2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Autor: Betrieb und Wartung Youshu Star Master Mit der rasanten Entwicklung der künstlichen Intelligenz, des maschinellen Lernens und der KI-Großmodelltechnologie steigt auch unser Bedarf an Rechenressourcen. Insbesondere für große KI-Modelle, die große Datenmengen und komplexe Algorithmen verarbeiten müssen, wird der Einsatz von GPU-Ressourcen entscheidend. Für Betriebs- und Wartungsingenieure ist es zu einer unverzichtbaren Fähigkeit geworden, die Verwaltung und Konfiguration von GPU-Ressourcen in Kubernetes-Clustern zu beherrschen und Anwendungen, die auf diesen Ressourcen basieren, effizient bereitzustellen.
Heute werde ich Ihnen ein tiefgreifendes Verständnis dafür vermitteln, wie Sie das leistungsstarke Ökosystem und die Tools von Kubernetes nutzen können, um GPU-Ressourcenmanagement und Anwendungsbereitstellung auf der KubeSphere-Plattform zu erreichen. Hier sind die drei Kernthemen, die in diesem Artikel behandelt werden:
Durch die Lektüre dieses Artikels erwerben Sie das Wissen und die Fähigkeiten zur Verwaltung von GPU-Ressourcen auf Kubernetes. So können Sie die GPU-Ressourcen in einer Cloud-nativen Umgebung optimal nutzen und die schnelle Entwicklung von KI-Anwendungen fördern.
KubeSphere Best Practice „2024“ Die Hardwarekonfiguration der experimentellen Umgebung und die Softwareinformationen der Dokumentreihe lauten wie folgt:
Tatsächliche Serverkonfiguration (Architektur 1:1-Nachbildung einer kleinen Produktionsumgebung, Konfiguration ist etwas anders)
| CPU-Name | IP | CPU | Erinnerung | Systemfestplatte | Datenträger | verwenden |
|---|---|---|---|---|---|---|
| KSP-Registrierung | 192.168.9.90 | 4 | 8 | 40 | 200 | Hafenspiegellager |
| ksp-steuerung-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-Steuerebene |
| ksp-steuerung-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-Steuerebene |
| ksp-steuerung-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-Steuerebene |
| ksp-arbeiter-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-Arbeiter/CI |
| ksp-arbeiter-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-Arbeiter |
| ksp-arbeiter-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-Arbeiter |
| ksp-speicher-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-speicher-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-speicher-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-arbeiter-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-arbeiter-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | Selbst erstelltes Anwendungsdienst-Proxy-Gateway/VIP: 192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | Selbst erstelltes Anwendungsdienst-Proxy-Gateway/VIP: 192.168.9.100 | |
| ksp-mitte | 192.168.9.105 | 4 | 8 | 40 | 100 | Dienstknoten, die außerhalb des k8s-Clusters bereitgestellt werden (Gitlab usw.) |
| gesamt | 15 | 56 | 152 | 600 | 2000 |
Die tatsächliche Kampfumgebung umfasst Informationen zur Softwareversion
Aufgrund von Ressourcen- und Kostenbeschränkungen habe ich keinen physischen High-End-Host und keine Grafikkarte zum Experimentieren. Als Worker-Knoten des Clusters können nur zwei virtuelle Maschinen hinzugefügt werden, die mit GPU-Grafikkarten der Einstiegsklasse ausgestattet sind.
Obwohl diese Grafikkarten nicht so leistungsstark sind wie High-End-Modelle, reichen sie für die meisten Lern- und Entwicklungsaufgaben aus. Bei begrenzten Ressourcen bietet mir eine solche Konfiguration wertvolle praktische Möglichkeiten, die GPU-Ressourcen in Kubernetes-Clustern eingehend zu erkunden Planungsstrategien.
Bitte beziehen Sie sich auf Kubernetes-Clusterknoten openEuler 22.03 LTS SP3-Systeminitialisierungshandbuch, schließen Sie die Initialisierungskonfiguration des Betriebssystems ab.
Die Erstkonfigurationsanleitung umfasst keine Betriebssystem-Upgrade-Aufgaben. Wenn Sie das System in einer Umgebung mit Internetzugang initialisieren, müssen Sie das Betriebssystem aktualisieren und dann den Knoten neu starten.
Als nächstes verwenden wir KubeKey, um den neu hinzugefügten GPU-Knoten zum vorhandenen Kubernetes-Cluster hinzuzufügen. Der gesamte Vorgang ist relativ einfach und erfordert nur zwei Schritte.
Wechseln Sie auf dem Control-1-Knoten zum Bereitstellungsverzeichnis kubekey und ändern Sie die ursprüngliche Cluster-Konfigurationsdatei. Der Name, den wir im tatsächlichen Kampf verwendet haben, lautet ksp-v341-v1288.yamlBitte ändern Sie es entsprechend der tatsächlichen Situation.
Hauptänderungspunkte:
Das modifizierte Beispiel lautet wie folgt:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Bevor wir Knoten hinzufügen, überprüfen wir die Knoteninformationen des aktuellen Clusters.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Als nächstes führen wir den folgenden Befehl aus und verwenden die geänderte Konfigurationsdatei, um den neuen Worker-Knoten zum Cluster hinzuzufügen.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlNachdem der obige Befehl ausgeführt wurde, prüft KubeKey zunächst, ob die Abhängigkeiten und andere Konfigurationen für die Bereitstellung von Kubernetes den Anforderungen entsprechen. Nach bestandener Prüfung werden Sie aufgefordert, die Installation zu bestätigen.eingebenJa und drücken Sie die EINGABETASTE, um mit der Bereitstellung fortzufahren.
Der Abschluss der Bereitstellung dauert etwa 5 Minuten. Die genaue Zeit hängt von der Netzwerkgeschwindigkeit, der Maschinenkonfiguration und der Anzahl der hinzugefügten Knoten ab.
Sobald die Bereitstellung abgeschlossen ist, sollten Sie auf Ihrem Terminal eine Ausgabe ähnlich der folgenden sehen.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyWir öffnen den Browser und greifen auf die IP-Adresse und den Port des Control-1-Knotens zu 30880Melden Sie sich auf der Anmeldeseite der KubeSphere-Verwaltungskonsole an.
Rufen Sie die Cluster-Verwaltungsoberfläche auf, klicken Sie links auf das Menü „Knoten“ und dann auf „Cluster-Knoten“, um detaillierte Informationen zu den verfügbaren Knoten des Kubernetes-Clusters anzuzeigen.
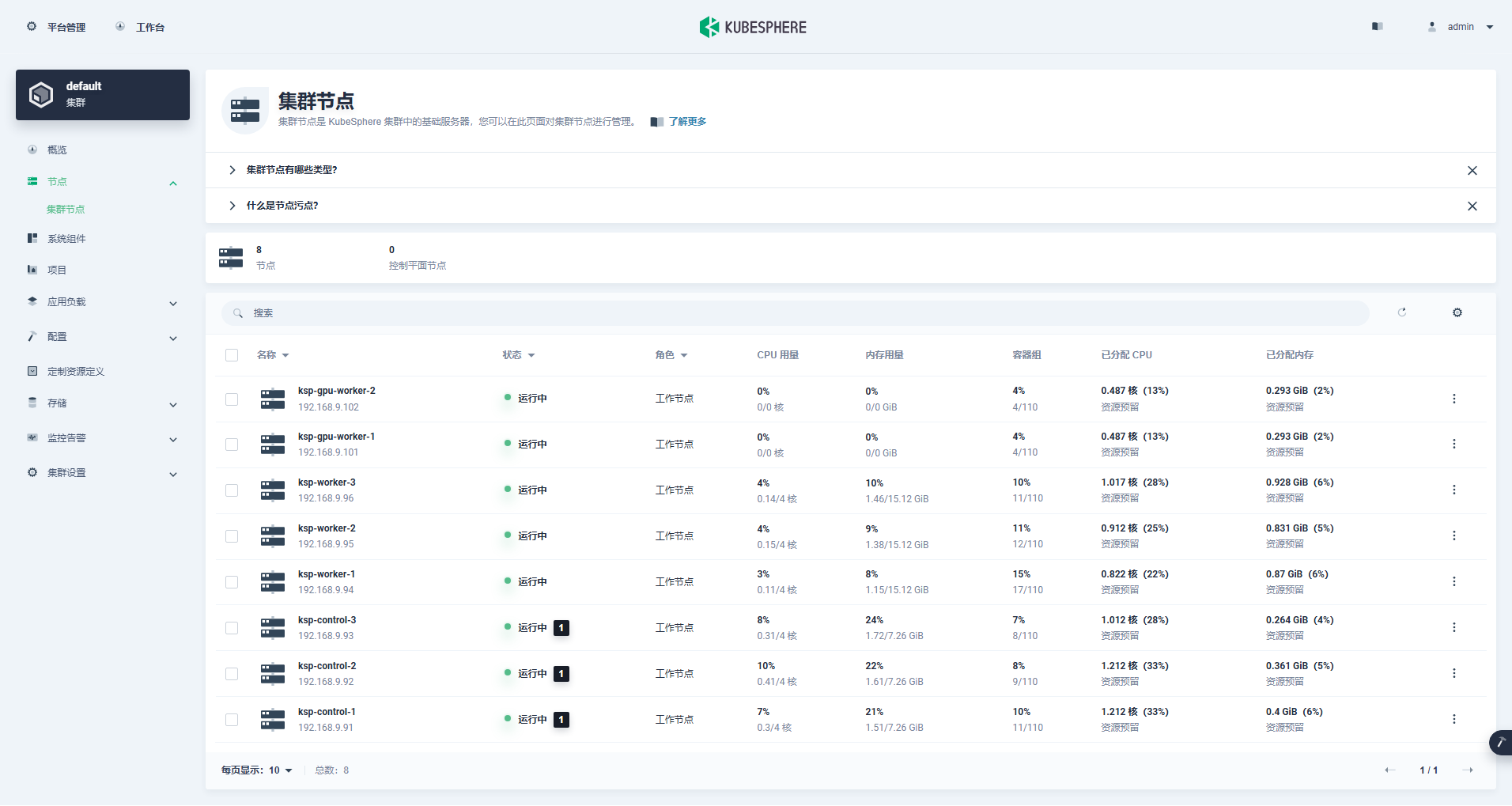
Führen Sie den Befehl kubectl auf dem Control-1-Knoten aus, um die Knoteninformationen des Kubernetes-Clusters abzurufen.
kubectl get nodes -o wideWie Sie in der Ausgabe sehen können, verfügt der aktuelle Kubernetes-Cluster über 8 Knoten. Name, Status, Rolle, Überlebenszeit, Kubernetes-Versionsnummer, interne IP, Betriebssystemtyp, Kernelversion und Containerlaufzeit jedes Knotens werden detailliert angezeigt . und andere Informationen.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Zu diesem Zeitpunkt haben wir alle Aufgaben zum Hinzufügen von zwei Worker-Knoten mit Kubekey zum bestehenden Kubernetes-Cluster abgeschlossen, der aus drei Master-Knoten und drei Worker-Knoten besteht.
Als Nächstes installieren wir den offiziell von NVIDIA produzierten NVIDIA GPU Operator, um den K8s-Planungs-Pod für die Nutzung von GPU-Ressourcen zu realisieren.
NVIDIA GPU Operator unterstützt die automatische Installation des Grafiktreibers, aber nur CentOS 7, 8 und Ubuntu 20.04, 22.04 und andere Versionen unterstützen openEuler nicht, sodass Sie den Grafiktreiber manuell installieren müssen.
Bitte beziehen Sie sich auf Best Practice von KubeSphere: openEuler 22.03 LTS SP3 installiert den NVIDIA-Grafikkartentreiber, schließen Sie die Installation des Grafikkartentreibers ab.
Node Feature Discovery (NFD) erkennt Feature-Checks.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Das Ausführungsergebnis des obigen Befehls ist true, veranschaulichen NFD Wird bereits im Cluster ausgeführt. Wenn NFD bereits im Cluster ausgeführt wird, muss die Bereitstellung von NFD bei der Installation des Operators deaktiviert werden.
veranschaulichen: Mit KubeSphere bereitgestellte K8s-Cluster installieren und konfigurieren NFD standardmäßig nicht.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateVerwenden Sie die Standardkonfigurationsdatei, deaktivieren Sie die automatische Installation von Grafikkartentreibern und installieren Sie den GPU Operator.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseHinweis: Da das installierte Image relativ groß ist, kann es bei der Erstinstallation zu einer Zeitüberschreitung kommen. Bitte prüfen Sie, ob Ihr Image erfolgreich gezogen wurde! Zur Lösung dieser Art von Problemen können Sie eine Offline-Installation in Betracht ziehen.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseDas Ausgabeergebnis der korrekten Ausführung ist wie folgt:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneNachdem Sie den Befehl zum Installieren des GPU-Operators ausgeführt haben, warten Sie bitte geduldig, bis alle Images erfolgreich abgerufen wurden und sich alle Pods im Status „Wird ausgeführt“ befinden.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110veranschaulichen: Fokus
nvidia.com/gpu:Der Wert des Feldes.
Die erfolgreich erstellte Arbeitslast lautet wie folgt:
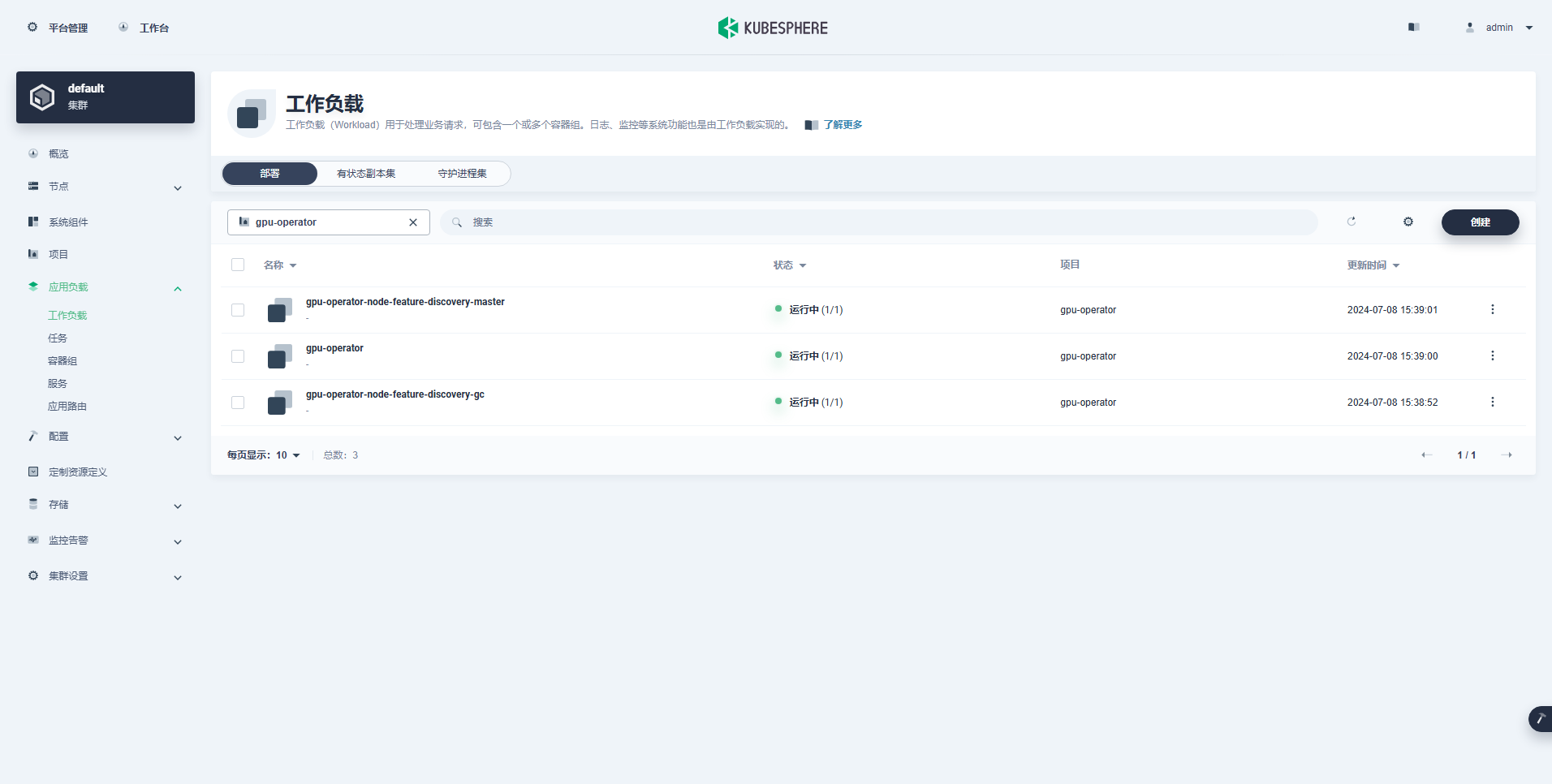
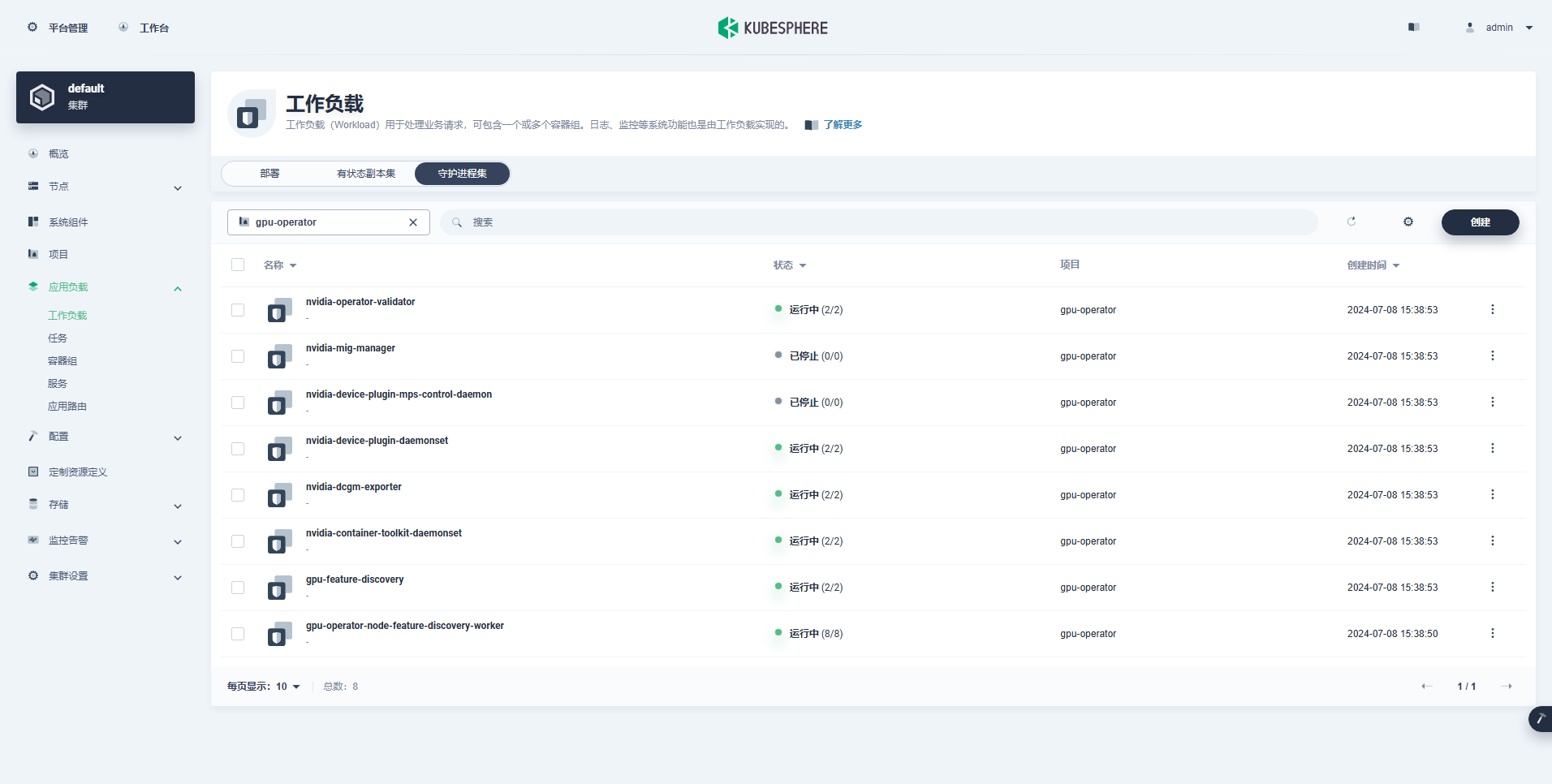
Nachdem der GPU-Operator korrekt installiert wurde, verwenden Sie das CUDA-Basisimage, um zu testen, ob K8s korrekt Pods erstellen kann, die GPU-Ressourcen nutzen.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlAnhand der Ergebnisse können Sie erkennen, dass der Pod auf dem Knoten ksp-gpu-worker-2 erstellt wurde (Das Knoten-Grafikkartenmodell Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Das Ausgabeergebnis der korrekten Ausführung ist wie folgt:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlImplementieren Sie ein einfaches CUDA-Beispiel zum Hinzufügen zweier Vektoren.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlDer Pod wurde erfolgreich erstellt und wird nach dem Start ausgeführt. vectorAdd Befehl und Ausgang.
$ kubectl logs pod/cuda-vectoraddDas Ausgabeergebnis der korrekten Ausführung ist wie folgt:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlDurch den obigen Verifizierungstest wurde bewiesen, dass Pod-Ressourcen mithilfe der GPU auf dem K8s-Cluster erstellt werden können. Als Nächstes verwenden wir KubeSphere, um ein großes Modellverwaltungstool Ollama im K8s-Cluster basierend auf den tatsächlichen Nutzungsanforderungen zu erstellen.
Bei diesem Beispiel handelt es sich um einen einfachen Test, bei dem der Speicher ausgewählt ist Hostpfad Modus, bitte ersetzen Sie ihn durch eine Speicherklasse oder andere Arten von persistentem Speicher, die tatsächlich verwendet werden.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortSpezielle Anweisungen: Die Verwaltungskonsole von KubeSphere unterstützt die grafische Konfiguration der Bereitstellung und anderer Ressourcen zur Verwendung von GPU-Ressourcen. Interessierte Freunde können die folgenden Konfigurationsbeispiele durchführen.
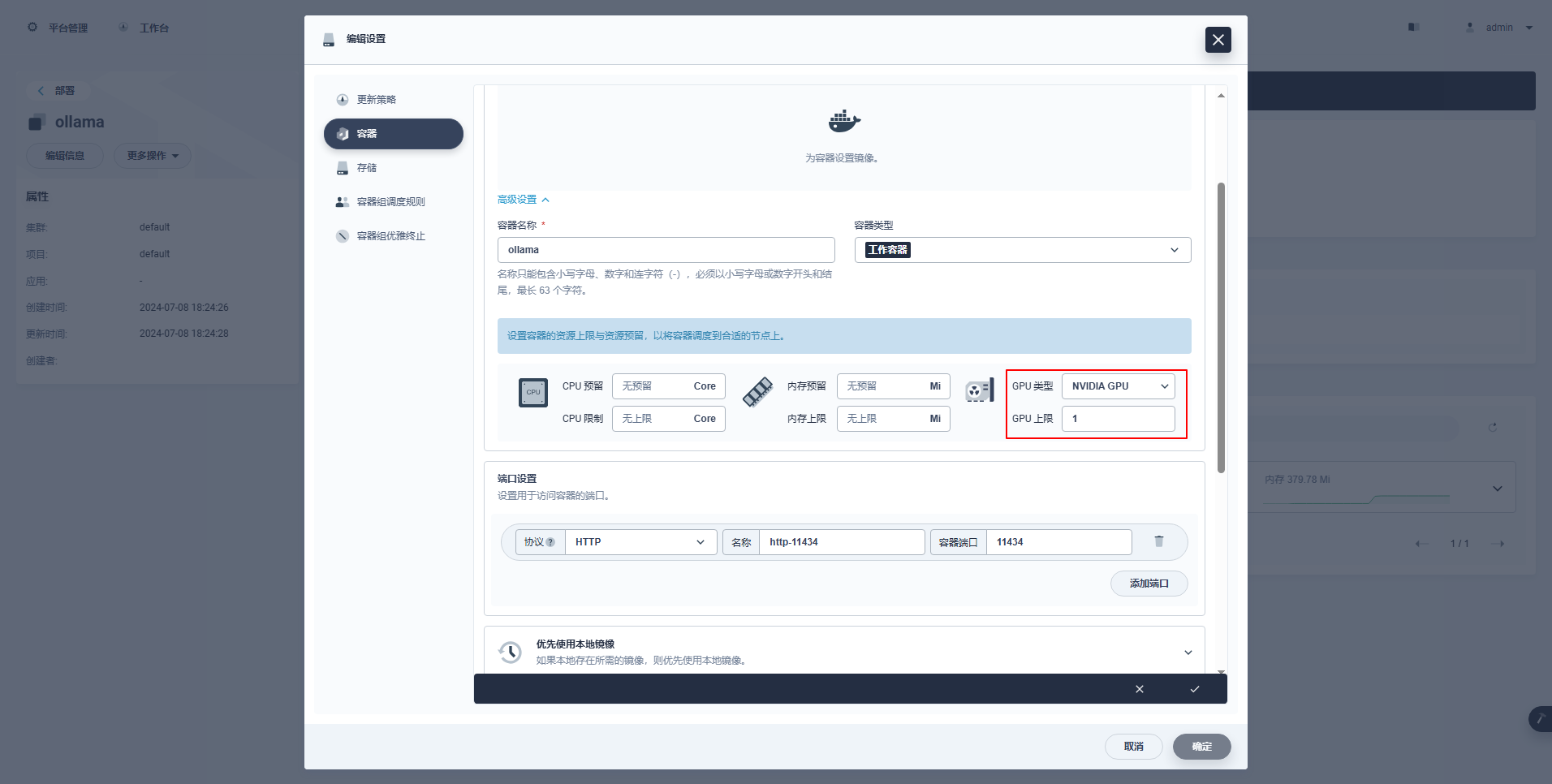
kubectl apply -f deploy-ollama.yamlAnhand der Ergebnisse können Sie erkennen, dass der Pod auf dem Knoten ksp-gpu-worker-1 erstellt wurde (Das Knoten-Grafikkartenmodell Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Um Zeit zu sparen, wird in diesem Beispiel das Open-Source-Kleinmodell qwen2 1.5b von Alibaba als Testmodell verwendet.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bDas Ausgabeergebnis der korrekten Ausführung ist wie folgt:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successexistieren ksp-gpu-arbeiter-1 Der Knoten führt den folgenden Ansichtsbefehl aus
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
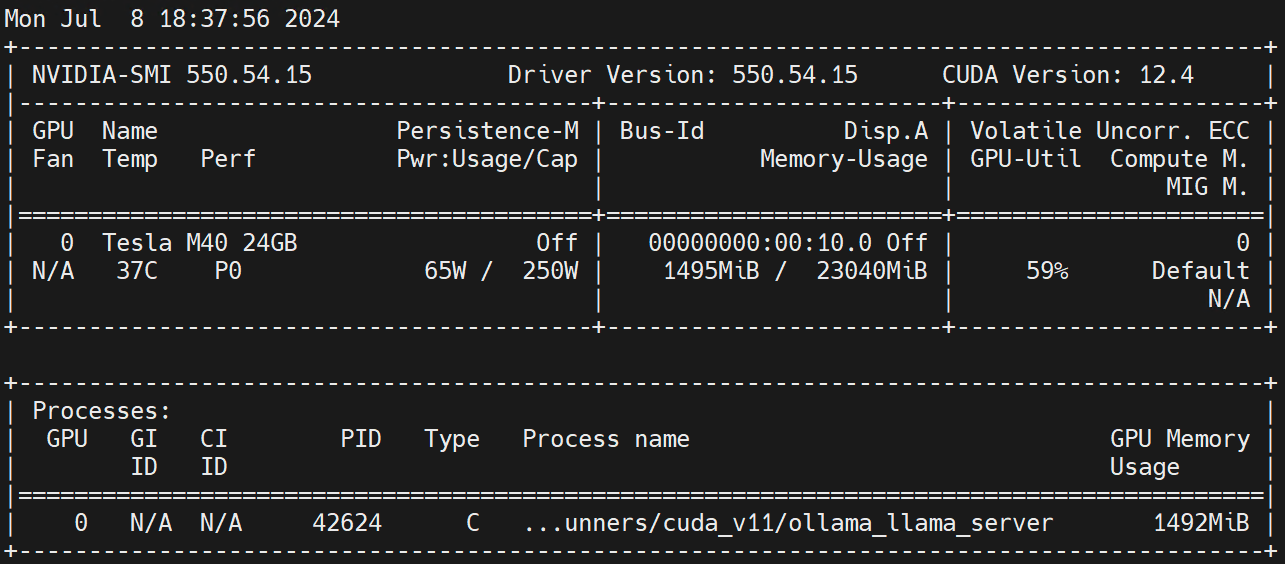
nvidia.com/gpu 1 1Auf Worker-Knoten ausführen nvidia-smi -l Beobachten Sie die GPU-Nutzung.
Haftungsausschluss:
Dieser Artikel wurde von der Blog One Post Multi-Publishing Platform veröffentlicht Offenes Schreiben freigeben!

Er widmet sich seit mehr als 30 Jahren der Technologieforschung und beherrscht verschiedene Sprachen wie Java, Linux, Javascript, PHP, CSS usw. Er hat viele Beiträge im Open-Source-Bereich geleistet Entwicklerdokumentationsstation, um einige Themen in der Technologieentwicklung als zukünftige Referenz zu teilen

