2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Pour analyser les données, en plus de la bibliothèque BeautifulSoup précédente, il existe deux méthodes : les expressions régulières et Xpath.
Les expressions régulières (RE en abrégé) sont des outils utilisés pour décrire et faire correspondre des modèles de chaînes.
Il est largement utilisé dans le traitement de texte, la validation de données, la recherche et le remplacement de texte et d'autres scénarios. Les expressions régulières utilisent une syntaxe spéciale pour effectuer une correspondance de modèles complexes sur des chaînes.
Test d'expression régulière :Test d'expression régulière en ligne
Métacaractères : symboles spéciaux avec des significations fixes. Chaque métacaractère ne correspond qu'à une seule chaîne par défaut et ne peut pas correspondre aux caractères de nouvelle ligne.
| métacaractères | décrire | Exemple |
|---|---|---|
. | Correspond à n'importe quel caractère sauf les nouvelles lignes | a.b peut correspondrea1b、acb |
w | Faites correspondre des lettres, des chiffres ou des traits de soulignement | w+ correspondrehello、world_123 |
s | Correspond à n'importe quel caractère d'espacement | s+ Correspond aux espaces, aux tabulations, etc. |
d | Faire correspondre les numéros | d+ correspondre123、456 |
n | Correspond à un caractère de nouvelle ligne | hellonworld Faire correspondre le caractère de nouvelle ligne |
t | faire correspondre un caractère de tabulation | hellotworld faire correspondre le caractère de tabulation |
^ | Correspond au début d'une chaîne | ^Hello correspondreHello chaîne au début |
$ | Faire correspondre la fin de la chaîne | World$ correspondreWorld fin de chaîne |
W | Correspond aux caractères autres que des lettres, des chiffres et des traits de soulignement | W+ correspondre!@#、$%^ |
D | Faire correspondre les caractères non numériques | D+ correspondreabc、XYZ |
S | Faire correspondre les caractères autres que les espaces | S+ correspondrehello、world123 |
| `un | b` | Faire correspondre les personnages a ou un personnageb |
(...) | Capture une expression entre parenthèses, représentant un groupe | (abc) capturerabc |
[...] | Correspond à n'importe quel caractère entre crochets | [abc] correspondrea、b ouc |
[^...] | Correspond à tout caractère non placé entre crochets | [^abc] match saufa、b、c Tout personnage autre que |
Quantificateur : contrôle le nombre d'occurrences du métacaractère précédent
| quantificateur | décrire |
|---|---|
* | Répétez zéro ou plusieurs fois |
+ | Répéter une ou plusieurs fois |
? | Répétez zéro ou une fois |
{n} | Répéter n fois |
{n,} | Répéter n fois ou plus |
{n,m} | Répéter n à m fois |
correspondance paresseuse.*? : Faites correspondre le moins de caractères possible.Après avoir ajouté des métacaractères répétés? Implémentez une correspondance paresseuse.
correspondance gourmande.* : Faites correspondre autant de caractères que possible. Les métacaractères répétés par défaut sont gourmands.
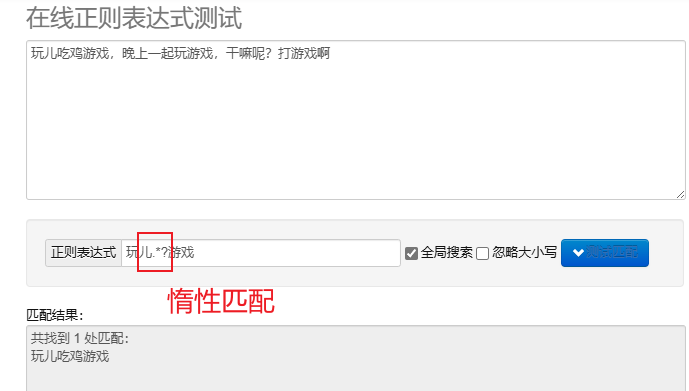
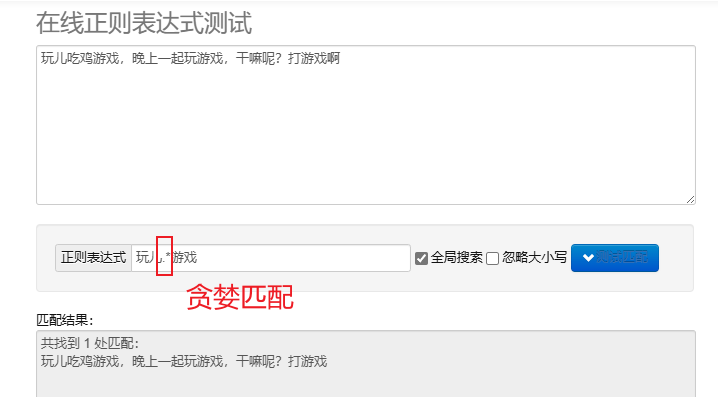
Pour traiter des expressions régulières en Python, vous pouvez utiliser re module, ce module fournit un ensemble de fonctions pour rechercher, faire correspondre et manipuler des chaînes.
| fonction | décrire |
|---|---|
re.search(pattern, string, flags=0) | Rechercher une chaîne et renvoyer le premier objet correspondant ; s'il n'y a pas de correspondance, renvoyer None |
re.match(pattern, string, flags=0) | Faites correspondre le modèle depuis le début de la chaîne ; si la correspondance réussit, renvoyez l'objet correspondant, sinon None |
re.fullmatch(pattern, string, flags=0) | Renvoie l'objet match si la chaîne entière correspond exactement au modèle, sinon il renvoie None |
re.findall(pattern, string, flags=0) | Renvoie une liste de toutes les correspondances qui ne se chevauchent pas dans une chaîne |
re.finditer(pattern, string, flags=0) | Renvoie un itérateur de toutes les correspondances qui ne se chevauchent pas dans une chaîne |
re.sub(pattern, repl, string, count=0, flags=0) | Remplace toutes les parties du modèle correspondant par la chaîne de remplacement, renvoyant la chaîne remplacée |
re.split(pattern, string, maxsplit=0, flags=0) | Divisez la chaîne en fonction de la correspondance de modèle et renvoyez la liste fractionnée |
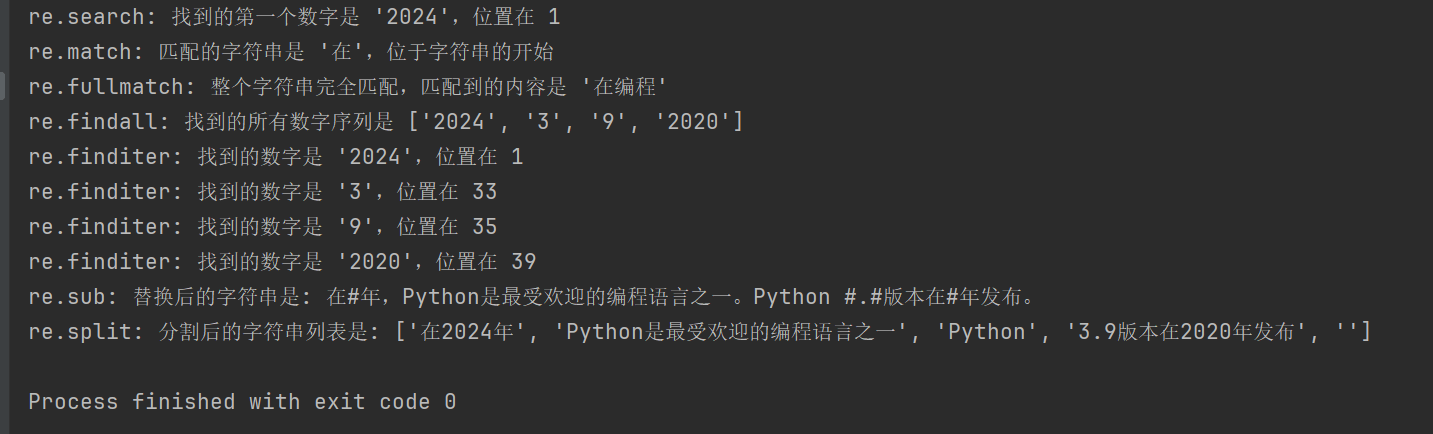
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
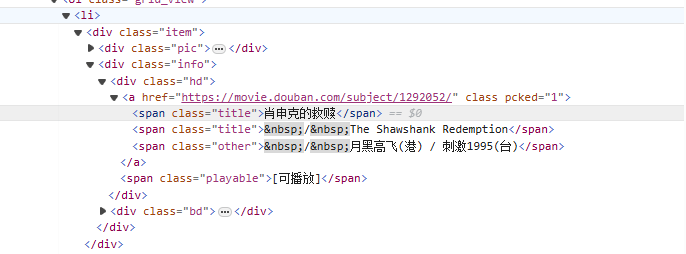
depuis<li>En partant du tag, faites correspondre progressivement le tag contenant le nom du film<span class="title">tag, utilisez le mode non gourmand (.*?) correspond à tous les caractères pouvant exister entre les deux jusqu'à ce que le prochain jeton explicite soit trouvé, en utilisant un groupe de capture nommé(?P<name>)Extrayez la partie titre du film.
Réécriture d'expression :
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Code du robot :
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath est un langage de recherche dans les documents XML. Il peut sélectionner des nœuds ou des ensembles de nœuds via des expressions de chemin. HTML est un sous-ensemble de XML.
Installez le module lxml : pip install lxml
| symbole | expliquer |
|---|---|
/ | Sélectionnez à partir du nœud racine. |
// | Sélectionne les nœuds du document à partir du nœud actuel correspondant à la sélection, quelle que soit leur position. |
. | Sélectionnez le nœud actuel. |
.. | Sélectionne le nœud parent du nœud actuel. |
@ | Sélectionnez les propriétés. |
| expression | expliquer |
|---|---|
/bookstore/book | Sélectionnez tous les sous-nœuds de livre sous le nœud de librairie. |
//book | Sélectionne tous les nœuds de livre dans le document, quelle que soit leur position. |
bookstore/book[1] | Sélectionnez le premier nœud enfant du livre sous le nœud librairie. |
//title[@lang] | Sélectionnez tous les nœuds de titre avec l'attribut lang. |
//title[@lang='en'] | Sélectionnez tous les nœuds de titre dont l'attribut lang est « en ». |
text(): Sélectionnez le texte de l'élément.@attr: Sélectionnez l'attribut de l'élément.contains(): Déterminer la relation d’inclusion.starts-with(): Le début du jugement.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Sélectionnez toutes les classes commemovieélément div.
/span[@class="title"][1]: Sélectionnez la classe dans chaque div commetitleLe premier élément span.
/text(): Obtenez le contenu textuel de l’élément span.
//div[@class="movie"]/span[@class="title"][2]/text()
Semblable à l’expression ci-dessus, mais la classe de chaque div est sélectionnée.titleLe deuxième élément de travée.
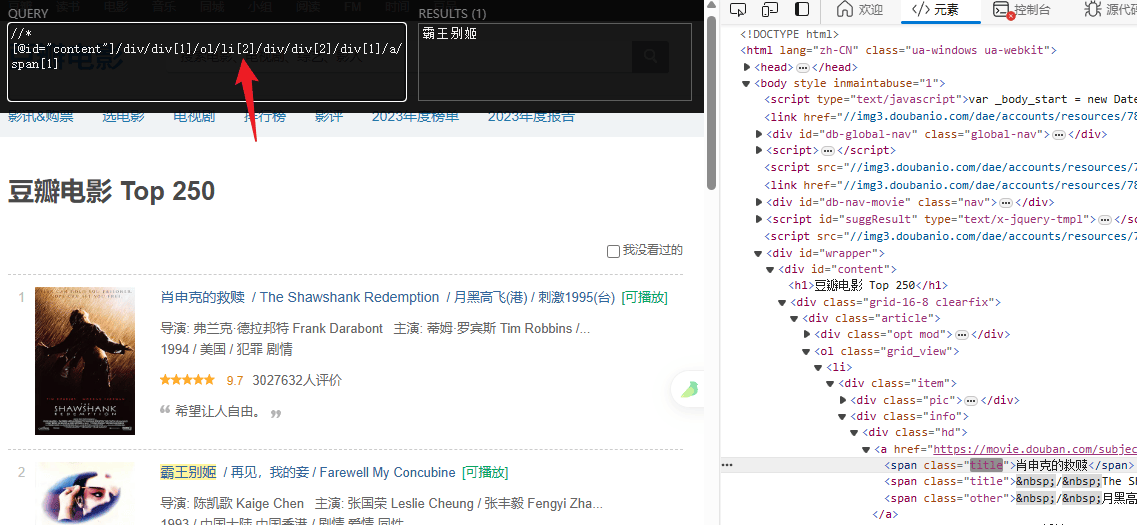
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

