
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
著者:選択DB 技術チーム
はじめに: Data Lakehouse は、データ ウェアハウスの高性能およびリアルタイム パフォーマンスと、データ レイクの低コストおよび柔軟性を組み合わせて、ユーザーがさまざまなデータ処理および分析のニーズをより便利に満たせるようにします。過去の複数のバージョンで、Apache Doris はデータ レイクとの統合を深め続け、成熟した統合レイクおよびウェアハウス ソリューションに進化しました。ユーザーがすぐに始められるように、Hudi、Iceberg、Paimon、OSS、Delta Lake などの一連の記事を通じて、Apache Doris およびさまざまな主流のデータ レイク形式とストレージ システムのレイクとウェアハウスの統合アーキテクチャ構築ガイドを紹介します。 、Kudu、BigQuery など。ようこそ、お待ちしております。
データ レイクハウスは、新しいオープン データ管理アーキテクチャとして、データ ウェアハウスの高性能およびリアルタイム パフォーマンスと、データ レイクの低コストおよび柔軟性を組み合わせて、ユーザーがさまざまなデータ ニーズをより便利に満たせるよう支援し、分析処理の需要が高まっています。エンタープライズビッグデータシステムで。
過去数回のバージョンにわたって、アパッチ・ドリス データ レイクとの統合をさらに深め、現在では成熟した統合レイクおよびウェアハウス ソリューションに進化しています。
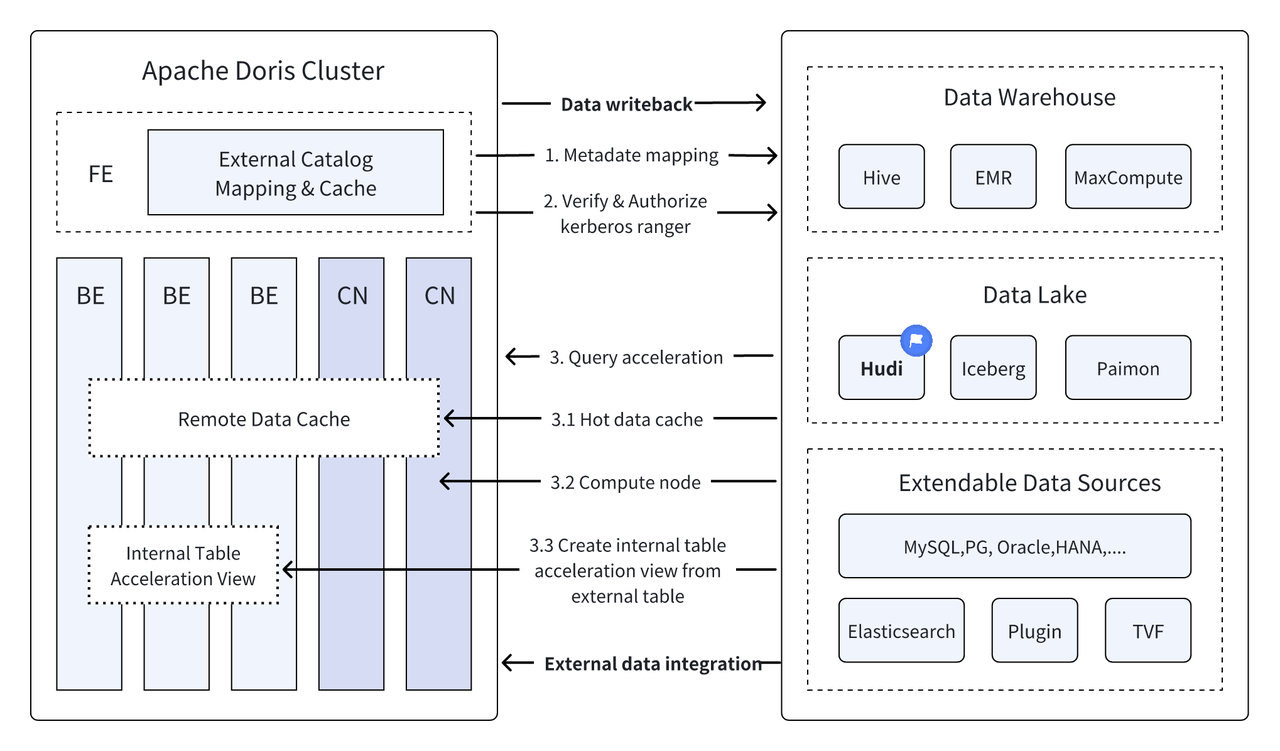
アパッチ・フディ これは現在、最も主流のオープン データ レイク フォーマットの 1 つであり、Apache Doris を含むさまざまな主流のクエリ エンジンをサポートするトランザクション データ レイク管理プラットフォームです。アパッチ・ドリス Apache Hudi データ テーブルの読み取り機能も強化されました。
- コピーオンライトテーブル:スナップショットクエリ
- 読み取りテーブルでのマージ:スナップショットクエリ、読み取り最適化クエリ
- タイムトラベルをサポート
- インクリメンタル読み取りのサポート
Apache Doris の高性能クエリ実行と Apache Hudi のリアルタイム データ管理機能により、効率的かつ柔軟で低コストのデータ クエリと分析を実現できます。また、強力なデータ バックトラッキング、監査、および増分処理も提供します。現在は Apache に基づいている機能 Doris と Apache Hudi の組み合わせは、複数のコミュニティ ユーザーによって実際のビジネス シナリオで検証され、推進されています。
リアルタイムのデータ分析と処理 : 金融業界のトランザクション分析、広告業界のリアルタイム クリック ストリーム分析、電子商取引業界のユーザー行動分析などの一般的なシナリオでは、すべてリアルタイムのデータ更新とクエリ分析が必要です。 Hudi はデータのリアルタイム更新と管理を実現し、Doris は大規模なデータ クエリ要求をリアルタイムで効率的に処理でき、リアルタイム データ分析と処理のニーズを完全に満たすことができます。 。
データのバックトラッキングと監査 : データのセキュリティと正確性に対する非常に高い要件が求められる金融や医療などの業界にとって、データのバックトラッキングと監査は非常に重要な機能です。 Hudi は、ユーザーが履歴データのステータスを表示できるタイム トラベル機能を提供し、Apache Doris の効率的なクエリ機能と組み合わせることで、任意の時点のデータを迅速に検索して分析し、正確なバックトラッキングと監査を実現できます。
増分データの読み取りと分析: ビッグデータ分析を行う場合、多くの場合、大規模なデータと頻繁な更新の問題に直面します。Hudi は増分データの読み取りをサポートしており、ユーザーは全量のデータを同時に更新することなく、変化するデータのみを処理できます。 , Apache Doris の増分読み取り関数を使用すると、このプロセスがより効率的になり、データの処理と分析の効率が大幅に向上します。
データソース全体にわたるフェデレーションクエリ : 多くのエンタープライズ データ ソースは複雑であり、データは異なるデータベースに保存されている場合があります。 Doris のマルチカタログ機能は、複数のデータ ソースの自動マッピングと同期をサポートし、データ ソース全体にわたるフェデレーション クエリをサポートします。分析のために複数のデータ ソースからデータを取得して統合する必要がある企業にとって、これによりデータ フロー パスが大幅に短縮され、作業効率が向上します。
この記事では、読者がすぐに使い始められるように、Docker 環境で Apache Doris + Apache Hudi のテストおよびデモンストレーション環境を迅速に構築する方法を紹介し、各機能の動作をデモンストレーションします。
この記事に関連するすべてのスクリプトとコードは、次のアドレスから入手できます。https://github.com/apache/doris/tree/master/samples/datalake/hudi
この記事の例は、Docker Compose を使用してデプロイされています。コンポーネントとバージョン番号は次のとおりです。

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
次に、Spark を通じて Hudi データを生成します。以下のコードに示すように、クラスターにはすでに という名前のカードが含まれています。 customer Hive テーブルでは、この Hive テーブルを通じて Hudi テーブルを作成できます。
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
以下に示すように、 hudi カタログ(以下から入手可能)HOW CATALOGS チェック)。以下はカタログの作成ステートメントです。
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 既存のデータ、つまり既存のデータを上書きする場合:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
インクリメンタルリードは、Hudi が提供する機能の 1 つであり、インクリメンタルリードにより、ユーザーは指定した時間範囲で増分データを取得し、データの増分処理を実現できます。このために、ドリスは次のように挿入できます。c_custkey=100後続の変更データをクエリします。以下に示すように、c_custkey=32データ:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris は、指定されたスナップショット バージョンの Hudi データのクエリをサポートし、それによってデータのタイム トラベル機能を実現します。まず、Spark を通じて 2 つの Hudi テーブルの送信履歴をクエリできます。
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
その後、ドリスを通じて実行できます c_custkey=32 、データが挿入される前にデータ スナップショットをクエリします。以下に示すようにc_custkey=32 データはまだ更新されていません:
注: タイム トラベル構文は現在新しいオプティマイザーをサポートしていないため、最初に実行する必要があります。
set enable_nereids_planner=false;新しいオプティマイザをオフにすると、この問題は後続のバージョンで修正される予定です。
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Apache Hudi のデータは、ベースライン データと増分データの 2 つのカテゴリに大別できます。ベースライン データは通常、マージされた Parquet ファイルですが、増分データは INSERT、UPDATE、または DELETE によって生成されたデータ増分を指します。ベースライン データは直接読み取ることができますが、増分データは Merge on Read を通じて読み取る必要があります。
Hudi COW テーブル クエリまたは MOR テーブル読み取り最適化クエリの場合、データはベースライン データであり、データ ファイルは Doris のネイティブ Parquet Reader を通じて直接読み取ることができ、非常に高速なクエリ応答を取得できます。増分データの場合、Doris はアクセスのために JNI 経由で Hudi の Java SDK を呼び出す必要があります。最適なクエリ パフォーマンスを実現するために、Apache Doris はクエリ内のデータをベースライン データと増分データの 2 つの部分に分割し、それぞれ上記の方法を使用して読み取ります。。
この最適化のアイデアを検証するために、次のコードを渡しました。 EXPLAIN ステートメントを使用して、以下のクエリに含まれるベースライン データと増分データの量を確認します。 COW テーブルの場合、101 個のデータ シャードすべてがベースライン データです (hudiNativeReadSplits=101/101 )、すべての COW テーブルを Doris Parquet Reader から直接読み取ることができるため、最高のクエリ パフォーマンスが得られます。 ROW テーブルの場合、データ シャードのほとんどはベースライン データです (hudiNativeReadSplits=100/101)、シャードの数は増分データであり、基本的にはより優れたクエリ パフォーマンスを実現できます。
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Spark を通じていくつかの削除操作を実行して、Hudi ベースライン データと増分データの変化をさらに観察できます。
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
さらに、データ量をさらに削減し、クエリ速度を向上させるために、パーティショニング条件を使用してパーティショニングを実行することもできます。次の例では、パーティション条件を通じてc_nationkey = 15 パーティション削減を実行して、クエリリクエストが 1 つのパーティションのみにアクセスする必要があるようにします (partition=1/26) データ。
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
上記は、Apache Doris と Apache Hudi に基づいてテスト/デモ環境を迅速に構築するための詳細なガイドです。将来的には、Apache Doris とさまざまな主流のデータ レイクを使用して統合されたレイクおよびウェアハウス アーキテクチャを構築するための一連のガイドも開始する予定です。 Iceberg、Paimon、OSS、Delta Lake などのフォーマットやストレージ システムに引き続き注目してください。

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: