
Mi informacion de contacto
Correo[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Autor: Operación y mantenimiento Youshu Star Master Con el rápido desarrollo de la inteligencia artificial, el aprendizaje automático y la tecnología de modelos grandes de IA, nuestra demanda de recursos informáticos también está aumentando. Especialmente para los grandes modelos de IA que necesitan procesar datos a gran escala y algoritmos complejos, el uso de recursos de GPU se vuelve fundamental. Para los ingenieros de operación y mantenimiento, dominar cómo administrar y configurar los recursos de GPU en los clústeres de Kubernetes y cómo implementar de manera eficiente aplicaciones que dependen de estos recursos se ha convertido en una habilidad indispensable.
Hoy, lo guiaré para que obtenga una comprensión profunda de cómo utilizar el poderoso ecosistema y las herramientas de Kubernetes para lograr la administración de recursos de GPU y la implementación de aplicaciones en la plataforma KubeSphere. Estos son los tres temas principales que explorará este artículo:
Al leer este artículo, obtendrá el conocimiento y las habilidades para administrar los recursos de GPU en Kubernetes, lo que le ayudará a aprovechar al máximo los recursos de GPU en un entorno nativo de la nube y promover el rápido desarrollo de aplicaciones de IA.
Mejores prácticas de KubeSphere "2024" La configuración del hardware del entorno experimental y la información del software de la serie de documentos son los siguientes:
Configuración real del servidor (arquitectura réplica 1:1 de un entorno de producción a pequeña escala, la configuración es ligeramente diferente)
| nombre de la CPU | Propiedad intelectual | UPC | Memoria | disco del sistema | disco de datos | usar |
|---|---|---|---|---|---|---|
| registro ksp | 192.168.9.90 | 4 | 8 | 40 | 200 | Almacén de espejos del puerto |
| control-ksp-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | Plano de control de KubeSphere/k8s |
| control-ksp-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | Plano de control de KubeSphere/k8s |
| control-ksp-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | Plano de control de KubeSphere/k8s |
| ksp-trabajador-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | Trabajador k8s/CI |
| trabajador-2 de ksp | 192.168.9.95 | 4 | 16 | 40 | 100 | trabajador k8s |
| ksp-trabajador-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | trabajador k8s |
| ksp-almacenamiento-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-almacenamiento-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | Búsqueda elástica//Ceph/Longhorn |
| ksp-almacenamiento-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | Búsqueda elástica//Ceph/Longhorn |
| ksp-gpu-trabajador-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-trabajador (GPU NVIDIA Tesla M40 24G) |
| Trabajador de GPU KSP 2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-trabajador (GPU NVIDIA Tesla P100 16G) |
| puerta de enlace ksp-1 | 192.168.9.103 | 2 | 4 | 40 | Puerta de enlace proxy/VIP de servicio de aplicación de creación propia: 192.168.9.100 | |
| puerta de enlace ksp-2 | 192.168.9.104 | 2 | 4 | 40 | Puerta de enlace proxy/VIP de servicio de aplicación de creación propia: 192.168.9.100 | |
| ksp-medio | 192.168.9.105 | 4 | 8 | 40 | 100 | Nodos de servicio implementados fuera del clúster k8s (Gitlab, etc.) |
| total | 15 | 56 | 152 | 600 | 2000 |
El entorno de combate real implica información sobre la versión del software.
Debido a limitaciones de recursos y costos, no tengo un host físico ni una tarjeta gráfica de alta gama para experimentar. Sólo se pueden agregar dos máquinas virtuales equipadas con tarjetas gráficas GPU de nivel básico como nodos trabajadores del clúster.
Aunque estas tarjetas gráficas no son tan poderosas como los modelos de alta gama, son suficientes para la mayoría de las tareas de aprendizaje y desarrollo con recursos limitados, esta configuración me brinda valiosas oportunidades prácticas para explorar en profundidad los recursos de GPU en la administración y el clúster de Kubernetes. estrategias de programación.
Por favor refiérase a Guía de inicialización del sistema openEuler 22.03 LTS SP3 del nodo del clúster de Kubernetes, complete la configuración de inicialización del sistema operativo.
La guía de configuración inicial no implica tareas de actualización del sistema operativo. Al inicializar el sistema en un entorno con acceso a Internet, debe actualizar el sistema operativo y luego reiniciar el nodo.
A continuación, usamos KubeKey para agregar el nodo GPU recién agregado al clúster de Kubernetes existente. Consulte la documentación oficial. Todo el proceso es relativamente simple y solo requiere dos pasos.
En el nodo Control-1, cambie al directorio kubekey para la implementación y modifique el archivo de configuración del clúster original. El nombre que usamos en el combate real es. ksp-v341-v1288.yaml, modifíquelo según la situación real.
Principales puntos de modificación:
El ejemplo modificado es el siguiente:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Antes de agregar nodos, confirmemos la información del nodo del clúster actual.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13A continuación, ejecutamos el siguiente comando y usamos el archivo de configuración modificado para agregar el nuevo nodo trabajador al clúster.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlDespués de ejecutar el comando anterior, KubeKey primero verifica si las dependencias y otras configuraciones para implementar Kubernetes cumplen con los requisitos. Después de pasar la verificación, se le pedirá que confirme la instalación.ingresarSí y presione ENTRAR para continuar con la implementación.
Se necesitan unos 5 minutos para completar la implementación. El tiempo específico depende de la velocidad de la red, la configuración de la máquina y la cantidad de nodos agregados.
Una vez que se complete la implementación, debería ver un resultado similar al siguiente en su terminal.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyAbrimos el navegador y accedemos a la dirección IP y puerto del nodo Control-1 30880, inicie sesión en la página de inicio de sesión de la consola de administración de KubeSphere.
Ingrese a la interfaz de administración del clúster, haga clic en el menú "Nodo" a la izquierda y haga clic en "Nodo del clúster" para ver información detallada sobre los nodos disponibles del clúster de Kubernetes.
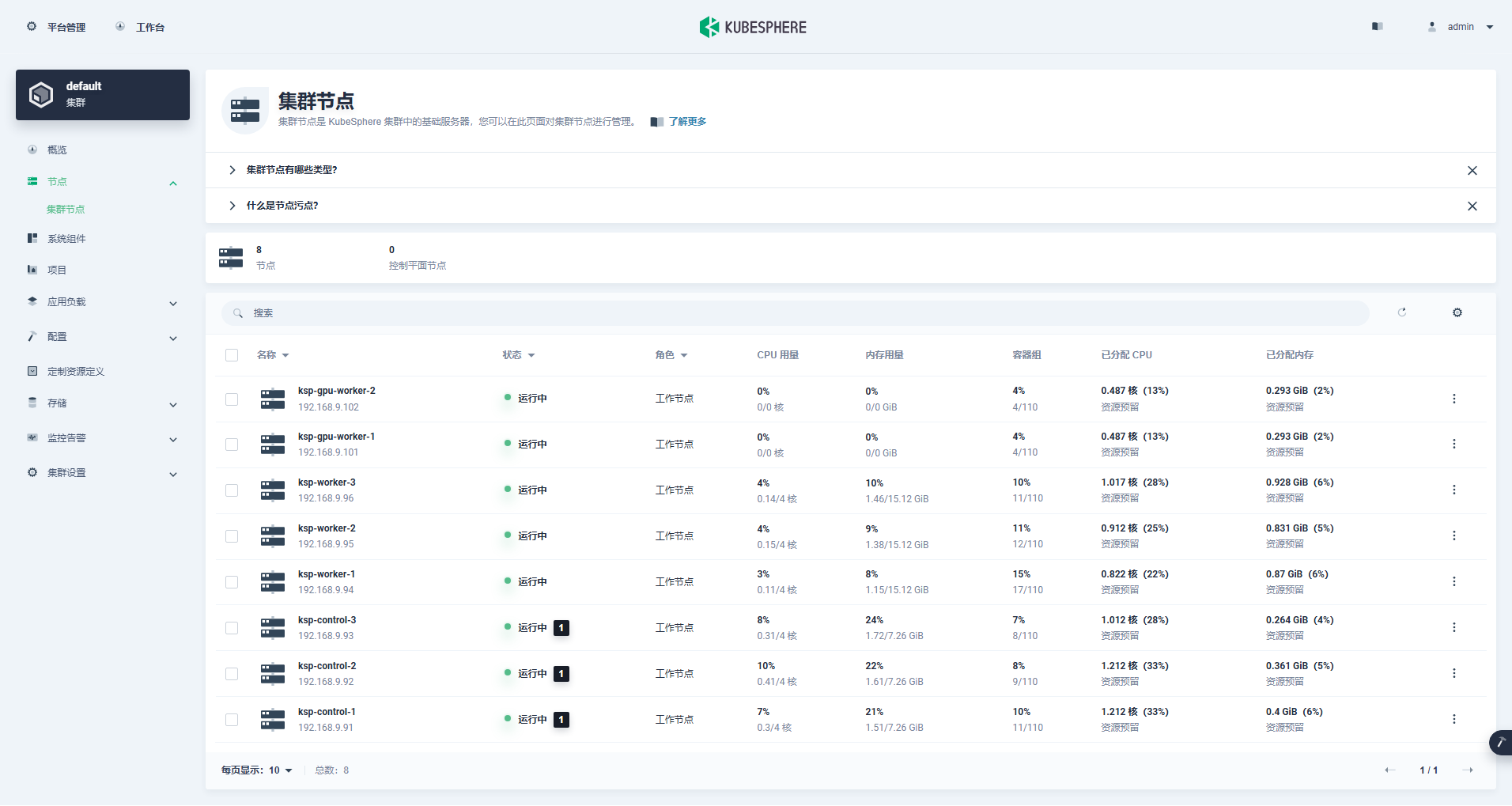
Ejecute el comando kubectl en el nodo Control-1 para obtener la información del nodo del clúster de Kubernetes.
kubectl get nodes -o wideComo puede ver en el resultado, el clúster de Kubernetes actual tiene 8 nodos y se muestran en detalle el nombre, estado, función, tiempo de supervivencia, número de versión de Kubernetes, IP interna, tipo de sistema operativo, versión del kernel y tiempo de ejecución del contenedor de cada nodo. y otra información.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13En este punto, hemos completado todas las tareas relacionadas con el uso de Kubekey para agregar 2 nodos trabajadores al clúster de Kubernetes existente que consta de 3 nodos maestros y 3 nodos trabajadores.
A continuación, instalamos el operador de GPU NVIDIA producido oficialmente por NVIDIA para realizar la programación del Pod K8 para utilizar los recursos de la GPU.
NVIDIA GPU Operador admite la instalación automática de controladores de tarjetas gráficas, pero solo CentOS 7, 8 y Ubuntu 20.04, 22.04 y otras versiones no admiten openEuler, por lo que debe instalar el controlador de la tarjeta gráfica manualmente.
Por favor refiérase a Mejores prácticas de KubeSphere: openEuler 22.03 LTS SP3 instala el controlador de la tarjeta gráfica NVIDIA, complete la instalación del controlador de la tarjeta gráfica.
Node Feature Discovery (NFD) detecta comprobaciones de funciones.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'El resultado de la ejecución del comando anterior es true, ilustrar NFD Ya ejecutándose en el clúster. Si NFD ya se está ejecutando en el clúster, se debe deshabilitar la implementación de NFD al instalar el operador.
ilustrar: Los clústeres K8 implementados con KubeSphere no instalarán ni configurarán NFD de forma predeterminada.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateUtilice el archivo de configuración predeterminado, desactive la instalación automática de los controladores de la tarjeta gráfica e instale el Operador de GPU.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseNota: Dado que la imagen instalada es relativamente grande, puede ocurrir un tiempo de espera durante la instalación inicial. Verifique si su imagen se extrajo correctamente. Puede considerar utilizar la instalación sin conexión para resolver este tipo de problema.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseEl resultado de salida de una ejecución correcta es el siguiente:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneDespués de ejecutar el comando para instalar el Operador de GPU, espere pacientemente hasta que todas las imágenes se extraigan correctamente y todos los Pods estén en estado de ejecución.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110ilustrar: Enfocar
nvidia.com/gpu:El valor del campo.
La carga de trabajo creada exitosamente es la siguiente:
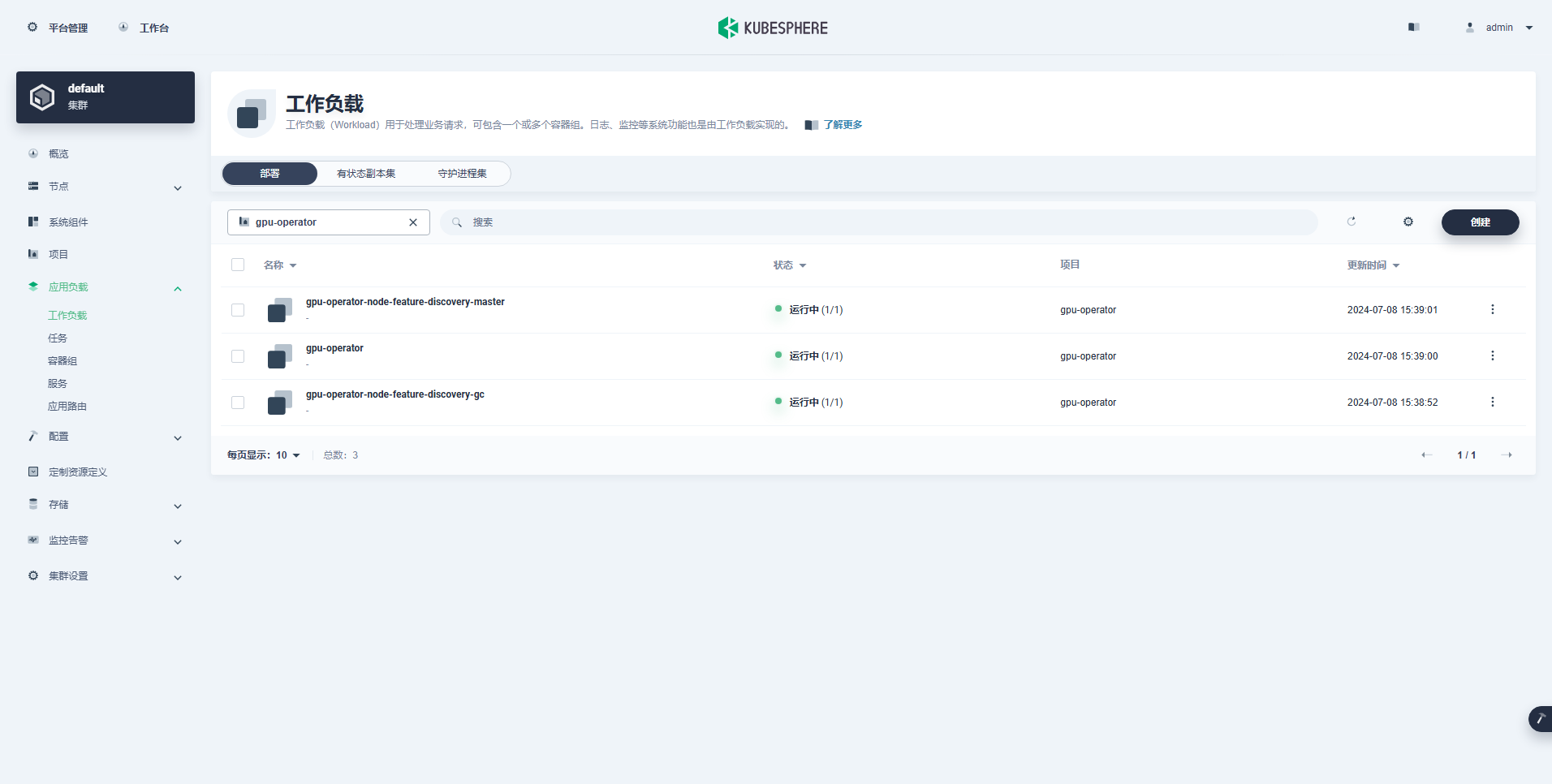
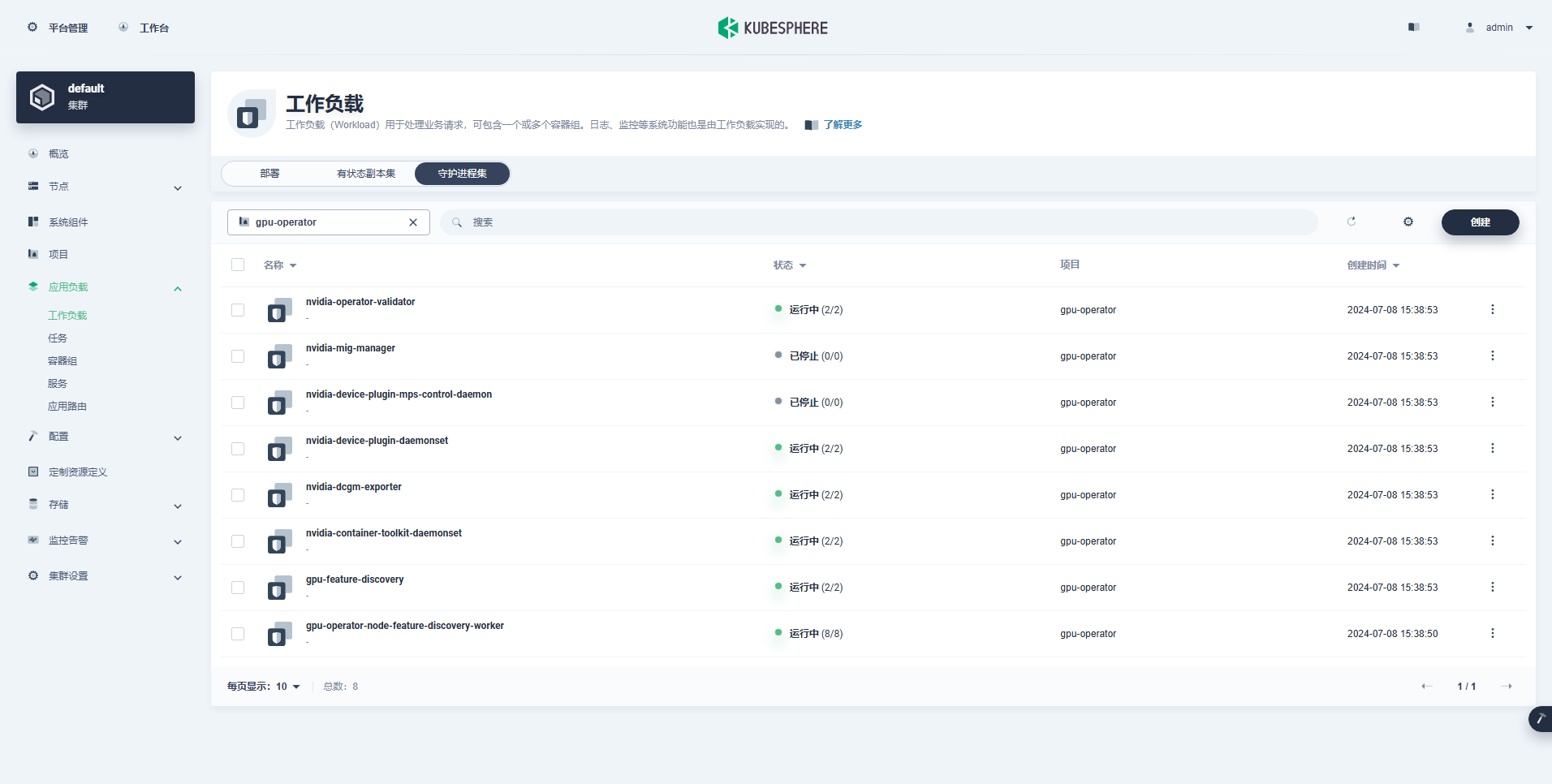
Después de que GPU Operador esté instalado correctamente, use la imagen base CUDA para probar si los K8 pueden crear correctamente Pods que usan recursos de GPU.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlEn los resultados, puede ver que el pod se creó en el nodo ksp-gpu-worker-2 (El modelo de tarjeta gráfica de nodo Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204El resultado de salida de una ejecución correcta es el siguiente:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlImplemente un ejemplo CUDA simple para sumar dos vectores.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlEl Pod se creó correctamente y se ejecutará después del inicio. vectorAdd Comando y salida.
$ kubectl logs pod/cuda-vectoraddEl resultado de salida de una ejecución correcta es el siguiente:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlA través de la prueba de verificación anterior, se demuestra que los recursos Pod que usan GPU se pueden crear en el clúster K8. A continuación, usamos KubeSphere para crear una gran herramienta de administración de modelos, Ollama, en el clúster K8 en función de los requisitos de uso reales.
Este ejemplo es una prueba simple y se selecciona el almacenamiento. ruta del host Modo, reemplácelo con una clase de almacenamiento u otros tipos de almacenamiento persistente en uso real.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortInstrucciones especiales: La consola de administración de KubeSphere admite la configuración gráfica de implementación y otros recursos para usar los recursos de GPU. Los ejemplos de configuración son los siguientes.
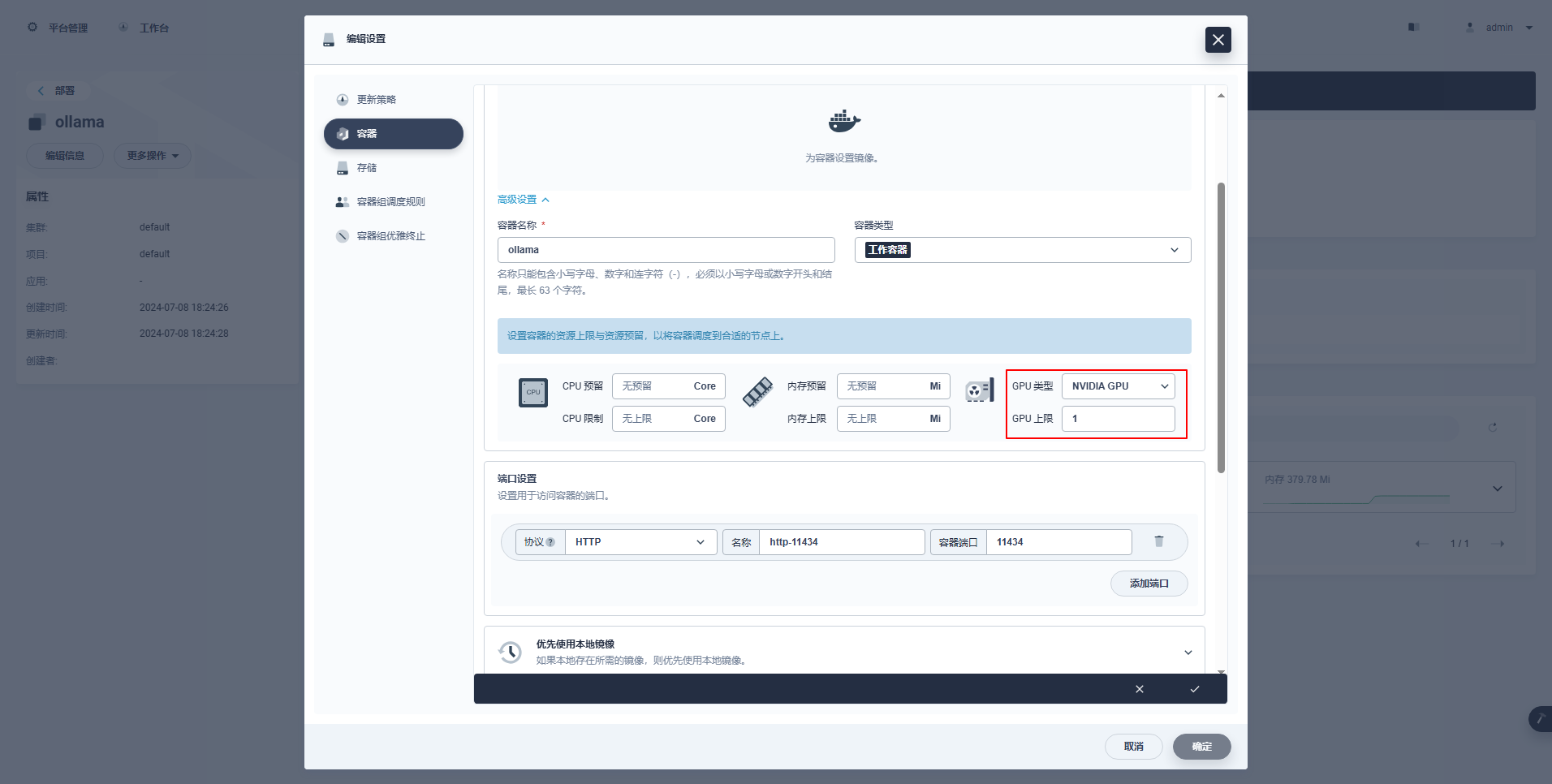
kubectl apply -f deploy-ollama.yamlEn los resultados, puede ver que el pod se creó en el nodo ksp-gpu-worker-1 (La tarjeta gráfica nodo modelo Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Para ahorrar tiempo, este ejemplo utiliza el modelo de tamaño pequeño qwen2 1.5b de código abierto de Alibaba como modelo de prueba.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bEl resultado de salida de una ejecución correcta es el siguiente:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successexistir ksp-gpu-trabajador-1 El nodo ejecuta el siguiente comando de vista
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Ejecutar en el nodo trabajador nvidia-smi -l Observe el uso de la GPU.
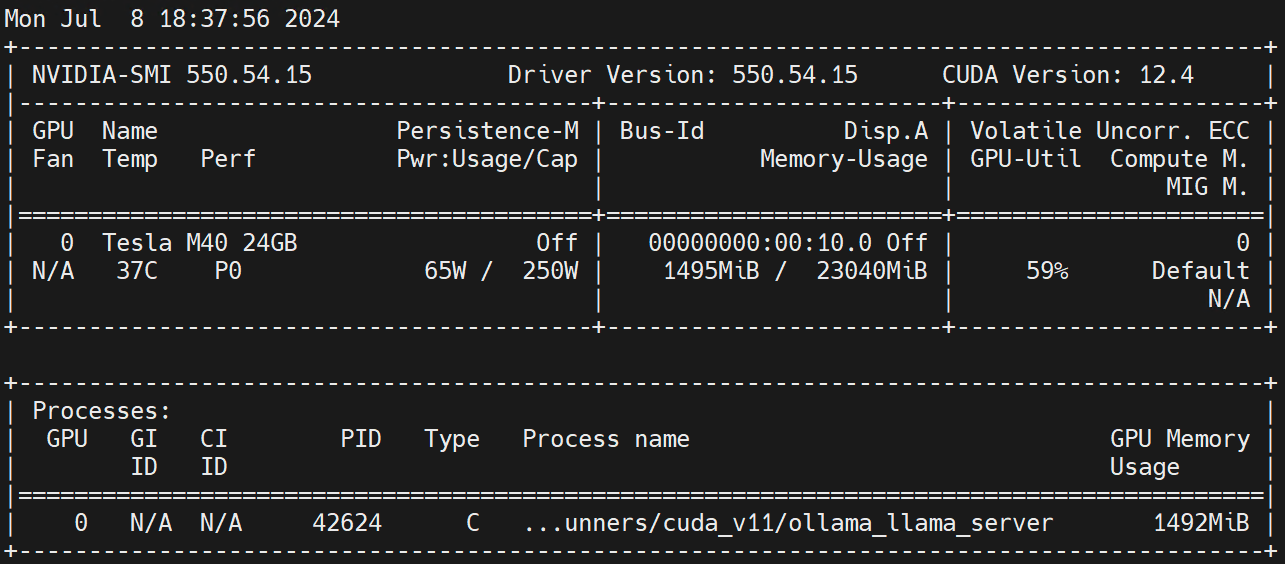
Descargo de responsabilidad:
Este artículo es publicado por la plataforma de publicación múltiple Blog One Post. Escritura abierta ¡liberar!

Se ha dedicado a la investigación de tecnología durante más de 30 años y domina varios lenguajes como java, linux, javascript, php, css, etc. Ha realizado muchas contribuciones en el campo del código abierto. Estación de documentación para desarrolladores para compartir algunos problemas en el desarrollo de tecnología para referencia futura.

Correo[email protected]