2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
लेखकः संचालनं अनुरक्षणं च Youshu Star Master कृत्रिमबुद्धेः, मशीनशिक्षणस्य, एआइ बृहत् मॉडलप्रौद्योगिक्याः च तीव्रविकासेन सह कम्प्यूटिंगसंसाधनानाम् अस्माकं माङ्गलिका अपि वर्धमाना अस्ति। विशेषतः बृहत् AI मॉडल् कृते येषु बृहत्-परिमाणस्य आँकडानां, जटिल-एल्गोरिदम्-इत्यस्य च संसाधनस्य आवश्यकता भवति, GPU संसाधनानाम् उपयोगः महत्त्वपूर्णः भवति । संचालन-रक्षण-इञ्जिनीयर्-कृते कुबेर्नेट्स्-समूहेषु GPU-संसाधनानाम् प्रबन्धनं विन्यस्तं च कथं करणीयम्, एतेषु संसाधनेषु निर्भराः अनुप्रयोगाः कथं कुशलतया परिनियोजिताः इति निपुणतां प्राप्तुं अनिवार्यं कौशलं जातम्
अद्य अहं भवन्तं KubeSphere मञ्चे GPU संसाधनप्रबन्धनं अनुप्रयोगनियोजनं च प्राप्तुं Kubernetes इत्यस्य शक्तिशालिनः पारिस्थितिकीतन्त्रस्य साधनानां च उपयोगः कथं करणीयः इति गहनबोधं प्राप्तुं नेष्यामि। अत्र त्रयः मूलविषयाः अयं लेखः अन्वेषयिष्यति-
एतत् लेखं पठित्वा, भवान् Kubernetes इत्यत्र GPU संसाधनानाम् प्रबन्धनार्थं ज्ञानं कौशलं च प्राप्स्यति, यत् भवान् क्लाउड्-देशीयवातावरणे GPU संसाधनानाम् पूर्णं उपयोगं कर्तुं सहायकं भविष्यति तथा च AI अनुप्रयोगानाम् द्रुतविकासं प्रवर्धयति
KubeSphere सर्वोत्तम अभ्यास "2024"। दस्तावेजश्रृङ्खलायाः प्रयोगात्मकवातावरणस्य हार्डवेयरविन्यासः सॉफ्टवेयरसूचना च निम्नलिखितरूपेण सन्ति ।
वास्तविकं सर्वरविन्यासः (लघु-परिमाणस्य उत्पादनवातावरणस्य वास्तुकला १:१ प्रतिकृतिः, विन्यासः किञ्चित् भिन्नः अस्ति)
| CPU नाम | IP | CPU | स्मृति | system disk | data disk | उपयुञ्जताम् |
|---|---|---|---|---|---|---|
| ksp-पञ्जीकरणम् | 192.168.9.90 | 4 | 8 | 40 | 200 | बन्दरगाहदर्पणगोदाम |
| ksp-नियन्त्रण-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | कुबेगोल/k8s-नियन्त्रण-विमान |
| ksp-नियन्त्रण-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | कुबेगोल/k8s-नियन्त्रण-विमान |
| ksp-नियन्त्रण-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | कुबेगोल/k8s-नियन्त्रण-विमान |
| ksp-कार्यकर्ता-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-कार्यकर्ता/CI |
| ksp-कार्यकर्ता-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-कार्यकर्ता |
| ksp-कार्यकर्ता-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-कार्यकर्ता |
| ksp-भण्डारण-१ | 192.168.9.97 | 4 | 8 | 40 | 300+ | इलास्टिकसर्च/सेफ/लॉन्गहॉर्न/एनएफएस/ |
| ksp-भण्डारण-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//सेफ/लॉन्गहॉर्न |
| ksp-भण्डारण-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//सेफ/लॉन्गहॉर्न |
| ksp-gpu-कार्यकर्ता-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA टेस्ला M40 24G) |
| ksp-gpu-कार्यकर्ता-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA टेस्ला P100 16G) |
| ksp-द्वार-1 | 192.168.9.103 | 2 | 4 | 40 | स्वनिर्मित अनुप्रयोगसेवा प्रॉक्सी गेटवे/VIP: 192.168.9.100 | |
| ksp-द्वार-2 | 192.168.9.104 | 2 | 4 | 40 | स्वनिर्मित अनुप्रयोगसेवा प्रॉक्सी गेटवे/VIP: 192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | k8s क्लस्टर् (Gitlab इत्यादि) बहिः नियोजिताः सेवानोड्स् |
| कुल | 15 | 56 | 152 | 600 | 2000 |
वास्तविकयुद्धवातावरणे सॉफ्टवेयरसंस्करणसूचना अन्तर्भवति
संसाधनस्य, व्ययस्य च बाधायाः कारणात् मम समीपे प्रयोगार्थं उच्चस्तरीयं भौतिकं होस्ट्, ग्राफिक्स् कार्ड् च नास्ति । केवलं प्रवेशस्तरीय-GPU-ग्राफिक्स्-कार्ड्-युक्तौ वर्चुअल्-यन्त्रद्वयं क्लस्टरस्य वर्कर्-नोड्-रूपेण योजयितुं शक्यते ।
यद्यपि एते ग्राफिक्स् कार्ड्स् उच्चस्तरीयाः मॉडल् इव शक्तिशालिनः न सन्ति तथापि ते अधिकांशशिक्षणस्य विकासस्य च कार्याणां कृते पर्याप्ताः सन्ति तथापि एतादृशः विन्यासः मम कृते Kubernetes क्लस्टर्स् मध्ये GPU संसाधनानाम् गहनतया अन्वेषणार्थं बहुमूल्यं हस्तगतं अवसरं प्रदाति समयनिर्धारण रणनीतयः।
कृपया देखें Kubernetes क्लस्टर नोड् openEuler 22.03 LTS SP3 प्रणाली आरम्भमार्गदर्शिका, प्रचालनतन्त्रस्य आरम्भविन्यासं सम्पूर्णं कुर्वन्तु ।
प्रारम्भिकविन्यासमार्गदर्शिकायां प्रचालनतन्त्रस्य उन्नयनकार्यं न भवति यदा अन्तर्जालप्रवेशयुक्ते वातावरणे प्रणालीं आरभते तदा भवद्भिः प्रचालनतन्त्रस्य उन्नयनं करणीयम् ततः नोड् पुनः आरभणीयम् ।
तदनन्तरं वयं KubeKey इत्यस्य उपयोगं कुर्मः यत् विद्यमानस्य Kubernetes क्लस्टरस्य मध्ये नवनिर्मितं GPU नोड् योजयितुं शक्नुमः सम्पूर्णं प्रक्रिया तुल्यकालिकरूपेण सरलं भवति तथा च केवलं द्वौ चरणौ आवश्यकौ भवतः ।
Control-1 नोड् इत्यत्र, परिनियोजनार्थं kubekey निर्देशिकायां स्विच् कुर्वन्तु तथा च मूलक्लस्टरविन्याससञ्चिकां परिवर्तयन्तु वास्तविकयुद्धे वयं यत् नाम प्रयुक्तवन्तः तत् अस्ति ksp-v341-v1288.यम्ल, कृपया वास्तविकस्थित्यानुसारं परिवर्तनं कुर्वन्तु ।
मुख्यसंशोधनबिन्दवः : १.
परिवर्तितं उदाहरणं यथा - १.
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变नोड् योजयितुं पूर्वं वर्तमानक्लस्टर् इत्यस्य नोड् सूचनां पुष्टयामः ।
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13तदनन्तरं वयं निम्नलिखितम् आदेशं निष्पादयामः तथा च नूतनं Worker नोड् क्लस्टर् मध्ये योजयितुं परिवर्तितां विन्याससञ्चिकां उपयुञ्ज्महे ।
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlउपर्युक्तस्य आदेशस्य निष्पादनस्य अनन्तरं KubeKey प्रथमं परीक्षते यत् Kubernetes परिनियोजनाय आश्रयाः अन्ये च विन्यासाः आवश्यकताः पूरयन्ति वा इति । चेकं पारयित्वा भवन्तः संस्थापनस्य पुष्टिं कर्तुं प्रार्थयिष्यन्ति ।प्रवेशआम् तथा परिनियोजनं निरन्तरं कर्तुं ENTER नुदन्तु।
परिनियोजनं पूर्णं कर्तुं प्रायः ५ निमेषाः भवन्ति ।
एकदा परिनियोजनं सम्पन्नं जातं चेत्, भवान् स्वस्य टर्मिनल् मध्ये निम्नलिखितसदृशं आउटपुट् द्रष्टव्यम् ।
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyवयं ब्राउजर् उद्घाट्य Control-1 नोड् इत्यस्य IP-सङ्केतं पोर्ट् च अभिगच्छामः 30880, KubeSphere प्रबन्धनकन्सोल् इत्यस्य प्रवेशपृष्ठे प्रवेशं कुर्वन्तु ।
क्लस्टर प्रबन्धन अन्तरफलकं प्रविश्य वामभागे "Node" मेन्यू नुदन्तु, Kubernetes क्लस्टरस्य उपलब्धनोड्स् विषये विस्तृतसूचनाः द्रष्टुं "Cluster Node" नुदन्तु ।
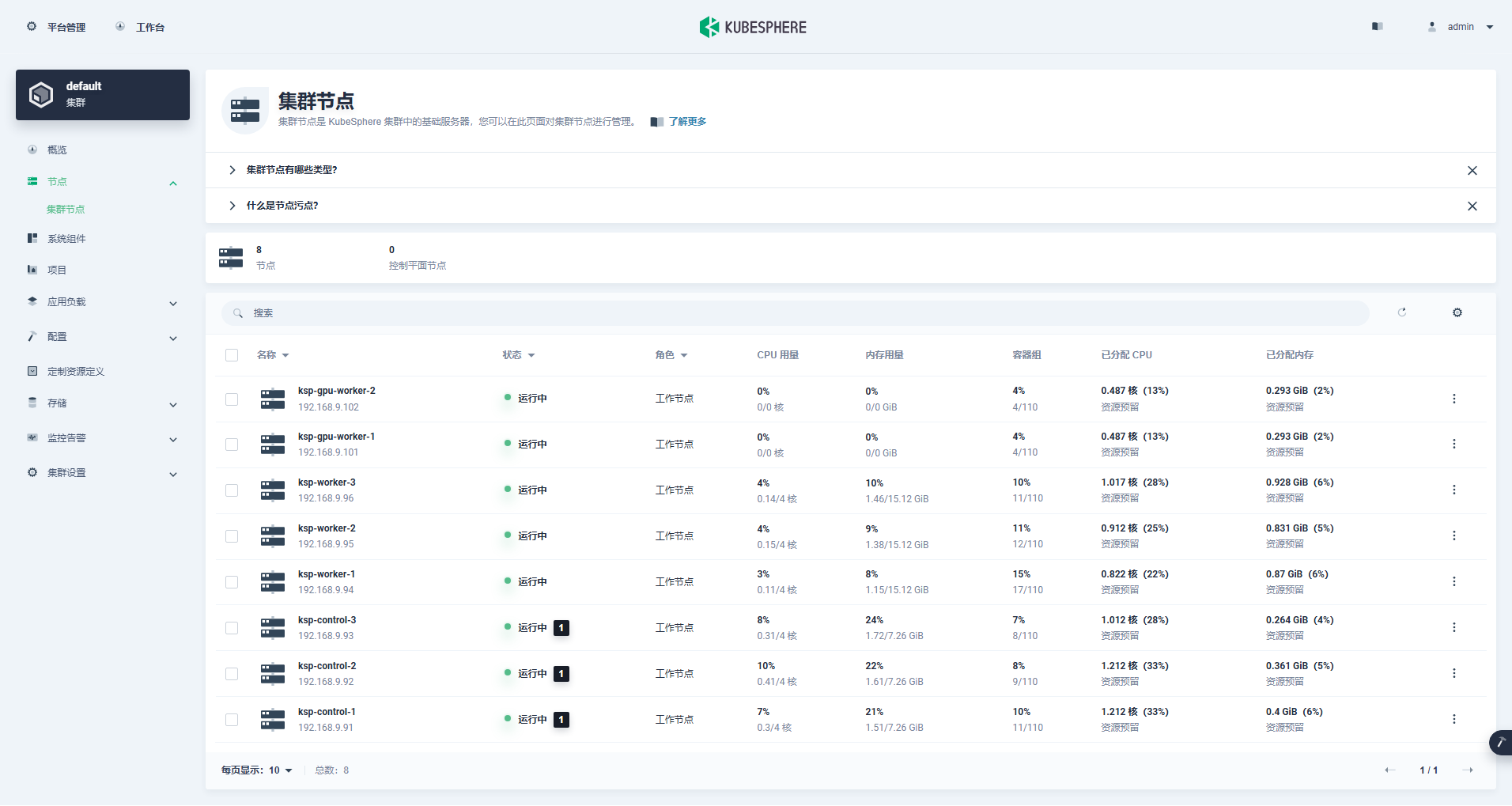
Kubernetes क्लस्टरस्य नोड् सूचनां प्राप्तुं Control-1 नोड् इत्यत्र kubectl आदेशं चालयन्तु ।
kubectl get nodes -o wideयथा भवान् आउटपुट् मध्ये द्रष्टुं शक्नोति, वर्तमानस्य Kubernetes क्लस्टरस्य 8 नोड् सन्ति, तथा च प्रत्येकस्य नोड् इत्यस्य नाम, स्थितिः, भूमिका, जीवितस्य समयः, Kubernetes संस्करणसङ्ख्या, आन्तरिक IP, ऑपरेटिंग् सिस्टम् प्रकारः, कर्नेल् संस्करणं, कंटेनर रनटाइम् च विस्तरेण प्रदर्शितं भवति .इत्यादीनि सूचनानि।
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13अस्मिन् क्षणे वयं Kubekey इत्यस्य उपयोगस्य सर्वाणि कार्याणि सम्पन्नवन्तः यत् 3 Master nodes तथा 3 Worker nodes युक्ते विद्यमान Kubernetes क्लस्टरमध्ये 2 Worker nodes योजयितुं शक्नुमः ।
तदनन्तरं वयं GPU संसाधनानाम् उपयोगाय K8s scheduling Pod इत्यस्य साक्षात्कारं कर्तुं NVIDIA द्वारा आधिकारिकतया उत्पादितं NVIDIA GPU Operator संस्थापयामः ।
NVIDIA GPU Operator ग्राफिक्स् चालकस्य स्वचालितस्थापनं समर्थयति, परन्तु केवलं CentOS 7, 8 तथा Ubuntu 20.04, 22.04 इत्यादीनि संस्करणाः openEuler इत्यस्य समर्थनं न कुर्वन्ति, अतः भवद्भिः ग्राफिक्स् चालकं मैन्युअल् रूपेण संस्थापनीयम्
कृपया देखें KubeSphere इत्यस्य सर्वोत्तमः अभ्यासः: openEuler 22.03 LTS SP3 NVIDIA ग्राफिक्स् कार्ड् चालकं संस्थापयति, ग्राफिक्स् कार्ड् चालकस्य संस्थापनं सम्पूर्णं कुर्वन्तु ।
Node Feature Discovery (NFD) इत्यनेन feature checks इत्यस्य ज्ञापनं भवति ।
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'उपर्युक्तस्य आदेशस्य निष्पादनफलं भवति true, दृष्टान्तरूपेण दर्शयतु NFD पूर्वमेव समूहे प्रचलति। यदि NFD पूर्वमेव क्लस्टर् मध्ये चाल्यते तर्हि संचालकस्य संस्थापनसमये NFD परिनियोजनं निष्क्रियं भवितुमर्हति ।
दृष्टान्तरूपेण दर्शयतु : १. KubeSphere इत्यस्य उपयोगेन नियोजिताः K8s क्लस्टराः पूर्वनिर्धारितरूपेण NFD संस्थापनं न विन्यस्यन्ति च ।
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateपूर्वनिर्धारितविन्याससञ्चिकायाः उपयोगं कुर्वन्तु, ग्राफिक्स् कार्ड् चालकानां स्वचालितस्थापनं निष्क्रियं कुर्वन्तु, GPU Operator संस्थापयन्तु च ।
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseनोट्: यतः संस्थापितं चित्रं तुल्यकालिकं विशालं भवति, प्रारम्भिकस्थापनकाले समयसमाप्तिः भवितुम् अर्हति कृपया पश्यन्तु यत् भवतः चित्रं सफलतया आकृष्टम् अस्ति वा! एतादृशस्य समस्यायाः समाधानार्थं भवान् अफलाइन संस्थापनस्य उपयोगं विचारयितुं शक्नोति ।
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseसम्यक् निष्पादनस्य आउटपुट् परिणामः निम्नलिखितरूपेण भवति ।
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneGPU Operator संस्थापयितुं आदेशं निष्पादयित्वा कृपया धैर्यपूर्वकं प्रतीक्षन्तु यावत् सर्वाणि चित्राणि सफलतया आकृष्यन्ते तथा च सर्वाणि Pods Running अवस्थायां न भवन्ति ।
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110दृष्टान्तरूपेण दर्शयतु : १. केंद्रबिन्दुः
nvidia.com/gpu:क्षेत्रस्य मूल्यम् ।
सफलतया निर्मितः कार्यभारः निम्नलिखितरूपेण अस्ति ।
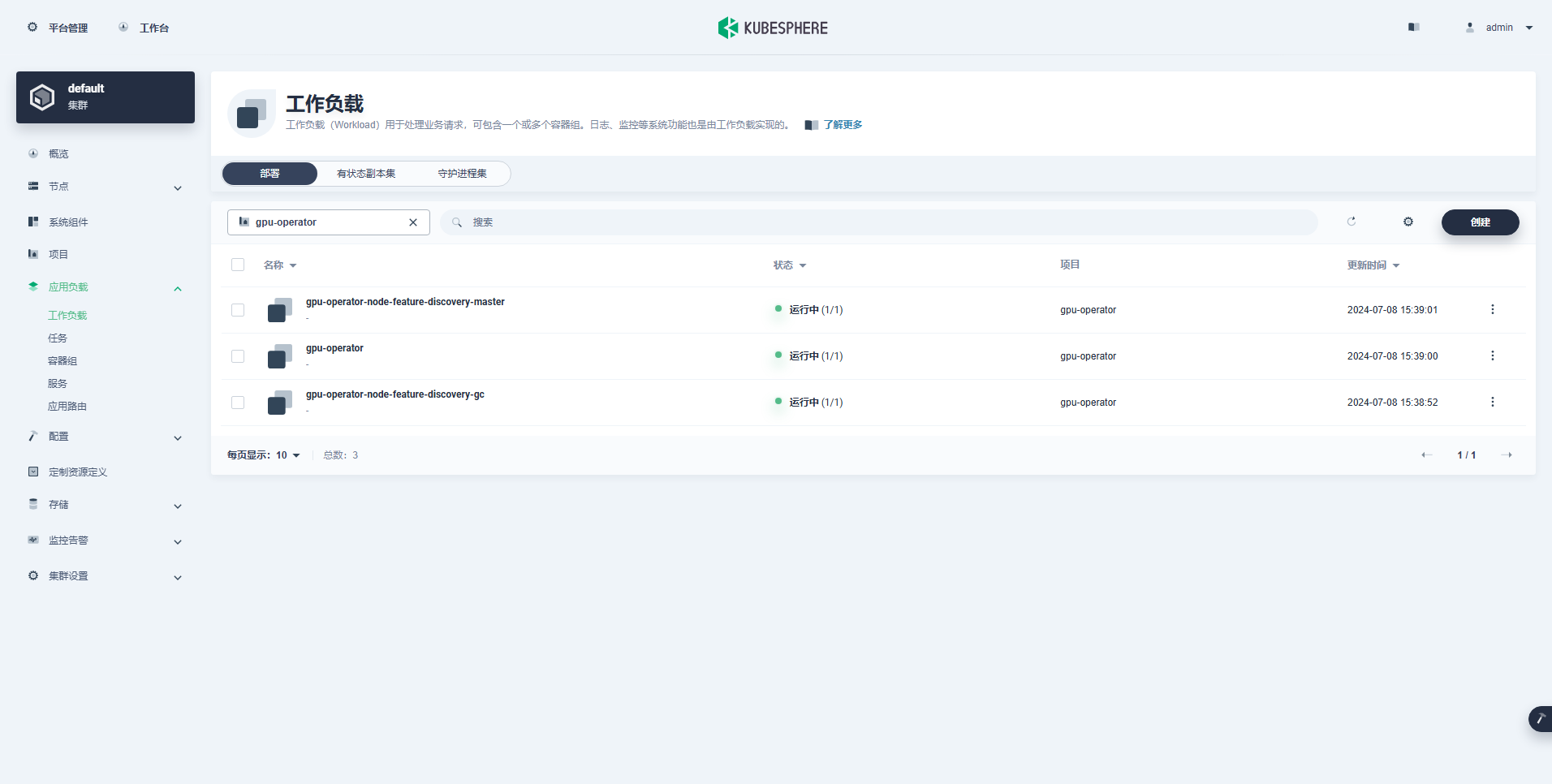
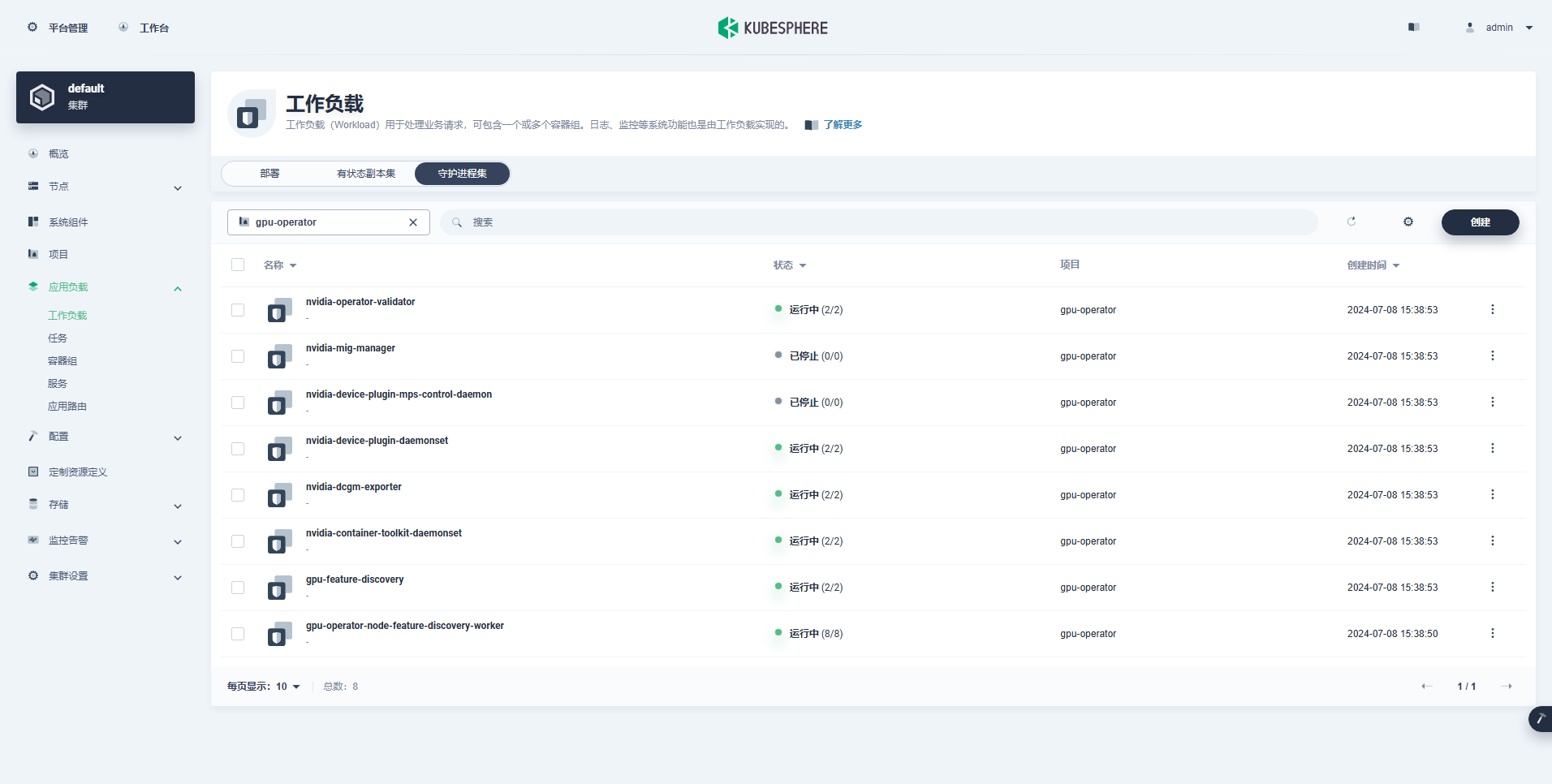
GPU Operator इत्यस्य सम्यक् संस्थापनानन्तरं, K8s GPU संसाधनानाम् उपयोगं कुर्वन्तः Pods सम्यक् निर्मातुं शक्नुवन्ति वा इति परीक्षितुं CUDA आधारप्रतिबिम्बस्य उपयोगं कुर्वन्तु ।
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlपरिणामेभ्यः भवन्तः द्रष्टुं शक्नुवन्ति यत् ksp-gpu-worker-2 नोड् (नोड् ग्राफिक्स् कार्ड् मॉडल् टेस्ला P100-PCIE-16GB इति)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204सम्यक् निष्पादनस्य आउटपुट् परिणामः निम्नलिखितरूपेण भवति ।
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlद्वौ सदिशौ योजयितुं सरलं CUDA उदाहरणं कार्यान्वितं कुर्वन्तु ।
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlPod सफलतया निर्मितं भवति, स्टार्टअप-पश्चात् च चालयिष्यति । vectorAdd आदेशं निर्गमनं च ।
$ kubectl logs pod/cuda-vectoraddसम्यक् निष्पादनस्य आउटपुट् परिणामः निम्नलिखितरूपेण भवति ।
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlउपर्युक्तसत्यापनपरीक्षायाः माध्यमेन सिद्धं भवति यत् GPU इत्यस्य उपयोगेन Pod संसाधनं K8s क्लस्टर् इत्यत्र निर्मातुं शक्यते तदनन्तरं वयं वास्तविक उपयोगस्य आवश्यकतानां आधारेण K8s क्लस्टर् मध्ये एकं विशालं मॉडल् प्रबन्धन साधनं Ollama निर्मातुं KubeSphere इत्यस्य उपयोगं कुर्मः ।
इदं उदाहरणं सरलं परीक्षणम् अस्ति, भण्डारणं च चयनितम् अस्ति hostPath मोड्, कृपया तस्य स्थाने भण्डारणवर्गः अथवा अन्यप्रकारस्य वास्तविकप्रयोगे निरन्तरं भण्डारणं स्थापयतु ।
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortविशेषनिर्देशाः : १. KubeSphere इत्यस्य प्रबन्धनकन्सोल् GPU संसाधनानाम् उपयोगाय Deployment इत्यस्य चित्रात्मकविन्यासस्य समर्थनं करोति विन्यासस्य उदाहरणानि निम्नलिखितरूपेण सन्ति ।
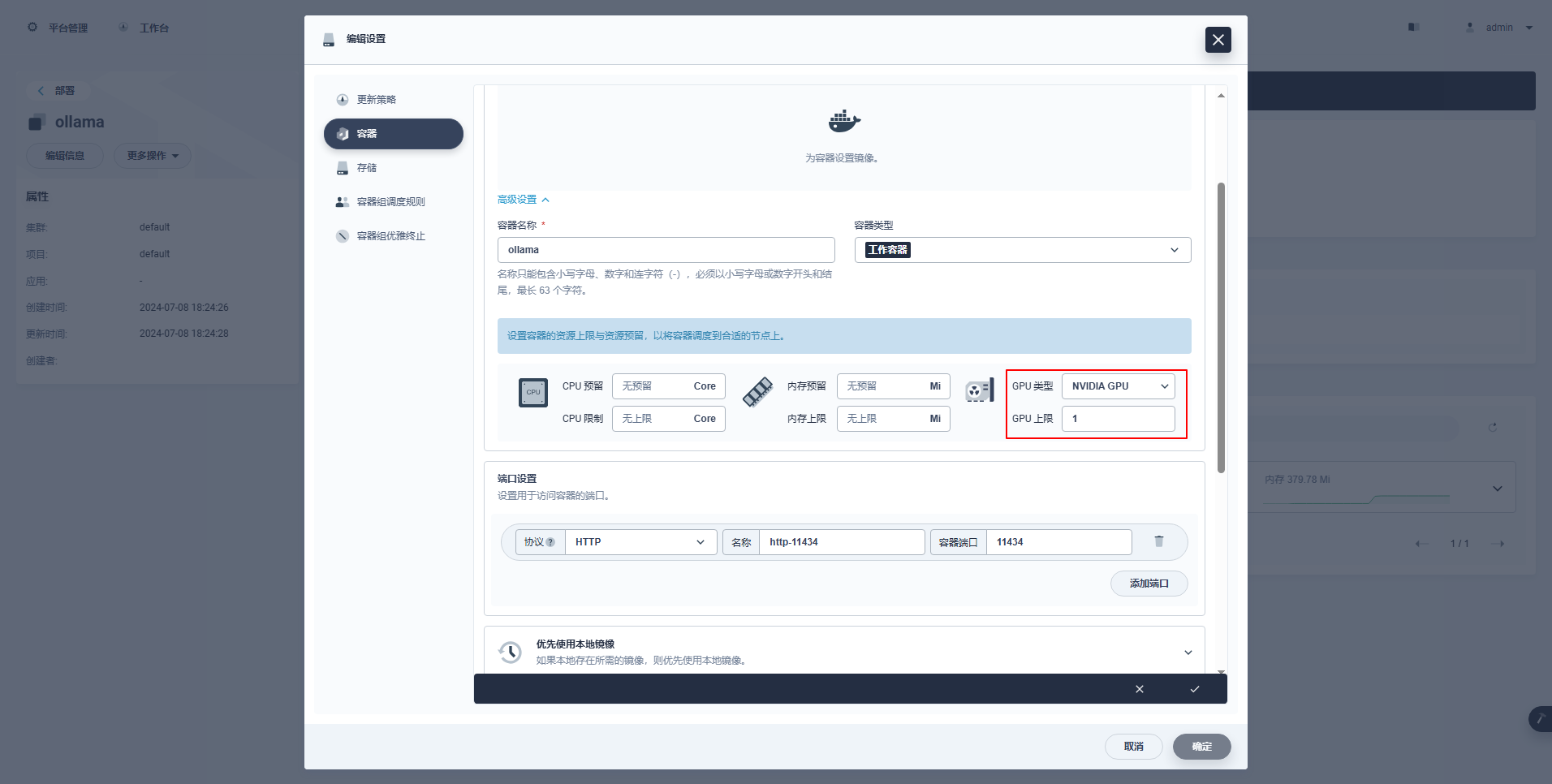
kubectl apply -f deploy-ollama.yamlपरिणामेभ्यः भवन्तः द्रष्टुं शक्नुवन्ति यत् ksp-gpu-worker-1 नोड् (नोड् ग्राफिक्स् कार्ड् मॉडल् टेस्ला एम४० २४जीबी)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"समयस्य रक्षणार्थं एतत् उदाहरणं परीक्षणप्रतिरूपरूपेण Alibaba इत्यस्य मुक्तस्रोतस्य qwen2 1.5b लघु-आकारस्य मॉडलस्य उपयोगं करोति ।
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bसम्यक् निष्पादनस्य आउटपुट् परिणामः निम्नलिखितरूपेण भवति ।
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successअस्ति ksp-gpu-कार्यकर्ता-1 नोड् निम्नलिखितम् view आदेशं निष्पादयति
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
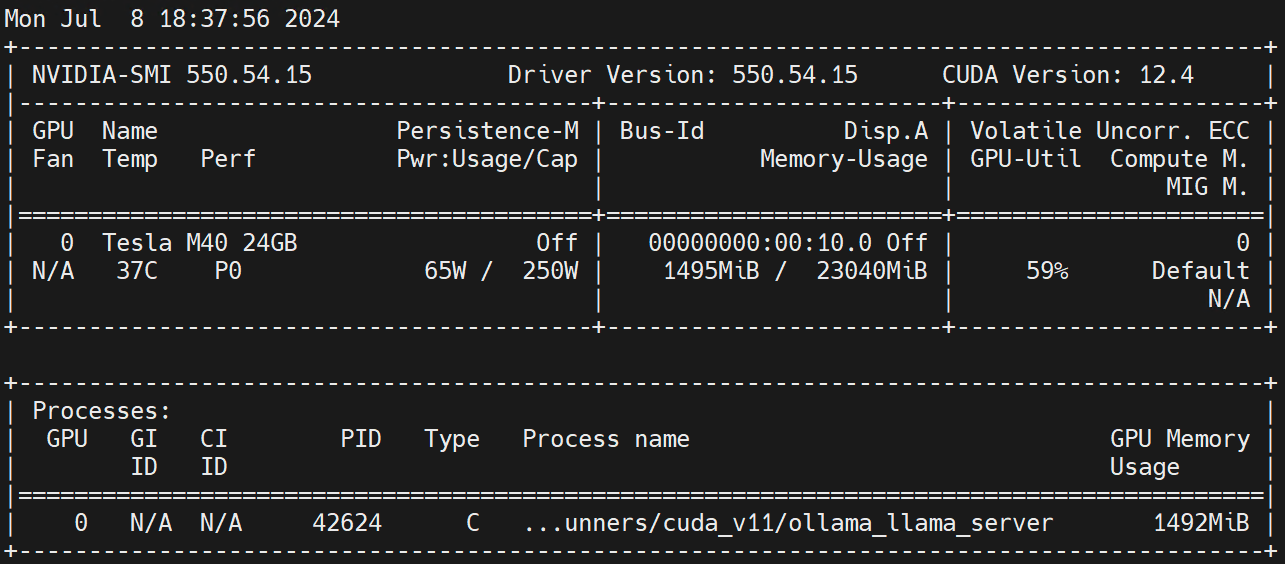
nvidia.com/gpu 1 1Worker नोड् इत्यत्र निष्पादयन्तु nvidia-smi -l GPU उपयोगं अवलोकयन्तु।
अस्वीकरणम् : १.
अयं लेखः Blog One Post Multi-Publishing Platform इत्यनेन प्रकाशितः अस्ति OpenWrite इति मोचनम्!

सः ३० वर्षाणाम् अधिकं कालात् प्रौद्योगिक्याः शोधकार्यं कर्तुं समर्पितः अस्ति, तथा च जावा, लिनक्स, जावास्क्रिप्ट्, php, css इत्यादिषु विविधभाषासु प्रवीणः अस्ति, मुक्तस्रोतक्षेत्रे सः बहु योगदानं कृतवान् अस्ति विकासक दस्तावेजीकरणस्थानकं भविष्ये सन्दर्भार्थं प्रौद्योगिकीविकासे केचन विषयाः साझां कर्तुं सर्वे तत् पश्यन्तु

