
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
συγγραφέας:Επιλέξτε DB Τεχνική ομάδα
Εισαγωγή: Το Data Lakehouse συνδυάζει την υψηλή απόδοση και την απόδοση σε πραγματικό χρόνο της αποθήκης δεδομένων με το χαμηλό κόστος και την ευελιξία της λίμνης δεδομένων για να βοηθήσει τους χρήστες να ανταποκριθούν πιο άνετα στις διάφορες ανάγκες επεξεργασίας και ανάλυσης δεδομένων. Στις προηγούμενες πολλαπλές εκδόσεις, το Apache Doris συνέχισε να εμβαθύνει την ενσωμάτωσή του με τη λίμνη δεδομένων και έχει εξελιχθεί σε μια ώριμη ολοκληρωμένη λύση λίμνης και αποθήκης. Για να διευκολύνουμε τους χρήστες να ξεκινήσουν γρήγορα, θα εισαγάγουμε τον οδηγό κατασκευής ολοκληρωμένης αρχιτεκτονικής λίμνης και αποθήκης για το Apache Doris και διάφορες κύριες μορφές λιμνών δεδομένων και συστήματα αποθήκευσης μέσω μιας σειράς άρθρων, όπως Hudi, Iceberg, Paimon, OSS, Delta Lake , Kudu, BigQuery, κ.λπ. Καλώς ήρθατε μείνετε συντονισμένοι.
Ως νέα αρχιτεκτονική ανοιχτής διαχείρισης δεδομένων, το Data Lakehouse συνδυάζει την υψηλή απόδοση και την απόδοση σε πραγματικό χρόνο των αποθηκών δεδομένων με το χαμηλό κόστος και την ευελιξία των λιμνών δεδομένων για να βοηθήσει τους χρήστες να ανταποκριθούν σε διάφορες ανάγκες δεδομένων. Η ζήτηση για ανάλυση επεξεργασίας χρησιμοποιείται όλο και περισσότερο σε εταιρικά συστήματα μεγάλων δεδομένων.
Κατά τις προηγούμενες πολλές εκδόσεις,Απάτσι Ντόρις Συνεχίζει να εμβαθύνει την ενσωμάτωσή του με τη λίμνη δεδομένων και έχει πλέον εξελιχθεί σε μια ώριμη ολοκληρωμένη λύση λίμνης και αποθήκης.
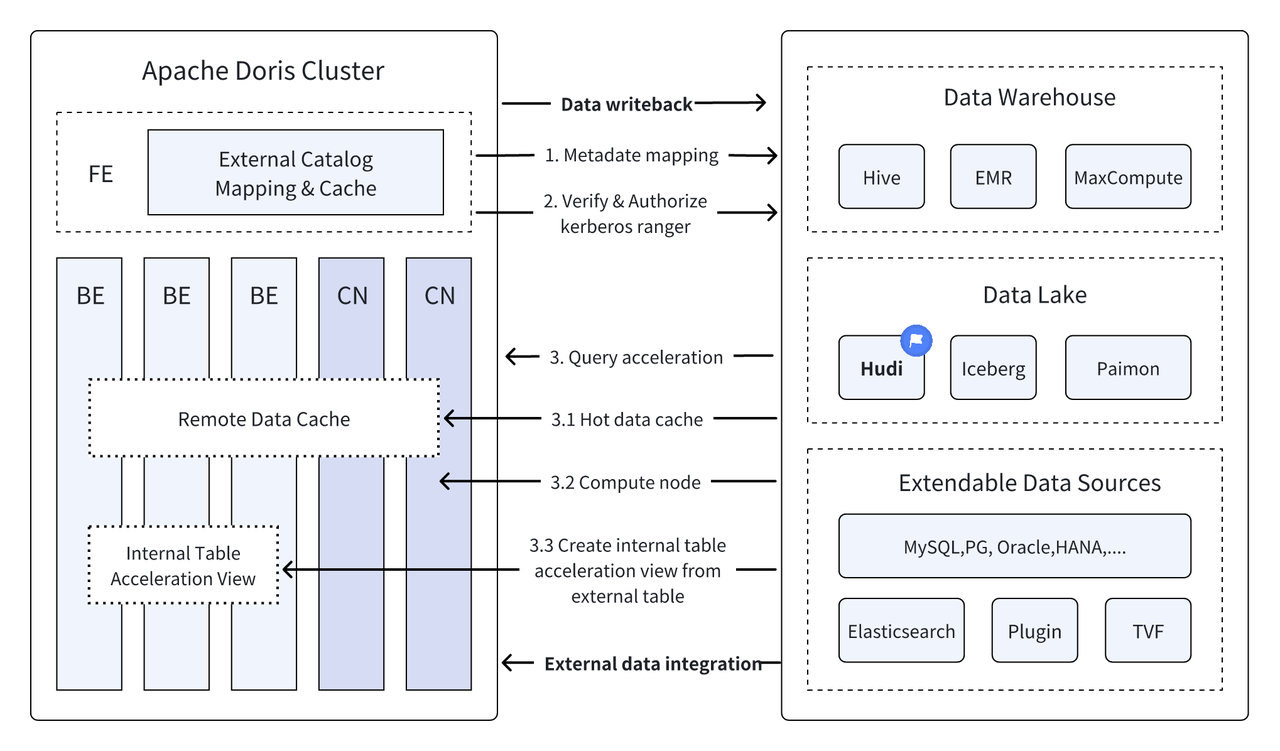
Απάτσι Χούντι Αυτήν τη στιγμή είναι μία από τις πιο συνηθισμένες μορφές ανοιχτών δεδομένων λίμνης και μια πλατφόρμα διαχείρισης λιμνών δεδομένων συναλλαγών που υποστηρίζει μια ποικιλία βασικών μηχανών αναζήτησης, συμπεριλαμβανομένου του Apache Doris.Απάτσι Ντόρις Οι δυνατότητες ανάγνωσης των πινάκων δεδομένων Apache Hudi έχουν επίσης βελτιωθεί:
- Αντιγραφή στον πίνακα εγγραφής: Ερώτημα στιγμιότυπου
- Συγχώνευση στο Read Table:Snapshot Queries, Read Optimized Queries
- Υποστήριξη Ταξίδι στο Χρόνο
- Υποστήριξη σταδιακής ανάγνωσης
Με την εκτέλεση ερωτημάτων υψηλής απόδοσης του Apache Doris και τις δυνατότητες διαχείρισης δεδομένων σε πραγματικό χρόνο του Apache Hudi, μπορεί να επιτευχθεί αποτελεσματική, ευέλικτη και χαμηλού κόστους αναζήτηση και ανάλυση δεδομένων λειτουργίες που βασίζονται επί του παρόντος στο Apache Ο συνδυασμός Doris και Apache Hudi έχει επαληθευτεί και προωθηθεί σε πραγματικά επιχειρηματικά σενάρια από πολλούς χρήστες της κοινότητας.
Ανάλυση και επεξεργασία δεδομένων σε πραγματικό χρόνο : Τα κοινά σενάρια όπως η ανάλυση συναλλαγών στον χρηματοπιστωτικό κλάδο, η ανάλυση ροής κλικ σε πραγματικό χρόνο στον κλάδο της διαφήμισης και η ανάλυση συμπεριφοράς των χρηστών στον κλάδο του ηλεκτρονικού εμπορίου απαιτούν ενημερώσεις δεδομένων σε πραγματικό χρόνο και ανάλυση ερωτημάτων. Η Hudi μπορεί να πραγματοποιήσει ενημέρωση και διαχείριση δεδομένων σε πραγματικό χρόνο και να εξασφαλίσει τη συνέπεια και την αξιοπιστία των δεδομένων .
Αναδρομή και έλεγχος δεδομένων : Για κλάδους όπως η χρηματοδότηση και η ιατρική περίθαλψη που έχουν εξαιρετικά υψηλές απαιτήσεις ασφάλειας και ακρίβειας δεδομένων, η αναδρομή δεδομένων και ο έλεγχος είναι πολύ σημαντικές λειτουργίες. Το Hudi παρέχει μια λειτουργία ταξιδιού στο χρόνο που επιτρέπει στους χρήστες να βλέπουν την κατάσταση των ιστορικών δεδομένων Σε συνδυασμό με τις αποτελεσματικές δυνατότητες ερωτημάτων του Apache Doris, μπορεί να αναζητήσει και να αναλύσει γρήγορα δεδομένα ανά πάσα στιγμή για να επιτύχει ακριβή backtracking και έλεγχο.
Αύξουσα ανάγνωση και ανάλυση δεδομένων: Κατά τη διεξαγωγή ανάλυσης μεγάλων δεδομένων, αντιμετωπίζουμε συχνά προβλήματα μεγάλης κλίμακας δεδομένων και συχνών ενημερώσεων, η οποία επιτρέπει στους χρήστες να επεξεργάζονται μόνο τα δεδομένα που αλλάζουν χωρίς να χρειάζεται να ενημερώνουν το σύνολο των δεδομένων , Οι συναρτήσεις αυξητικής ανάγνωσης του Apache Doris μπορούν επίσης να κάνουν αυτή τη διαδικασία πιο αποτελεσματική, βελτιώνοντας σημαντικά την αποτελεσματικότητα της επεξεργασίας και ανάλυσης δεδομένων.
Συνενωμένα ερωτήματα μεταξύ πηγών δεδομένων : Πολλές πηγές εταιρικών δεδομένων είναι πολύπλοκες και τα δεδομένα ενδέχεται να αποθηκευτούν σε διαφορετικές βάσεις δεδομένων. Η λειτουργία Multi-Catalog της Doris υποστηρίζει αυτόματη αντιστοίχιση και συγχρονισμό πολλαπλών πηγών δεδομένων και υποστηρίζει ενοποιημένα ερωτήματα μεταξύ των πηγών δεδομένων. Για τις επιχειρήσεις που πρέπει να αποκτήσουν και να ενσωματώσουν δεδομένα από πολλαπλές πηγές δεδομένων για ανάλυση, αυτό συντομεύει σημαντικά τη διαδρομή ροής δεδομένων και βελτιώνει την αποδοτικότητα της εργασίας.
Αυτό το άρθρο θα παρουσιάσει στους αναγνώστες πώς να δημιουργήσουν γρήγορα ένα περιβάλλον δοκιμής και επίδειξης για το Apache Doris + Apache Hudi σε περιβάλλον Docker και θα παρουσιάσει τη λειτουργία κάθε λειτουργίας για να βοηθήσουν τους αναγνώστες να ξεκινήσουν γρήγορα.
Όλα τα σενάρια και ο κώδικας που περιλαμβάνονται σε αυτό το άρθρο μπορούν να ληφθούν από αυτήν τη διεύθυνση:https://github.com/apache/doris/tree/master/samples/datalake/hudi
Το παράδειγμα σε αυτό το άρθρο αναπτύσσεται χρησιμοποιώντας το Docker Compose Τα στοιχεία και οι αριθμοί έκδοσης είναι οι εξής:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Στη συνέχεια, δημιουργήστε δεδομένα Hudi μέσω του Spark.Όπως φαίνεται στον παρακάτω κώδικα, το σύμπλεγμα περιέχει ήδη μια κάρτα με όνομαcustomer Hive table, μπορείτε να δημιουργήσετε έναν πίνακα Hudi μέσω αυτού του πίνακα Hive:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Όπως φαίνεται παρακάτω, ένα αρχείο με το όνομα hudi Κατάλογος (διαθέσιμος μέσωHOW CATALOGS Ελεγχος). Ακολουθεί η δήλωση δημιουργίας του Καταλόγου:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Ήδη υπάρχοντα δεδομένα, δηλαδή αντικατάσταση υπαρχόντων δεδομένων:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
Η επαυξητική ανάγνωση είναι μία από τις λειτουργικές δυνατότητες που παρέχει η Hudi Μέσω της Αύξουσας Ανάγνωσης, οι χρήστες μπορούν να αποκτήσουν στοιχειώδη δεδομένα σε ένα καθορισμένο χρονικό διάστημα, επιτυγχάνοντας έτσι σταδιακή επεξεργασία δεδομένων.Για αυτό, η Doris μπορεί να εισάγειc_custkey=100 Αναζητήστε τα δεδομένα της επακόλουθης αλλαγής.Όπως φαίνεται παρακάτω, εισάγαμε έναc_custkey=32Τα δεδομένα:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Η Doris υποστηρίζει την αναζήτηση των δεδομένων Hudi της καθορισμένης έκδοσης στιγμιότυπου, πραγματοποιώντας έτσι τη λειτουργία Ταξίδι στο χρόνο των δεδομένων. Αρχικά, μπορείτε να ρωτήσετε το ιστορικό υποβολής των δύο πινάκων Hudi μέσω του Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Στη συνέχεια, μπορεί να εκτελεστεί μέσω της Doris c_custkey=32 , υποβάλετε ερώτημα στο στιγμιότυπο δεδομένων πριν από την εισαγωγή των δεδομένων.Όπως μπορείτε να δείτε παρακάτωc_custkey=32 Τα δεδομένα δεν έχουν ενημερωθεί ακόμα:
Σημείωση: Η σύνταξη Time Travel δεν υποστηρίζει αυτήν τη στιγμή το νέο βελτιστοποιητή και πρέπει να εκτελεστεί πρώτα
set enable_nereids_planner=false;Απενεργοποιήστε το νέο βελτιστοποιητή, αυτό το πρόβλημα θα διορθωθεί σε επόμενες εκδόσεις.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Τα δεδομένα στο Apache Hudi μπορούν να χωριστούν χονδρικά σε δύο κατηγορίες - δεδομένα βάσης και αυξητικά δεδομένα. Τα δεδομένα βασικής γραμμής είναι συνήθως ένα συγχωνευμένο αρχείο Parquet, ενώ τα στοιχειώδη δεδομένα αναφέρονται στην αύξηση δεδομένων που δημιουργείται από INSERT, UPDATE ή DELETE. Τα δεδομένα βασικής γραμμής μπορούν να διαβαστούν απευθείας και τα αυξητικά δεδομένα πρέπει να διαβαστούν μέσω της συγχώνευσης σε ανάγνωση.
Για ερωτήματα πίνακα Hudi COW ή ερωτήματα πίνακα MOR Read Optimized, τα δεδομένα είναι δεδομένα βάσης και τα αρχεία δεδομένων μπορούν να διαβαστούν απευθείας μέσω του εγγενούς Parquet Reader της Doris και μπορούν να ληφθούν εξαιρετικά γρήγορες απαντήσεις ερωτημάτων. Για πρόσθετα δεδομένα, η Doris πρέπει να καλέσει το Java SDK του Hudi μέσω του JNI για πρόσβαση.Προκειμένου να επιτευχθεί η βέλτιστη απόδοση του ερωτήματος, το Apache Doris θα χωρίσει τα δεδομένα σε ένα ερώτημα σε δύο μέρη: τα δεδομένα βάσης και τα αυξητικά δεδομένα και θα τα διαβάσει χρησιμοποιώντας τις παραπάνω μεθόδους αντίστοιχα.。
Για να επαληθεύσουμε αυτήν την ιδέα βελτιστοποίησης, περάσαμε EXPLAIN δήλωση για να δείτε πόσα δεδομένα βάσης και αυξητικά δεδομένα υπάρχουν στο παρακάτω ερώτημα. Για τον πίνακα COW, και τα 101 θραύσματα δεδομένων είναι δεδομένα βάσης (hudiNativeReadSplits=101/101 ), ώστε όλοι οι πίνακες COW να μπορούν να διαβαστούν απευθείας μέσω του Doris Parquet Reader, ώστε να επιτυγχάνεται η καλύτερη απόδοση ερωτήματος. Για πίνακες ROW, τα περισσότερα θραύσματα δεδομένων είναι δεδομένα βάσης (hudiNativeReadSplits=100/101), ο αριθμός των θραυσμάτων είναι σταδιακά δεδομένα και μπορεί βασικά να επιτύχει καλύτερη απόδοση ερωτήματος.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Μπορείτε να εκτελέσετε ορισμένες λειτουργίες διαγραφής μέσω του Spark για να παρατηρήσετε περαιτέρω αλλαγές στα δεδομένα βάσης Hudi και στα αυξητικά δεδομένα:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Επιπλέον, η κατάτμηση μπορεί επίσης να πραγματοποιηθεί μέσω συνθηκών κατάτμησης για περαιτέρω μείωση της ποσότητας δεδομένων και βελτίωση της ταχύτητας ερωτημάτων.Στο παρακάτω παράδειγμα, μέσω της συνθήκης κατάτμησηςc_nationkey = 15 Πραγματοποιήστε μείωση διαμερισμάτων έτσι ώστε τα αιτήματα ερωτημάτων να χρειάζονται πρόσβαση μόνο σε ένα διαμέρισμα (partition=1/26) δεδομένα.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Το παραπάνω είναι ένας λεπτομερής οδηγός για τη γρήγορη δημιουργία ενός περιβάλλοντος δοκιμής/επίδειξης που βασίζεται στο Apache Doris και στο Apache Hudi Στο μέλλον, θα λανσάρουμε επίσης μια σειρά οδηγών για την κατασκευή μιας ολοκληρωμένης αρχιτεκτονικής λίμνης και αποθήκης με το Apache Doris και διάφορα mainstream lake δεδομένων. μορφές και συστήματα αποθήκευσης, συμπεριλαμβανομένων των Iceberg, Paimon, OSS, Delta Lake, κ.λπ., είναι ευπρόσδεκτα να συνεχίσουν να δίνουν προσοχή.

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα σταθμός τεκμηρίωσης προγραμματιστή για να μοιραστείτε ορισμένα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]