2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Autor:Wählen SieDB IT-Abteilung
Einführung: Data Lakehouse kombiniert die hohe Leistung und Echtzeitleistung des Data Warehouse mit den geringen Kosten und der Flexibilität des Data Lake, um Benutzern dabei zu helfen, verschiedene Datenverarbeitungs- und Analyseanforderungen bequemer zu erfüllen. In den letzten mehreren Versionen hat Apache Doris seine Integration mit dem Data Lake weiter vertieft und sich zu einer ausgereiften integrierten Lake- und Warehouse-Lösung entwickelt. Um den Benutzern den schnellen Einstieg zu erleichtern, werden wir in einer Reihe von Artikeln, darunter Hudi, Iceberg, Paimon, OSS und Delta Lake, den Bauleitfaden für die integrierte Lake- und Warehouse-Architektur für Apache Doris und verschiedene gängige Data-Lake-Formate und Speichersysteme vorstellen , Kudu, BigQuery usw. Willkommen, bleiben Sie dran.
Als neue offene Datenverwaltungsarchitektur kombiniert Data Lakehouse die hohe Leistung und Echtzeitleistung von Data Warehouses mit den niedrigen Kosten und der Flexibilität von Data Lakes, um Benutzern dabei zu helfen, verschiedene Datenanforderungen bequemer zu erfüllen. Die Nachfrage nach Verarbeitungsanalysen wird zunehmend genutzt in Big-Data-Systemen von Unternehmen.
In den vergangenen VersionenApache Doris Die Integration mit dem Data Lake wird weiter vertieft und hat sich mittlerweile zu einer ausgereiften integrierten Lake- und Warehouse-Lösung entwickelt.
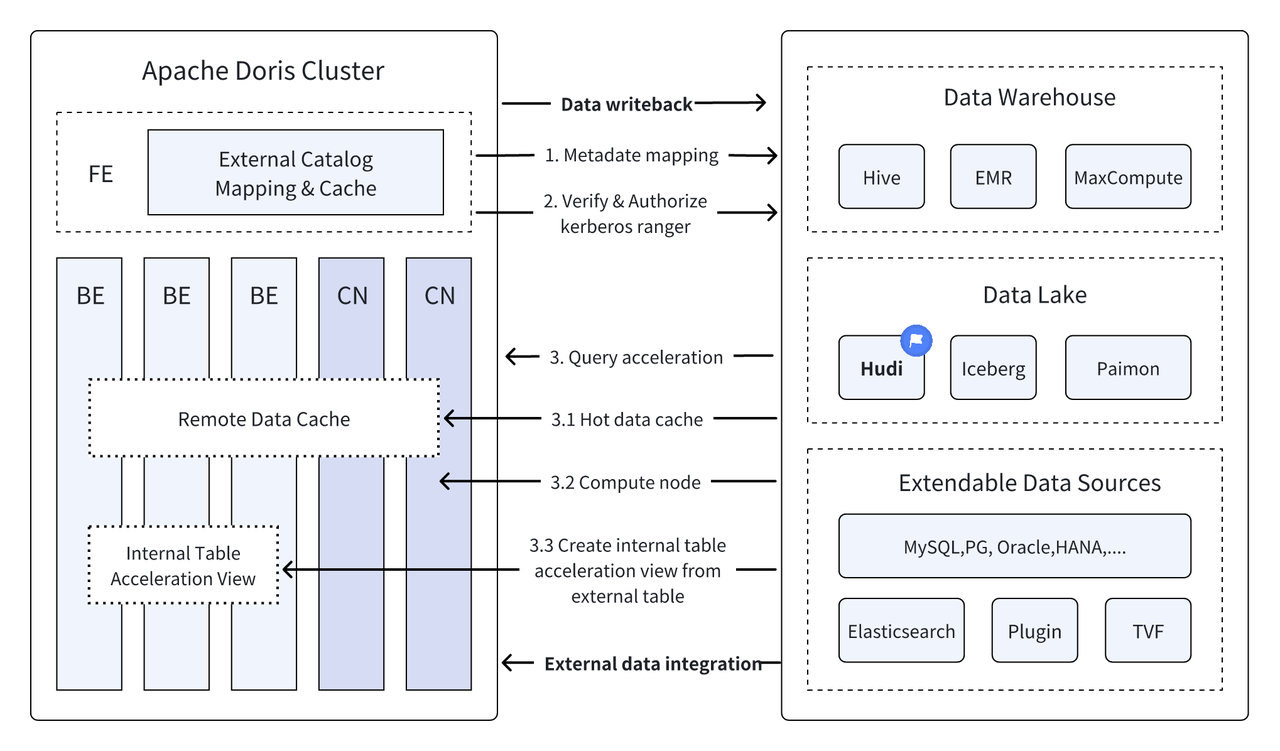
Apache Hudi Es ist derzeit eines der gängigsten offenen Data-Lake-Formate und eine transaktionale Data-Lake-Management-Plattform, die eine Vielzahl gängiger Abfrage-Engines unterstützt, darunter Apache Doris.Apache Doris Die Lesefunktionen von Apache Hudi-Datentabellen wurden ebenfalls verbessert:
- Kopieren beim Schreiben der Tabelle: Snapshot-Abfrage
- Zusammenführen beim Lesen der Tabelle: Snapshot-Abfragen, optimierte Leseabfragen
- Unterstützen Sie Zeitreisen
- Unterstützt inkrementelles Lesen
Mit der leistungsstarken Abfrageausführung von Apache Doris und den Echtzeit-Datenverwaltungsfunktionen von Apache Hudi können effiziente, flexible und kostengünstige Datenabfragen und -analysen erreicht werden. Außerdem werden leistungsstarke Datenrückverfolgung, Prüfung und inkrementelle Verarbeitung ermöglicht Funktionen, die derzeit auf Apache basieren. Die Kombination von Doris und Apache Hudi wurde in realen Geschäftsszenarien von mehreren Community-Benutzern überprüft und gefördert:
Datenanalyse und -verarbeitung in Echtzeit : Gängige Szenarien wie die Transaktionsanalyse in der Finanzbranche, die Echtzeit-Clickstream-Analyse in der Werbebranche und die Analyse des Benutzerverhaltens in der E-Commerce-Branche erfordern alle Datenaktualisierungen und Abfrageanalysen in Echtzeit. Hudi kann die Datenaktualisierung und -verwaltung in Echtzeit realisieren und die Datenkonsistenz und -zuverlässigkeit sicherstellen. Die Kombination beider kann die Anforderungen der Echtzeit-Datenanalyse und -verarbeitung vollständig erfüllen .
Datenrückverfolgung und -prüfung : Für Branchen wie das Finanzwesen und die medizinische Versorgung, die extrem hohe Anforderungen an Datensicherheit und -genauigkeit stellen, sind Datenrückverfolgung und -prüfung sehr wichtige Funktionen. Hudi bietet eine Zeitreisefunktion, mit der Benutzer den Status historischer Daten anzeigen können. In Kombination mit den effizienten Abfragefunktionen von Apache Doris können Daten jederzeit schnell durchsucht und analysiert werden, um eine genaue Rückverfolgung und Prüfung zu erreichen.
Inkrementelles Lesen und Analysieren von Daten: Bei der Durchführung von Big-Data-Analysen stehen wir häufig vor dem Problem großer Datenmengen und häufiger Aktualisierungen. Hudi unterstützt das inkrementelle Lesen von Daten, sodass Benutzer nur sich ändernde Daten verarbeiten können, ohne die gesamte Datenmenge gleichzeitig aktualisieren zu müssen Auch die inkrementellen Lesefunktionen von Apache Doris können diesen Prozess effizienter machen und die Effizienz der Datenverarbeitung und -analyse deutlich verbessern.
Verbundabfragen über Datenquellen hinweg : Viele Unternehmensdatenquellen sind komplex und die Daten können in verschiedenen Datenbanken gespeichert sein. Die Multi-Catalog-Funktion von Doris unterstützt die automatische Zuordnung und Synchronisierung mehrerer Datenquellen sowie föderierte Abfragen über Datenquellen hinweg. Für Unternehmen, die Daten aus mehreren Datenquellen zur Analyse abrufen und integrieren müssen, verkürzt dies den Datenflusspfad erheblich und verbessert die Arbeitseffizienz.
In diesem Artikel erfahren die Leser, wie sie schnell eine Test- und Demonstrationsumgebung für Apache Doris + Apache Hudi in einer Docker-Umgebung erstellen können, und demonstrieren die Funktionsweise der einzelnen Funktionen, um den Lesern einen schnellen Einstieg zu erleichtern.
Alle in diesem Artikel enthaltenen Skripte und Codes können von dieser Adresse bezogen werden:https://github.com/apache/doris/tree/master/samples/datalake/hudi
Das Beispiel in diesem Artikel wird mit Docker Compose bereitgestellt. Die Komponenten und Versionsnummern lauten wie folgt:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Als nächstes generieren Sie Hudi-Daten über Spark.Wie im folgenden Code gezeigt, enthält der Cluster bereits eine Karte mit dem Namencustomer Hive-Tabelle, Sie können über diese Hive-Tabelle eine Hudi-Tabelle erstellen:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Wie unten gezeigt, eine Datei mit dem Namen hudi Katalog (erhältlich überHOW CATALOGS Überprüfen). Das Folgende ist die Erstellungsanweisung des Katalogs:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Bereits vorhandene Daten, d. h. vorhandene Daten werden überschrieben:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Inkrementelles Lesen ist eine der von Hudi bereitgestellten Funktionsfunktionen. Durch inkrementelles Lesen können Benutzer inkrementelle Daten in einem bestimmten Zeitbereich abrufen und so eine inkrementelle Datenverarbeitung erreichen.Dafür kann Doris einlegenc_custkey=100 Fragen Sie die nachfolgenden Änderungsdaten ab.Wie unten gezeigt, haben wir a eingefügtc_custkey=32Die Daten:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris unterstützt die Abfrage der Hudi-Daten der angegebenen Snapshot-Version und realisiert so die Zeitreisefunktion der Daten. Zunächst können Sie den Übermittlungsverlauf der beiden Hudi-Tabellen über Spark abfragen:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Dann kann es durch Doris ausgeführt werden c_custkey=32 Fragen Sie den Daten-Snapshot ab, bevor die Daten eingefügt werden.Wie Sie unten sehen könnenc_custkey=32 Die Daten wurden noch nicht aktualisiert:
Hinweis: Die Time Travel-Syntax unterstützt den neuen Optimierer derzeit nicht und muss zuerst ausgeführt werden
set enable_nereids_planner=false;Schalten Sie den neuen Optimierer aus. Dieses Problem wird in nachfolgenden Versionen behoben.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Daten in Apache Hudi können grob in zwei Kategorien unterteilt werden: Basisdaten und inkrementelle Daten. Basisdaten sind normalerweise eine zusammengeführte Parquet-Datei, während sich inkrementelle Daten auf das durch INSERT, UPDATE oder DELETE generierte Dateninkrement beziehen. Basisdaten können direkt gelesen werden, und inkrementelle Daten müssen über Merge on Read gelesen werden.
Bei Hudi COW-Tabellenabfragen oder leseoptimierten MOR-Tabellenabfragen handelt es sich bei den Daten um Basisdaten, und die Datendateien können direkt über den nativen Parquet Reader von Doris gelesen werden, und es können extrem schnelle Abfrageantworten erhalten werden. Für inkrementelle Daten muss Doris das Java SDK von Hudi über JNI aufrufen, um darauf zuzugreifen.Um eine optimale Abfrageleistung zu erreichen, teilt Apache Doris die Daten in einer Abfrage in zwei Teile: Basisdaten und inkrementelle Daten, und liest sie jeweils mit den oben genannten Methoden.。
Um diese Optimierungsidee zu überprüfen, haben wir bestanden EXPLAIN -Anweisung, um zu sehen, wie viele Basisdaten und inkrementelle Daten in der folgenden Abfrage enthalten sind. Für die COW-Tabelle sind alle 101 Daten-Shards Basisdaten (hudiNativeReadSplits=101/101 ), sodass alle COW-Tabellen direkt über Doris Parquet Reader gelesen werden können und so die beste Abfrageleistung erzielt werden kann. Bei ROW-Tabellen handelt es sich bei den meisten Daten-Shards um Basisdaten (hudiNativeReadSplits=100/101), ist die Anzahl der Shards inkrementelle Daten und kann grundsätzlich eine bessere Abfrageleistung erzielen.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Sie können einige Löschvorgänge über Spark durchführen, um Änderungen in den Hudi-Basisdaten und inkrementellen Daten weiter zu beobachten:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Darüber hinaus kann die Partitionierung auch über Partitionierungsbedingungen durchgeführt werden, um die Datenmenge weiter zu reduzieren und die Abfragegeschwindigkeit zu verbessern.Im folgenden Beispiel durch die Partitionsbedingungc_nationkey = 15 Führen Sie eine Partitionsreduzierung durch, sodass Abfrageanforderungen nur auf eine Partition zugreifen müssen (partition=1/26) Daten.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Das Obige ist eine detaillierte Anleitung zum schnellen Aufbau einer Test-/Demoumgebung auf Basis von Apache Doris und Apache Hudi. In Zukunft werden wir auch eine Reihe von Anleitungen zum Aufbau einer integrierten Lake- und Warehouse-Architektur mit Apache Doris und verschiedenen Mainstream-Data Lakes veröffentlichen Formate und Speichersysteme, einschließlich Iceberg, Paimon, OSS, Delta Lake usw., dürfen weiterhin beachtet werden.

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

