
моя контактная информация
Почтамезофия@protonmail.com
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Автор: Эксплуатация и обслуживание Youshu Star Master С быстрым развитием искусственного интеллекта, машинного обучения и технологий больших моделей искусственного интеллекта наша потребность в вычислительных ресурсах также растет. Использование ресурсов графического процессора становится критически важным, особенно для крупных моделей искусственного интеллекта, которым необходимо обрабатывать крупномасштабные данные и сложные алгоритмы. Для инженеров по эксплуатации и техническому обслуживанию стало незаменимым навыком управлять ресурсами графического процессора и настраивать их в кластерах Kubernetes, а также эффективно развертывать приложения, использующие эти ресурсы.
Сегодня я познакомлю вас с более глубоким пониманием того, как использовать мощную экосистему и инструменты Kubernetes для управления ресурсами графического процессора и развертывания приложений на платформе KubeSphere. Вот три основные темы, которые будут рассмотрены в этой статье:
Прочитав эту статью, вы получите знания и навыки управления ресурсами графического процессора в Kubernetes, которые помогут вам в полной мере использовать ресурсы графического процессора в облачной среде и способствовать быстрой разработке приложений искусственного интеллекта.
Лучшие практики KubeSphere «2024» Конфигурация аппаратного обеспечения экспериментальной среды и информация о программном обеспечении из серии документов следующие:
Фактическая конфигурация сервера (копия архитектуры 1:1 мелкомасштабной производственной среды, конфигурация немного отличается)
| Имя процессора | ИС | Процессор | Память | системный диск | диск с данными | использовать |
|---|---|---|---|---|---|---|
| ksp-реестр | 192.168.9.90 | 4 | 8 | 40 | 200 | Зеркальный склад в порту |
| ксп-контроль-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-управление-плоскостью |
| ksp-контроль-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-управление-плоскостью |
| ксп-контроль-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-управление-плоскостью |
| ksp-работник-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-worker/CI |
| ksp-работник-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-работник |
| ksp-работник-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-работник |
| ksp-хранилище-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-хранилище-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-хранилище-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(ГП NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(ГП NVIDIA Tesla P100 16G) |
| ksp-шлюз-1 | 192.168.9.103 | 2 | 4 | 40 | Самостоятельно созданный прокси-шлюз/VIP службы приложений: 192.168.9.100 | |
| ksp-шлюз-2 | 192.168.9.104 | 2 | 4 | 40 | Самостоятельно созданный прокси-шлюз/VIP службы приложений: 192.168.9.100 | |
| ксп-мид | 192.168.9.105 | 4 | 8 | 40 | 100 | Сервисные узлы, развернутые за пределами кластера k8s (Gitlab и т. д.) |
| общий | 15 | 56 | 152 | 600 | 2000 |
Реальная боевая среда включает информацию о версии программного обеспечения.
Из-за ограниченности ресурсов и стоимости у меня нет высококлассного физического хоста и видеокарты, с которой можно было бы экспериментировать. В качестве рабочих узлов кластера можно добавить только две виртуальные машины, оснащенные видеокартами начального уровня с графическим процессором.
Хотя эти видеокарты не такие мощные, как модели высокого класса, их достаточно для большинства задач обучения и разработки. Учитывая ограниченные ресурсы, такая конфигурация дает мне ценные практические возможности для глубокого изучения ресурсов графического процессора в управлении кластерами Kubernetes. стратегии планирования.
Пожалуйста, обратитесь к Руководство по инициализации узла кластера Kubernetes openEuler 22.03 LTS SP3, завершите настройку инициализации операционной системы.
Руководство по первоначальной настройке не включает задачи обновления операционной системы. При инициализации системы в среде с доступом к Интернету необходимо обновить операционную систему, а затем перезапустить узел.
Далее мы используем KubeKey, чтобы добавить новый добавленный узел GPU в существующий кластер Kubernetes. Весь процесс относительно прост и требует всего двух шагов.
На узле Control-1 переключитесь в каталог kubekey для развертывания и измените исходный файл конфигурации кластера. Имя, которое мы использовали в реальном бою, — ksp-v341-v1288.yaml, пожалуйста, измените его в соответствии с реальной ситуацией.
Основные моменты модификации:
Модифицированный пример выглядит следующим образом:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Прежде чем добавлять узлы, давайте подтвердим информацию об узлах текущего кластера.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Затем мы выполняем следующую команду и используем измененный файл конфигурации, чтобы добавить новый рабочий узел в кластер.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlПосле выполнения вышеуказанной команды KubeKey сначала проверяет, соответствуют ли зависимости и другие конфигурации для развертывания Kubernetes требованиям. После прохождения проверки вам будет предложено подтвердить установку.входитьда и нажмите ENTER, чтобы продолжить развертывание.
Завершение развертывания занимает около 5 минут. Конкретное время зависит от скорости сети, конфигурации машины и количества добавленных узлов.
После завершения развертывания вы должны увидеть на своем терминале вывод, аналогичный следующему.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyОткрываем браузер и получаем доступ к IP-адресу и порту узла Control-1. 30880, войдите на страницу входа в консоль управления KubeSphere.
Войдите в интерфейс управления кластером, щелкните меню «Узел» слева и нажмите «Узел кластера», чтобы просмотреть подробную информацию о доступных узлах кластера Kubernetes.
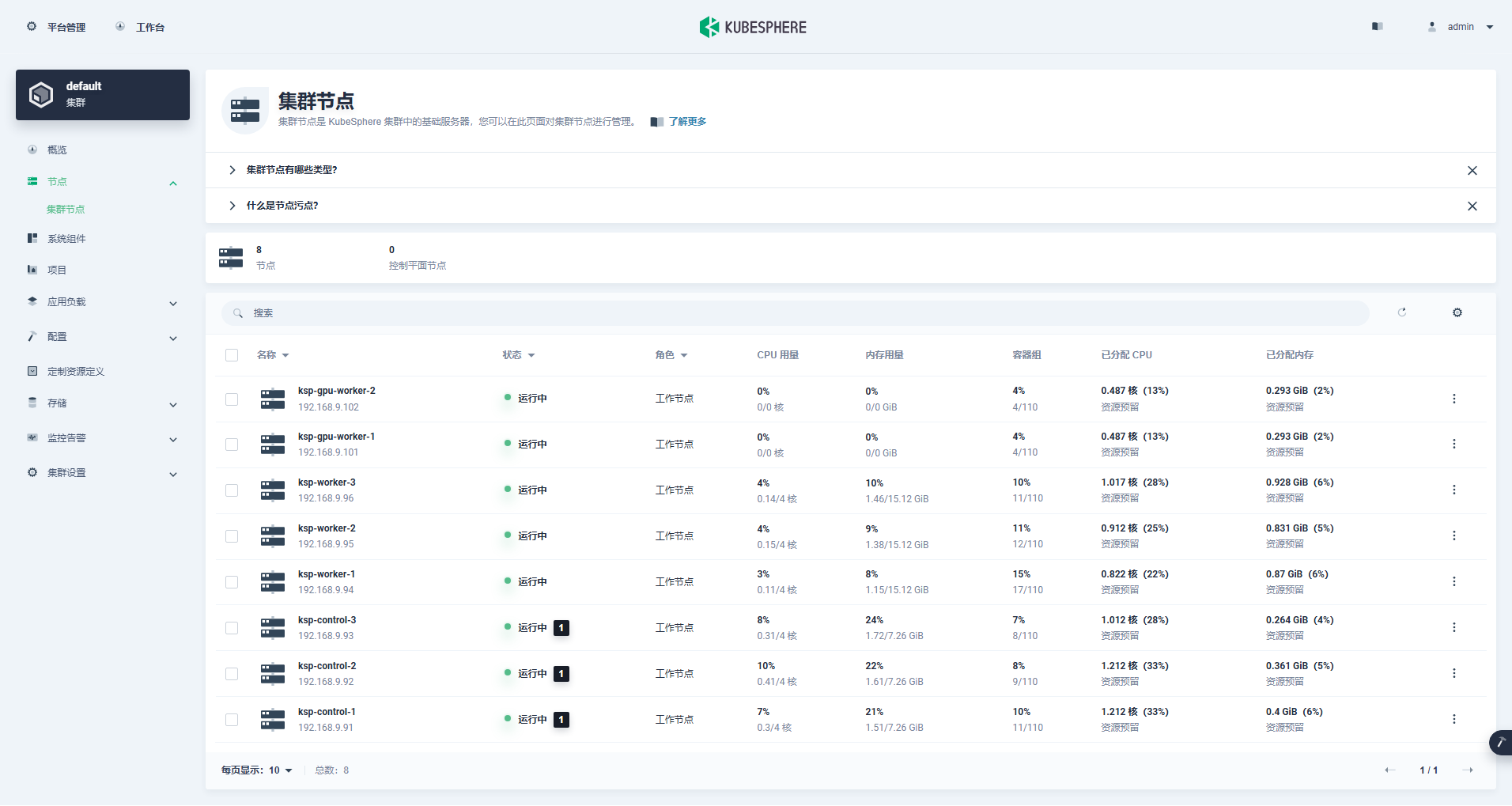
Запустите команду kubectl на узле Control-1, чтобы получить информацию об узле кластера Kubernetes.
kubectl get nodes -o wideКак вы можете видеть в выводе, текущий кластер Kubernetes имеет 8 узлов, и имя, статус, роль, время существования, номер версии Kubernetes, внутренний IP-адрес, тип операционной системы, версия ядра и время выполнения контейнера каждого узла отображаются подробно. и другая информация.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13На данный момент мы выполнили все задачи по использованию Kubekey для добавления 2 рабочих нод в существующий кластер Kubernetes, состоящий из 3 главных нод и 3 рабочих нод.
Затем мы устанавливаем оператор NVIDIA GPU, официально выпущенный NVIDIA, чтобы реализовать модуль планирования K8 для использования ресурсов графического процессора.
Оператор NVIDIA GPU поддерживает автоматическую установку графического драйвера, но только CentOS 7, 8 и Ubuntu 20.04, 22.04 и другие версии не поддерживают openEuler, поэтому вам необходимо установить графический драйвер вручную.
Пожалуйста, обратитесь к Лучшая практика KubeSphere: openEuler 22.03 LTS SP3 устанавливает драйвер видеокарты NVIDIA, завершите установку драйвера видеокарты.
Обнаружение функций узла (NFD) обнаруживает проверки функций.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Результат выполнения приведенной выше команды: true, проиллюстрировать NFD Уже работает в кластере. Если NFD уже запущен в кластере, развертывание NFD необходимо отключить при установке оператора.
проиллюстрировать: Кластеры K8s, развернутые с помощью KubeSphere, по умолчанию не будут устанавливать и настраивать NFD.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateИспользуйте файл конфигурации по умолчанию, отключите автоматическую установку драйверов видеокарты и установите Оператор графического процессора.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseПримечание. Поскольку установленный образ относительно большой, во время первоначальной установки может возникнуть тайм-аут. Проверьте, успешно ли получен ваш образ! Для решения проблемы такого типа можно рассмотреть возможность использования автономной установки.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseВыходной результат правильного выполнения следующий:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneПосле выполнения команды установки оператора графического процессора терпеливо подождите, пока все образы не будут успешно извлечены и все модули не перейдут в состояние «Работа».
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110проиллюстрировать: Фокус
nvidia.com/gpu:Значение поля.
Успешно созданная рабочая нагрузка выглядит следующим образом:
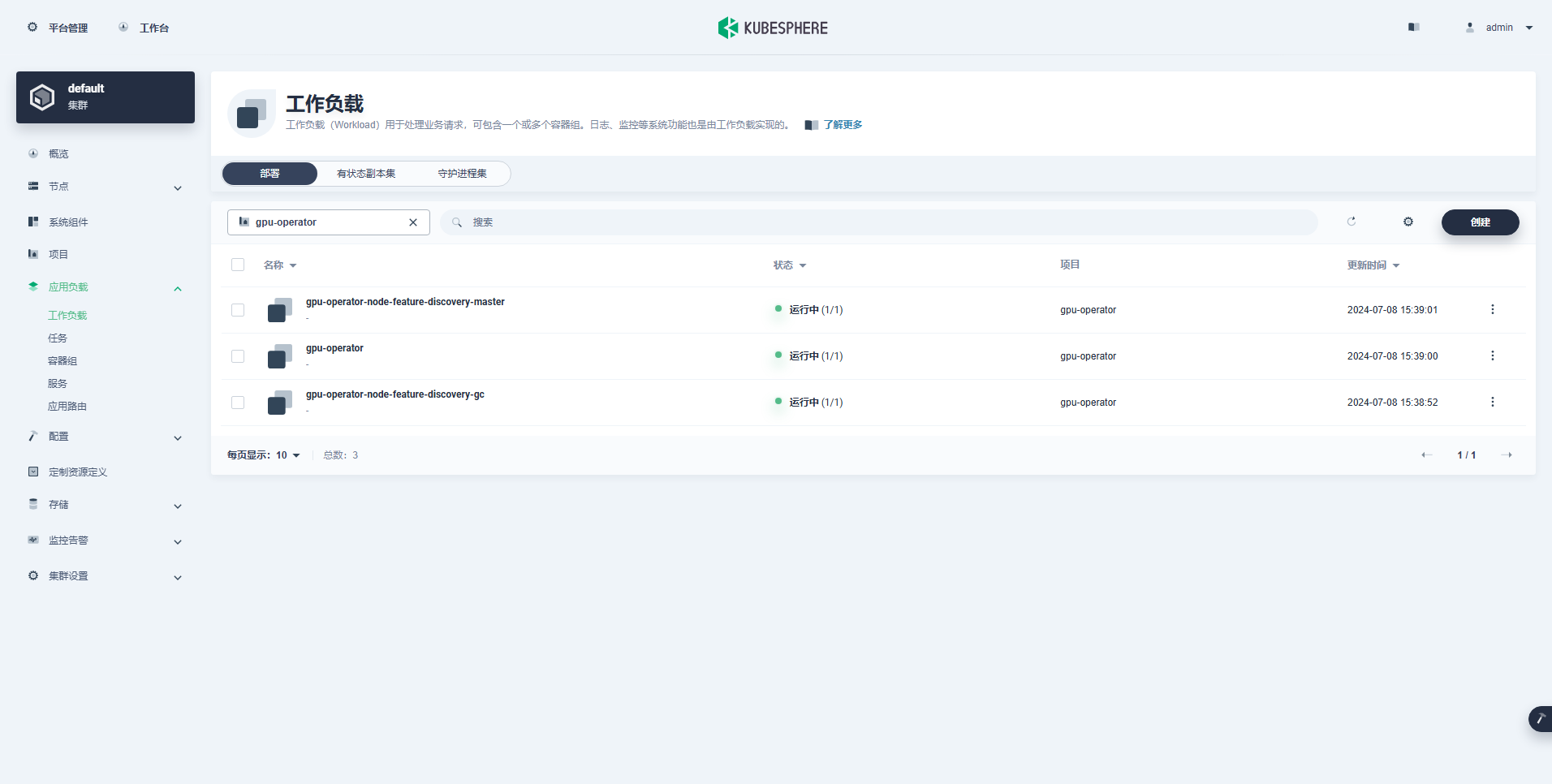
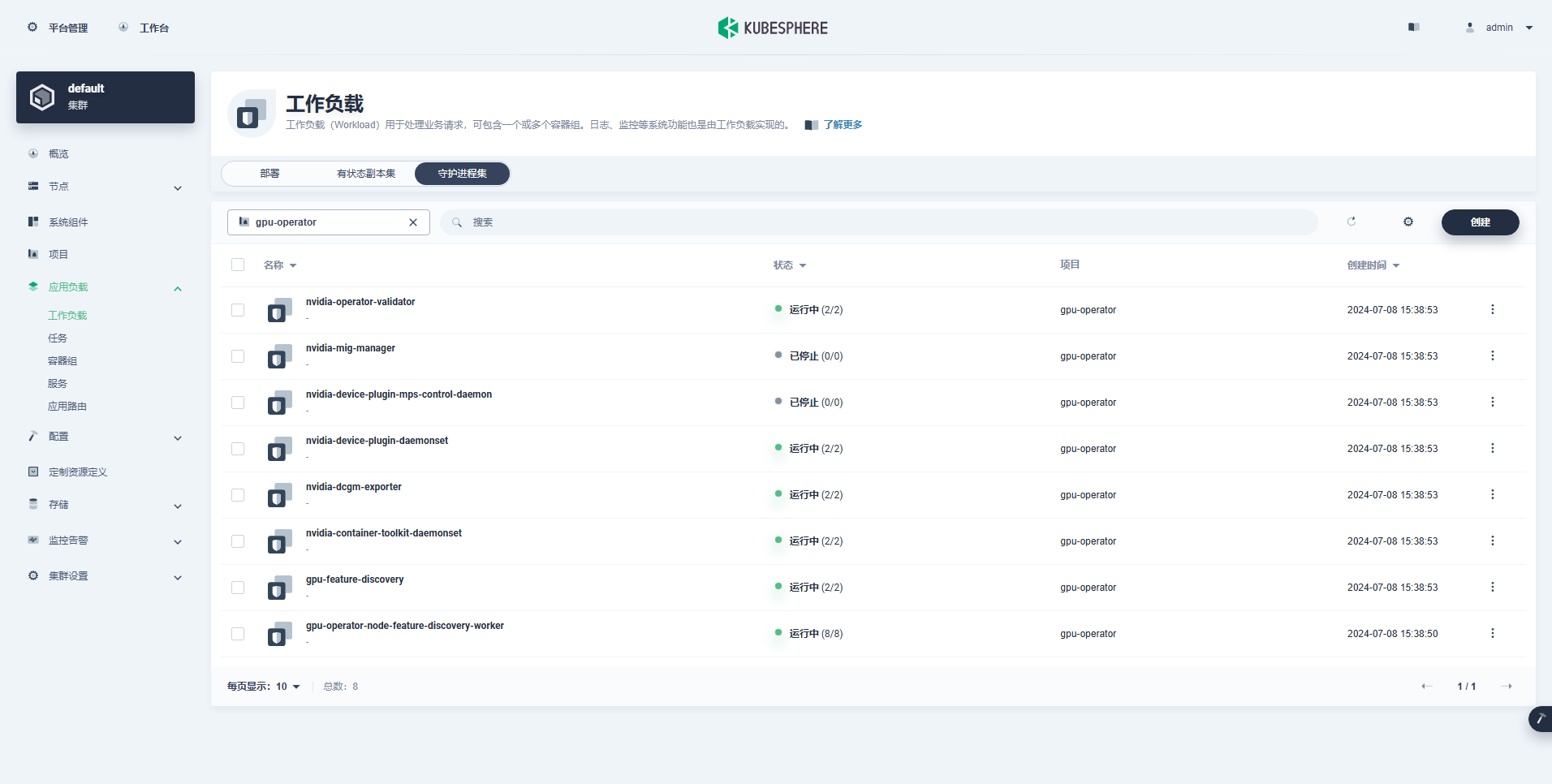
После правильной установки оператора графического процессора используйте базовый образ CUDA, чтобы проверить, может ли K8 правильно создавать модули, использующие ресурсы графического процессора.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlПо результатам видно, что под создан на узле ksp-gpu-worker-2 (Модель узла видеокарты Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Выходной результат правильного выполнения следующий:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlРеализуйте простой пример CUDA для добавления двух векторов.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlПод успешно создан и будет запущен после запуска. vectorAdd команду и выход.
$ kubectl logs pod/cuda-vectoraddВыходной результат правильного выполнения следующий:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlС помощью приведенного выше проверочного теста доказано, что ресурсы Pod с использованием графического процессора могут быть созданы в кластере K8s. Затем мы используем KubeSphere для создания большого инструмента управления моделями Ollama в кластере K8s на основе фактических требований использования.
Этот пример представляет собой простой тест, и хранилище выбрано hostPath Mode, замените его на класс хранилища или другие типы постоянного хранилища, которые используются в реальности.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortСпециальные инструкции: Консоль управления KubeSphere поддерживает графическую настройку развертывания и других ресурсов для использования ресурсов графического процессора. Заинтересованные друзья могут изучить их самостоятельно.
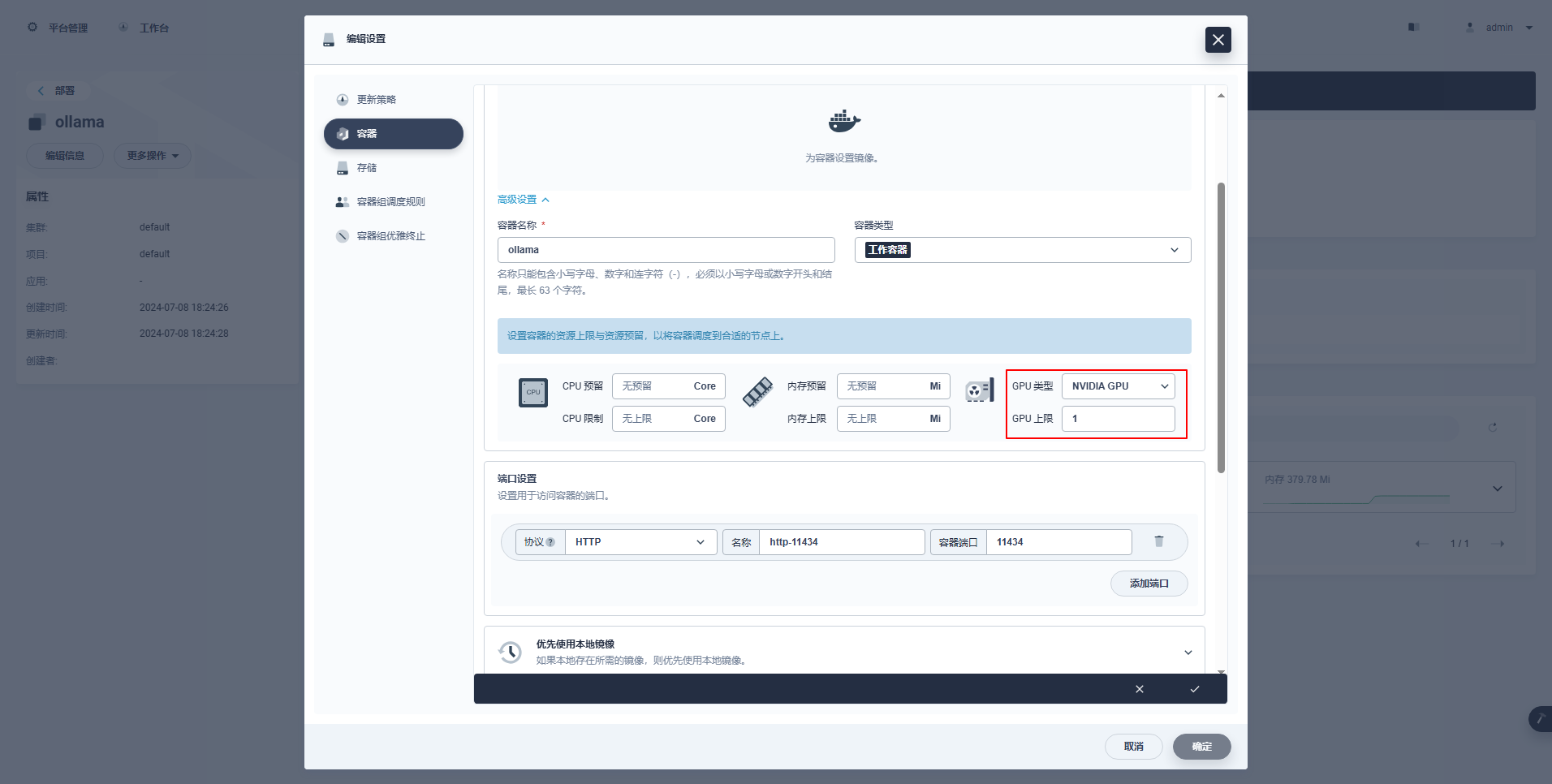
kubectl apply -f deploy-ollama.yamlПо результатам видно, что под создан на узле ksp-gpu-worker-1 (Модель узла видеокарты Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Чтобы сэкономить время, в этом примере в качестве тестовой модели используется малоразмерная модель qwen2 1.5b с открытым исходным кодом от Alibaba.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bВыходной результат правильного выполнения следующий:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successсуществовать ksp-gpu-worker-1 Узел выполняет следующую команду просмотра
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Выполнить на рабочем узле nvidia-smi -l Наблюдайте за использованием графического процессора.
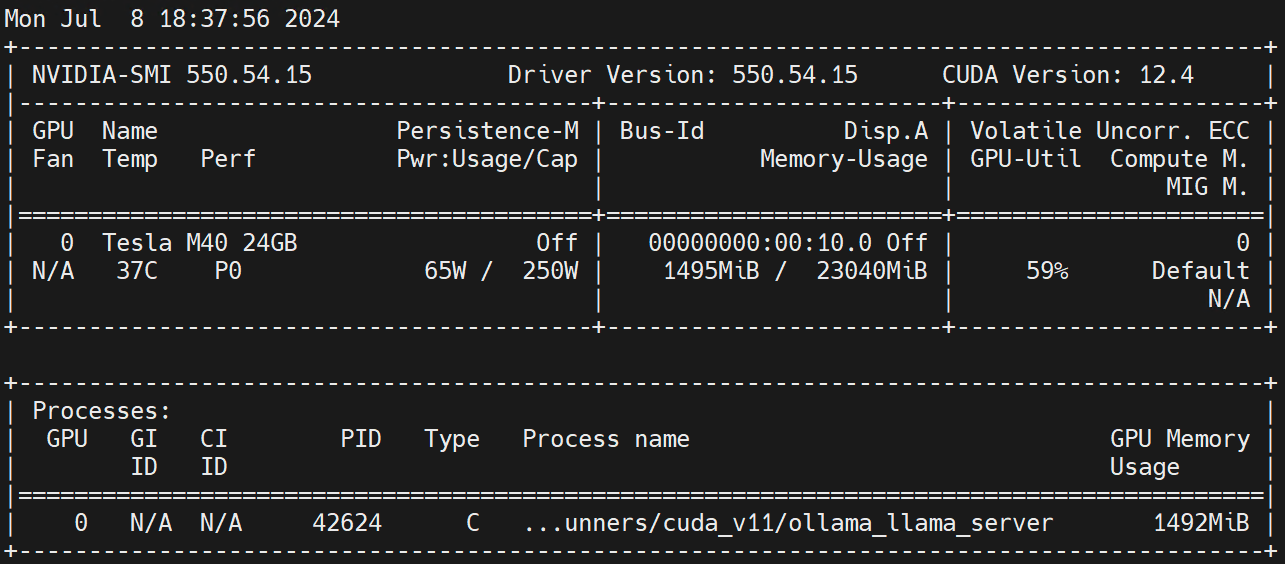
Отказ от ответственности:
Эта статья опубликована мультипубликационной платформой Blog One Post. ОткрытьЗаписать выпускать!

Он посвятил себя исследованию технологий более 30 лет и владеет различными языками, такими как Java, Linux, Javascript, php, css и т. д. Он внес большой вклад в область открытого исходного кода. Станция документации для разработчиков, где можно поделиться некоторыми проблемами в разработке технологий для дальнейшего использования. Все ознакомьтесь.

Почтамезофия@protonmail.com