2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Author: Operatio et Sustentatio Youshu Star Magister Cum celeri progressu intelligentiae artificialis, machinae doctrinae, AI magnae technologiae exemplar, nostra postulatio computandi facultates etiam resurget. Praesertim pro magnis AI exemplaribus quae necessaria sunt ut notitias magnarum et algorithmorum multiplices processus, usus facultatum GPU criticus fit. Ad fabrum operandi et sustentationem, necessaria scientia facta est ad dominandum quomodo facultates GPU in Kubernetes ligaturas regendi et conformandi, et quomodo ad applicationes quae his opibus nituntur efficaciter explicandae.
Hodie perducam te ad altiorem cognitionem acquirendi quomodo potens oeconomia et instrumenta Kubernetensium utantur ut GPU subsidiorum administratione ac applicatione instruere in suggestu KubeSphere possit. Hic sunt tres nuclei themata hunc articulum exploraturus;
Hoc articulum legendo, scientiam et artes GPU opes in Kubernetes administrandi acquires, adiuvando plenam opibus usum GPU in ambitu nubilo-nativa fovebis et celeri progressu AI applicationum promovebis.
KubeSphere Best Practice "2024" Ambitus ambitus experimentalis configuratione ferramentorum ac programmatum indicio seriei documentorum haec sunt:
Configuratio servilis actualis (architectura 1:1 effigies parvae ambitus productionis, conformatio paulum diversa)
| CPU nomen | IP | cpu | Memoria | ratio orbis | notitia orbis | usus |
|---|---|---|---|---|---|---|
| ksp-subcriptio | 192.168.9.90 | 4 | 8 | 40 | 200 | Portus Speculum CELLA |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp cooperator-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-worker/CI * |
| ksp adiutor-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s operarius |
| ksp adiutor-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s operarius |
| ksp-repono-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-storage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu operarius-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-workers(GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-adjutor-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s cooperator (GPU NVIDIA Tesla P100 16G) |
| ksp-porta-1 | 192.168.9.103 | 2 | 4 | 40 | Auto-exstructum applicationis officium procuratorem portae/VIP: 192.168.9.100 | |
| ksp-porta-2 | 192.168.9.104 | 2 | 4 | 40 | Auto-exstructum applicationis officium procuratorem portae/VIP: 192.168.9.100 | |
| ksp-medium | 192.168.9.105 | 4 | 8 | 40 | 100 | Servitium nodum extra botrum k8s (Gitlab, etc.) instruxit. |
| total | 15 | 56 | 152 | 600 | 2000 |
Ipsum proelium environment involvit software version informationes
Ob subsidia et angustias sumptus, summum finem hospitii corporalis non habeo, et chartam graphics ad experimentum. Duae tantum machinis virtualis instructae cum GPU graphicis chartis viscus-gradu adici possunt nodi operarii botri.
Etsi hae chartae graphicae non tantum pollent quam exempla summus finis, satis sunt ad opera doctissima et progressus scheduling strategies.
Placere referuntur ad Kubernetes botri nodi openEuler 22.03 LTS SP3 systema initialization guideperfice systema operantem initialization configurationem.
Configurationis initialis dux non involvit operantem systema upgrade opera.
Deinceps KubeKey utimur, ut nodum GPU recentem additae ad botrum Kubernetes existentium. Refer ad documenta publica.
De nodo control-1, switch ad kubekey presul ad instruere et modificare fasciculum originalis glomerationis conformationis ksp-v341-v1288.yamlre ipsa temperare velim.
Praecipua modificatio punctorum:
Modum exemplum tale est:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Priusquam nodos addas, confirmemus informationes nodi botri currentis.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Deinceps mandatum sequens exequimur et lima configuratione mutata utimur ut nodum artificem novum botro adiciamus.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlPostquam supra mandatum supplicium est, KubeKey primum inhibet num clientelas et alias figurationes Kubernetes cum requisitis explicandis. Peracta perscriptio, rogaberis ad institutionem confirmandam.intraresic and press Penetro pergere instruere.
Tempus circiter 5 minutes ad instruere perficiendam accipit.
Postquam instruere peracta est, videre debes output simile sequenti in termino tuo.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullynavigatrum aperimus et accessum IP inscriptionis et portus nodi-I Imperium-I 30880, aperi in pagina login administratione KubeSphere consolandi.
Ingredere in administratione botri interfaciei, preme "Node" tabulam sinistra, et preme "Cluster Node" ut consideres detailed informationes de nodis nodi Kubernetarum botri.
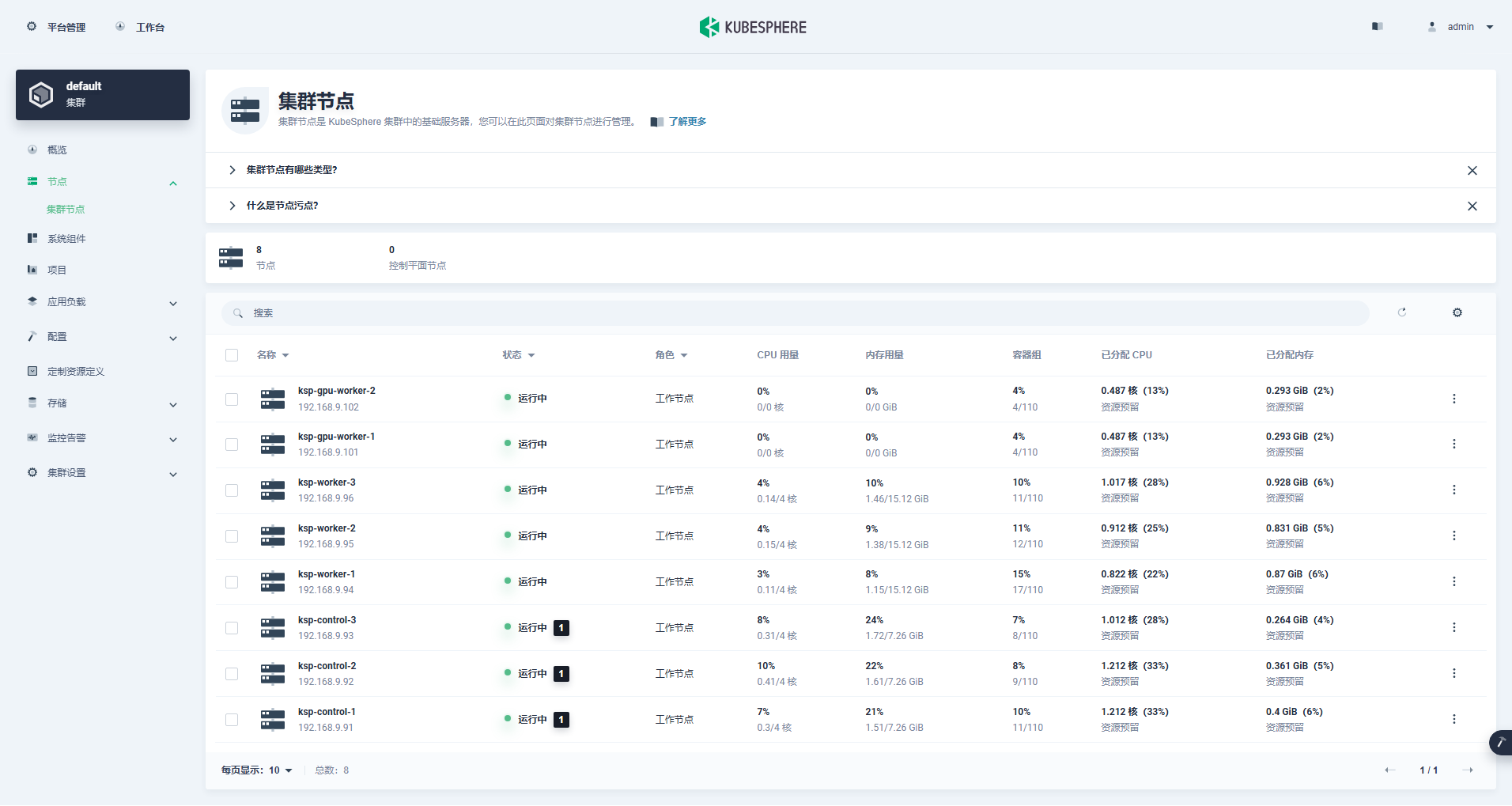
Currite mandatum kubectl in nodo 1 Control-ad nodi informationem botri Kubernetarum obtinendam.
kubectl get nodes -o wideUt videre potes in output, botrus hodiernus Kubernetes habet 8 nodos, et nomen, status, partes, tempus superstes, numerus versionis Kubernetes, typus internus IP, ratio operandi genus, versio nuclei et continens runtime cuiusque nodi singillatim exponuntur. et alia notitia.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Hoc loco omnia opera Kubekey utendi addendi 2 nodi operarii ad Kubernetes botrum exsistentium 3 nodis magistri et 3 nodi operarii addendi.
Deinde instituimus NVIDIA GPU Operator ab NVIDIA publice productos ad intellegendum K8s Pod scheduling ut facultates GPU utatur.
NVIDIA GPU Operator institutionem autocineticam graphicae agitatoris sustinet, sed tantum CentOS 7, 8 et Ubuntu 20.04, 22.04 aliaeque versiones openEuler non sustinent, ideo necesse est ut manually coegi graphice instituere.
Placere referuntur ad KubeSphere praxim optimam: openEuler 22.03 LTS SP3 installs NVIDIA graphics card exactoris, perfice institutionem graphicae electronicae card.
Node Feature Inventionis (NFD) pluma cohibet detegit.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Executio ex mandato supradicto true, illustra NFD Iam in botro currit. Si NFD iam in botro currit, disponere NFD debet debilitari cum operator inauguratus est.
illustrare; Botri K8s usura KubeSphere explicaverunt nec institutionem et NFD configurant per defaltam.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateConfiguratione defalta lima utere, automatariam institutionem graphicarum cardrum rectorum inactivare, et GPU operatorem instituere.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseNota: Cum imago inaugurata relative magna sit, speculatio fieri potest per initialem institutionem. Potes considerare institutionem offline ad solvendum hoc genus problematis.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseProventus output rectae exsecutionis talis est:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NonePost mandatum exsecutionis operantis GPU installandi, patienter sustine quaeso donec imagines omnes feliciter trahantur et siliquae omnes in statu currendo sunt.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110illustrare; Focus
nvidia.com/gpu:Valor agri.
Quod inposuit feliciter creatum est hoc modo:
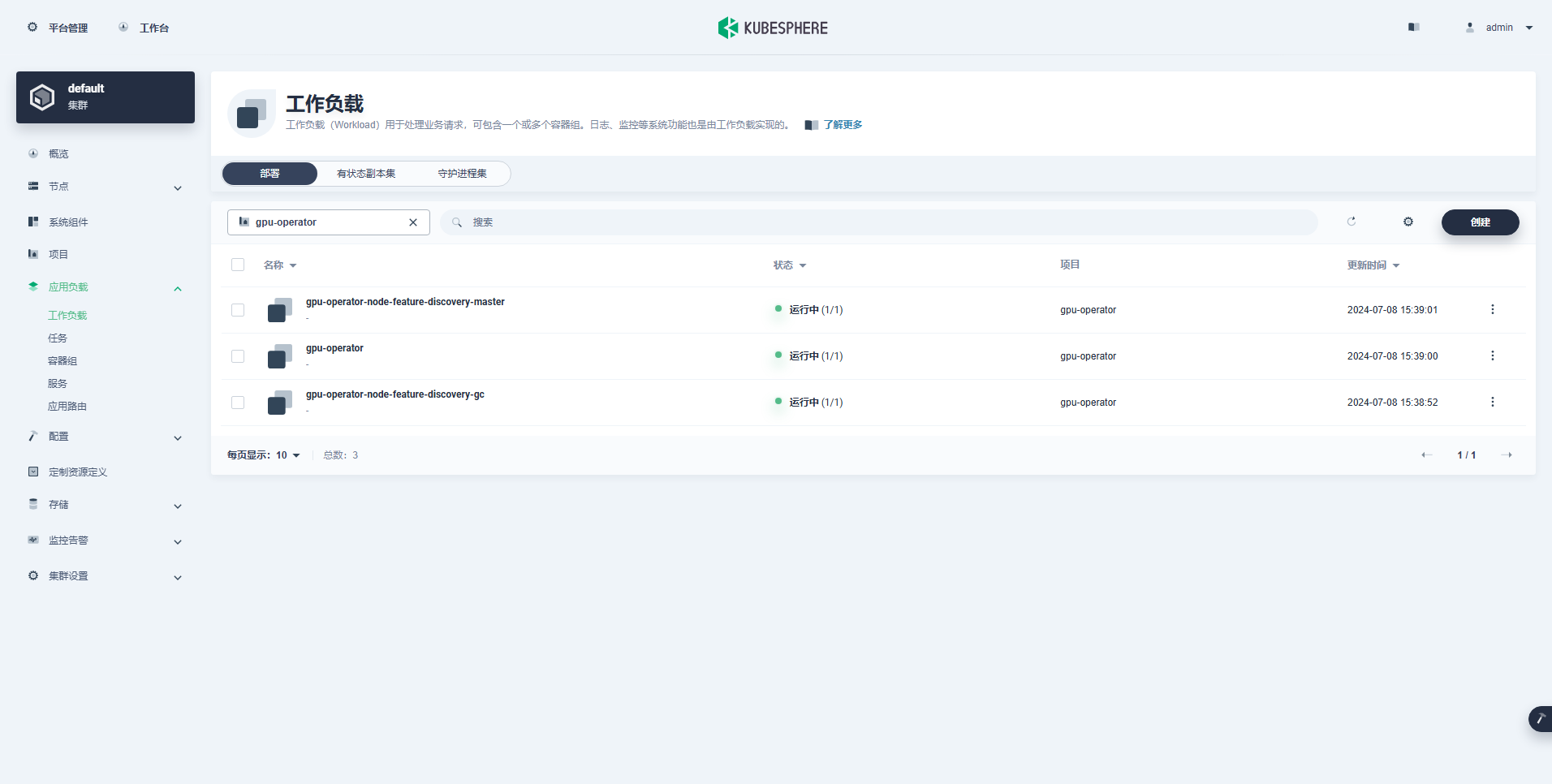
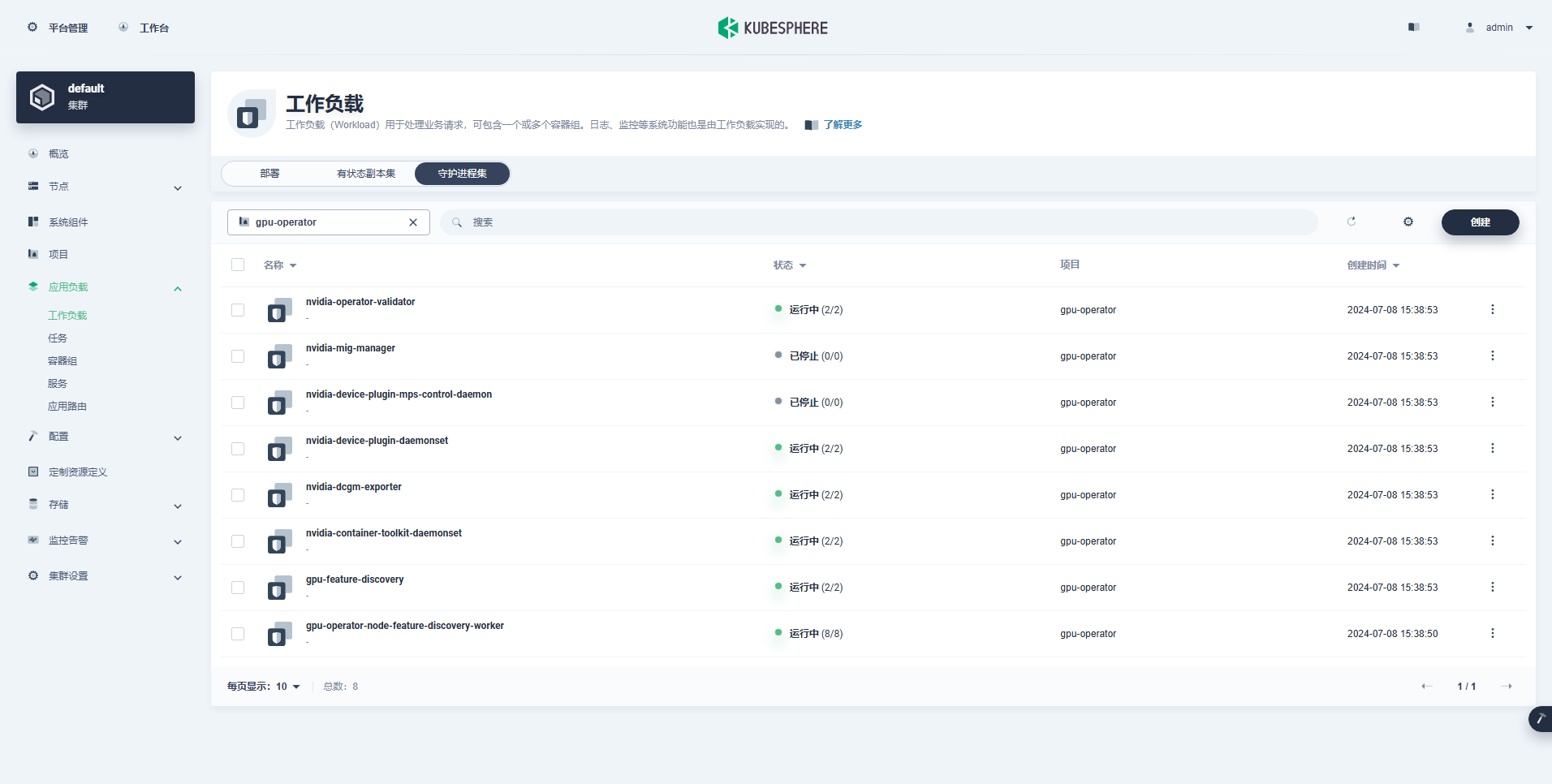
Postquam GPU Operator recte inauguratus est, CUDA basi imagine utere ad probandum utrum K8s recte creare possit Pods quae opibus GPU utuntur.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlEx eventibus, videre potes vasculum in nodo 2 ksp-gpu laborantis creatum (Nodus graphics chartae exemplar Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Proventus output rectae exsecutionis talis est:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlExemplum simplex deducendi CUDA ad duos vectores addendo.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlPodex feliciter creatur et post satus current. vectorAdd mandatum et exitum.
$ kubectl logs pod/cuda-vectoraddProventus output rectae exsecutionis talis est:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlPer probationem superius verificationem probatur Pod opes GPU utentes in botro K8s creari posse. Deinde KubeSphere utimur ut magnum exemplar instrumenti administrationis creare Ollama in K8s botrum ex actuali usu requisitorum.
Hoc exemplum simplex probatio est et repositio seligitur hostPath Modus, quaeso, eam repone cum classi repositionis vel aliis generibus repositionis persistentis in usu actuali.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortInstructiones speciales: KubeSphere procuratio consolandi figuram instruere et alia subsidia graphice instruere subsidia adiuvat. Exempla conformatio haec sunt.
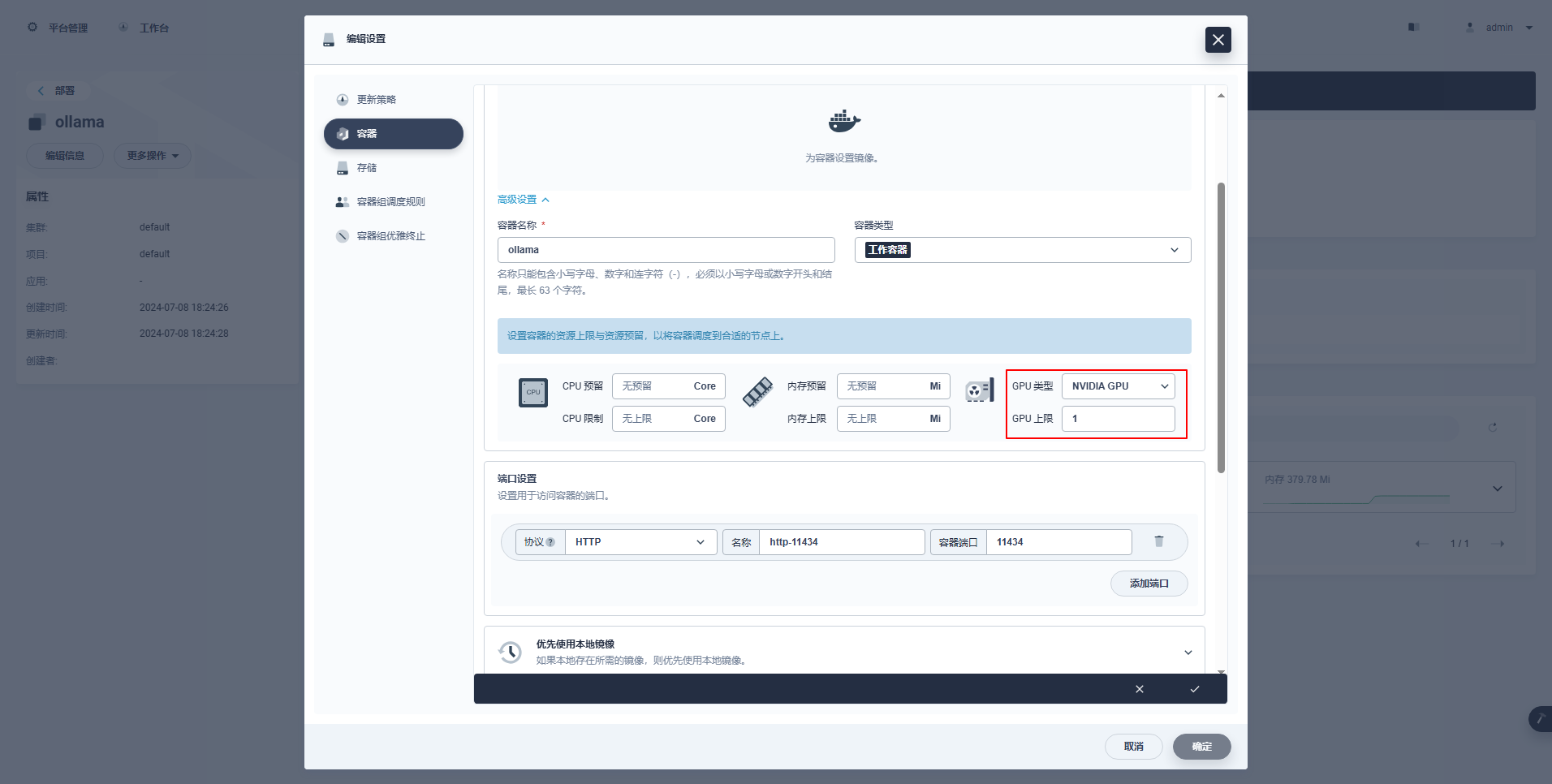
kubectl apply -f deploy-ollama.yamlEx eventibus, videre potes vasculum creatum in nodi ksp-gpu operario-1 (Nodus graphics card exemplum Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Ut tempus conserves, hoc exemplum Alibaba fonte aperto utitur qwen2 1.5b exemplum parvae quantitatis sicut exemplar probativae.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bProventus output rectae exsecutionis talis est:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successexist ksp-gpu operarius-1 Nodus sequens mandatum exequitur
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Facite in opifice nodi nvidia-smi -l Observa GPU consuetudinem.
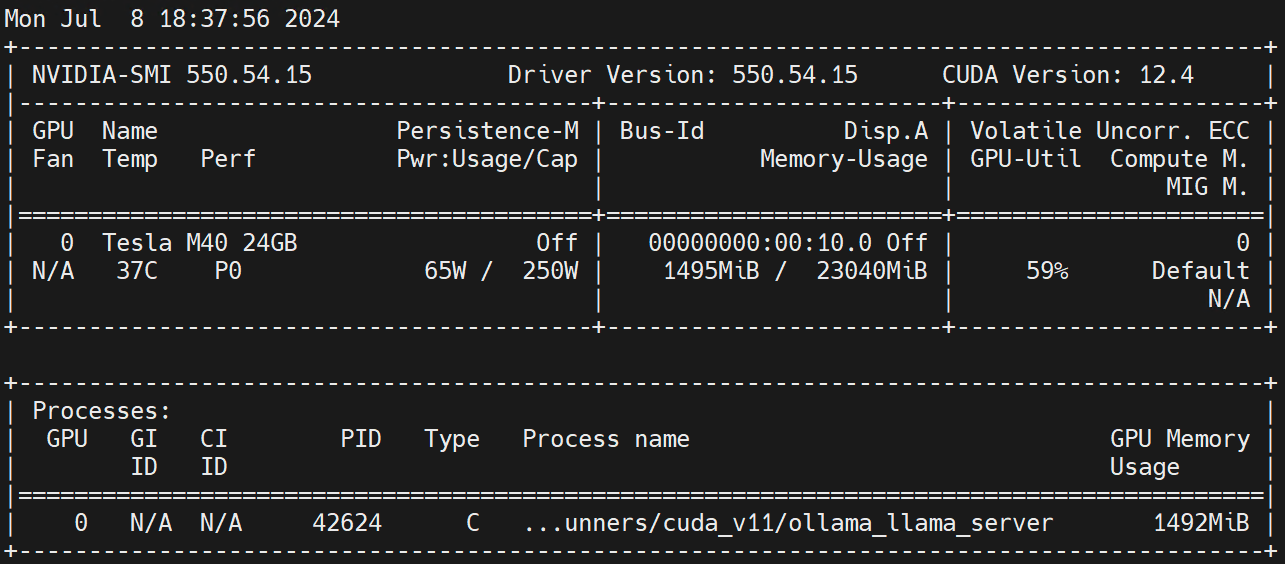
Disclaimer:
Hic articulus divulgatus est a Blog One Post Multi-Publishing Platform OpenWrite dimittis!

technologiae technologiae plus quam 30 annos operam dedit et in variis linguis proficit ut java, linux, javascript, php, css, etc. Multas contributiones in aperto fonte campo fecit elit documentorum statione ad communicandas quaestiones in technologia progressus ad futuram referentiam

