
Mi información de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
autor:SeleccionarDB Equipo técnico
Introducción: Data Lakehouse combina el alto rendimiento y el rendimiento en tiempo real del almacén de datos con el bajo costo y la flexibilidad del lago de datos para ayudar a los usuarios a satisfacer diversas necesidades de procesamiento y análisis de datos de manera más conveniente. En las últimas versiones, Apache Doris continuó profundizando su integración con el lago de datos y evolucionó hasta convertirse en una solución madura de almacén y lago integrado. Para facilitar que los usuarios comiencen rápidamente, presentaremos la guía de construcción de arquitectura integrada de lago y almacén para Apache Doris y varios formatos de lago de datos y sistemas de almacenamiento convencionales a través de una serie de artículos, que incluyen Hudi, Iceberg, Paimon, OSS, Delta Lake. , Kudu, BigQuery, etc. Bienvenidos, estad atentos.
Como nueva arquitectura de gestión de datos abierta, Data Lakehouse combina el alto rendimiento y el rendimiento en tiempo real del almacén de datos con el bajo costo y la flexibilidad del lago de datos para ayudar a los usuarios a satisfacer diversas necesidades de datos de manera más conveniente. Se utiliza cada vez más en sistemas de big data empresariales.
En las últimas versiones,Doris apache Continúa profundizando su integración con el lago de datos y ahora ha evolucionado hasta convertirse en una solución madura integrada de lago y almacén.
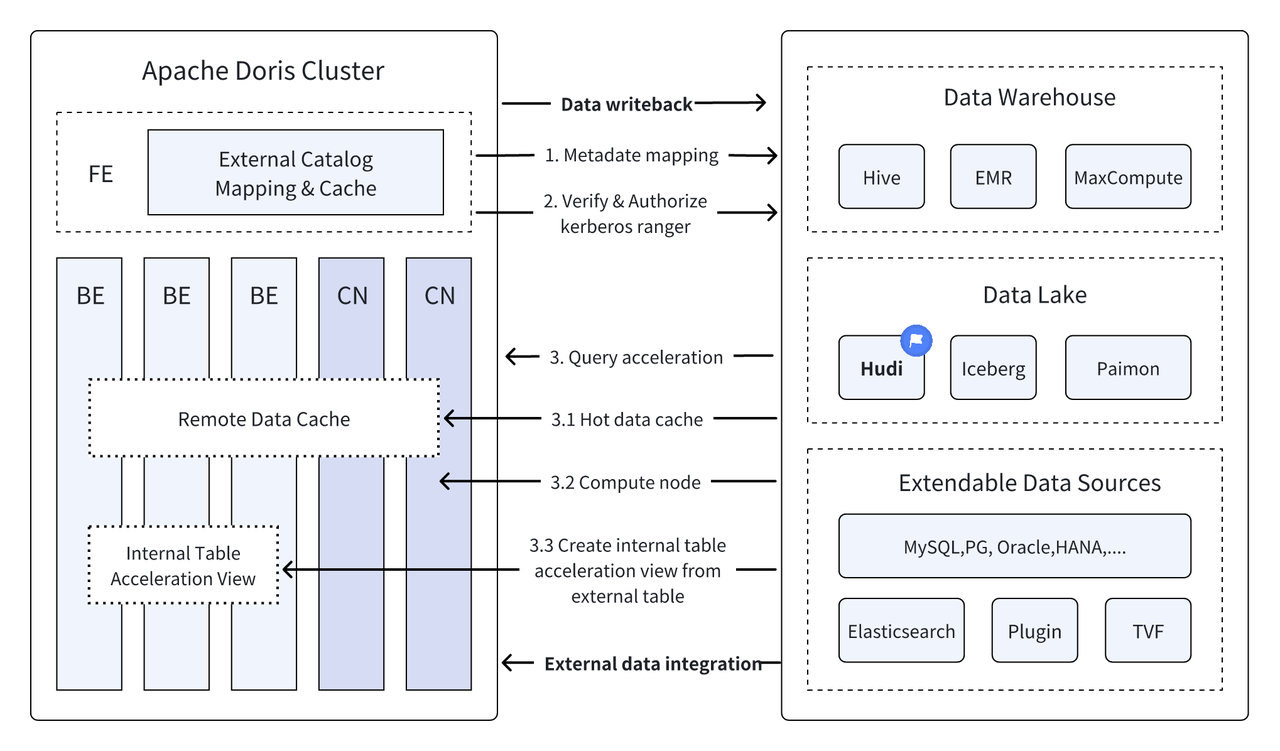
Apache Hudi Actualmente es uno de los formatos de lago de datos abiertos más utilizados y una plataforma de gestión de lagos de datos transaccionales que admite una variedad de motores de consulta convencionales, incluido Apache Doris.Doris apache También se han mejorado las capacidades de lectura de las tablas de datos de Apache Hudi:
- Copiar en la tabla de escritura: consulta de instantáneas
- Fusionar en tabla de lectura: consultas de instantáneas, consultas optimizadas de lectura
- Soporte para viajes en el tiempo
- Admite lectura incremental
Con la ejecución de consultas de alto rendimiento de Apache Doris y las capacidades de administración de datos en tiempo real de Apache Hudi, se pueden lograr consultas y análisis de datos eficientes, flexibles y de bajo costo. También proporciona un potente seguimiento de datos, auditoría y procesamiento incremental. funciones Actualmente basado en Apache La combinación de Doris y Apache Hudi ha sido verificada y promovida en escenarios comerciales reales por múltiples usuarios de la comunidad:
Análisis y procesamiento de datos en tiempo real. : Escenarios comunes como el análisis de transacciones en la industria financiera, el análisis del flujo de clics en tiempo real en la industria publicitaria y el análisis del comportamiento del usuario en la industria del comercio electrónico requieren actualizaciones de datos y análisis de consultas en tiempo real. Hudi puede realizar actualizaciones y gestión de datos en tiempo real y garantizar la coherencia y confiabilidad de los datos. Doris puede manejar de manera eficiente solicitudes de consultas de datos a gran escala en tiempo real. La combinación de los dos puede satisfacer completamente las necesidades del análisis y procesamiento de datos en tiempo real. .
Seguimiento y auditoría de datos : Para industrias como las finanzas y la atención médica que tienen requisitos extremadamente altos de seguridad y precisión de los datos, el seguimiento y la auditoría de datos son funciones muy importantes. Hudi proporciona una función de viaje en el tiempo que permite a los usuarios ver el estado de los datos históricos. Combinado con las capacidades de consulta eficientes de Apache Doris, puede buscar y analizar datos rápidamente en cualquier momento para lograr un seguimiento y una auditoría precisos.
Lectura y análisis de datos incrementales.: Al realizar análisis de big data, a menudo nos enfrentamos a problemas de gran escala de datos y actualizaciones frecuentes. Hudi admite la lectura de datos incrementales, lo que permite a los usuarios procesar solo datos cambiantes sin tener que actualizar la cantidad total de datos al mismo tiempo. , Las funciones de lectura incremental de Apache Doris también pueden hacer que este proceso sea más eficiente, mejorando significativamente la eficiencia del procesamiento y análisis de datos.
Consultas federadas entre fuentes de datos : Muchas fuentes de datos empresariales son complejas y los datos pueden almacenarse en diferentes bases de datos. La función de catálogo múltiple de Doris admite la asignación y sincronización automática de múltiples fuentes de datos y admite consultas federadas entre fuentes de datos. Para las empresas que necesitan obtener e integrar datos de múltiples fuentes de datos para su análisis, esto acorta en gran medida la ruta del flujo de datos y mejora la eficiencia del trabajo.
Este artículo presentará a los lectores cómo configurar rápidamente el entorno de prueba y demostración de Apache Doris + Apache Hudi en el entorno Docker y demostrará el funcionamiento de cada función para ayudar a los lectores a comenzar rápidamente.
Todos los scripts y códigos involucrados en este artículo se pueden obtener en esta dirección:https://github.com/apache/doris/tree/master/samples/datalake/hudi
El ejemplo de este artículo se implementa utilizando Docker Compose. Los componentes y números de versión son los siguientes:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
A continuación, genere datos de Hudi a través de Spark.Como se muestra en el código siguiente, el grupo ya contiene una tarjeta llamadacustomer Tabla de Hive, puede crear una tabla Hudi a través de esta tabla de Hive:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Como se muestra a continuación, un archivo llamado hudi Catálogo (disponible a través deHOW CATALOGS Controlar). La siguiente es la declaración de creación del Catálogo:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Datos ya existentes, es decir, sobrescribiendo datos existentes:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
La lectura incremental es una de las características funcionales proporcionadas por Hudi. A través de la lectura incremental, los usuarios pueden obtener datos incrementales en un rango de tiempo específico, logrando así un procesamiento incremental de datos.Para esto, Doris puede insertarc_custkey=100 Consulta los datos de cambios posteriores.Como se muestra a continuación, insertamos unc_custkey=32Los datos:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris admite la consulta de datos de Hudi de la versión de instantánea especificada, realizando así la función de viaje en el tiempo de los datos. Primero, puede consultar el historial de envío de las dos tablas Hudi a través de Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Luego, se puede ejecutar a través de Doris. c_custkey=32 , consulte la instantánea de datos antes de insertar los datos.Como puede ver abajoc_custkey=32 Los datos aún no han sido actualizados:
Nota: la sintaxis de Time Travel no admite actualmente el nuevo optimizador y debe ejecutarse primero
set enable_nereids_planner=false;Apague el nuevo optimizador, este problema se solucionará en versiones posteriores.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Los datos en Apache Hudi se pueden dividir aproximadamente en dos categorías: datos de referencia y datos incrementales. Los datos de referencia suelen ser un archivo Parquet fusionado, mientras que los datos incrementales se refieren al incremento de datos generado por INSERT, UPDATE o DELETE. Los datos de referencia se pueden leer directamente, mientras que los datos incrementales deben leerse mediante Merge on Read.
Para las consultas de la tabla Hudi COW o las consultas de lectura optimizada de la tabla MOR, los datos son datos de referencia y los archivos de datos se pueden leer directamente a través del Parquet Reader nativo de Doris, y se pueden obtener respuestas a las consultas extremadamente rápidas. Para datos incrementales, Doris necesita llamar al SDK de Java de Hudi a través de JNI para acceder a ellos.Para lograr un rendimiento óptimo de las consultas, Apache Doris dividirá los datos de una consulta en dos partes: datos de referencia e incrementales, y los leerá utilizando los métodos anteriores respectivamente.。
Para verificar esta idea de optimización, pasamos EXPLAIN declaración para ver cuántos datos de referencia y datos incrementales hay en la consulta siguiente. Para la tabla COW, los 101 fragmentos de datos son datos de referencia (hudiNativeReadSplits=101/101 ), por lo que todas las tablas COW se pueden leer directamente a través de Doris Parquet Reader, para obtener el mejor rendimiento de consulta. Para las tablas ROW, la mayoría de los fragmentos de datos son datos de referencia (hudiNativeReadSplits=100/101), la cantidad de fragmentos son datos incrementales y básicamente puede lograr un mejor rendimiento de las consultas.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Puede realizar algunas operaciones de eliminación a través de Spark para observar más cambios en los datos de referencia y los datos incrementales de Hudi:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Además, la poda de particiones se puede realizar mediante condiciones de partición para reducir aún más la cantidad de datos y mejorar la velocidad de consulta.En el siguiente ejemplo, a través de la condición de particiónc_nationkey = 15 Realice una reducción de partición para que las solicitudes de consulta solo necesiten acceder a una partición (partition=1/26) datos.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Lo anterior es una guía detallada para construir rápidamente un entorno de prueba/demostración basado en Apache Doris y Apache Hudi. En el futuro, también lanzaremos una serie de guías para construir una arquitectura de almacén y lago integrada con Apache Doris y varios lagos de datos convencionales. Formatos y sistemas de almacenamiento, incluidos Iceberg, Paimon, OSS, Delta Lake, etc., bienvenidos a seguir prestando atención.

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]