
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
データを解析するには、以前の BeautifulSoup ライブラリに加えて、正規表現と Xpath の 2 つの方法があります。
正規表現 (略して RE) は、文字列パターンを記述して照合するために使用されるツールです。
テキスト処理、データ検証、テキスト検索と置換、その他のシナリオで広く使用されています。正規表現では、文字列に対する複雑なパターン マッチングを可能にする特別な構文が使用されます。
正規表現テスト:オンライン正規表現テスト
メタキャラクター: 固定された意味を持つ特別な記号。各メタキャラクターは、デフォルトでは 1 つの文字列のみと一致し、改行文字と一致することはできません。
| メタキャラクター | 説明する | 例 |
|---|---|---|
. | 改行を除く任意の文字と一致します | a.b 一致することができますa1b、acb |
w | 文字、数字、またはアンダースコアの一致 | w+ マッチhello、world_123 |
s | 任意の空白文字と一致します | s+ スペース、タブなどと一致します。 |
d | 番号を一致させる | d+ マッチ123、456 |
n | 改行文字と一致します | hellonworld 改行文字と一致する |
t | タブ文字と一致する | hellotworld タブ文字と一致する |
^ | 文字列の先頭と一致します | ^Hello マッチHello 先頭の文字列 |
$ | 文字列の末尾と一致する | World$ マッチWorld 文字列の終わり |
W | 文字、数字、アンダースコア以外の文字と一致します | W+ マッチ!@#、$%^ |
D | 数字以外の文字と一致する | D+ マッチabc、XYZ |
S | 空白以外の文字と一致する | S+ マッチhello、world123 |
| `a | b` | 文字を一致させる a またはキャラクターb |
(...) | グループを表す括弧内の式をキャプチャします。 | (abc) 捕獲abc |
[...] | 角括弧内の任意の文字と一致します | [abc] マッチa、b またはc |
[^...] | 角括弧で囲まれていない任意の文字と一致します | [^abc] 以外と一致するa、b、c 以外のキャラクター |
数量子: 先行するメタキャラクターの出現数を制御します。
| 数量詞 | 説明する |
|---|---|
* | 0 回以上繰り返します |
+ | 1 回以上繰り返します |
? | 0 回または 1 回繰り返す |
{n} | n回繰り返す |
{n,} | n回以上繰り返す |
{n,m} | n回からm回繰り返します |
遅延マッチング.*? : できるだけ少ない文字と一致します。メタキャラクターを繰り返した後に追加? 遅延マッチングを実装します。
貪欲なマッチング.* : できるだけ多くの文字に一致します。デフォルトの反復メタキャラクターは貪欲です。
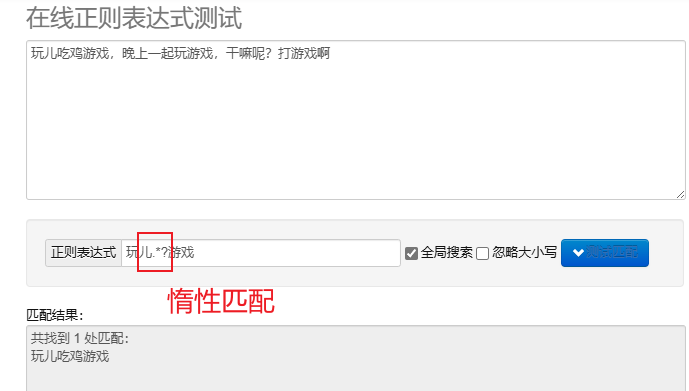
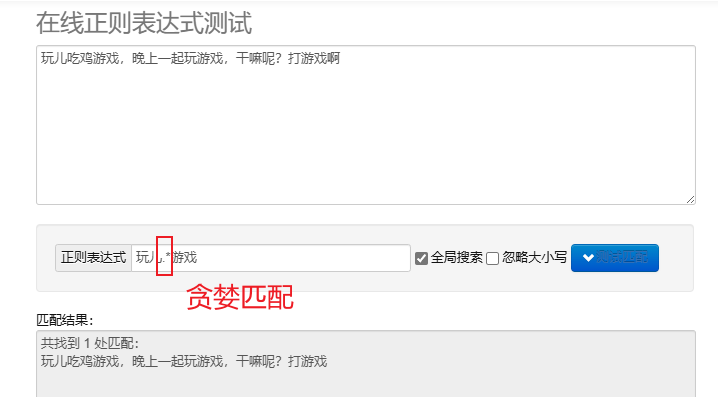
Python で正規表現を処理するには、次を使用できます。 re モジュールでは、このモジュールは文字列の検索、照合、および操作のための一連の関数を提供します。
| 関数 | 説明する |
|---|---|
re.search(pattern, string, flags=0) | 文字列を検索し、最初に一致したオブジェクトを返します。一致しない場合は戻ります。 None |
re.match(pattern, string, flags=0) | 文字列の先頭からパターンを照合し、一致した場合は一致したオブジェクトを返します。そうでない場合は、一致するオブジェクトを返します。 None |
re.fullmatch(pattern, string, flags=0) | 文字列全体がパターンに正確に一致する場合は一致オブジェクトを返し、それ以外の場合は一致オブジェクトを返します。 None |
re.findall(pattern, string, flags=0) | 文字列内の重複しないすべての一致のリストを返します。 |
re.finditer(pattern, string, flags=0) | 文字列内の重複しないすべての一致の反復子を返します。 |
re.sub(pattern, repl, string, count=0, flags=0) | 一致するパターンのすべての部分を置換文字列で置換し、置換された文字列を返します。 |
re.split(pattern, string, maxsplit=0, flags=0) | パターンマッチングに基づいて文字列を分割し、分割リストを返します。 |
import re
# 示例文本
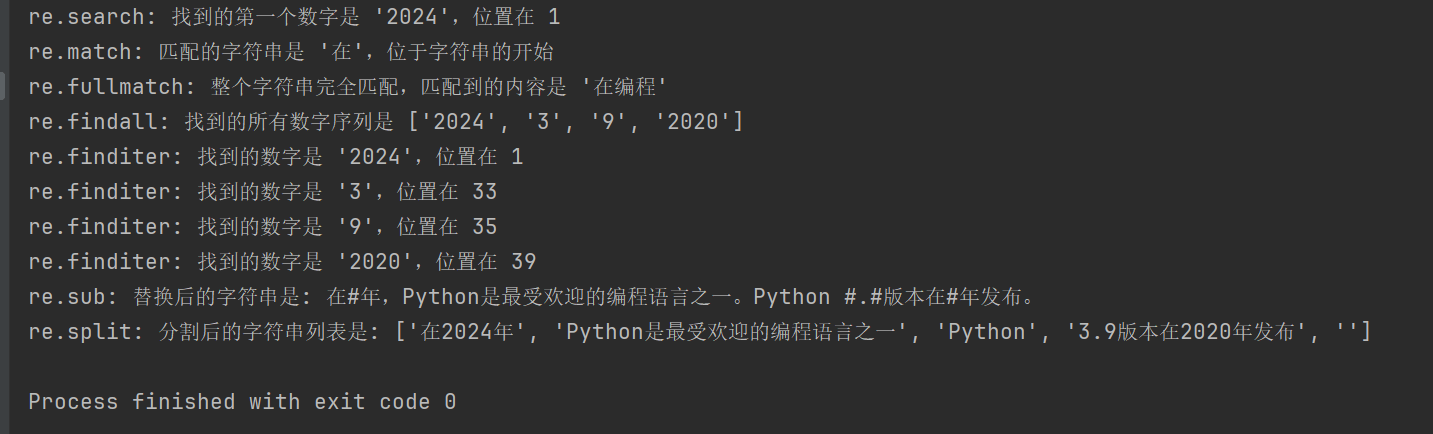
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
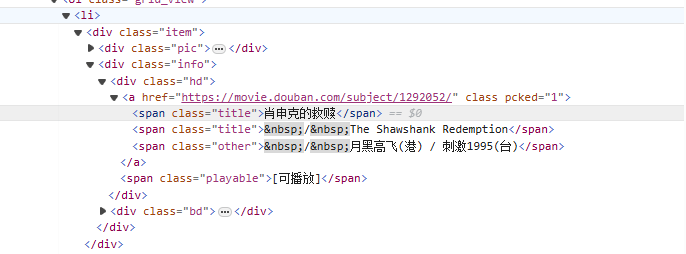
から<li>タグから始まり、徐々に動画名が含まれるタグと一致します<span class="title">タグ、非貪欲モードを使用 (.*?) は、名前付きキャプチャ グループを使用して、次の明示的なトークンが見つかるまで、間に存在する可能性のある任意の文字と一致します。(?P<name>)映画のタイトル部分を抽出します。
式の書き方について:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
クローラーコード:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath は、XML ドキュメント内を検索するための言語であり、HTML は XML のサブセットです。
lxml モジュールをインストールします。 pip install lxml
| シンボル | 説明する |
|---|---|
/ | ルートノードから選択します。 |
// | 位置に関係なく、選択内容に一致する現在のノードからドキュメント内のノードを選択します。 |
. | 現在のノードを選択します。 |
.. | 現在のノードの親ノードを選択します。 |
@ | プロパティを選択します。 |
| 表現 | 説明する |
|---|---|
/bookstore/book | 書店ノードの下にあるすべての本のサブノードを選択します。 |
//book | 位置に関係なく、ドキュメント内のすべてのブック ノードを選択します。 |
bookstore/book[1] | 書店ノードの下にある最初の本の子ノードを選択します。 |
//title[@lang] | lang 属性を持つすべてのタイトル ノードを選択します。 |
//title[@lang='en'] | lang 属性が「en」であるタイトル ノードをすべて選択します。 |
text(): 要素のテキストを選択します。@attr: 要素の属性を選択します。contains():包含関係を判定します。starts-with():審判の始まり。from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: すべてのクラスを次のように選択しますmoviediv要素。
/span[@class="title"][1]: 各 div のクラスを次のように選択します。title最初のスパン要素。
/text():span要素のテキスト内容を取得します。
//div[@class="movie"]/span[@class="title"][2]/text()
上の式と似ていますが、各 div のクラスが選択されます。title2 番目のスパン要素。
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
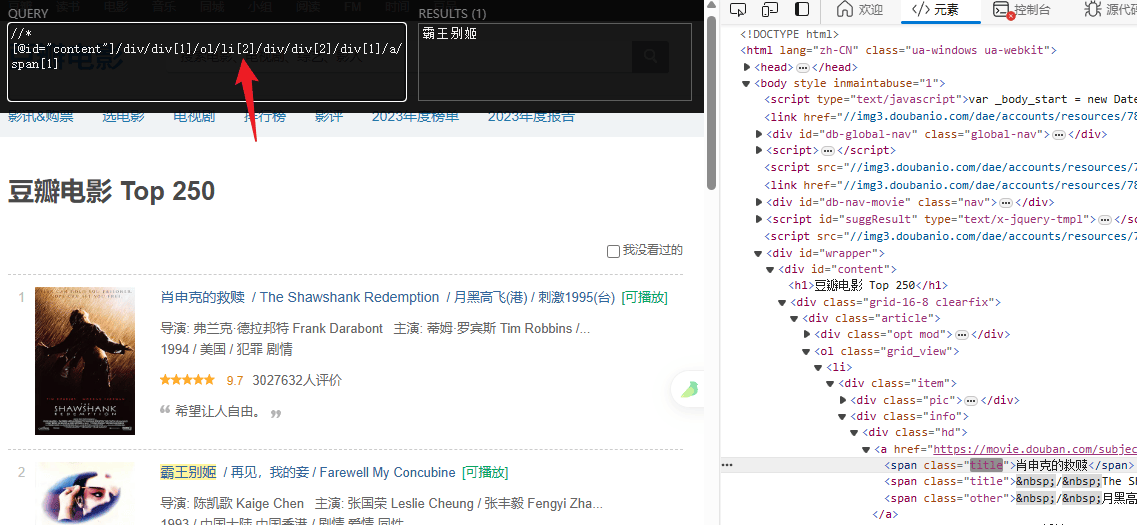
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

彼は 30 年以上テクノロジーの研究に専念しており、Java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: