2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Auteur : Exploitation et maintenance Youshu Star Master Avec le développement rapide de l'intelligence artificielle, de l'apprentissage automatique et de la technologie des grands modèles d'IA, notre demande en ressources informatiques augmente également. L’utilisation des ressources GPU devient critique, en particulier pour les grands modèles d’IA qui doivent traiter des données à grande échelle et des algorithmes complexes. Pour les ingénieurs d’exploitation et de maintenance, maîtriser la gestion et la configuration des ressources GPU sur les clusters Kubernetes et déployer efficacement des applications qui s’appuient sur ces ressources est devenu une compétence indispensable.
Aujourd'hui, je vais vous amener à acquérir une compréhension approfondie de la façon d'utiliser le puissant écosystème et les outils de Kubernetes pour réaliser la gestion des ressources GPU et le déploiement d'applications sur la plate-forme KubeSphere. Voici les trois thèmes principaux que cet article explorera :
En lisant cet article, vous acquerrez les connaissances et les compétences nécessaires pour gérer les ressources GPU sur Kubernetes, vous aidant ainsi à utiliser pleinement les ressources GPU dans un environnement cloud natif et à promouvoir le développement rapide d'applications d'IA.
Meilleures pratiques KubeSphere « 2024 » La configuration matérielle de l'environnement expérimental et les informations logicielles de la série de documents sont les suivantes :
Configuration réelle du serveur (architecture réplique 1:1 d'un environnement de production à petite échelle, la configuration est légèrement différente)
| Nom du processeur | Propriété intellectuelle | CPU | Mémoire | disque système | disque de données | utiliser |
|---|---|---|---|---|---|---|
| registre ksp | 192.168.9.90 | 4 | 8 | 40 | 200 | Entrepôt miroir du port |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | Plan de contrôle KubeSphere/k8s |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | Plan de contrôle KubeSphere/k8s |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | Plan de contrôle KubeSphere/k8s |
| ksp-travailleur-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | Travailleur k8s/CI |
| ksp-travailleur-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | travailleur k8s |
| ksp-travailleur-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | travailleur k8s |
| ksp-stockage-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | Recherche élastique/Ceph/Longhorn/NFS/ |
| ksp-stockage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | Recherche élastique//Ceph/Longhorn |
| ksp-stockage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | Recherche élastique//Ceph/Longhorn |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla P100 16G) |
| passerelle-ksp-1 | 192.168.9.103 | 2 | 4 | 40 | Passerelle proxy/VIP de service d'application auto-construite : 192.168.9.100 | |
| passerelle-ksp-2 | 192.168.9.104 | 2 | 4 | 40 | Passerelle proxy/VIP de service d'application auto-construite : 192.168.9.100 | |
| ksp-milieu | 192.168.9.105 | 4 | 8 | 40 | 100 | Nœuds de service déployés en dehors du cluster k8s (Gitlab, etc.) |
| total | 15 | 56 | 152 | 600 | 2000 |
L'environnement de combat réel implique des informations sur la version du logiciel
En raison de contraintes de ressources et de coûts, je n'ai pas d'hôte physique ni de carte graphique haut de gamme avec lesquels expérimenter. Seules deux machines virtuelles équipées de cartes graphiques GPU d'entrée de gamme peuvent être ajoutées en tant que nœuds de travail du cluster.
Bien que ces cartes graphiques ne soient pas aussi puissantes que les modèles haut de gamme, elles sont suffisantes pour la plupart des tâches d'apprentissage et de développement. Avec des ressources limitées, une telle configuration m'offre de précieuses opportunités pratiques pour explorer en profondeur les ressources GPU dans la gestion et les clusters Kubernetes. stratégies de planification.
Prière de se référer à Guide d'initialisation du système du nœud de cluster Kubernetes openEuler 22.03 LTS SP3, terminez la configuration d'initialisation du système d'exploitation.
Le guide de configuration initiale n'implique pas de tâches de mise à niveau du système d'exploitation. Lors de l'initialisation du système dans un environnement avec accès à Internet, vous devez mettre à niveau le système d'exploitation, puis redémarrer le nœud.
Ensuite, nous utilisons KubeKey pour ajouter le nœud GPU nouvellement ajouté au cluster Kubernetes existant. Reportez-vous à la documentation officielle. L'ensemble du processus est relativement simple et ne nécessite que deux étapes.
Sur le nœud Control-1, basculez vers le répertoire kubekey pour le déploiement et modifiez le fichier de configuration du cluster d'origine. Le nom que nous avons utilisé dans le combat réel est. ksp-v341-v1288.yaml, veuillez le modifier en fonction de la situation réelle.
Principaux points de modifications :
L'exemple modifié est le suivant :
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Avant d'ajouter des nœuds, confirmons les informations sur les nœuds du cluster actuel.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Ensuite, nous exécutons la commande suivante et utilisons le fichier de configuration modifié pour ajouter le nouveau nœud Worker au cluster.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlUne fois la commande ci-dessus exécutée, KubeKey vérifie d'abord si les dépendances et autres configurations pour le déploiement de Kubernetes répondent aux exigences. Après avoir réussi le contrôle, vous serez invité à confirmer l'installation.entrerOui et appuyez sur ENTRÉE pour poursuivre le déploiement.
Le déploiement prend environ 5 minutes. La durée spécifique dépend de la vitesse du réseau, de la configuration de la machine et du nombre de nœuds ajoutés.
Une fois le déploiement terminé, vous devriez voir une sortie similaire à celle suivante sur votre terminal.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyNous ouvrons le navigateur et accédons à l'adresse IP et au port du nœud Control-1 30880, connectez-vous à la page de connexion de la console de gestion KubeSphere.
Entrez dans l'interface de gestion du cluster, cliquez sur le menu « Nœud » à gauche, puis cliquez sur « Nœud de cluster » pour afficher des informations détaillées sur les nœuds disponibles du cluster Kubernetes.
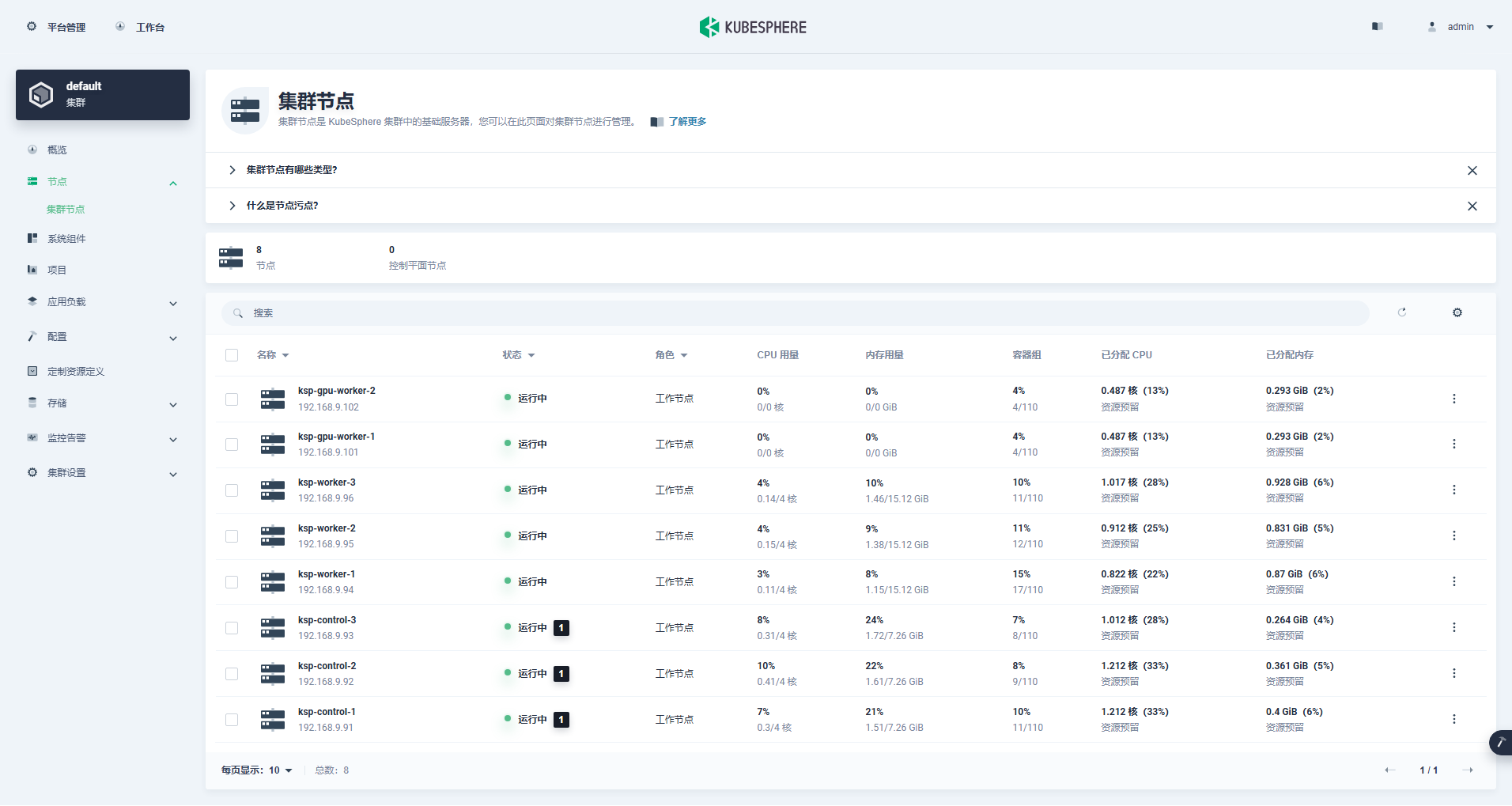
Exécutez la commande kubectl sur le nœud Control-1 pour obtenir les informations sur le nœud du cluster Kubernetes.
kubectl get nodes -o wideComme vous pouvez le voir dans le résultat, le cluster Kubernetes actuel comporte 8 nœuds et le nom, l'état, le rôle, la durée de survie, le numéro de version de Kubernetes, l'adresse IP interne, le type de système d'exploitation, la version du noyau et le temps d'exécution du conteneur de chaque nœud sont affichés en détail. .et d'autres informations.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13À ce stade, nous avons terminé toutes les tâches d'utilisation de Kubekey pour ajouter 2 nœuds Worker au cluster Kubernetes existant composé de 3 nœuds maîtres et de 3 nœuds Worker.
Ensuite, nous installons l'opérateur NVIDIA GPU officiellement produit par NVIDIA pour réaliser le pod de planification K8 afin d'utiliser les ressources GPU.
NVIDIA GPU Operator prend en charge l'installation automatique du pilote graphique, mais seuls CentOS 7, 8 et Ubuntu 20.04, 22.04 et les autres versions ne prennent pas en charge openEuler, vous devez donc installer le pilote graphique manuellement.
Prière de se référer à Bonne pratique de KubeSphere : openEuler 22.03 LTS SP3 installe le pilote de la carte graphique NVIDIA, terminez l'installation du pilote de la carte graphique.
Node Feature Discovery (NFD) détecte les vérifications de fonctionnalités.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Le résultat de l'exécution de la commande ci-dessus est true, illustrer NFD Déjà en cours d'exécution dans le cluster. Si NFD est déjà exécuté dans le cluster, le déploiement de NFD doit être désactivé lors de l'installation de l'opérateur.
illustrer: Les clusters K8 déployés à l'aide de KubeSphere n'installeront ni ne configureront NFD par défaut.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateUtilisez le fichier de configuration par défaut, désactivez l'installation automatique des pilotes de la carte graphique et installez l'opérateur GPU.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseRemarque : étant donné que l'image installée est relativement volumineuse, un délai d'attente peut se produire lors de l'installation initiale. Veuillez vérifier si votre image a été extraite avec succès ! Vous pouvez envisager d'utiliser l'installation hors ligne pour résoudre ce type de problème.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseLe résultat d’une exécution correcte est le suivant :
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneAprès avoir exécuté la commande pour installer l'opérateur GPU, veuillez attendre patiemment jusqu'à ce que toutes les images soient extraites avec succès et que tous les pods soient à l'état d'exécution.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110illustrer: Se concentrer
nvidia.com/gpu:La valeur du champ.
La charge de travail créée avec succès est la suivante :
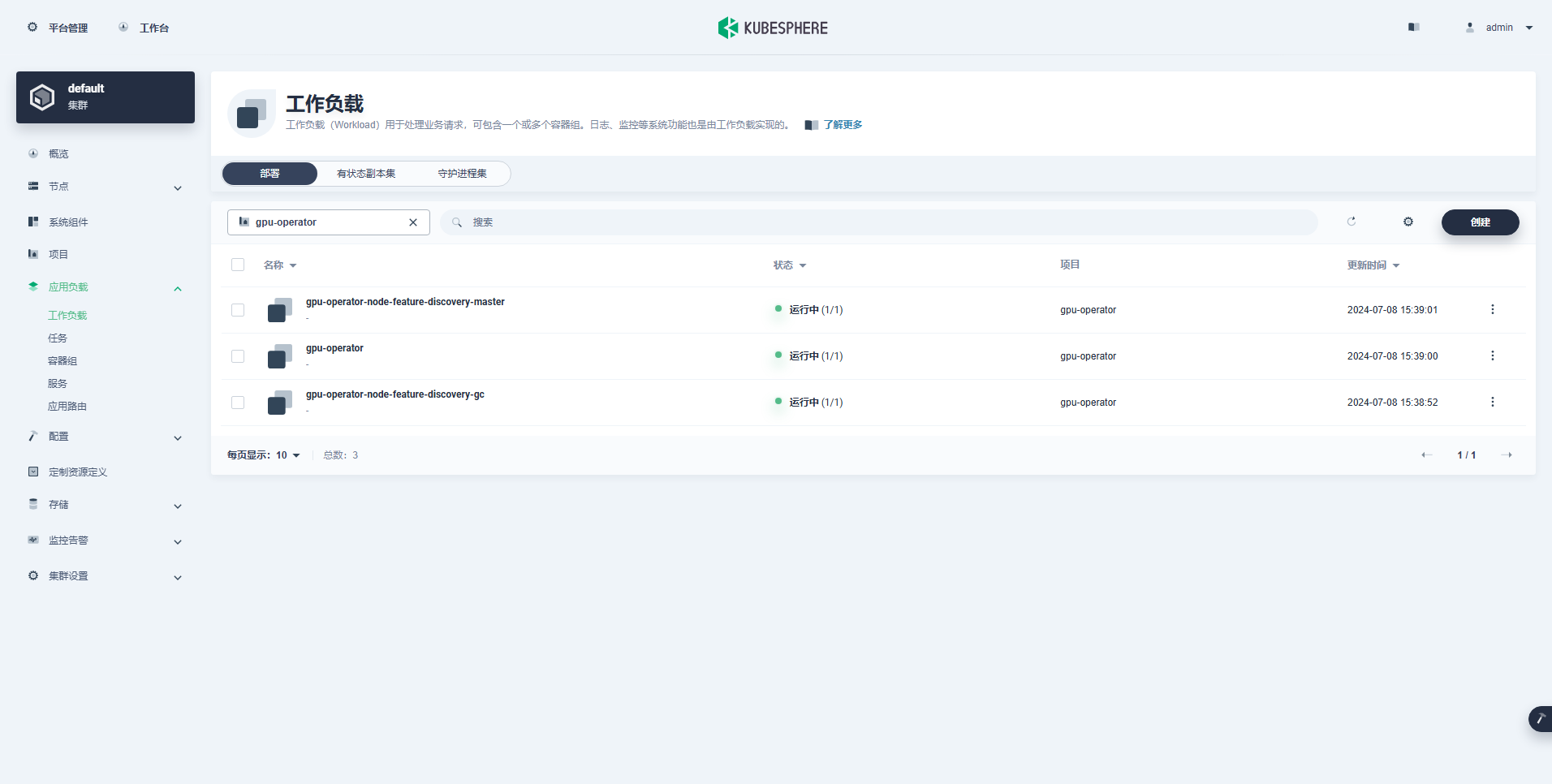
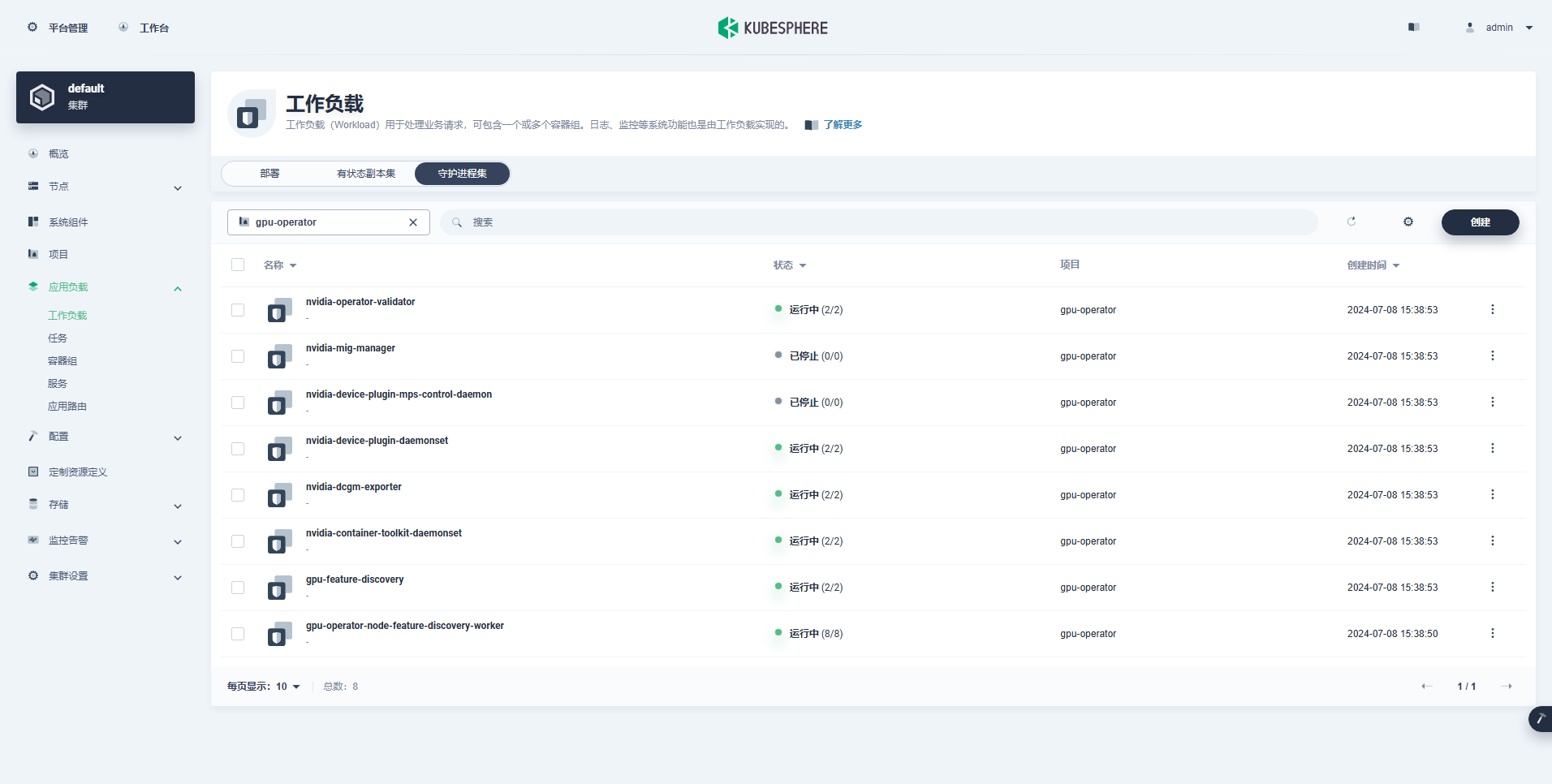
Une fois l'opérateur GPU correctement installé, utilisez l'image de base CUDA pour tester si les K8 peuvent créer correctement des pods qui utilisent des ressources GPU.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlÀ partir des résultats, vous pouvez voir que le pod a été créé sur le nœud ksp-gpu-worker-2 (Le modèle de carte graphique de nœud Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Le résultat d’une exécution correcte est le suivant :
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlImplémentez un exemple CUDA simple pour ajouter deux vecteurs.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlLe Pod est créé avec succès et s'exécutera après le démarrage. vectorAdd commande et sortie.
$ kubectl logs pod/cuda-vectoraddLe résultat d’une exécution correcte est le suivant :
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlGrâce au test de vérification ci-dessus, il est prouvé que les ressources Pod utilisant le GPU peuvent être créées sur le cluster K8s. Ensuite, nous utilisons KubeSphere pour créer un grand outil de gestion de modèles Ollama dans le cluster K8s en fonction des exigences d'utilisation réelles.
Cet exemple est un test simple, et le stockage est sélectionné chemin d'hôte Mode, veuillez le remplacer par une classe de stockage ou d'autres types de stockage persistant en utilisation réelle.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortInstructions spéciales: La console de gestion de KubeSphere prend en charge la configuration graphique du déploiement et d'autres ressources pour utiliser les ressources GPU. Les amis intéressés peuvent étudier par eux-mêmes.
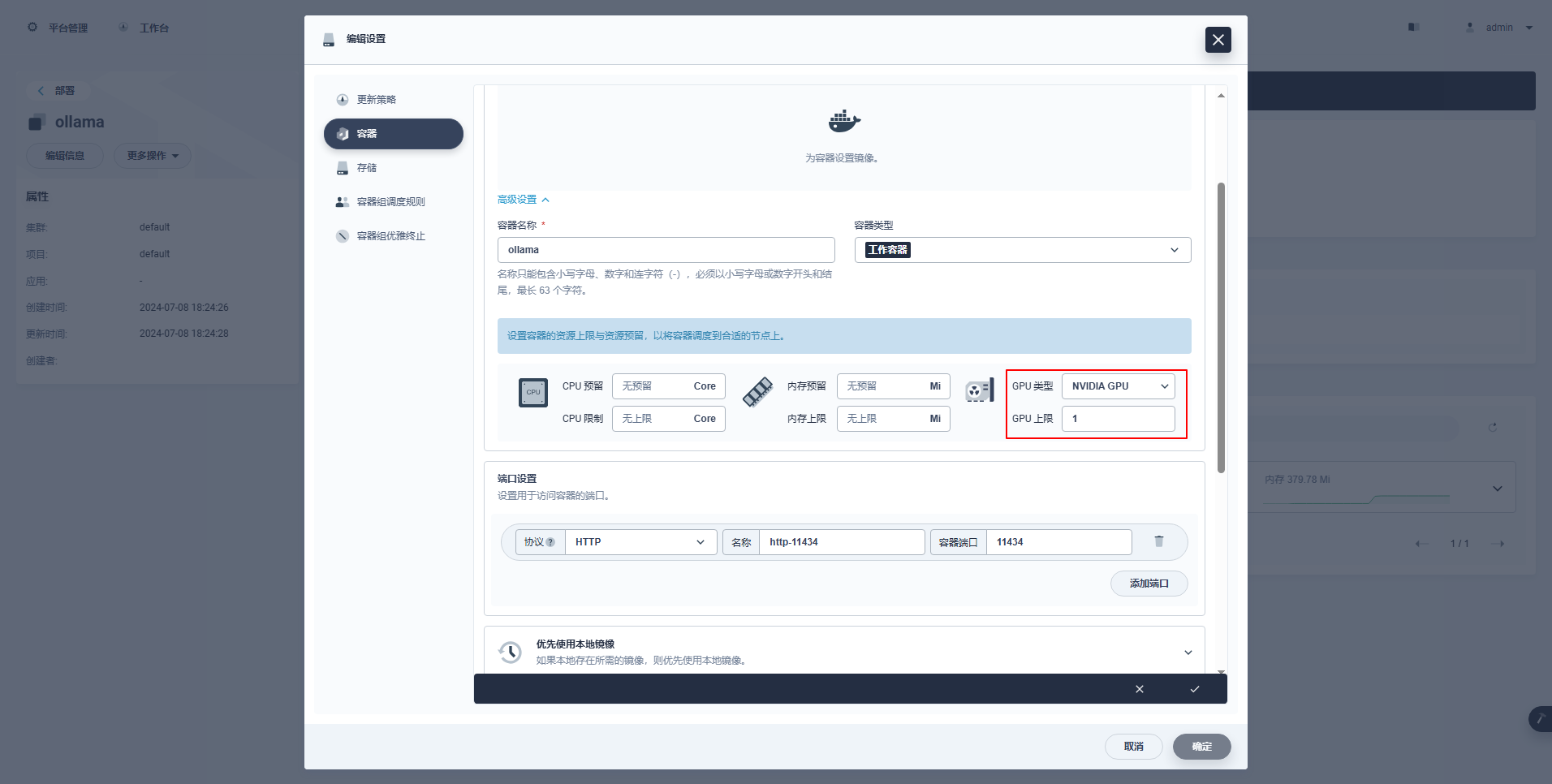
kubectl apply -f deploy-ollama.yamlÀ partir des résultats, vous pouvez voir que le pod a été créé sur le nœud ksp-gpu-worker-1 (Le modèle de carte graphique node Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Afin de gagner du temps, cet exemple utilise le modèle de petite taille open source qwen2 1.5b d'Alibaba comme modèle de test.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bLe résultat d’une exécution correcte est le suivant :
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successexister ksp-gpu-worker-1 Le nœud exécute la commande view suivante
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Exécuter sur le nœud Worker nvidia-smi -l Observez l’utilisation du GPU.
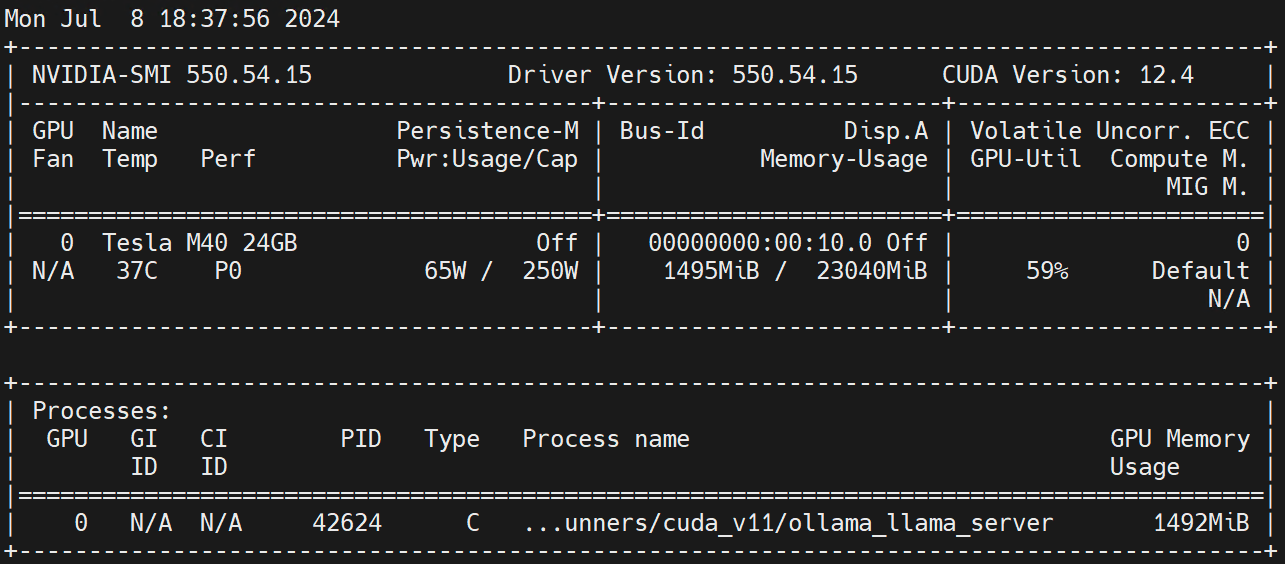
Clause de non-responsabilité:
Cet article est publié par la plateforme multi-édition Blog One Post Ouvrir l'écriture libérer!

Il se consacre à la recherche technologique depuis plus de 30 ans et maîtrise divers langages tels que java, linux, javascript, php, css, etc. Il a apporté de nombreuses contributions dans le domaine de l'open source. station de documentation pour les développeurs pour partager certains problèmes de développement technologique pour référence future.

