
le mie informazioni di contatto
Posta[email protected]
2024-07-12
한어Русский языкEnglishFrançaisIndonesianSanskrit日本語DeutschPortuguêsΕλληνικάespañolItalianoSuomalainenLatina
Autore: Funzionamento e manutenzione Youshu Star Master Con il rapido sviluppo dell'intelligenza artificiale, dell'apprendimento automatico e della tecnologia dei modelli di grandi dimensioni dell'intelligenza artificiale, anche la nostra domanda di risorse informatiche è in aumento. Soprattutto per i modelli di intelligenza artificiale di grandi dimensioni che devono elaborare dati su larga scala e algoritmi complessi, l’uso delle risorse GPU diventa fondamentale. Per gli ingegneri operativi e di manutenzione, è diventata una competenza indispensabile padroneggiare come gestire e configurare le risorse GPU sui cluster Kubernetes e come distribuire in modo efficiente le applicazioni che si basano su queste risorse.
Oggi ti guiderò ad acquisire una comprensione approfondita di come utilizzare il potente ecosistema e gli strumenti di Kubernetes per ottenere la gestione delle risorse GPU e la distribuzione delle applicazioni sulla piattaforma KubeSphere. Ecco i tre temi principali che questo articolo esplorerà:
Leggendo questo articolo acquisirai le conoscenze e le competenze per gestire le risorse GPU su Kubernetes, aiutandoti a sfruttare appieno le risorse GPU in un ambiente cloud-native e a promuovere il rapido sviluppo di applicazioni AI.
Miglior pratica KubeSphere "2024" La configurazione hardware dell'ambiente sperimentale e le informazioni software della serie di documenti sono le seguenti:
Configurazione effettiva del server (replica 1:1 dell'architettura di un ambiente di produzione su piccola scala, la configurazione è leggermente diversa)
| Nome della CPU | Proprietà intellettuale | processore | Memoria | disco di sistema | disco dati | utilizzo |
|---|---|---|---|---|---|---|
| registro ksp | 192.168.9.90 | 4 | 8 | 40 | 200 | Magazzino degli specchi del porto |
| controllo ksp-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-piano-di-controllo |
| controllo ksp-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-piano-di-controllo |
| controllo ksp-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-piano-di-controllo |
| ksp-lavoratore-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-lavoratore/CI |
| ksp-lavoratore-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-lavoratore |
| ksp-lavoratore-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-lavoratore |
| ksp-archiviazione-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | Ricerca Elastica/Ceph/Longhorn/NFS/ |
| ksp-archiviazione-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | Ricerca Elastica//Ceph/Longhorn |
| ksp-archiviazione-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | Ricerca Elastica//Ceph/Longhorn |
| ksp-gpu-lavoratore-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-lavoratore-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker (GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | Gateway proxy/VIP del servizio applicativo autocostruito: 192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | Gateway proxy/VIP del servizio applicativo autocostruito: 192.168.9.100 | |
| ksp-medio | 192.168.9.105 | 4 | 8 | 40 | 100 | Nodi di servizio distribuiti all'esterno del cluster k8s (Gitlab, ecc.) |
| totale | 15 | 56 | 152 | 600 | 2000 |
L'ambiente di combattimento reale prevede informazioni sulla versione del software
A causa dei vincoli in termini di risorse e costi, non dispongo di un host fisico e di una scheda grafica di fascia alta con cui sperimentare. È possibile aggiungere solo due macchine virtuali dotate di schede grafiche GPU entry-level come nodi di lavoro del cluster.
Sebbene queste schede grafiche non siano potenti come i modelli di fascia alta, sono sufficienti per la maggior parte delle attività di apprendimento e sviluppo. Con risorse limitate, una configurazione di questo tipo mi offre preziose opportunità pratiche per esplorare in modo approfondito le risorse GPU nella gestione dei cluster Kubernetes strategie di pianificazione.
Per favore riferisci a Guida all'inizializzazione del sistema del nodo cluster Kubernetes openEuler 22.03 LTS SP3, completare la configurazione di inizializzazione del sistema operativo.
La guida alla configurazione iniziale non prevede attività di aggiornamento del sistema operativo Quando si inizializza il sistema in un ambiente con accesso a Internet, è necessario aggiornare il sistema operativo e quindi riavviare il nodo.
Successivamente, utilizziamo KubeKey per aggiungere il nodo GPU appena aggiunto al cluster Kubernetes esistente. Fare riferimento alla documentazione ufficiale. L'intero processo è relativamente semplice e richiede solo due passaggi.
Sul nodo Control-1, passa alla directory kubekey per la distribuzione e modifica il file di configurazione del cluster originale. Il nome che abbiamo utilizzato nel combattimento reale è ksp-v341-v1288.yaml, modificarlo in base alla situazione reale.
Principali punti di modifica:
L'esempio modificato è il seguente:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变Prima di aggiungere nodi, confermiamo le informazioni sul nodo del cluster corrente.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13Successivamente, eseguiamo il comando seguente e utilizziamo il file di configurazione modificato per aggiungere il nuovo nodo di lavoro al cluster.
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yamlDopo aver eseguito il comando precedente, KubeKey controlla innanzitutto se le dipendenze e le altre configurazioni per la distribuzione di Kubernetes soddisfano i requisiti. Dopo aver superato il controllo, ti verrà richiesto di confermare l'installazione.accedereSÌ e premere INVIO per continuare la distribuzione.
Sono necessari circa 5 minuti per completare la distribuzione. Il tempo specifico dipende dalla velocità della rete, dalla configurazione della macchina e dal numero di nodi aggiunti.
Una volta completata la distribuzione, dovresti vedere un output simile al seguente sul tuo terminale.
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfullyApriamo il browser e accediamo all'indirizzo IP e alla porta del nodo Control-1 30880, accedere alla pagina di login della console di gestione KubeSphere.
Accedere all'interfaccia di gestione del cluster, fare clic sul menu "Nodo" a sinistra, quindi fare clic su "Nodo cluster" per visualizzare informazioni dettagliate sui nodi disponibili del cluster Kubernetes.
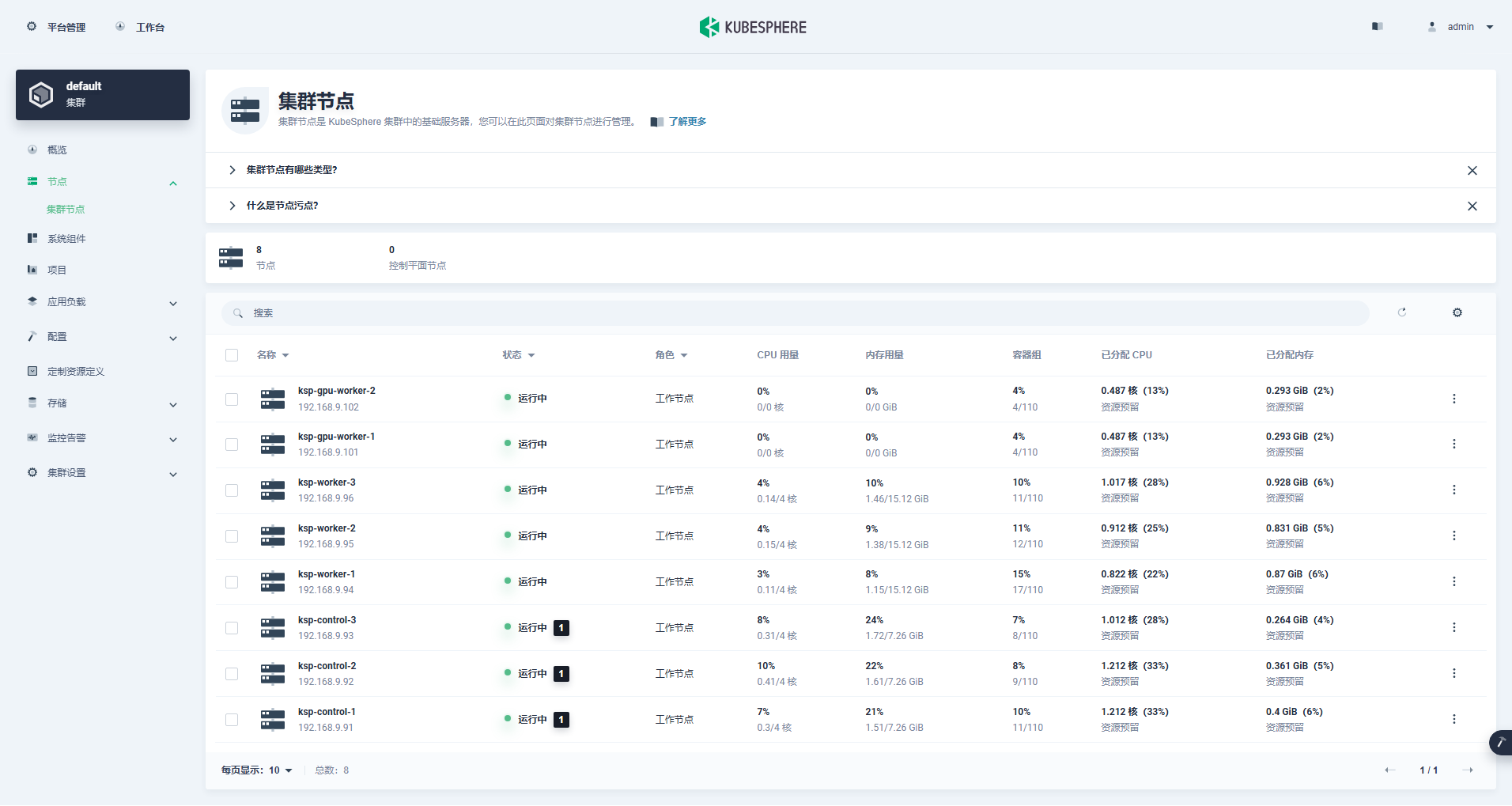
Esegui il comando kubectl sul nodo Control-1 per ottenere le informazioni sul nodo del cluster Kubernetes.
kubectl get nodes -o wideCome puoi vedere nell'output, l'attuale cluster Kubernetes ha 8 nodi e il nome, lo stato, il ruolo, il tempo di sopravvivenza, il numero di versione di Kubernetes, l'IP interno, il tipo di sistema operativo, la versione del kernel e il runtime del contenitore di ciascun nodo vengono visualizzati in dettaglio e altre informazioni.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13A questo punto, abbiamo completato tutte le attività relative all'utilizzo di Kubekey per aggiungere 2 nodi di lavoro al cluster Kubernetes esistente composto da 3 nodi Master e 3 nodi di lavoro.
Successivamente, installiamo NVIDIA GPU Operator prodotto ufficialmente da NVIDIA per realizzare il pod di pianificazione K8 per utilizzare le risorse GPU.
NVIDIA GPU Operator supporta l'installazione automatica del driver grafico, ma solo CentOS 7, 8 e Ubuntu 20.04, 22.04 e altre versioni non supportano openEuler, quindi è necessario installare manualmente il driver grafico.
Per favore riferisci a Le migliori pratiche di KubeSphere: openEuler 22.03 LTS SP3 installa il driver della scheda grafica NVIDIA, completare l'installazione del driver della scheda grafica.
Node Feature Discovery (NFD) rileva i controlli delle funzionalità.
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'Il risultato dell'esecuzione del comando precedente è true, illustrare NFD Già in esecuzione nel cluster. Se NFD è già in esecuzione nel cluster, la distribuzione di NFD deve essere disabilitata durante l'installazione dell'operatore.
illustrare: I cluster K8 distribuiti utilizzando KubeSphere non installeranno e configureranno NFD per impostazione predefinita.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo updateUtilizza il file di configurazione predefinito, disabilita l'installazione automatica dei driver della scheda grafica e installa GPU Operator.
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseNota: poiché l'immagine installata è relativamente grande, durante l'installazione iniziale potrebbe verificarsi un timeout. Controlla se l'immagine è stata estratta correttamente! Puoi prendere in considerazione l'utilizzo dell'installazione offline per risolvere questo tipo di problema.
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=falseIl risultato di output dell'esecuzione corretta è il seguente:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: NoneDopo aver eseguito il comando per installare GPU Operator, attendi pazientemente finché tutte le immagini non vengono estratte correttamente e tutti i pod sono nello stato In esecuzione.
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110illustrare: Messa a fuoco
nvidia.com/gpu:Il valore del campo.
Il carico di lavoro creato correttamente è il seguente:
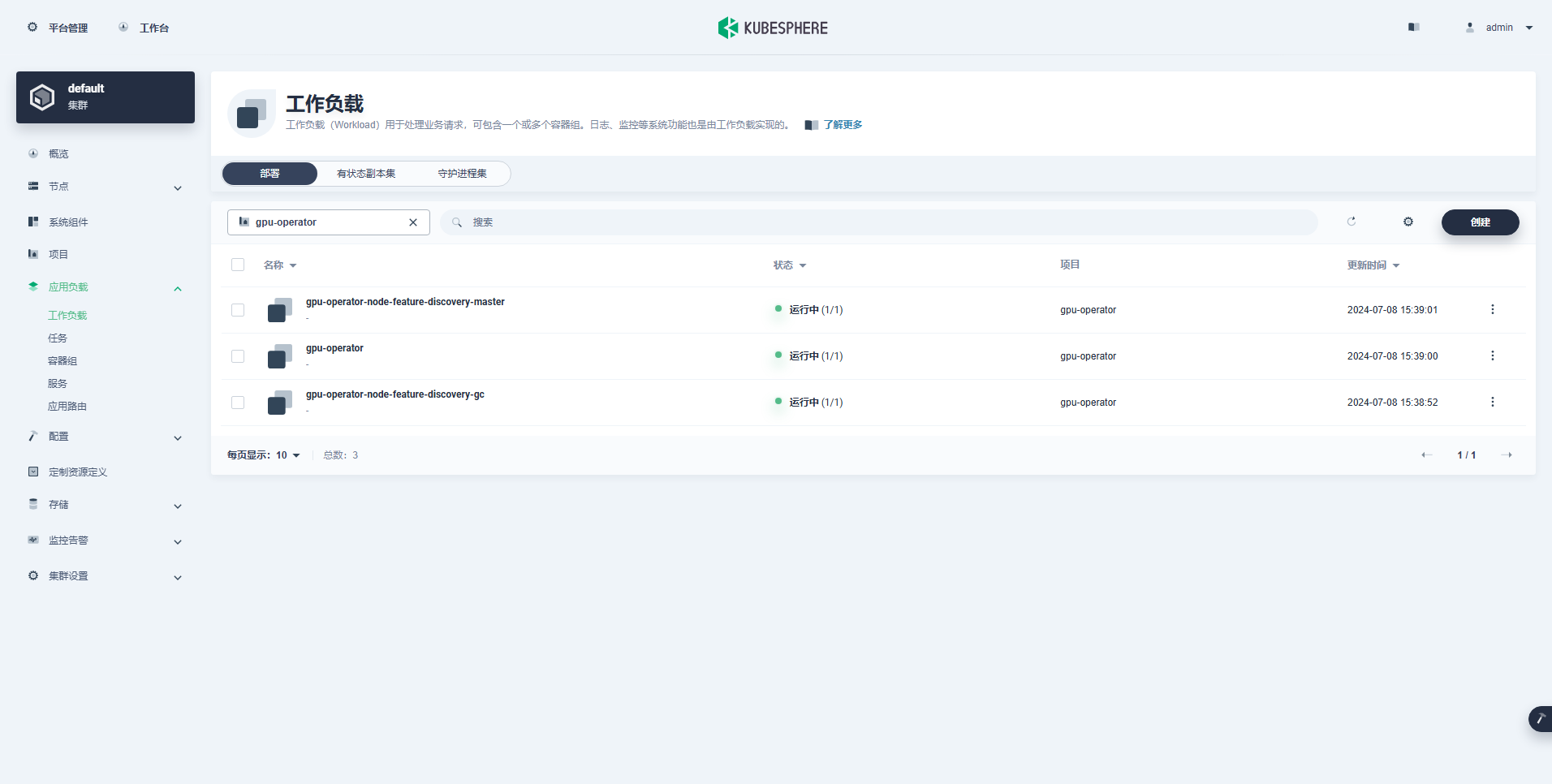
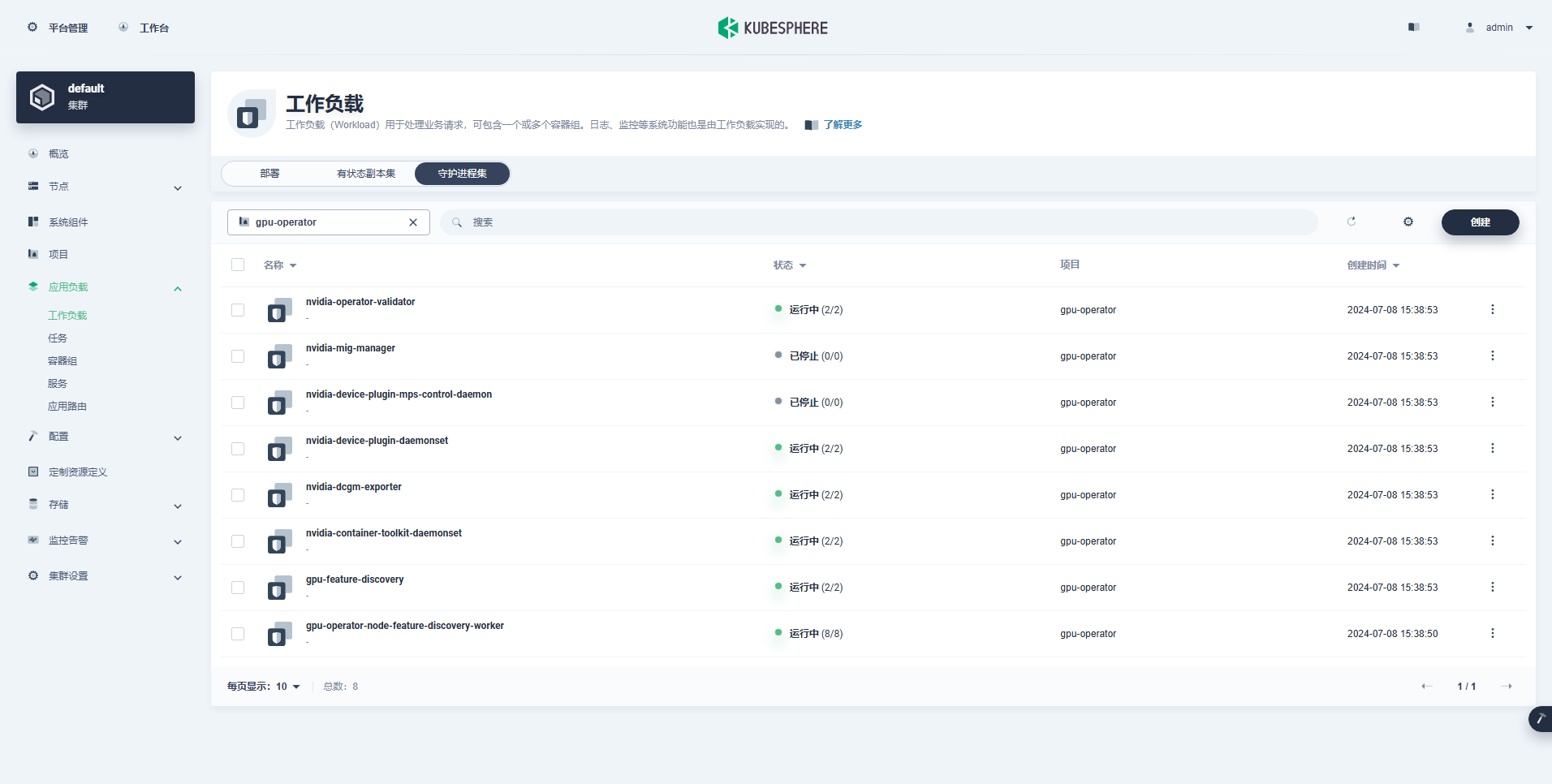
Dopo aver installato correttamente GPU Operator, utilizza l'immagine di base CUDA per verificare se i K8 possono creare correttamente pod che utilizzano le risorse GPU.
vi cuda-ubuntu.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]kubectl apply -f cuda-ubuntu.yamlDai risultati, puoi vedere che il pod è stato creato sul nodo ksp-gpu-worker-2 (Il modello della scheda grafica del nodo Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>kubectl logs pod/cuda-ubuntu2204Il risultato di output dell'esecuzione corretta è il seguente:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+kubectl apply -f cuda-ubuntu.yamlImplementa un semplice esempio CUDA per aggiungere due vettori.
vi cuda-vectoradd.yamlapiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1$ kubectl apply -f cuda-vectoradd.yamlIl pod è stato creato correttamente e verrà eseguito dopo l'avvio. vectorAdd comando ed esci.
$ kubectl logs pod/cuda-vectoraddIl risultato di output dell'esecuzione corretta è il seguente:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Donekubectl delete -f cuda-vectoradd.yamlAttraverso il test di verifica di cui sopra, è stato dimostrato che le risorse Pod che utilizzano la GPU possono essere create sul cluster K8. Successivamente, utilizziamo KubeSphere per creare un grande strumento di gestione del modello Ollama nel cluster K8 in base ai requisiti di utilizzo effettivi.
Questo esempio è un semplice test e l'archiviazione è selezionata PercorsoOspite Modalità, sostituirla con la classe di archiviazione o altri tipi di archiviazione persistente effettivamente in uso.
vi deploy-ollama.yamlkind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePortIstruzioni speciali: La console di gestione di KubeSphere supporta la configurazione grafica della distribuzione e di altre risorse per utilizzare le risorse GPU. Gli esempi di configurazione sono i seguenti. Gli amici interessati possono studiare da soli.
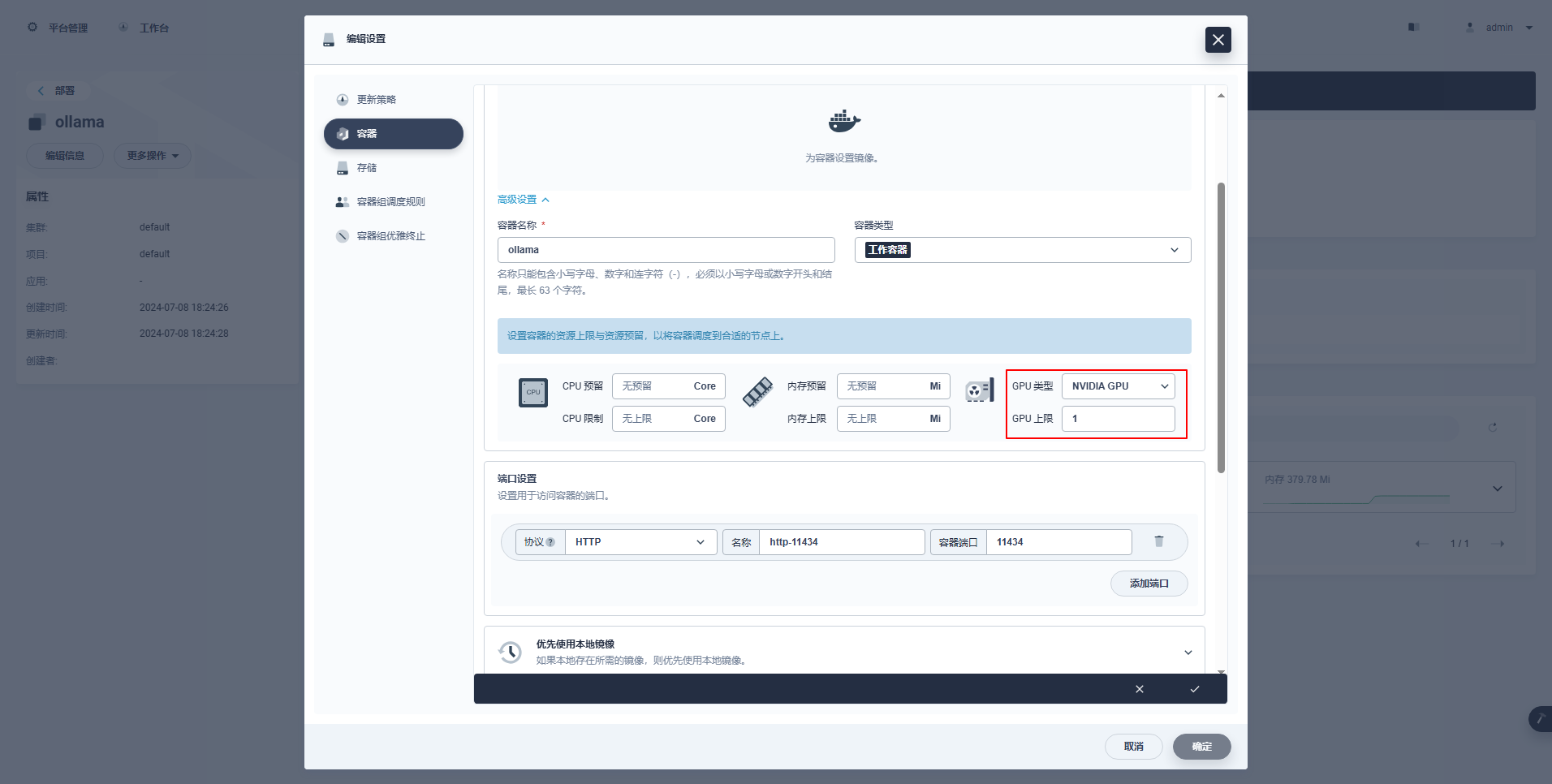
kubectl apply -f deploy-ollama.yamlDai risultati, puoi vedere che il pod è stato creato sul nodo ksp-gpu-worker-1 (Il modello di scheda grafica del nodo Tesla M40 da 24 GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"Per risparmiare tempo, questo esempio utilizza il modello di piccole dimensioni qwen2 1.5b open source di Alibaba come modello di test.
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5bIl risultato di output dell'esecuzione corretta è il seguente:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
successesistere ksp-gpu-lavoratore-1 Il nodo esegue il seguente comando di visualizzazione
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5bcurl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1Esegui sul nodo di lavoro nvidia-smi -l Osserva l'utilizzo della GPU.
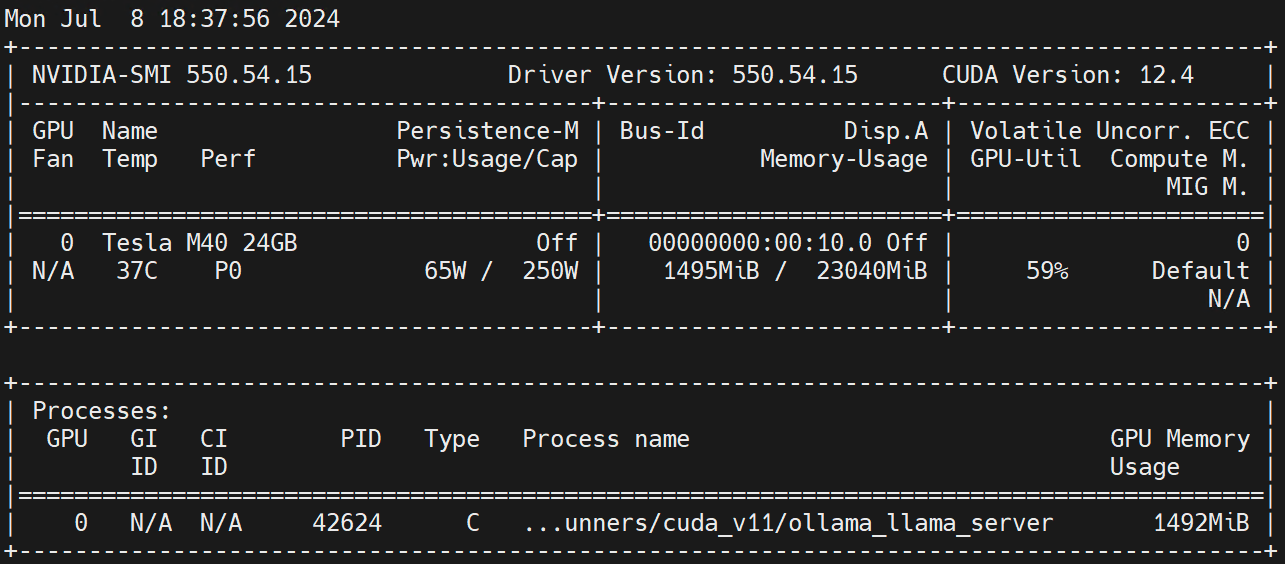
Disclaimer:
Questo articolo è pubblicato da Blog One Post Multi-Publishing Platform ApriScrivi pubblicazione!

Si dedica alla ricerca tecnologica da più di 30 anni ed è esperto in vari linguaggi come Java, Linux, Javascript, php, css, ecc. Ha dato numerosi contributi nel campo dell'open source stazione di documentazione per gli sviluppatori per condividere alcuni problemi nello sviluppo della tecnologia per riferimento futuro

Posta[email protected]