2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Tekijä: Käyttö ja ylläpito Youshu Star Master Tekoälyn, koneoppimisen ja tekoälyn suuren malliteknologian nopean kehityksen myötä myös laskentaresurssien kysyntämme kasvaa. Erityisesti suurissa tekoälymalleissa, joissa on käsiteltävä laajamittaista dataa ja monimutkaisia algoritmeja, GPU-resurssien käyttö tulee kriittistä. Käyttö- ja ylläpitoinsinööreille on tullut välttämätön taito hallita ja määrittää GPU-resursseja Kubernetes-klustereissa ja ottaa tehokkaasti käyttöön näihin resursseihin perustuvia sovelluksia.
Tänään opastan sinut saamaan syvällisen ymmärryksen siitä, kuinka Kubernetesin tehokkaan ekosysteemin ja työkalujen avulla voit saavuttaa GPU-resurssien hallinnan ja sovellusten käyttöönoton KubeSphere-alustalla. Tässä on kolme tämän artikkelin pääteemaa:
Lukemalla tämän artikkelin saat tiedot ja taidot hallita GPU-resursseja Kubernetesissa, mikä auttaa sinua hyödyntämään täysimääräisesti GPU-resursseja pilvipohjaisessa ympäristössä ja edistämään tekoälysovellusten nopeaa kehitystä.
KubeSpheren paras käytäntö "2024" Asiakirjasarjan kokeellisen ympäristön laitteisto- ja ohjelmistotiedot ovat seuraavat:
Todellinen palvelinkokoonpano (arkkitehtuuri 1:1 kopio pienimuotoisesta tuotantoympäristöstä, kokoonpano on hieman erilainen)
| CPU:n nimi | IP | prosessori | Muisti | järjestelmälevy | datalevy | käyttää |
|---|---|---|---|---|---|---|
| ksp-rekisteri | 192.168.9.90 | 4 | 8 | 40 | 200 | Sataman peilivarasto |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-työntekijä-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-työntekijä/CI |
| ksp-työntekijä-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-työntekijä |
| ksp-työläinen-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-työntekijä |
| ksp-storage-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-tallennus-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | Itse rakennettu sovelluspalvelun välityspalvelinyhdyskäytävä/VIP: 192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | Itse rakennettu sovelluspalvelun välityspalvelinyhdyskäytävä/VIP: 192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | Palvelusolmut käyttöön k8s-klusterin ulkopuolella (Gitlab jne.) |
| kaikki yhteensä | 15 | 56 | 152 | 600 | 2000 |
Varsinainen taisteluympäristö sisältää ohjelmistoversiotiedot
Resurssi- ja kustannusrajoitusten vuoksi minulla ei ole huippuluokan fyysistä isäntä- ja näytönohjainkorttia kokeillakseni. Vain kaksi virtuaalikonetta, jotka on varustettu lähtötason GPU-näytönohjaimella, voidaan lisätä klusterin työsolmuiksi.
Vaikka nämä näytönohjaimet eivät ole yhtä tehokkaita kuin huippuluokan mallit, ne ovat riittäviä useimpiin oppimis- ja kehitystehtäviin. Rajallisilla resursseilla tällainen kokoonpano tarjoaa minulle arvokkaita käytännön mahdollisuuksia tutkia syvällisesti Kubernetes-klusterien resursseja aikataulustrategiat.
Katso Kubernetes-klusterisolmu openEuler 22.03 LTS SP3 -järjestelmän alustusopas, viimeistele käyttöjärjestelmän alustusasetukset.
Alkumääritysopas ei sisällä käyttöjärjestelmän päivitystehtäviä. Kun alustat järjestelmää Internet-yhteydellä varustetussa ympäristössä, sinun on päivitettävä käyttöjärjestelmä ja käynnistettävä sitten solmu uudelleen.
Seuraavaksi lisäämme äskettäin lisätyn GPU-solmun olemassa olevaan Kubernetes-klusteriin KubeKeyn avulla. Koko prosessi on suhteellisen yksinkertainen ja vaatii vain kaksi vaihetta.
Vaihda Control-1-solmussa kubekey-hakemistoon käyttöönottoa varten ja muokkaa alkuperäistä klusterin määritystiedostoa Varsinaisessa taistelussa käyttämämme nimi ksp-v341-v1288.yaml, muuta sitä todellisen tilanteen mukaan.
Tärkeimmät muutoskohdat:
Muokattu esimerkki on seuraava:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Ennen kuin lisäät solmuja, vahvistetaan nykyisen klusterin solmutiedot.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Seuraavaksi suoritamme seuraavan komennon ja lisäämme uuden Worker-solmun klusteriin muokatun määritystiedoston avulla.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlKun yllä oleva komento on suoritettu, KubeKey tarkistaa ensin, vastaavatko Kubernetesin käyttöönoton riippuvuudet ja muut kokoonpanot vaatimukset. Kun olet läpäissyt tarkistuksen, sinua pyydetään vahvistamaan asennus.tulla sisäänJoo ja paina ENTER jatkaaksesi käyttöönottoa.
Käyttöönoton suorittaminen kestää noin 5 minuuttia. Aika riippuu verkon nopeudesta, koneen kokoonpanosta ja lisättyjen solmujen määrästä.
Kun käyttöönotto on valmis, sinun pitäisi nähdä seuraavanlaista tulostetta päätteessäsi.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyAvaamme selaimen ja käytämme Control-1-solmun IP-osoitetta ja porttia 30880, kirjaudu sisään KubeSphere-hallintakonsolin kirjautumissivulle.
Siirry klusterinhallintaliittymään, napsauta vasemmalla olevaa "Solmu"-valikkoa ja napsauta "Cluster Node" nähdäksesi yksityiskohtaiset tiedot Kubernetes-klusterin käytettävissä olevista solmuista.
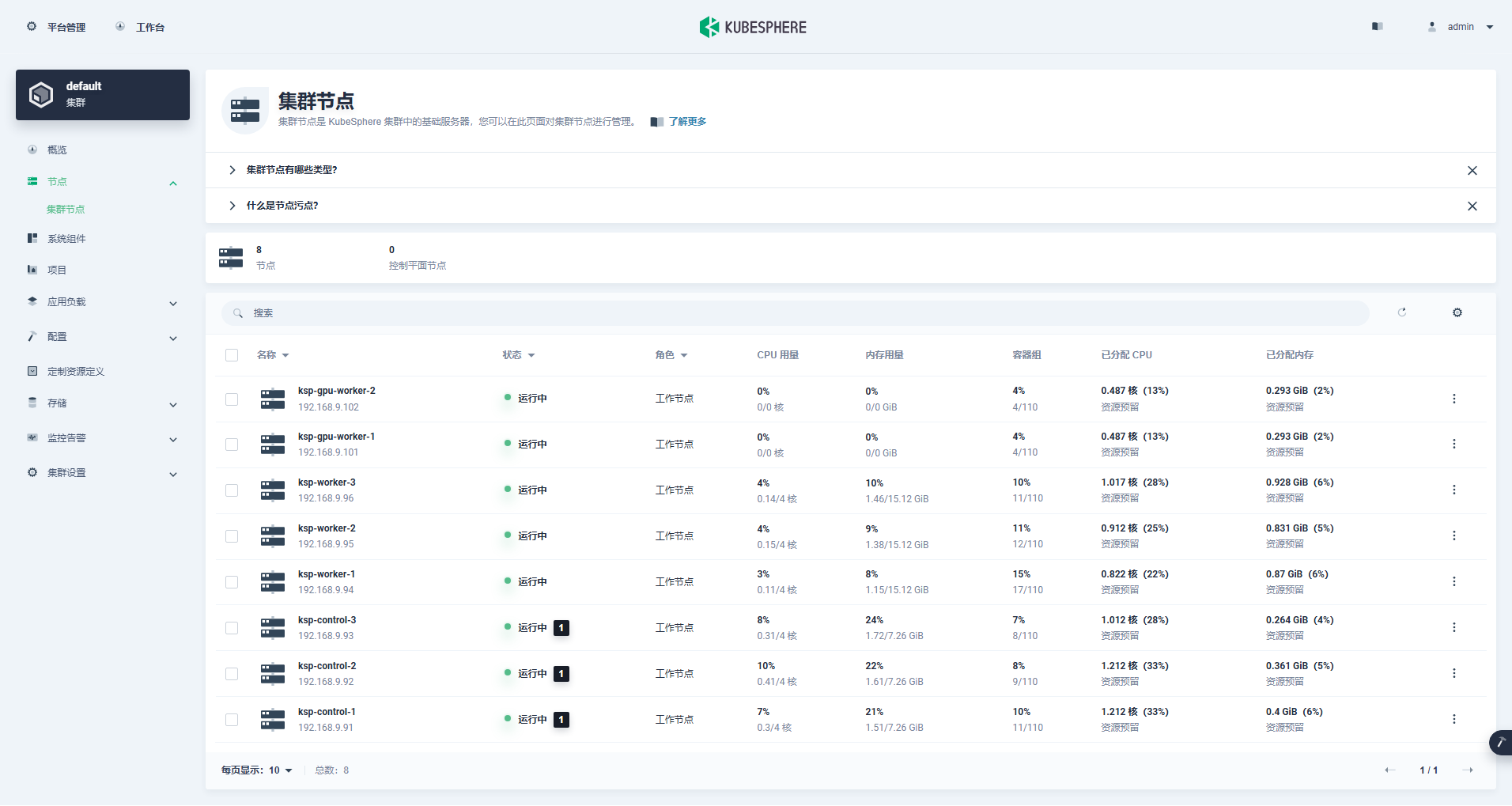
Suorita kubectl-komento Control-1-solmussa saadaksesi Kubernetes-klusterin solmutiedot.
kubectl get nodes -o wideKuten tulosteessa näkyy, nykyisessä Kubernetes-klusterissa on 8 solmua, ja kunkin solmun nimi, tila, rooli, selviytymisaika, Kubernetes-versionumero, sisäinen IP, käyttöjärjestelmän tyyppi, ytimen versio ja säilön ajonaika näytetään yksityiskohtaisesti. ja muuta tietoa.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Tässä vaiheessa olemme saaneet päätökseen kaikki tehtävät, jotka liittyvät Kubekeyn avulla 2 Worker-solmun lisäämiseen olemassa olevaan Kubernetes-klusteriin, joka koostuu 3 pääsolmusta ja 3 Worker-solmusta.
Seuraavaksi asennamme NVIDIA:n virallisesti tuottaman NVIDIA GPU Operatorin toteuttaaksemme K8s Scheduling Podin käyttämään GPU-resursseja.
NVIDIA GPU Operator tukee näytönohjaimen automaattista asennusta, mutta vain CentOS 7, 8 ja Ubuntu 20.04, 22.04 ja muut versiot eivät tue openEuleria, joten sinun on asennettava näytönohjain manuaalisesti.
Katso KubeSpheren paras käytäntö: openEuler 22.03 LTS SP3 asentaa NVIDIA-näytönohjaimen ohjaimen, viimeistele näytönohjaimen ohjaimen asennus.
Node Feature Discovery (NFD) havaitsee ominaisuuksien tarkistukset.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Yllä olevan komennon suoritustulos on true, havainnollistaa NFD Käynnissä jo klusterissa. Jos NFD on jo käynnissä klusterissa, NFD:n käyttöönotto on poistettava käytöstä operaattoria asennettaessa.
havainnollistaa: KubeSpheren avulla käyttöön otetut K8s-klusterit eivät asenna ja määritä NFD:tä oletusarvoisesti.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateKäytä oletusasetustiedostoa, poista näytönohjaimen ohjainten automaattinen asennus käytöstä ja asenna GPU-operaattori.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseHuomautus: Koska asennettu kuva on suhteellisen suuri, ensimmäisen asennuksen aikana voi tapahtua aikakatkaisu. Tarkista, onko kuvasi vedetty onnistuneesti. Voit harkita offline-asennuksen käyttöä tämän tyyppisen ongelman ratkaisemiseksi.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseOikean suorituksen tulos on seuraava:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneKun olet suorittanut GPU-operaattorin asennuskomennon, odota kärsivällisesti, kunnes kaikki kuvat on vedetty onnistuneesti ja kaikki Podit ovat käynnissä-tilassa.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110havainnollistaa: Keskity
nvidia.com/gpu:Kentän arvo.
Onnistuneesti luotu työmäärä on seuraava:
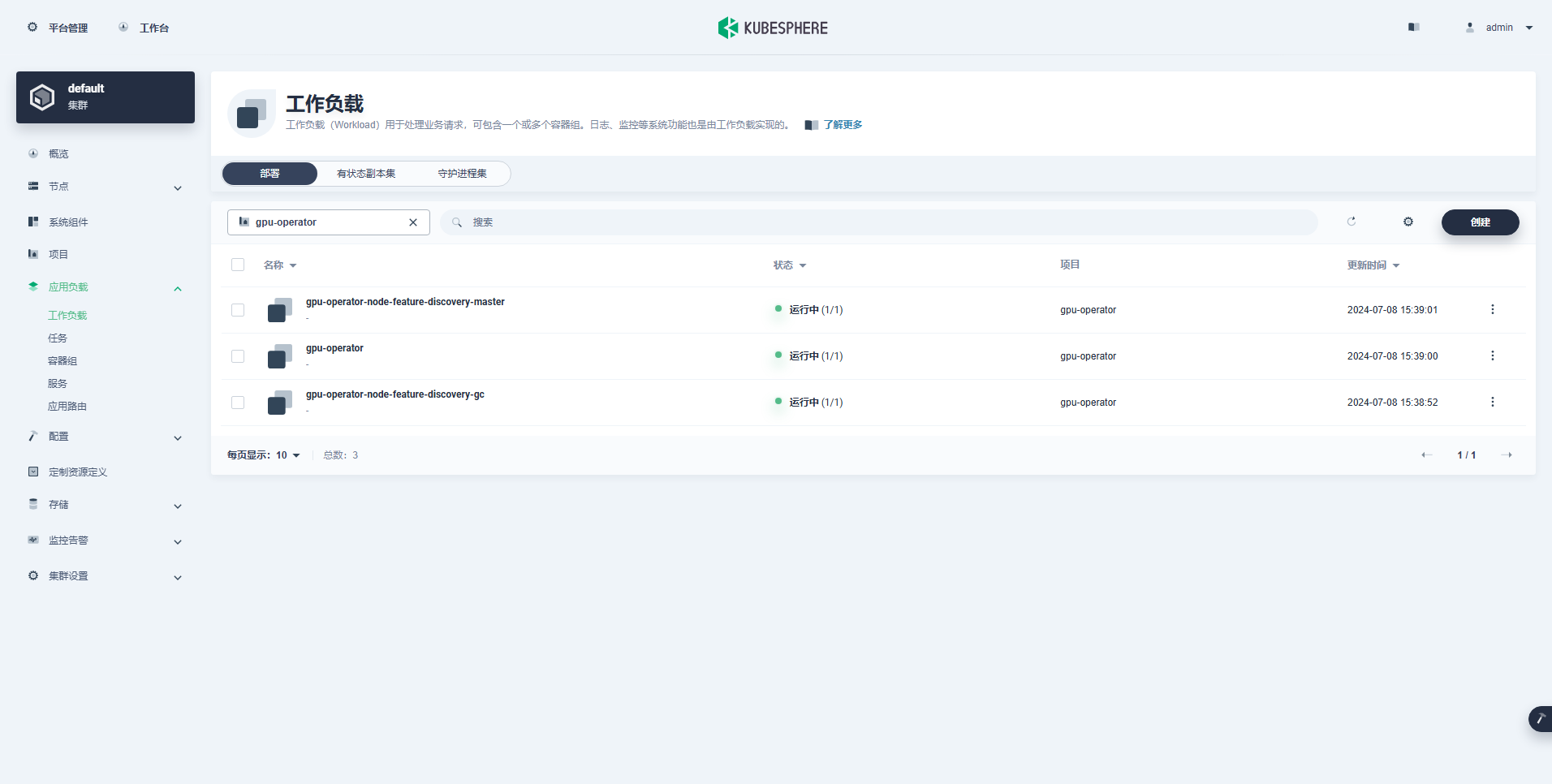
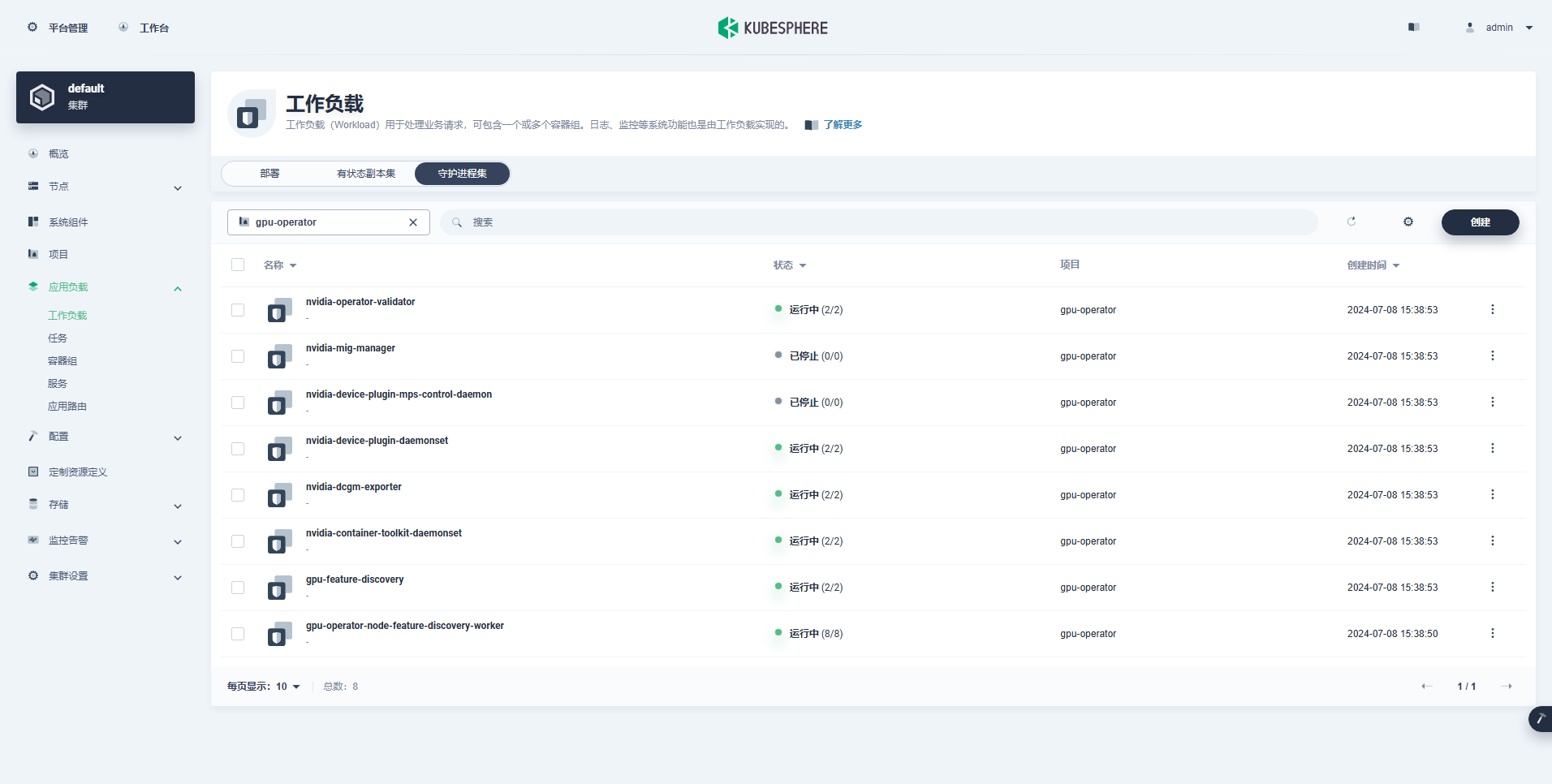
Kun GPU-operaattori on asennettu oikein, testaa CUDA-peruskuvan avulla, voivatko K8:t luoda GPU-resursseja käyttäviä podeja oikein.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlTuloksista voit nähdä, että pod luotiin ksp-gpu-worker-2-solmuun (Node-näytönohjaimen malli Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Oikean suorituksen tulos on seuraava:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlToteuta yksinkertainen CUDA-esimerkki kahden vektorin lisäämiseksi.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlPod on luotu onnistuneesti ja toimii käynnistyksen jälkeen. vectorAdd komento ja poistu.
$ kubectl logs pod/cuda-vectoraddOikean suorituksen tulos on seuraava:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlYllä olevan varmistustestin avulla on todistettu, että GPU:ta käyttävät Pod-resurssit voidaan luoda K8s-klusteriin. Seuraavaksi käytämme KubeSphereä suuren mallinhallintatyökalun Ollaman luomiseen K8s-klusteriin todellisten käyttövaatimusten perusteella.
Tämä esimerkki on yksinkertainen testi, ja tallennustila valitaan hostPath Tila, vaihda se tallennusluokkaan tai muun tyyppiseen jatkuvaan tallennustilaan todellisessa käytössä.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortErityisohjeet: KubeSpheren hallintakonsoli tukee käyttöönoton ja muiden resurssien graafista määritystä GPU-resurssien käyttöä varten. Kiinnostuneet ystävät voivat opiskella itse.
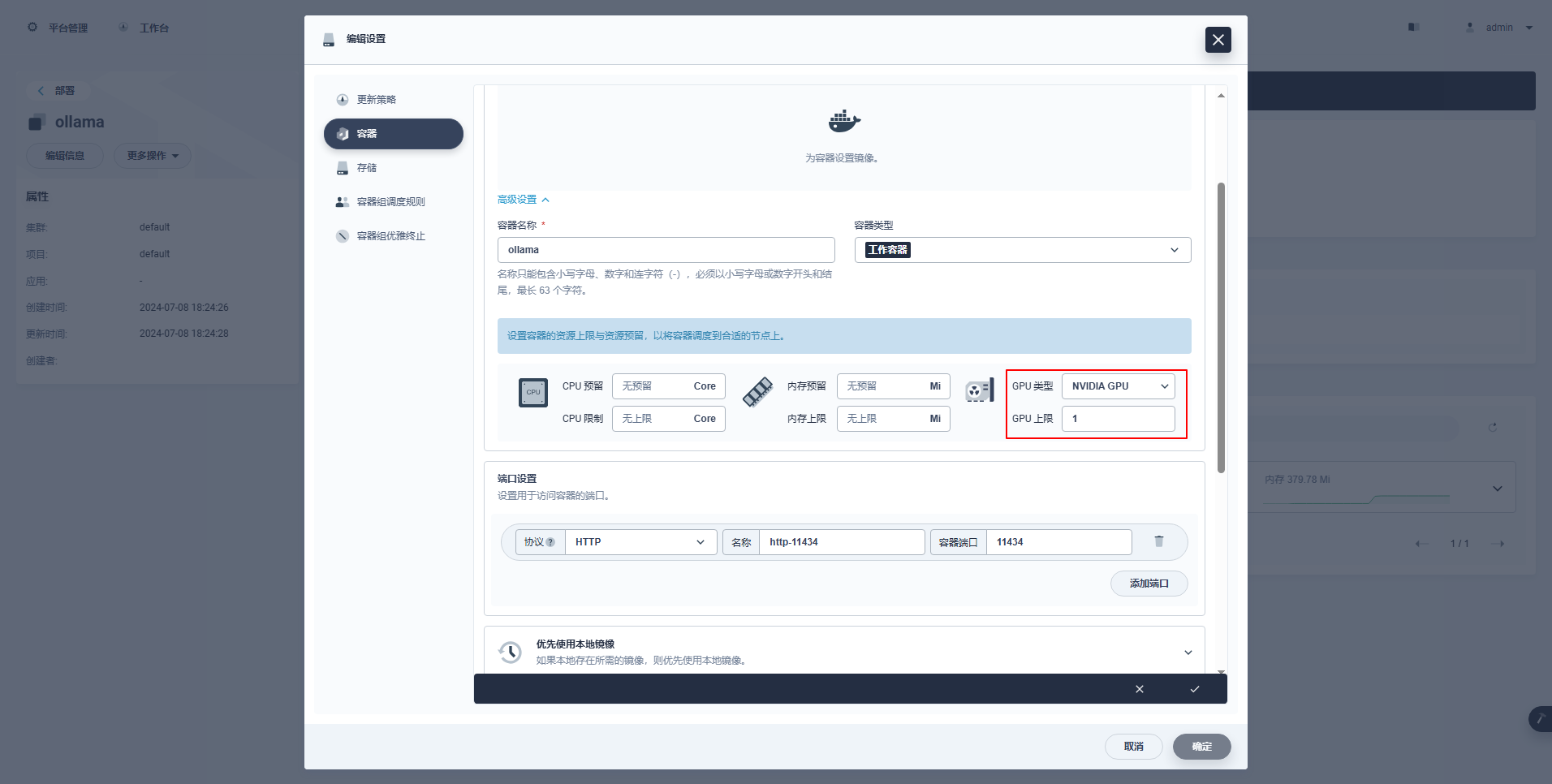
kubectl apply -f deploy-ollama.yamlTuloksista näet, että pod luotiin solmuun ksp-gpu-worker-1 (Node-näytönohjaimen malli Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Ajan säästämiseksi tässä esimerkissä testimallina käytetään Alibaban avoimen lähdekoodin qwen2 1.5b pienikokoista mallia.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bOikean suorituksen tulos on seuraava:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successolla olemassa ksp-gpu-worker-1 Solmu suorittaa seuraavan näkymäkomennon
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Suorita Worker-solmussa nvidia-smi -l Tarkkaile GPU:n käyttöä.
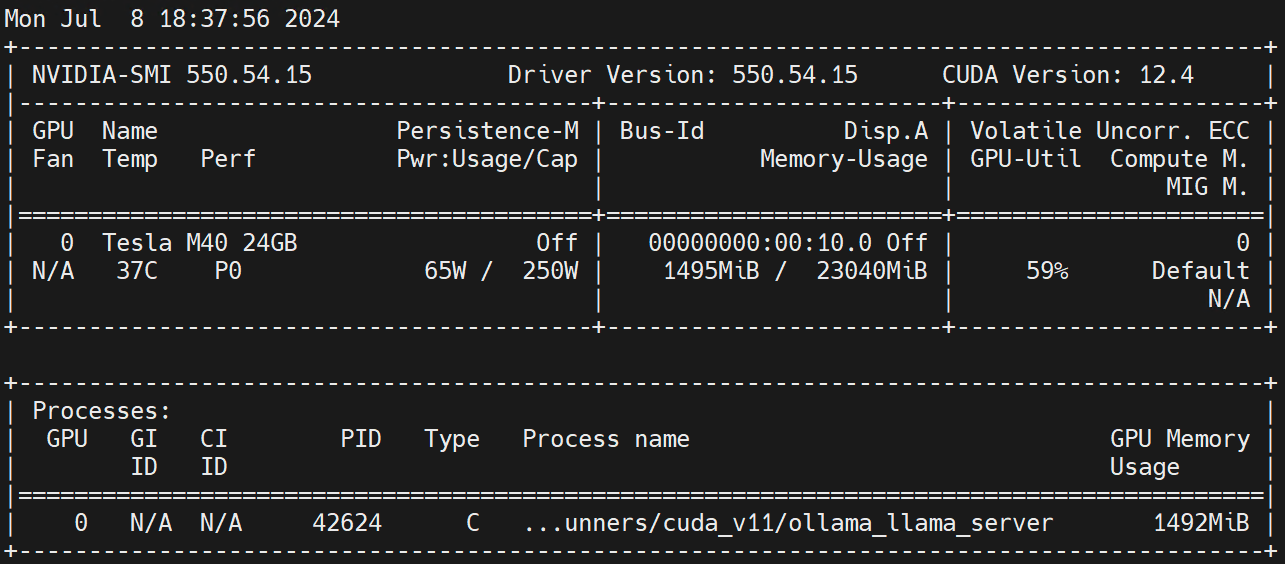
Vastuuvapauslauseke:
Tämän artikkelin on julkaissut Blog One Post Multi-Publishing Platform OpenWrite vapauttaa!

Hän on omistautunut teknologian tutkimukselle yli 30 vuoden ajan ja hallitsee useita kieliä, kuten java, linux, javascript, php, css jne. Hän on tehnyt paljon työtä avoimen lähdekoodin alalla Kehittäjän dokumentaatioasema, jossa voit jakaa joitakin teknologian kehittämisen ongelmia myöhempää käyttöä varten

