2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
आँकडानां विश्लेषणार्थं पूर्वस्य BeautifulSoup पुस्तकालयस्य अतिरिक्तं द्वौ विधिौ स्तः : नियमितव्यञ्जनानि Xpath च ।
नियमितव्यञ्जनानि (संक्षेपेण RE) स्ट्रिंग्-प्रतिमानानाम् वर्णनाय, मेलनाय च प्रयुक्तानि साधनानि सन्ति ।
पाठसंसाधनं, दत्तांशसत्यापनं, पाठसन्धानं प्रतिस्थापनं च अन्येषु परिदृश्येषु च अस्य व्यापकरूपेण उपयोगः भवति । नियमितव्यञ्जनानि विशेषवाक्यविन्यासस्य उपयोगं कुर्वन्ति यत् तारानाम् उपरि जटिलप्रतिमानमेलनं सक्षमं करोति ।
नियमित अभिव्यक्तिपरीक्षा : १.ऑनलाइन नियमित अभिव्यक्ति परीक्षण
मेटावर्णाः - नियतार्थयुक्ताः विशेषचिह्नाः । प्रत्येकं मेटावर्णं पूर्वनिर्धारितरूपेण केवलमेकं स्ट्रिंग् मेलनं करोति, नूतनपङ्क्तिवर्णैः सह मेलनं कर्तुं न शक्नोति ।
| मेटावर्णाः | वर्णेतु | उदाहरण |
|---|---|---|
. | नवीनपङ्क्तयः विहाय कस्यापि वर्णस्य मेलनं करोति | a.b मेलनं कर्तुं शक्नोतिa1b、acb |
w | अक्षराणां, संख्यानां, रेखाङ्कानां वा मेलनं कुर्वन्तु | w+ मेलनम्hello、world_123 |
s | कस्यापि श्वेतस्थानवर्णस्य मेलनं करोति | s+ रिक्तस्थानानि, ट्याब्स् इत्यादीनि मेलयति। |
d | संख्यानां मेलनं कुर्वन्तु | d+ मेलनम्123、456 |
n | नूतनपङ्क्तिवर्णस्य मेलनं करोति | hellonworld नवीनपङ्क्तिवर्णस्य मेलनं कुर्वन्तु |
t | एकं ट्याब् वर्णं मेलयितुम् | hellotworld match tab character इति |
^ | तारस्य आरम्भं मेलयति | ^Hello मेलनम्Hello आरम्भे तारः |
$ | तारस्य अन्तस्य मेलनं कुर्वन्तु | World$ मेलनम्World तारस्य अन्तः |
W | अक्षररहितं, असंख्याकं, अरेखाङ्कं च वर्णानाम् मेलनं करोति | W+ मेलनम्!@#、$%^ |
D | असंख्याकवर्णानां मेलनं कुर्वन्तु | D+ मेलनम्abc、XYZ |
S | अश्वेतस्थानवर्णानां मेलनं कुर्वन्तु | S+ मेलनम्hello、world123 |
| `क | ख` | वर्णानाम् मेलनं कुर्वन्तु a चरित्रं वाb |
(...) | कोष्ठकान्तर्गतं व्यञ्जनं गृह्णाति, समूहस्य प्रतिनिधित्वं करोति | (abc) पटलabc |
[...] | वर्गकोष्ठकानां अन्तः कस्यापि वर्णस्य मेलनं करोति | [abc] मेलनम्a、b वाc |
[^...] | वर्गकोष्ठकेषु न निबद्धस्य कस्यचित् वर्णस्य मेलनं करोति | [^abc] मेलनं विहायa、b、c परं यत्किमपि पात्रम् |
परिमाणकर्ता : पूर्ववर्ती मेटावर्णस्य आवृत्तीनां संख्यां नियन्त्रयति
| परिमाणकर्त्ता | वर्णेतु |
|---|---|
* | शून्यं वा अधिकं वा पुनः पुनः कुर्वन्तु |
+ | एकं वा अधिकं वा पुनः पुनः कुर्वन्तु |
? | शून्यं वा एकवारं वा पुनः कुर्वन्तु |
{n} | न वारं पुनरावृत्तिः |
{n,} | न वा अधिकवारं पुनः पुनः कुर्वन्तु |
{n,m} | न तः म पर्यन्तं पुनः पुनः कुर्वन्तु |
आलस्यं मेलनं.*? : यथासम्भवं न्यूनानि वर्णाः मेलयन्तु।पुनः पुनः मेटावर्णानां अनन्तरं योजयति? आलस्यमेलनं कार्यान्वितम्।
लोभी मिलान.* : यथासंभवं वर्णानाम् मेलनं कुर्वन्तु। पूर्वनिर्धारितपुनरावृत्तिमेटावर्णाः लोभी भवन्ति ।
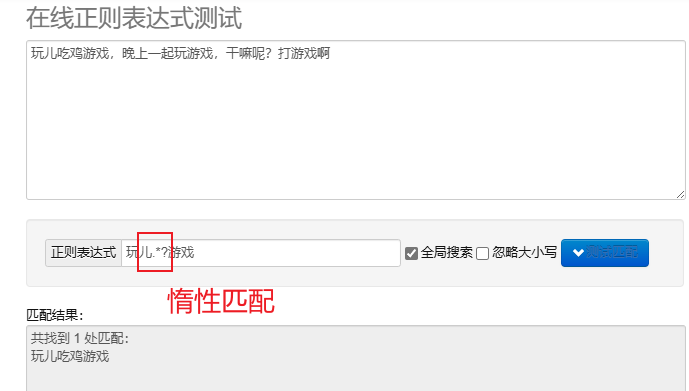
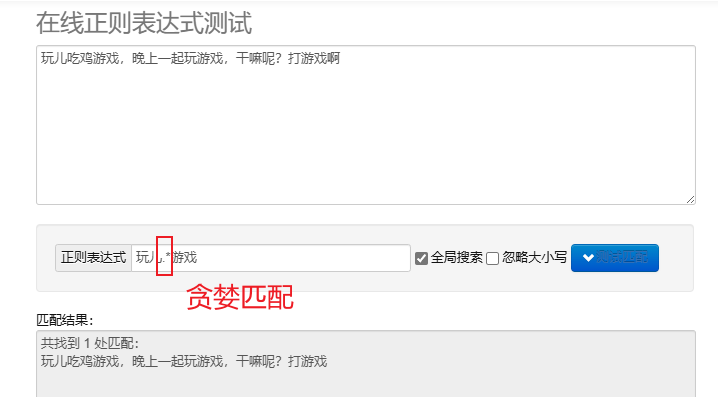
पायथन् मध्ये नियमितव्यञ्जनानि संसाधितुं, भवान् उपयोक्तुं शक्नोति re module, एतत् मॉड्यूल् स्ट्रिंग् अन्वेष्टुं, मेलनं कर्तुं, परिवर्तनं च कर्तुं कार्याणां समुच्चयं प्रदाति ।
| नियोग | वर्णेतु |
|---|---|
re.search(pattern, string, flags=0) | स्ट्रिंग् अन्वेष्टुम् प्रथमं मेलयुक्तं वस्तु प्रत्यागच्छतु यदि मेलनं नास्ति तर्हि प्रत्यागच्छतु; None |
re.match(pattern, string, flags=0) | स्ट्रिंग् इत्यस्य आरम्भात् एव प्रतिमानं मेलनं कुर्वन्तु यदि मेलनं सफलं भवति तर्हि मेलनं प्रत्यागच्छन्तु, अन्यथा None |
re.fullmatch(pattern, string, flags=0) | यदि सम्पूर्णं स्ट्रिंग् पैटर्न् इत्यस्य सम्यक् मेलनं करोति तर्हि match ऑब्जेक्ट् प्रत्यागच्छति, अन्यथा प्रत्यागच्छति None |
re.findall(pattern, string, flags=0) | स्ट्रिंग् मध्ये सर्वेषां अ-अतिव्याप्त-मेलनानां सूचीं प्रत्यागच्छति |
re.finditer(pattern, string, flags=0) | स्ट्रिंग् मध्ये सर्वेषां अ-अतिव्याप्त-मेलनानां पुनरावर्तकं प्रत्यागच्छति |
re.sub(pattern, repl, string, count=0, flags=0) | मेल-प्रतिरूपस्य सर्वान् भागान् प्रतिस्थापन-तारेन प्रतिस्थापयन्तु, प्रतिस्थापितं तारं प्रत्यागच्छन्तु |
re.split(pattern, string, maxsplit=0, flags=0) | pattern matching इत्यस्य आधारेण स्ट्रिंग् विभज्य विभक्तसूचीं प्रत्यागच्छतु |
import re
# 示例文本
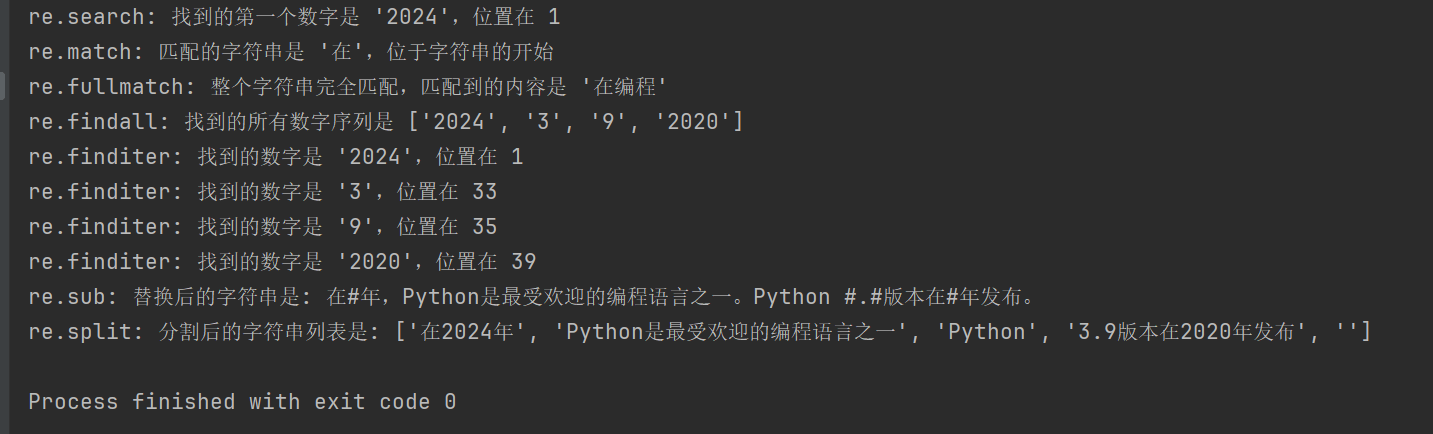
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
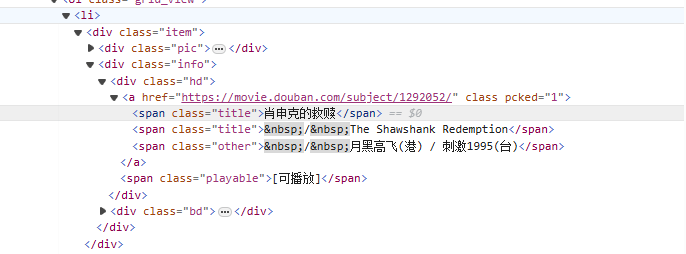
इत्यस्मात्<li>टैग् तः आरभ्य क्रमेण चलचित्रनाम युक्तेन टैग् इत्यनेन सह मेलनं कुर्वन्तु<span class="title">टैग, अलोभी मोडस्य उपयोगं कुर्वन्तु (.*?) नामकं ग्रहणसमूहं उपयुज्य यावत् अग्रिमः स्पष्टः टोकनः न लभ्यते तावत् मध्ये विद्यमानाः केचन वर्णाः मेलयति(?P<name>)चलचित्रस्य शीर्षकभागं निष्कासयन्तु।
पुनः अभिव्यक्ति लेखनम् : १.
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
क्रॉलर कोडः : १.
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath इति XML दस्तावेजेषु अन्वेषणार्थं भाषा अस्ति ।
lxml मॉड्यूल् संस्थापयन्तु: pip install lxml
| चिह्न | व्याख्याति |
|---|---|
/ | मूलनोड् तः चयनं कुर्वन्तु । |
// | चयनेन सह मेलनं कुर्वन्तः वर्तमाननोड् तः दस्तावेजे नोड् चयनं करोति, तेषां स्थितिं न कृत्वा । |
. | वर्तमान नोड् चिनोतु । |
.. | वर्तमाननोड् इत्यस्य मातापितृनोड् चिनोति । |
@ | गुणाः चयनं कुर्वन्तु। |
| अभिव्यक्ति | व्याख्याति |
|---|---|
/bookstore/book | पुस्तकभण्डारनोड् इत्यस्य अधः सर्वाणि पुस्तक-उप-नोड्-इत्येतत् चिनोतु । |
//book | दस्तावेजे सर्वाणि पुस्तकनोड्स् स्थानं न कृत्वा चयनं करोति । |
bookstore/book[1] | पुस्तकभण्डारनोड् इत्यस्य अधः प्रथमं पुस्तकबाल नोड् चिनोतु । |
//title[@lang] | lang विशेषतायुक्तानि सर्वाणि शीर्षकनोड्स् चिनोतु । |
//title[@lang='en'] | येषां lang एट्रिब्यूट् 'en' अस्ति तान् सर्वान् शीर्षकनोड् चिनोतु । |
text(): तत्त्वस्य पाठं चिनोतु।@attr: तत्वस्य विशेषतां चिनोतु।contains(): समावेशसम्बन्धं निर्धारयतु।starts-with(): न्यायस्य आरम्भः।from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: सर्वाणि वर्गाणि यथा चिनोतुmovieदिव तत्वम् ।
/span[@class="title"][1]: प्रत्येकं div as मध्ये क्लास् चिनोतुtitleप्रथमं स्पैनतत्त्वम् ।
/text(): span element इत्यस्य पाठसामग्री प्राप्तुम्।
//div[@class="movie"]/span[@class="title"][2]/text()
उपर्युक्तव्यञ्जनस्य सदृशं, परन्तु प्रत्येकस्मिन् div मध्ये वर्गः चयनितः भवति ।titleद्वितीयः स्पन् तत्वः ।
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु

