2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
auteur:SélectionnerDB Équipe technique
Introduction : Data Lakehouse combine les hautes performances et les performances en temps réel de l'entrepôt de données avec le faible coût et la flexibilité du lac de données pour aider les utilisateurs à répondre plus facilement aux divers besoins de traitement et d'analyse des données. Dans les différentes versions précédentes, Apache Doris a continué à approfondir son intégration avec le lac de données et a évolué vers une solution de lac et d'entrepôt intégrée mature. Afin de permettre aux utilisateurs de démarrer rapidement, nous présenterons le guide de construction d'architecture intégrée de lac et d'entrepôt pour Apache Doris et divers formats et systèmes de stockage de lac de données grand public à travers une série d'articles, notamment Hudi, Iceberg, Paimon, OSS, Delta Lake. , Kudu, BigQuery, etc. Bienvenue, restez à l'écoute.
En tant que nouvelle architecture ouverte de gestion des données, Data Lakehouse combine les hautes performances et les performances en temps réel des entrepôts de données avec le faible coût et la flexibilité des lacs de données pour aider les utilisateurs à répondre plus facilement aux divers besoins en matière de données. La demande d'analyse de traitement est de plus en plus utilisée. dans les systèmes Big Data d’entreprise.
Au cours des dernières versions,Apache Doris Il continue d’approfondir son intégration avec le lac de données et a désormais évolué vers une solution intégrée de lac et d’entrepôt mature.
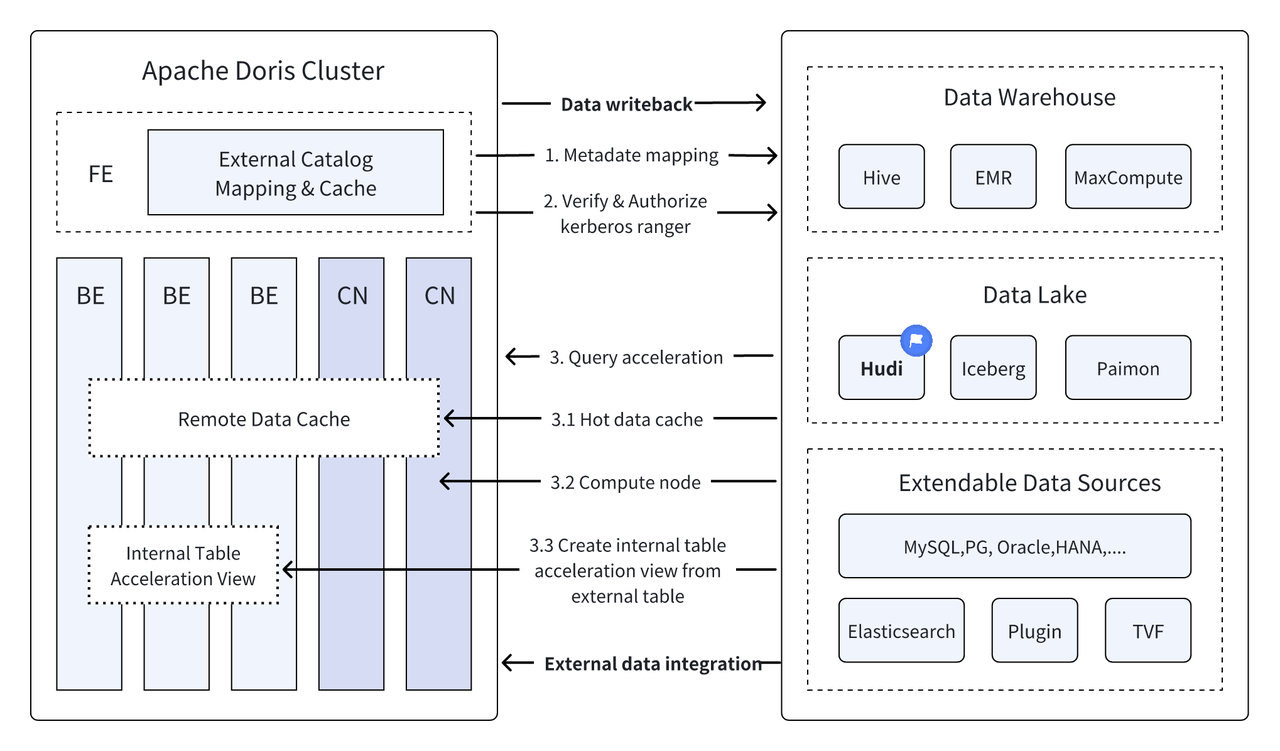
Apache Hudi Il s'agit actuellement de l'un des formats de lac de données ouverts les plus courants et d'une plate-forme de gestion de lac de données transactionnelle qui prend en charge une variété de moteurs de requêtes grand public, notamment Apache Doris.Apache Doris Les capacités de lecture des tables de données Apache Hudi ont également été améliorées :
- Copie sur table d'écriture : requête d'instantané
- Fusionner lors de la lecture de la table : requêtes instantanées, requêtes optimisées en lecture
- Voyage dans le temps
- Prise en charge de la lecture incrémentielle
Grâce à l'exécution de requêtes hautes performances d'Apache Doris et aux capacités de gestion des données en temps réel d'Apache Hudi, des requêtes et des analyses de données efficaces, flexibles et peu coûteuses peuvent être réalisées. Elles fournissent également de puissants retours en arrière, audit et traitement incrémentiel des données. fonctions Actuellement basé sur Apache La combinaison de Doris et Apache Hudi a été vérifiée et promue dans des scénarios commerciaux réels par plusieurs utilisateurs de la communauté :
Analyse et traitement des données en temps réel : Les scénarios courants tels que l'analyse des transactions dans le secteur financier, l'analyse des flux de clics en temps réel dans le secteur de la publicité et l'analyse du comportement des utilisateurs dans le secteur du commerce électronique nécessitent tous des mises à jour des données et une analyse des requêtes en temps réel. Hudi peut réaliser la mise à jour et la gestion des données en temps réel et garantir la cohérence et la fiabilité des données. Doris peut gérer efficacement les demandes de requêtes de données à grande échelle en temps réel. La combinaison des deux peut répondre pleinement aux besoins d'analyse et de traitement des données en temps réel. .
Backtracking et audit des données : Pour des secteurs tels que la finance et les soins médicaux, qui ont des exigences extrêmement élevées en matière de sécurité et d'exactitude des données, le backtracking et l'audit des données sont des fonctions très importantes. Hudi fournit une fonction de voyage dans le temps qui permet aux utilisateurs de visualiser l'état des données historiques. Associée aux capacités de requête efficaces d'Apache Doris, il peut rechercher et analyser rapidement les données à tout moment pour obtenir un retour en arrière et un audit précis.
Lecture et analyse incrémentielles de données: Lors de l'analyse de Big Data, nous sommes souvent confrontés aux problèmes de données à grande échelle et de mises à jour fréquentes. Hudi prend en charge la lecture incrémentielle des données, ce qui permet aux utilisateurs de traiter uniquement les données changeantes sans avoir à mettre à jour la totalité des données en même temps. , les fonctions de lecture incrémentielles d'Apache Doris peuvent également rendre ce processus plus efficace, améliorant ainsi considérablement l'efficacité du traitement et de l'analyse des données.
Requêtes fédérées sur plusieurs sources de données : De nombreuses sources de données d'entreprise sont complexes et les données peuvent être stockées dans différentes bases de données. La fonction Multi-Catalogue de Doris prend en charge le mappage et la synchronisation automatiques de plusieurs sources de données, ainsi que les requêtes fédérées entre les sources de données. Pour les entreprises qui ont besoin d'obtenir et d'intégrer des données provenant de plusieurs sources de données à des fins d'analyse, cela raccourcit considérablement le chemin du flux de données et améliore l'efficacité du travail.
Cet article expliquera aux lecteurs comment créer rapidement un environnement de test et de démonstration pour Apache Doris + Apache Hudi dans un environnement Docker, et démontrera le fonctionnement de chaque fonction pour aider les lecteurs à démarrer rapidement.
Tous les scripts et codes impliqués dans cet article peuvent être obtenus à partir de cette adresse :https://github.com/apache/doris/tree/master/samples/datalake/hudi
L'exemple de cet article est déployé à l'aide de Docker Compose. Les composants et les numéros de version sont les suivants :

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Ensuite, générez des données Hudi via Spark.Comme le montre le code ci-dessous, le cluster contient déjà une carte nomméecustomer Table Hive, vous pouvez créer une table Hudi via cette table Hive :
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Comme indiqué ci-dessous, un fichier nommé hudi Catalogue (disponible viaHOW CATALOGS Vérifier). Voici la déclaration de création du catalogue :
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Données déjà existantes, c'est-à-dire écrasement des données existantes :spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
La lecture incrémentielle est l'une des fonctionnalités fonctionnelles fournies par Hudi. Grâce à la lecture incrémentielle, les utilisateurs peuvent obtenir des données incrémentielles dans une plage de temps spécifiée, réalisant ainsi un traitement incrémentiel des données.Pour cela, Doris peut insérerc_custkey=100 Interrogez les données de modification ultérieures.Comme indiqué ci-dessous, nous avons inséré unc_custkey=32Les données:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris prend en charge l'interrogation des données Hudi de la version d'instantané spécifiée, réalisant ainsi la fonction Time Travel des données. Tout d'abord, vous pouvez interroger l'historique de soumission des deux tables Hudi via Spark :
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Ensuite, il peut être exécuté via Doris c_custkey=32 , interrogez l'instantané de données avant que les données ne soient insérées.Comme vous pouvez le voir ci-dessousc_custkey=32 Les données n'ont pas encore été mises à jour :
Remarque : La syntaxe Time Travel ne prend actuellement pas en charge le nouvel optimiseur et doit être exécutée en premier.
set enable_nereids_planner=false;Désactivez le nouvel optimiseur, ce problème sera corrigé dans les versions suivantes.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Les données dans Apache Hudi peuvent être grossièrement divisées en deux catégories : les données de base et les données incrémentielles. Les données de base sont généralement un fichier Parquet fusionné, tandis que les données incrémentielles font référence à l'incrément de données généré par INSERT, UPDATE ou DELETE. Les données de base peuvent être lues directement et les données incrémentielles doivent être lues via Merge on Read.
Pour les requêtes de table Hudi COW ou les requêtes de lecture optimisées de table MOR, les données sont des données de base et les fichiers de données peuvent être lus directement via Parquet Reader natif de Doris, et des réponses aux requêtes extrêmement rapides peuvent être obtenues. Pour les données incrémentielles, Doris doit appeler le SDK Java de Hudi via JNI pour y accéder.Afin d'obtenir des performances de requête optimales, Apache Doris divisera les données d'une requête en deux parties : les données de base et les données incrémentielles, et les lira respectivement à l'aide des méthodes ci-dessus.。
Pour vérifier cette idée d'optimisation, nous avons passé EXPLAIN pour voir la quantité de données de base et de données incrémentielles contenues dans la requête ci-dessous. Pour la table COW, les 101 fragments de données sont des données de base (hudiNativeReadSplits=101/101 ), de sorte que toutes les tables COW peuvent être lues directement via Doris Parquet Reader, afin d'obtenir les meilleures performances de requête. Pour les tables ROW, la plupart des fragments de données sont des données de référence (hudiNativeReadSplits=100/101), le nombre de fragments est constitué de données incrémentielles et permet essentiellement d'obtenir de meilleures performances de requête.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Vous pouvez effectuer certaines opérations de suppression via Spark pour observer davantage les changements dans les données de base Hudi et les données incrémentielles :
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
De plus, le partitionnement peut également être effectué via des conditions de partitionnement pour réduire davantage la quantité de données et améliorer la vitesse des requêtes.Dans l'exemple suivant, via la condition de partitionc_nationkey = 15 Effectuez une réduction de partition afin que les requêtes de requête n’aient besoin d’accéder qu’à une seule partition (partition=1/26) données.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
Ce qui précède est un guide détaillé pour créer rapidement un environnement de test/démo basé sur Apache Doris et Apache Hudi. À l'avenir, nous lancerons également une série de guides pour créer une architecture de lac et d'entrepôt intégrée avec Apache Doris et divers lacs de données grand public. Les formats et systèmes de stockage, notamment Iceberg, Paimon, OSS, Delta Lake, etc., sont invités à continuer à y prêter attention.

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

