
informasi kontak saya
Surat[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Penulis: Pengoperasian dan Pemeliharaan Youshu Star Master Dengan pesatnya perkembangan kecerdasan buatan, pembelajaran mesin, dan teknologi model besar AI, permintaan kami akan sumber daya komputasi juga meningkat. Khususnya untuk model AI berukuran besar yang perlu memproses data berskala besar dan algoritma yang kompleks, penggunaan sumber daya GPU menjadi sangat penting. Bagi para insinyur operasi dan pemeliharaan, menguasai cara mengelola dan mengonfigurasi sumber daya GPU di kluster Kubernetes, dan cara menerapkan aplikasi yang mengandalkan sumber daya ini, merupakan suatu keterampilan yang sangat diperlukan.
Hari ini, saya akan memandu Anda untuk mendapatkan pemahaman mendalam tentang cara menggunakan ekosistem dan alat Kubernetes yang kuat untuk mencapai manajemen sumber daya GPU dan penerapan aplikasi pada platform KubeSphere. Berikut adalah tiga tema inti yang akan dieksplorasi artikel ini:
Dengan membaca artikel ini, Anda akan memperoleh pengetahuan dan keterampilan untuk mengelola sumber daya GPU di Kubernetes, membantu Anda memanfaatkan sepenuhnya sumber daya GPU di lingkungan cloud-native dan mendorong perkembangan pesat aplikasi AI.
Praktik Terbaik KubeSphere "2024" Konfigurasi perangkat keras lingkungan eksperimental dan informasi perangkat lunak dari rangkaian dokumen adalah sebagai berikut:
Konfigurasi server aktual (arsitektur replika 1:1 dari lingkungan produksi skala kecil, konfigurasinya sedikit berbeda)
| nama CPU | AKU P | prosesor | Penyimpanan | disk sistem | disk data | menggunakan |
|---|---|---|---|---|---|---|
| pendaftaran ksp | 192.168.9.90 | 4 | 8 | 40 | 200 | Gudang cermin pelabuhan |
| ksp-kontrol-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/bidang-kontrol-k8s |
| ksp-kontrol-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/bidang-kontrol-k8s |
| ksp-kontrol-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/bidang-kontrol-k8s |
| pekerja-ksp-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-pekerja/CI |
| pekerja-ksp-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-pekerja |
| pekerja-ksp-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-pekerja |
| penyimpanan-ksp-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| penyimpanan-ksp-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| penyimpanan-ksp-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-pekerja-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-pekerja (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-pekerja-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-pekerja (GPU NVIDIA Tesla P100 16G) |
| gerbang-ksp-1 | 192.168.9.103 | 2 | 4 | 40 | Gerbang proksi layanan aplikasi/VIP yang dibuat sendiri: 192.168.9.100 | |
| gerbang-ksp-2 | 192.168.9.104 | 2 | 4 | 40 | Gerbang proksi layanan aplikasi/VIP yang dibuat sendiri: 192.168.9.100 | |
| ksp-tengah | 192.168.9.105 | 4 | 8 | 40 | 100 | Node layanan dikerahkan di luar kluster k8s (Gitlab, dll.) |
| total | 15 | 56 | 152 | 600 | 2000 |
Lingkungan pertarungan sebenarnya melibatkan informasi versi perangkat lunak
Karena keterbatasan sumber daya dan biaya, saya tidak memiliki host fisik dan kartu grafis kelas atas untuk bereksperimen. Hanya dua mesin virtual yang dilengkapi dengan kartu grafis GPU tingkat pemula yang dapat ditambahkan sebagai node pekerja dalam cluster.
Meskipun kartu grafis ini tidak sekuat model kelas atas, namun cukup untuk sebagian besar tugas pembelajaran dan pengembangan. Dengan sumber daya yang terbatas, konfigurasi seperti itu memberi saya peluang langsung yang berharga untuk mengeksplorasi sumber daya GPU secara mendalam dalam manajemen dan cluster Kubernetes strategi penjadwalan.
Silakan merujuk ke Panduan inisialisasi sistem node cluster Kubernetes openEuler 22.03 LTS SP3, selesaikan konfigurasi inisialisasi sistem operasi.
Panduan konfigurasi awal tidak melibatkan tugas pemutakhiran sistem operasi. Saat menginisialisasi sistem di lingkungan dengan akses Internet, Anda harus memutakhirkan sistem operasi dan kemudian memulai ulang node.
Selanjutnya, kami menggunakan KubeKey untuk menambahkan node GPU yang baru ditambahkan ke cluster Kubernetes yang ada. Lihat dokumentasi resminya.
Pada node Control-1, beralih ke direktori kubekey untuk penerapan dan ubah file konfigurasi cluster asli ksp-v341-v1288.yaml, harap modifikasi sesuai dengan situasi sebenarnya.
Poin modifikasi utama:
Contoh yang dimodifikasi adalah sebagai berikut:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Sebelum menambahkan node, mari konfirmasi informasi node dari cluster saat ini.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Selanjutnya, kami menjalankan perintah berikut dan menggunakan file konfigurasi yang dimodifikasi untuk menambahkan node Pekerja baru ke cluster.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlSetelah perintah di atas dijalankan, KubeKey terlebih dahulu memeriksa apakah dependensi dan konfigurasi lain untuk penerapan Kubernetes memenuhi persyaratan. Setelah melewati pemeriksaan, Anda akan diminta untuk mengkonfirmasi instalasi.memasukiYa dan tekan ENTER untuk melanjutkan penerapan.
Diperlukan waktu sekitar 5 menit untuk menyelesaikan penerapan. Waktu spesifiknya bergantung pada kecepatan jaringan, konfigurasi mesin, dan jumlah node yang ditambahkan.
Setelah penerapan selesai, Anda akan melihat keluaran seperti berikut di terminal Anda.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyKami membuka browser dan mengakses alamat IP dan port node Control-1 30880, masuk ke halaman login konsol manajemen KubeSphere.
Masuk ke antarmuka manajemen cluster, klik menu "Node" di sebelah kiri, dan klik "Cluster Node" untuk melihat informasi rinci tentang node yang tersedia di cluster Kubernetes.
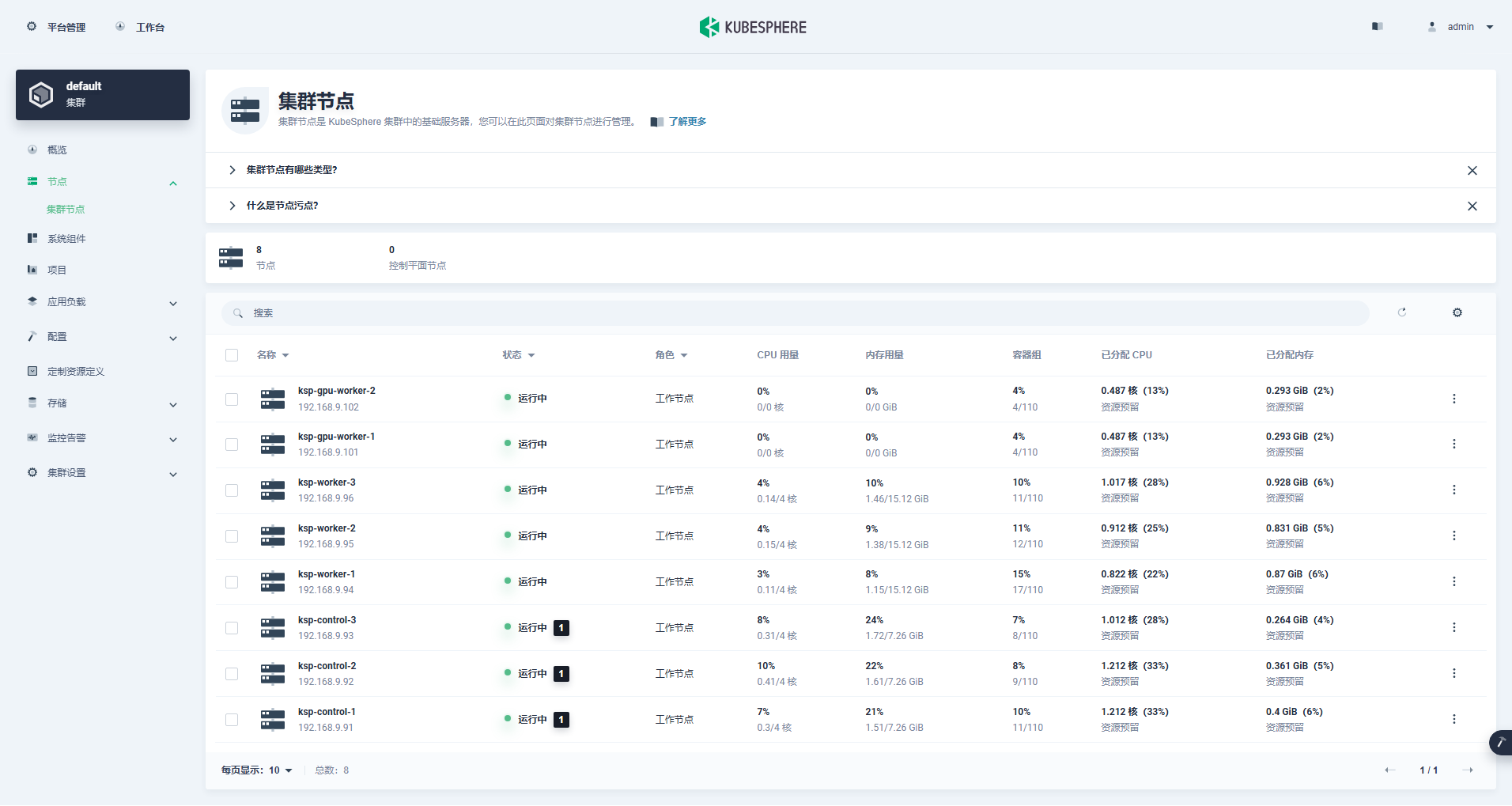
Jalankan perintah kubectl pada node Control-1 untuk mendapatkan informasi node cluster Kubernetes.
kubectl get nodes -o wideSeperti yang bisa Anda lihat di output, cluster Kubernetes saat ini memiliki 8 node, dan nama, status, peran, waktu bertahan, nomor versi Kubernetes, IP internal, jenis sistem operasi, versi kernel, dan runtime container dari setiap node ditampilkan secara detail. .dan informasi lainnya.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Sampai disini kita telah menyelesaikan seluruh tugas penggunaan Kubekey untuk menambahkan 2 node Worker pada cluster Kubernetes yang sudah ada yang terdiri dari 3 node Master dan 3 node Worker.
Selanjutnya, kami menginstal Operator GPU NVIDIA yang diproduksi secara resmi oleh NVIDIA untuk mewujudkan Pod penjadwalan K8 untuk menggunakan sumber daya GPU.
Operator GPU NVIDIA mendukung instalasi otomatis driver grafis, tetapi hanya CentOS 7, 8 dan Ubuntu 20.04, 22.04 dan versi lainnya tidak mendukung openEuler, jadi Anda perlu menginstal driver grafis secara manual.
Silakan merujuk ke Praktik terbaik KubeSphere: openEuler 22.03 LTS SP3 menginstal driver kartu grafis NVIDIA, selesaikan instalasi driver kartu grafis.
Node Feature Discovery (NFD) mendeteksi pemeriksaan fitur.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Hasil eksekusi dari perintah di atas adalah true, menjelaskan NFD Sudah berjalan di cluster. Jika NFD sudah berjalan di cluster, penerapan NFD harus dinonaktifkan saat menginstal operator.
menjelaskan: Kluster K8 yang disebarkan menggunakan KubeSphere tidak akan menginstal dan mengonfigurasi NFD secara default.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateGunakan file konfigurasi default, nonaktifkan instalasi otomatis driver kartu grafis, dan instal Operator GPU.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseCatatan: Karena gambar yang diinstal relatif besar, waktu tunggu mungkin terjadi selama instalasi awal. Silakan periksa apakah gambar Anda berhasil ditarik! Anda dapat mempertimbangkan untuk menggunakan instalasi offline untuk mengatasi masalah jenis ini.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseHasil keluaran dari eksekusi yang benar adalah sebagai berikut:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneSetelah menjalankan perintah untuk menginstal Operator GPU, harap menunggu dengan sabar hingga semua image berhasil ditarik dan semua Pod berada dalam status Running.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110menjelaskan: Fokus
nvidia.com/gpu:Nilai lapangan.
Beban kerja yang berhasil dibuat adalah sebagai berikut:
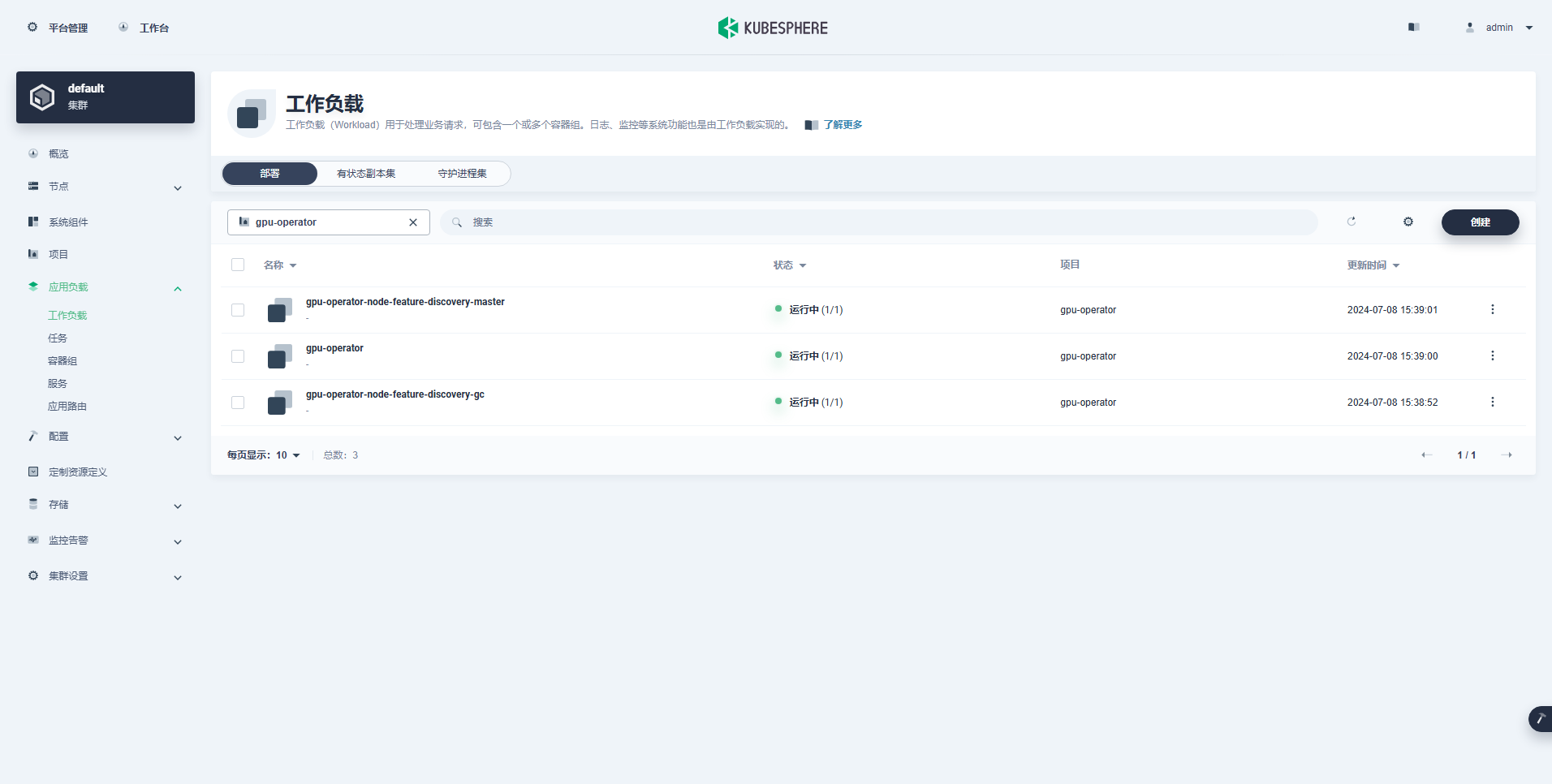
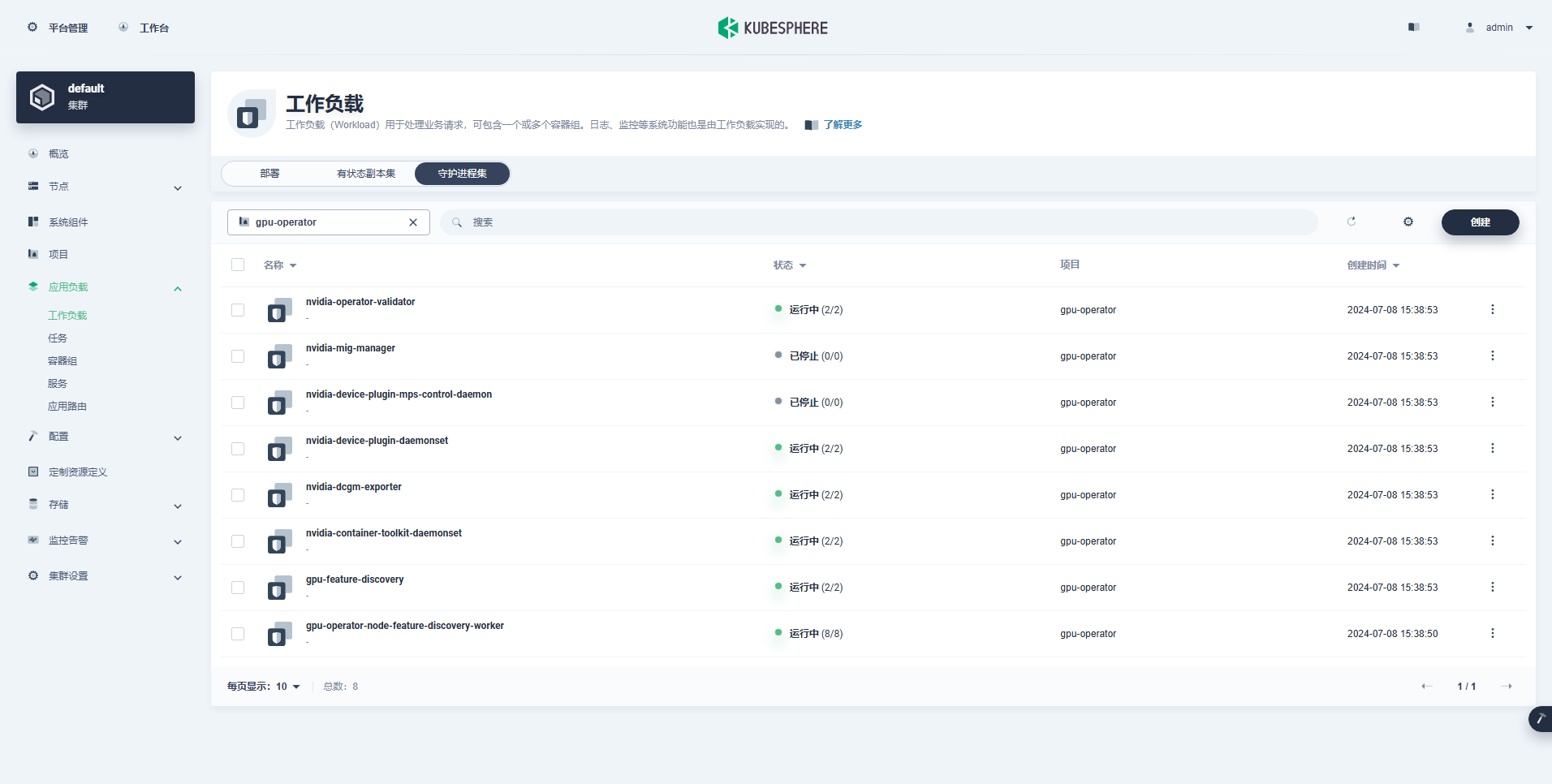
Setelah Operator GPU terinstal dengan benar, gunakan image dasar CUDA untuk menguji apakah K8 dapat membuat Pod yang menggunakan sumber daya GPU dengan benar.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlDari hasilnya, Anda dapat melihat bahwa pod dibuat pada node ksp-gpu-worker-2 (Model kartu grafis simpul Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Hasil keluaran dari eksekusi yang benar adalah sebagai berikut:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlTerapkan contoh CUDA sederhana untuk menjumlahkan dua vektor.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlPod berhasil dibuat dan akan dijalankan setelah startup. vectorAdd perintah dan keluar.
$ kubectl logs pod/cuda-vectoraddHasil keluaran dari eksekusi yang benar adalah sebagai berikut:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlMelalui pengujian verifikasi di atas, terbukti bahwa sumber daya Pod menggunakan GPU dapat dibuat di cluster K8s. Selanjutnya, kami menggunakan KubeSphere untuk membuat alat manajemen model besar Ollama di cluster K8s berdasarkan kebutuhan penggunaan sebenarnya.
Contoh ini adalah tes sederhana, dan penyimpanan dipilih jalurhosting Mode, silakan ganti dengan kelas penyimpanan atau jenis penyimpanan persisten lainnya yang digunakan sebenarnya.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortInstruksi Khusus: Konsol manajemen KubeSphere mendukung konfigurasi grafis Deployment dan sumber daya lainnya untuk menggunakan sumber daya GPU. Contoh konfigurasinya adalah sebagai berikut.
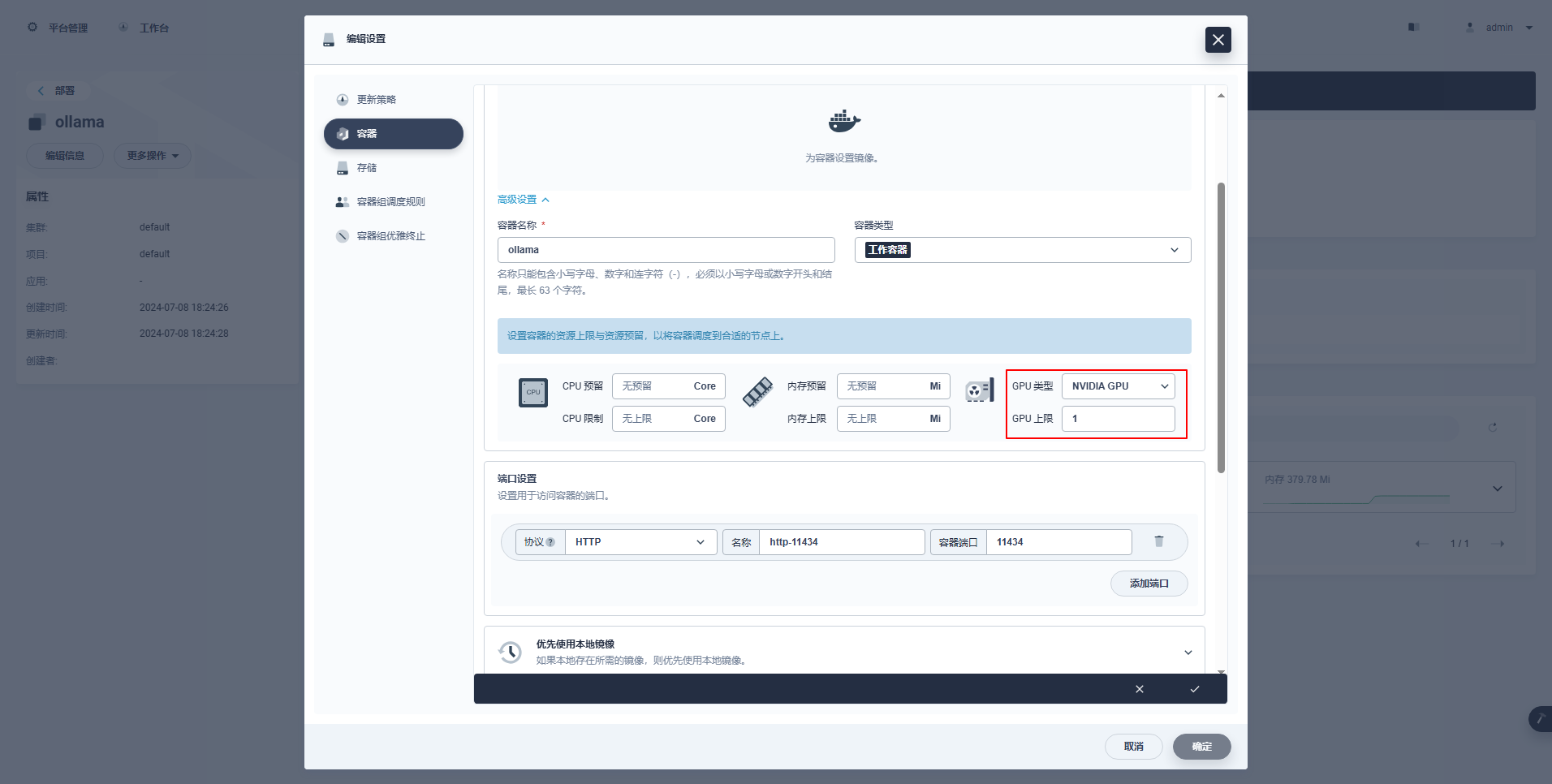
kubectl apply -f deploy-ollama.yamlDari hasilnya, Anda dapat melihat bahwa pod dibuat pada node ksp-gpu-worker-1 (Model kartu grafis simpul Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Untuk menghemat waktu, contoh ini menggunakan model ukuran kecil qwen2 1.5b open source Alibaba sebagai model pengujian.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bHasil keluaran dari eksekusi yang benar adalah sebagai berikut:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successada ksp-gpu-pekerja-1 Node menjalankan perintah tampilan berikut
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Jalankan pada node Pekerja nvidia-smi -l Amati penggunaan GPU.
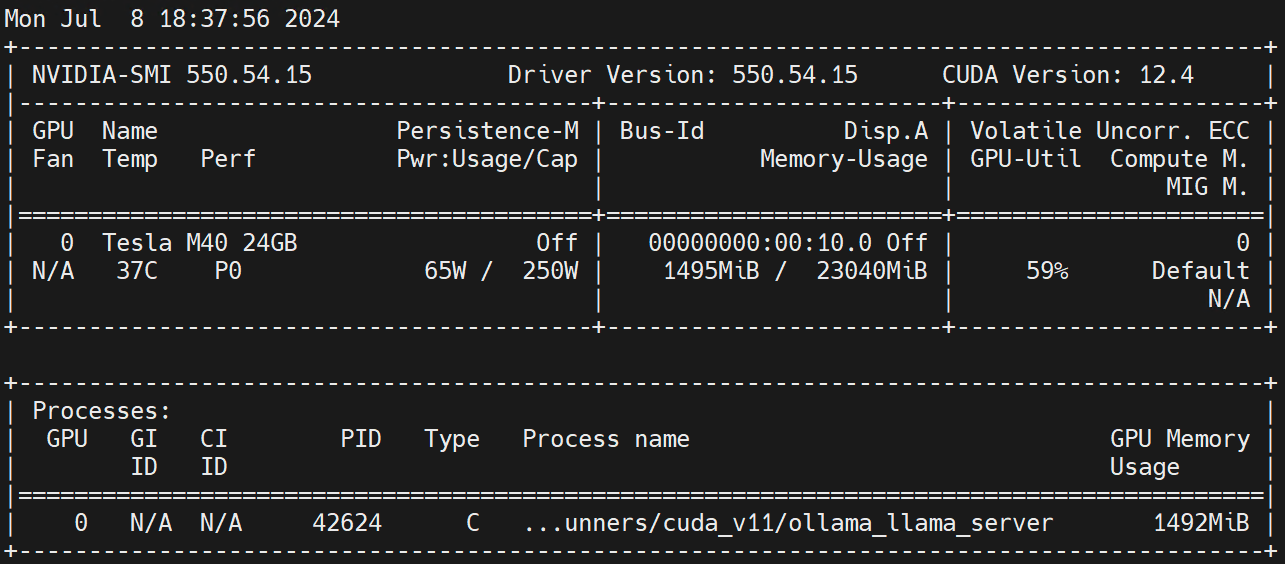
Penafian:
Artikel ini diterbitkan oleh Platform Posting Ganda Artikel Blog One BukaTulis melepaskan!

Ia telah mengabdikan dirinya untuk meneliti teknologi selama lebih dari 30 tahun, dan mahir dalam berbagai bahasa seperti java, linux, javascript, php, css, dll. Ia telah memberikan banyak kontribusi di bidang open source stasiun dokumentasi pengembang untuk berbagi beberapa masalah dalam pengembangan teknologi untuk referensi di masa mendatang

Surat[email protected]