
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
autore:SelezionaDB Team tecnico
Introduzione: Data Lakehouse combina le prestazioni elevate e in tempo reale del data warehouse con il basso costo e la flessibilità del data Lake per aiutare gli utenti a soddisfare le varie esigenze di elaborazione e analisi dei dati in modo più conveniente. Nelle versioni precedenti, Apache Doris ha continuato ad approfondire la sua integrazione con il data Lake e si è evoluto in una soluzione matura e integrata di Lake e Warehouse. Per consentire agli utenti di iniziare rapidamente, introdurremo la guida alla costruzione dell'architettura integrata Lake e Warehouse per Apache Doris e vari formati di data Lake e sistemi di storage tradizionali attraverso una serie di articoli, tra cui Hudi, Iceberg, Paimon, OSS, Delta Lake , Kudu, BigQuery e così via. Benvenuto, resta sintonizzato.
Essendo una nuova architettura di gestione dei dati aperta, Data Lakehouse combina le prestazioni elevate e in tempo reale del data warehouse con il basso costo e la flessibilità del data Lake per aiutare gli utenti a soddisfare le varie esigenze di dati in modo più conveniente sempre più utilizzato nei sistemi di big data aziendali.
Nelle ultime versioni,Doris Apache Continua ad approfondire la sua integrazione con il data Lake e ora si è evoluto in una soluzione matura e integrata di Lake e Warehouse.
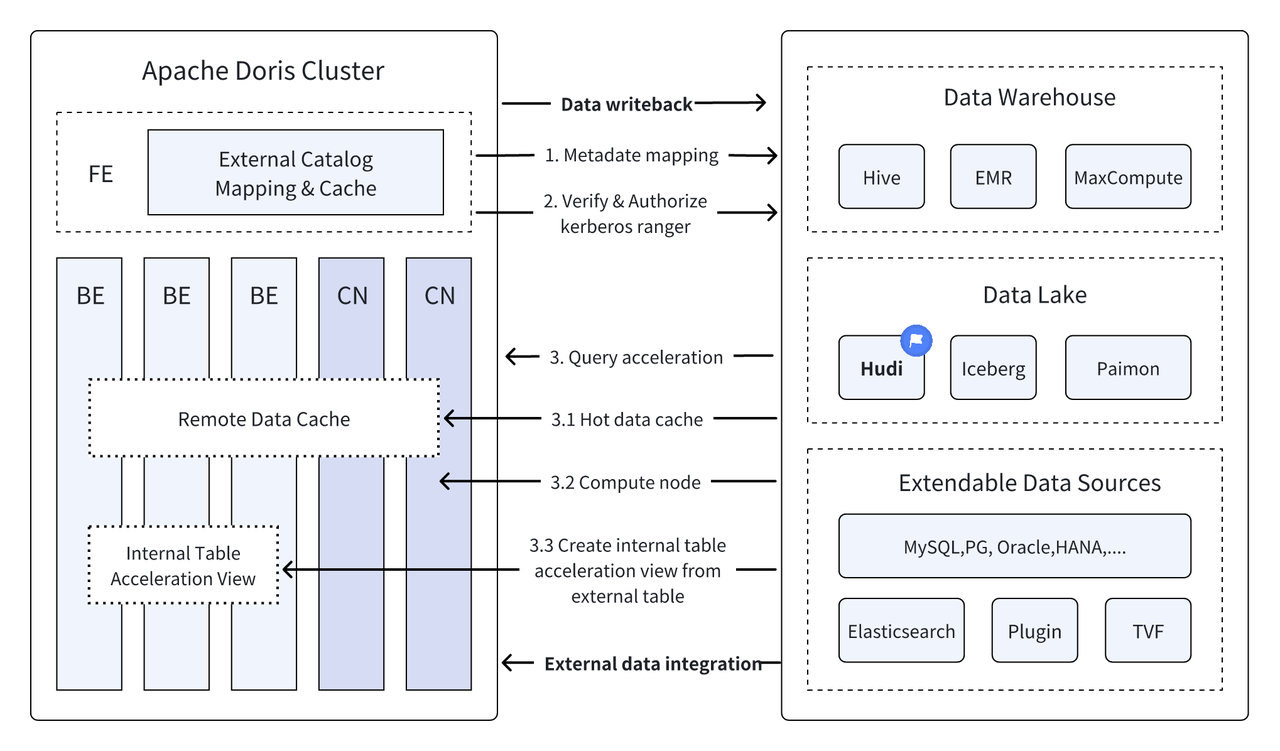
Apache Hudi Attualmente è uno dei formati di data Lake aperti più diffusi e una piattaforma di gestione di data Lake transazionale che supporta una varietà di motori di query tradizionali, tra cui Apache Doris.Doris Apache Sono state migliorate anche le capacità di lettura delle tabelle dati di Apache Hudi:
- Copia sulla tabella di scrittura: query snapshot
- Unione in lettura tabella: query snapshot, query di lettura ottimizzate
- Supporta il viaggio nel tempo
- Supporta la lettura incrementale
Con l'esecuzione di query ad alte prestazioni di Apache Doris e le funzionalità di gestione dei dati in tempo reale di Apache Hudi, è possibile ottenere query e analisi dei dati efficienti, flessibili e a basso costo. Fornisce inoltre potenti backtracking, auditing ed elaborazione incrementale dei dati funzioni. Attualmente basato su Apache La combinazione di Doris e Apache Hudi è stata verificata e promossa in scenari aziendali reali da più utenti della comunità:
Analisi ed elaborazione dei dati in tempo reale : scenari comuni come l'analisi delle transazioni nel settore finanziario, l'analisi del flusso di clic in tempo reale nel settore pubblicitario e l'analisi del comportamento degli utenti nel settore dell'e-commerce richiedono tutti aggiornamenti dei dati in tempo reale e analisi delle query. Hudi può realizzare l'aggiornamento e la gestione dei dati in tempo reale e garantire la coerenza e l'affidabilità dei dati. Doris può gestire in modo efficiente richieste di query di dati su larga scala in tempo reale. La combinazione dei due può soddisfare pienamente le esigenze di analisi ed elaborazione dei dati in tempo reale .
Backtracking e auditing dei dati : Per settori come quello finanziario e medico che hanno requisiti estremamente elevati in termini di sicurezza e accuratezza dei dati, il backtracking e l'auditing dei dati sono funzioni molto importanti. Hudi fornisce una funzione di viaggio nel tempo che consente agli utenti di visualizzare lo stato dei dati storici. In combinazione con le efficienti capacità di query di Apache Doris, può cercare e analizzare rapidamente i dati in qualsiasi momento per ottenere backtracking e auditing accurati.
Lettura e analisi incrementale dei dati: Quando conduciamo analisi di big data, ci troviamo spesso di fronte ai problemi di grandi dimensioni di dati e aggiornamenti frequenti. Hudi supporta la lettura incrementale dei dati, che consente agli utenti di elaborare solo i dati che cambiano senza dover aggiornare l'intera quantità di dati allo stesso tempo , le funzioni di lettura incrementale di Apache Doris possono anche rendere questo processo più efficiente, migliorando significativamente l'efficienza dell'elaborazione e dell'analisi dei dati.
Query federate tra origini dati : molte origini dati aziendali sono complesse e i dati possono essere archiviati in database diversi. La funzione Multi-Catalog di Doris supporta la mappatura e la sincronizzazione automatiche di più origini dati e supporta query federate tra origini dati. Per le aziende che necessitano di ottenere e integrare dati da più origini dati per l'analisi, ciò riduce notevolmente il percorso del flusso di dati e migliora l'efficienza del lavoro.
Questo articolo introdurrà i lettori a come configurare rapidamente l'ambiente di test e dimostrazione di Apache Doris + Apache Hudi nell'ambiente Docker e dimostrerà il funzionamento di ciascuna funzione per aiutare i lettori a iniziare rapidamente.
Tutti gli script e il codice coinvolti in questo articolo possono essere ottenuti da questo indirizzo:https://github.com/apache/doris/tree/master/samples/datalake/hudi
L'esempio in questo articolo viene distribuito utilizzando Docker Compose. I componenti e i numeri di versione sono i seguenti:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Successivamente, genera dati Hudi tramite Spark.Come mostrato nel codice seguente, il cluster contiene già una carta denominatacustomer Tabella Hive, puoi creare una tabella Hudi tramite questa tabella Hive:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Come mostrato di seguito, un file denominato hudi Catalogo (disponibile tramiteHOW CATALOGS Controllo). Quella che segue è la dichiarazione di creazione del Catalogo:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Dati già esistenti, ovvero sovrascrittura dei dati esistenti:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
La lettura incrementale è una delle caratteristiche funzionali fornite da Hudi. Attraverso la lettura incrementale, gli utenti possono ottenere dati incrementali in un intervallo di tempo specificato, ottenendo così un'elaborazione incrementale dei dati.Per questo, Doris può inserirsic_custkey=100 Interrogare i dati di modifica successivi.Come mostrato di seguito, abbiamo inserito ac_custkey=32I dati:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris supporta l'interrogazione dei dati Hudi della versione dell'istantanea specificata, realizzando così la funzione di viaggio nel tempo dei dati. Innanzitutto, puoi interrogare la cronologia di invio delle due tabelle Hudi tramite Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Quindi, può essere eseguito tramite Doris c_custkey=32 , eseguire una query sullo snapshot dei dati prima che i dati vengano inseriti.Come puoi vedere qui sottoc_custkey=32 I dati non sono ancora stati aggiornati:
Nota: la sintassi Time Travel attualmente non supporta il nuovo ottimizzatore e deve essere eseguita prima
set enable_nereids_planner=false;Disattiva il nuovo ottimizzatore, questo problema verrà risolto nelle versioni successive.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
I dati in Apache Hudi possono essere suddivisi approssimativamente in due categorie: dati di base e dati incrementali. I dati di base sono solitamente un file Parquet unito, mentre i dati incrementali si riferiscono all'incremento dei dati generato da INSERT, UPDATE o DELETE. I dati di base possono essere letti direttamente, mentre i dati incrementali devono essere letti tramite Unisci in lettura.
Per le query sulla tabella Hudi COW o le query ottimizzate per la lettura della tabella MOR, i dati sono dati di base e i file di dati possono essere letti direttamente tramite Parquet Reader nativo di Doris e si possono ottenere risposte alle query estremamente rapide. Per i dati incrementali, Doris deve chiamare Java SDK di Hudi tramite JNI per accedervi.Per ottenere prestazioni ottimali delle query, Apache Doris dividerà i dati in una query in due parti: dati di base e incrementali e li leggerà utilizzando rispettivamente i metodi sopra indicati.。
Per verificare questa idea di ottimizzazione, siamo passati EXPLAIN per vedere quanti dati di base e dati incrementali sono presenti nella query seguente. Per la tabella COW, tutti i 101 frammenti di dati sono dati di base (hudiNativeReadSplits=101/101 ), quindi tutte le tabelle COW possono essere lette direttamente tramite Doris Parquet Reader, in modo da ottenere le migliori prestazioni di query. Per le tabelle ROW, la maggior parte dei frammenti di dati sono dati di base (hudiNativeReadSplits=100/101), il numero di partizioni è un dato incrementale e può sostanzialmente ottenere prestazioni di query migliori.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
È possibile eseguire alcune operazioni di eliminazione tramite Spark per osservare ulteriormente le modifiche nei dati di base Hudi e nei dati incrementali:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Inoltre, è possibile eseguire l'eliminazione delle partizioni tramite condizioni di partizione per ridurre ulteriormente la quantità di dati e migliorare la velocità delle query.Nell'esempio seguente, attraverso la condizione di partizionec_nationkey = 15 Eseguire la riduzione della partizione in modo che le richieste di query debbano accedere solo a una partizione (partition=1/26) dati.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Quanto sopra è una guida dettagliata per creare rapidamente un ambiente di test/demo basato su Apache Doris e Apache Hudi. In futuro, lanceremo anche una serie di guide per costruire un'architettura Lake e Warehouse integrata con Apache Doris e vari data Lake tradizionali. formati e sistemi di archiviazione, tra cui Iceberg, Paimon, OSS, Delta Lake, ecc., sono invitati a continuare a prestare attenzione.

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]