
minhas informações de contato
Correspondência[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Autor: Operação e Manutenção Youshu Star Master Com o rápido desenvolvimento da inteligência artificial, aprendizado de máquina e tecnologia de grandes modelos de IA, nossa demanda por recursos de computação também está aumentando. Especialmente para grandes modelos de IA que precisam processar dados em grande escala e algoritmos complexos, o uso de recursos de GPU torna-se crítico. Para engenheiros de operação e manutenção, tornou-se uma habilidade indispensável dominar como gerenciar e configurar recursos de GPU em clusters Kubernetes e como implantar com eficiência aplicativos que dependem desses recursos.
Hoje, vou levá-lo a obter uma compreensão profunda de como usar o poderoso ecossistema e as ferramentas do Kubernetes para obter gerenciamento de recursos de GPU e implantação de aplicativos na plataforma KubeSphere. Aqui estão os três temas principais que este artigo irá explorar:
Ao ler este artigo, você obterá conhecimento e habilidades para gerenciar recursos de GPU no Kubernetes, ajudando você a aproveitar ao máximo os recursos de GPU em um ambiente nativo da nuvem e promover o rápido desenvolvimento de aplicativos de IA.
Prática recomendada do KubeSphere "2024" A configuração de hardware do ambiente experimental e as informações de software da série de documentos são as seguintes:
Configuração real do servidor (réplica 1:1 da arquitetura de um ambiente de produção em pequena escala, a configuração é um pouco diferente)
| Nome da CPU | Propriedade Intelectual | CPU | Memória | disco do sistema | disco de dados | usar |
|---|---|---|---|---|---|---|
| registro ksp | 192.168.9.90 | 4 | 8 | 40 | 200 | Armazém de espelhos portuários |
| ksp-controle-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/plano de controle k8s |
| ksp-controle-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/plano de controle k8s |
| ksp-controle-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/plano de controle k8s |
| ksp-trabalhador-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-trabalhador/CI |
| ksp-trabalhador-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-trabalhador |
| ksp-trabalhador-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-trabalhador |
| ksp-armazenamento-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-armazenamento-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-armazenamento-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-trabalhador-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-trabalhador-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | Gateway proxy/VIP de serviço de aplicativo autoconstruído: 192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | Gateway proxy/VIP de serviço de aplicativo autoconstruído: 192.168.9.100 | |
| ksp-médio | 192.168.9.105 | 4 | 8 | 40 | 100 | Nós de serviço implantados fora do cluster k8s (Gitlab, etc.) |
| total | 15 | 56 | 152 | 600 | 2000 |
O ambiente de combate real envolve informações sobre a versão do software
Devido a restrições de recursos e custos, não tenho um host físico de última geração e uma placa gráfica para experimentar. Apenas duas máquinas virtuais equipadas com placas gráficas GPU básicas podem ser adicionadas como nós de trabalho do cluster.
Embora essas placas gráficas não sejam tão poderosas quanto os modelos de última geração, elas são suficientes para a maioria das tarefas de aprendizado e desenvolvimento. Com recursos limitados, essa configuração me fornece oportunidades práticas valiosas para explorar profundamente os recursos de GPU no gerenciamento e clusters Kubernetes. estratégias de agendamento.
Consulte Guia de inicialização do sistema Kubernetes cluster node openEuler 22.03 LTS SP3, conclua a configuração de inicialização do sistema operacional.
O guia de configuração inicial não envolve tarefas de atualização do sistema operacional Ao inicializar o sistema em um ambiente com acesso à Internet, você deve atualizar o sistema operacional e, em seguida, reiniciar o nó.
Em seguida, usamos o KubeKey para adicionar o nó GPU recém-adicionado ao cluster Kubernetes existente. Consulte a documentação oficial. Todo o processo é relativamente simples e requer apenas duas etapas.
No nó Control-1, mude para o diretório kubekey para implantação e modifique o arquivo de configuração do cluster original. O nome que usamos no combate real é. ksp-v341-v1288.yaml, modifique-o de acordo com a situação real.
Principais pontos de modificação:
O exemplo modificado é o seguinte:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Antes de adicionar nós, vamos confirmar as informações do nó do cluster atual.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Em seguida, executamos o seguinte comando e usamos o arquivo de configuração modificado para adicionar o novo nó Worker ao cluster.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlApós a execução do comando acima, o KubeKey primeiro verifica se as dependências e outras configurações para implantação do Kubernetes atendem aos requisitos. Depois de passar na verificação, você será solicitado a confirmar a instalação.digitarsim e pressione ENTER para continuar a implantação.
Demora cerca de 5 minutos para concluir a implantação. O tempo específico depende da velocidade da rede, da configuração da máquina e do número de nós adicionados.
Assim que a implantação for concluída, você deverá ver uma saída semelhante à seguinte em seu terminal.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyAbrimos o navegador e acessamos o endereço IP e a porta do nó Control-1 30880, efetue login na página de login do console de gerenciamento KubeSphere.
Entre na interface de gerenciamento de cluster, clique no menu "Nó" à esquerda e clique em "Nó de cluster" para visualizar informações detalhadas sobre os nós disponíveis do cluster Kubernetes.
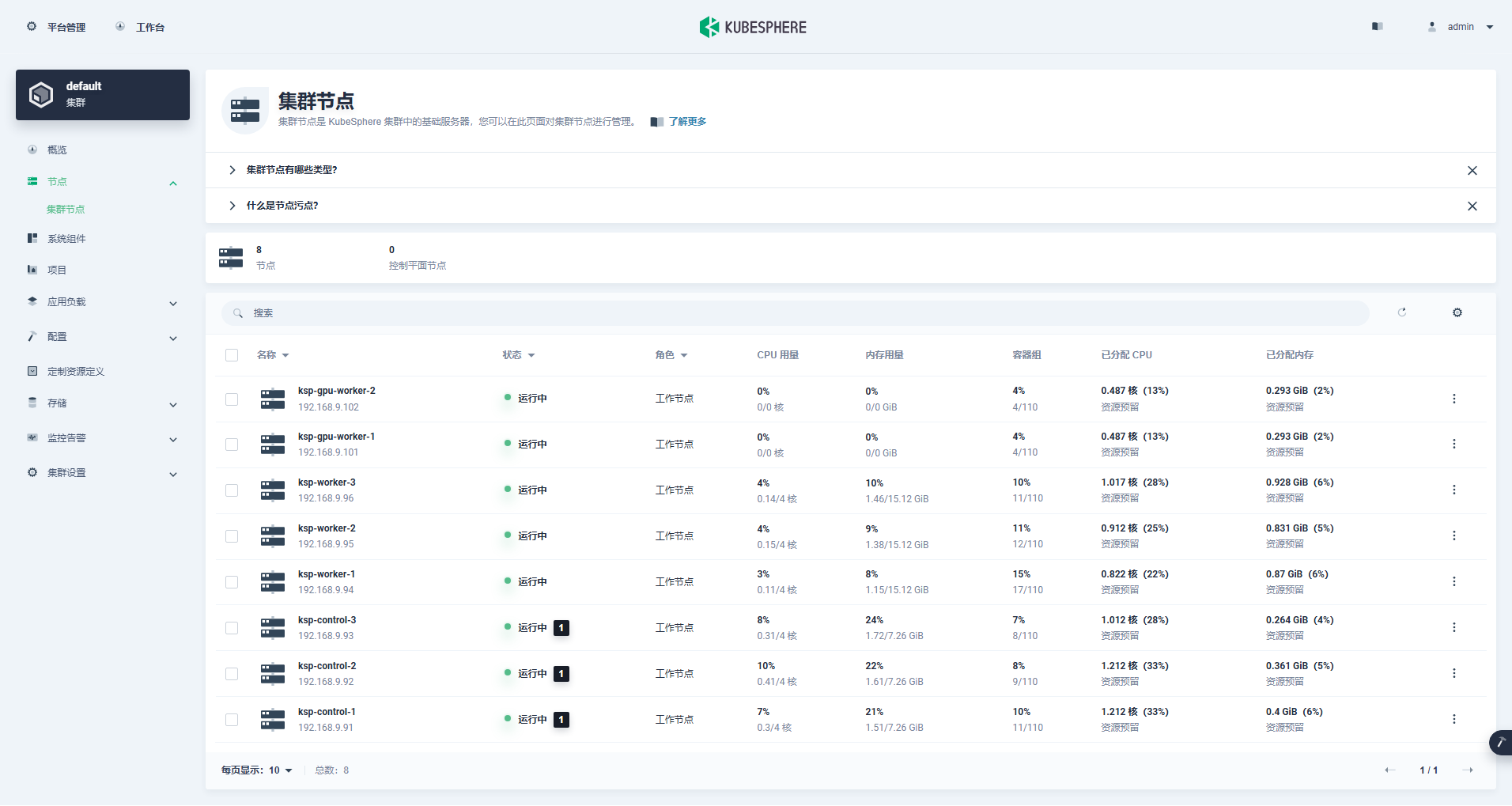
Execute o comando kubectl no nó Control-1 para obter as informações do nó do cluster Kubernetes.
kubectl get nodes -o wideComo você pode ver na saída, o cluster Kubernetes atual tem 8 nós, e o nome, status, função, tempo de sobrevivência, número de versão do Kubernetes, IP interno, tipo de sistema operacional, versão do kernel e tempo de execução do contêiner de cada nó são exibidos em detalhes . e outras informações.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Neste ponto, concluímos todas as tarefas de uso do Kubekey para adicionar 2 nós de trabalho ao cluster Kubernetes existente que consiste em 3 nós mestres e 3 nós de trabalho.
Em seguida, instalamos o NVIDIA GPU Operator produzido oficialmente pela NVIDIA para realizar o agendamento do Pod K8 para usar recursos da GPU.
Operador de GPU NVIDIA suporta instalação automática de driver gráfico, mas apenas CentOS 7, 8 e Ubuntu 20.04, 22.04 e outras versões não suportam openEuler, então você precisa instalar o driver gráfico manualmente.
Consulte Prática recomendada do KubeSphere: openEuler 22.03 LTS SP3 instala driver da placa gráfica NVIDIA, conclua a instalação do driver da placa gráfica.
Node Feature Discovery (NFD) detecta verificações de recursos.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'O resultado da execução do comando acima é true, ilustrar NFD Já em execução no cluster. Se o NFD já estiver em execução no cluster, a implantação do NFD deverá ser desabilitada ao instalar o operador.
ilustrar: Os clusters K8s implementados usando o KubeSphere não instalarão e configurarão o NFD por padrão.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateUse o arquivo de configuração padrão, desative a instalação automática dos drivers da placa gráfica e instale o Operador GPU.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseNota: Como a imagem instalada é relativamente grande, pode ocorrer um tempo limite durante a instalação inicial. Verifique se sua imagem foi extraída com sucesso! Você pode considerar o uso da instalação offline para resolver esse tipo de problema.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseO resultado de saída da execução correta é o seguinte:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneDepois de executar o comando para instalar o GPU Operator, aguarde pacientemente até que todas as imagens sejam extraídas com sucesso e todos os pods estejam no estado Running.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110ilustrar: Foco
nvidia.com/gpu:O valor do campo.
A carga de trabalho criada com sucesso é a seguinte:
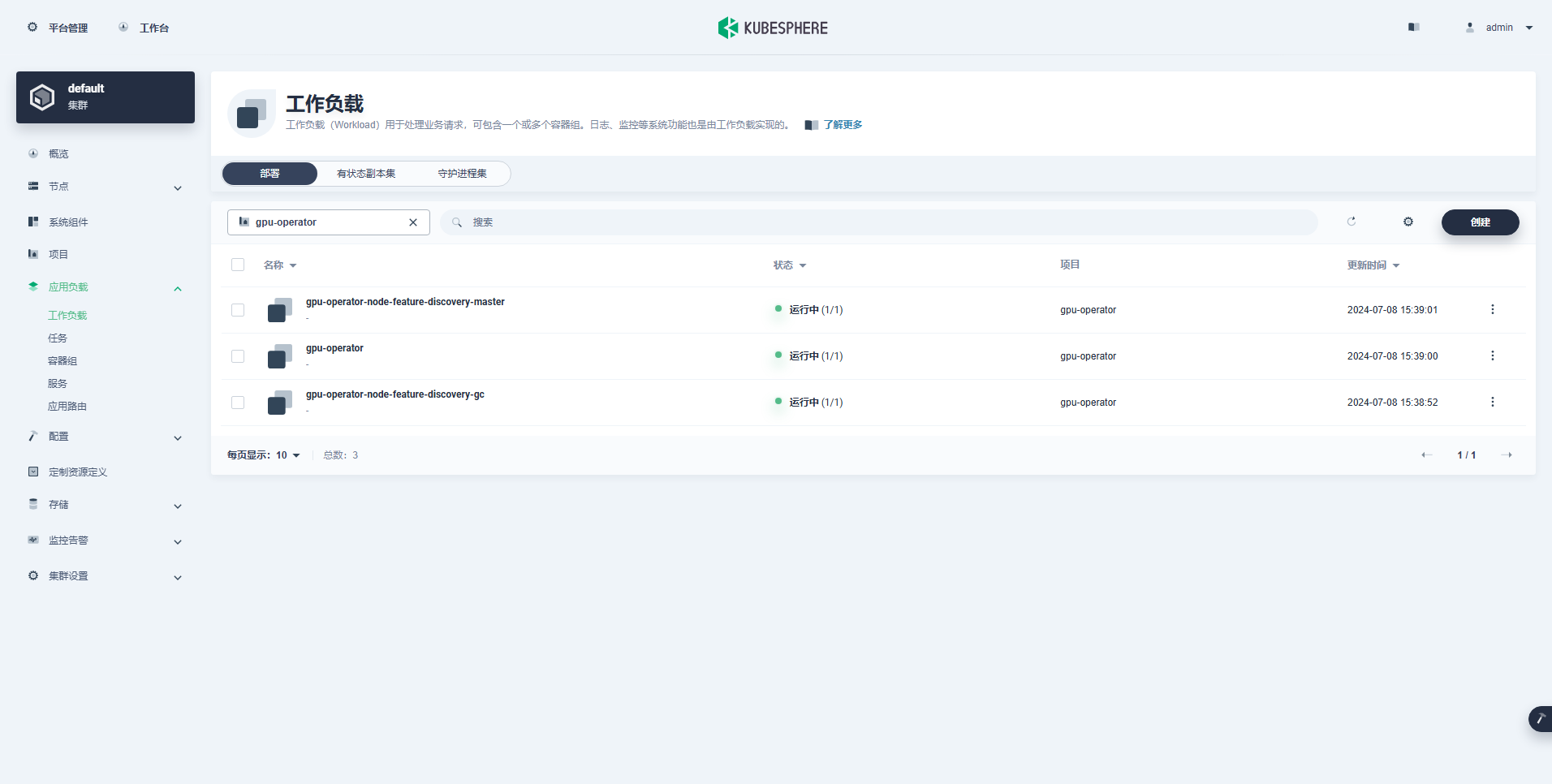
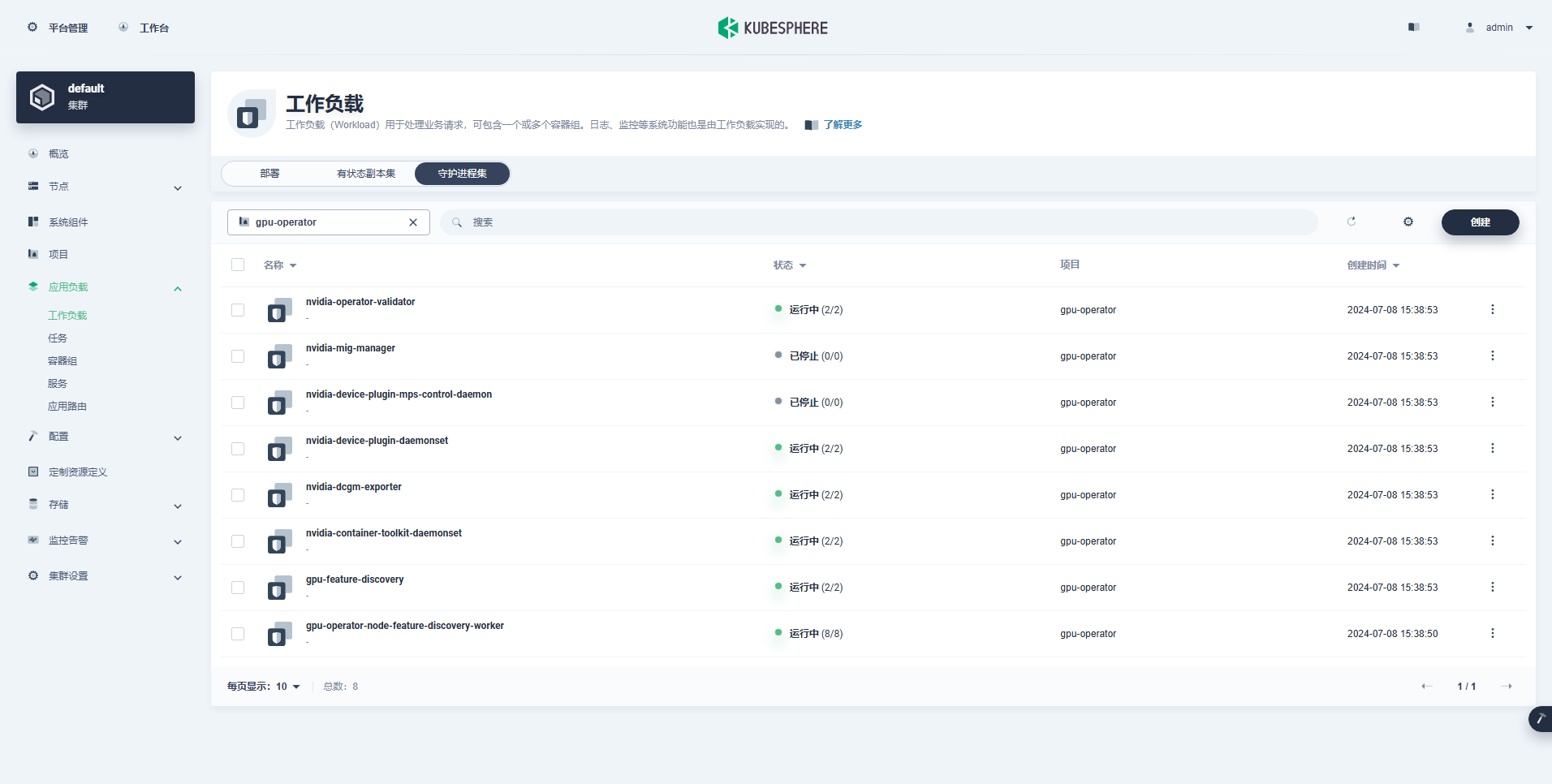
Depois que o Operador de GPU estiver instalado corretamente, use a imagem base CUDA para testar se os K8s podem criar pods corretamente que usam recursos de GPU.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlA partir dos resultados, você pode ver que o pod foi criado no nó ksp-gpu-worker-2 (O modelo de placa gráfica de nó Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204O resultado de saída da execução correta é o seguinte:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlImplemente um exemplo simples de CUDA para adicionar dois vetores.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlO pod foi criado com sucesso e será executado após a inicialização. vectorAdd comando e saia.
$ kubectl logs pod/cuda-vectoraddO resultado de saída da execução correta é o seguinte:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlAtravés do teste de verificação acima, foi provado que os recursos do Pod usando GPU podem ser criados no cluster K8s. Em seguida, usamos o KubeSphere para criar uma grande ferramenta de gerenciamento de modelo Ollama no cluster K8s com base nos requisitos de uso reais.
Este exemplo é um teste simples e o armazenamento é selecionado caminho do host Modo, substitua-o por classe de armazenamento ou outros tipos de armazenamento persistente em uso real.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortInstruções Especiais: O console de gerenciamento do KubeSphere suporta configuração gráfica de implantação e outros recursos para usar recursos de GPU. Os exemplos de configuração são os seguintes.
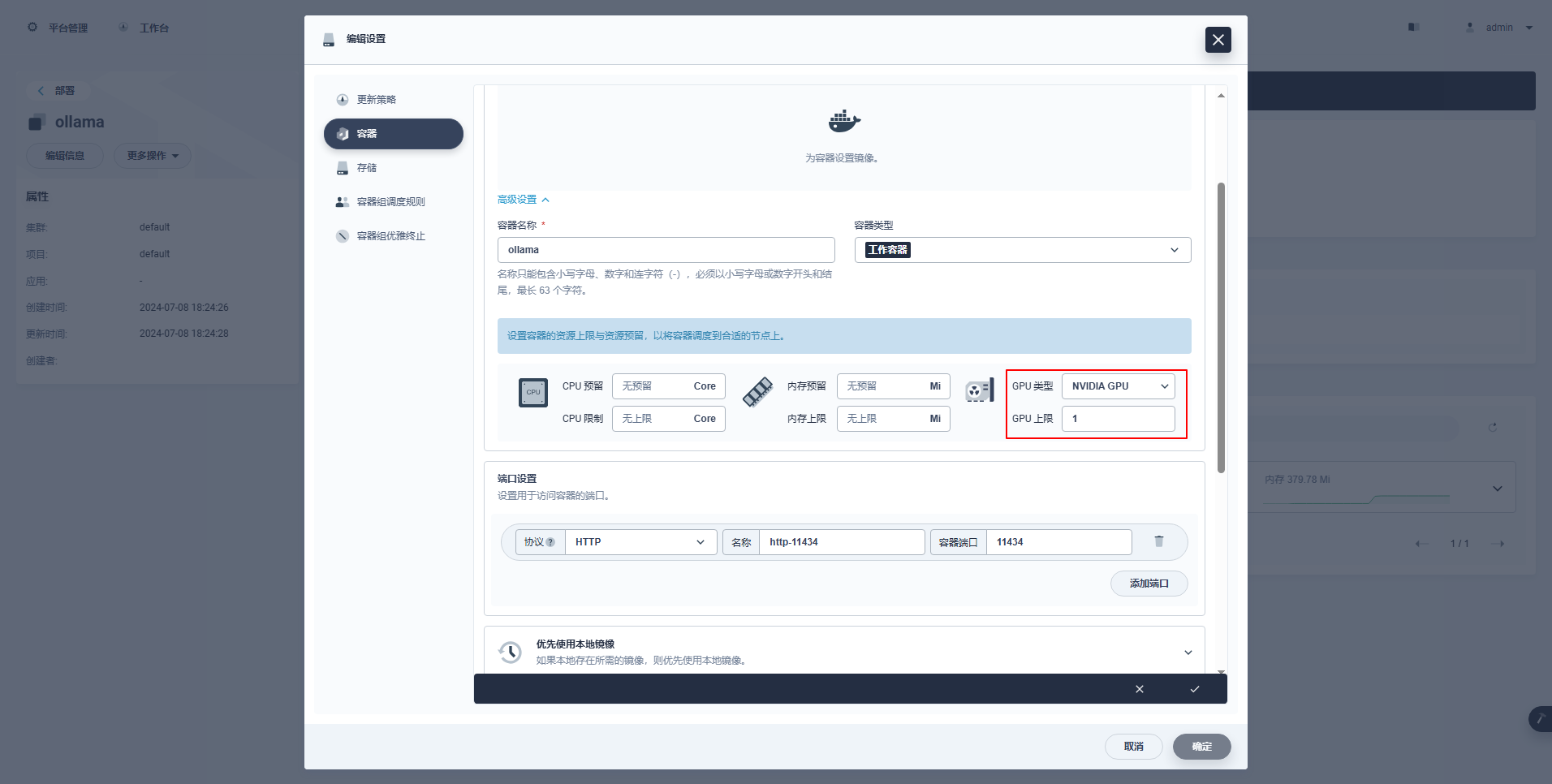
kubectl apply -f deploy-ollama.yamlA partir dos resultados, você pode ver que o pod foi criado no nó ksp-gpu-worker-1 (O modelo de placa gráfica de nó Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Para economizar tempo, este exemplo usa o modelo de tamanho pequeno qwen2 1.5b de código aberto do Alibaba como modelo de teste.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bO resultado de saída da execução correta é o seguinte:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successexistir ksp-gpu-trabalhador-1 O nó executa o seguinte comando de visualização
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Executar no nó de trabalho nvidia-smi -l Observe o uso da GPU.
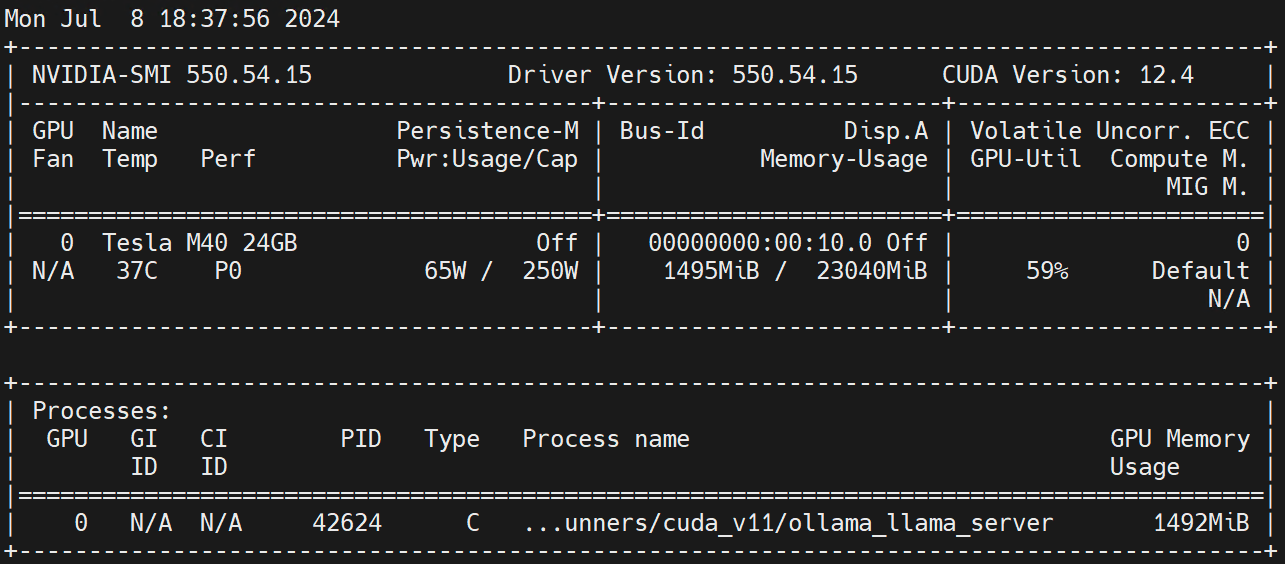
Isenção de responsabilidade:
Este artigo foi publicado pela plataforma multipublicação Blog One Post Escrita Aberta liberar!

Ele se dedica à pesquisa de tecnologia há mais de 30 anos e é proficiente em diversas linguagens como java, linux, javascript, php, css, etc. estação de documentação do desenvolvedor para compartilhar alguns problemas no desenvolvimento de tecnologia para referência futura.

Correspondência[email protected]