
내 연락처 정보
우편메소피아@프로톤메일.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
데이터를 구문 분석하기 위해 이전 BeautifulSoup 라이브러리 외에 정규 표현식과 Xpath라는 두 가지 방법이 있습니다.
정규식(줄여서 RE)은 문자열 패턴을 설명하고 일치시키는 데 사용되는 도구입니다.
텍스트 처리, 데이터 유효성 검사, 텍스트 검색 및 교체 및 기타 시나리오에 널리 사용됩니다. 정규식은 문자열에 대한 복잡한 패턴 일치를 가능하게 하는 특수 구문을 사용합니다.
정규식 테스트:온라인 정규식 테스트
메타문자: 고정된 의미를 지닌 특수 기호입니다. 각 메타 문자는 기본적으로 하나의 문자열에만 일치하며 개행 문자와 일치할 수 없습니다.
| 메타 문자 | 설명하다 | 예 |
|---|---|---|
. | 줄 바꿈을 제외한 모든 문자와 일치합니다. | a.b 일치할 수 있다a1b、acb |
w | 문자, 숫자, 밑줄 일치 | w+ 성냥hello、world_123 |
s | 모든 공백 문자와 일치합니다. | s+ 공백, 탭 등과 일치합니다. |
d | 숫자 일치 | d+ 성냥123、456 |
n | 개행 문자와 일치합니다. | hellonworld 개행 문자 일치 |
t | 탭 문자와 일치 | hellotworld 일치 탭 문자 |
^ | 문자열의 시작과 일치합니다. | ^Hello 성냥Hello 처음에 문자열 |
$ | 문자열의 끝과 일치 | World$ 성냥World 문자열의 끝 |
W | 문자, 숫자, 밑줄이 아닌 문자와 일치합니다. | W+ 성냥!@#、$%^ |
D | 숫자가 아닌 문자와 일치 | D+ 성냥abc、XYZ |
S | 공백이 아닌 문자와 일치 | S+ 성냥hello、world123 |
| `아 | 비` | 문자 일치 a 또는 캐릭터b |
(...) | 그룹을 나타내는 괄호 안에 표현식을 캡처합니다. | (abc) 포착abc |
[...] | 대괄호 안의 모든 문자와 일치합니다. | [abc] 성냥a、b 또는c |
[^...] | 대괄호로 묶이지 않은 모든 문자와 일치합니다. | [^abc] 제외하고 일치a、b、c 이외의 모든 문자 |
수량자: 이전 메타 문자의 발생 횟수를 제어합니다.
| 수량자 | 설명하다 |
|---|---|
* | 0회 이상 반복 |
+ | 한 번 이상 반복하세요. |
? | 0회 또는 1회 반복 |
{n} | n번 반복 |
{n,} | n회 이상 반복 |
{n,m} | n~m번 반복 |
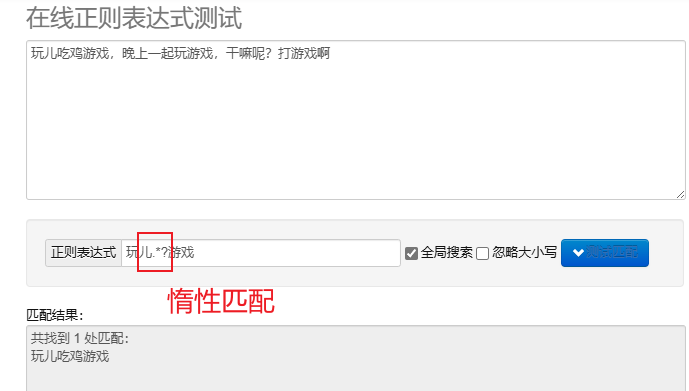
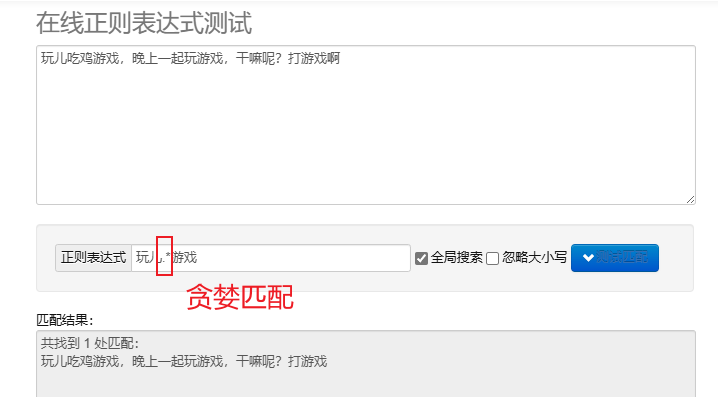
게으른 일치.*? : 가능한 한 적은 수의 문자를 일치시킵니다.반복되는 메타 문자 뒤에 추가? 게으른 일치를 구현합니다.
탐욕스러운 매칭.* : 최대한 많은 문자를 일치시킵니다. 기본 반복 메타 문자는 탐욕적입니다.
Python에서 정규식을 처리하려면 다음을 사용할 수 있습니다. re 모듈에서 이 모듈은 문자열 검색, 일치 및 조작을 위한 일련의 기능을 제공합니다.
| 기능 | 설명하다 |
|---|---|
re.search(pattern, string, flags=0) | 문자열을 검색하고 일치하는 첫 번째 객체를 반환합니다. 일치하는 항목이 없으면 반환합니다. None |
re.match(pattern, string, flags=0) | 문자열의 시작 부분부터 패턴을 일치시킵니다. 일치에 성공하면 일치하는 객체를 반환하고, 그렇지 않으면 None |
re.fullmatch(pattern, string, flags=0) | 전체 문자열이 패턴과 정확히 일치하면 일치 개체를 반환하고, 그렇지 않으면 반환합니다. None |
re.findall(pattern, string, flags=0) | 문자열에서 겹치지 않는 모든 일치 항목의 목록을 반환합니다. |
re.finditer(pattern, string, flags=0) | 문자열에서 겹치지 않는 모든 일치 항목의 반복자를 반환합니다. |
re.sub(pattern, repl, string, count=0, flags=0) | 일치하는 패턴의 모든 부분을 대체 문자열로 바꾸고, 대체된 문자열을 반환합니다. |
re.split(pattern, string, maxsplit=0, flags=0) | 패턴 일치를 기반으로 문자열을 분할하고 분할 목록을 반환합니다. |
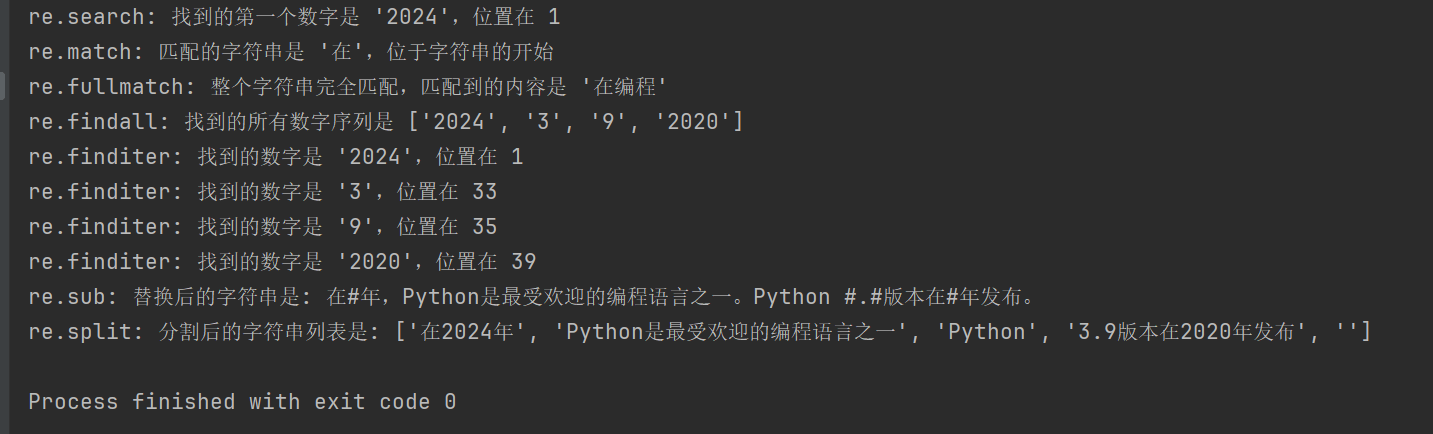
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
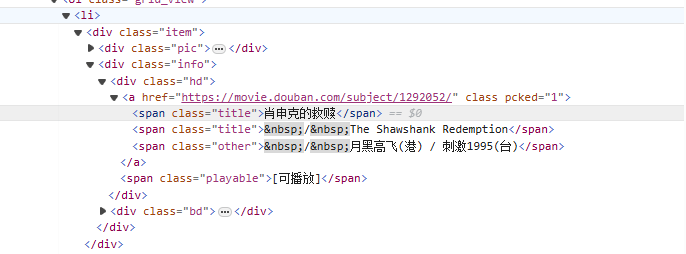
~에서<li>태그부터 시작하여 점차적으로 영화 이름이 포함된 태그와 일치시킵니다.<span class="title">태그, non-greedy 모드 사용(.*?) 명명된 캡처 그룹을 사용하여 다음 명시적 토큰이 발견될 때까지 그 사이에 존재할 수 있는 모든 문자와 일치합니다.(?P<name>)영화 제목 부분을 추출합니다.
Re 표현 쓰기:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
크롤러 코드:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
Xpath는 XML 문서에서 검색하기 위한 언어입니다. HTML은 XML의 하위 집합입니다.
lxml 모듈을 설치합니다: pip install lxml
| 상징 | 설명하다 |
|---|---|
/ | 루트 노드에서 선택합니다. |
// | 위치에 관계없이 선택 항목과 일치하는 현재 노드에서 문서의 노드를 선택합니다. |
. | 현재 노드를 선택합니다. |
.. | 현재 노드의 부모 노드를 선택합니다. |
@ | 속성을 선택합니다. |
| 표현 | 설명하다 |
|---|---|
/bookstore/book | bookstore 노드 아래의 모든 book 하위 노드를 선택합니다. |
//book | 위치에 관계없이 문서의 모든 책 노드를 선택합니다. |
bookstore/book[1] | bookstore 노드 아래의 첫 번째 book 하위 노드를 선택합니다. |
//title[@lang] | lang 속성이 있는 모든 제목 노드를 선택합니다. |
//title[@lang='en'] | lang 속성이 'en'인 제목 노드를 모두 선택합니다. |
text(): 요소의 텍스트를 선택합니다.@attr: 요소의 속성을 선택합니다.contains(): 포함관계를 결정합니다.starts-with(): 심판의 시작.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: 모든 수업을 다음과 같이 선택합니다.moviediv 요소.
/span[@class="title"][1]: 각 div의 클래스를 다음과 같이 선택합니다.title첫 번째 범위 요소입니다.
/text(): 범위 요소의 텍스트 내용을 가져옵니다.
//div[@class="movie"]/span[@class="title"][2]/text()
위의 표현식과 유사하지만 각 div의 클래스가 선택됩니다.title두 번째 범위 요소입니다.
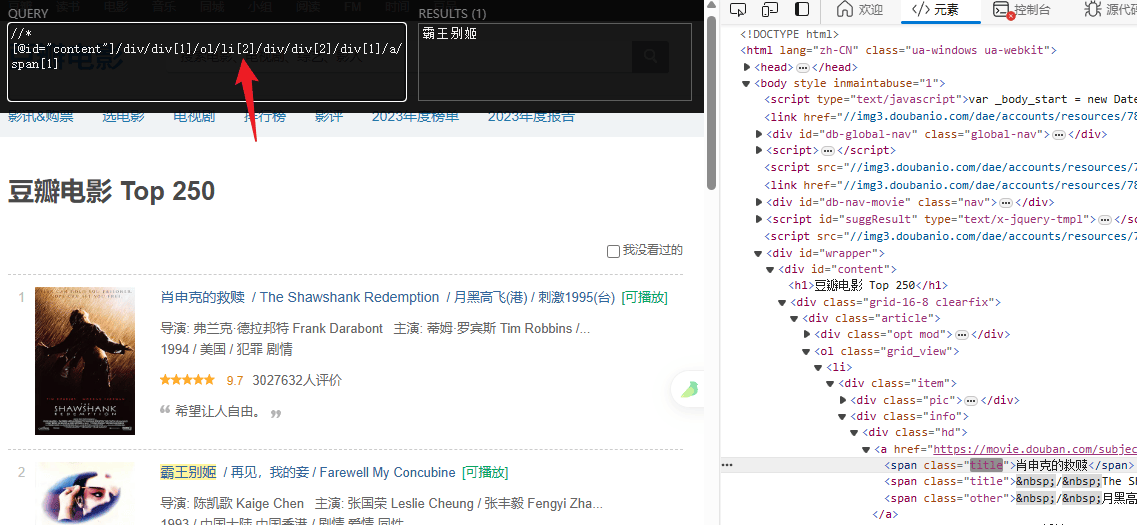
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

그는 30년 이상 기술 연구에 전념해 왔으며, java, linux, javascript, php, css 등 다양한 언어에 능숙하며, 오픈 소스 분야에 많은 공헌을 했습니다. 나중에 참조할 수 있도록 기술 개발의 일부 문제를 공유하는 개발자 문서 스테이션입니다.

우편메소피아@프로톤메일.com