2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Aiemman BeautifulSoup-kirjaston lisäksi tietojen jäsentämiseen on kaksi menetelmää: säännölliset lausekkeet ja Xpath.
Säännölliset lausekkeet (lyhyesti RE) ovat työkaluja, joita käytetään merkkijonomallien kuvaamiseen ja sovittamiseen.
Sitä käytetään laajasti tekstinkäsittelyssä, tietojen validoinnissa, tekstin haussa ja korvaamisessa ja muissa skenaarioissa. Säännölliset lausekkeet käyttävät erityistä syntaksia, joka mahdollistaa monimutkaisen kuvion sovituksen merkkijonoissa.
Säännöllisen lausekkeen testi:Online-säännöllinen lauseketesti
Metamerkit: Erikoissymbolit, joilla on kiinteä merkitys. Jokainen metamerkki vastaa oletusarvoisesti vain yhtä merkkijonoa, eikä se voi vastata rivinvaihtomerkkejä.
| Metahahmot | kuvata | Esimerkki |
|---|---|---|
. | Vastaa mitä tahansa merkkiä paitsi rivinvaihtoja | a.b voi sopiaa1b、acb |
w | Yhdistä kirjaimet, numerot tai alaviivat | w+ otteluhello、world_123 |
s | Vastaa mitä tahansa välilyöntiä | s+ Vastaa välilyöntejä, sarkaimia jne. |
d | Vastaa numeroita | d+ ottelu123、456 |
n | Vastaa rivinvaihtomerkkiä | hellonworld Yhdistä rivinvaihtomerkki |
t | vastaa sarkainmerkkiä | hellotworld vastaa sarkainmerkkiä |
^ | Vastaa merkkijonon alkua | ^Hello otteluHello merkkijono alussa |
$ | Yhdistä merkkijonon loppu | World$ otteluWorld merkkijonon loppu |
W | Vastaa muita kuin kirjaimia, ei-numeroita ja ei-alaviivoja merkkejä | W+ ottelu!@#、$%^ |
D | Vastaa ei-numeerisia merkkejä | D+ otteluabc、XYZ |
S | Käytä muita kuin välilyöntejä | S+ otteluhello、world123 |
| `a | b` | Yhdistä hahmoja a tai hahmob |
(...) | Sieppaa lausekkeen sulkeissa edustaen ryhmää | (abc) kaapataabc |
[...] | Vastaa mitä tahansa merkkiä hakasulkeissa | [abc] ottelua、b taic |
[^...] | Vastaa mitä tahansa merkkiä, jota ei ole suljettu hakasulkeisiin | [^abc] ottelu paitsia、b、c Mikä tahansa muu hahmo kuin |
Quantifier: ohjaa edellisen metamerkin esiintymisten määrää
| kvantori | kuvata |
|---|---|
* | Toista nolla tai useampia kertoja |
+ | Toista yksi tai useampia kertoja |
? | Toista nolla tai kerran |
{n} | Toista n kertaa |
{n,} | Toista n tai useammin |
{n,m} | Toista n - m kertaa |
laiska sovitus.*? : Yhdistä mahdollisimman vähän merkkejä.Lisää toistuvien metamerkkien jälkeen? Toteuta laiska sovitus.
ahne yhteensopivuus.* : Yhdistä mahdollisimman monta hahmoa. Oletuksena toistuvat metamerkit ovat ahneita.
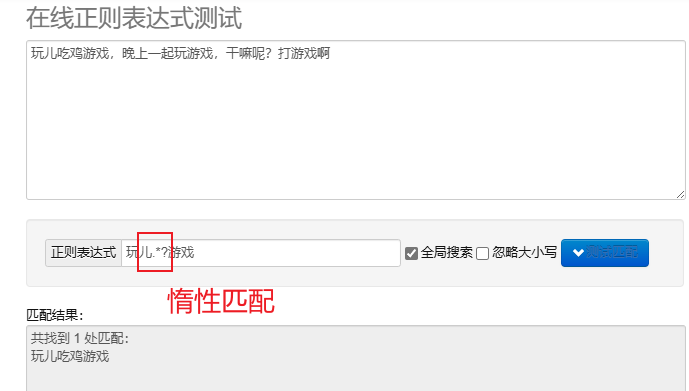
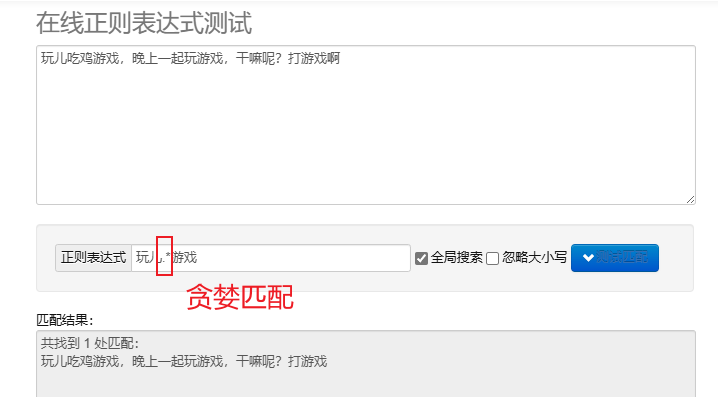
Voit käsitellä säännöllisiä lausekkeita Pythonissa käyttämällä re Tämä moduuli tarjoaa joukon toimintoja merkkijonojen etsimiseen, sovittamiseen ja käsittelyyn.
| toiminto | kuvata |
|---|---|
re.search(pattern, string, flags=0) | Hae merkkijonoa ja palauta ensimmäinen vastaava objekti, jos hakua ei löydy None |
re.match(pattern, string, flags=0) | Yhdistä kuvio merkkijonon alusta, jos täsmääminen onnistuu, palauta vastaava objekti None |
re.fullmatch(pattern, string, flags=0) | Palauttaa hakuobjektin, jos koko merkkijono vastaa kuviota tarkasti, muussa tapauksessa se palauttaa None |
re.findall(pattern, string, flags=0) | Palauttaa luettelon kaikista merkkijonon ei-päällekkäisistä vastaavuuksista |
re.finditer(pattern, string, flags=0) | Palauttaa iteraattorin kaikista merkkijonon ei-päällekkäisistä osumista |
re.sub(pattern, repl, string, count=0, flags=0) | Vaihda kaikki vastaavan kuvion osat korvaavalla merkkijonolla ja palauta korvattu merkkijono |
re.split(pattern, string, maxsplit=0, flags=0) | Jaa merkkijono kaavavastaavuuden perusteella ja palauta jakoluettelo |
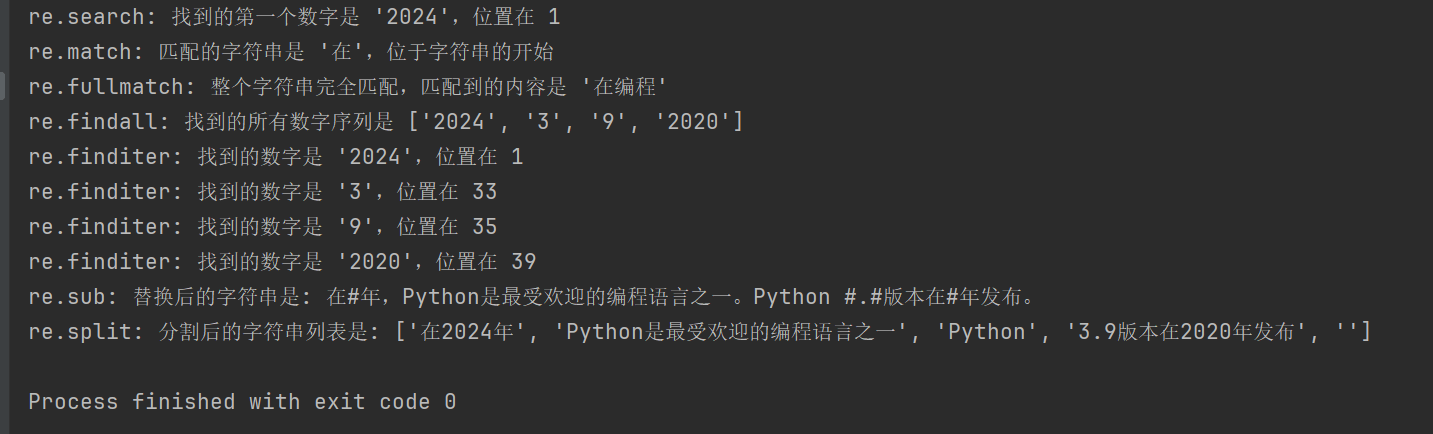
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
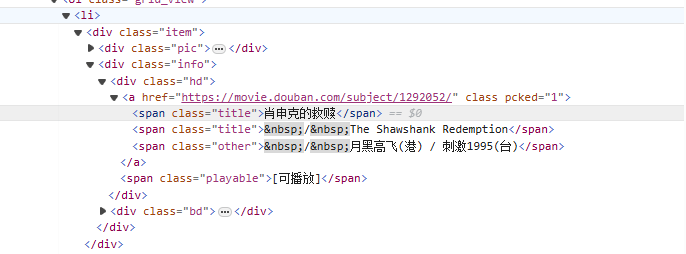
alkaen<li>Aloita tunnisteesta, yhdistä asteittain elokuvan nimen sisältävään tagiin<span class="title">tag, käytä ei-ahnetilaa (.*?) vastaa mitä tahansa merkkejä, jotka voivat olla niiden välissä, kunnes seuraava eksplisiittinen merkki löytyy, käyttämällä nimettyä kaappausryhmää(?P<name>)Pura elokuvan nimiosa.
Re ilmaisun kirjoittaminen:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Indeksointikoodi:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath on kieli XML-dokumenteista etsimiseen. Se voi valita solmuja tai solmujoukkoja polkulausekkeiden avulla.
Asenna lxml-moduuli: pip install lxml
| symboli | selittää |
|---|---|
/ | Valitse juurisolmusta. |
// | Valitsee asiakirjan solmut nykyisestä valintaa vastaavasta solmusta niiden sijainnista riippumatta. |
. | Valitse nykyinen solmu. |
.. | Valitsee nykyisen solmun pääsolmun. |
@ | Valitse ominaisuudet. |
| ilmaisu | selittää |
|---|---|
/bookstore/book | Valitse kaikki kirjan alisolmut kirjakauppasolmun alta. |
//book | Valitsee asiakirjan kaikki kirjasolmut niiden sijainnista riippumatta. |
bookstore/book[1] | Valitse ensimmäinen kirjan alisolmu kirjakauppasolmun alta. |
//title[@lang] | Valitse kaikki otsikon solmut, joissa on lang-attribuutti. |
//title[@lang='en'] | Valitse kaikki otsikkosolmut, joiden lang-attribuutti on "en". |
text(): Valitse elementin teksti.@attr: Valitse elementin attribuutti.contains(): Määritä inkluusiosuhde.starts-with(): Tuomion alku.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Valitse kaikki luokat nimellämoviediv-elementti.
/span[@class="title"][1]: Valitse luokka kussakin div astitleEnsimmäinen jänne-elementti.
/text(): Hae span-elementin tekstisisältö.
//div[@class="movie"]/span[@class="title"][2]/text()
Samanlainen kuin yllä oleva lauseke, mutta kunkin div:n luokka on valittu.titleToinen jänne-elementti.
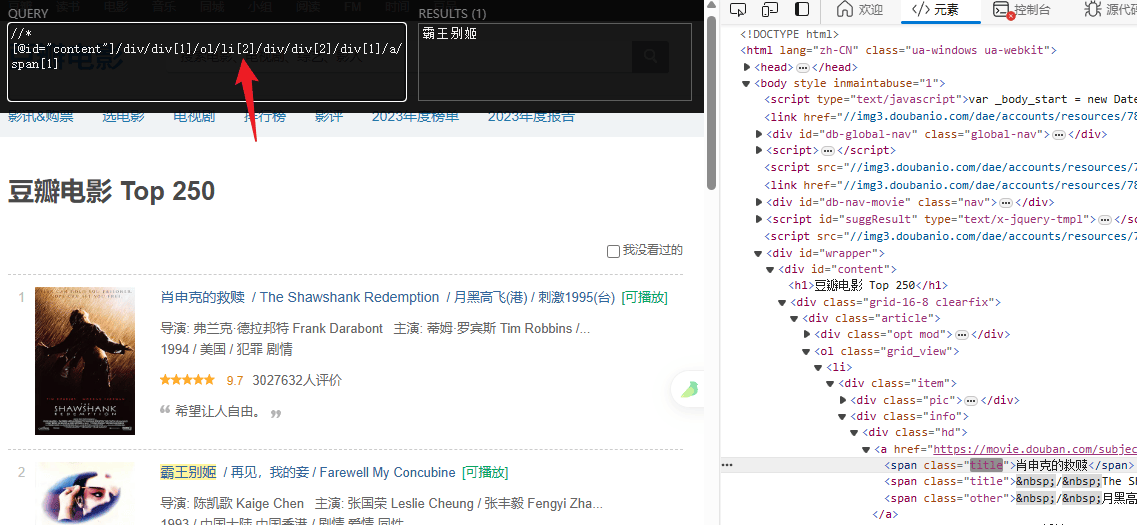
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin tässä Kehittäjän dokumentaatioasema, jossa voit ja teknologian kehittämisen ongelman myöhempää käyttöä varten

