2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Zum Parsen von Daten gibt es zusätzlich zur vorherigen BeautifulSoup-Bibliothek zwei Methoden: reguläre Ausdrücke und Xpath.
Reguläre Ausdrücke (kurz RE) sind Werkzeuge zur Beschreibung und Zuordnung von Zeichenfolgenmustern.
Es wird häufig in der Textverarbeitung, Datenvalidierung, Textsuche und -ersetzung und anderen Szenarien eingesetzt. Reguläre Ausdrücke verwenden eine spezielle Syntax, die den komplexen Mustervergleich für Zeichenfolgen ermöglicht.
Test auf reguläre Ausdrücke:Online-Test für reguläre Ausdrücke
Metazeichen: Sonderzeichen mit fester Bedeutung. Jedes Metazeichen entspricht standardmäßig nur einer Zeichenfolge und kann nicht mit Zeilenumbruchzeichen übereinstimmen.
| Metazeichen | beschreiben | Beispiel |
|---|---|---|
. | Entspricht jedem Zeichen außer Zeilenumbrüchen | a.b kann zusammenpassena1b、acb |
w | Ordnen Sie Buchstaben, Zahlen oder Unterstriche zu | w+ übereinstimmenhello、world_123 |
s | Entspricht jedem Leerzeichen | s+ Entspricht Leerzeichen, Tabulatoren usw. |
d | Übereinstimmungszahlen | d+ übereinstimmen123、456 |
n | Entspricht einem Zeilenumbruchzeichen | hellonworld Übereinstimmendes Zeilenumbruchzeichen |
t | einem Tabulatorzeichen entsprechen | hellotworld Übereinstimmung mit dem Tabulatorzeichen |
^ | Entspricht dem Anfang einer Zeichenfolge | ^Hello übereinstimmenHello Zeichenfolge am Anfang |
$ | Passen Sie das Ende der Zeichenfolge an | World$ übereinstimmenWorld Ende der Zeichenfolge |
W | Entspricht Zeichen, die keine Buchstaben, keine Zahlen und keine Unterstriche sind | W+ übereinstimmen!@#、$%^ |
D | Passen Sie nicht numerische Zeichen an | D+ übereinstimmenabc、XYZ |
S | Passen Sie Zeichen an, die keine Leerzeichen sind | S+ übereinstimmenhello、world123 |
| `ein | b` | Ordne Charaktere zu a oder Charakterb |
(...) | Erfasst einen Ausdruck in Klammern, der eine Gruppe darstellt | (abc) erfassenabc |
[...] | Entspricht jedem Zeichen in eckigen Klammern | [abc] übereinstimmena、b oderc |
[^...] | Entspricht jedem Zeichen, das nicht in eckigen Klammern steht | [^abc] Spiel außera、b、c Jeder andere Charakter als |
Quantifizierer: steuert die Häufigkeit des Vorkommens des vorhergehenden Metazeichens
| Quantor | beschreiben |
|---|---|
* | Null oder mehrmals wiederholen |
+ | Wiederholen Sie dies einmal oder mehrmals |
? | Null oder einmal wiederholen |
{n} | n-mal wiederholen |
{n,} | Wiederholen Sie dies n-mal oder öfter |
{n,m} | Wiederholen Sie dies n bis m Mal |
Lazy Matching.*? : Passen Sie so wenige Zeichen wie möglich an.Nach wiederholten Metazeichen hinzufügen? Implementieren Sie Lazy Matching.
Gieriges Matching.* : Passen Sie so viele Zeichen wie möglich an. Die standardmäßigen wiederholten Metazeichen sind gierig.
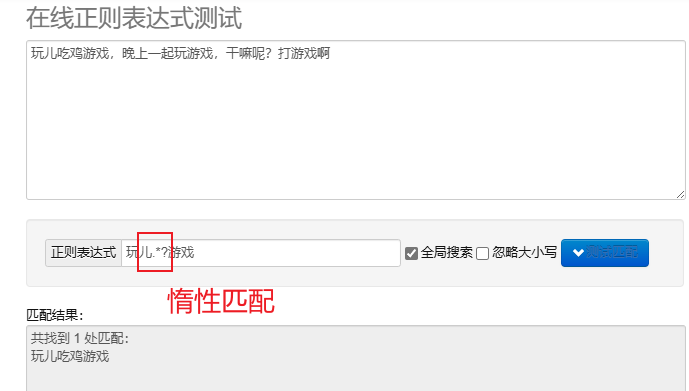
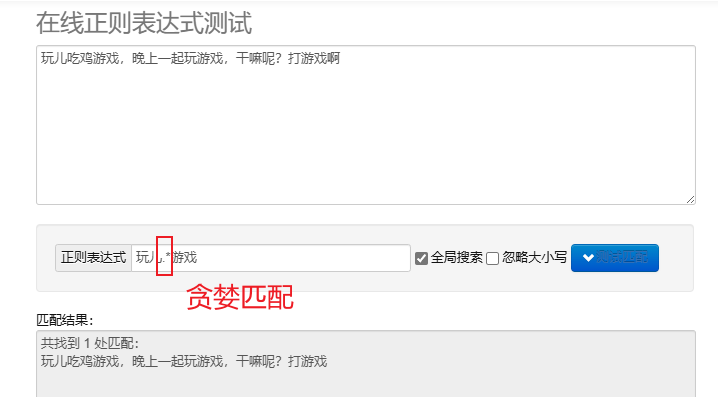
Um reguläre Ausdrücke in Python zu verarbeiten, können Sie verwenden re Dieses Modul bietet eine Reihe von Funktionen zum Suchen, Abgleichen und Bearbeiten von Zeichenfolgen.
| Funktion | beschreiben |
|---|---|
re.search(pattern, string, flags=0) | Suchzeichenfolge und Rückgabe des ersten passenden Objekts; wenn es keine Übereinstimmung gibt, Rückgabe None |
re.match(pattern, string, flags=0) | Passen Sie das Muster vom Anfang der Zeichenfolge an. Wenn die Übereinstimmung erfolgreich ist, wird das übereinstimmende Objekt zurückgegeben, andernfalls None |
re.fullmatch(pattern, string, flags=0) | Gibt das Übereinstimmungsobjekt zurück, wenn die gesamte Zeichenfolge genau mit dem Muster übereinstimmt, andernfalls wird zurückgegeben None |
re.findall(pattern, string, flags=0) | Gibt eine Liste aller nicht überlappenden Übereinstimmungen in einer Zeichenfolge zurück |
re.finditer(pattern, string, flags=0) | Gibt einen Iterator aller nicht überlappenden Übereinstimmungen in einer Zeichenfolge zurück |
re.sub(pattern, repl, string, count=0, flags=0) | Ersetzen Sie alle Teile des passenden Musters durch die Ersatzzeichenfolge und geben Sie die ersetzte Zeichenfolge zurück |
re.split(pattern, string, maxsplit=0, flags=0) | Teilen Sie die Zeichenfolge basierend auf dem Mustervergleich auf und geben Sie die Teilungsliste zurück |
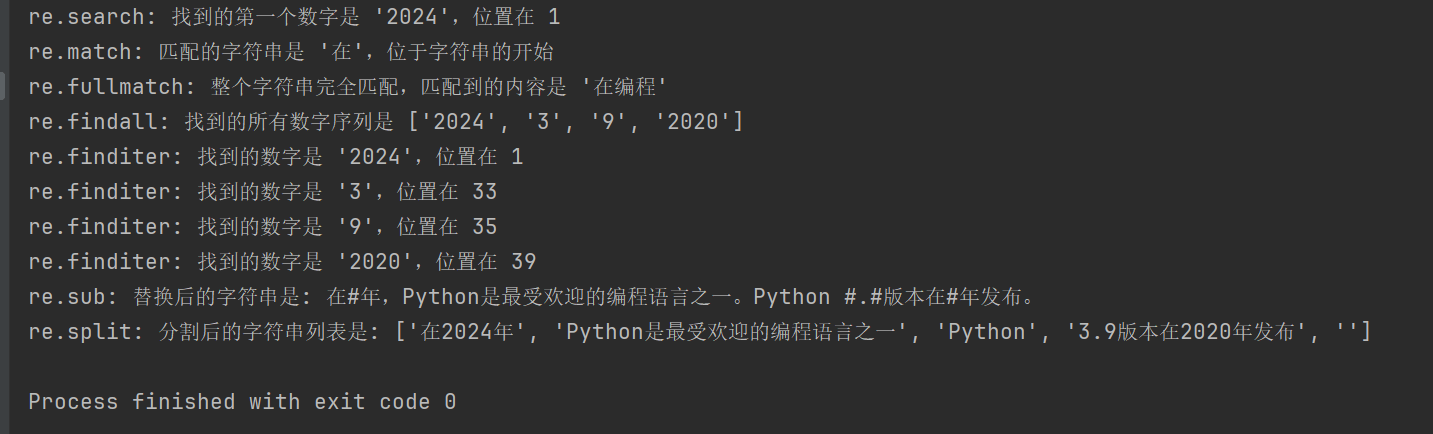
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
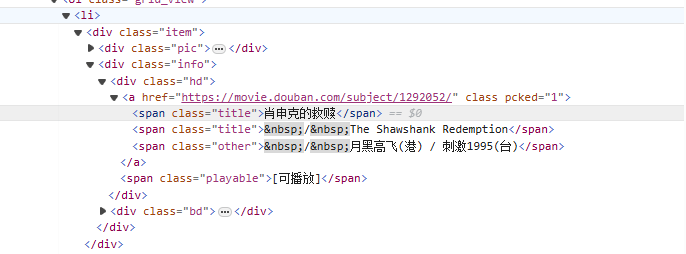
aus<li>Beginnen Sie mit dem Tag und passen Sie es nach und nach dem Tag an, das den Filmnamen enthält<span class="title">Tag, verwenden Sie den nicht gierigen Modus (.*?) gleicht alle Zeichen ab, die dazwischen vorhanden sein können, bis das nächste explizite Token gefunden wird, und zwar unter Verwendung einer benannten Capture-Gruppe(?P<name>)Extrahieren Sie den Teil des Filmtitels.
Re-Expression-Schreiben:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Crawler-Code:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath ist eine Sprache zum Suchen in XML-Dokumenten. Sie kann Knoten oder Knotensätze über Pfadausdrücke auswählen. HTML ist eine Teilmenge von XML.
Installieren Sie das lxml-Modul: pip install lxml
| Symbol | erklären |
|---|---|
/ | Wählen Sie aus dem Wurzelknoten aus. |
// | Wählt Knoten im Dokument aus dem aktuellen Knoten aus, der der Auswahl entspricht, unabhängig von ihrer Position. |
. | Wählen Sie den aktuellen Knoten aus. |
.. | Wählt den übergeordneten Knoten des aktuellen Knotens aus. |
@ | Wählen Sie Eigenschaften aus. |
| Ausdruck | erklären |
|---|---|
/bookstore/book | Wählen Sie alle Buchunterknoten unter dem Buchladenknoten aus. |
//book | Wählt alle Buchknoten im Dokument unabhängig von ihrer Position aus. |
bookstore/book[1] | Wählen Sie den ersten untergeordneten Buchknoten unter dem Buchladenknoten aus. |
//title[@lang] | Wählen Sie alle Titelknoten mit dem Attribut „lang“ aus. |
//title[@lang='en'] | Wählen Sie alle Titelknoten aus, deren lang-Attribut „en“ ist. |
text(): Wählen Sie den Text des Elements aus.@attr: Wählen Sie das Attribut des Elements aus.contains(): Bestimmen Sie die Einschlussbeziehung.starts-with(): Der Beginn des Urteils.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Alle Klassen auswählen alsmoviediv-Element.
/span[@class="title"][1]: Wählen Sie die Klasse in jedem Div aus alstitleDas erste span-Element.
/text(): Den Textinhalt des span-Elements abrufen.
//div[@class="movie"]/span[@class="title"][2]/text()
Ähnlich dem obigen Ausdruck, aber die Klasse in jedem Div wird ausgewählt.titleDas zweite span-Element.
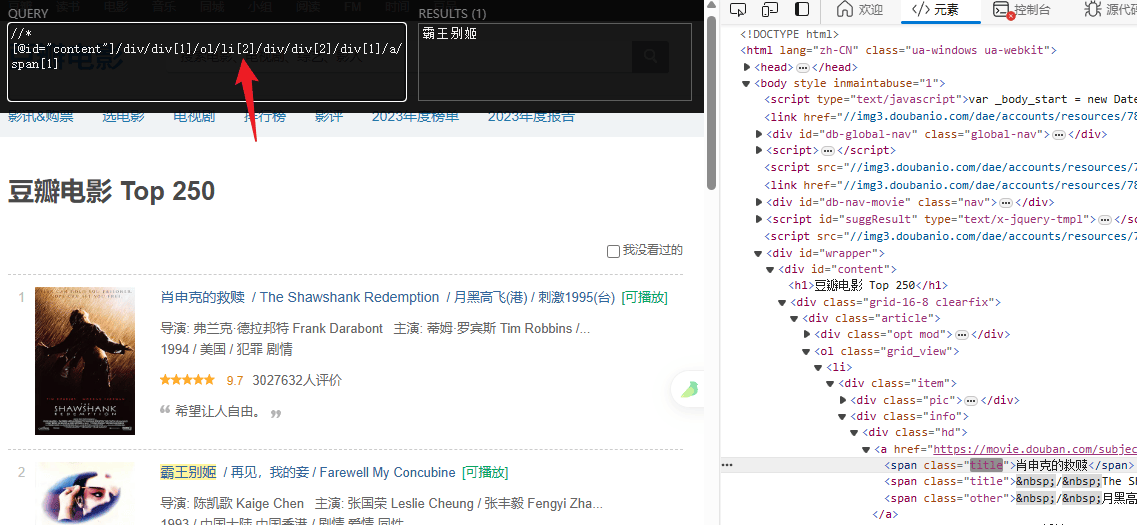
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet, Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

