
私の連絡先情報
郵便メール:
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
著者: 運用保守 Youshu Star Master 人工知能、機械学習、AI 大型モデル技術の急速な発展に伴い、コンピューティング リソースの需要も高まっています。特に大規模なデータと複雑なアルゴリズムを処理する必要がある大規模な AI モデルの場合、GPU リソースの使用が重要になります。運用およびメンテナンス エンジニアにとって、Kubernetes クラスター上の GPU リソースを管理および構成する方法、およびこれらのリソースに依存するアプリケーションを効率的にデプロイする方法を習得することは、不可欠なスキルとなっています。
今日は、Kubernetes の強力なエコシステムとツールを使用して、KubeSphere プラットフォーム上で GPU リソース管理とアプリケーションのデプロイメントを実現する方法を深く理解できるように指導します。この記事で取り上げる 3 つの中心テーマは次のとおりです。
この記事を読むことで、Kubernetes で GPU リソースを管理するための知識とスキルを習得し、クラウドネイティブ環境で GPU リソースを最大限に活用し、AI アプリケーションの迅速な開発を促進することができます。
KubeSphere ベスト プラクティス "2024" 一連のドキュメントの実験環境のハードウェア構成とソフトウェア情報は以下のとおりです。
実際のサーバー構成 (小規模な運用環境のアーキテクチャ 1:1 レプリカ、構成は若干異なります)
| CPU名 | IP | CPU | メモリ | システムディスク | データディスク | 使用 |
|---|---|---|---|---|---|---|
| kspレジストリ | 192.168.9.90 | 4 | 8 | 40 | 200 | ハーバーミラー倉庫 |
| ksp-コントロール-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s コントロールプレーン |
| ksp-コントロール-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s コントロールプレーン |
| ksp-コントロール-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s コントロールプレーン |
| ksp-ワーカー-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-ワーカー/CI |
| ksp-ワーカー-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8sワーカー |
| ksp-ワーカー-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8sワーカー |
| ksp-ストレージ-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | エラスティックサーチ/Ceph/Longhorn/NFS/ |
| ksp-ストレージ-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | エラスティックサーチ//Ceph/Longhorn |
| ksp-ストレージ-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | エラスティックサーチ//Ceph/Longhorn |
| ksp-gpu-ワーカー-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-ワーカー-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla P100 16G) |
| ksp-ゲートウェイ-1 | 192.168.9.103 | 2 | 4 | 40 | 自己構築されたアプリケーション サービス プロキシ ゲートウェイ/VIP: 192.168.9.100 | |
| ksp-ゲートウェイ-2 | 192.168.9.104 | 2 | 4 | 40 | 自己構築されたアプリケーション サービス プロキシ ゲートウェイ/VIP: 192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | k8s クラスターの外部にデプロイされたサービス ノード (Gitlab など) |
| 合計 | 15 | 56 | 152 | 600 | 2000 |
実際の戦闘環境にはソフトウェアのバージョン情報が関係します
リソースとコストの制約により、実験できるハイエンドの物理ホストとグラフィックス カードがありません。クラスターのワーカー ノードとして追加できるのは、エントリー レベルの GPU グラフィックス カードを搭載した 2 つの仮想マシンのみです。
これらのグラフィックス カードはハイエンド モデルほど強力ではありませんが、リソースが限られているため、ほとんどの学習および開発タスクには十分です。このような構成は、Kubernetes クラスターの GPU リソースを深く調査する貴重な実践的な機会を提供します。スケジュール戦略。
を参照してください。 Kubernetes クラスター ノード openEuler 22.03 LTS SP3 システム初期化ガイド、オペレーティング システムの初期化構成を完了します。
初期構成ガイドには、オペレーティング システムのアップグレード タスクは含まれていません。インターネットにアクセスできる環境でシステムを初期化する場合は、オペレーティング システムをアップグレードしてからノードを再起動する必要があります。
次に、KubeKey を使用して、新しく追加した GPU ノードを既存の Kubernetes クラスターに追加します。このプロセス全体は比較的単純で、必要な手順は 2 つだけです。
Control-1 ノードで、デプロイメント用の kubekey ディレクトリに切り替え、実際の戦闘で使用した元のクラスター構成ファイルを変更します。 ksp-v341-v1288.yaml実際の状況に応じて修正してください。
主な修正点:
変更された例は次のとおりです。
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变ノードを追加する前に、現在のクラスターのノード情報を確認しましょう。
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13次に、次のコマンドを実行し、変更した構成ファイルを使用して新しいワーカー ノードをクラスターに追加します。
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yaml上記のコマンドが実行されると、KubeKey はまず、Kubernetes をデプロイするための依存関係とその他の構成が要件を満たしているかどうかを確認します。チェックに合格すると、インストールの確認を求めるメッセージが表示されます。入力 はい Enter キーを押して展開を続行します。
導入が完了するまでにかかる時間は、ネットワーク速度、マシン構成、および追加されたノードの数によって異なります。
デプロイが完了すると、ターミナルに次のような出力が表示されるはずです。
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyブラウザを開いて、Control-1 ノードの IP アドレスとポートにアクセスします。 30880、KubeSphere管理コンソールのログインページにログインします。
クラスター管理インターフェイスに入り、左側の [ノード] メニューをクリックし、[クラスター ノード] をクリックして、Kubernetes クラスターの使用可能なノードに関する詳細情報を表示します。
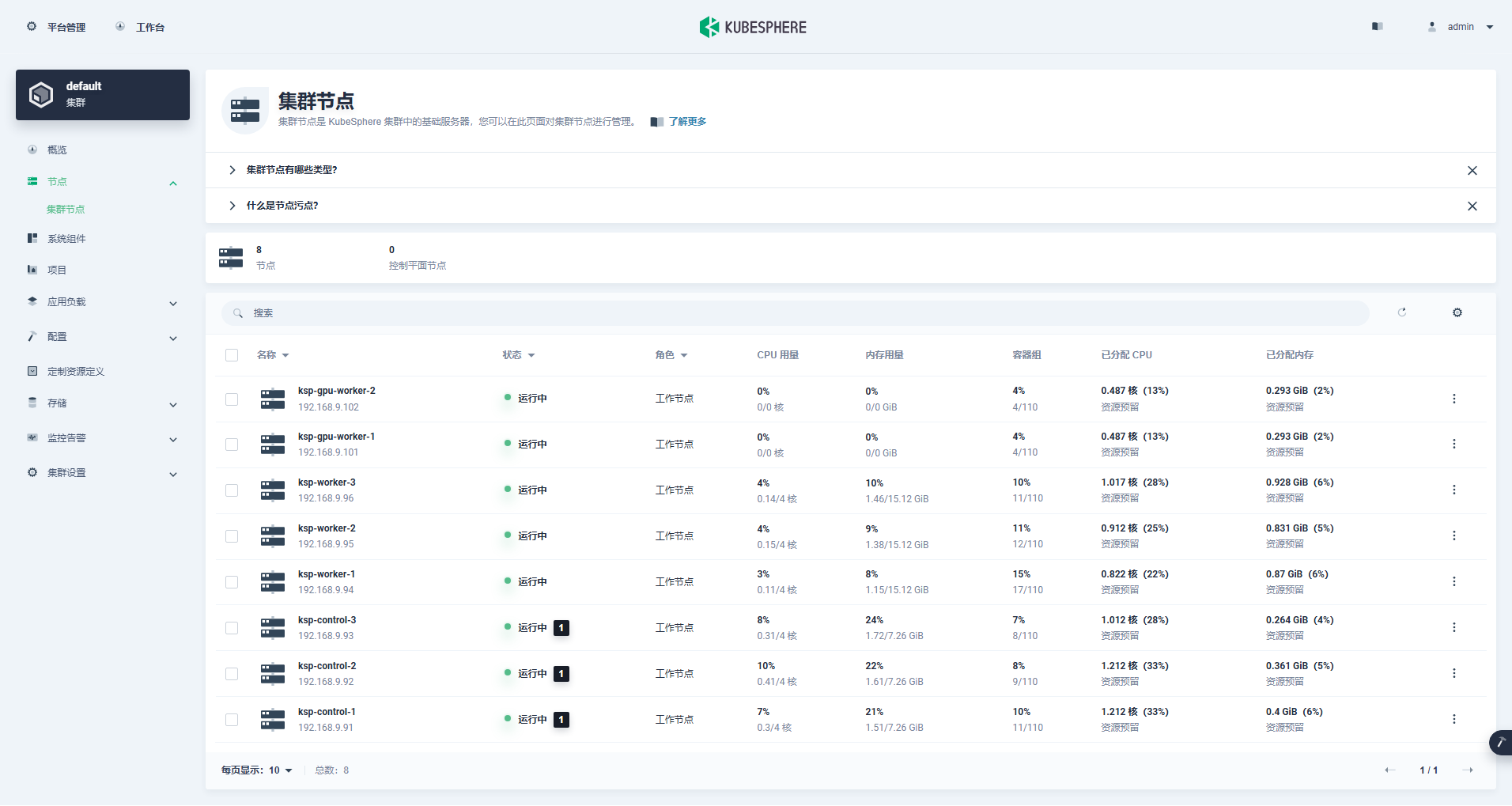
Control-1 ノードで kubectl コマンドを実行して、Kubernetes クラスターのノード情報を取得します。
kubectl get nodes -o wide出力でわかるように、現在の Kubernetes クラスターには 8 つのノードがあり、各ノードの名前、ステータス、ロール、生存時間、Kubernetes バージョン番号、内部 IP、オペレーティング システムの種類、カーネル バージョン、コンテナー ランタイムが詳細に表示されます。 、その他の情報。
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13この時点で、Kubekey を使用して 3 つのマスター ノードと 3 つのワーカー ノードで構成される既存の Kubernetes クラスターに 2 つのワーカー ノードを追加するすべてのタスクが完了しました。
次に、GPU リソースを使用する K8s スケジューリング Pod を実現するために、NVIDIA が公式に作成した NVIDIA GPU Operator をインストールします。
NVIDIA GPU Operator はグラフィックス ドライバーの自動インストールをサポートしていますが、CentOS 7、8 と Ubuntu 20.04、22.04 およびその他のバージョンのみが openEuler をサポートしていないため、グラフィックス ドライバーを手動でインストールする必要があります。
を参照してください。 KubeSphere のベスト プラクティス: openEuler 22.03 LTS SP3 は NVIDIA グラフィック カード ドライバーをインストールします、グラフィックス カード ドライバーのインストールを完了します。
ノード機能検出 (NFD) は機能チェックを検出します。
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'上記コマンドの実行結果は、 true、図解 NFD すでにクラスター内で実行されています。 NFD がすでにクラスター内で実行されている場合は、オペレーターのインストール時に NFD の展開を無効にする必要があります。
例証します: KubeSphere を使用してデプロイされた K8s クラスターは、デフォルトでは NFD をインストールおよび構成しません。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateデフォルトの構成ファイルを使用し、グラフィックス カード ドライバーの自動インストールを無効にして、GPU Operator をインストールします。
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false注: インストールされたイメージは比較的大きいため、最初のインストール中にタイムアウトが発生する可能性があります。イメージが正常に取得されたかどうかを確認してください。この種の問題を解決するには、オフライン インストールの使用を検討できます。
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false正しく実行された場合の出力結果は次のとおりです。
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneGPU Operator をインストールするコマンドを実行した後、すべてのイメージが正常にプルされ、すべての Pod が実行状態になるまで辛抱強くお待ちください。
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110例証します: 集中
nvidia.com/gpu:フィールドの値。
正常に作成されたワークロードは次のとおりです。
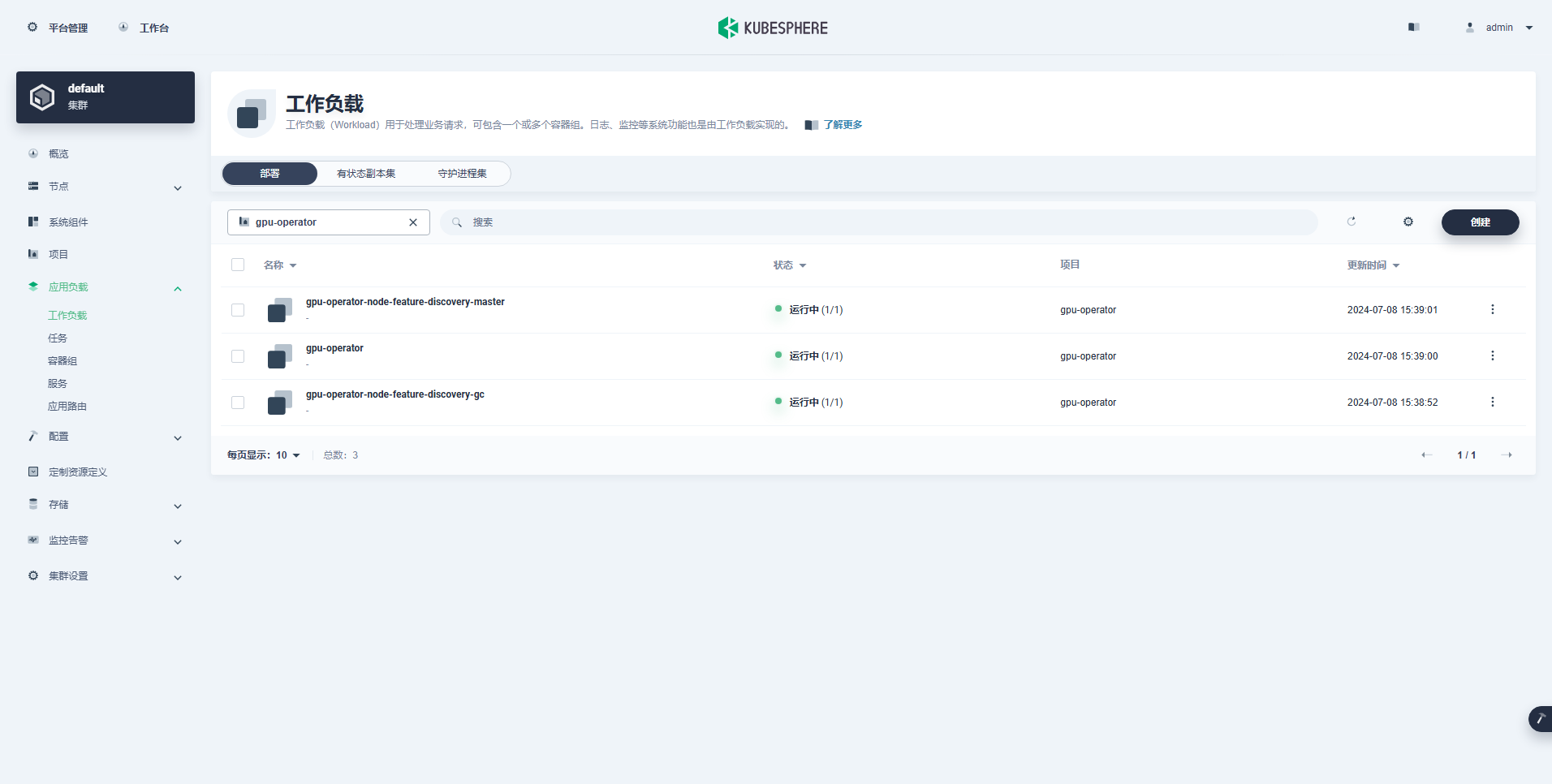
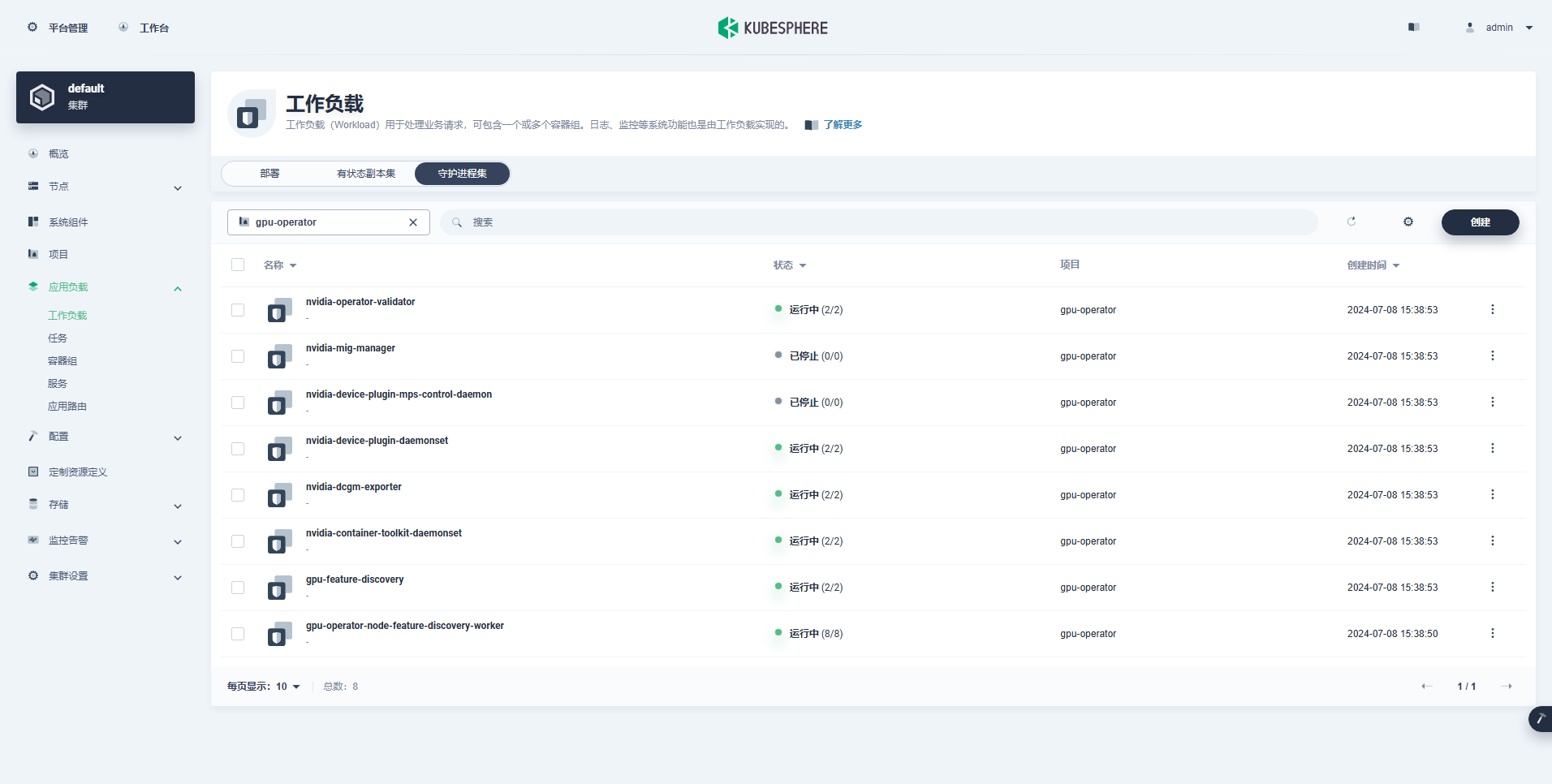
GPU Operator が正しくインストールされたら、CUDA 基本イメージを使用して、K8 が GPU リソースを使用する Pod を正しく作成できるかどうかをテストします。
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yaml結果から、ポッドが ksp-gpu-worker-2 ノードに作成されたことがわかります (ノード グラフィックス カード モデル Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204正しく実行された場合の出力結果は次のとおりです。
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yaml2 つのベクトルを追加するための簡単な CUDA サンプルを実装します。
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlポッドは正常に作成され、起動後に実行されます。 vectorAdd コマンドを実行して終了します。
$ kubectl logs pod/cuda-vectoradd正しく実行された場合の出力結果は次のとおりです。
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yaml以上の検証により、K8s クラスタ上に GPU を利用した Pod リソースを作成できることが確認できました。 次に、実際の使用要件に基づいて、KubeSphere を使用して、K8s クラスタ上に大規模なモデル管理ツール Ollama を作成します。
この例は簡単なテストであり、ストレージが選択されています ホストパス 実際に使用する場合は、ストレージ クラスまたは他の種類の永続ストレージに置き換えてください。
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePort特別な指示: KubeSphere の管理コンソールは、GPU リソースを使用するためのデプロイメントおよびその他のリソースのグラフィカルな構成をサポートしています。興味のある方は、ご自身で学習してください。
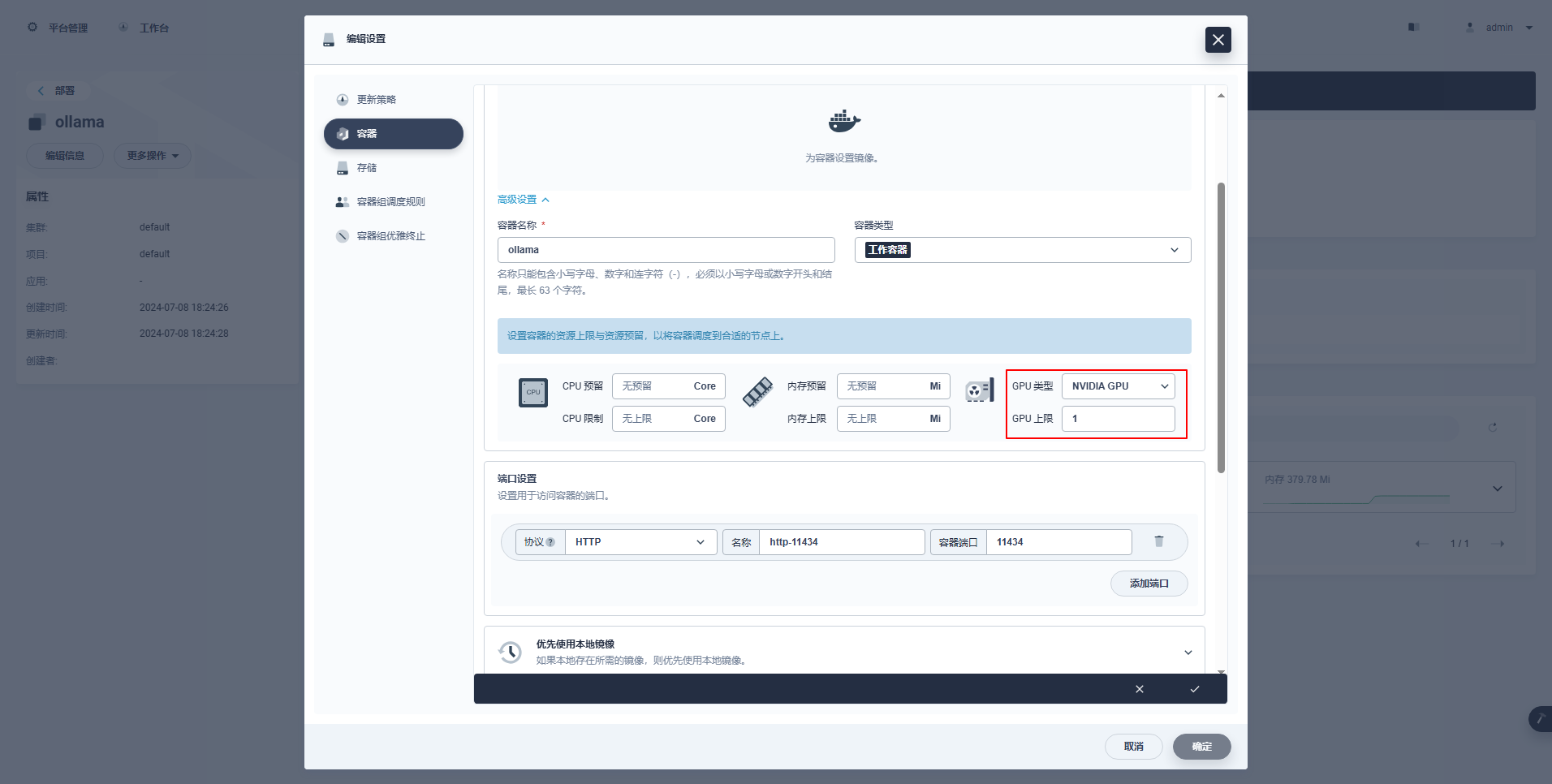
kubectl apply -f deploy-ollama.yaml結果から、ポッドが ksp-gpu-worker-1 ノードに作成されたことがわかります (ノード グラフィックス カード モデル Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"時間を節約するために、この例では Alibaba のオープンソース qwen2 1.5b 小型モデルをテスト モデルとして使用します。
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b正しく実行された場合の出力結果は次のとおりです。
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success存在する ksp-gpu-ワーカー-1 ノードは次の view コマンドを実行します。
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
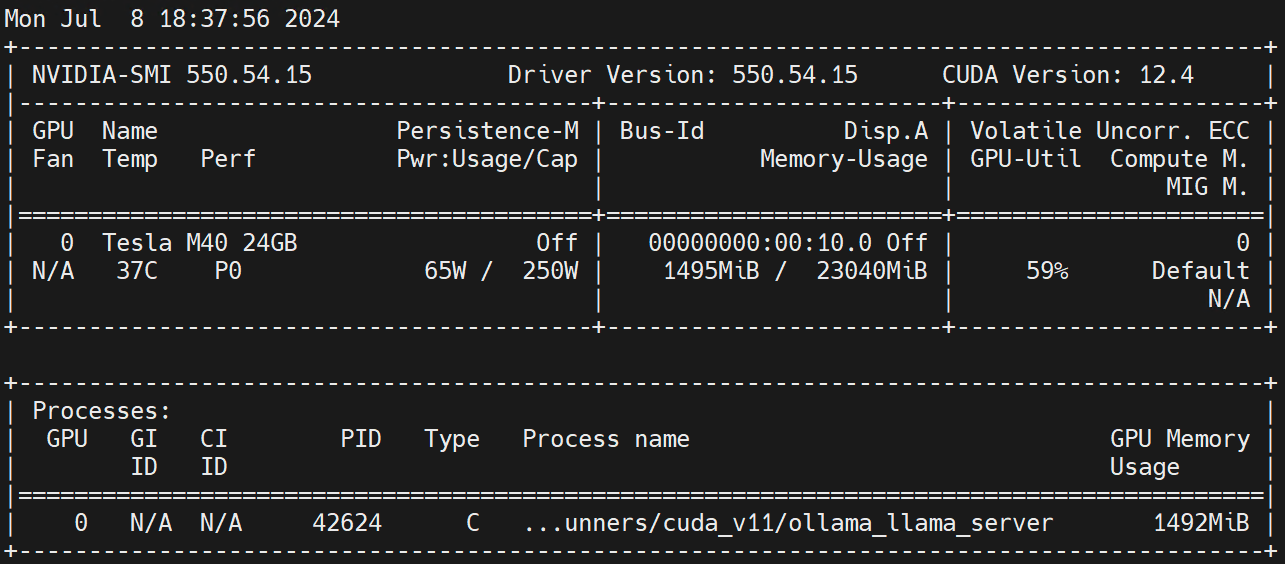
nvidia.com/gpu 1 1ワーカーノードで実行 nvidia-smi -l GPU の使用率を観察します。
免責事項:
この記事は Blog One ポスト マルチパブリッシング プラットフォームによって公開されています オープンライト リリース!

彼は 30 年以上テクノロジーの研究に専念しており、java、linux、javascript、php、css などのさまざまな言語に堪能であり、オープンソース分野で多くの貢献を行っています。将来の参考のために技術開発におけるいくつかの問題を共有する開発者ドキュメント ステーション。

郵便メール: