
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
автор:SelectDB Техническая команда
Введение: Data Lakehouse сочетает в себе высокую производительность и производительность хранилища данных в режиме реального времени с низкой стоимостью и гибкостью озера данных, что помогает пользователям более удобно удовлетворять различные потребности в обработке и анализе данных. В предыдущих нескольких версиях Apache Doris продолжал углублять свою интеграцию с озером данных и превратился в зрелое интегрированное решение для озера и хранилища. Чтобы помочь пользователям быстро приступить к работе, мы представим руководство по построению интегрированной архитектуры озер и хранилищ для Apache Doris и различных основных форматов озер данных и систем хранения в серии статей, включая Hudi, Iceberg, Paimon, OSS, Delta Lake. , Kudu, BigQuery и т. д. Добро пожаловать, следите за обновлениями.
Являясь новой открытой архитектурой управления данными, Data Lakehouse сочетает в себе высокую производительность и производительность хранилищ данных в режиме реального времени с низкой стоимостью и гибкостью озер данных, помогая пользователям более удобно удовлетворять различные потребности в данных. Спрос на анализ обработки данных используется все чаще. в корпоративных системах больших данных.
За последние несколько версийАпач Дорис Оно продолжает углублять интеграцию с озером данных и теперь превратилось в зрелое интегрированное решение для озера и хранилища.
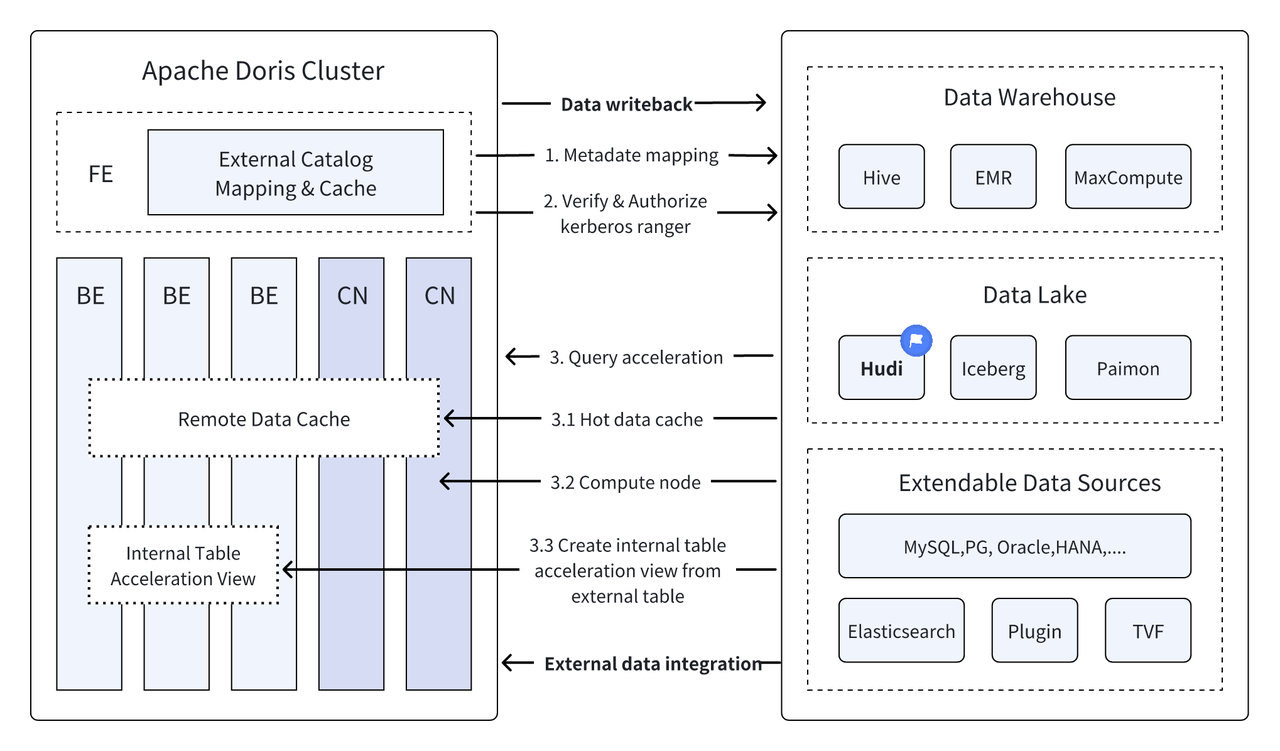
Апачи Худи В настоящее время это один из наиболее распространенных форматов открытых озер данных и платформа управления озером транзакционных данных, которая поддерживает множество основных механизмов запросов, включая Apache Doris.Апач Дорис Также были улучшены возможности чтения таблиц данных Apache Hudi:
- Копировать при записи таблицы: Запрос моментального снимка
- Объединение при чтении таблицы: запросы моментальных снимков, оптимизированные запросы чтения
- Поддержка путешествий во времени
- Поддержка добавочного чтения
Благодаря высокопроизводительному выполнению запросов Apache Doris и возможностям управления данными в реальном времени Apache Hudi можно обеспечить эффективный, гибкий и недорогой запрос и анализ данных. Он также обеспечивает мощный обратный поиск данных, аудит и инкрементную обработку. Функции в настоящее время основаны на Apache. Комбинация Doris и Apache Hudi была проверена и продвинута в реальных бизнес-сценариях несколькими пользователями сообщества:
Анализ и обработка данных в режиме реального времени : Общие сценарии, такие как анализ транзакций в финансовой отрасли, анализ потока кликов в реальном времени в рекламной индустрии и анализ поведения пользователей в индустрии электронной коммерции, требуют обновления данных в реальном времени и анализа запросов. Hudi может осуществлять обновление и управление данными в режиме реального времени, а также обеспечивать согласованность и надежность данных. Doris может эффективно обрабатывать крупномасштабные запросы к данным в режиме реального времени. Сочетание этих двух функций может полностью удовлетворить потребности в анализе и обработке данных в реальном времени. .
Отслеживание и аудит данных : Для таких отраслей, как финансы и здравоохранение, где предъявляются чрезвычайно высокие требования к безопасности и точности данных, возврат данных и аудит являются очень важными функциями. Hudi предоставляет функцию перемещения во времени, которая позволяет пользователям просматривать состояние исторических данных. В сочетании с эффективными возможностями запросов Apache Doris он может быстро искать и анализировать данные в любой момент времени для достижения точного обратного отслеживания и аудита.
Инкрементное чтение и анализ данных: При проведении анализа больших данных мы часто сталкиваемся с проблемами большого масштаба данных и частых обновлений. Hudi поддерживает инкрементальное чтение данных, что позволяет пользователям обрабатывать только изменяющиеся данные без необходимости одновременного обновления всего объема данных; Функции инкрементального чтения Apache Doris также могут сделать этот процесс более эффективным, значительно повышая эффективность обработки и анализа данных.
Федеративные запросы к источникам данных : Многие источники корпоративных данных сложны, и данные могут храниться в разных базах данных. Функция мультикаталога Doris поддерживает автоматическое сопоставление и синхронизацию нескольких источников данных, а также поддерживает объединенные запросы между источниками данных. Для предприятий, которым необходимо получать и интегрировать данные из нескольких источников данных для анализа, это значительно сокращает путь потока данных и повышает эффективность работы.
Эта статья познакомит читателей с тем, как быстро создать тестовую и демонстрационную среду для Apache Doris + Apache Hudi в среде Docker, а также продемонстрирует работу каждой функции, чтобы помочь читателям быстро приступить к работе.
Все скрипты и код, задействованные в этой статье, можно получить по этому адресу:https://github.com/apache/doris/tree/master/samples/datalake/hudi
Пример в этой статье развертывается с помощью Docker Compose. Компоненты и номера версий следующие:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Затем сгенерируйте данные Hudi через Spark.Как показано в коде ниже, кластер уже содержит карту с именемcustomer Таблицу Hive, вы можете создать таблицу Hudi с помощью этой таблицы Hive:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Как показано ниже, файл с именем hudi Каталог (доступен черезHOW CATALOGS Проверять). Ниже приводится заявление о создании каталога:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Уже существующие данные, то есть перезапись существующих данных:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Инкрементное чтение — это одна из функциональных функций, предоставляемых Hudi. С помощью инкрементального чтения пользователи могут получать инкрементные данные в указанном диапазоне времени, тем самым обеспечивая инкрементную обработку данных.Для этого Дорис может вставитьc_custkey=100 Запросите данные последующих изменений.Как показано ниже, мы вставилиc_custkey=32Данные:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris поддерживает запрос данных Hudi указанной версии снимка, тем самым реализуя функцию перемещения данных во времени. Во-первых, вы можете запросить историю отправки двух таблиц Hudi через Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Затем его можно выполнить через Дорис. c_custkey=32 , запросите снимок данных перед вставкой данных.Как вы можете видеть нижеc_custkey=32 Данные еще не обновлены:
Примечание. Синтаксис Time Travel в настоящее время не поддерживает новый оптимизатор, и его необходимо выполнить в первую очередь.
set enable_nereids_planner=false;Отключите новый оптимизатор, в последующих версиях эта проблема будет исправлена.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Данные в Apache Hudi можно условно разделить на две категории: базовые данные и дополнительные данные. Базовые данные обычно представляют собой объединенный файл Parquet, а инкрементные данные относятся к приращению данных, созданному с помощью INSERT, UPDATE или DELETE. Базовые данные можно считывать напрямую, а дополнительные данные необходимо считывать посредством слияния при чтении.
Для запросов к таблицам Hudi COW или запросов, оптимизированных для чтения таблиц MOR, данные представляют собой базовые данные, а файлы данных можно считывать непосредственно через встроенное средство чтения паркета Doris, что позволяет получить чрезвычайно быстрые ответы на запросы. Для получения дополнительных данных Дорис необходимо вызвать Java SDK Hudi через JNI для доступа.Чтобы добиться оптимальной производительности запросов, Apache Doris разделит данные запроса на две части: базовые и инкрементальные данные и прочитает их, используя вышеуказанные методы соответственно.。
Чтобы проверить эту идею оптимизации, мы передали EXPLAIN оператор, чтобы увидеть, сколько базовых и дополнительных данных содержится в приведенном ниже запросе. Для таблицы COW все 101 сегмент данных являются базовыми данными (hudiNativeReadSplits=101/101 ), поэтому все таблицы COW можно читать непосредственно через Doris Parquet Reader, что позволяет добиться наилучшей производительности запросов. Для таблиц ROW большинство сегментов данных являются базовыми данными (hudiNativeReadSplits=100/101), количество сегментов представляет собой инкрементные данные, и это может в основном обеспечить лучшую производительность запросов.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Вы можете выполнить некоторые операции удаления через Spark, чтобы дополнительно наблюдать за изменениями в базовых и дополнительных данных Hudi:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Кроме того, секционирование также может выполняться с помощью условий секционирования, чтобы еще больше уменьшить объем данных и повысить скорость запросов.В следующем примере через условие разделаc_nationkey = 15 Выполните сокращение разделов, чтобы запросы запросов обращались только к одному разделу (partition=1/26) данные.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Выше приведено подробное руководство по быстрому созданию тестовой/демонстрационной среды на основе Apache Doris и Apache Hudi. В будущем мы также выпустим серию руководств по созданию интегрированной архитектуры озера и хранилища с использованием Apache Doris и различных основных озер данных. форматы и системы хранения, включая Iceberg, Paimon, OSS, Delta Lake и т. д., добро пожаловать на дальнейшее внимание.

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com