
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Untuk mengurai data, selain perpustakaan BeautifulSoup sebelumnya, ada dua metode: ekspresi reguler dan Xpath.
Ekspresi reguler (singkatnya RE) adalah alat yang digunakan untuk mendeskripsikan dan mencocokkan pola string.
Ini banyak digunakan dalam pemrosesan teks, validasi data, pencarian dan penggantian teks, dan skenario lainnya. Ekspresi reguler menggunakan sintaks khusus yang memungkinkan pencocokan pola kompleks pada string.
Tes ekspresi reguler:Tes ekspresi reguler online
Metakarakter: Simbol khusus dengan makna tetap. Setiap metakarakter hanya cocok dengan satu string secara default dan tidak dapat cocok dengan karakter baris baru.
| Metakarakter | menggambarkan | Contoh |
|---|---|---|
. | Cocok dengan karakter apa pun kecuali baris baru | a.b bisa cocoka1b、acb |
w | Cocokkan huruf, angka, atau garis bawah | w+ cocokhello、world_123 |
s | Cocok dengan karakter spasi apa pun | s+ Mencocokkan spasi, tab, dll. |
d | Nomor yang cocok | d+ cocok123、456 |
n | Cocok dengan karakter baris baru | hellonworld Cocokkan karakter baris baru |
t | cocok dengan karakter tab | hellotworld karakter tab yang cocok |
^ | Cocok dengan awal string | ^Hello cocokHello tali di awal |
$ | Cocokkan ujung senarnya | World$ cocokWorld akhir string |
W | Cocok dengan karakter bukan huruf, bukan angka, dan bukan garis bawah | W+ cocok!@#、$%^ |
D | Cocokkan karakter non-numerik | D+ cocokabc、XYZ |
S | Cocokkan karakter non-spasi | S+ cocokhello、world123 |
| 'sebuah | aku | Cocokkan karakter a atau karakterb |
(...) | Menangkap ekspresi dalam tanda kurung, mewakili suatu grup | (abc) menangkapabc |
[...] | Cocok dengan karakter apa pun dalam tanda kurung siku | [abc] cocoka、b atauc |
[^...] | Cocok dengan karakter apa pun yang tidak diapit tanda kurung siku | [^abc] cocok kecualia、b、c Karakter apa pun selain |
Quantifier: mengontrol jumlah kemunculan metakarakter sebelumnya
| pembilang | menggambarkan |
|---|---|
* | Ulangi nol kali atau lebih |
+ | Ulangi satu kali atau lebih |
? | Ulangi nol atau satu kali |
{n} | Ulangi sebanyak n kali |
{n,} | Ulangi sebanyak n kali atau lebih |
{n,m} | Ulangi n hingga m kali |
malas mencocokkan.*? : Cocokkan karakter sesedikit mungkin.Setelah metakarakter berulang ditambahkan? Terapkan pencocokan malas.
pencocokan serakah.* : Cocokkan karakter sebanyak mungkin. Metakarakter berulang default adalah serakah.
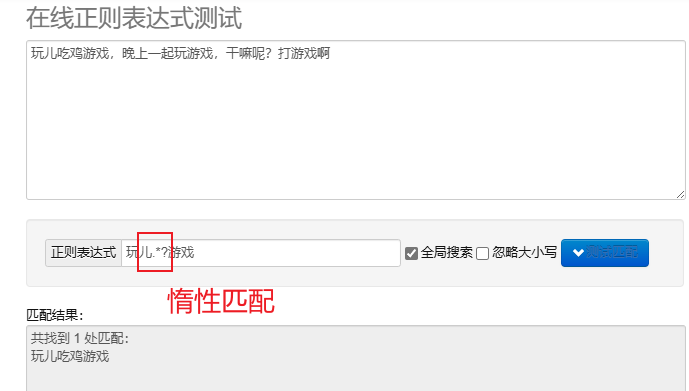
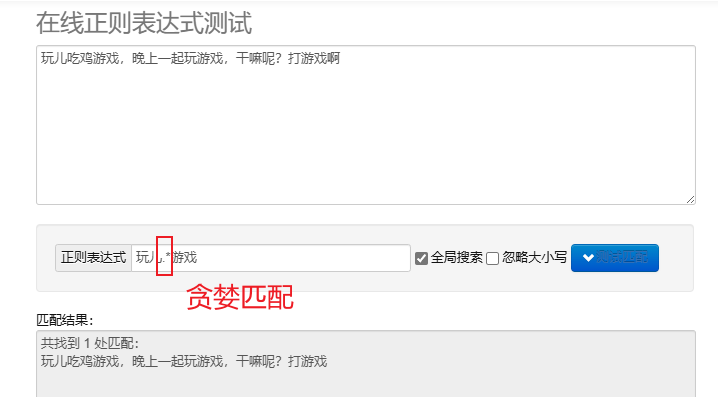
Untuk memproses ekspresi reguler dengan Python, Anda dapat menggunakan re modul, modul ini menyediakan serangkaian fungsi untuk mencari, mencocokkan, dan memanipulasi string.
| fungsi | menggambarkan |
|---|---|
re.search(pattern, string, flags=0) | Cari string dan kembalikan objek pertama yang cocok; jika tidak ada yang cocok, kembalikan None |
re.match(pattern, string, flags=0) | Cocokkan pola dari awal string; jika pencocokan berhasil, kembalikan objek yang cocok, jika tidak None |
re.fullmatch(pattern, string, flags=0) | Mengembalikan objek yang cocok jika seluruh string sama persis dengan polanya, jika tidak maka akan kembali None |
re.findall(pattern, string, flags=0) | Mengembalikan daftar semua kecocokan yang tidak tumpang tindih dalam sebuah string |
re.finditer(pattern, string, flags=0) | Mengembalikan iterator dari semua kecocokan yang tidak tumpang tindih dalam sebuah string |
re.sub(pattern, repl, string, count=0, flags=0) | Ganti semua bagian pola yang cocok dengan senar pengganti, kembalikan senar yang diganti |
re.split(pattern, string, maxsplit=0, flags=0) | Pisahkan string berdasarkan pencocokan pola dan kembalikan daftar pemisahan |
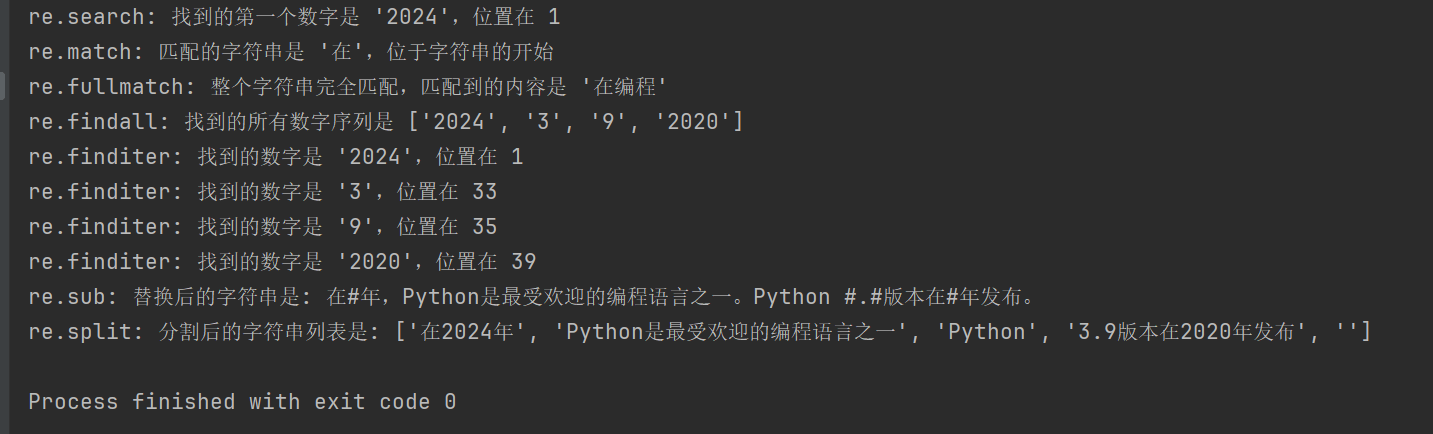
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
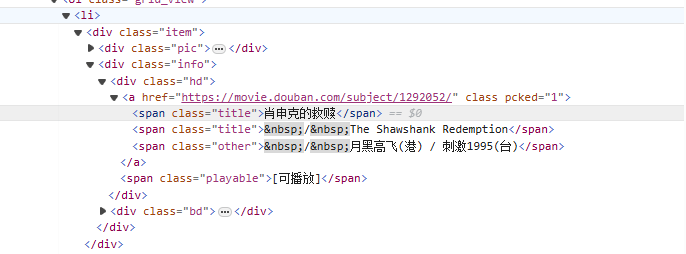
dari<li>Mulai dari tag, bertahap dicocokkan dengan tag yang berisi nama film<span class="title">tag, gunakan mode tidak serakah (.*?) cocok dengan karakter apa pun yang mungkin ada di antaranya hingga token eksplisit berikutnya ditemukan, menggunakan grup tangkapan bernama(?P<name>)Ekstrak bagian judul film.
Penulisan ekspresi ulang:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Kode perayap:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath adalah bahasa untuk mencari dalam dokumen XML. Xpath dapat memilih node atau kumpulan node melalui ekspresi jalur.
Instal modul lxml: pip install lxml
| simbol | menjelaskan |
|---|---|
/ | Pilih dari simpul akar. |
// | Memilih node dalam dokumen dari node saat ini yang cocok dengan pilihan, terlepas dari posisinya. |
. | Pilih node saat ini. |
.. | Memilih node induk dari node saat ini. |
@ | Pilih properti. |
| ekspresi | menjelaskan |
|---|---|
/bookstore/book | Pilih semua sub-node buku di bawah node toko buku. |
//book | Memilih semua node buku dalam dokumen terlepas dari posisinya. |
bookstore/book[1] | Pilih node anak buku pertama di bawah node toko buku. |
//title[@lang] | Pilih semua node judul dengan atribut lang. |
//title[@lang='en'] | Pilih semua node judul yang atribut langnya 'en'. |
text(): Pilih teks elemen.@attr: Pilih atribut elemen.contains(): Menentukan hubungan inklusi.starts-with(): Awal penghakiman.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Pilih semua kelas sebagaimovieelemen div.
/span[@class="title"][1]: Pilih kelas di setiap div sebagaititleElemen rentang pertama.
/text(): Dapatkan konten teks elemen span.
//div[@class="movie"]/span[@class="title"][2]/text()
Mirip dengan ekspresi di atas, tetapi kelas di setiap div dipilih.titleElemen rentang kedua.
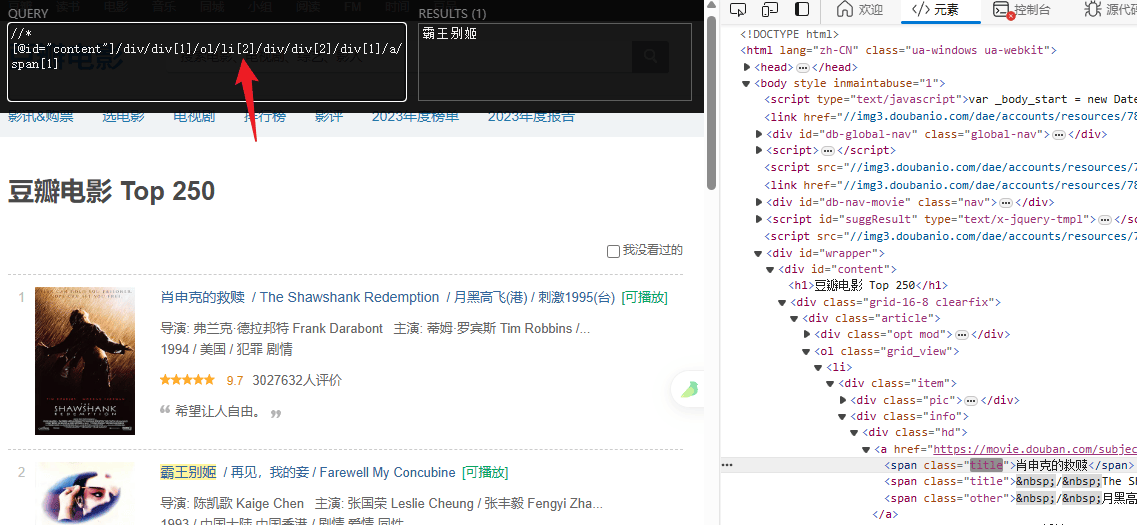
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Saya telah memberikan banyak kontribusi di bidang dokumentasi pengembang open source untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang.

Surat[email protected]