2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
kirjoittaja:Valitse DB Tekninen tiimi
Johdanto: Data Lakehouse yhdistää tietovaraston korkean suorituskyvyn ja reaaliaikaisen suorituskyvyn datajärven alhaisiin kustannuksiin ja joustavuuteen auttaakseen käyttäjiä vastaamaan erilaisiin tietojenkäsittely- ja analysointitarpeisiin kätevämmin. Aiemmissa useissa versioissa Apache Doris on jatkanut integroinnin syventämistä datajärven kanssa ja kehittynyt kypsäksi integroiduksi järvi- ja varastoratkaisuksi. Helpottaaksemme käyttäjien nopeaa aloittamista, esittelemme Apache Dorisin järven ja varaston integroidun arkkitehtuurin rakennusoppaan sekä useat valtavirran datajärven formaatit ja tallennusjärjestelmät artikkelisarjan kautta, mukaan lukien Hudi, Iceberg, Paimon, OSS, Delta Lake , Kudu, BigQuery jne. Tervetuloa pysy kuulolla.
Uutena avoimena tiedonhallintaarkkitehtuurina Data Lakehouse yhdistää tietovarastojen korkean suorituskyvyn ja reaaliaikaisen suorituskyvyn datalakkien alhaisiin kustannuksiin ja joustavuuteen auttaakseen käyttäjiä vastaamaan erilaisiin tietotarpeisiin entistä kätevämmin yritysten big datajärjestelmissä.
Useiden viimeisten versioiden aikanaApache Doris Se jatkaa integroinnin syventämistä datajärven kanssa ja on nyt kehittynyt kypsäksi integroiduksi järvi- ja varastoratkaisuksi.
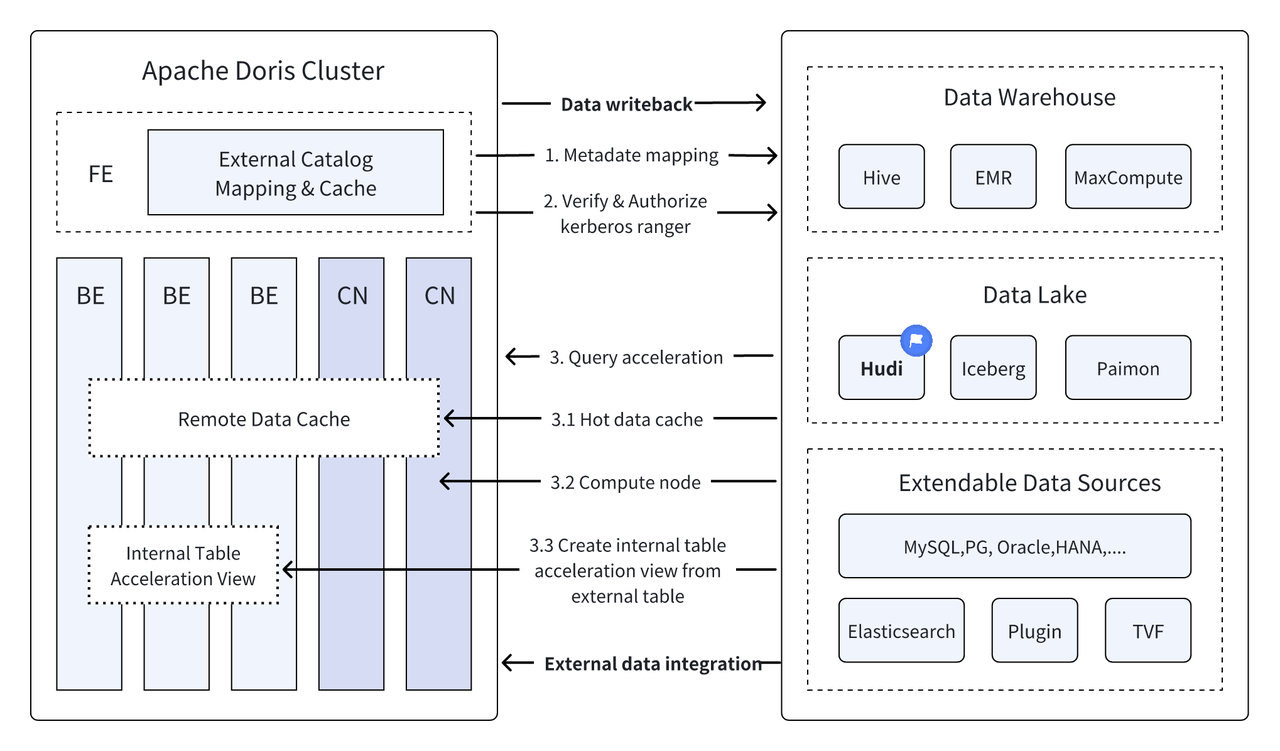
Apache Hudi Se on tällä hetkellä yksi valtavirran avoimen datajärven muodoista ja transaktioiden datajärven hallintaalusta, joka tukee useita valtavirran kyselymoottoreita, mukaan lukien Apache Doris.Apache Doris Apache Hudi -tietotaulukoiden lukuominaisuuksia on myös parannettu:
- Kopioi kirjoitustaulukkoon: Snapshot Query
- Yhdistä lukutaulukkoon: tilannekuvakyselyt, lue optimoidut kyselyt
- Tue aikamatkailua
- Tuki asteittaista lukemista
Apache Dorisin tehokkaan kyselyn suorittamisen ja Apache Hudin reaaliaikaisten tietojen hallintaominaisuuksien avulla voidaan saavuttaa tehokas, joustava ja edullinen datakysely ja -analyysi. Se tarjoaa myös tehokkaan tietojen jäljityksen, tarkastuksen ja lisäkäsittelyn Toiminnot perustuvat tällä hetkellä Apacheen Useat yhteisön käyttäjät ovat vahvistaneet ja mainostaneet Dorisin ja Apache Hudin yhdistelmää todellisissa liiketoimintaskenaarioissa:
Reaaliaikainen tietojen analysointi ja käsittely : Yleiset skenaariot, kuten transaktioanalyysi rahoitusalalla, reaaliaikainen napsautusvirta-analyysi mainosalalla ja käyttäjien käyttäytymisanalyysi sähköisen kaupankäynnin alalla, edellyttävät kaikki reaaliaikaisia tietojen päivityksiä ja kyselyanalyysiä. Hudi pystyy toteuttamaan reaaliaikaisen tiedon päivityksen ja hallinnan sekä varmistamaan tietojen johdonmukaisuuden ja luotettavuuden .
Tietojen jälkiseuranta ja auditointi : Rahoituksen ja sairaanhoidon kaltaisilla toimialoilla, joilla on erittäin korkeat vaatimukset tietoturvalle ja tarkkuudelle, tietojen jäljitys ja auditointi ovat erittäin tärkeitä toimintoja. Hudi tarjoaa aikamatkustustoiminnon, jonka avulla käyttäjät voivat tarkastella historiallisten tietojen tilaa. Yhdessä Apache Dorisin tehokkaiden kyselyominaisuuksien kanssa se voi nopeasti etsiä ja analysoida tietoja milloin tahansa tarkan taaksepäinseurannan ja tarkastuksen saavuttamiseksi.
Inkrementaalinen tietojen lukeminen ja analysointi: Suuren datan analyysiä tehdessämme kohtaamme usein suuria tietomääriä ja toistuvia päivityksiä koskevia ongelmia, joiden avulla käyttäjät voivat käsitellä vain muuttuvia tietoja ilman, että heidän tarvitsee päivittää koko dataa samanaikaisesti , Apache Dorisin inkrementaaliset lukutoiminnot voivat myös tehdä tästä prosessista tehokkaamman, mikä parantaa merkittävästi tietojenkäsittelyn ja analyysin tehokkuutta.
Yhdistetyt kyselyt tietolähteistä : Monet yritystietolähteet ovat monimutkaisia, ja tiedot voidaan tallentaa eri tietokantoihin. Dorisin Multi-Catalogi-toiminto tukee useiden tietolähteiden automaattista kartoittamista ja synkronointia sekä yhdistettyjä kyselyitä tietolähteiden välillä. Yrityksille, joiden on hankittava ja integroitava tietoja useista tietolähteistä analysointia varten, tämä lyhentää huomattavasti tiedonkulkupolkua ja parantaa työn tehokkuutta.
Tämä artikkeli esittelee lukijoille, kuinka nopeasti rakentaa testi- ja esittelyympäristö Apache Doris + Apache Hudille Docker-ympäristössä, ja esittelee kunkin toiminnon toiminnan, jotta lukijat pääsevät nopeasti alkuun.
Kaikki tähän artikkeliin liittyvät skriptit ja koodit ovat saatavissa tästä osoitteesta:https://github.com/apache/doris/tree/master/samples/datalake/hudi
Tämän artikkelin esimerkki on otettu käyttöön Docker Compose -sovelluksella. Komponentit ja versionumerot ovat seuraavat:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Luo seuraavaksi Hudi-data Sparkin kautta.Kuten alla olevasta koodista näkyy, klusteri sisältää jo nimetyn kortincustomer Hive-pöytä, voit luoda Hudi-taulukon tämän Hive-taulukon kautta:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Kuten alla näkyy, tiedosto nimeltä hudi Katalogi (saatavilla osoitteessaHOW CATALOGS Tarkistaa). Seuraava on luettelon luontilauseke:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Jo olemassa olevat tiedot, eli olemassa olevien tietojen korvaaminen:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Inkrementaalinen luku on yksi Hudin tarjoamista toiminnallisista ominaisuuksista. Inkremental Readin avulla käyttäjät voivat saada lisätietoa tietyllä aikavälillä, mikä saavuttaa tietojen asteittaisen käsittelyn.Tätä varten Doris voi lisätäc_custkey=100 Pyydä myöhempiä muutostietoja.Kuten alla näkyy, lisäsimme ac_custkey=32Tiedot:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris tukee määritetyn tilannekuvaversion Hudi-tietojen kyselyä, mikä toteuttaa datan aikamatkatoiminnon. Ensin voit tiedustella kahden Hudi-taulukon lähetyshistoriaa Sparkin kautta:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Sitten se voidaan suorittaa Dorisin kautta c_custkey=32 , kysy tietojen tilannekuvaa ennen tietojen lisäämistä.Kuten alla näetc_custkey=32 Tietoja ei ole vielä päivitetty:
Huomautus: Time Travel -syntaksi ei tällä hetkellä tue uutta optimoijaa, ja se on suoritettava ensin
set enable_nereids_planner=false;Sammuta uusi optimointi, tämä ongelma korjataan myöhemmissä versioissa.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Apache Hudin tiedot voidaan jakaa karkeasti kahteen luokkaan - perustietoihin ja lisätietoihin. Perustiedot ovat yleensä yhdistettyä parkettitiedostoa, kun taas lisätiedot viittaavat INSERT-, UPDATE- tai DELETE-toimintojen luomaan tietolisäykseen. Perustiedot voidaan lukea suoraan, ja lisätiedot on luettava Merge on Read -toiminnon kautta.
Hudi COW -taulukkokyselyissä tai MOR-taulukon Read Optimized -kyselyissä tiedot ovat perustietoja, ja datatiedostot voidaan lukea suoraan Doriksen alkuperäisen Parquet Readerin kautta, ja kyselyvastaukset voidaan saada erittäin nopeasti. Lisätietoa varten Dorisin on kutsuttava Hudin Java SDK:ta JNI:n kautta päästäkseen siihen.Saavuttaakseen optimaalisen kyselyn suorituskyvyn Apache Doris jakaa kyselyn tiedot kahteen osaan: perustieto- ja lisätietoihin ja lukee ne käyttämällä edellä olevia menetelmiä.。
Hyväksyimme tämän optimointiidean EXPLAIN lauseke nähdäksesi, kuinka paljon perustietoja ja lisätietoa alla olevassa kyselyssä on. COW-taulukossa kaikki 101 datasirpaletta ovat perustietoja (hudiNativeReadSplits=101/101 ), joten kaikki COW-taulukot voidaan lukea suoraan Doris Parquet Readerin kautta, jolloin saadaan paras kyselyn suorituskyky. ROW-taulukoissa suurin osa datasirpaleista on perustietoja (hudiNativeReadSplits=100/101), sirpaleiden määrä on lisätietoa, ja se voi periaatteessa saavuttaa paremman kyselyn suorituskyvyn.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Voit suorittaa joitakin poistotoimintoja Sparkin kautta tarkkaillaksesi edelleen muutoksia Hudin perustiedot ja lisätiedot:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Lisäksi osion karsiminen voidaan suorittaa osioehtojen avulla, mikä vähentää edelleen tiedon määrää ja parantaa kyselyn nopeutta.Seuraavassa esimerkissä osioehdon kauttac_nationkey = 15 Suorita osion pienentäminen niin, että kyselypyyntöjen tarvitsee päästä vain yhteen osioon (partition=1/26) tiedot.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Yllä oleva on yksityiskohtainen opas Apache Dorisiin ja Apache Hudiin perustuvan testi-/demo-ympäristön nopeaan rakentamiseen. Tulevaisuudessa julkaisemme myös sarjan oppaita integroidun järvi- ja varastoarkkitehtuurin rakentamiseksi Apache Dorisin ja useiden valtavirran datajärvien kanssa. muodot ja tallennusjärjestelmät, mukaan lukien Iceberg, Paimon, OSS, Delta Lake jne., tervetuloa jatkossakin kiinnittämään huomiota.

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema jakaaksesi joitain teknologian kehittämisen ongelmia tulevaa käyttöä varten

