
τα στοιχεία επικοινωνίας μου
Ταχυδρομείο[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Συγγραφέας: Λειτουργία και Συντήρηση Youshu Star Master Με την ταχεία ανάπτυξη της τεχνητής νοημοσύνης, της μηχανικής μάθησης και της τεχνολογίας μεγάλων μοντέλων AI, η ζήτηση μας για υπολογιστικούς πόρους αυξάνεται επίσης. Ειδικά για μεγάλα μοντέλα τεχνητής νοημοσύνης που χρειάζεται να επεξεργάζονται δεδομένα μεγάλης κλίμακας και πολύπλοκους αλγόριθμους, η χρήση πόρων GPU γίνεται κρίσιμη. Για τους μηχανικούς λειτουργίας και συντήρησης, έχει γίνει απαραίτητη δεξιότητα η γνώση του τρόπου διαχείρισης και διαμόρφωσης πόρων GPU σε συμπλέγματα Kubernetes και πώς να αναπτύσσουν αποτελεσματικά εφαρμογές που βασίζονται σε αυτούς τους πόρους.
Σήμερα, θα σας οδηγήσω να κατανοήσετε σε βάθος πώς να χρησιμοποιήσετε το ισχυρό οικοσύστημα και τα εργαλεία του Kubernetes για να επιτύχετε διαχείριση πόρων GPU και ανάπτυξη εφαρμογών στην πλατφόρμα KubeSphere. Εδώ είναι τα τρία βασικά θέματα που θα διερευνήσει αυτό το άρθρο:
Διαβάζοντας αυτό το άρθρο, θα αποκτήσετε τις γνώσεις και τις δεξιότητες για τη διαχείριση πόρων GPU στο Kubernetes, βοηθώντας σας να κάνετε πλήρη χρήση των πόρων GPU σε ένα εγγενές περιβάλλον στο cloud και να προωθήσετε την ταχεία ανάπτυξη εφαρμογών τεχνητής νοημοσύνης.
KubeSphere Best Practice "2024" Οι πληροφορίες διαμόρφωσης υλικού πειραματικού περιβάλλοντος και λογισμικού της σειράς εγγράφων είναι οι εξής:
Πραγματική διαμόρφωση διακομιστή (αρχιτεκτονική 1:1 αντίγραφο ενός περιβάλλοντος παραγωγής μικρής κλίμακας, η διαμόρφωση είναι ελαφρώς διαφορετική)
| Όνομα CPU | IP | ΕΠΕΞΕΡΓΑΣΤΗΣ | Μνήμη | δίσκο συστήματος | δίσκος δεδομένων | χρήση |
|---|---|---|---|---|---|---|
| ksp-registry | 192.168.9.90 | 4 | 8 | 40 | 200 | Αποθήκη καθρέφτη στο λιμάνι |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-εργάτης-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-εργάτης/CI |
| ksp-εργάτης-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-εργάτης |
| ksp-εργάτης-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-εργάτης |
| ksp-storage-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-storage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | Πύλη μεσολάβησης υπηρεσίας εφαρμογών που έχει κατασκευαστεί από μόνος του/VIP: 192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | Πύλη μεσολάβησης υπηρεσίας εφαρμογών που έχει κατασκευαστεί από μόνος του/VIP: 192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | Κόμβοι υπηρεσίας που αναπτύσσονται εκτός του συμπλέγματος k8s (Gitlab, κ.λπ.) |
| σύνολο | 15 | 56 | 152 | 600 | 2000 |
Το πραγματικό περιβάλλον μάχης περιλαμβάνει πληροφορίες έκδοσης λογισμικού
Λόγω περιορισμών πόρων και κόστους, δεν έχω φυσικό κεντρικό υπολογιστή και κάρτα γραφικών υψηλής τεχνολογίας για να πειραματιστώ. Μόνο δύο εικονικές μηχανές εξοπλισμένες με κάρτες γραφικών GPU αρχικού επιπέδου μπορούν να προστεθούν ως κόμβοι εργασίας του συμπλέγματος.
Αν και αυτές οι κάρτες γραφικών δεν είναι τόσο ισχυρές όσο τα μοντέλα προηγμένης τεχνολογίας, είναι επαρκείς για τις περισσότερες εργασίες εκμάθησης και ανάπτυξης Με περιορισμένους πόρους, μια τέτοια διαμόρφωση μου παρέχει πολύτιμες πρακτικές ευκαιρίες για να εξερευνήσω σε βάθος τους πόρους GPU στα συμπλέγματα Kubernetes στρατηγικές προγραμματισμού.
Παρακαλώ αναφερθείτε σε Οδηγός προετοιμασίας συστήματος Kubernetes cluster node openEuler 22.03 LTS SP3, ολοκληρώστε τη διαμόρφωση προετοιμασίας του λειτουργικού συστήματος.
Ο αρχικός οδηγός διαμόρφωσης δεν περιλαμβάνει εργασίες αναβάθμισης του λειτουργικού συστήματος Κατά την προετοιμασία του συστήματος σε περιβάλλον με πρόσβαση στο Διαδίκτυο, πρέπει να αναβαθμίσετε το λειτουργικό σύστημα και στη συνέχεια να επανεκκινήσετε τον κόμβο.
Στη συνέχεια, χρησιμοποιούμε το KubeKey για να προσθέσουμε τον νέο κόμβο GPU στο υπάρχον σύμπλεγμα Kubernetes. Η όλη διαδικασία είναι σχετικά απλή και απαιτεί μόνο δύο βήματα.
Στον κόμβο Control-1, μεταβείτε στον κατάλογο kubekey για ανάπτυξη και τροποποιήστε το αρχικό αρχείο διαμόρφωσης συμπλέγματος Το όνομα που χρησιμοποιήσαμε στην πραγματική μάχη είναι ksp-v341-v1288.yaml, τροποποιήστε το σύμφωνα με την πραγματική κατάσταση.
Κύρια σημεία τροποποίησης:
Το τροποποιημένο παράδειγμα είναι το εξής:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Πριν προσθέσουμε κόμβους, ας επιβεβαιώσουμε τις πληροφορίες κόμβου του τρέχοντος συμπλέγματος.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Στη συνέχεια, εκτελούμε την ακόλουθη εντολή και χρησιμοποιούμε το τροποποιημένο αρχείο διαμόρφωσης για να προσθέσουμε τον νέο κόμβο Worker στο σύμπλεγμα.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlΑφού εκτελεστεί η παραπάνω εντολή, το KubeKey ελέγχει πρώτα εάν οι εξαρτήσεις και άλλες διαμορφώσεις για την ανάπτυξη του Kubernetes πληρούν τις απαιτήσεις. Αφού περάσετε τον έλεγχο, θα σας ζητηθεί να επιβεβαιώσετε την εγκατάσταση.εισαγωΝαί και πατήστε ENTER για να συνεχίσετε την ανάπτυξη.
Χρειάζονται περίπου 5 λεπτά για να ολοκληρωθεί η ανάπτυξη Ο συγκεκριμένος χρόνος εξαρτάται από την ταχύτητα του δικτύου, τη διαμόρφωση του μηχανήματος και τον αριθμό των κόμβων που προστέθηκαν.
Μόλις ολοκληρωθεί η ανάπτυξη, θα πρέπει να δείτε έξοδο παρόμοια με την παρακάτω στο τερματικό σας.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyΑνοίγουμε το πρόγραμμα περιήγησης και έχουμε πρόσβαση στη διεύθυνση IP και στη θύρα του κόμβου Control-1 30880, συνδεθείτε στη σελίδα σύνδεσης της κονσόλας διαχείρισης KubeSphere.
Εισαγάγετε τη διεπαφή διαχείρισης συμπλέγματος, κάντε κλικ στο μενού "Κόμβος" στα αριστερά και κάντε κλικ στο "Κόμβος συμπλέγματος" για να δείτε λεπτομερείς πληροφορίες σχετικά με τους διαθέσιμους κόμβους του συμπλέγματος Kubernetes.
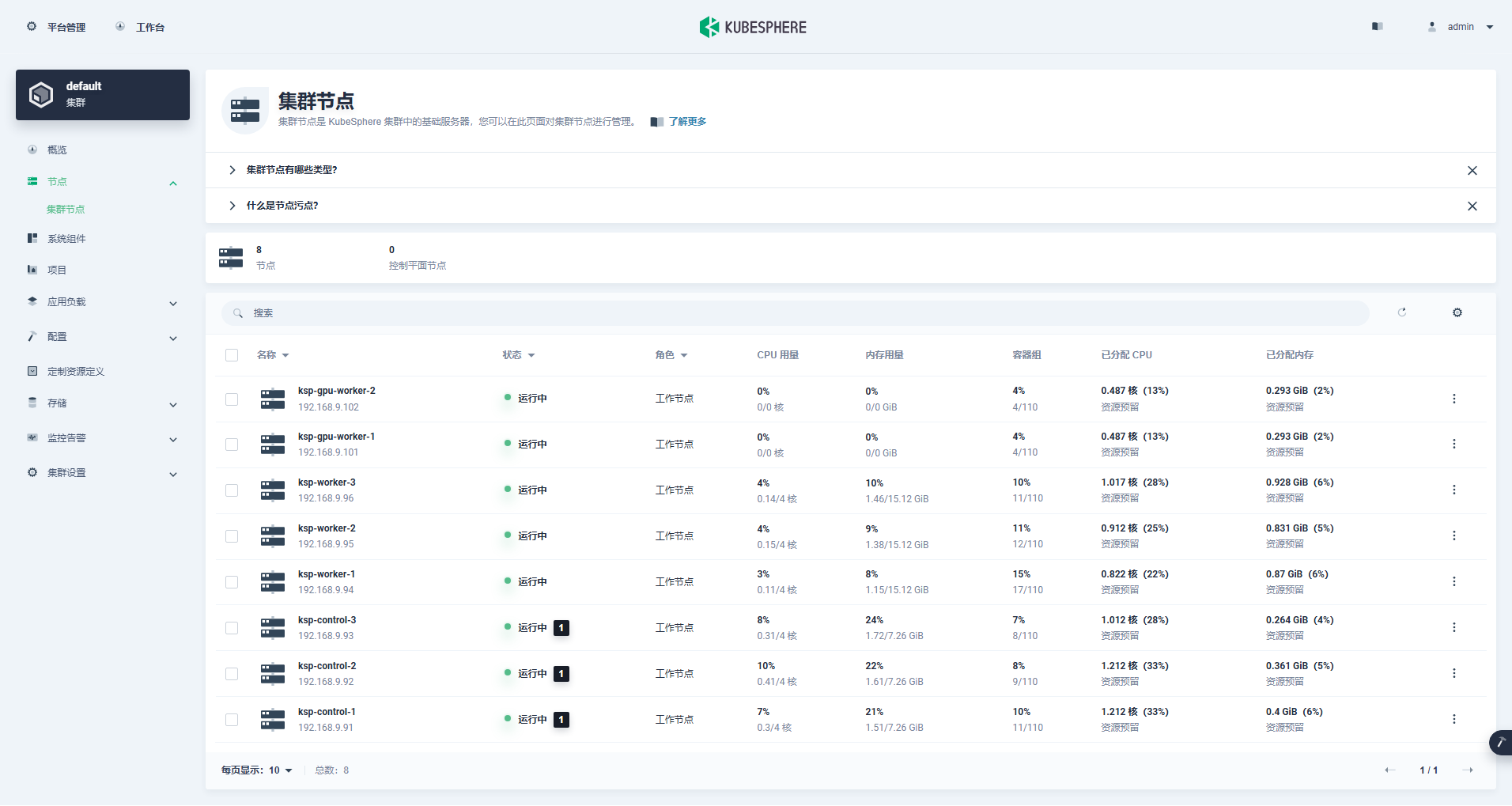
Εκτελέστε την εντολή kubectl στον κόμβο Control-1 για να λάβετε τις πληροφορίες κόμβου του συμπλέγματος Kubernetes.
kubectl get nodes -o wideΌπως μπορείτε να δείτε στην έξοδο, το τρέχον σύμπλεγμα Kubernetes έχει 8 κόμβους και το όνομα, η κατάσταση, ο ρόλος, ο χρόνος επιβίωσης, ο αριθμός έκδοσης Kubernetes, η εσωτερική IP, ο τύπος λειτουργικού συστήματος, η έκδοση πυρήνα και ο χρόνος εκτέλεσης κοντέινερ κάθε κόμβου εμφανίζονται λεπτομερώς και άλλες πληροφορίες.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Σε αυτό το σημείο, έχουμε ολοκληρώσει όλες τις εργασίες χρήσης του Kubekey για να προσθέσουμε 2 κόμβους Worker στο υπάρχον σύμπλεγμα Kubernetes που αποτελείται από 3 κύριους κόμβους και 3 κόμβους Worker.
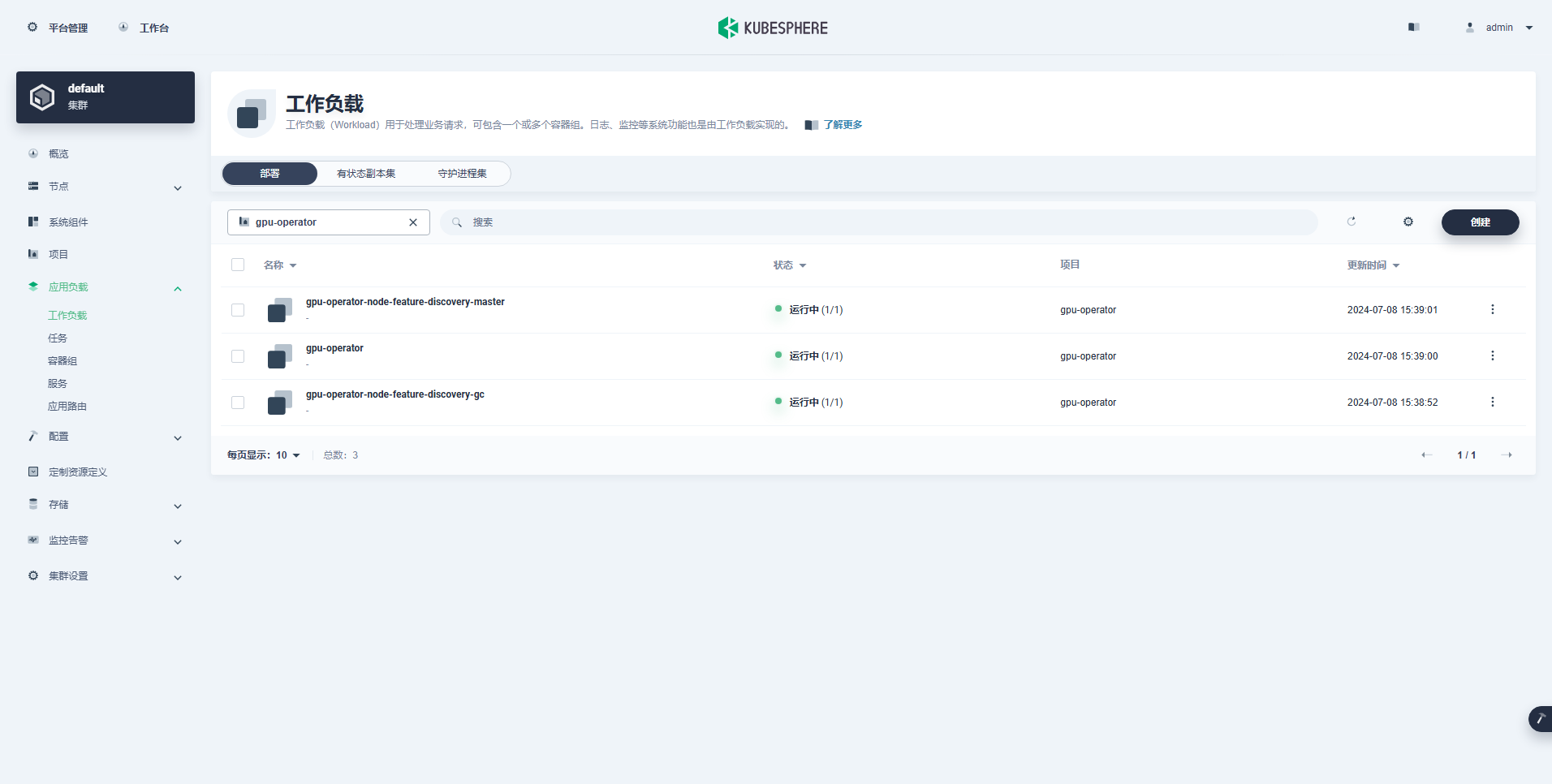
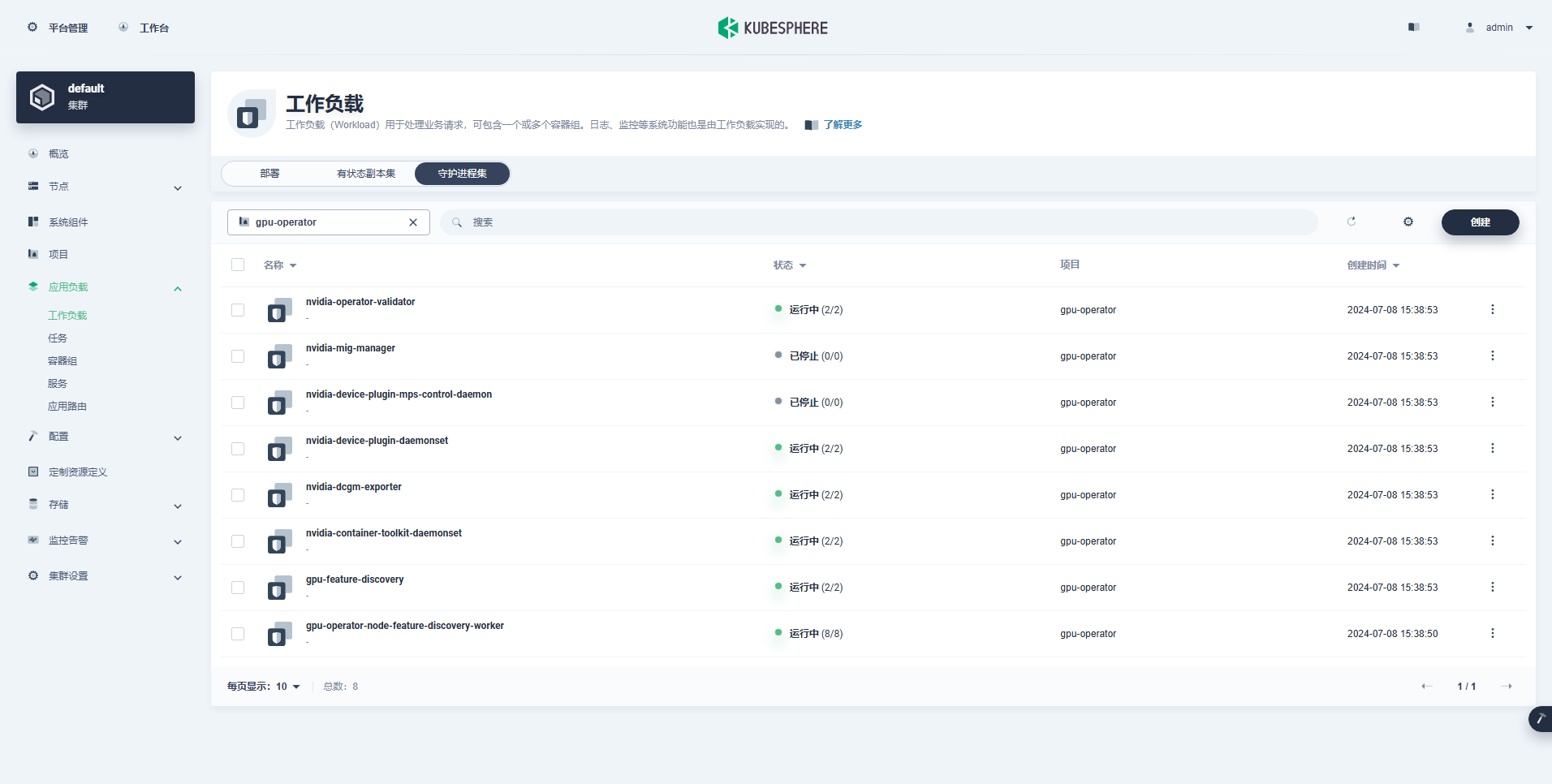
Στη συνέχεια, εγκαθιστούμε το NVIDIA GPU Operator που παράγεται επίσημα από την NVIDIA για να πραγματοποιήσουμε το scheduling Pod του K8 για χρήση πόρων GPU.
Το NVIDIA GPU Operator υποστηρίζει αυτόματη εγκατάσταση προγραμμάτων οδήγησης κάρτας γραφικών, αλλά μόνο τα CentOS 7, 8 και Ubuntu 20.04, 22.04 και άλλες εκδόσεις δεν υποστηρίζουν το openEuler, επομένως πρέπει να εγκαταστήσετε το πρόγραμμα οδήγησης της κάρτας γραφικών με μη αυτόματο τρόπο.
Παρακαλώ αναφερθείτε σε Η καλύτερη πρακτική του KubeSphere: το openEuler 22.03 LTS SP3 εγκαθιστά το πρόγραμμα οδήγησης κάρτας γραφικών NVIDIA, ολοκληρώστε την εγκατάσταση του προγράμματος οδήγησης της κάρτας γραφικών.
Το Node Feature Discovery (NFD) εντοπίζει ελέγχους χαρακτηριστικών.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Το αποτέλεσμα εκτέλεσης της παραπάνω εντολής είναι true, εικονογραφούν NFD Εκτελείται ήδη στο σύμπλεγμα. Εάν το NFD εκτελείται ήδη στο σύμπλεγμα, η ανάπτυξη του NFD πρέπει να απενεργοποιηθεί κατά την εγκατάσταση του χειριστή.
εικονογραφώ: Τα συμπλέγματα K8s που αναπτύσσονται χρησιμοποιώντας το KubeSphere δεν θα εγκαταστήσουν και δεν θα διαμορφώσουν το NFD από προεπιλογή.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateΧρησιμοποιήστε το προεπιλεγμένο αρχείο διαμόρφωσης, απενεργοποιήστε την αυτόματη εγκατάσταση προγραμμάτων οδήγησης κάρτας γραφικών και εγκαταστήστε τον χειριστή GPU.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseΣημείωση: Δεδομένου ότι η εγκατεστημένη εικόνα είναι σχετικά μεγάλη, ενδέχεται να προκύψει χρονικό όριο κατά την αρχική εγκατάσταση. Μπορείτε να εξετάσετε το ενδεχόμενο να χρησιμοποιήσετε εγκατάσταση εκτός σύνδεσης για να λύσετε αυτό το είδος προβλήματος.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseΤο αποτέλεσμα εξόδου της σωστής εκτέλεσης είναι το εξής:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneΜετά την εκτέλεση της εντολής εγκατάστασης του χειριστή GPU, περιμένετε υπομονετικά μέχρι να τραβήξουν με επιτυχία όλες οι εικόνες και όλα τα Pods να βρίσκονται σε κατάσταση Εκτέλεσης.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110εικονογραφώ: Συγκεντρώνω
nvidia.com/gpu:Η αξία του πεδίου.
Ο φόρτος εργασίας που δημιουργήθηκε με επιτυχία έχει ως εξής:
Αφού εγκατασταθεί σωστά ο χειριστής GPU, χρησιμοποιήστε την εικόνα βάσης CUDA για να ελέγξετε εάν τα K8 μπορούν να δημιουργήσουν σωστά Pods που χρησιμοποιούν πόρους GPU.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlΑπό τα αποτελέσματα, μπορείτε να δείτε ότι το pod δημιουργήθηκε στον κόμβο ksp-gpu-worker-2 (Η κάρτα γραφικών node μοντέλο Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Το αποτέλεσμα εξόδου της σωστής εκτέλεσης είναι το εξής:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlΕφαρμόστε ένα απλό παράδειγμα CUDA για την προσθήκη δύο διανυσμάτων.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlΤο Pod δημιουργήθηκε με επιτυχία και θα τρέξει μετά την εκκίνηση. vectorAdd εντολή και έξοδος.
$ kubectl logs pod/cuda-vectoraddΤο αποτέλεσμα εξόδου της σωστής εκτέλεσης είναι το εξής:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlΜέσω της παραπάνω δοκιμής επαλήθευσης, αποδεικνύεται ότι οι πόροι Pod με χρήση GPU μπορούν να δημιουργηθούν στο σύμπλεγμα K8s Στη συνέχεια, χρησιμοποιούμε το KubeSphere για να δημιουργήσουμε ένα μεγάλο εργαλείο διαχείρισης μοντέλων στο σύμπλεγμα K8s με βάση τις πραγματικές απαιτήσεις χρήσης.
Αυτό το παράδειγμα είναι μια απλή δοκιμή και έχει επιλεγεί η αποθήκευση hostPath Λειτουργία, αντικαταστήστε την με κατηγορία αποθήκευσης ή άλλους τύπους μόνιμης αποθήκευσης σε πραγματική χρήση.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortΕιδικές Οδηγίες: Η κονσόλα διαχείρισης του KubeSphere υποστηρίζει τη γραφική διαμόρφωση του Deployment και άλλων πόρων για τη χρήση πόρων GPU Τα παραδείγματα διαμόρφωσης είναι τα εξής Οι ενδιαφερόμενοι φίλοι μπορούν να μελετήσουν μόνοι τους.
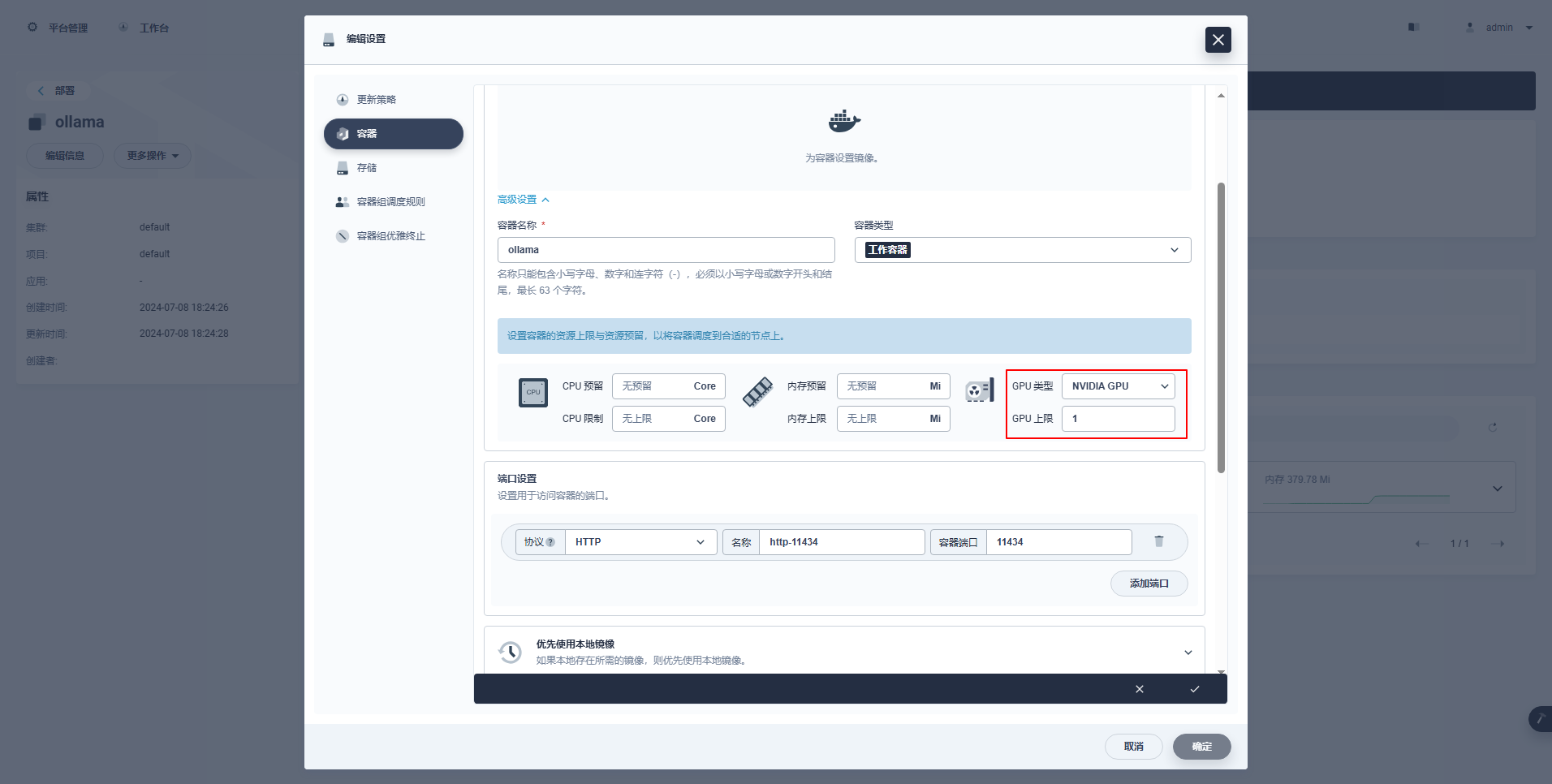
kubectl apply -f deploy-ollama.yamlΑπό τα αποτελέσματα, μπορείτε να δείτε ότι το pod δημιουργήθηκε στον κόμβο ksp-gpu-worker-1 (Η κάρτα γραφικών node μοντέλο Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Για εξοικονόμηση χρόνου, αυτό το παράδειγμα χρησιμοποιεί το μοντέλο ανοιχτού κώδικα qwen2 1.5b μικρού μεγέθους της Alibaba ως μοντέλο δοκιμής.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bΤο αποτέλεσμα εξόδου της σωστής εκτέλεσης είναι το εξής:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successυπάρχει ksp-gpu-worker-1 Ο κόμβος εκτελεί την ακόλουθη εντολή προβολής
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Εκτέλεση στον κόμβο Worker nvidia-smi -l Παρατηρήστε τη χρήση της GPU.
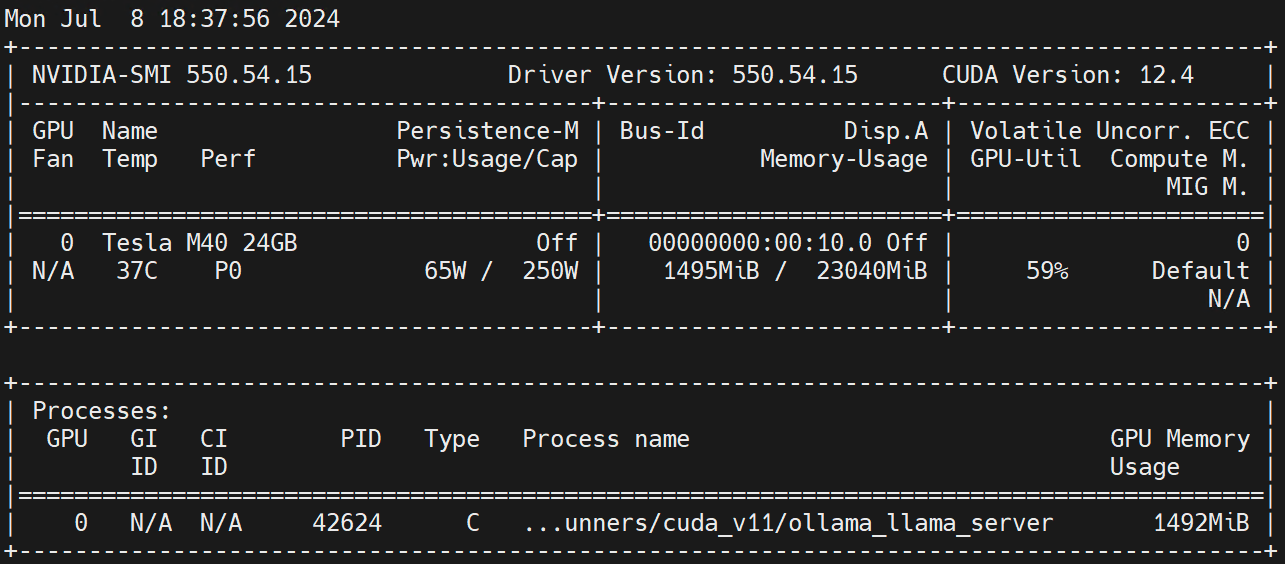
Αποποίηση ευθυνών:
Αυτό το άρθρο δημοσιεύεται από το Blog One Post Multi-Publishing Platform OpenWrite ελευθέρωση!

Έχει αφοσιωθεί στην έρευνα της τεχνολογίας για περισσότερα από 30 χρόνια και είναι ικανός σε διάφορες γλώσσες όπως java, linux, javascript, php, css κ.λπ. Έχει κάνει πολλές συνεισφορές στον τομέα του ανοιχτού κώδικα τεκμηρίωσης προγραμματιστή για να μοιραστείτε τα ζητήματα στην ανάπτυξη τεχνολογίας για μελλοντική αναφορά

Ταχυδρομείο[email protected]