2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
author:SelectDB Technical Team
Introduction: Data Lakehouse combines the high performance and real-time performance of data warehouses with the low cost and flexibility of data lakes, helping users to more conveniently meet various data processing and analysis needs. In the past versions, Apache Doris has continued to deepen its integration with data lakes and has evolved into a mature lakehouse solution. To help users get started quickly, we will introduce a series of articles to build a lakehouse architecture for Apache Doris and various mainstream data lake formats and storage systems, including Hudi, Iceberg, Paimon, OSS, Delta Lake, Kudu, BigQuery, etc. Please continue to pay attention.
As a new open data management architecture, Data Lakehouse combines the high performance and real-time performance of a data warehouse with the low cost and flexibility of a data lake, helping users to more conveniently meet various data processing and analysis needs. It has been increasingly used in the big data systems of enterprises.
In the past versions,Apache Doris We continue to deepen our integration with the data lake, and have now evolved into a mature lake-warehouse integrated solution.
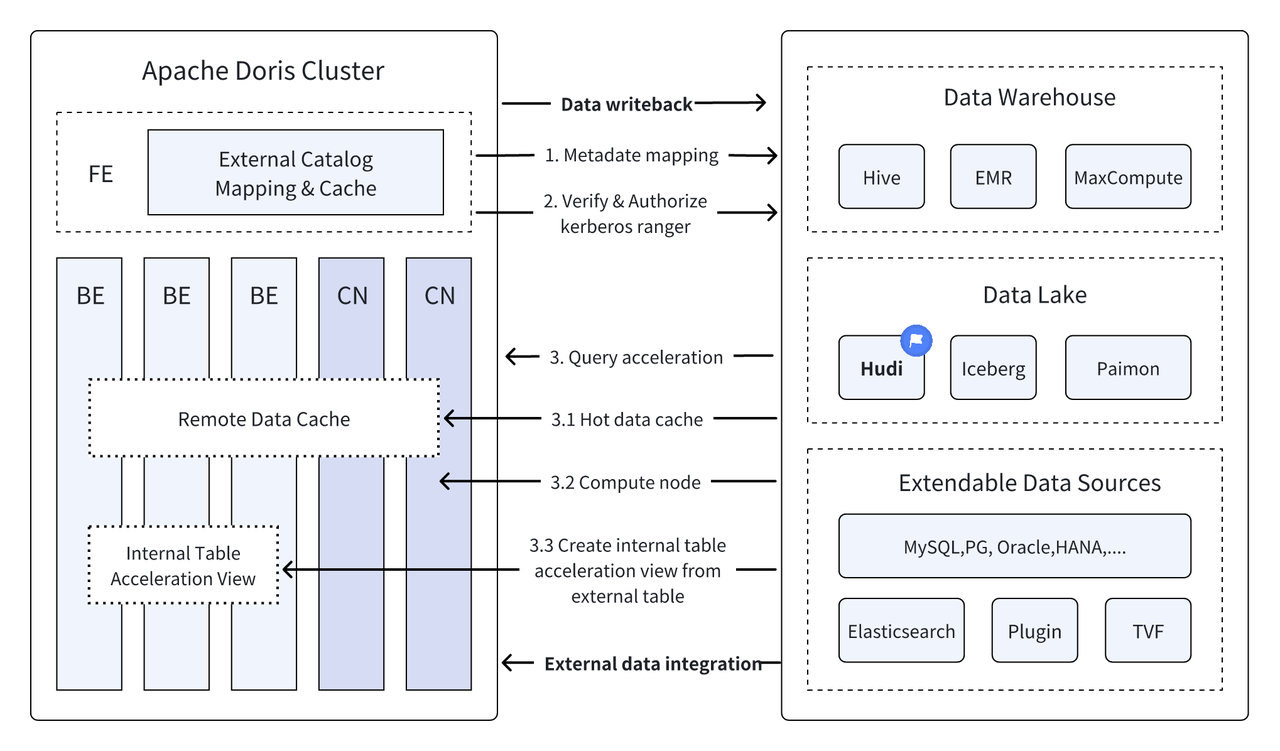
Apache Hudi It is one of the most mainstream open data lake formats and a transactional data lake management platform that supports multiple mainstream query engines including Apache Doris.Apache Doris The reading capability of Apache Hudi data tables has also been enhanced:
- Copy on Write Table: Snapshot Query
- Merge on Read Table:Snapshot Queries, Read Optimized Queries
- Support Time Travel
- Support Incremental Read
With the high-performance query execution of Apache Doris and the real-time data management capabilities of Apache Hudi, efficient, flexible and low-cost data query and analysis can be achieved. It also provides powerful data backtracking, auditing and incremental processing functions. The current combination of Apache Doris and Apache Hudi has been verified and promoted in the real business scenarios of multiple community users:
Real-time data analysis and processing:For example, in common scenarios such as financial industry transaction analysis, advertising industry real-time clickstream analysis, and e-commerce industry user behavior analysis, real-time data update and query analysis are required. Hudi can achieve real-time update and management of data and ensure data consistency and reliability, while Doris can process large-scale data query requests in real time and efficiently. The combination of the two can fully meet the needs of real-time data analysis and processing.
Data backtracking and auditing:For industries such as finance and healthcare that have extremely high requirements for data security and accuracy, data backtracking and auditing are very important functions. Hudi provides a time travel function that allows users to view the status of historical data. Combined with the efficient query capabilities of Apache Doris, it can quickly find and analyze data at any time point to achieve accurate backtracking and auditing.
Incremental data reading and analysis:When conducting big data analysis, we often face the problems of large data scale and frequent updates. Hudi supports incremental data reading, which allows users to only process changed data without having to update the entire data. At the same time, Apache Doris's Incremental Read function can also make this process more efficient, significantly improving the efficiency of data processing and analysis.
Federated query across data sources:Many enterprises have complex data sources, and data may be stored in different databases. Doris's Multi-Catalog function supports automatic mapping and synchronization of multiple data sources, and supports federated queries across data sources. This greatly shortens the data flow path and improves work efficiency for enterprises that need to obtain and integrate data from multiple data sources for analysis.
This article will introduce how to quickly build a test and demonstration environment for Apache Doris + Apache Hudi in a Docker environment, and demonstrate the operation of each function to help readers get started quickly.
All scripts and codes involved in this article can be obtained from this address:https://github.com/apache/doris/tree/master/samples/datalake/hudi
This article uses Docker Compose for deployment. The components and version numbers are as follows:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Next, we will use Spark to generate Hudi data. As shown in the code below, the cluster already contains a table called customer A Hive table can be used to create a Hudi table:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
As shown below, a cluster named hudi Catalog (available throughHOW CATALOGS View). The following is the creation statement of the Catalog:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Existing data, that is, overwriting existing data:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Incremental Read is one of the features provided by Hudi. Through Incremental Read, users can obtain incremental data within a specified time range, thereby realizing incremental processing of data.c_custkey=100As shown below, we inserted ac_custkey=32The data:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris supports querying Hudi data of a specified snapshot version, thereby realizing the Time Travel function of the data. First, you can query the submission history of two Hudi tables through Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Then, you can execute it through Doris c_custkey=32 , query the data snapshot before data insertion. As shown belowc_custkey=32 Data has not been updated yet:
Note: Time Travel syntax does not yet support the new optimizer. You need to execute
set enable_nereids_planner=false;Disable the new optimizer. This issue will be fixed in subsequent versions.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
The data in Apache Hudi can be roughly divided into two categories: baseline data and incremental data. Baseline data is usually a merged Parquet file, while incremental data refers to the data increment generated by INSERT, UPDATE or DELETE. Baseline data can be read directly, while incremental data needs to be read through Merge on Read.
For queries on Hudi COW tables or Read Optimized queries on MOR tables, the data is baseline data, and the data files can be directly read through Doris' native Parquet Reader, and extremely fast query responses can be obtained. For incremental data, Doris needs to call Hudi's Java SDK through JNI to access it.In order to achieve the best query performance, Apache Doris will divide the data in a query into two parts: baseline and incremental data, and read them separately using the above methods.。
To verify this optimization idea, we EXPLAIN To see how much baseline data and incremental data there are in a query like the one below, use the following statement. For a COW table, all 101 data shards are baseline data (hudiNativeReadSplits=101/101), so all COW tables can be read directly through Doris Parquet Reader, so the best query performance can be achieved. For ROW tables, most data shards are baseline data (hudiNativeReadSplits=100/101), one shard number is incremental data, which can basically achieve good query performance.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
You can perform some deletion operations through Spark to further observe the changes in Hudi baseline data and incremental data:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
In addition, partition pruning can be performed by partition conditions to further reduce the amount of data and improve query speed.c_nationkey = 15 Perform partition pruning so that query requests only need to access one partition (partition=1/26) data.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
The above is a detailed guide for quickly building a test/demonstration environment based on Apache Doris and Apache Hudi. In the future, we will also launch a series of guides for building a lake-warehouse integrated architecture with Apache Doris and various mainstream data lake formats and storage systems, including Iceberg, Paimon, OSS, Delta Lake, etc. Please continue to pay attention.

I have devoted myself to the research of technology for more than 30 years. I am proficient in various languages such as Java, Linux, JavaScript, PHP, CSS, etc. I have made many contributions in the field of open source. I have established a developer documentation site to share some problems in technology development for everyone to read.

