2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Ad partem datam, praeter bibliothecam BeautifulSoup priorem, duo sunt modi: expressiones regulares et Xpath.
Expressiones regulares (RE ad breves) instrumenta adhibenda sunt ad exemplaria describenda et ad chordas componendas.
Late in textu processus, notitia sanationis, textus inquisitionis et postea in aliis missionibus adhibita est. Expressiones regulares speciali syntaxi utuntur ad adaptationem complexam exemplarium perficiendam in chordis.
Regular expression test:Test online expressio iusto
Metacharacteres: Notae speciales cum certis significationibus. Quisque metacharacter una tantum chorda compositus per defaltam et characteribus newlines aequare non potest.
| metacharacters | describere | Exemplum |
|---|---|---|
. | Nullo modo congruit newlines | a.b potest aequarea1b、acb |
w | Par litteris, numeris vel underscores | w+ parhello、world_123 |
s | Aequat aliqua whitespace mores | s+ Matches spatia, tabs, etc. |
d | Numeri par | d+ par123、456 |
n | Matches a newline character | hellonworld Par newline mores |
t | par in tab mores | hellotworld par tab character |
^ | Initium par filo | ^Hello parHello linea in principio |
$ | Inserere finem filum | World$ parWorld finis filum |
W | Aequet non-littera, non-numerum, et non-underscore characteribus | W+ par!@#、$%^ |
D | Par characteribus numerorum non- | D+ parabc、XYZ |
S | Par characteribus non-whitespace | S+ parhello、world123 |
| 'a | b` | Par characters a aut moresb |
(...) | Expressio inter parentheses capit, coetus repraesentans | (abc) captisabc |
[...] | Aequet ingenium in brackets quadrata | [abc] para、b or *c |
[^...] | Aequet quodlibet ingenium non inclusum in brackets quadrata | [^abc] par nisia、b、c Quodlibet ingenium quam |
Quantifier: numerum regit eventus metacharacteris praecedentis
| quantifier | describere |
|---|---|
* | Repetere nulla vel interdum |
+ | Iterare vel temporibus |
? | Repetere nulla vel uno tempore |
{n} | Iterare n temporibus |
{n,} | Repetere n vel temporibus |
{n,m} | Iterare n ad m tempora |
piger matching.*? : Par quam paucis characteribus quam maxime.Post crebris metacharacteribus add? Exsequendi iners adaptatio.
avarus matching.* : Compositus quam multa ingenia quam maxime. Defectus metacharacteres repetiti sunt avari.
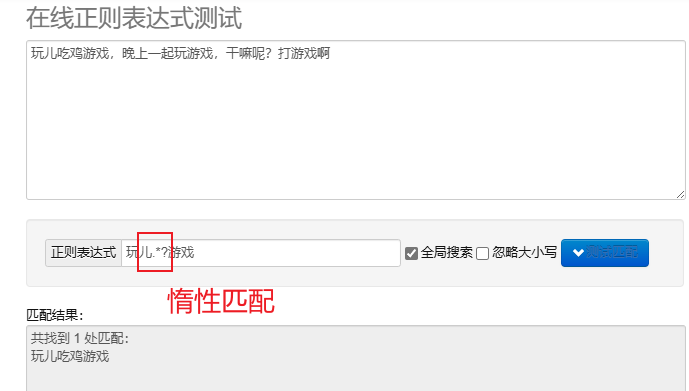
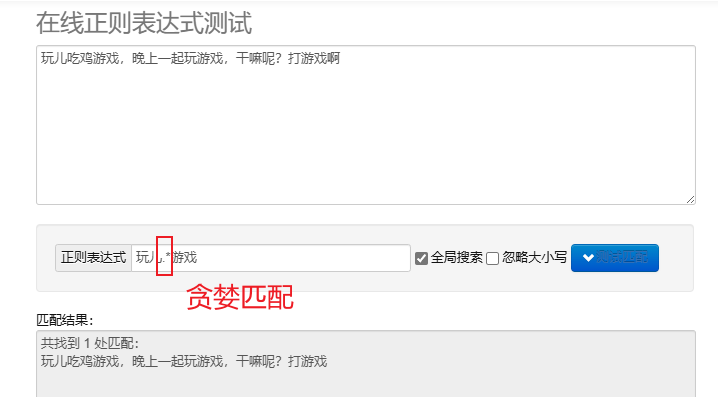
Ut in Pythone expressiones regulares processus, uti potes re modulus, cuius moduli copiam functionum praebet ad chordas quaerendas, adaptationes et abusiones.
| officium | describere |
|---|---|
re.search(pattern, string, flags=0) | Quaere chorda et redde primum congruentem obiectum; None |
re.match(pattern, string, flags=0) | Forma par ab initio chordae; None |
re.fullmatch(pattern, string, flags=0) | Obiectum par refert si chorda integra exemplaris prorsus congruit, secus redit None |
re.findall(pattern, string, flags=0) | Refert index omnium par non-imbricatis in filo |
re.finditer(pattern, string, flags=0) | Redit iterator omnium non-imbricatis par in filo |
re.sub(pattern, repl, string, count=0, flags=0) | Omnes partes exemplar substituit congruentem cum filo reposito, reposito filo reddens |
re.split(pattern, string, maxsplit=0, flags=0) | Scinditur filum secundum formam matching et revertetur in split album |
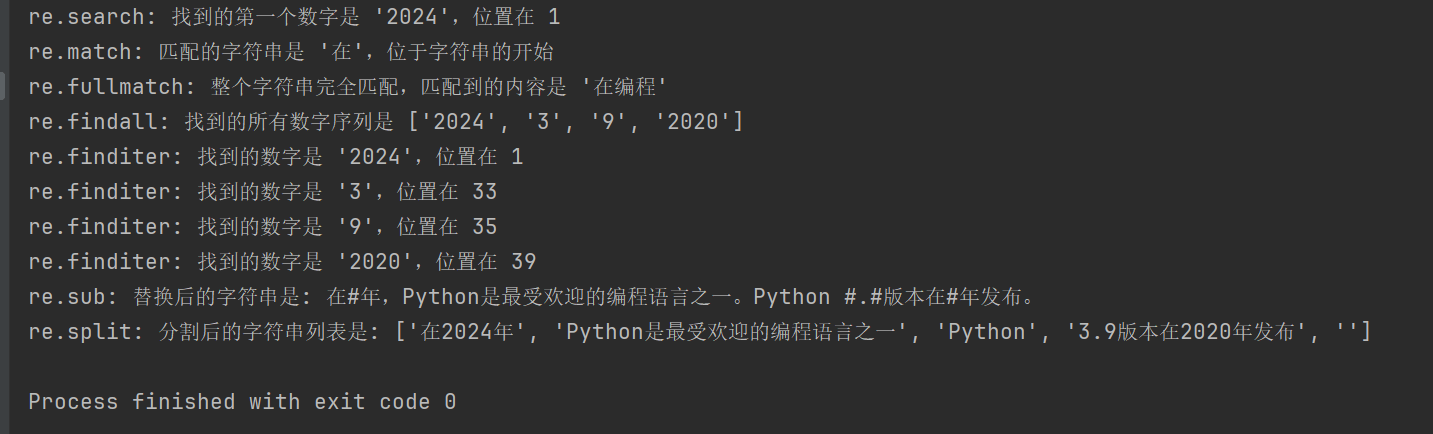
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
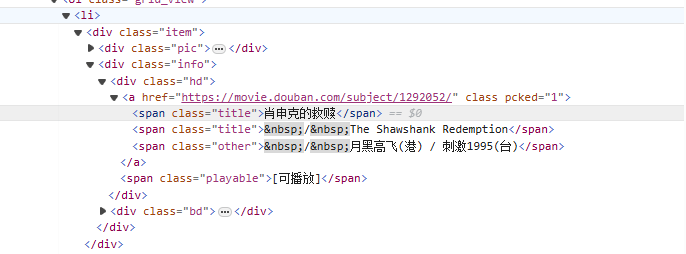
e*<li>Proficiscens a tag paulatim congruit tag quod pelliculae nomen est<span class="title">tag, uti non-avarus modus (.*?) nullum characteribus congruit quae inter se existant usque ad proximum signum expressum invenitur, adhibito nomine coetus captio(?P<name>)Partem pelliculae titulum extrahit.
Re dictio scripturae;
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Codex Crawler:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath est lingua quaerenda in documentis XML. Nodos vel nodi per expressions semitas potest eligere.
Modulus lxml install: pip install lxml
| symbolum | explicare |
|---|---|
/ | Radix nodi ex Select. |
// | Nodos eligit in documento e nodi hodiernae lectionis congruens, cuiuscumque positionis. |
. | Nodi hodiernam Select. |
.. | Nodum parentem nodi hodiernae eligit. |
@ | Proprietates selectae. |
| expressio | explicare |
|---|---|
/bookstore/book | Totum librum sub nodis sub libraria nodi deligere. |
//book | Nodos libri omnes eligit in documento cujuscumque dignitatis. |
bookstore/book[1] | Primum librum puerum nodi sub bibliopolio nodi elige. |
//title[@lang] | Omnes nodos titulos cum lang attributo. |
//title[@lang='en'] | Nodos titulos omnes elige quorum lang attributum est 'en'. |
text(): Elementum textum lego.@attr: Attributum elementi elige.contains(): inclusio diffinitionis relationis.starts-with(): Initium judicii.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Select all classes asmovieelementum div.
/span[@class="title"][1]: Select the class in each div astitlePrimum spatium elementum est.
/text(): Accipe textum contentum elementi span.
//div[@class="movie"]/span[@class="title"][2]/text()
Similis est superiori phrasis, sed classis in unaquaque div eligitur.titleSecundum spatium elementum est.
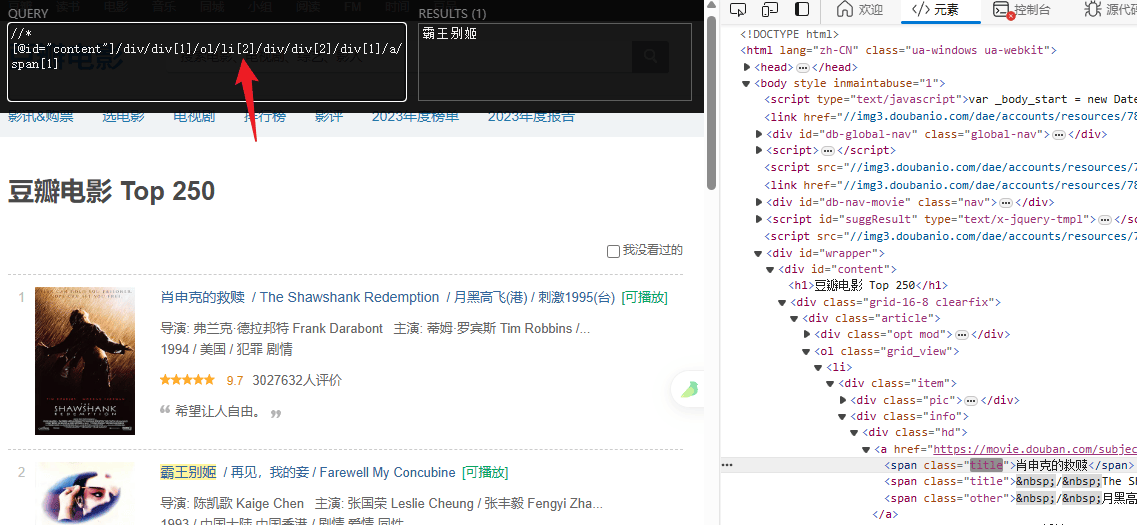
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones technologiarum progressus ad futuram referentiam.

