
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Для парсинга данных, помимо предыдущей библиотеки BeautifulSoup, есть два метода: регулярные выражения и Xpath.
Регулярные выражения (сокращенно RE) — это инструменты, используемые для описания и сопоставления строковых шаблонов.
Он широко используется при обработке текста, проверке данных, поиске и замене текста и в других сценариях. Регулярные выражения используют специальный синтаксис, который обеспечивает сопоставление строк по сложному шаблону.
Проверка регулярного выражения:Онлайн-тест регулярных выражений
Метасимволы: специальные символы с фиксированным значением. По умолчанию каждый метасимвол соответствует только одной строке и не может соответствовать символам новой строки.
| Метасимволы | описывать | Пример |
|---|---|---|
. | Соответствует любому символу, кроме новой строки. | a.b может соответствоватьa1b、acb |
w | Сопоставление букв, цифр или подчеркиваний | w+ соответствоватьhello、world_123 |
s | Соответствует любому символу пробела | s+ Соответствует пробелам, табуляциям и т. д. |
d | Номера совпадений | d+ соответствовать123、456 |
n | Соответствует символу новой строки | hellonworld Соответствовать символу новой строки |
t | соответствовать символу табуляции | hellotworld совпадение с символом табуляции |
^ | Соответствует началу строки | ^Hello соответствоватьHello строка в начале |
$ | Сопоставить конец строки | World$ соответствоватьWorld конец строки |
W | Соответствует символам, не являющимся буквами, цифрами и символами без подчеркивания. | W+ соответствовать!@#、$%^ |
D | Сопоставление нечисловых символов | D+ соответствоватьabc、XYZ |
S | Сопоставление символов без пробелов | S+ соответствоватьhello、world123 |
| `а | б` | Сопоставление символов a или персонажb |
(...) | Захватывает выражение в круглых скобках, представляющее группу. | (abc) захватыватьabc |
[...] | Соответствует любому символу в квадратных скобках. | [abc] соответствоватьa、b илиc |
[^...] | Соответствует любому символу, не заключенному в квадратные скобки. | [^abc] совпадение, кромеa、b、c Любой персонаж, кроме |
Квантор: контролирует количество вхождений предыдущего метасимвола.
| квантификатор | описывать |
|---|---|
* | Повторить ноль или более раз |
+ | Повторите один или несколько раз |
? | Повторить ноль или один раз |
{n} | Повторить n раз |
{n,} | Повторите n или более раз |
{n,m} | Повторите от n до m раз |
ленивое сопоставление.*? : Сопоставьте как можно меньше символов.После повторных метасимволов добавьте? Реализуйте ленивое сопоставление.
жадное сопоставление.* : Сопоставьте как можно больше символов. Повторяющиеся метасимволы по умолчанию являются жадными.
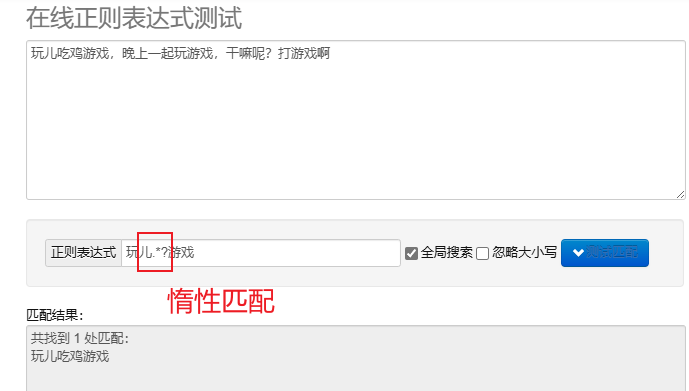
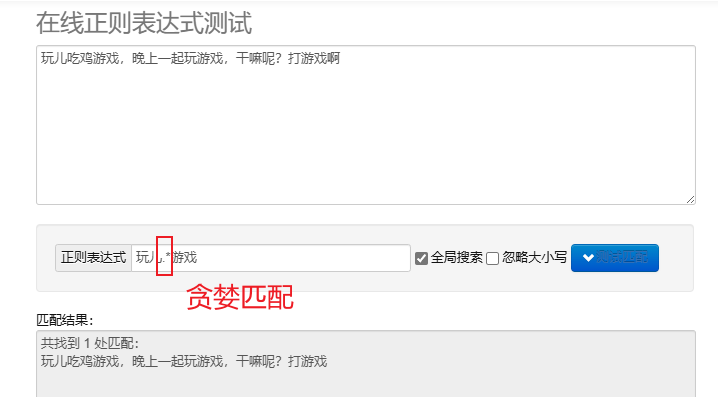
Для обработки регулярных выражений в Python вы можете использовать re модуль, этот модуль предоставляет набор функций для поиска, сопоставления и управления строками.
| функция | описывать |
|---|---|
re.search(pattern, string, flags=0) | Найдите строку и верните первый совпадающий объект, если совпадений нет, верните; None |
re.match(pattern, string, flags=0) | Сопоставить шаблон с начала строки; если совпадение прошло успешно, вернуть соответствующий объект, в противном случае. None |
re.fullmatch(pattern, string, flags=0) | Возвращает объект сопоставления, если вся строка точно соответствует шаблону, в противном случае возвращается None |
re.findall(pattern, string, flags=0) | Возвращает список всех непересекающихся совпадений в строке. |
re.finditer(pattern, string, flags=0) | Возвращает итератор всех непересекающихся совпадений в строке. |
re.sub(pattern, repl, string, count=0, flags=0) | Замените все части соответствующего шаблона замещающей строкой, вернув замененную строку. |
re.split(pattern, string, maxsplit=0, flags=0) | Разделить строку на основе сопоставления с образцом и вернуть разделенный список. |
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
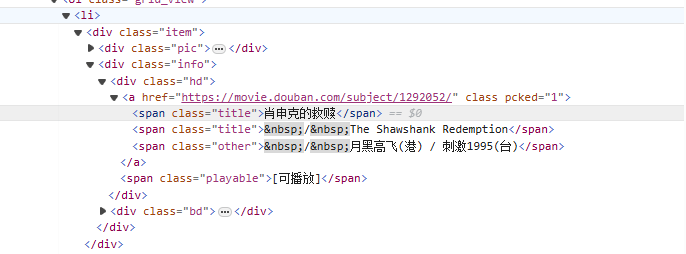
от<li>Начиная с тега, постепенно сопоставляйте его с тегом, содержащим название фильма.<span class="title">тег, используйте нежадный режим (.*?) соответствует любым символам, которые могут существовать между ними, пока не будет найден следующий явный токен, используя именованную группу захвата.(?P<name>)Извлеките часть названия фильма.
Повторное написание выражения:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Код краулера:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath — это язык поиска в документах XML. Он может выбирать узлы или наборы узлов с помощью выражений пути. HTML — это подмножество XML.
Установите модуль lxml: pip install lxml
| символ | объяснять |
|---|---|
/ | Выберите из корневого узла. |
// | Выбирает узлы в документе из текущего узла, соответствующего выделенному, независимо от их положения. |
. | Выберите текущий узел. |
.. | Выбирает родительский узел текущего узла. |
@ | Выберите свойства. |
| выражение | объяснять |
|---|---|
/bookstore/book | Выберите все подузлы книги в узле книжного магазина. |
//book | Выбирает все узлы книги в документе, независимо от их положения. |
bookstore/book[1] | Выберите первый дочерний узел книги под узлом книжного магазина. |
//title[@lang] | Выберите все узлы заголовка с атрибутом lang. |
//title[@lang='en'] | Выберите все узлы заголовков, у которых атрибут lang имеет значение «en». |
text(): выберите текст элемента.@attr: выберите атрибут элемента.contains(): Определить взаимосвязь включения.starts-with(): Начало суда.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: выбрать все классы какmovieэлемент div.
/span[@class="title"][1]: выберите класс в каждом div какtitleПервый элемент диапазона.
/text(): получить текстовое содержимое элемента span.
//div[@class="movie"]/span[@class="title"][2]/text()
Аналогично приведенному выше выражению, но выбирается класс в каждом элементе div.titleВторой элемент диапазона.
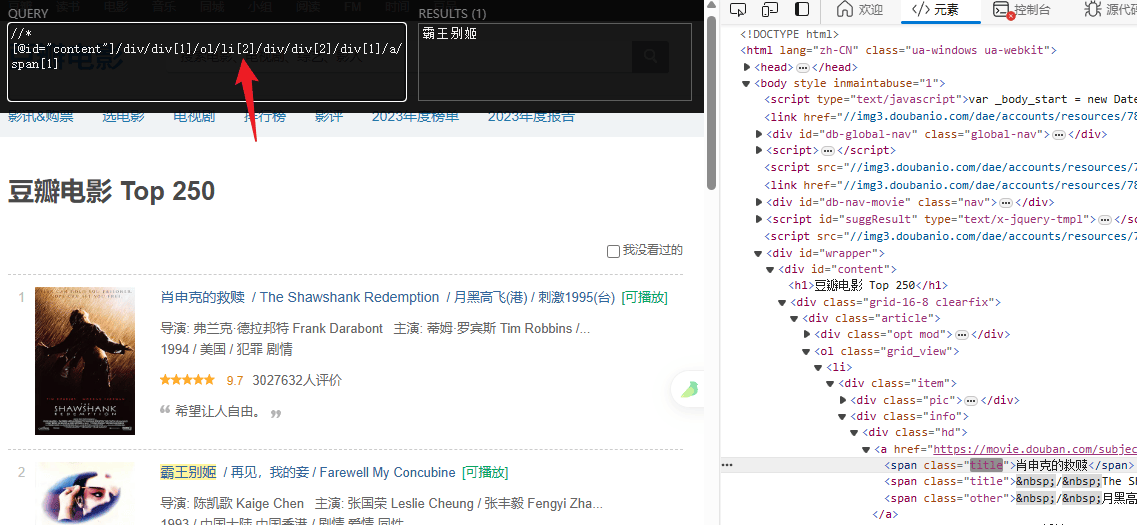
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования.

Почтамезофия@protonmail.com