
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
pengarang:PilihDB Tim teknis
Pendahuluan: Data Lakehouse menggabungkan kinerja tinggi dan kinerja real-time dari gudang data dengan biaya rendah dan fleksibilitas data lake untuk membantu pengguna memenuhi berbagai kebutuhan pemrosesan dan analisis data dengan lebih nyaman. Dalam beberapa versi terakhir, Apache Doris terus memperdalam integrasinya dengan data lake dan telah berkembang menjadi solusi danau dan gudang terintegrasi yang matang. Untuk memudahkan pengguna memulai dengan cepat, kami akan memperkenalkan panduan konstruksi arsitektur terintegrasi danau dan gudang untuk Apache Doris dan berbagai format danau data utama serta sistem penyimpanan melalui serangkaian artikel, termasuk Hudi, Iceberg, Paimon, OSS, Delta Lake , Kudu, BigQuery, dll. Selamat datang, pantau terus.
Sebagai arsitektur manajemen data terbuka yang baru, Data Lakehouse menggabungkan kinerja tinggi dan kinerja real-time dari gudang data dengan biaya rendah dan fleksibilitas data lake untuk membantu pengguna memenuhi berbagai kebutuhan data dengan lebih nyaman dalam sistem data besar perusahaan.
Selama beberapa versi terakhir,Apache Doris Perusahaan ini terus memperdalam integrasinya dengan data lake dan kini telah berkembang menjadi solusi danau dan gudang terintegrasi yang matang.
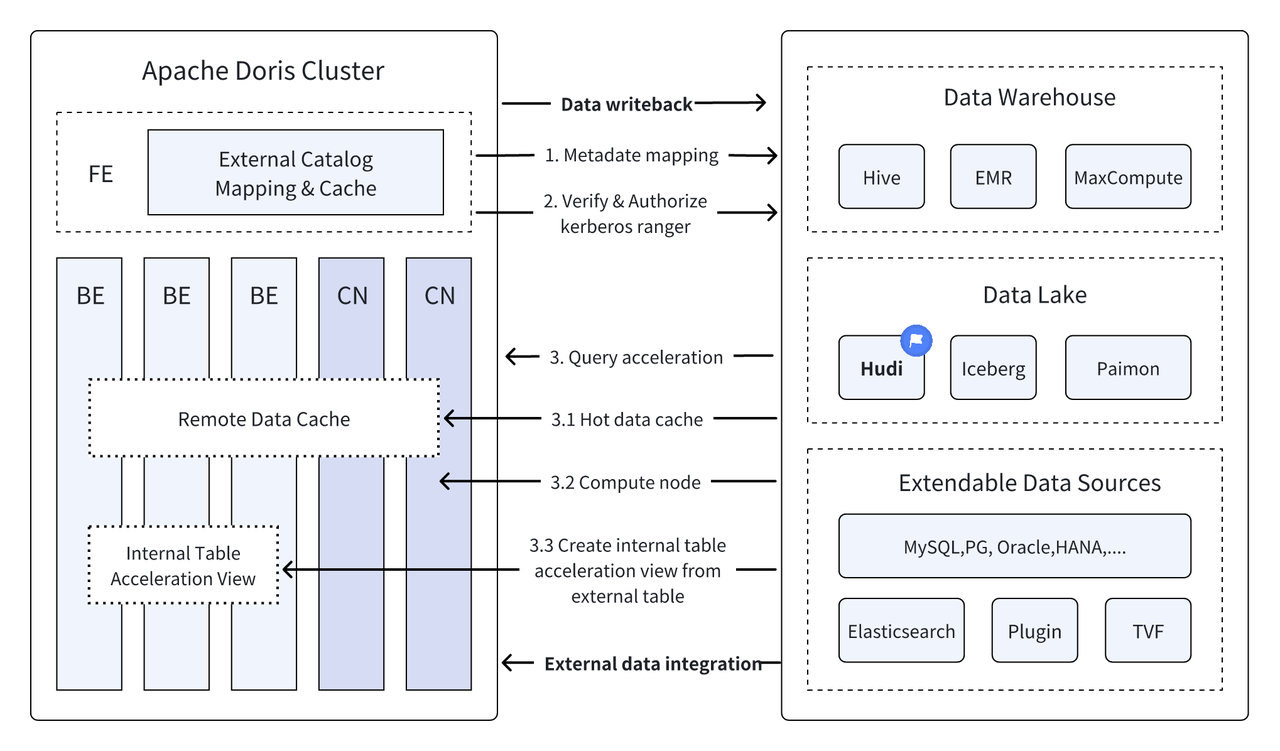
Apache Hudi Saat ini merupakan salah satu format data lake terbuka yang paling umum dan platform manajemen data lake transaksional yang mendukung berbagai mesin kueri utama termasuk Apache Doris.Apache Doris Kemampuan membaca tabel data Apache Hudi juga telah ditingkatkan:
- Salin pada Tabel Tulis: Kueri Snapshot
- Gabungkan pada Tabel Baca: Kueri Snapshot, Kueri Baca yang Dioptimalkan
- Mendukung Perjalanan Waktu
- Mendukung Bacaan Tambahan
Dengan eksekusi kueri berkinerja tinggi dari Apache Doris dan kemampuan manajemen data real-time dari Apache Hudi, kueri dan analisis data yang efisien, fleksibel, dan berbiaya rendah dapat dicapai. Ini juga menyediakan penelusuran balik data yang kuat, audit, dan pemrosesan tambahan fungsi. Saat ini berdasarkan Apache Kombinasi Doris dan Apache Hudi telah diverifikasi dan dipromosikan dalam skenario bisnis nyata oleh banyak pengguna komunitas:
Analisis dan pemrosesan data waktu nyata : Skenario umum seperti analisis transaksi di industri keuangan, analisis aliran klik waktu nyata di industri periklanan, dan analisis perilaku pengguna di industri e-niaga semuanya memerlukan pembaruan data waktu nyata dan analisis kueri. Hudi dapat mewujudkan pembaruan dan pengelolaan data secara real-time serta memastikan konsistensi dan keandalan data. Doris dapat secara efisien menangani permintaan kueri data berskala besar secara real-time. Kombinasi keduanya dapat sepenuhnya memenuhi kebutuhan analisis dan pemrosesan data secara real-time .
Pelacakan dan audit data : Untuk industri seperti keuangan dan perawatan medis yang memiliki persyaratan sangat tinggi terhadap keamanan dan keakuratan data, penelusuran ulang dan audit data merupakan fungsi yang sangat penting. Hudi menyediakan fungsi perjalanan waktu yang memungkinkan pengguna melihat status data historis. Dikombinasikan dengan kemampuan kueri Apache Doris yang efisien, Hudi dapat dengan cepat mencari dan menganalisis data kapan saja untuk mencapai penelusuran mundur dan audit yang akurat.
Pembacaan dan analisis data tambahan: Saat melakukan analisis data besar, kita sering dihadapkan pada masalah skala data yang besar dan pembaruan yang sering dilakukan. Hudi mendukung pembacaan data tambahan, yang memungkinkan pengguna hanya memproses perubahan data tanpa harus memperbarui seluruh jumlah data pada saat yang bersamaan , Fungsi Baca Inkremental Apache Doris juga dapat membuat proses ini lebih efisien, sehingga secara signifikan meningkatkan efisiensi pemrosesan dan analisis data.
Kueri gabungan di seluruh sumber data : Banyak sumber data perusahaan yang kompleks, dan datanya mungkin disimpan dalam database yang berbeda. Fungsi Multi-Katalog Doris mendukung pemetaan otomatis dan sinkronisasi berbagai sumber data, dan mendukung kueri gabungan di seluruh sumber data. Bagi perusahaan yang perlu memperoleh dan mengintegrasikan data dari berbagai sumber data untuk analisis, hal ini sangat memperpendek jalur aliran data dan meningkatkan efisiensi kerja.
Artikel ini akan memperkenalkan kepada pembaca cara cepat membangun lingkungan pengujian dan demonstrasi untuk Apache Doris + Apache Hudi di lingkungan Docker, dan mendemonstrasikan pengoperasian setiap fungsi untuk membantu pembaca memulai dengan cepat.
Semua skrip dan kode yang terlibat dalam artikel ini dapat diperoleh dari alamat ini:https://github.com/apache/doris/tree/master/samples/datalake/hudi
Contoh dalam artikel ini di-deploy menggunakan Docker Compose. Komponen dan nomor versinya adalah sebagai berikut:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Selanjutnya, hasilkan data Hudi melalui Spark.Seperti yang ditunjukkan pada kode di bawah, cluster sudah berisi kartu bernamacustomer Tabel Hive, Anda dapat membuat tabel Hudi melalui tabel Hive ini:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Seperti yang ditunjukkan di bawah ini, sebuah file bernama hudi Katalog (tersedia melaluiHOW CATALOGS Memeriksa). Berikut pernyataan pembuatan Katalog:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Data yang sudah ada, yaitu menimpa data yang sudah ada:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Bacaan Tambahan adalah salah satu fitur fungsional yang disediakan oleh Hudi. Melalui Bacaan Tambahan, pengguna dapat memperoleh data tambahan dalam rentang waktu tertentu, sehingga mencapai pemrosesan data tambahan.Untuk ini, Doris bisa menyisipkanc_custkey=100 Kueri data perubahan berikutnya.Seperti yang ditunjukkan di bawah ini, kami memasukkan ac_custkey=32Data:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris mendukung kueri data Hudi dari versi snapshot yang ditentukan, sehingga mewujudkan fungsi Perjalanan Waktu pada data tersebut. Pertama, Anda bisa menanyakan riwayat pengiriman dua tabel Hudi melalui Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Kemudian bisa dieksekusi melalui Doris c_custkey=32 , kueri cuplikan data sebelum data dimasukkan.Seperti yang Anda lihat di bawahc_custkey=32 Data belum diperbarui:
Catatan: Sintaks Time Travel saat ini tidak mendukung pengoptimal baru dan perlu dijalankan terlebih dahulu
set enable_nereids_planner=false;Matikan pengoptimal baru, masalah ini akan diperbaiki di versi berikutnya.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Data di Apache Hudi secara kasar dapat dibagi menjadi dua kategori - data dasar dan data tambahan. Data dasar biasanya berupa file Parket yang digabungkan, sedangkan data tambahan mengacu pada penambahan data yang dihasilkan oleh INSERT, UPDATE, atau DELETE. Data dasar dapat dibaca secara langsung, dan data tambahan perlu dibaca melalui Gabung saat Dibaca.
Untuk kueri tabel Hudi COW atau kueri Baca Dioptimalkan tabel MOR, datanya adalah data dasar, dan file data dapat dibaca langsung melalui Parket Reader asli Doris, dan respons kueri yang sangat cepat dapat diperoleh. Untuk data tambahan, Doris perlu memanggil Java SDK Hudi melalui JNI untuk mengaksesnya.Untuk mencapai performa kueri yang optimal, Apache Doris akan membagi data dalam kueri menjadi dua bagian: data dasar dan tambahan, dan membacanya masing-masing menggunakan metode di atas.。
Untuk memverifikasi ide pengoptimalan ini, kami lulus EXPLAIN pernyataan untuk melihat berapa banyak data dasar dan data tambahan yang ada dalam kueri di bawah ini. Untuk tabel COW, seluruh 101 pecahan data adalah data dasar (hudiNativeReadSplits=101/101 ), sehingga seluruh tabel COW dapat dibaca langsung melalui Doris Parket Reader, sehingga dapat diperoleh performa query terbaik. Untuk tabel ROW, sebagian besar pecahan datanya adalah data dasar (hudiNativeReadSplits=100/101), jumlah pecahan adalah data tambahan, dan pada dasarnya dapat mencapai kinerja kueri yang lebih baik.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Anda dapat melakukan beberapa operasi penghapusan melalui Spark untuk mengamati lebih lanjut perubahan pada data dasar Hudi dan data tambahan:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Selain itu, partisi juga dapat dilakukan melalui kondisi partisi untuk lebih mengurangi jumlah data dan meningkatkan kecepatan kueri.Pada contoh berikut, melalui kondisi partisic_nationkey = 15 Lakukan pengurangan partisi sehingga permintaan query hanya perlu mengakses satu partisi (partition=1/26) data.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Di atas adalah panduan terperinci untuk dengan cepat membangun lingkungan pengujian/demo berdasarkan Apache Doris dan Apache Hudi. Di masa mendatang, kami juga akan meluncurkan serangkaian panduan untuk membangun arsitektur lake dan gudang terintegrasi dengan Apache Doris dan berbagai data lake arus utama. format dan sistem penyimpanan, termasuk Iceberg, Paimon, OSS, Delta Lake, dll., dipersilakan untuk terus memperhatikan.

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang. Semua orang memeriksanya

Surat[email protected]