
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
autor:SelecionarDB Equipe técnica
Introdução: Data Lakehouse combina o alto desempenho e o desempenho em tempo real do data warehouse com o baixo custo e a flexibilidade do data lake para ajudar os usuários a atender a diversas necessidades de processamento e análise de dados de maneira mais conveniente. Nas múltiplas versões anteriores, o Apache Doris continuou a aprofundar sua integração com o data lake e evoluiu para uma solução integrada madura de lago e armazém. Para facilitar o início rápido dos usuários, apresentaremos o guia de construção de arquitetura integrada de lago e armazém para Apache Doris e vários formatos de data lake e sistemas de armazenamento convencionais por meio de uma série de artigos, incluindo Hudi, Iceberg, Paimon, OSS, Delta Lake , Kudu, BigQuery, etc. Bem-vindo, fique ligado.
Como uma nova arquitetura aberta de gerenciamento de dados, o Data Lakehouse combina o alto desempenho e o desempenho em tempo real do data warehouse com o baixo custo e a flexibilidade do data lake para ajudar os usuários a atender a diversas necessidades de dados de maneira mais conveniente. cada vez mais usado em sistemas corporativos de big data.
Nas últimas versões,Apache Doris Ele continua a aprofundar sua integração com o data lake e agora evoluiu para uma solução madura e integrada de lago e armazém.
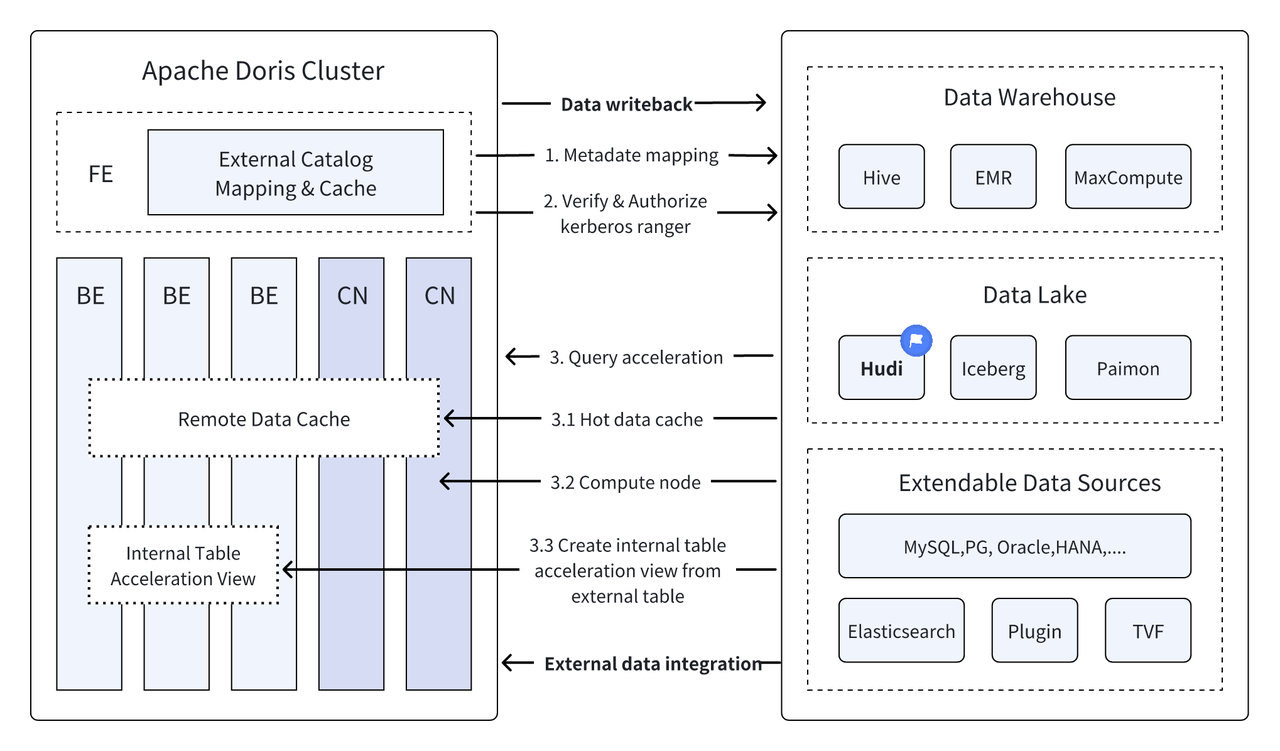
Apache Hudi Atualmente é um dos formatos de data lake abertos mais populares e uma plataforma de gerenciamento de data lake transacional que oferece suporte a uma variedade de mecanismos de consulta convencionais, incluindo Apache Doris.Apache Doris Os recursos de leitura das tabelas de dados do Apache Hudi também foram aprimorados:
- Copiar na tabela de gravação: Consulta de instantâneo
- Mesclar na tabela de leitura: consultas de instantâneo, consultas otimizadas para leitura
- Suporte para viagem no tempo
- Suporte para leitura incremental
Com a execução de consultas de alto desempenho do Apache Doris e os recursos de gerenciamento de dados em tempo real do Apache Hudi, consultas e análises de dados eficientes, flexíveis e de baixo custo podem ser alcançadas. funções Atualmente baseadas em Apache A combinação de Doris e Apache Hudi foi verificada e promovida em cenários de negócios reais por vários usuários da comunidade:
Análise e processamento de dados em tempo real : Cenários comuns, como análise de transações no setor financeiro, análise de fluxo de cliques em tempo real no setor de publicidade e análise do comportamento do usuário no setor de comércio eletrônico, exigem atualizações de dados e análise de consultas em tempo real. Hudi pode realizar atualização e gerenciamento de dados em tempo real e garantir a consistência e confiabilidade dos dados. Doris pode lidar com eficiência com solicitações de consulta de dados em grande escala em tempo real. .
Retrocesso e auditoria de dados : Para setores como finanças e assistência médica, que possuem requisitos extremamente elevados de segurança e precisão de dados, o retrocesso e a auditoria de dados são funções muito importantes. Hudi fornece uma função de viagem no tempo que permite aos usuários visualizar o status dos dados históricos. Combinado com os recursos de consulta eficientes do Apache Doris, ele pode pesquisar e analisar dados rapidamente a qualquer momento para obter retrocesso e auditoria precisos.
Leitura e análise incremental de dados: Ao realizar análises de big data, muitas vezes nos deparamos com problemas de grande escala de dados e atualizações frequentes. O Hudi suporta leitura incremental de dados, o que permite aos usuários processar apenas dados alterados sem ter que atualizar a quantidade total de dados ao mesmo tempo; , As funções de leitura incremental do Apache Doris também podem tornar esse processo mais eficiente, melhorando significativamente a eficiência do processamento e análise de dados.
Consultas federadas em fontes de dados : muitas fontes de dados empresariais são complexas e os dados podem ser armazenados em diferentes bancos de dados. A função Multi-Catalog do Doris oferece suporte ao mapeamento e sincronização automáticos de diversas fontes de dados e oferece suporte a consultas federadas entre fontes de dados. Para empresas que precisam obter e integrar dados de diversas fontes de dados para análise, isso reduz bastante o caminho do fluxo de dados e melhora a eficiência do trabalho.
Este artigo apresentará aos leitores como configurar rapidamente o ambiente de teste e demonstração do Apache Doris + Apache Hudi no ambiente Docker e demonstrará a operação de cada função para ajudar os leitores a começar rapidamente.
Todos os scripts e códigos envolvidos neste artigo podem ser obtidos neste endereço:https://github.com/apache/doris/tree/master/samples/datalake/hudi
O exemplo neste artigo é implantado usando Docker Compose. Os componentes e números de versão são os seguintes:

sudo docker network create -d bridge hudi-net
sudo ./start-hudi-compose.sh
sudo ./login-spark.sh
sudo ./login-doris.sh
Em seguida, gere dados Hudi por meio do Spark.Conforme mostrado no código abaixo, o cluster já contém um cartão chamadocustomer Tabela Hive, você pode criar uma tabela Hudi por meio desta tabela Hive:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = 'cow',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = 'mor',
primaryKey = 'c_custkey',
preCombineField = 'c_name'
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
Como mostrado abaixo, um arquivo chamado hudi Catálogo (disponível viaHOW CATALOGS Verificar). A seguir está a declaração de criação do Catálogo:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
'hive.metastore.uris' = 'thrift://hive-metastore:9083',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
c_custkey=32 Dados já existentes, ou seja, substituindo dados existentes:spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
A leitura incremental é um dos recursos funcionais fornecidos pelo Hudi. Por meio da leitura incremental, os usuários podem obter dados incrementais em um intervalo de tempo especificado, obtendo assim um processamento incremental de dados.Para isso, Doris pode inserirc_custkey=100 Consulte os dados de alteração subsequentes.Conforme mostrado abaixo, inserimos umc_custkey=32Os dados:
doris> select * from customer_cow@incr('beginTime'='20240603015018572');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_cow', 'latest_state', '20240603015018572');
doris> select * from customer_mor@incr('beginTime'='20240603015058442');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes('customer_mor', 'latest_state', '20240603015058442');
Doris suporta a consulta dos dados Hudi da versão do instantâneo especificada, realizando assim a função de viagem no tempo dos dados. Primeiro, você pode consultar o histórico de envio das duas tabelas Hudi por meio do Spark:
spark-sql> call show_commits(table => 'customer_cow', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => 'customer_mor', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
Então, pode ser executado através de Doris c_custkey=32 , consulte o instantâneo de dados antes que os dados sejam inseridos.Como você pode ver abaixoc_custkey=32 Os dados ainda não foram atualizados:
Nota: A sintaxe da Viagem no Tempo não suporta atualmente o novo otimizador e precisa ser executada primeiro
set enable_nereids_planner=false;Desligue o novo otimizador, este problema será corrigido nas versões subsequentes.
doris> select * from customer_cow for time as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of '20240603015018572' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of '20240603015058442' where c_custkey = 32 or c_custkey = 100;
Os dados no Apache Hudi podem ser divididos aproximadamente em duas categorias - dados de linha de base e dados incrementais. Os dados de linha de base geralmente são um arquivo Parquet mesclado, enquanto os dados incrementais se referem ao incremento de dados gerado por INSERT, UPDATE ou DELETE. Os dados de linha de base podem ser lidos diretamente, enquanto os dados incrementais precisam ser lidos por meio de Merge on Read.
Para consultas de tabela Hudi COW ou consultas de leitura otimizada de tabela MOR, os dados são dados de linha de base e os arquivos de dados podem ser lidos diretamente por meio do Parquet Reader nativo de Doris, e respostas de consulta extremamente rápidas podem ser obtidas. Para dados incrementais, Doris precisa chamar o Java SDK de Hudi por meio de JNI para acessá-los.Para obter o desempenho ideal da consulta, o Apache Doris dividirá os dados de uma consulta em duas partes: linha de base e dados incrementais, e os lerá usando os métodos acima, respectivamente.。
Para verificar esta ideia de otimização, passamos EXPLAIN declaração para ver quantos dados de linha de base e dados incrementais existem na consulta abaixo. Para a tabela COW, todos os 101 fragmentos de dados são dados de linha de base (hudiNativeReadSplits=101/101 ), para que todas as tabelas COW possam ser lidas diretamente através do Doris Parquet Reader, para que o melhor desempenho de consulta possa ser obtido. Para tabelas ROW, a maioria dos fragmentos de dados são dados de linha de base (hudiNativeReadSplits=100/101), o número de fragmentos são dados incrementais e basicamente podem obter melhor desempenho de consulta.
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
Você pode realizar algumas operações de exclusão por meio do Spark para observar melhor as alterações nos dados de linha de base e nos dados incrementais do Hudi:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
Além disso, a remoção da partição pode ser realizada por meio de condições de partição para reduzir ainda mais a quantidade de dados e melhorar a velocidade da consulta.No exemplo a seguir, através da condição de partiçãoc_nationkey = 15 Execute a redução de partição para que as solicitações de consulta precisem acessar apenas uma partição (partition=1/26) dados.
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
O texto acima é um guia detalhado para construir rapidamente um ambiente de teste/demonstração baseado em Apache Doris e Apache Hudi. No futuro, também lançaremos uma série de guias para construir uma arquitetura integrada de lago e armazém com Apache Doris e vários data lakes convencionais. formatos e sistemas de armazenamento, incluindo Iceberg, Paimon, OSS, Delta Lake, etc., bem-vindos para continuar a prestar atenção.

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]