
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Per analizzare i dati, oltre alla precedente libreria BeautifulSoup, esistono due metodi: le espressioni regolari e Xpath.
Le espressioni regolari (RE in breve) sono strumenti utilizzati per descrivere e abbinare modelli di stringhe.
È ampiamente utilizzato nell'elaborazione del testo, nella convalida dei dati, nella ricerca e sostituzione del testo e in altri scenari. Le espressioni regolari utilizzano una sintassi speciale che consente la corrispondenza di modelli complessi sulle stringhe.
Test delle espressioni regolari:Test online sulle espressioni regolari
Metacaratteri: simboli speciali con significati fissi. Ogni metacarattere corrisponde a una sola stringa per impostazione predefinita e non può corrispondere a caratteri di nuova riga.
| Metacaratteri | descrivere | Esempio |
|---|---|---|
. | Corrisponde a qualsiasi carattere tranne i caratteri di nuova riga | a.b può corrisponderea1b、acb |
w | Abbina lettere, numeri o trattini bassi | w+ incontrohello、world_123 |
s | Corrisponde a qualsiasi carattere di spazio bianco | s+ Corrisponde a spazi, tabulazioni, ecc. |
d | Abbina i numeri | d+ incontro123、456 |
n | Corrisponde a un carattere di nuova riga | hellonworld Corrisponde al carattere di nuova riga |
t | corrisponde a un carattere di tabulazione | hellotworld corrisponde al carattere della scheda |
^ | Corrisponde all'inizio di una stringa | ^Hello incontroHello stringa all'inizio |
$ | Abbina la fine della stringa | World$ incontroWorld fine della corda |
W | Corrisponde a caratteri diversi da lettere, cifre e trattini bassi | W+ incontro!@#、$%^ |
D | Corrisponde a caratteri non numerici | D+ incontroabc、XYZ |
S | Corrisponde a caratteri diversi dagli spazi bianchi | S+ incontrohello、world123 |
| `un | essere | Abbina i caratteri a o carattereb |
(...) | Cattura un'espressione tra parentesi, che rappresenta un gruppo | (abc) catturareabc |
[...] | Corrisponde a qualsiasi carattere tra parentesi quadre | [abc] incontroa、b Oc |
[^...] | Corrisponde a qualsiasi carattere non racchiuso tra parentesi quadre | [^abc] corrispondere trannea、b、c Qualsiasi carattere diverso da |
Quantificatore: controlla il numero di occorrenze del metacarattere precedente
| quantificatore | descrivere |
|---|---|
* | Ripeti zero o più volte |
+ | Ripeti una o più volte |
? | Ripeti zero o una volta |
{n} | Ripeti n volte |
{n,} | Ripeti n o più volte |
{n,m} | Ripeti da n a m volte |
abbinamento pigro.*? : corrisponde al minor numero di caratteri possibile.Dopo aver aggiunto metacaratteri ripetuti? Implementa la corrispondenza pigra.
abbinamento goloso.* : abbina il maggior numero di caratteri possibile. I metacaratteri ripetuti predefiniti sono golosi.
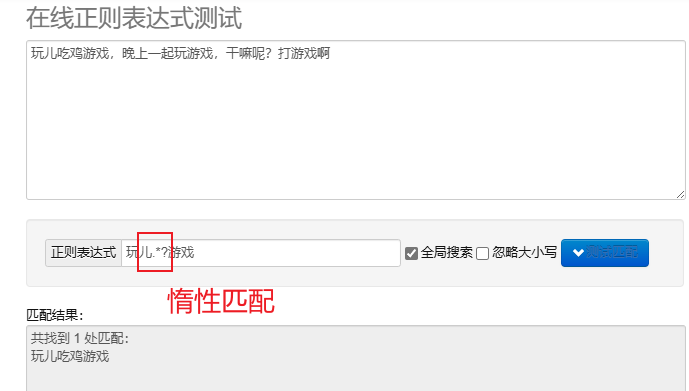
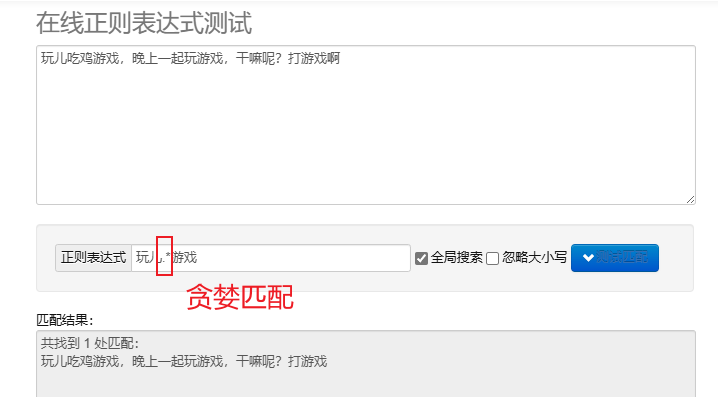
Per elaborare le espressioni regolari in Python, puoi usare re modulo, questo modulo fornisce un insieme di funzioni per la ricerca, la corrispondenza e la manipolazione delle stringhe.
| funzione | descrivere |
|---|---|
re.search(pattern, string, flags=0) | Cerca la stringa e restituisce il primo oggetto corrispondente; se non c'è corrispondenza, ritorna None |
re.match(pattern, string, flags=0) | Corrisponde al modello dall'inizio della stringa; se la corrispondenza ha esito positivo, restituisce l'oggetto corrispondente, altrimenti None |
re.fullmatch(pattern, string, flags=0) | Restituisce l'oggetto match se l'intera stringa corrisponde esattamente al modello, altrimenti restituisce None |
re.findall(pattern, string, flags=0) | Restituisce un elenco di tutte le corrispondenze non sovrapposte in una stringa |
re.finditer(pattern, string, flags=0) | Restituisce un iteratore di tutte le corrispondenze non sovrapposte in una stringa |
re.sub(pattern, repl, string, count=0, flags=0) | Sostituisci tutte le parti del modello corrispondente con la stringa sostitutiva, restituendo la stringa sostituita |
re.split(pattern, string, maxsplit=0, flags=0) | Divide la stringa in base alla corrispondenza del modello e restituisce l'elenco diviso |
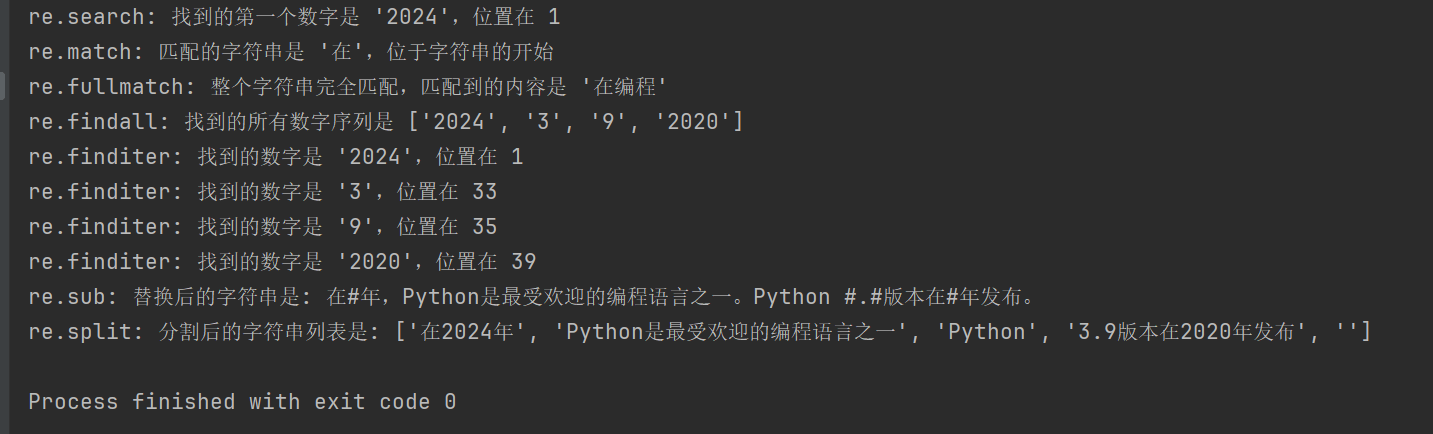
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
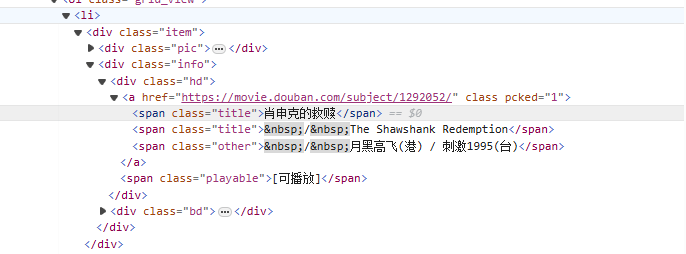
da<li>Partendo dal tag, abbina gradualmente al tag contenente il nome del film<span class="title">tag, utilizza la modalità non avida (.*?) corrisponde a tutti i caratteri che possono esistere nel mezzo finché non viene trovato il token esplicito successivo, utilizzando un gruppo di acquisizione denominato(?P<name>)Estrai la parte del titolo del film.
Scrittura di riespressione:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Codice crawler:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath è un linguaggio per la ricerca nei documenti XML. Può selezionare nodi o set di nodi tramite espressioni di percorso HTML è un sottoinsieme di XML.
Installa il modulo lxml: pip install lxml
| simbolo | spiegare |
|---|---|
/ | Seleziona dal nodo radice. |
// | Seleziona i nodi nel documento dal nodo corrente che corrisponde alla selezione, indipendentemente dalla loro posizione. |
. | Seleziona il nodo corrente. |
.. | Seleziona il nodo genitore del nodo corrente. |
@ | Seleziona proprietà. |
| espressione | spiegare |
|---|---|
/bookstore/book | Seleziona tutti i sottonodi dei libri sotto il nodo della libreria. |
//book | Seleziona tutti i nodi del libro nel documento, indipendentemente dalla loro posizione. |
bookstore/book[1] | Seleziona il primo nodo figlio del libro sotto il nodo della libreria. |
//title[@lang] | Seleziona tutti i nodi del titolo con l'attributo lang. |
//title[@lang='en'] | Seleziona tutti i nodi titolo il cui attributo lang è 'en'. |
text(): seleziona il testo dell'elemento.@attr: Seleziona l'attributo dell'elemento.contains(): Determina la relazione di inclusione.starts-with(): L'inizio del giudizio.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Seleziona tutte le classi comemovieelemento div.
/span[@class="title"][1]: seleziona la classe in ciascun div astitleIl primo elemento campata.
/text(): ottiene il contenuto testuale dell'elemento span.
//div[@class="movie"]/span[@class="title"][2]/text()
Simile all'espressione precedente, ma è selezionata la classe in ciascun div.titleIl secondo elemento campata.
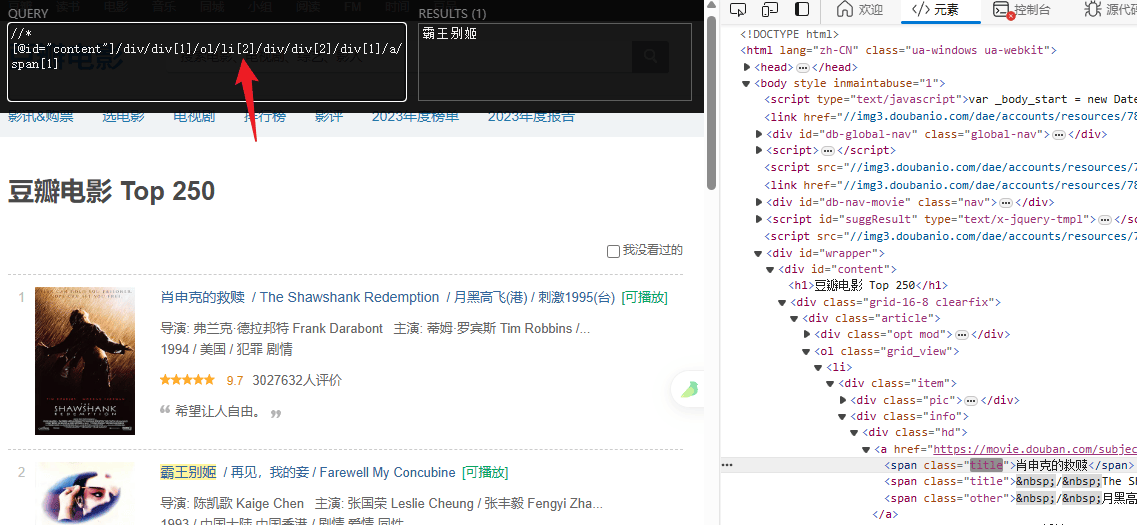
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]