным Weibo.
Статистика количества посещений слухов
статистика weibo_df['visitTimes'] Распределение времен доступа и построение соответствующей гистограммы. Результаты следующие.
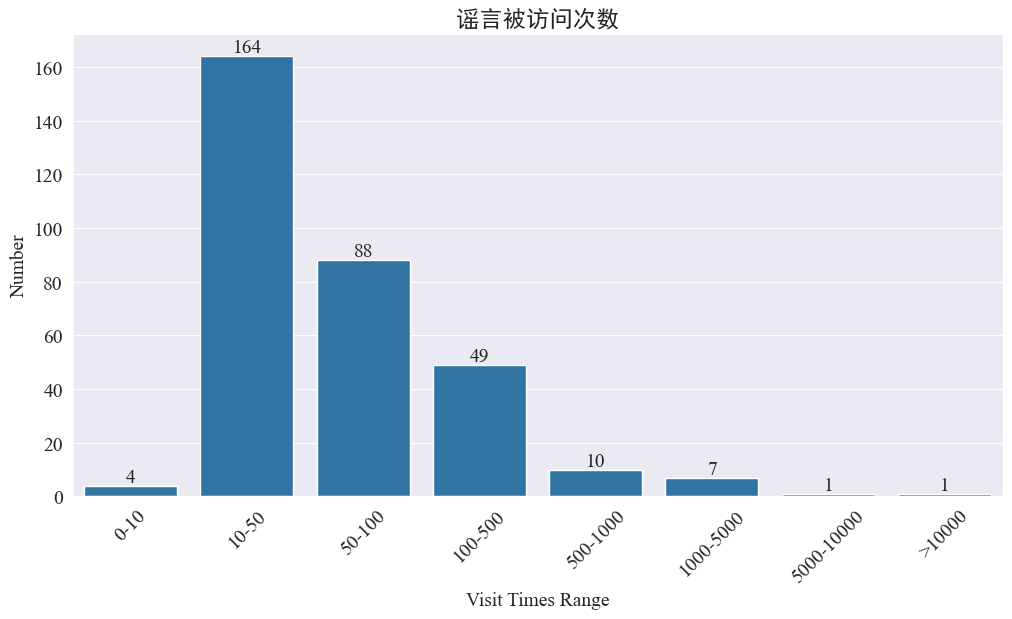
Судя по количеству посещений Weibo, большинство слухов об эпидемиях посещались на Weibo менее 500 раз, причем наибольшая доля приходится на 10-50 раз. Однако на Weibo также ходят слухи, к которым обращались более 5000 раз, что вызвало серьезные последствия и по закону считается «серьезным».
Статистика появления распространителей слухов и информаторов
по статистике weibo_df['rumormongerName'] иweibo_df['informerName'] Получены следующие данные о количестве слухов, опубликованных каждым издателем слухов, и количестве слухов, о которых сообщил каждый репортер.
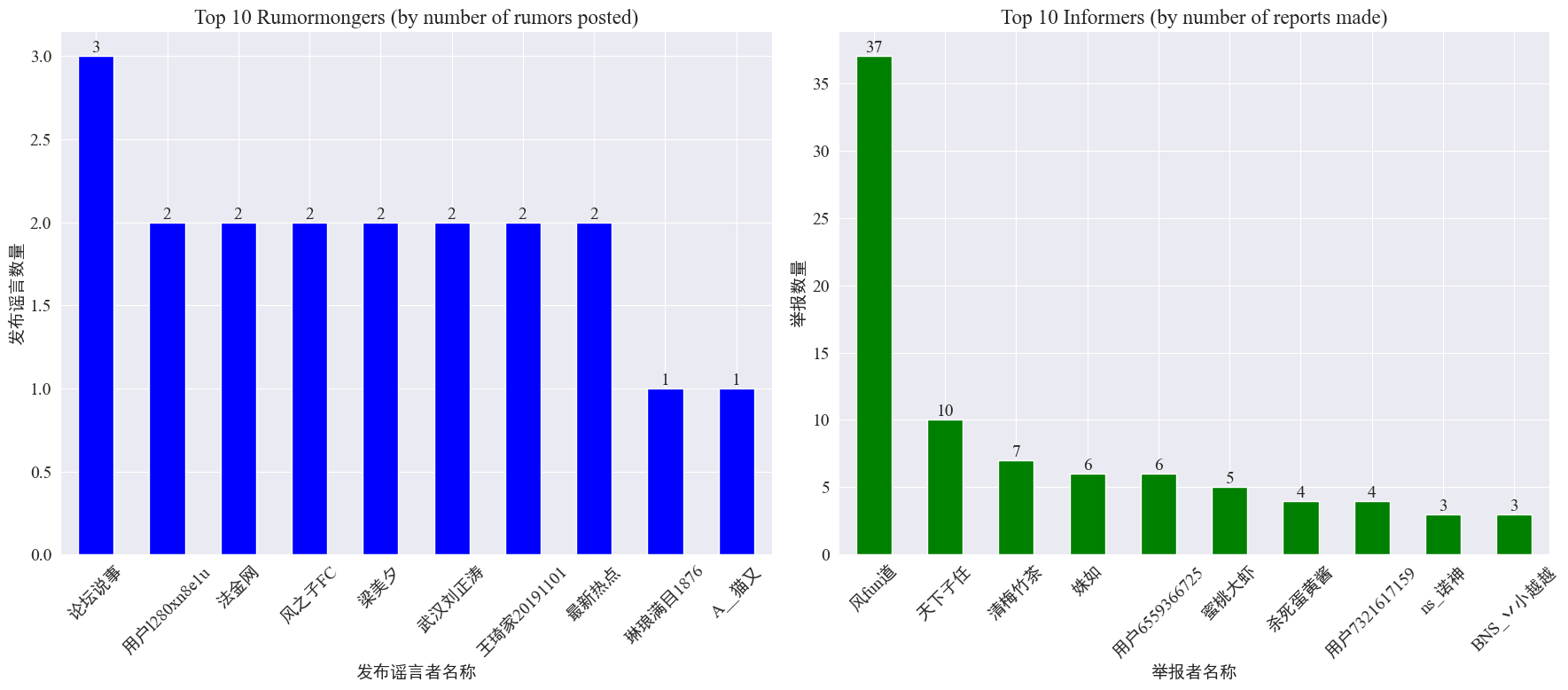
Видно, что количество слухов, опубликованных создателями слухов, не сосредоточено на нескольких людях, а относительно равномерно. Аккаунт, на котором опубликовано больше всего слухов, опубликовал три сообщения со слухами на Weibo. Каждый из 10 крупнейших информаторов сообщил как минимум о 3 слуховых статьях. Среди них количество слухов, о которых сообщили информаторы на Weibo, было значительно выше, чем у других пользователей, и достигло 37 статей.
Основываясь на приведенных выше данных, аудитория может сосредоточиться на сообщениях об аккаунтах с большим количеством слухов, чтобы облегчить обнаружение слухов.
Статистика распространения комментариев по слухам
Подсчитав распределение объема распространения слухов и объема комментариев, получается следующая картина распределения.

Видно, что количество комментариев и репостов на большинстве слухов Weibo находится в пределах 10 раз, при этом максимальное количество комментариев не превышает 500, а максимальное количество репостов достигает более 10 000. Согласно Закону об управлении Интернетом, если слух распространился более 500 раз, это считается «серьезной» ситуацией.
Кластерный анализ текстов слухов
Эта часть выполняет предварительную обработку данных текстов слухов Weibo и выполняет кластерный анализ после сегментации слов, чтобы увидеть, где сконцентрированы слухи Weibo.
Предварительная обработка данных
Сначала очистите текст данных слухов, удалите значения по умолчанию и <> Содержимое прилагаемой ссылки.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Затем загрузите стоп-слова на китайском языке и используйте стоп-слова cn_стоп-слова ,использоватьjieba Реализуйте обработку данных сегментацией слов и выполните векторизацию текста.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Определите лучшую кластеризацию
Используя метод локтя, определяются лучшие кластеры.
Метод локтя — это метод, используемый для определения оптимального количества кластеров в кластерном анализе. Он основан на взаимосвязи между суммой квадратов ошибок (SSE) и количеством кластеров. SSE — это сумма квадратов евклидовых расстояний от всех точек данных в кластере до центра кластера, которому он принадлежит. Он отражает эффект кластеризации: чем меньше SSE, тем лучше эффект кластеризации.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
Метод локтя определяет оптимальное количество кластеров путем поиска «локтя», то есть поиска точки на кривой, после которой скорость снижения SSE существенно замедляется. Эта точка похожа на локоть руки, отсюда и локтевой метод. название «Метод локтя». Эту точку обычно считают оптимальным количеством кластеров.
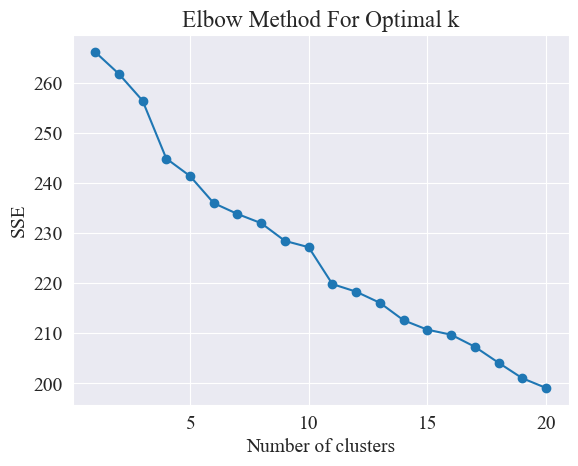
Из приведенного выше рисунка определено, что значение кластеризации колена равно 11, и построена соответствующая диаграмма рассеяния. Результаты следующие.
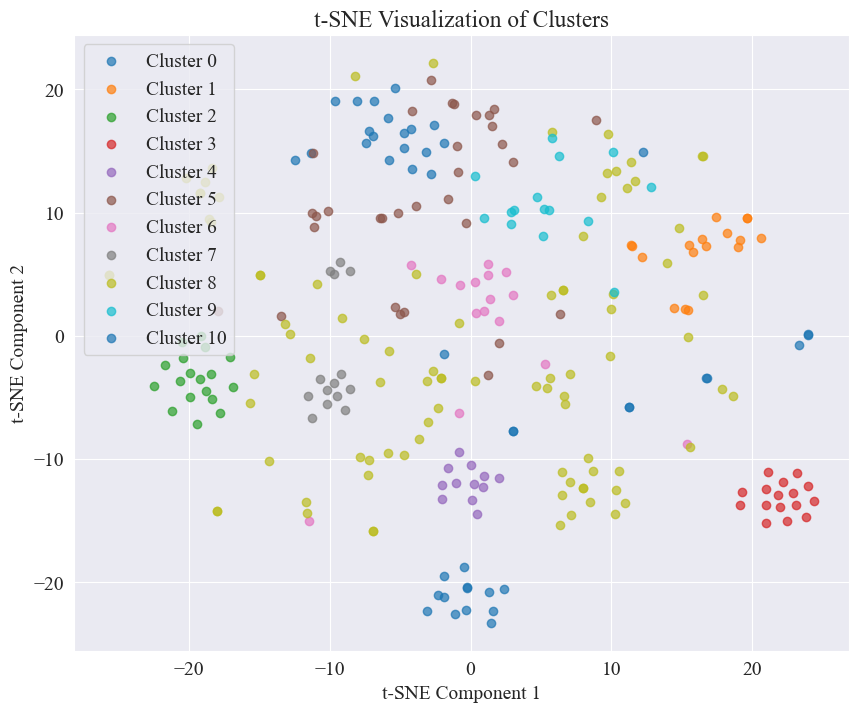
Видно, что большинство постов Weibo, о которых ходят слухи, хорошо сгруппированы: № 3 и № 4, некоторые широко распространены, но не очень хорошо сгруппированы, например № 5 и № 8;
Результаты кластеризации
Чтобы четко показать, какие слухи группируются в каждой категории, для каждой категории нарисована облачная диаграмма. Результаты следующие.

Распечатайте хорошо сгруппированный контент Weibo по слухам, и результаты будут следующими.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Кластерный анализ результатов проверки слухов
Кластеризация текстового содержимого слухов может быть не очень хороша для анализа содержания слухов, поэтому мы решили сгруппировать результаты проверки слухов.
Определите лучшую кластеризацию
Используя локтевой график, определите лучшую кластеризацию.
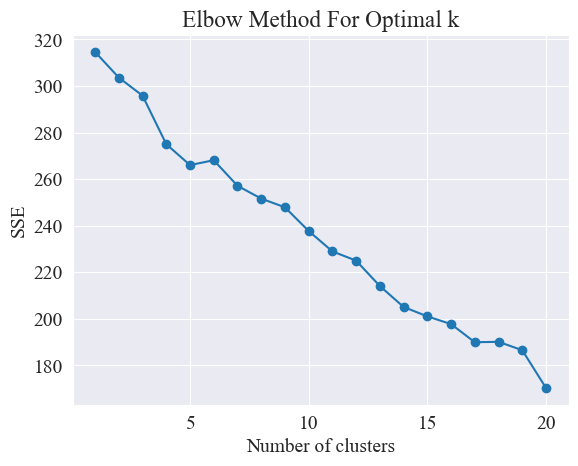
Из приведенной выше диаграммы колен можно определить два колена: одно — когда кластеризация равна 5, а другое — когда кластеризация равна 20. Я выбираю 20 для кластеризации.
Диаграмма рассеяния, полученная путем кластеризации 20 категорий, выглядит следующим образом.
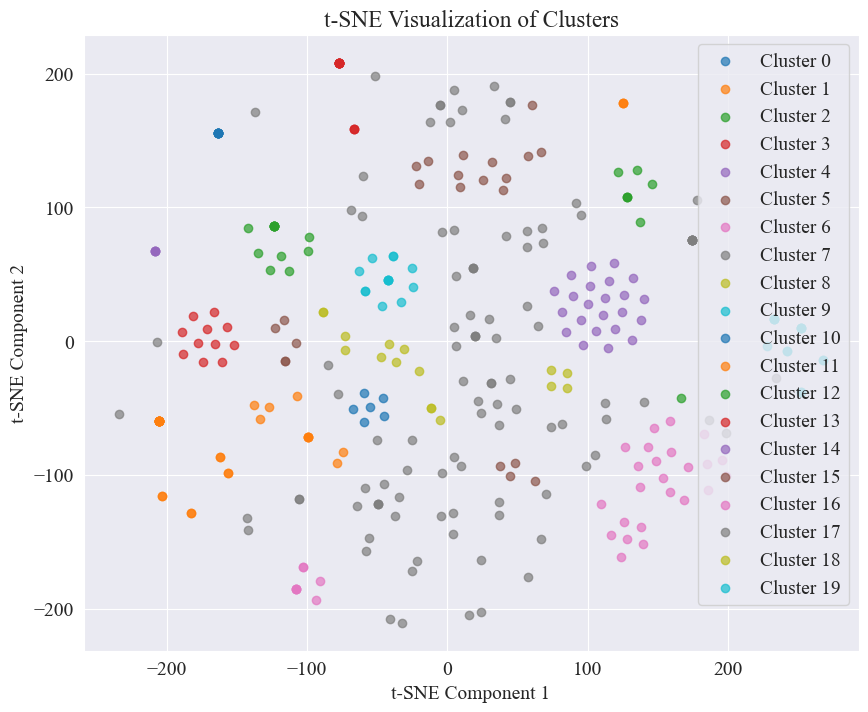
Видно, что большинство из них хорошо кластеризованы, но 7-я и 17-я категории кластеризованы недостаточно хорошо.
Результаты кластеризации
Чтобы четко показать, какие результаты проверки слухов сгруппированы в каждой категории, для каждой категории строится облачная диаграмма. Результаты следующие.

Распечатайте результаты хорошо сгруппированного обзора слухов. Результаты следующие.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Для обнаружения слухов мы решили использовать наборы данных, которые были опровергнуты. fact.json Сравните сходство между опровергнутыми слухами и реальными слухами и выберите опровергнутую статью, имеющую наибольшее сходство со слухом Weibo, в качестве основы для обнаружения слухов.
Загрузка данных Weibo по слухам и наборов данных, опровергающих слухи
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Используйте предварительно обученные языковые модели для кодирования слухов Weibo и заголовков, опровергающих слухи, во встраиваемые векторы.
В этом эксперименте использовалось bert-base-chinese В качестве предварительно обученной модели выполните обучение модели. Модель SimCSE используется для улучшения представления и измерения сходства семантики предложений посредством контрастного обучения.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Рассчитать сходство
Чтобы вычислить сходство, для расчета полного сходства используются встраивание предложений и сходство именованных объектов модели SimCSE.
extract_entitiesФункция извлекает именованные объекты из текста, используя модель NER.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityФункция вычисляет сходство именованного объекта между двумя текстами.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityФункция объединяет встраивание предложений и сходство именованных объектов модели SimCSE для расчета полного сходства.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Внедрить обнаружение слухов
Путем сравнения сходств реализуется механизм обнаружения слухов.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
Вывод следующий:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Успешно нашел основания для опровержения слухов и вынес решение об опровержении слухов.
Формат данных
Этот эксперимент предоставляет набор данных новостей CSDC-News, связанных с эпидемией, который собирает новости и комментарии за первую половину 2020 года. Набор данных содержит следующее.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
Папка данных разделена на три части:data,comment。
data В папке находится несколько файлов, каждый файл соответствует данным на определенную дату, в форматеjson . Содержимое этой части соответствует текстовым данным новости (будет постепенно обновляться с датой), а поля включают:
time: Время выхода новостей.title: Название новости.url: Исходный адрес ссылки новости.meta: текстовая информация новости, включающая следующие поля: content: Текстовое содержание новости.description: Краткое описание новости.title: Название новости.keyword: Ключевые слова новостей.type: Тип новости.comment В папке находится несколько файлов, каждый файл соответствует данным на определенную дату, в форматеjson . Эта часть контента соответствует данным комментариев новостей (между данными комментариев и текстовыми данными новостей может быть задержка около недели). Поля включают в себя:
time: Время выпуска новостей и data Соответствует данным в папке.title: заголовок новости с data Соответствует данным в папке.url: исходный адрес ссылки на новость и data Соответствует данным в папке.comment: Информация о комментариях к новостям. Это поле представляет собой массив. Каждый элемент массива содержит следующую информацию: area: Область рецензента.content:Комментарии.nickname: псевдоним рецензента.reply_to: Объект ответа комментатора. Если его нет, это означает, что это не ответ.time: Время комментариев.Предварительная обработка данных
Данные о новостных статьях data При предварительной обработке данных необходимоmeta Содержимое выпускается и сохраняется в формате DataFrame.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
В обзорных данных comment При предварительной обработке данных необходимоcomment Содержимое выпускается и сохраняется в формате DataFrame.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Загрузить набор данных
Загрузите набор данных в соответствии с вышеуказанной функцией предварительной обработки данных.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Результат печати показывает, что длина данных новостей: 502550, а длина данных комментариев: 1534616.
Статистика распределения новостей по времени
Посчитайте отдельно news_df Количество новостных статей за месяц и количество новостных статей в час представлены гистограммами и линейными диаграммами. Результаты следующие.
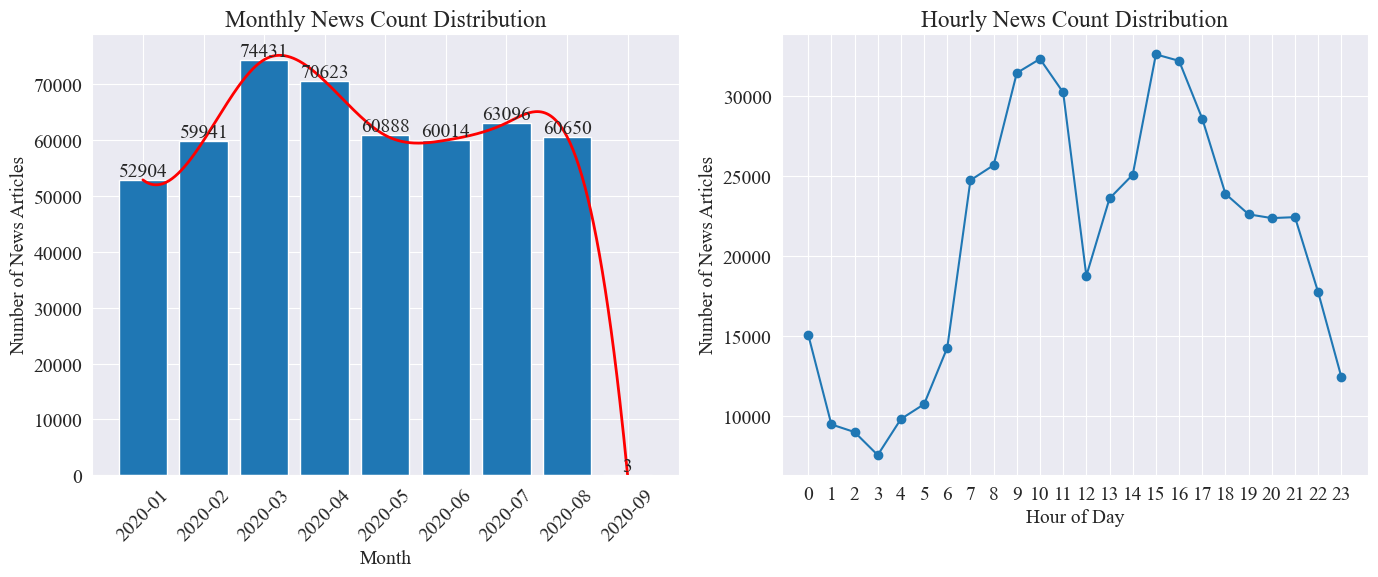
Как видно из приведенного выше рисунка, с началом эпидемии количество новостей увеличивалось из месяца в месяц, достигнув пика в марте с 74 000 новостных статей, а затем постепенно снижалось и стабилизировалось до 60 000 статей в месяц, из которых данные за сентябрь составили 3 статьи в 0:00, могут не включаться в статистику.
Судя по распределению количества новостей в час, видно, что 10 и 15 часов каждый день являются часами пикового выпуска новостей, в каждом из которых публикуется более 30 000 статей. В 12 часов наступает обеденный перерыв, а количество выпусков новостей достигает пиков и спадов. Количество выпусков новостей наименьшее в период с 0:00 до 5:00 каждый день, причем наименьшее значение составляет 3:00.
Отслеживание горячих точек новостей
В этом эксперименте предполагается использовать метод извлечения ключевых слов новостей для отслеживания горячих точек новостей за эти восемь месяцев. Подсчитав распределение существующих ключевых слов и построив гистограмму, мы получили следующие результаты.
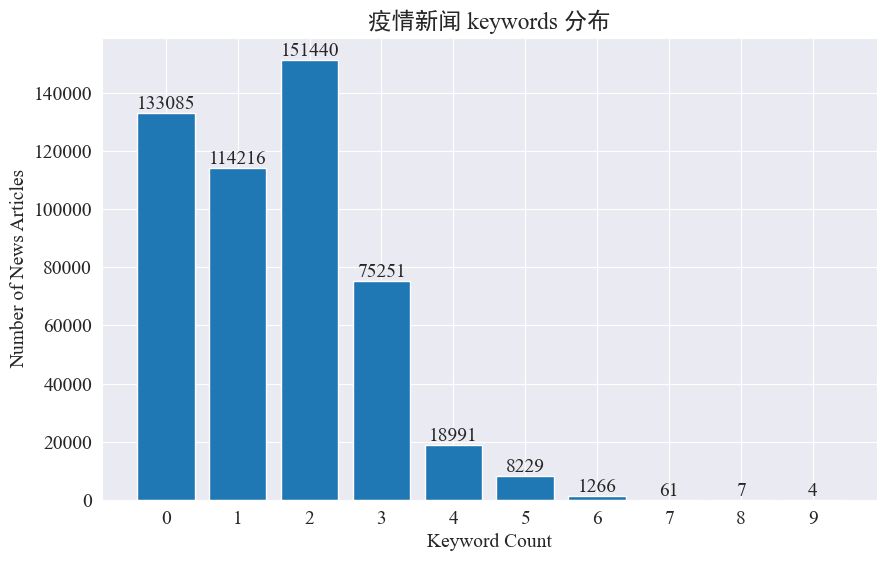
Видно, что большинство новостных статей имеют менее трех ключевых слов, а большая часть статей даже не имеет ключевых слов. Поэтому вам необходимо самостоятельно собирать статистику и суммировать ключевые слова для отслеживания хотспотов.На этот раз используйтеjieba.analyse.textrank() для подсчета ключевых слов.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Отсчитайте 5 новых ключевых слов, сохраните их в ключевое слово_new, затем объедините с ними ключевые слова и удалите повторяющиеся слова.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Печать после слияния keyword_data , результаты печати следующие.
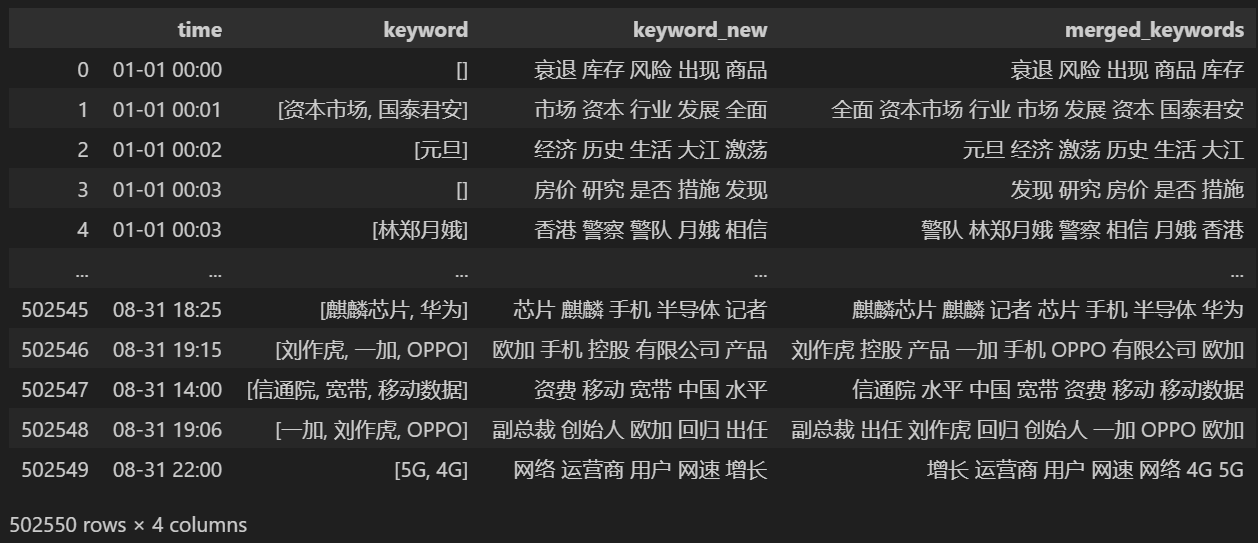
Чтобы отслеживать «горячие точки», подсчитайте частоту появления всех встречающихся слов и подсчитайте keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Затем на основе приведенных выше статистических данных постройте график ежедневного изменения горячих слов.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Наконец, была получена диаграмма изменений ключевых слов в новостях об эпидемиях. Результаты следующие.
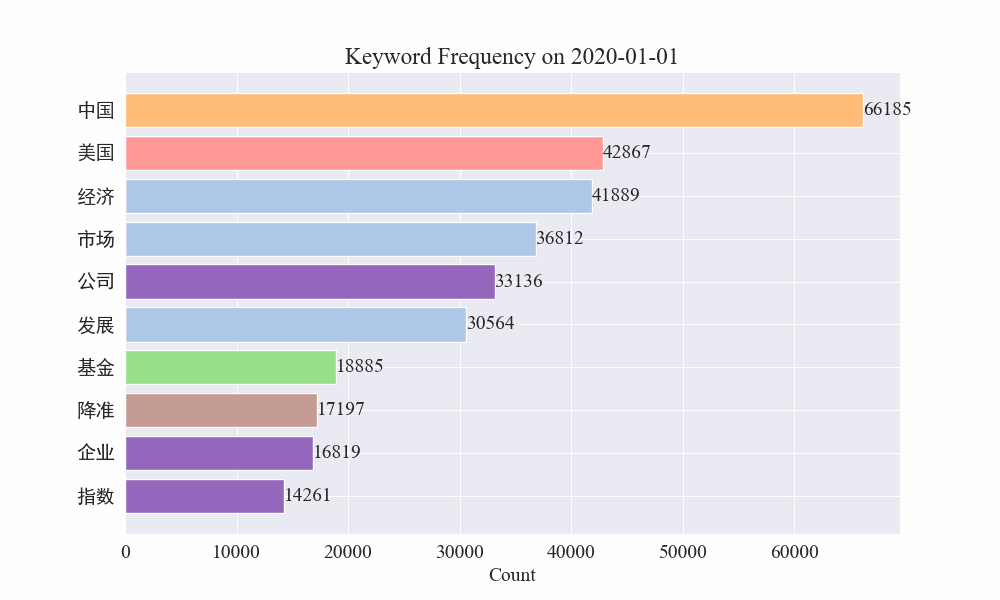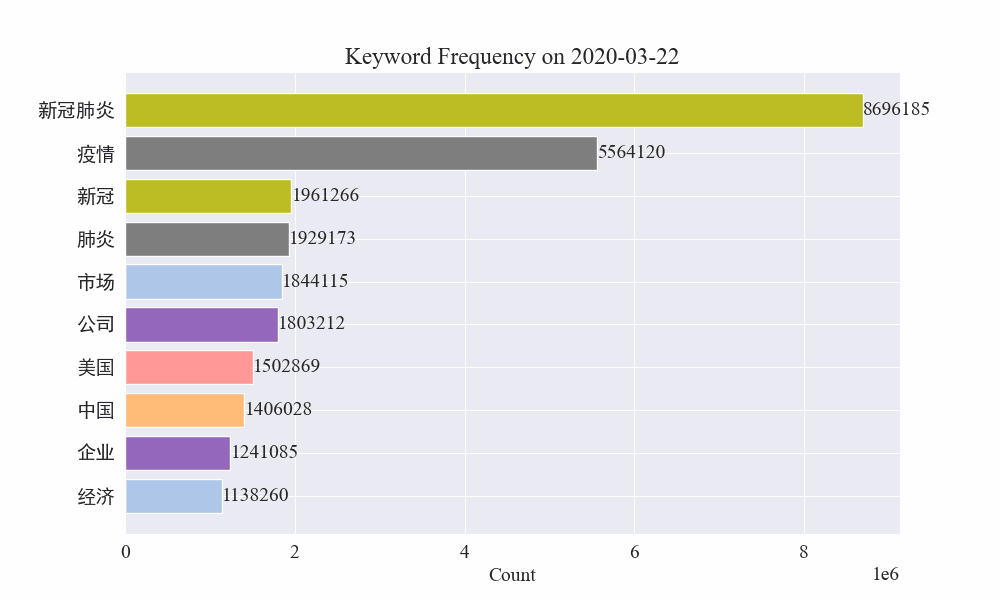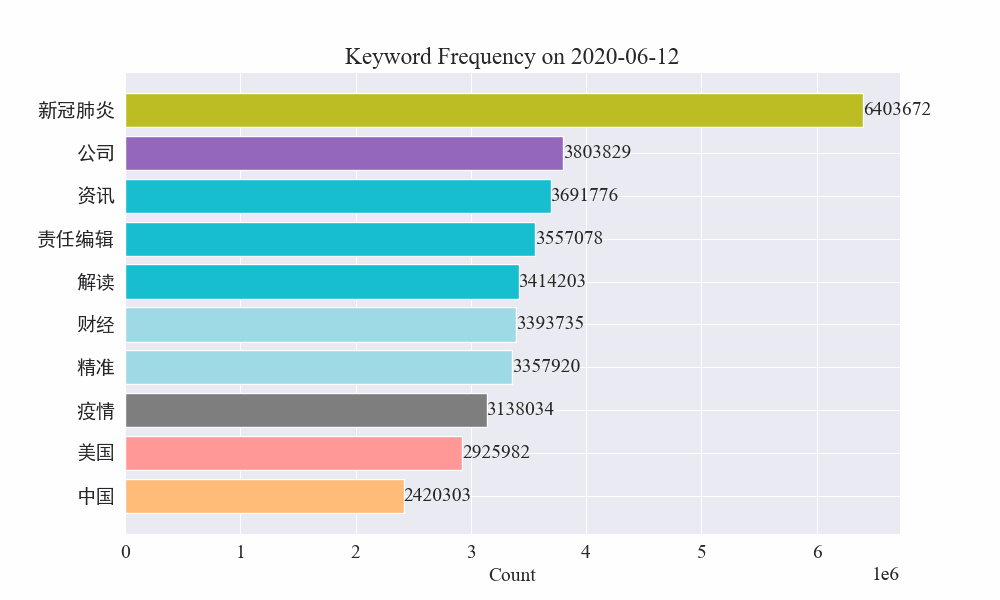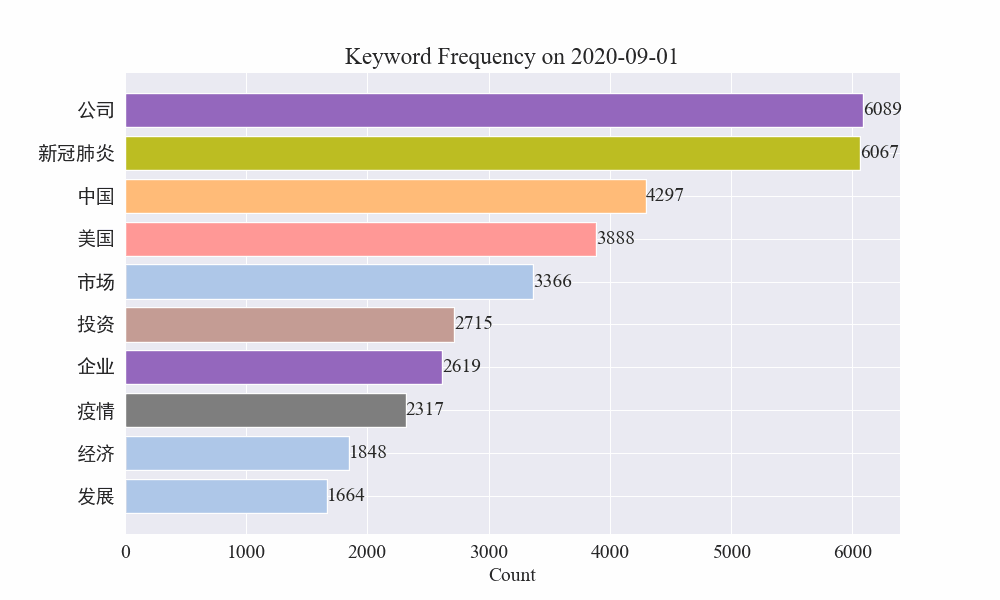
До вспышки термины «компания» и «Иран» оставались высокими. Видно, что после начала эпидемии количество новостей, связанных с эпидемией, начало расти в феврале. После этого термин «новый коронавирус» резко вырос и продолжал оставаться на первом месте до конца августа. первая волна эпидемии замедлилась и вышла на второе место.
В этом разделе сначала проводится количественный статистический анализ комментариев к новостям, а затем анализ настроений по различным комментариям.
Статистика количества комментариев в новостях за день
Подсчитайте тенденцию количества комментариев к новостям, используйте для ее представления гистограмму и нарисуйте приблизительную кривую. Код выглядит следующим образом.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Статистическая диаграмма количества ежедневных комментариев к новостям строится следующим образом.
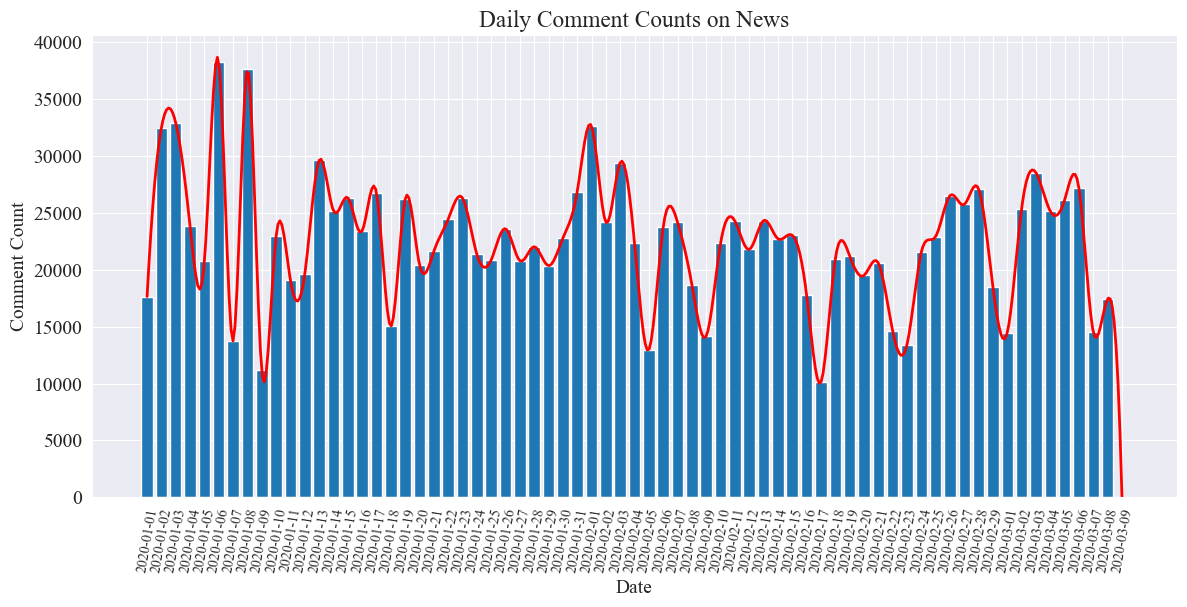
Видно, что количество новостных комментариев во время эпидемии колебалось от 10 000 до 40 000, при этом в среднем около 20 000 комментариев в день.
Статистика эпидемических новостей по регионам
по провинциям comment_df['province'] Подсчитайте количество новостей в каждой провинции и подсчитайте количество комментариев к новостям об эпидемии в каждой провинции.
Сначала вам нужно пройти comment_df['province'] Извлеките информацию о провинции.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Затем на основе статистических данных строится круговая диаграмма, показывающая долю комментариев к новостям в каждой провинции.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

В этом эксперименте мы также использовали pyecharts.charts изMap Компонент, отображающий распределение количества комментариев на карте Китая по провинциям.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
В полученном HTML распределение количества комментариев к новостям об эпидемии в каждой провинции Китая выглядит следующим образом.
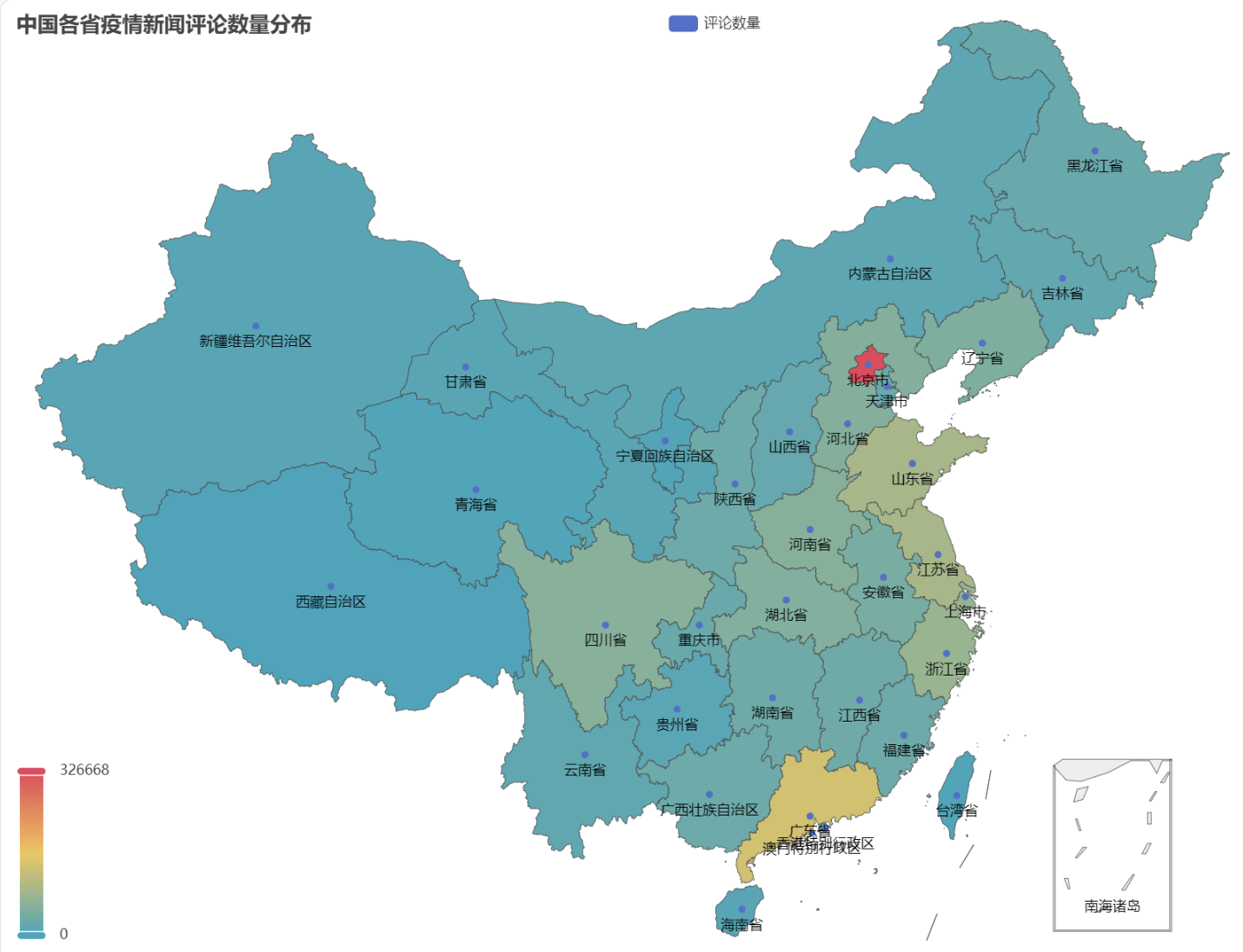
Видно, что во время эпидемии наибольшая доля комментариев приходилась на Пекин, за ним следовала провинция Гуандун, а количество комментариев в других провинциях было относительно равномерным.
эпидемияОбзор анализа настроений
В этом эксперименте используется библиотека НЛП для обработки текста на китайском языке. SnowNLP , внедрить анализ настроений на китайском языке, проанализировать каждый комментарий и дать соответствующую оценку.sentiment Значение, значение находится между 0 и 1, чем ближе к 1, тем более положительное, чем ближе к 0, тем более отрицательное.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
В этом эксперименте в качестве порога используется значение 0,5. Все, что превышает это значение, является положительным комментарием, а все, что меньше этого значения, является отрицательным комментарием. Написав код, нарисуйте диаграмму анализа настроений ежедневных комментариев к новостям и подсчитайте количество положительных комментариев и количество отрицательных комментариев к ежедневным новостям. Количество положительных комментариев — это положительное значение, а количество отрицательных комментариев — отрицательное. ценить.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
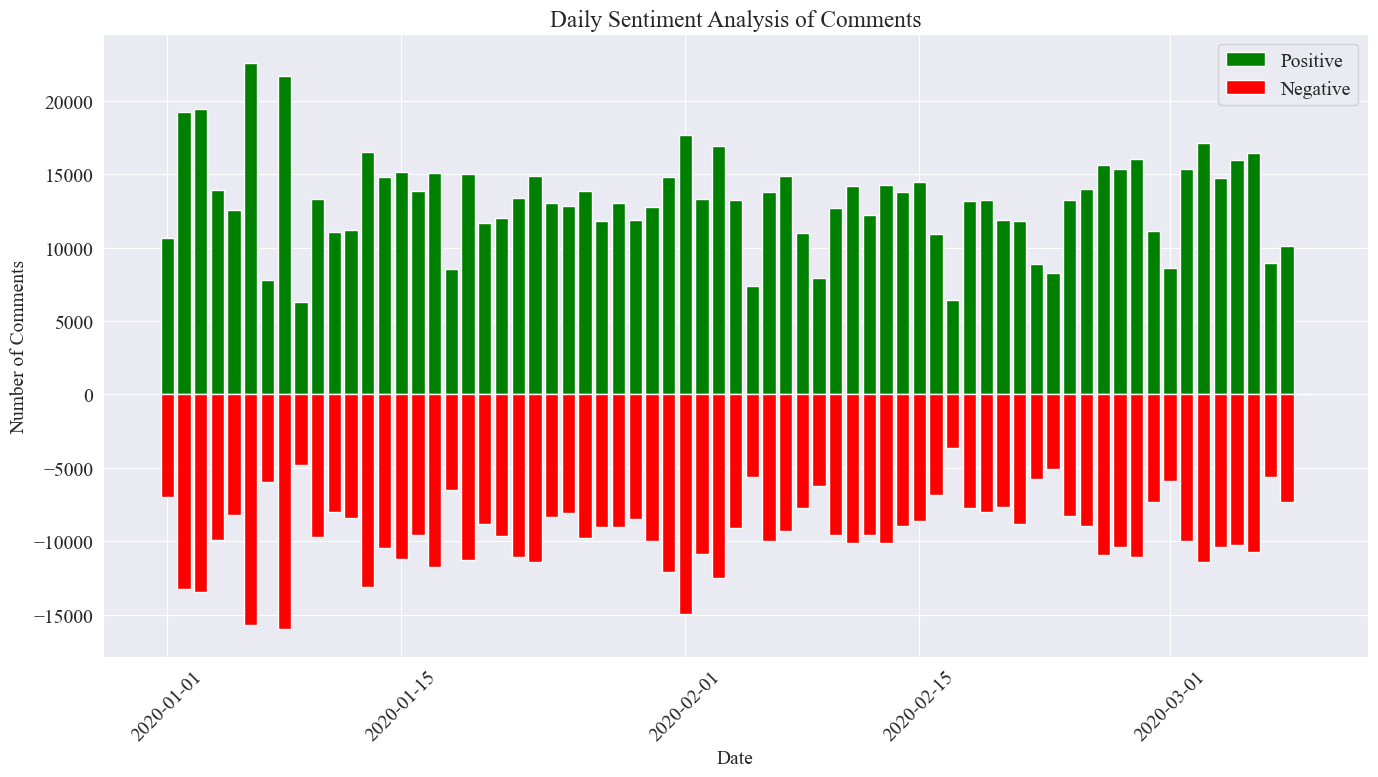
Итоговая статистическая картина показана выше. Видно, что положительных комментариев во время эпидемии было немного больше, чем отрицательных. Подсчитав долю положительных комментариев, выяснилось, что доля положительных комментариев составила 58,63%, что указывает на то. что общественность более позитивно отнеслась к эпидемии.
Анализ тональности комментариев по регионам
Путем подсчета доли положительных комментариев, размещенных в каждой провинции и регионе, был получен график доли положительных комментариев в каждом регионе.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
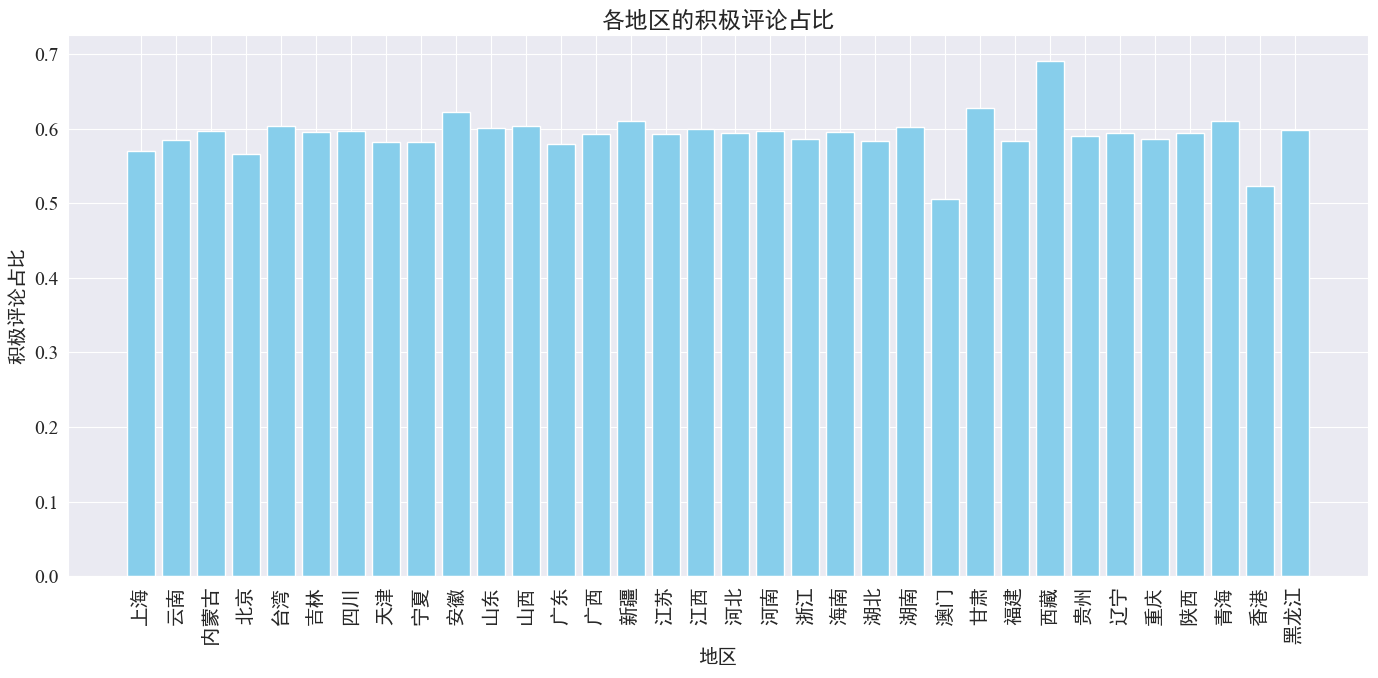
Как видно из приведенного выше рисунка, доля положительных комментариев в большинстве провинций составляет около 60%. В Гонконге и Макао самая низкая доля положительных комментариев, около 50%, тогда как в Тибете самая высокая доля положительных комментариев, близкая к 70%.
Из приведенного выше распределения комментариев мы видим, что комментарии в материковом Китае в основном положительные, тогда как количество отрицательных комментариев в Гонконге и Макао значительно возросло. Наибольшее количество положительных комментариев в Тибете может быть связано с ошибкой, вызванной ошибкой. небольшой размер выборки в Тибете.
Комментарии к новостям Рисунок облака слов
Диаграммы облака слов для всех комментариев, положительных комментариев и отрицательных комментариев учитывались отдельно. На рисунке диаграммы облака слов положительные комментарии были указаны как выше 0,6, а отрицательные комментарии были классифицированы как ниже 0,4. Ниже приводится облако из трех слов. нарисованы схемы.

Видно, что комментарии большинства людей во время эпидемии относительно простые, например «ха-ха», «хорошо» и т. д. В положительных комментариях можно увидеть ободряющие слова, такие как «Давай, Китай», «Давай, Ухань». и т. д., а в негативных комментариях встречаются критические высказывания типа «Ха-ха» и «Трудно сделать страну богатой».

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com