
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Para analisar dados, além da biblioteca BeautifulSoup anterior, existem dois métodos: expressões regulares e Xpath.
Expressões regulares (RE, abreviadamente) são ferramentas usadas para descrever e combinar padrões de string.
É amplamente utilizado em processamento de texto, validação de dados, pesquisa e substituição de texto e outros cenários. Expressões regulares usam uma sintaxe especial para realizar correspondências complexas de padrões em strings.
Teste de expressão regular:Teste de expressão regular online
Metacaracteres: Símbolos especiais com significados fixos. Cada metacaractere corresponde a apenas uma string por padrão e não pode corresponder a caracteres de nova linha.
| metacaracteres | descrever | Exemplo |
|---|---|---|
. | Corresponde a qualquer caractere, exceto novas linhas | a.b pode combinara1b、acb |
w | Combine letras, números ou sublinhados | w+ corresponderhello、world_123 |
s | Corresponde a qualquer caractere de espaço em branco | s+ Corresponde a espaços, tabulações, etc. |
d | Números correspondentes | d+ corresponder123、456 |
n | Corresponde a um caractere de nova linha | hellonworld Corresponder ao caractere de nova linha |
t | corresponder a um caractere de tabulação | hellotworld combinar caractere de tabulação |
^ | Corresponde ao início de uma string | ^Hello corresponderHello corda no início |
$ | Combine o final da string | World$ corresponderWorld fim da corda |
W | Corresponde a caracteres que não sejam letras, números e não sublinhados | W+ corresponder!@#、$%^ |
D | Corresponder caracteres não numéricos | D+ corresponderabc、XYZ |
S | Combine caracteres que não sejam espaços em branco | S+ corresponderhello、world123 |
| `um | b` | Combine personagens a ou personagemb |
(...) | Captura uma expressão entre parênteses, representando um grupo | (abc) capturarabc |
[...] | Corresponde a qualquer caractere entre colchetes | [abc] correspondera、b ouc |
[^...] | Corresponde a qualquer caractere não colocado entre colchetes | [^abc] combinar, excetoa、b、c Qualquer personagem que não seja |
Quantificador: controla o número de ocorrências do metacaractere anterior
| quantificador | descrever |
|---|---|
* | Repita zero ou mais vezes |
+ | Repita uma ou mais vezes |
? | Repita zero ou uma vez |
{n} | Repita n vezes |
{n,} | Repita n ou mais vezes |
{n,m} | Repita n a m vezes |
correspondência preguiçosa.*? : combine o mínimo de caracteres possível.Depois de metacaracteres repetidos, adicione? Implemente a correspondência lenta.
correspondência gananciosa.* : Combine tantos caracteres quanto possível. Os metacaracteres repetidos padrão são gananciosos.
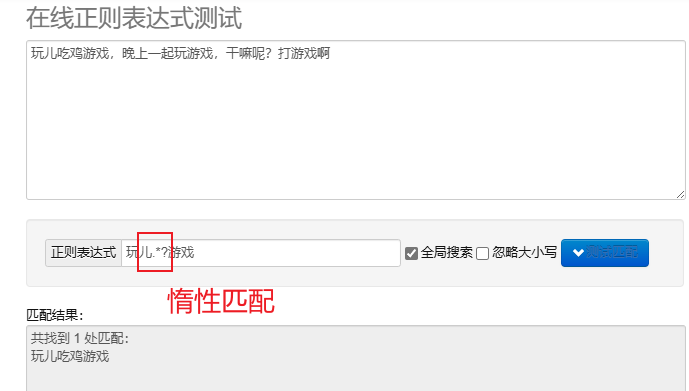
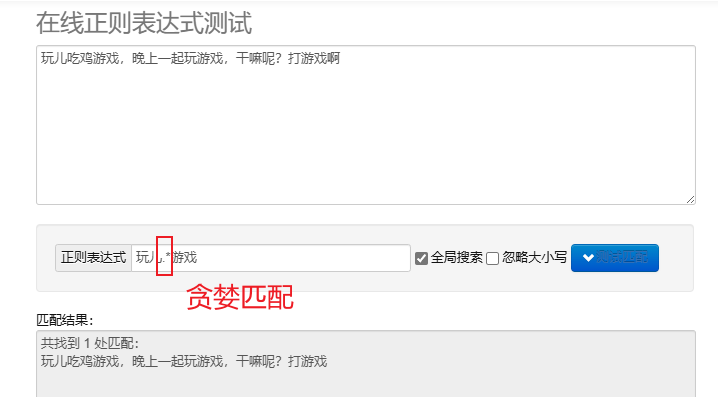
Para processar expressões regulares em Python, você pode usar re módulo, este módulo fornece um conjunto de funções para pesquisar, combinar e manipular strings.
| função | descrever |
|---|---|
re.search(pattern, string, flags=0) | Pesquise a string e retorne o primeiro objeto correspondente; se não houver correspondência, retorne; None |
re.match(pattern, string, flags=0) | Combine o padrão desde o início da string; se a correspondência for bem-sucedida, retorne o objeto correspondente, caso contrário; None |
re.fullmatch(pattern, string, flags=0) | Retorna o objeto match se toda a string corresponder exatamente ao padrão, caso contrário, retorna None |
re.findall(pattern, string, flags=0) | Retorna uma lista de todas as correspondências não sobrepostas em uma string |
re.finditer(pattern, string, flags=0) | Retorna um iterador de todas as correspondências não sobrepostas em uma string |
re.sub(pattern, repl, string, count=0, flags=0) | Substitui todas as partes do padrão correspondente pela string de substituição, retornando a string substituída |
re.split(pattern, string, maxsplit=0, flags=0) | Divida a string com base na correspondência de padrões e retorne a lista dividida |
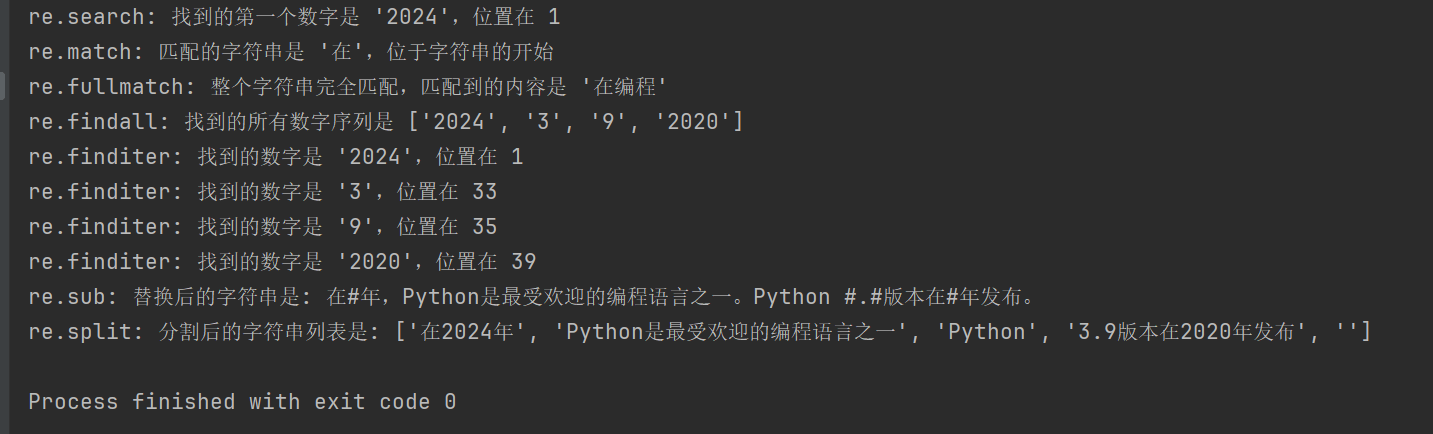
import re
# 示例文本
text = "在2024年,Python是最受欢迎的编程语言之一。Python 3.9版本在2020年发布。"
# 1. re.search() 搜索字符串,返回第一个匹配的对象
# 查找第一个数字序列
search_result = re.search(r'd+', text)
if search_result:
print(f"re.search: 找到的第一个数字是 '{search_result.group()}',位置在 {search_result.start()}")
# 2. re.match() 从字符串起始位置匹配模式
# 匹配字符串开头是否为 '在'
match_result = re.match(r'在', text)
if match_result:
print(f"re.match: 匹配的字符串是 '{match_result.group()}',位于字符串的开始")
# 3. re.fullmatch() 整个字符串完全匹配模式
# 检查整个字符串是否只包含中文字符
fullmatch_result = re.fullmatch(r'[u4e00-u9fff]+', '在编程')
if fullmatch_result:
print(f"re.fullmatch: 整个字符串完全匹配,匹配到的内容是 '{fullmatch_result.group()}'")
# 4. re.findall() 返回字符串中所有非重叠匹配的列表
# 查找所有的数字序列
findall_result = re.findall(r'd+', text)
print(f"re.findall: 找到的所有数字序列是 {findall_result}")
# 5. re.finditer() 返回字符串中所有非重叠匹配的迭代器
# 查找所有的数字序列,并逐一输出
finditer_result = re.finditer(r'd+', text)
for match in finditer_result:
print(f"re.finditer: 找到的数字是 '{match.group()}',位置在 {match.start()}")
# 6. re.sub() 用替换字符串替换匹配模式的所有部分
# 将所有数字替换为 '#'
sub_result = re.sub(r'd+', '#', text)
print(f"re.sub: 替换后的字符串是: {sub_result}")
# 7. re.split() 根据模式匹配分割字符串
# 按照空白字符或标点分割字符串
split_result = re.split(r'[,。 ]+', text)
print(f"re.split: 分割后的字符串列表是: {split_result}")
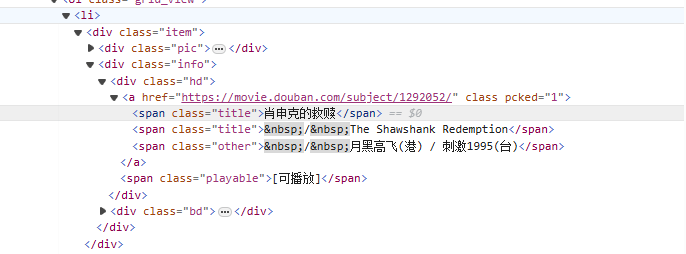
de<li>Começando pela tag, combine gradualmente com a tag que contém o nome do filme<span class="title">tag, use o modo não ganancioso (.*?) corresponde a quaisquer caracteres que possam existir até que o próximo token explícito seja encontrado, usando um grupo de captura nomeado(?P<name>)Extraia a parte do título do filme.
Escrita de reexpressão:
<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>
Código do rastreador:
import requests
import re
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用re解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
# 开始匹配
result = obj.finditer(html)
# 打印结果
for it in result:
print(it.group('name'))
XPath é uma linguagem para pesquisa em documentos XML. Ele pode selecionar nós ou conjuntos de nós por meio de expressões de caminho. HTML é um subconjunto de XML.
Instale o módulo lxml: pip install lxml
| símbolo | explicar |
|---|---|
/ | Selecione no nó raiz. |
// | Seleciona nós no documento a partir do nó atual que corresponde à seleção, independentemente de sua posição. |
. | Selecione o nó atual. |
.. | Seleciona o nó pai do nó atual. |
@ | Selecione propriedades. |
| expressão | explicar |
|---|---|
/bookstore/book | Selecione todos os subnós do livro no nó da livraria. |
//book | Seleciona todos os nós de livro no documento, independentemente de sua posição. |
bookstore/book[1] | Selecione o primeiro nó filho do livro no nó da livraria. |
//title[@lang] | Selecione todos os nós de título com atributo lang. |
//title[@lang='en'] | Selecione todos os nós de título cujo atributo lang seja 'en'. |
text(): selecione o texto do elemento.@attr: selecione o atributo do elemento.contains(): Determine a relação de inclusão.starts-with(): O início do julgamento.from lxml import etree
html_content = '''
<html>
<body>
<div class="movie">
<span class="title">肖申克的救赎</span>
<span class="title">The Shawshank Redemption</span>
</div>
<div class="movie">
<span class="title">霸王别姬</span>
<span class="title">Farewell My Concubine</span>
</div>
</body>
</html>
'''
# 解析HTML
tree = etree.HTML(html_content)
# 提取电影标题
titles_cn = tree.xpath('//div[@class="movie"]/span[@class="title"][1]/text()')
titles_en = tree.xpath('//div[@class="movie"]/span[@class="title"][2]/text()')
# 打印结果
for cn, en in zip(titles_cn, titles_en):
print(f'中文标题: {cn}, 英文标题: {en}')
//div[@class="movie"]/span[@class="title"][1]/text()
//div[@class="movie"]: Selecione todas as classes comomovieelemento div.
/span[@class="title"][1]: Selecione a classe em cada div comotitleO primeiro elemento de extensão.
/text(): Obtenha o conteúdo do texto do elemento span.
//div[@class="movie"]/span[@class="title"][2]/text()
Semelhante à expressão acima, mas a classe em cada div é selecionada.titleO segundo elemento de extensão.
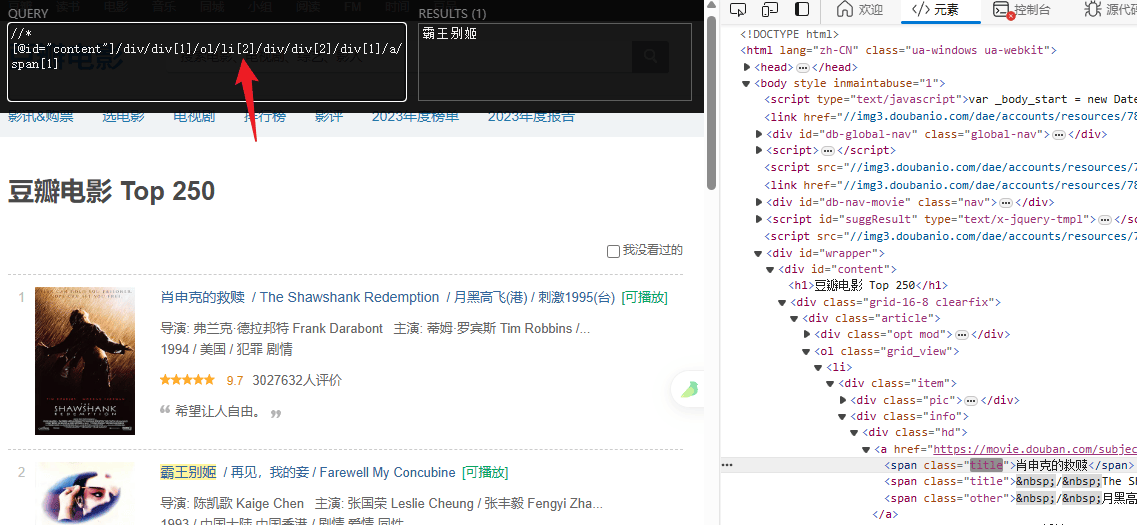
import requests
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"
}
for start_num in range(0, 250, 25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)
# 拿到页面源代码
html = response.text
# 使用lxml解析页面
html = etree.HTML(html)
# 提取电影名字
titles = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
# 提取评分
ratings = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
# 打印结果
for title, rating in zip(titles, ratings):
print(f"电影: {title} 评分: {rating}")

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]