
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
작가:셀렉트DB 기술팀
소개: Data Lakehouse는 데이터 웨어하우스의 고성능 및 실시간 성능과 데이터 레이크의 저렴한 비용 및 유연성을 결합하여 사용자가 다양한 데이터 처리 및 분석 요구를 보다 편리하게 충족할 수 있도록 지원합니다. 과거의 여러 버전에서 Apache Doris는 데이터 레이크와의 통합을 계속 심화하여 성숙한 통합 레이크 및 웨어하우스 솔루션으로 발전했습니다. 사용자가 빠르게 시작할 수 있도록 Hudi, Iceberg, Paimon, OSS, Delta Lake를 포함한 일련의 기사를 통해 Apache Doris 및 다양한 주류 데이터 레이크 형식 및 스토리지 시스템에 대한 레이크 및 웨어하우스 통합 아키텍처 구축 가이드를 소개합니다. , Kudu, BigQuery 등 계속 지켜봐 주시기 바랍니다.
새로운 개방형 데이터 관리 아키텍처인 Data Lakehouse는 데이터 웨어하우스의 고성능 및 실시간 성능과 데이터 레이크의 저렴한 비용 및 유연성을 결합하여 사용자가 다양한 데이터 요구 사항을 보다 편리하게 충족할 수 있도록 지원합니다. 엔터프라이즈 빅데이터 시스템에서.
지난 여러 버전에 걸쳐,아파치 도리스 데이터 레이크와의 통합을 계속해서 심화시켜 이제는 성숙한 통합 레이크 및 웨어하우스 솔루션으로 발전했습니다.
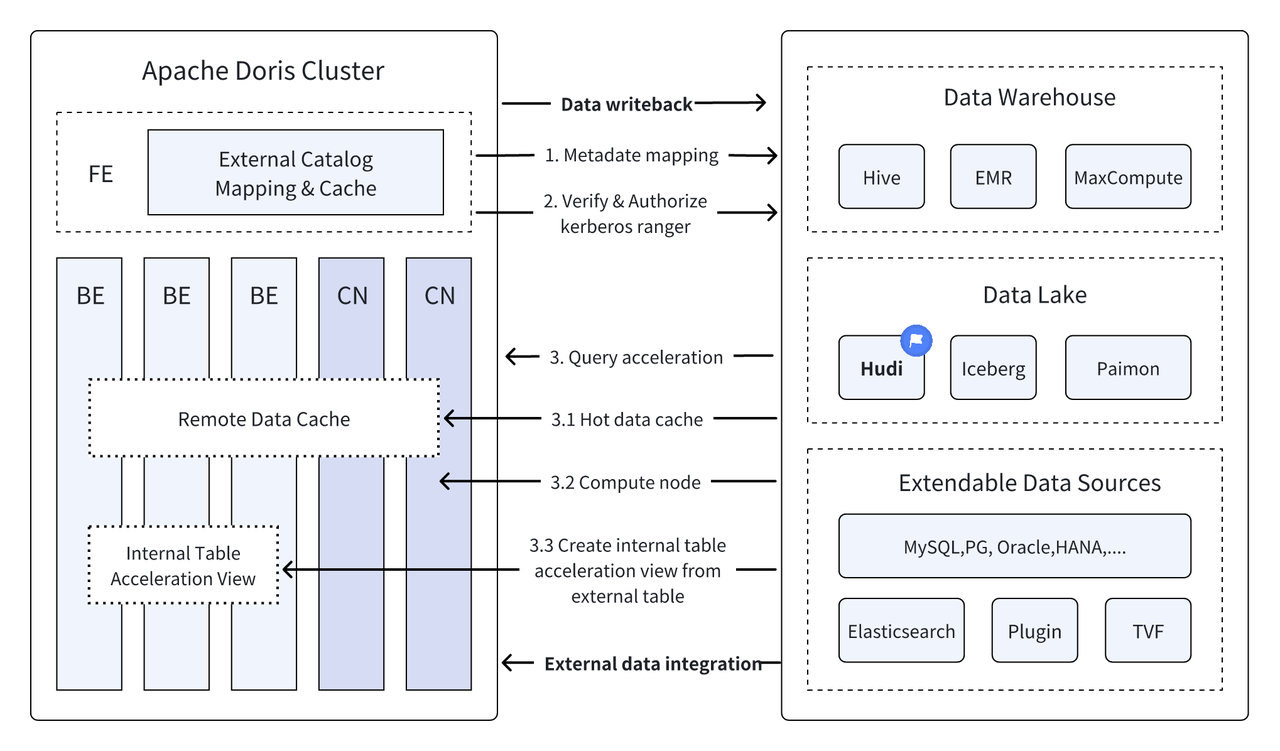
아파치 후디 현재 가장 주류를 이루는 개방형 데이터 레이크 형식 중 하나이며 Apache Doris를 포함한 다양한 주류 쿼리 엔진을 지원하는 트랜잭션 데이터 레이크 관리 플랫폼입니다.아파치 도리스 Apache Hudi 데이터 테이블의 읽기 기능도 향상되었습니다.
- 쓰기 테이블에서 복사: 스냅샷 쿼리
- 읽기 테이블에서 병합: 스냅샷 쿼리, 읽기 최적화 쿼리
- 시간 여행 지원
- 증분 읽기 지원
Apache Doris의 고성능 쿼리 실행과 Apache Hudi의 실시간 데이터 관리 기능을 통해 효율적이고 유연하며 저렴한 데이터 쿼리 및 분석이 가능하며 강력한 데이터 역추적, 감사 및 증분 처리도 제공합니다. 현재 Apache 기반 Doris와 Apache Hudi의 조합은 여러 커뮤니티 사용자에 의해 실제 비즈니스 시나리오에서 검증되고 홍보되었습니다.
실시간 데이터 분석 및 처리 : 금융업계의 거래 분석, 광고업계의 실시간 클릭스트림 분석, 전자상거래 업계의 사용자 행동 분석 등 일반적인 시나리오에는 모두 실시간 데이터 업데이트와 쿼리 분석이 필요합니다. Hudi는 데이터의 실시간 업데이트 및 관리를 실현하고 데이터 일관성과 신뢰성을 보장할 수 있습니다. Doris는 실시간으로 대규모 데이터 쿼리 요청을 효율적으로 처리할 수 있으며 이 두 가지의 조합은 실시간 데이터 분석 및 처리 요구 사항을 완벽하게 충족할 수 있습니다. .
데이터 역추적 및 감사 : 데이터 보안 및 정확성에 대한 요구 사항이 매우 높은 금융, 의료 등의 산업에서는 데이터 역추적 및 감사가 매우 중요한 기능입니다. Hudi는 사용자가 과거 데이터 상태를 볼 수 있는 시간 여행 기능을 제공합니다. Apache Doris의 효율적인 쿼리 기능과 결합되어 언제든지 데이터를 신속하게 검색하고 분석하여 정확한 역추적 및 감사를 달성할 수 있습니다.
증분 데이터 읽기 및 분석: 빅데이터 분석을 수행할 때 데이터 규모가 크고 업데이트가 자주 발생하는 문제에 직면하는 경우가 많습니다. Hudi는 사용자가 전체 데이터를 동시에 업데이트하지 않고 변화하는 데이터만 처리할 수 있는 증분 데이터 읽기를 지원합니다. , Apache Doris의 증분 읽기 기능은 이 프로세스를 더욱 효율적으로 만들어 데이터 처리 및 분석의 효율성을 크게 향상시킬 수 있습니다.
데이터 소스 전반에 걸친 통합 쿼리 : 많은 기업 데이터 소스는 복잡하며 데이터가 다른 데이터베이스에 저장될 수 있습니다. Doris의 다중 카탈로그 기능은 여러 데이터 소스의 자동 매핑 및 동기화를 지원하고 데이터 소스 전반에 걸쳐 통합 쿼리를 지원합니다. 분석을 위해 여러 데이터 소스에서 데이터를 얻고 통합해야 하는 기업의 경우 이는 데이터 흐름 경로를 크게 단축하고 작업 효율성을 향상시킵니다.
이 기사에서는 Docker 환경에서 Apache Doris + Apache Hudi에 대한 테스트 및 데모 환경을 빠르게 구축하는 방법을 독자에게 소개하고 독자가 빠르게 시작할 수 있도록 각 기능의 작동을 보여줍니다.
이 기사에 관련된 모든 스크립트와 코드는 다음 주소에서 얻을 수 있습니다.https://github.com/apache/doris/tree/master/samples/datalake/hudi
이 문서의 예제는 Docker Compose를 사용하여 배포됩니다. 구성 요소 및 버전 번호는 다음과 같습니다.

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
다음으로 Spark를 통해 Hudi 데이터를 생성합니다.아래 코드에서 볼 수 있듯이 클러스터에는 이미 다음과 같은 카드가 포함되어 있습니다.customer Hive 테이블, 이 Hive 테이블을 통해 Hudi 테이블을 생성할 수 있습니다.
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
아래와 같이 파일 이름이 hudi 카탈로그(다음을 통해 이용 가능)HOW CATALOGS 확인하다). 다음은 카탈로그 생성 설명입니다.
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 이미 존재하는 데이터, 즉 기존 데이터를 덮어쓰는 경우:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Incremental Read는 Hudi가 제공하는 기능 중 하나입니다. Incremental Read를 통해 사용자는 지정된 시간 범위의 증분 데이터를 얻어 데이터의 증분 처리를 달성할 수 있습니다.이를 위해 Doris는 다음을 삽입할 수 있습니다.c_custkey=100 후속 변경 데이터를 쿼리합니다.아래와 같이c_custkey=32자료:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris는 지정된 스냅샷 버전의 Hudi 데이터 쿼리를 지원하여 데이터의 시간 여행 기능을 실현합니다. 먼저 Spark를 통해 두 Hudi 테이블의 제출 기록을 쿼리할 수 있습니다.
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
그러면 Doris를 통해 실행될 수 있다. c_custkey=32 , 데이터가 삽입되기 전에 데이터 스냅샷을 쿼리합니다.아래에서 볼 수 있듯이c_custkey=32 데이터가 아직 업데이트되지 않았습니다.
참고: 시간 여행 구문은 현재 새로운 최적화 프로그램을 지원하지 않으며 먼저 실행되어야 합니다.
set enable_nereids_planner=false;새 최적화 프로그램을 끄십시오. 이 문제는 후속 버전에서 수정될 것입니다.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Apache Hudi의 데이터는 대략 기준 데이터와 증분 데이터라는 두 가지 범주로 나눌 수 있습니다. 기본 데이터는 일반적으로 병합된 Parquet 파일인 반면, 증분 데이터는 INSERT, UPDATE 또는 DELETE에 의해 생성된 데이터 증분을 나타냅니다. Baseline 데이터는 직접 읽어올 수 있고, Incremental 데이터는 Merge on Read를 통해 읽어야 합니다.
Hudi COW 테이블 쿼리 또는 MOR 테이블 읽기 최적화 쿼리의 경우 데이터는 기준 데이터이며 Doris의 기본 Parquet Reader를 통해 데이터 파일을 직접 읽을 수 있으며 매우 빠른 쿼리 응답을 얻을 수 있습니다. 증분 데이터의 경우 Doris는 액세스를 위해 JNI를 통해 Hudi의 Java SDK를 호출해야 합니다.최적의 쿼리 성능을 달성하기 위해 Apache Doris는 쿼리의 데이터를 기준 데이터와 증분 데이터의 두 부분으로 나누고 각각 위의 방법을 사용하여 읽습니다.。
이 최적화 아이디어를 검증하기 위해 우리는 통과했습니다. EXPLAIN 아래 쿼리에 기준 데이터와 증분 데이터가 얼마나 있는지 확인하는 명령문입니다. COW 테이블의 경우 101개 데이터 샤드 모두 기준 데이터(hudiNativeReadSplits=101/101 )이므로 모든 COW 테이블을 Doris Parquet Reader를 통해 직접 읽을 수 있어 최고의 쿼리 성능을 얻을 수 있습니다. ROW 테이블의 경우 대부분의 데이터 샤드는 기준 데이터(hudiNativeReadSplits=100/101), 샤드 수는 증분 데이터이며 기본적으로 더 나은 쿼리 성능을 얻을 수 있습니다.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Spark를 통해 일부 삭제 작업을 수행하여 Hudi 기준 데이터 및 증분 데이터의 변경 사항을 추가로 관찰할 수 있습니다.
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
또한, 파티셔닝 조건을 통해 파티셔닝을 수행하여 데이터 양을 더욱 줄이고 쿼리 속도를 향상시킬 수도 있습니다.다음 예에서는 파티션 조건을 통해c_nationkey = 15 쿼리 요청이 하나의 파티션(partition=1/26) 데이터.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
위 내용은 Apache Doris 및 Apache Hudi를 기반으로 테스트/데모 환경을 신속하게 구축하기 위한 자세한 가이드입니다. 향후에는 Apache Doris 및 다양한 주류 데이터 레이크를 사용하여 통합 레이크 및 웨어하우스 아키텍처를 구축하기 위한 가이드 시리즈도 출시할 예정입니다. Iceberg, Paimon, OSS, Delta Lake 등을 포함한 형식 및 스토리지 시스템에 계속해서 관심을 가져주시기 바랍니다.

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com