
Mi información de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Para analizar datos, además de la biblioteca BeautifulSoup anterior, existen dos métodos: expresiones regulares y Xpath.
Las expresiones regulares (RE para abreviar) son herramientas que se utilizan para describir y hacer coincidir patrones de cadenas.
Se utiliza ampliamente en procesamiento de texto, validación de datos, búsqueda y reemplazo de texto y otros escenarios. Las expresiones regulares utilizan una sintaxis especial que permite la coincidencia de patrones complejos en cadenas.
Prueba de expresión regular:Prueba de expresión regular en línea
Metacaracteres: símbolos especiales con significados fijos. Cada metacarácter coincide solo con una cadena de forma predeterminada y no puede coincidir con caracteres de nueva línea.
| Metacaracteres | describir | Ejemplo |
|---|---|---|
. | Coincide con cualquier carácter excepto nuevas líneas | a.b puede coincidira1b、acb |
w | Emparejar letras, números o guiones bajos | w+ fósforohello、world_123 |
s | Coincide con cualquier carácter de espacio en blanco | s+ Coincide con espacios, tabulaciones, etc. |
d | Números coincidentes | d+ fósforo123、456 |
n | Coincide con un carácter de nueva línea | hellonworld Coincidir con el carácter de nueva línea |
t | coincidir con un carácter de tabulación | hellotworld coincidir con el carácter de la pestaña |
^ | Coincide con el comienzo de una cadena | ^Hello fósforoHello cadena al principio |
$ | Haga coincidir el final de la cuerda | World$ fósforoWorld final de la cuerda |
W | Coincide con caracteres que no son letras, ni dígitos ni guiones bajos | W+ fósforo!@#、$%^ |
D | Coincidir caracteres no numéricos | D+ fósforoabc、XYZ |
S | Coincidir con caracteres que no sean espacios en blanco | S+ fósforohello、world123 |
| `un | B` | Coincidir personajes a o personajeb |
(...) | Captura una expresión entre paréntesis, que representa un grupo. | (abc) capturaabc |
[...] | Coincide con cualquier carácter entre corchetes | [abc] fósforoa、b oc |
[^...] | Coincide con cualquier carácter que no esté entre corchetes | [^abc] coincidir exceptoa、b、c Cualquier personaje que no sea |
Cuantificador: controla el número de apariciones del metacarácter anterior.
| cuantificador | describir |
|---|---|
* | Repetir cero o más veces |
+ | Repetir una o más veces |
? | Repetir cero o una vez |
{n} | repetir n veces |
{n,} | Repetir no más veces |
{n,m} | Repetir n a m veces |
emparejamiento perezoso.*? : Combina la menor cantidad de personajes posible.Después de repetir los metacaracteres, agregue? Implementar coincidencias diferidas.
coincidencia codiciosa.* : Combina tantos personajes como sea posible. Los metacaracteres repetidos predeterminados son codiciosos.
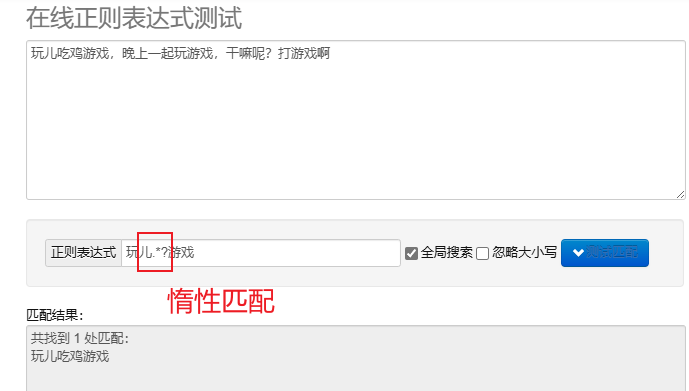
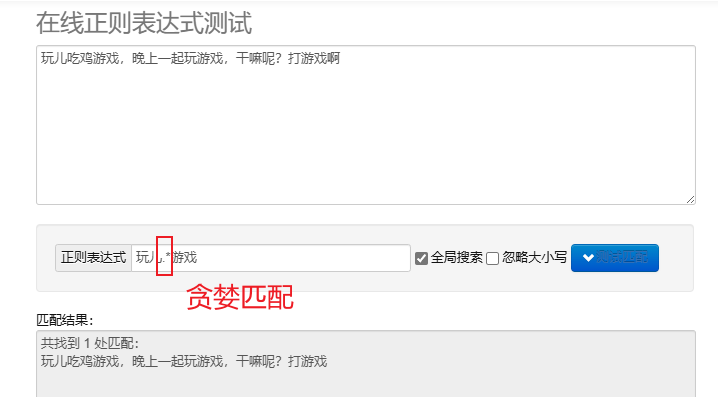
Para procesar expresiones regulares en Python, puedes usar re módulo, este módulo proporciona un conjunto de funciones para buscar, hacer coincidir y manipular cadenas.
| función | describir |
|---|---|
re.search(pattern, string, flags=0) | Busque una cadena y devuelva el primer objeto coincidente; si no hay ninguna coincidencia, devuelva; None |
re.match(pattern, string, flags=0) | Haga coincidir el patrón desde el principio de la cadena; si la coincidencia es exitosa, devuelva el objeto coincidente; de lo contrario, None |
re.fullmatch(pattern, string, flags=0) | Devuelve el objeto coincidente si toda la cadena coincide exactamente con el patrón; de lo contrario, devuelve None |
re.findall(pattern, string, flags=0) | Devuelve una lista de todas las coincidencias que no se superponen en una cadena |
re.finditer(pattern, string, flags=0) | Devuelve un iterador de todas las coincidencias que no se superponen en una cadena |
re.sub(pattern, repl, string, count=0, flags=0) | Reemplace todas las partes del patrón coincidente con la cadena de reemplazo, devolviendo la cadena reemplazada |
re.split(pattern, string, maxsplit=0, flags=0) | Divida la cadena según la coincidencia de patrones y devuelva la lista dividida |
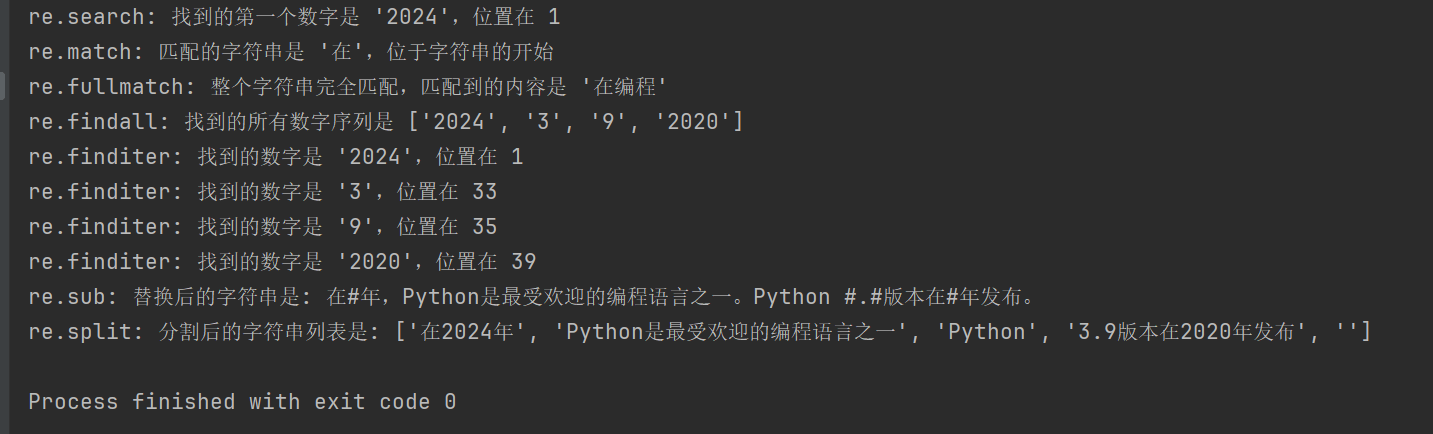
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
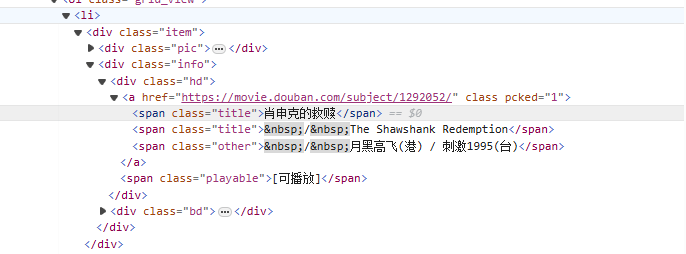
de<li>A partir de la etiqueta, haga coincidir gradualmente la etiqueta que contiene el nombre de la película.<span class="title">etiqueta, use el modo no codicioso (.*?) coincide con cualquier carácter que pueda existir en el medio hasta que se encuentre el siguiente token explícito, utilizando un grupo de captura con nombre(?P<name>)Extrae la parte del título de la película.
Re expresión escrita:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Código de rastreo:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
XPath es un lenguaje para buscar en documentos XML. Puede seleccionar nodos o conjuntos de nodos mediante expresiones de ruta. HTML es un subconjunto de XML.
Instale el módulo lxml: pip install lxml
| símbolo | explicar |
|---|---|
/ | Seleccione desde el nodo raíz. |
// | Selecciona nodos en el documento a partir del nodo actual que coincide con la selección, independientemente de su posición. |
. | Seleccione el nodo actual. |
.. | Selecciona el nodo principal del nodo actual. |
@ | Seleccione propiedades. |
| expresión | explicar |
|---|---|
/bookstore/book | Seleccione todos los subnodos de libros en el nodo de librería. |
//book | Selecciona todos los nodos del libro en el documento, independientemente de su posición. |
bookstore/book[1] | Seleccione el primer nodo secundario del libro debajo del nodo de la librería. |
//title[@lang] | Seleccione todos los nodos de título con atributo lang. |
//title[@lang='en'] | Seleccione todos los nodos de título cuyo atributo de idioma sea 'en'. |
text(): Seleccione el texto del elemento.@attr: Seleccione el atributo del elemento.contains(): Determinar la relación de inclusión.starts-with(): El comienzo del juicio.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Seleccione todas las clases comomovieelemento div.
/span[@class="title"][1]: Seleccione la clase en cada div comotitleEl primer elemento de tramo.
/text(): obtiene el contenido de texto del elemento span.
//div[@class="movie"]/span[@class="title"][2]/text()
Similar a la expresión anterior, pero se selecciona la clase en cada div.titleEl segundo elemento de tramo.
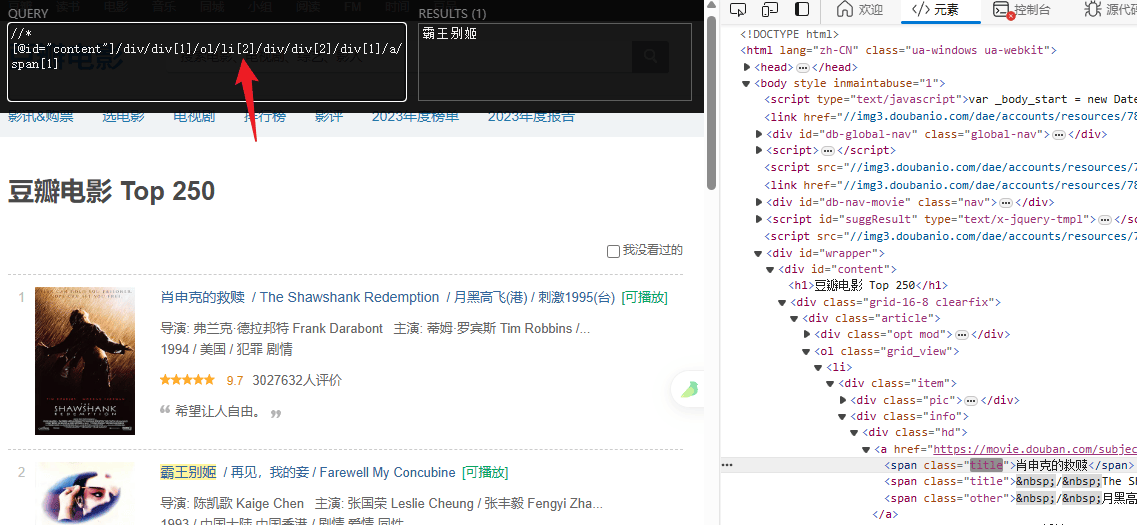
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]