2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
COVID-19-epidemia vaikuttaa meidän jokaisen sydämeen Tässä tapauksessa yritämme analysoida epidemiaan liittyviä uutisia ja huhuja sosiaalisten tietojenkäsittelymenetelmien avulla.Epidemiatiedot Tutkimus. Tämä tehtävä on avoin tehtävä. Tarjoamme sosiaalista tietoa epidemian aikana ja kannustamme opiskelijoita analysoimaan sosiaalisia trendejä uutisten, huhujen ja lakiasiakirjojen perusteella. (Vinkki: Käytä tunnilla opittuja menetelmiä, kuten tunteiden analysointia, tiedon poimimista, luetun ymmärtämistä jne. tietojen analysointiin)
https://covid19.thunlp.org/ tarjoaa uuteen koronavirusepidemiaan liittyvää sosiaalista dataa, mukaan lukien epidemioihin liittyvät huhut CSDC-Rumor, epidemioihin liittyvät kiinalaiset uutiset CSDC-News ja epidemioihin liittyvät CSDC-Legal-oikeudelliset asiakirjat.
Tämä osa kerätystä tietojoukosta:
(1) 22.1.2020 alkaenWeibo väärää tietoaTiedot sisältävät virheellisenä tiedon katsottujen Weibo-viestien sisällön, julkaisijat, ilmiantajat, koeajan, tulokset ja muuta tietoa 1.3.2020 mennessä yhteensä 324 Weibo-alkuperäistä tekstiä, 31 284 eteenpäinlähetystä ja 7 912 kommenttia. , jota käytetään auttamaan tutkijoita analysoimaan ja tutkimaan väärän tiedon leviämistä epidemian aikana;
(2) Tencentin huhujen varmistusalusta ja Dingxiangyuanin väärät tiedot 18. tammikuuta 2020 lähtien, mukaan lukien tiedot, kuten oikeaksi tai vääräksi katsotun huhun sisältö, ajankohta ja perusteet arvioida, onko kyseessä huhu, alkaen 1. maaliskuuta 2020 huhutietoja on 507 kappaletta, joista 124 faktatietoa. Tietojen jakautuminen on: negatiivisia tapauksia: 420, positiivisia tapauksia: 33 ja epävarmoja: 54.
Tämä tietojoukon osa kerää uutisia 1.1.2020 alkaen, mukaan lukien uutisen otsikko, sisältö, avainsanat ja muut tiedot 16.3.2020 mennessä uutisia on kerätty yhteensä 148 960 kappaletta ja niitä vastaavia kommentteja oli 1 653 086. Käytetään auttamaan tutkijoita analysoimaan ja tutkimaan uutisdataa epidemian aikana.
Nämä tiedot ovat peräisin CAIL Kerätyistä anonymisoiduista oikeudellisista dokumenteista poimittiin yhteensä 1 203 historiallista epidemiaan liittyvää osaa. Jokainen tieto sisältää asiakirjan otsikon, tapausnumeron ja asiakirjan koko tekstin, joita tutkijat voivat käyttää tutkimuksen tekemiseen asiaan liittyvistä oikeudellisista kysymyksistä epidemian aikana.
Tehtävä on avoin tehtävä, aloitamme alkaen
Arvostelutehtävät muilta osin.
[1] Tietojen uskottavuus Twitterissä. julkaisussa Proceedings of WWW, 2011.
[2] Huhujen havaitseminen mikroblogeista, joissa on toistuvia hermoverkkoja. julkaisussa Proceedings of IJCAI, 2016.
[3] Konvoluutiomenetelmä väärän tiedon tunnistamiseen. julkaisussa Proceedings of IJCAI, 2017.
[4] Oikeiden ja väärien uutisten leviäminen verkossa. Tiede, 2018.
[5] Väärää tietoa verkossa ja sosiaalisessa mediassa: Kysely. arXiv preprint, 2018.
[6] Englanninkielisten sanojen affektiivisten normien luonnehdinta erillisten tunnekategorioiden mukaan. Behavior Research Methods, 2007.
Tämä kokeilu tarjoaa epidemiaan liittyvän huhutietojoukon CSDC-Rumor Analysoimalla tietojoukon sisältöä, valitsemme ensin kvantitatiivisen tilastollisen analyysin datajoukolle, sitten käytämme klusterointia toteuttamaan huhujen semanttista analyysiä ja lopuksi suunnittelemme huhujen havaitsemisjärjestelmä.
Tietojen muoto
Tämä kokeilu tarjoaa epidemiaan liittyvän huhutietojoukon CSDC-Rumor, joka kerää Weibo-virhetietoja ja huhujen kumoavia tietoja. Tietojoukko sisältää seuraavat tiedot.
rumor
│ fact.json
│
├─rumor_forward_comment
│ 2020-01-22_K1CaS7Qxd76ol.json
│ 2020-01-23_K1CaS7Q1c768i.json
...
│ 2020-03-03_K1CaS8wxh6agf.json
└─rumor_weibo
2020-01-22_K1CaS7Qth660h.json
2020-01-22_K1CaS7Qxd76ol.json
...
2020-03-03_K1CaS8wxh6agf.json
Weibo väärää tietoavastaavasti rumor_weibo jarumor_forward_comment kaksi samannimistäjson kuvattu tiedostossa.rumor_weibo keskelläjson Tarkat kentät ovat seuraavat:
rumorCode: Huhun ainutlaatuinen koodi, jonka kautta huhuraportointisivulle pääsee suoraan.title: Raportoidun huhun otsikkosisältö.informerName: Toimittajan Weibo-nimi.informerUrl: Toimittajan Weibo-linkki.rumormongerName: Huhun julkaisijan Weibo-nimi.rumormongerUr: Huhun lähettäneen henkilön Weibo-linkki.rumorText: Huhujen sisältö.visitTimes: Kuinka monta kertaa tässä huhussa on vierailtu.result: Tämän huhutarkistuksen tulokset.publishTime: Aika, jolloin huhu julkaistiin.related_url: Linkkejä tähän huhuun liittyviin todisteisiin, määräyksiin jne.rumor_forward_comment keskelläjson Tarkat kentät ovat seuraavat:
uid: Julkaise käyttäjätunnus.text: Kommentoi tai välitä jälkikirjoitus.date: julkaisuaika.comment_or_forward: binääri joko comment, jompikumpi forward, joka osoittaa, onko viesti kommentti vai edelleenlähetetty jälkikirjoitus.Tencent ja Lilac Garden vääriä tietojaSisällön muoto on:
date: aikaexplain: Huhutyyppitag:huhut tagabstract: Huhujen vahvistamiseen käytetty sisältörumor: HuhuTietojen esikäsittely
kulkea json.load() Pura huhu Weibo-tiedot erikseenweibo_data Kommenttien välitystiedot huhuillaforward_comment_data ja muuntaa sen sitten DataFrame-muotoon. Kaksi samannimistä tiedostoa, Weibo-artikkeli ja Weibo-kommenttien edelleenlähetys vastaavat toisiaan, kun käsittelet rumor_forward_comment-kansion tietoja, lisää rumorCode myöhempää vastaavuutta varten.
# 文件路径
weibo_dir = 'data/rumor/rumor_weibo'
forward_comment_dir = 'data/rumor/rumor_forward_comment'
# 初始化数据列表
weibo_data = []
forward_comment_data = []
# 处理rumor_weibo文件夹中的数据
for filename in os.listdir(weibo_dir):
if filename.endswith('.json'):
filepath = os.path.join(weibo_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
weibo_data.append(data)
# 处理rumor_forward_comment文件夹中的数据
for filename in os.listdir(forward_comment_dir):
if filename.endswith('.json'):
filepath = os.path.join(forward_comment_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
data = json.load(file)
# 提取rumorCode
rumor_code = filename.split('_')[1].split('.')[0]
for comment in data:
comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配
forward_comment_data.append(comment)
# 转换为DataFrame
weibo_df = pd.DataFrame(weibo_data)
forward_comment_df = pd.DataFrame(forward_comment_data)
Tässä osiossa käytetään kvantitatiivista tilastoanalyysiä saadakseen erityistä käsitystä epidemiahuhujen Weibo-tietojen jakautumisesta.
Tilastot siitä, kuinka monta kertaa huhuissa on vieraillut
tilastot weibo_df['visitTimes'] Pääsyaikojen jakauma ja piirrä vastaava histogrammi Tulokset ovat seuraavat.
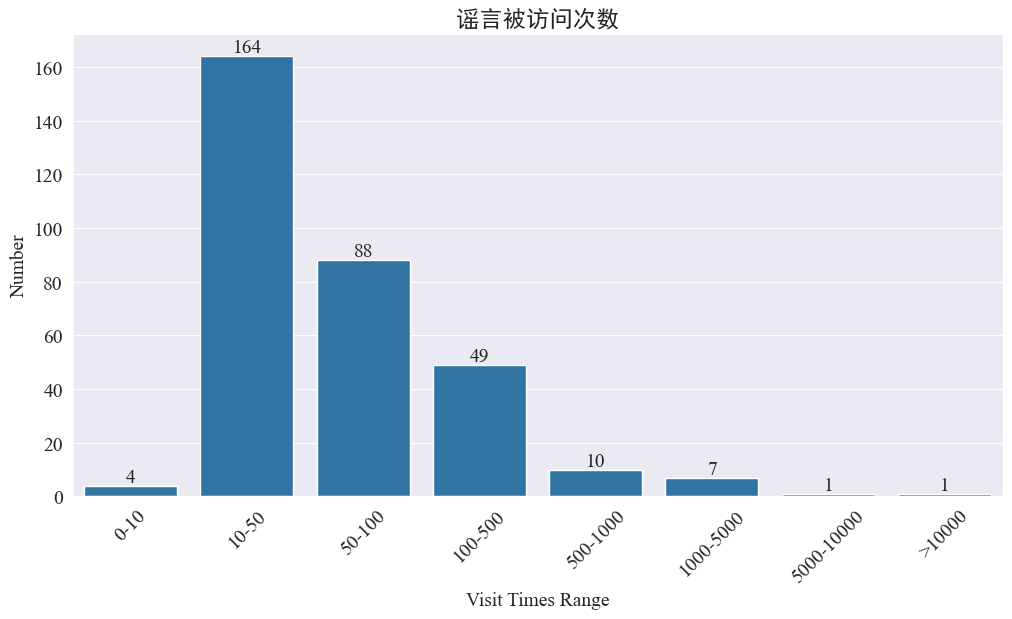
Weibon käyntien määrän mukaan useimmat epidemiahuhut on vieraillut Weibossa alle 500 kertaa, joista suurin osuus on 10-50. Weibossa liikkuu kuitenkin myös huhuja, joihin on käytetty yli 5 000 kertaa ja jotka ovat aiheuttaneet vakavia vaikutuksia ja joita pidetään lain mukaan "vakavina".
Tilastot huhujen tekijöiden ja ilmiantajien esiintymisestä
tilastojen mukaan weibo_df['rumormongerName'] jaweibo_df['informerName'] Kunkin huhujulkaisijan julkaisemien huhujen määrä ja kunkin toimittajan raportoimien huhujen määrä saadaan seuraavasti.
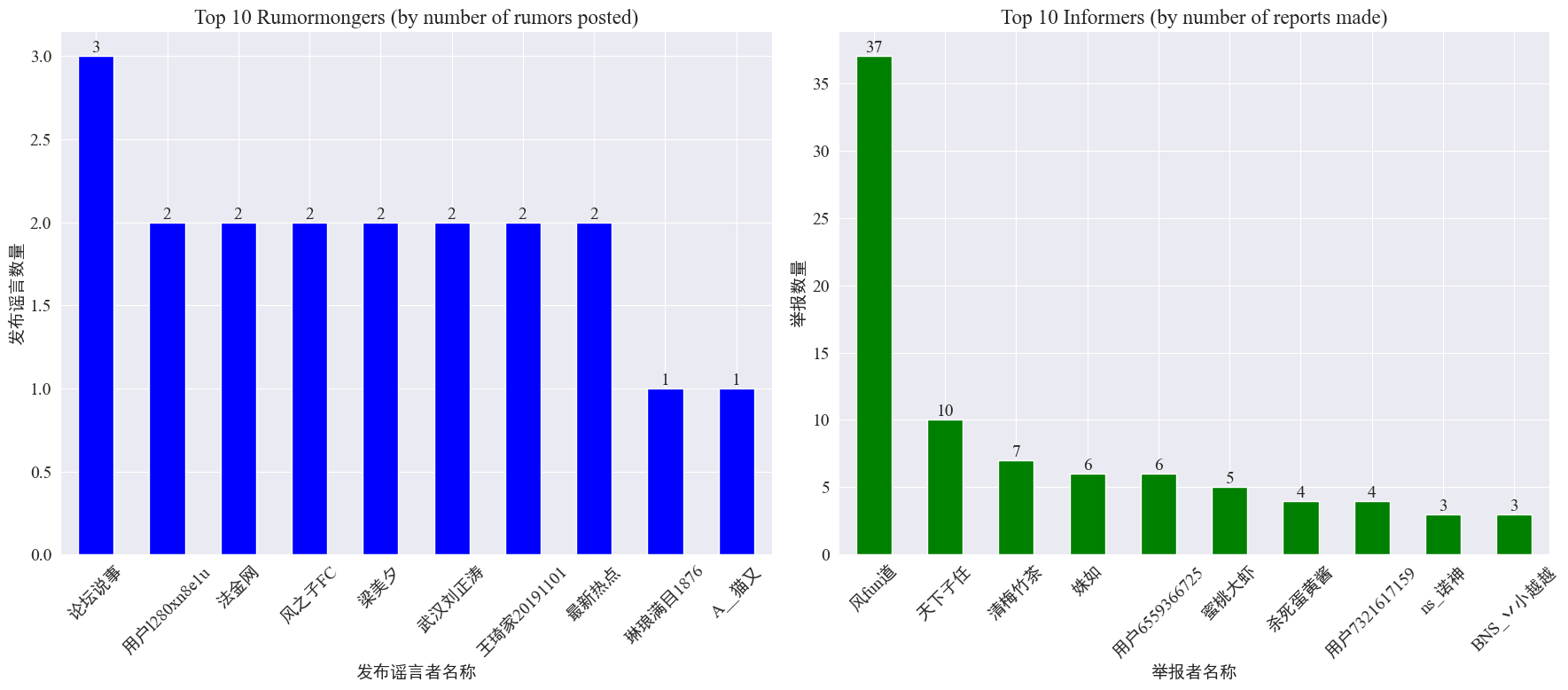
Voidaan nähdä, että huhujen tekijöiden julkaisemien huhujen määrä ei ole keskittynyt muutamaan henkilöön, vaan on suhteellisen tasainen. Eniten huhuja julkaissut tili julkaisi kolme huhu-Weibo-viestiä. Jokainen 10 suurimmasta ilmiantajasta raportoi vähintään kolmesta huhuartikkelista, Weibon ilmiantajien raportoimien huhujen määrä oli huomattavasti suurempi kuin muiden käyttäjien ja oli 37 artikkelia.
Yllä olevien tietojen perusteella yleisö voi keskittyä raportoimaan tilejä, joilla on suuri määrä huhuja, mikä helpottaa huhujen havaitsemista.
Huhujen välityskommenttien jakelutilastot
Laskemalla huhujen välitysmäärän ja kommenttien määrän jakautuminen saadaan seuraava jakelukuva.

Voidaan nähdä, että useimpien Weibo-huhujen kommenttien ja uudelleenpostausten määrä on 10-kertainen, kun kommenttien enimmäismäärä on enintään 500 ja uusintapostausten enimmäismäärä on yli 10 000. Internet-hallintalain mukaan jos huhu välitetään yli 500 kertaa, sitä pidetään "vakavana" tilanteena.
Huhutekstiklusterianalyysi
Tämä osa suorittaa tietojen esikäsittelyn Weibo-huhuteksteille ja suorittaa klusterianalyysin sanan segmentoinnin jälkeen nähdäkseen, mihin Weibo-huhut ovat keskittyneet.
Tietojen esikäsittely
Puhdista ensin huhutietoteksti, poista oletusarvot ja <> Oheisen linkin sisältö.
# 去除缺失值
weibo_df_rumorText = weibo_df.dropna(subset=['rumorText'])
def clean_text(text):
# 定义正则表达式模式,匹配 <>
pattern = re.compile(r'<.*?>')
# 使用 sub 方法删除匹配的部分
cleaned_text = re.sub(pattern, '', text)
return cleaned_text
weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)
Lataa sitten kiinalaiset lopetussanat ja lopetussanat käyttävät cn_stopwords ,käyttääjieba Toteuta datan sanasegmentointikäsittely ja suorita tekstin vektorointi.
# 加载停用词文件
with open('cn_stopwords.txt', encoding='utf-8') as f:
stopwords = set(f.read().strip().split('n'))
# 分词和去停用词函数
def preprocess_text(text):
words = jieba.lcut(text)
words = [word for word in words if word not in stopwords and len(word) > 1]
return ' '.join(words)
# 应用到数据集
weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text)
# 文本向量化
vectorizer = TfidfVectorizer(max_features=10000)
X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])
Selvitä paras klusterointi
Kyynärpäämenetelmää käyttämällä määritetään parhaat klusterit.
Kyynärpäämenetelmä on menetelmä, jolla määritetään optimaalinen klusterien lukumäärä klusterianalyysissä. Se perustuu Sum of Squared Errors (SSE) ja klusterien lukumäärän väliseen suhteeseen. SSE on neliöityjen euklidisten etäisyyksien summa klusterin kaikista datapisteistä klusterin keskustaan, johon se kuuluu. Se heijastaa klusteroinnin vaikutusta: mitä pienempi SSE, sitä parempi klusterointivaikutus.
# 使用肘部法确定最佳聚类数量
def plot_elbow_method(X):
sse = []
for k in range(1, 21):
kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto')
kmeans.fit(X)
sse.append(kmeans.inertia_)
plt.plot(range(1, 21), sse, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title('Elbow Method For Optimal k')
plt.show()
# 绘制肘部法图
plot_elbow_method(X_tfidf)
Kyynärpäämenetelmä määrittää optimaalisen klustereiden lukumäärän etsimällä "kyynärpäätä", eli etsimällä käyrältä pistettä, jonka jälkeen SSE:n laskunopeus hidastuu merkittävästi. Tämä piste on kuin käsivarren kyynärpää nimi "kyynärpäämenetelmä". Tätä kohtaa pidetään yleensä optimaalisena klusterimääränä.
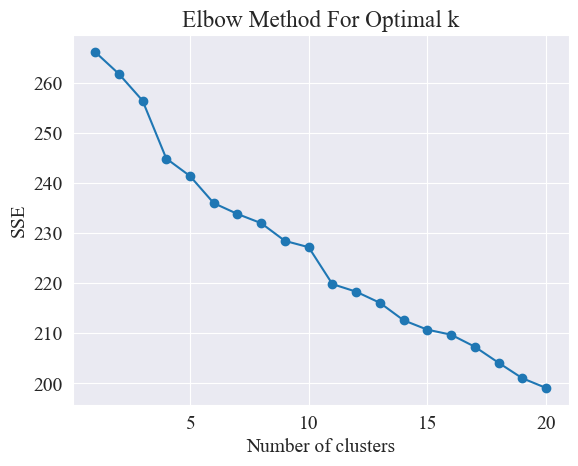
Yllä olevasta kuvasta määritetään, että kyynärpään klusterointiarvo on 11, ja vastaava sirontakäyrä piirretään seuraavasti.
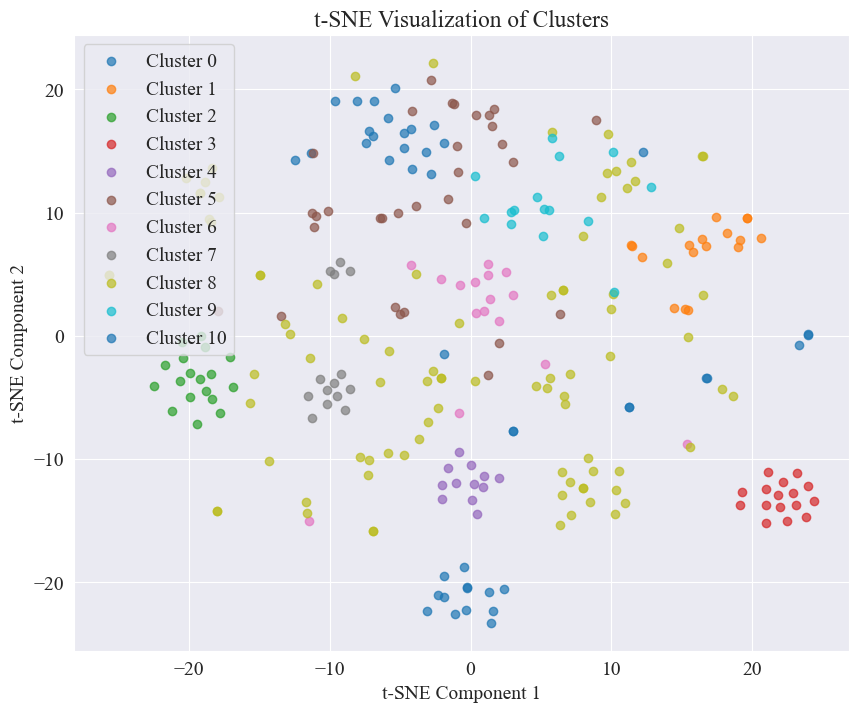
Voidaan nähdä, että useimmat huhujen Weibo-viestit ovat hyvin ryhmiteltyjä, jotkin numerot 3 ja 4 ovat hajallaan ja huonosti ryhmitelty, kuten nro 5 ja nro 8.
Klusterin tulokset
Jotta voidaan selkeästi näyttää, mitkä huhut ovat ryhmitelty kuhunkin kategoriaan, jokaiselle luokalle piirretään pilvikaavio. Tulokset ovat seuraavat.

Tulosta hyvin klusteroitua huhu-Weibo-sisältöä, ja tulokset ovat seuraavat.
Cluster 2:
13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此...
17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩...
18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确...
19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交...
21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封...
Name: rumorText, dtype: object
Cluster 3:
212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日...
213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级...
224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高...
225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月...
226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二...
Name: rumorText, dtype: object
Huhutarkastelutulosten klusterianalyysi
Huhutekstin sisällön klusterointi ei välttämättä ole kovin hyvä huhusisällön analysointiin, joten päätimme klusteroida huhutarkistuksen tulokset.
Selvitä paras klusterointi
Määritä paras klusterointi kyynärpääkuvaajan avulla.
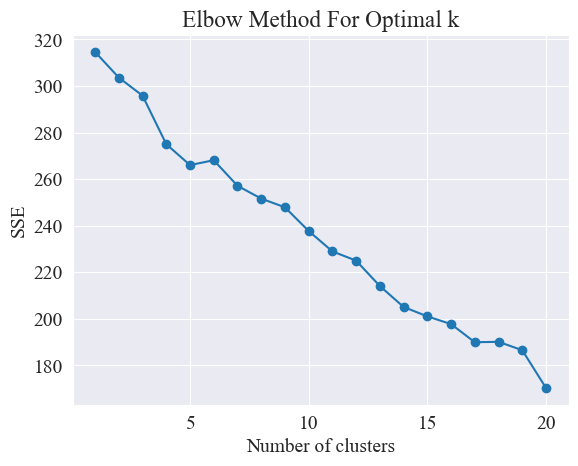
Yllä olevasta kyynärpääkaaviosta voidaan määrittää kaksi kulmaa, joista toinen on kun klusterointi on 5 ja toinen kun klusterointi on 20. Valitsen klusterointiin 20.
20 luokkaa klusteroimalla saatu sirontakäyrä on seuraava.
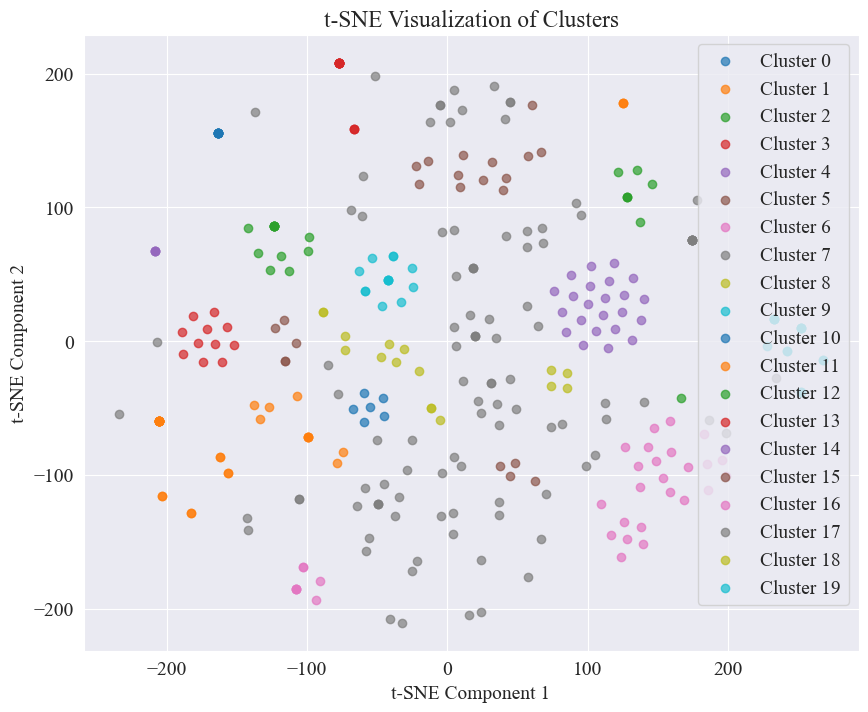
Voidaan nähdä, että suurin osa niistä on klusteroitunut hyvin, mutta 7. ja 17. kategoriat eivät ole ryhmitelty hyvin.
Klusterin tulokset
Jotta voidaan selvästi näyttää, mitkä huhutarkastelutulokset on ryhmitelty kuhunkin kategoriaan, jokaiselle luokalle piirretään pilvikaavio. Tulokset ovat seuraavat.

Tulosta joitakin hyvin ryhmiteltyjä huhutarkastelutuloksia. Tulokset ovat seuraavat.
Cluster 4:
52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车
Name: result, dtype: object
Cluster 10:
214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织
Name: result, dtype: object
Cluster 15:
7 在福州,里面坐的是周杰伦
8 周杰伦去福州自备隔离仓
9 周杰伦去福州自备隔离仓
10 周杰伦福州演唱会,给自己整了个隔离舱
12 周杰伦福州演唱会,给自己整了个隔离舱
Name: result, dtype: object
Tässä huhun havaitsemisessa päätimme käyttää tietojoukkoja, jotka on kumottu. fact.json Vertaa kumottujen ja todellisten huhujen välistä samankaltaisuutta ja valitse huhujen havaitsemisen perustaksi kumottu artikkeli, jolla on suurin samankaltaisuus huhu Weibon kanssa.
Lataa Weibo-huhutiedot ja huhujen kumoamistietojoukot
# 定义一个空的列表来存储每个 JSON 对象
fact_data = []
# 逐行读取 JSON 文件
with open('data/rumor/fact.json', 'r', encoding='utf-8') as f:
for line in f:
fact_data.append(json.loads(line.strip()))
# 创建辟谣数据的 DataFrame
fact_df = pd.DataFrame(fact_data)
fact_df = fact_df.dropna(subset=['title'])
Käytä valmiiksi koulutettuja kielimalleja Weibo-huhujen ja huhujen kumoavien nimikkeiden koodaamiseen upotusvektoreihin
Käytetty tässä kokeessa bert-base-chinese Esikoulutettuna mallina suorita mallikoulutus. SimCSE-mallia käytetään parantamaan lausesemantiikan esitystä ja samankaltaisuuden mittaamista kontrastiivisen oppimisen avulla.
# 加载SimCSE模型
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# 加载到 GPU
model.to('cuda')
# 加载预训练的NER模型
ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)
Laske samankaltaisuus
Samankaltaisuuden laskemiseen käytetään SimCSE-mallin lauseen upottamista ja nimetyn entiteetin samankaltaisuutta laskemaan kattava samankaltaisuus.
extract_entitiesFunktio poimii nimetyt entiteetit tekstistä käyttämällä NER-mallia.
# 提取命名实体
def extract_entities(text):
entities = ner_pipeline(text)
return {entity['word'] for entity in entities}
entity_similarityFunktio laskee nimetyn entiteetin samankaltaisuuden kahden tekstin välillä.
# 计算命名实体相似度
def entity_similarity(text1, text2):
entities1 = extract_entities(text1)
entities2 = extract_entities(text2)
if not entities1 or not entities2:
return 0.0
intersection = entities1.intersection(entities2)
union = entities1.union(entities2)
return len(intersection) / len(union)
combined_similarityFunktio yhdistää SimCSE-mallin lauseen upotuksen ja nimetyn kokonaisuuden samankaltaisuuden kokonaisvaltaisen samankaltaisuuden laskemiseksi.
# 结合句子嵌入相似度和实体相似度
def combined_similarity(text1, text2):
embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item()
entity_sim = entity_similarity(text1, text2)
return 0.5 * embed_sim + 0.5 * entity_sim
Ota käyttöön huhujen havaitseminen
Vertailemalla yhtäläisyyksiä toteutetaan huhujen havaitsemismekanismi.
def debunk_rumor(input_rumor):
# 计算输入谣言与所有辟谣标题的相似度
similarity_scores = []
for fact_text in fact_df['title']:
similarity_scores.append(combined_similarity(input_rumor, fact_text))
# 找到最相似的辟谣标题
most_similar_index = np.argmax(similarity_scores)
most_similar_fact = fact_df.iloc[most_similar_index]
# 输出辟谣判断及依据
print("微博谣言:", input_rumor)
print(f"辟谣判断:{most_similar_fact['explain']}")
print(f"辟谣依据:{most_similar_fact['title']}")
weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。"
debunk_rumor(weibo_rumor)
Tulos on seuraava:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。
辟谣判断:尚无定论
辟谣依据:狗能感染新型冠状病毒
Löysi onnistuneesti perustan huhujen kumoamiseksi ja antoi tuomion huhujen kumoamiseksi.
Tietojen muoto
Tämä kokeilu tarjoaa epidemioihin liittyvän uutisaineiston CSDC-News, joka kerää uutisia ja kommentteja vuoden 2020 ensimmäisellä puoliskolla. Tietojoukko sisältää seuraavat tiedot.
news
│
├─comment
│ 01-01.txt
│ 01-02.txt
...
│ 03-08.txt
└─data
01-01.txt
01-02.txt
...
08-31.txt
Tietokansio on jaettu kolmeen osaan:data,comment。
data Kansio sisältää useita tiedostoja, joista jokainen vastaa tietyn päivämäärän tietoja, muodossajson . Tämän osan sisältö vastaa uutisen tekstidataa (päivitetään asteittain päivämäärän mukaan), ja kentät sisältävät:
time: Uutisen julkaisuaika.title:Uutisen otsikko.url: Uutisten alkuperäinen osoitelinkki.meta: Uutisten tekstitiedot, jotka sisältävät seuraavat kentät: content: Uutisten tekstisisältö.description: Lyhyt kuvaus uutisesta.title:Uutisen otsikko.keyword: Uutiset avainsanat.type: Uutisen tyyppi.comment Kansio sisältää useita tiedostoja, joista jokainen vastaa tietyn päivämäärän tietoja, muodossajson . Tämä osa sisällöstä vastaa uutisen kommenttitietoja (kommenttitietojen ja uutistekstitietojen välillä voi olla noin viikon viive).
time: uutisjulkaisuaika ja data Vastaa kansion tietoja.title: Uutisen otsikko, jossa data Vastaa kansion tietoja.url: Uutisten alkuperäinen osoitelinkki ja data Vastaa kansion tietoja.comment: Uutiskommenttitiedot Tämä kenttä on taulukon jokainen elementti. area: Arvostelija-alue.content:kommentit.nickname: Arvostelijan lempinimi.reply_to: Kommentoijan vastausobjekti Jos sitä ei ole, se ei ole vastaus.time: Kommentointiaika.Tietojen esikäsittely
Tiedot uutisartikkeleista data Tietojen esikäsittelyn aikana on välttämätöntämeta Sisältö julkaistaan ja tallennetaan DataFrame-muodossa.
# 加载新闻数据
def load_news_data(data_dir):
news_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_news = json.load(f)
for news in daily_news:
news_entry = {
'time': news.get('time', 'NULL'),
'title': news.get('title', 'NULL'),
'url': news.get('url', 'NULL'),
'content': news.get('meta', {}).get('content', 'NULL'),
'description': news.get('meta', {}).get('description', 'NULL'),
'keyword': news.get('meta', {}).get('keyword', 'NULL'),
'meta_title': news.get('meta', {}).get('title', 'NULL'),
'type': news.get('meta', {}).get('type', 'NULL')
}
news_data.append(news_entry)
return pd.DataFrame(news_data)
Arvostelutiedoissa comment Tietojen esikäsittelyn aikana on välttämätöntäcomment Sisältö julkaistaan ja tallennetaan DataFrame-muodossa.
# 加载评论数据
def load_comment_data(data_dir):
comment_data = []
files = sorted(os.listdir(data_dir))
for file in files:
if file.endswith('.txt'):
with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f:
daily_comments = json.load(f)
for comment in daily_comments:
for com in comment.get('comment', []):
comment_entry = {
'news_time': comment.get('time', 'NULL'),
'news_title': comment.get('title', 'NULL'),
'news_url': comment.get('url', 'NULL'),
'comment_area': com.get('area', 'NULL'),
'comment_content': com.get('content', 'NULL'),
'comment_nickname': com.get('nickname', 'NULL'),
'comment_reply_to': com.get('reply_to', 'NULL'),
'comment_time': com.get('time', 'NULL')
}
comment_data.append(comment_entry)
return pd.DataFrame(comment_data)
Lataa tietojoukko
Lataa tietojoukko yllä olevan tietojen esikäsittelytoiminnon mukaisesti.
# 数据文件夹路径
news_data_dir = 'data/news/data/'
comment_data_dir = 'data/news/comment/'
# 加载数据
news_df = load_news_data(news_data_dir)
comment_df = load_comment_data(comment_data_dir)
# 展示加载的数据
print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")
Tulostustulos osoittaa, että uutistietojen pituus: 502550 ja kommenttitietojen pituus: 1534616.
Uutisten aikajakaumatilastot
Laske erikseen news_df Kuukausittaisten uutisartikkelien määrä ja uutisartikkelien määrä tunnissa esitetään pylväskaavioilla ja viivakaavioilla.
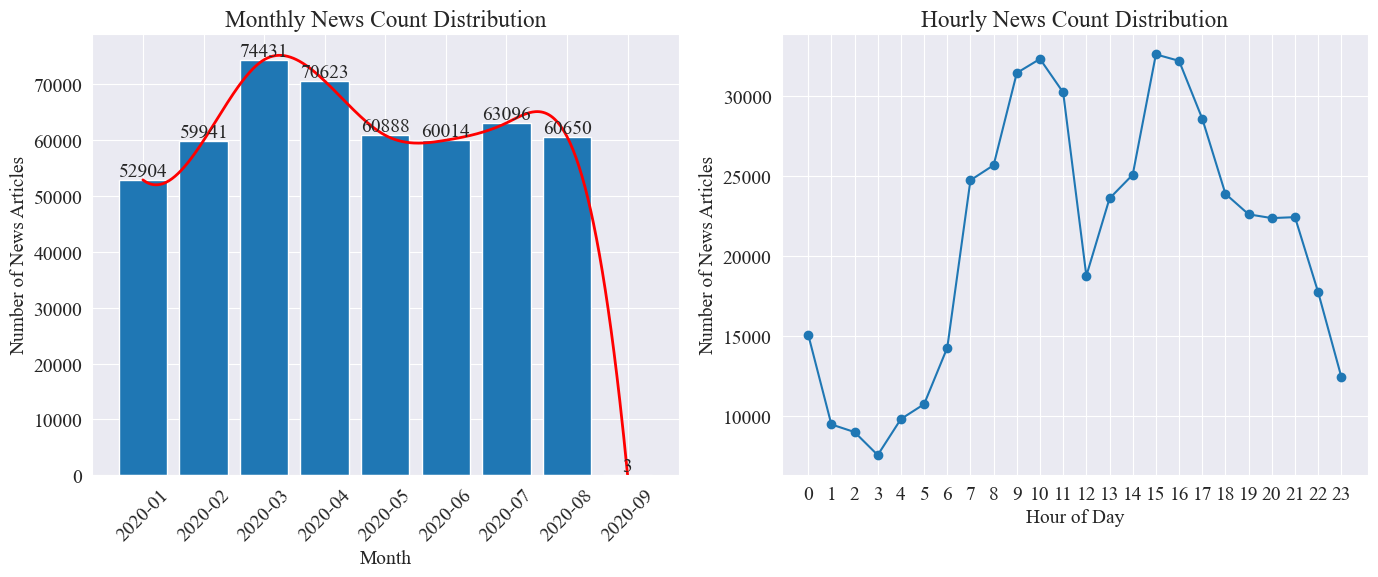
Kuten yllä olevasta kuvasta voidaan nähdä, epidemian puhkeamisen myötä uutisten määrä kasvoi kuukausittain ja saavutti huippunsa maaliskuussa 74 000 uutisartikkelilla, minkä jälkeen se laski vähitellen ja vakiintui 60 000 artikkeliin kuukaudessa, joista tiedot syyskuussa oli 3 klo 0:00 artikkeleita, ei välttämättä sisälly tilastoihin.
Tuntikohtaisen uutismäärän jakauman perusteella voidaan nähdä, että joka päivä kello 10 ja 15 ovat lehdistötiedotteiden huipputunteja, joista jokaisessa julkaistaan yli 30 000 artikkelia. Kello 12 on lounastauko, ja tiedotteiden määrä on huipussaan ja aallonpohjassa. Lehdistötiedotteiden määrä on pienin päivittäin kello 0:00 ja 5:00 välillä, ja 3:00 on pienin piste.
Uutisten hot spottien seuranta
Tämän kokeen tarkoituksena on käyttää uutisavainsanojen poimimismenetelmää seuratakseen uutiskohteita näiden kahdeksan kuukauden aikana. Laskemalla olemassa olevien avainsanojen jakauman ja piirtämällä histogrammin tulokset ovat seuraavat.
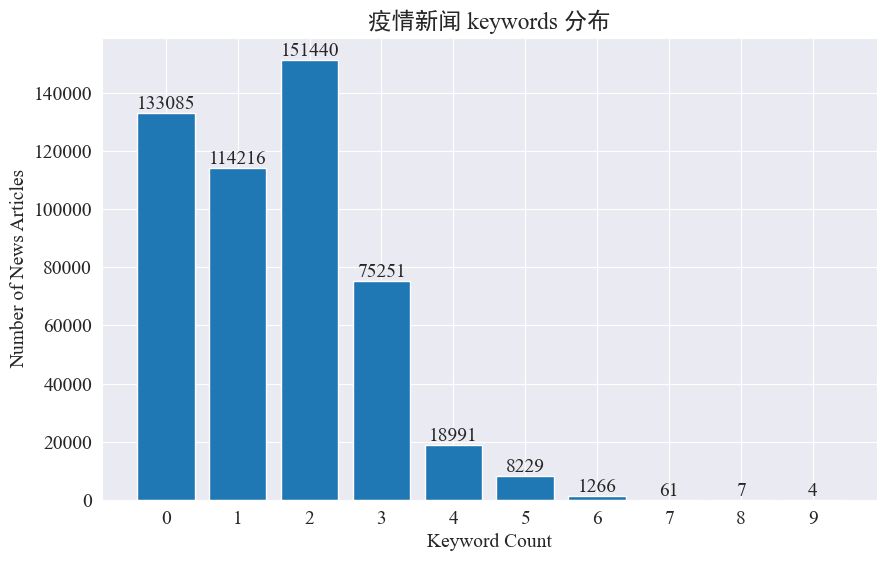
Voidaan nähdä, että useimmissa uutisartikkeleissa on alle 3 avainsanaa, ja suuressa osassa artikkeleista ei ole edes avainsanoja. Siksi sinun on itse kerättävä tilastoja ja yhteenveto avainsanoista hotspot-seurantaa varten.Tällä kertaa käytössäjieba.analyse.textrank() laskea avainsanoja.
import jieba
import jieba.analyse
def extract_keywords(text):
# 基于jieba的textrank算法实现
keywords = jieba.analyse.textrank(text,topK=5,withWeight=True)
return ' '.join([keyword[0] for keyword in keywords])
news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x))
keyword_data = news_df[['time','keyword','keyword_new']]
keyword_data
Laske viisi uutta avainsanaa, tallenna ne avainsanaan keyword_new, yhdistä avainsanat niihin ja poista päällekkäiset sanat.
# 合并并去除重复的词
def merge_keywords(row):
# 将keyword列和keyword_new列合并
keywords = set(row['keyword']) | set(row['keyword_new'].split())
return ' '.join(keywords)
keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1)
keyword_data
Tulosta yhdistämisen jälkeen keyword_data , tulostetut tulokset ovat seuraavat.
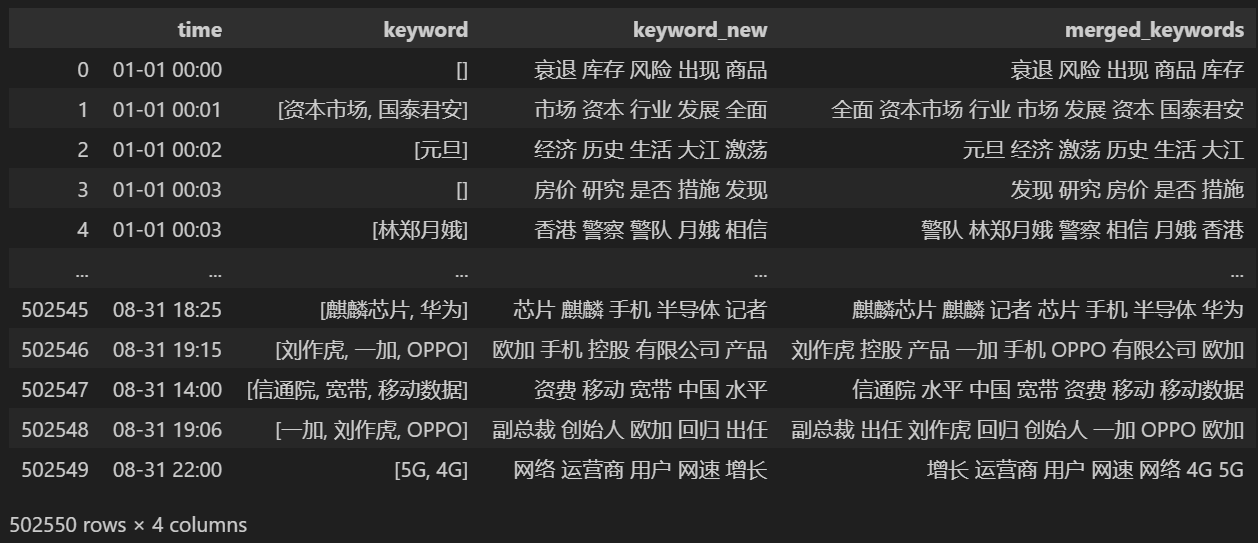
Jotta voit seurata hot spotteja, laske kaikkien esiintyvien sanojen sanatiheys ja laske keyword_data['rolling_keyword_freq']。
# 按时间排序
keyword_data = keyword_data.sort_values(by='time')
# 计算滚动频率
def get_rolling_keyword_freq(df, window=7):
rolling_keyword_freq = []
for i in range(len(df)):
start_time = df.iloc[i]['time'] - timedelta(days=window)
end_time = df.iloc[i]['time']
mask = (df['time'] > start_time) & (df['time'] <= end_time)
recent_data = df.loc[mask]
keywords = ' '.join(recent_data['merged_keywords']).split()
keyword_counter = Counter(keywords)
top_keywords = keyword_counter.most_common(20)
rolling_keyword_freq.append(dict(top_keywords))
return rolling_keyword_freq
keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data)
keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0)
keyword_df = keyword_df.astype(int)
# 将原始的时间列合并到新的DataFrame中
result_df = pd.concat([keyword_data['time'], keyword_df], axis=1)
# 保存为CSV文件
result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)
Piirrä sitten yllä olevien tilastotietojen perusteella päivittäinen muutoskaavio kuumista sanoista.
# 读取数据
file_path = './data/news/output/keyword_frequency.csv'
data = pd.read_csv(file_path, parse_dates=['time'])
# 聚合数据,按日期合并统计
data['date'] = data['time'].dt.date
daily_data = data.groupby('date').sum().reset_index()
# 准备颜色列表,确保每个关键词都有不同的颜色
colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors
color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])}
def update(frame):
plt.clf()
date = daily_data['date'].iloc[frame]
day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T
day_data.columns = ['count']
day_data = day_data.sort_values(by='count', ascending=False).head(10)
bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index])
plt.xlabel('Count')
plt.title(f'Keyword Frequency on {date}')
for bar in bars:
plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center')
plt.gca().invert_yaxis()
# 创建动画
fig = plt.figure(figsize=(10, 6))
anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False)
# 保存动画
anim.save('keyword_trend.gif', writer='imagemagick')
Lopuksi saatiin gif-kaavio epidemiauutisten avainsanojen muutoksista. Tulokset ovat seuraavat.
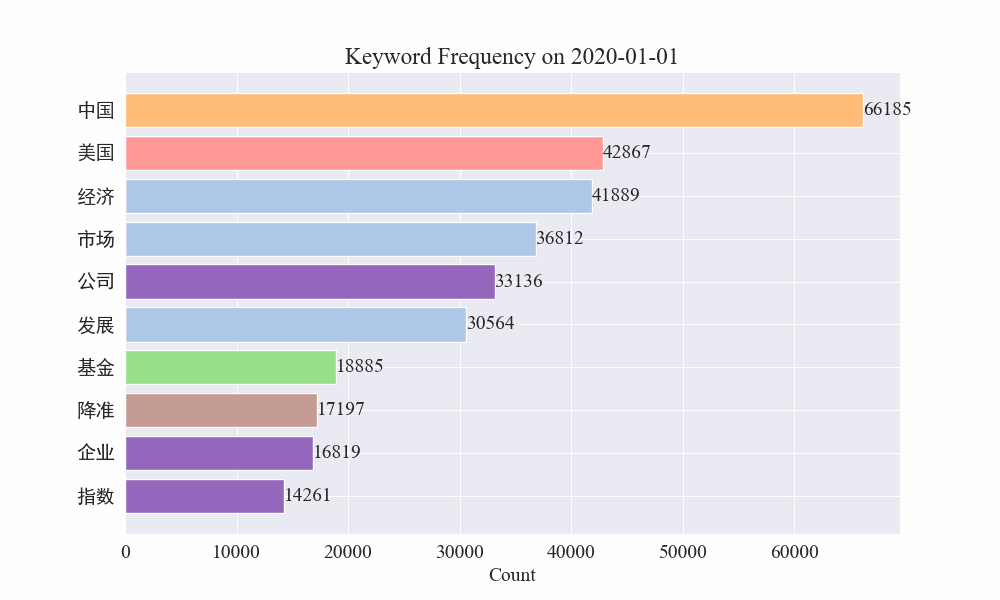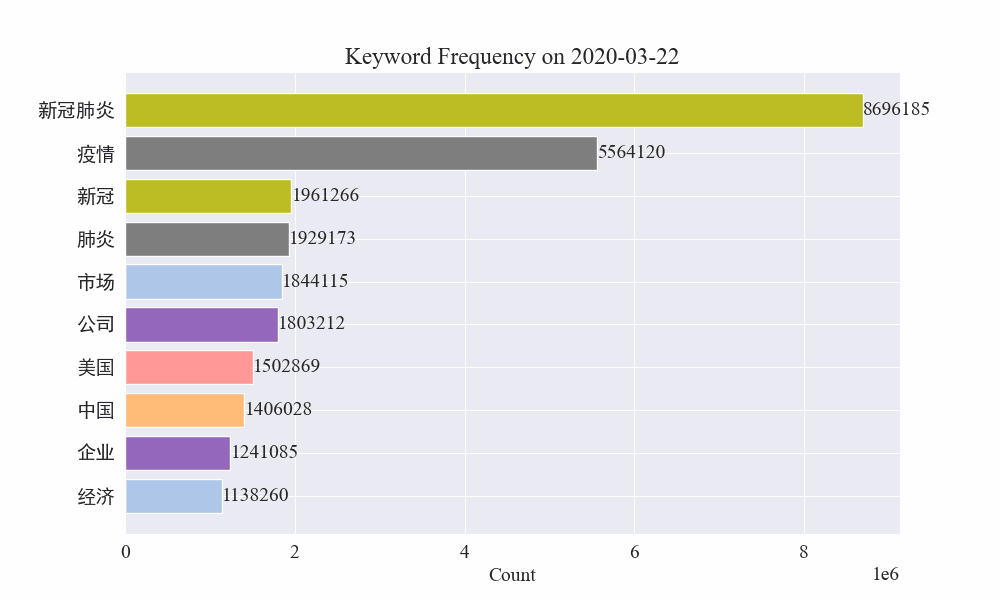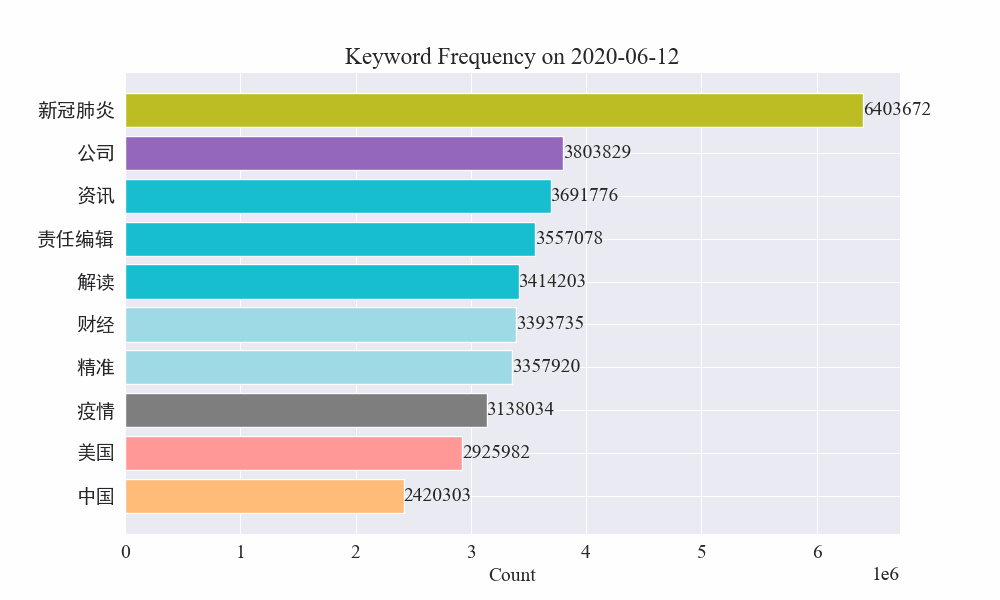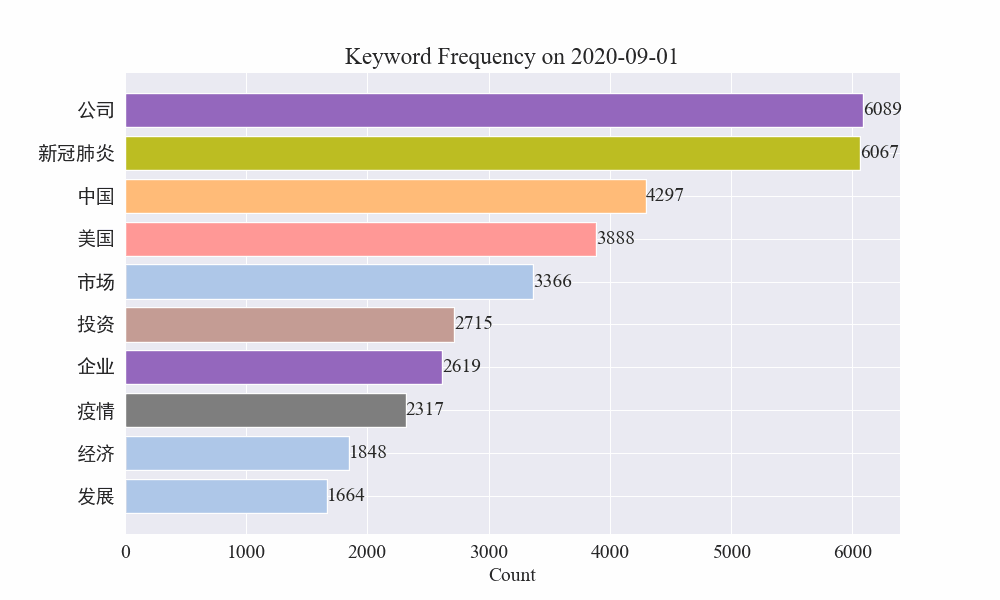
Ennen epidemian puhkeamista termit "yritys" ja "Iran" pysyivät korkeina. On nähtävissä, että epidemian puhkeamisen jälkeen epidemia-uutisten määrä alkoi nousta räjähdysmäisesti helmikuussa. epidemian ensimmäinen aalto hidastui ja nousi toiseksi.
Tämä osio suorittaa ensin kvantitatiivisen tilastollisen analyysin uutiskommenteista ja sen jälkeen mielipideanalyysin erilaisista kommenteista.
Päivittäisten uutisten kommenttien määrätilastot
Laske uutiskommenttien määrän trendi, kuvaa se pylväskaaviolla ja piirrä likimääräinen käyrä Koodi on seuraava.
# 提取日期和小时信息
dates = []
hours = []
for time_str in comment_df['news_time']:
try:
time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M')
dates.append(time_obj.strftime('%Y-%m-%d'))
hours.append(time_obj.hour)
except ValueError:
pass
# 统计每日新闻数量
daily_comment_counts = Counter(dates)
daily_comment_counts = dict(sorted(daily_comment_counts.items()))
# 统计每小时新闻数量
hourly_news_count = Counter(hours)
hourly_news_count = dict(sorted(hourly_news_count.items()))
# 绘制每月新闻数量分布柱状图
plt.figure(figsize=(14, 6))
days = list(daily_comment_counts.keys())
comment_counts = list(daily_comment_counts.values())
bars = plt.bar(days, comment_counts, label='Daily Comment Count')
plt.xlabel('Date')
plt.ylabel('Comment Count')
plt.title('Daily Comment Counts on News')
plt.xticks(rotation=80, fontsize=10)
# 绘制近似曲线
x = np.arange(len(days))
y = comment_counts
spl = UnivariateSpline(x, y, s=100)
xs = np.linspace(0, len(days) - 1, 500)
ys = spl(xs)
plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve')
plt.show()
Päivittäisten uutiskommenttien tilastollinen kaavio piirretään seuraavasti.
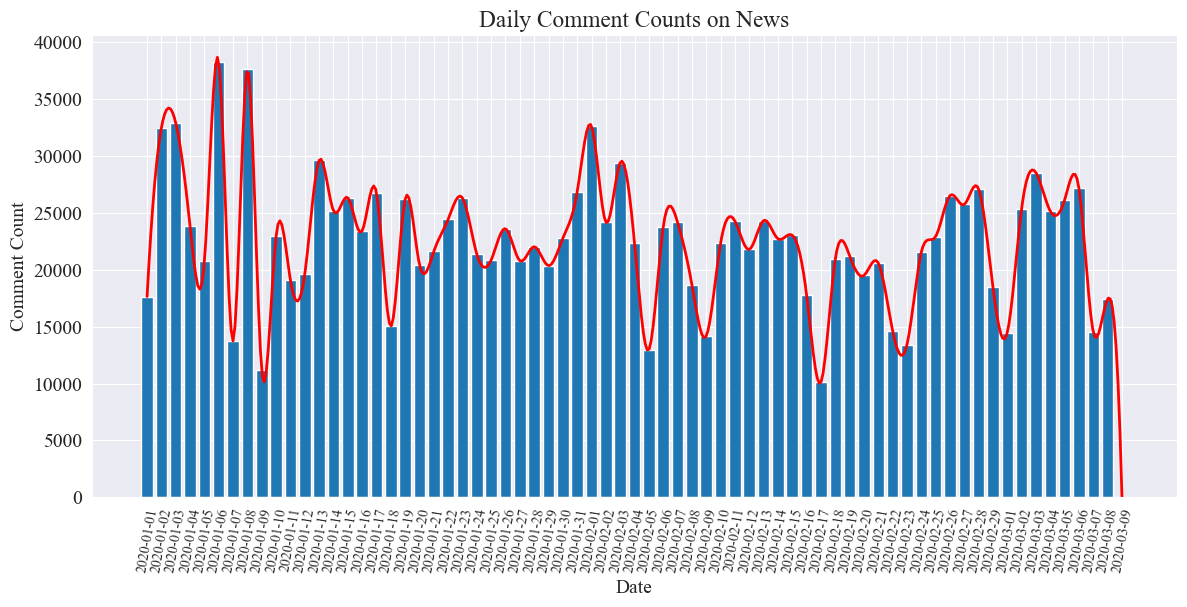
Voidaan nähdä, että uutiskommenttien määrä epidemian aikana vaihteli 10 000 ja 40 000 välillä, keskimäärin noin 20 000 kommenttia päivässä.
Epidemiauutiset tilastot alueittain
maakunnan mukaan comment_df['province'] Laske kunkin maakunnan uutisten määrä ja epidemiauutisten kommenttien määrä kussakin maakunnassa.
Ensin sinun on läpäistävä comment_df['province'] Poimi maakunnan tiedot.
# 统计包含全国34个省、直辖市、自治区名称的地域数据
province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆',
'江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东',
'青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门']
# 提取省份信息
def extract_province(comment_area):
for province in province_name:
if province in comment_area:
return province
return None
comment_df['province'] = comment_df['comment_area'].apply(extract_province)
# 过滤出省份不为空的行
comment_df_filtered = comment_df[comment_df['province'].notnull()]
# 统计每个省份的评论数量
province_counts = comment_df_filtered['province'].value_counts().to_dict()
Sitten tilastotietojen perusteella piirretään ympyräkaavio, joka näyttää uutiskommenttien osuuden kussakin maakunnassa.
# 计算总评论数量
total_comments = sum(province_counts.values())
# 计算各省份评论数量占比
provinces = []
comments = []
labels = []
for province, count in province_counts.items():
if count / total_comments >= 0.02:
provinces.append(province)
comments.append(count)
labels.append(province + f" ({count})")
# 绘制饼图
plt.figure(figsize=(10, 8))
plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title('各省疫情新闻评论数量占比')
plt.axis('equal') # 保证饼图是圆形
plt.show()

Tässä kokeessa käytimme myös pyecharts.charts /Map Komponentti, joka kuvaa kommenttien määrän jakautumista Kiinan kartalle provinssien mukaan.
from pyecharts.charts import Map
from pyecharts import options as opts
# 省份简称到全称的映射字典
province_full_name = {
'北京': '北京市',
'天津': '天津市',
'上海': '上海市',
'重庆': '重庆市',
'河北': '河北省',
'河南': '河南省',
'云南': '云南省',
'辽宁': '辽宁省',
'黑龙江': '黑龙江省',
'湖南': '湖南省',
'安徽': '安徽省',
'山东': '山东省',
'新疆': '新疆维吾尔自治区',
'江苏': '江苏省',
'浙江': '浙江省',
'江西': '江西省',
'湖北': '湖北省',
'广西': '广西壮族自治区',
'甘肃': '甘肃省',
'山西': '山西省',
'内蒙古': '内蒙古自治区',
'陕西': '陕西省',
'吉林': '吉林省',
'福建': '福建省',
'贵州': '贵州省',
'广东': '广东省',
'青海': '青海省',
'西藏': '西藏自治区',
'四川': '四川省',
'宁夏': '宁夏回族自治区',
'海南': '海南省',
'台湾': '台湾省',
'香港': '香港特别行政区',
'澳门': '澳门特别行政区'
}
# 将省份名称替换为全称
full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()}
# 创建中国地图
map_chart = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"),
visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values()))
)
)
# 渲染图表为 HTML 文件
map_chart.render("comment_area_distribution.html")
Saatussa HTML:ssä epidemiauutisten kommenttien määrä jakautuu Kiinan jokaisessa maakunnassa seuraavasti.
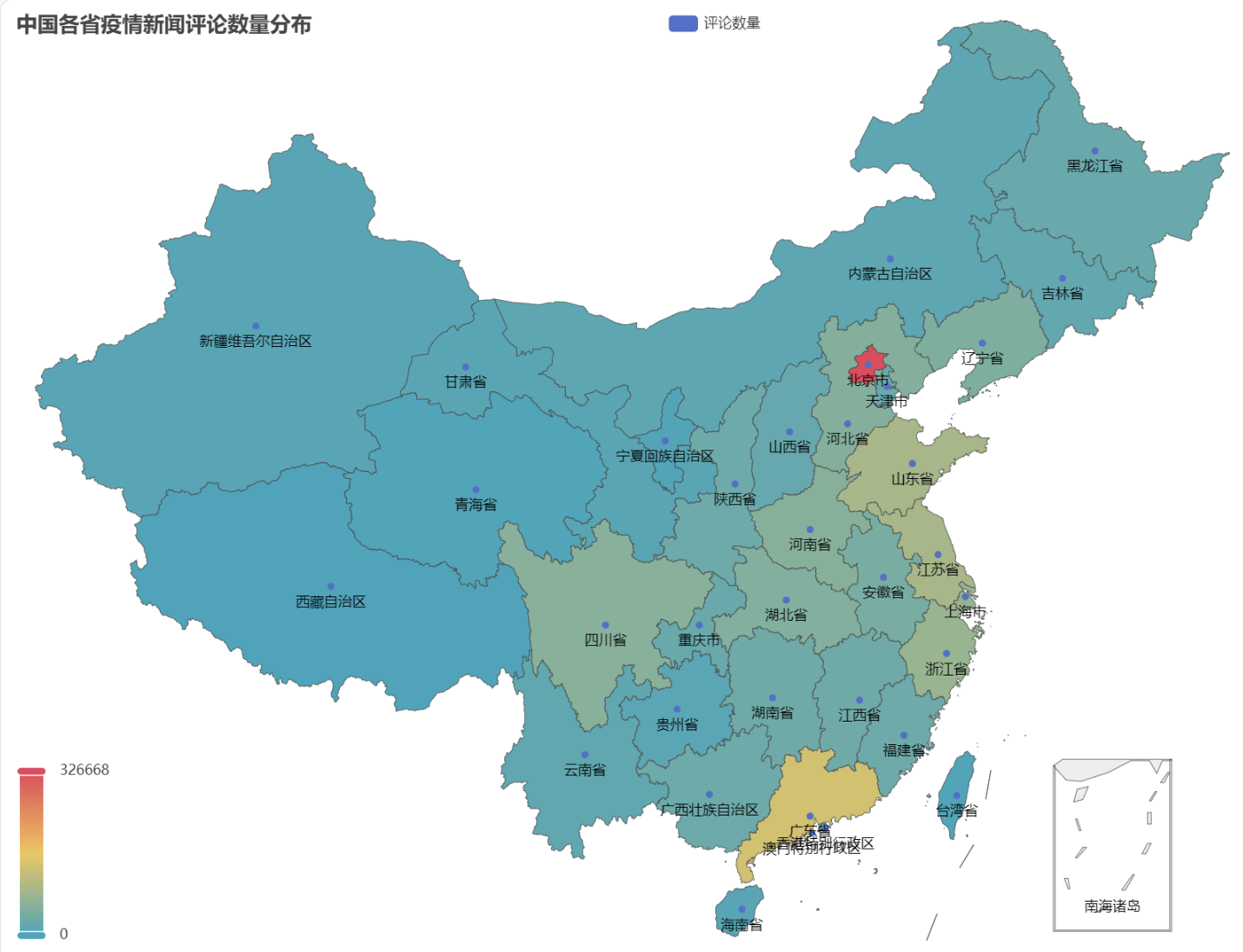
Voidaan nähdä, että epidemian aikana kommenttien määrä oli suurin Pekingissä, seuraavaksi Guangdongin maakunnassa, ja muissa maakunnissa kommenttien määrä oli suhteellisen tasainen.
epideeminenTarkista tunneanalyysi
Tämä kokeilu käyttää NLP-kirjastoa kiinankielisen tekstin käsittelyyn SnowNLP , ota käyttöön kiinalainen mielipideanalyysi, analysoi jokainen kommentti ja anna vastaavasentiment Arvo, arvo on välillä 0 ja 1, mitä lähempänä 1:tä, sitä positiivisempi, mitä lähempänä 0:ta, sitä negatiivisempi.
from snownlp import SnowNLP
# 定义一个函数来计算情感得分,并处理可能的错误
def sentiment_analysis(text):
try:
s = SnowNLP(text)
return s.sentiments
except ZeroDivisionError:
return None
# 对每条评论内容进行情感分析
comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis)
# 删除情感得分为 None 的评论
comment_df = comment_df[comment_df['sentiment'].notna()]
# 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类
comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')
Tässä kokeessa kynnysarvona käytetään arvoa 0,5, mikä on tätä arvoa suurempi, ja mikä tahansa tätä arvoa pienempi on negatiivinen kommentti. Kirjoittamalla koodia, piirrä mielipideanalyysikaavio päivittäisistä uutiskommenteista ja laske päiväuutisten positiivisten ja negatiivisten kommenttien määrä Positiivisten kommenttien määrä on positiivinen arvo ja negatiivisten kommenttien määrä arvo.
# 提取新闻日期
comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date
# 统计每一天的正向和负向评论数量
daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0)
# 绘制柱状图
plt.figure(figsize=(14, 8))
# 绘制正向评论数量的柱状图
plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green')
# 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示)
plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red')
# 添加标签和标题
plt.xlabel('Date')
plt.ylabel('Number of Comments')
plt.title('Daily Sentiment Analysis of Comments')
plt.legend()
# 设置x轴刻度旋转
plt.xticks(rotation=45)
# 显示图表
plt.tight_layout()
plt.show()
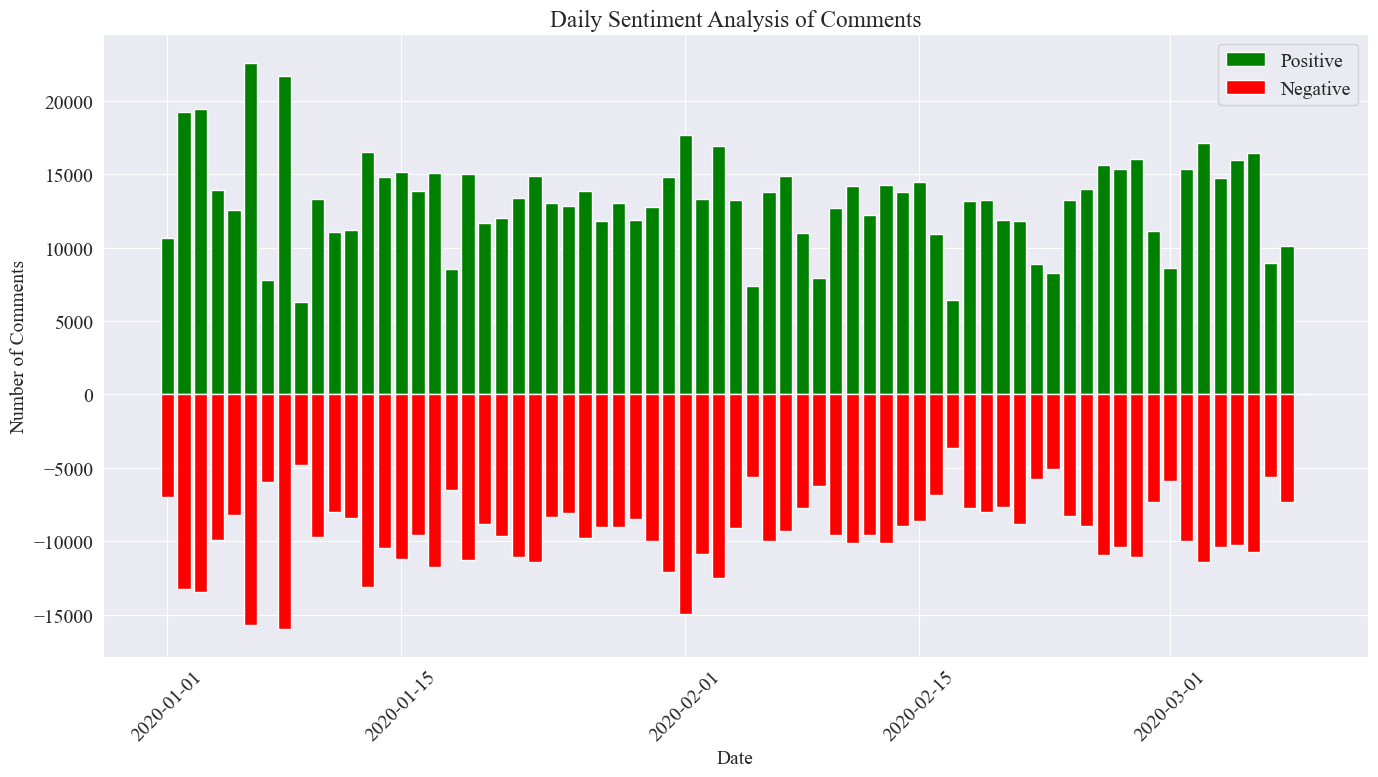
Lopullinen tilastollinen kuva on edellä esitetyn kaltainen. Positiiviset kommentit epidemian aikana olivat hieman suurempia kuin negatiiviset kommentit. että yleisö suhtautui epidemiaan myönteisemmin.
Kommenttien tunneanalyysi alueittain
Laskemalla kussakin maakunnassa ja alueella lähetettyjen positiivisten kommenttien osuudet saatiin kaavio positiivisten kommenttien osuudesta kullakin alueella.
# 计算各地区的积极评论数量和总评论数量
area_sentiment_stats = comment_df.groupby('province').agg(
total_comments=('comment_content', 'count'),
positive_comments=('sentiment', lambda x: (x > 0.5).sum())
)
# 计算各地区的积极评论占比
area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments']
# 绘制柱状图
plt.figure(figsize=(14, 7))
plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue')
plt.xlabel('地区')
plt.ylabel('积极评论占比')
plt.title('各地区的积极评论占比')
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
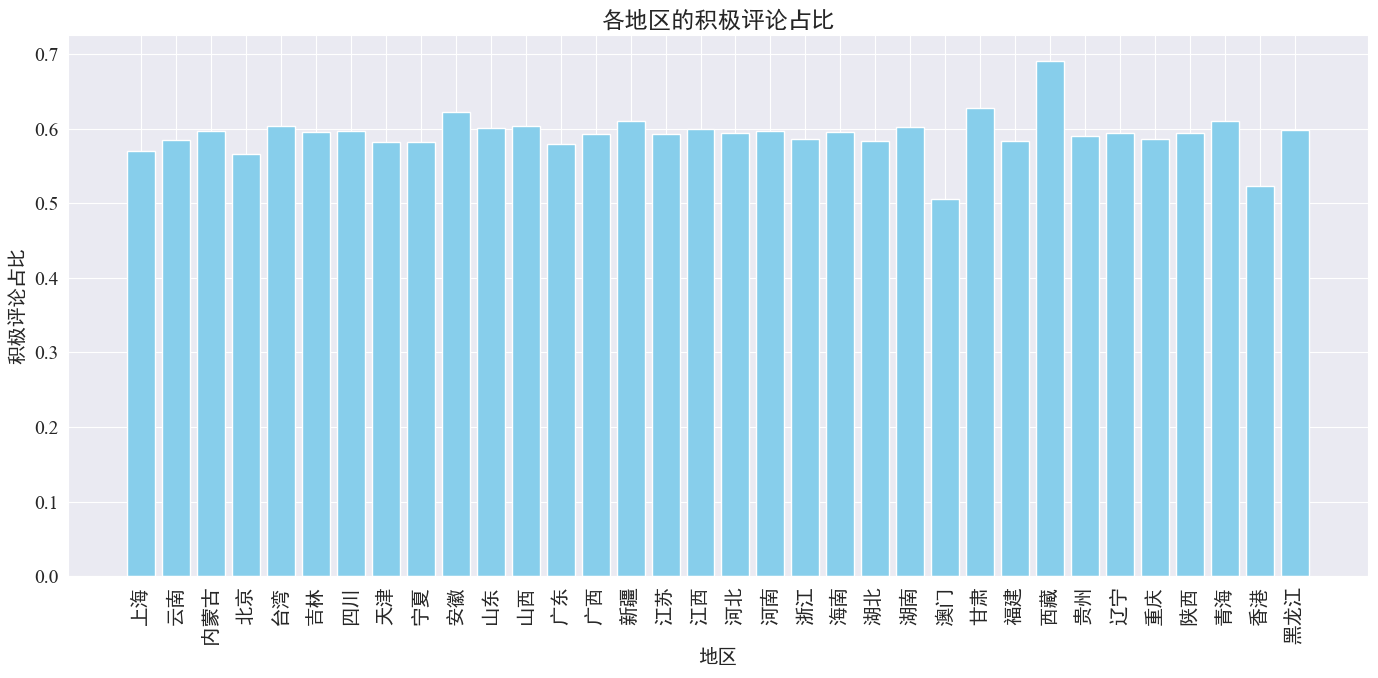
Kuten yllä olevasta kaaviosta voidaan nähdä, myönteisten kommenttien osuus on useimmissa provinsseissa noin 60 prosenttia, ja Macaossa on vähiten myönteisiä kommentteja, noin 50 prosenttia, kun taas Tiibetissä on suurin positiivisten kommenttien osuus, lähellä noin 50 prosenttia. 70 %.
Yllä olevasta kommenttien jakautumisesta voidaan nähdä, että kommentit Manner-Kiinassa ovat pääosin myönteisiä, kun taas Hongkongin ja Macaon negatiiviset kommentit ovat lisääntyneet Tiibetin pieni otoskoko.
Uutiset Kommentit Word Cloud Chart Drawing
Kaikkien kommenttien sanapilvikaaviot, positiiviset kommentit ja negatiiviset kommentit laskettiin erikseen piirretyt kaaviot.

Voidaan nähdä, että useimpien ihmisten kommentit epidemian aikana ovat suhteellisen yksinkertaisia, kuten "haha", "hyvä" jne. Positiivisissa kommenteissa voi nähdä rohkaisevia sanoja, kuten "Come on China", "Come on Wuhan" , jne., kun taas negatiivisissa kommenteissa on kritiikkiä, kuten "Haha" ja "Maasta on vaikea tehdä rikas".

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten
